一種視頻信息結構組織方法和系統與流程
本發明涉及視頻技術領域,具體涉及一種視頻信息結構組織方法和系統。
背景技術:
隨著寬帶網絡的普及、計算機技術的發展以及圖像處理技術的提高,視頻監控技術作為協助公共安全部門打擊犯罪、維持社會安定的重要手段,越來越廣泛地滲透到人們日常生活的各種領域。然而,現有的監控視頻智能分析方法處于需要借助數據中心的海量存儲能力進行事后分析、人力分析的低層次水平,無法真正做到視頻分析的實時性和智能化。
技術實現要素:
有鑒于此,本發明實施例提供了一種視頻信息結構組織方法和系統,解決了現有技術中對視頻的分析在借助數據中心的海量存儲能力的基礎上不能做到實時分析和智能化的問題。
本發明實施例提供的一種視頻信息結構組織方法包括:
獲取視頻現場原始數據,構建基本場景數據層;
將基本場景數據層進行實時分層處理,形成層級數據,按需輸出。
本發明實施例提供的一種視頻信息結構組織系統包括:
收集數據裝置101,用于獲取視頻現場原始數據,構建基本場景數據層;
分層處理裝置102,用于將基本場景數據層進行實時分層處理,形成層級數據,按需輸出。
本發明實施例提供的一種視頻信息結構組織方法和系統,全面考慮了視頻監控中的實際情況,通過對視頻數據的實時分層級分析,將智能分析任務分布形成分布處理過程,真正做到了視頻處理的實時化、智能化和可交互性。
附圖說明
圖1所示為本發明一實施例提供的一種視頻信息結構組織方法的流程示意圖。
圖2所示為本發明一實施例提供的一種視頻信息結構組織系統的裝置示意圖。
圖3所示為本發明一實施例提供的一種視頻信息結構組織系統的模型示意圖。
圖4所示為本發明另一實施例提供的一種視頻信息結構組織方法的流程示意圖。
圖4’所示為本發明另一實施例提供的一種視頻信息結構組織方法的流程示意圖。
圖5所示為本發明另一實施例提供的一種視頻信息結構組織系統的裝置示意圖。
圖6所示為本發明另一實施例提供的一種視頻信息結構組織系統的模型示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
本發明實施例提供的視頻信息結構組織方法,包括:
獲取視頻現場原始數據,構建基本場景數據層;
將基本場景數據層進行實時分層處理,形成層級數據,按需輸出。
在本發明實施例中,首先收集視頻現場原始數據,包括視頻中數據和視頻現場數據,用以構建基本場景數據層,對基本場景數據層進行實時分層處理,形成不同的層級數據,且各層級數據之間或各層級數據與基本場景數據層之間按照實際需求進行實時數據交換,并按照實際需求進行處理或輸出,以達到視頻分析的實時性和智能化。
本發明實施例提供的視頻信息結構組織系統,包括:
收集數據裝置101,用于獲取視頻現場原始數據,構建基本場景數據層;
分層處理裝置102,用于將基本場景數據層進行實時分層處理,形成層級數據,按需輸出。
圖1所示為本發明一實施例提供的一種視頻信息結構組織方法的流程示意圖。如圖1所示,視頻信息結構組織方法包括如下步驟:
步驟01,收集視頻現場原始數據,構建基本場景數據層。
圖3所示為本發明一實施例提供的一種視頻信息結構組織系統的模型示意圖。如圖3所示,步驟01中,基本場景數據層包括環境感知層。現場原始數據包括視頻中感知的原始數據和/或視頻現場的原始數據,視頻中感知的原始數據包括但不限于音頻、時間、地理位置、相機位姿等數據,視頻現場的原始數據包括但不限于溫度、濕度、氣象等信息。
步驟02,對基本場景數據層進行前端處理,形成地理標志數據和對象數據,形成與監控對象數據關聯的特征數據,并將形成的數據結果存入前端數據層。
步驟02中,前端處理包括基于機器學習方法的預處理和/或前端智能分析,經過處理分析后的數據存入到前端數據層中,前端數據層包括地理標志層,對象層,特征層。
地理標志層,用于存儲對原始數據進行前端處理后所得的與交通標志、顯著性地貌、地標性建筑等相關的地理標志數據。
對象層,用于存儲對原始數據進行前端處理后所得的與人、交通工具、物、其他監控目標等相關的對象數據。
特征層,用于存儲對原始數據進行前端處理后所得的與面部、衣著、姿態、運動速度、運動方向、遮蔽、距離、車輛品牌、車牌號、火光、浪涌等相關的特征數據。
其中,預處理包括圖像變換、圖像增強、邊緣檢測、圖像恢復、場景識別、目標探測、目標跟蹤、語義分割中等一系列視頻圖像處理步驟。
其中,預處理以及前端智能分析,可全部或部分基于機器學習方法來實現。
舉例說明,視頻監控場景中的交通標志、標記、顯著性地貌、地標性建筑等數據屬于地理標志層的范疇;監控的感興趣目標,如:人、交通工具(車輛、飛行物、船舶等)以及其他監控目標(標線、障礙物等),屬于對象層的范疇;監控目標的外在屬性,如:面部、色彩、姿態、運動速度、運動方向、距離、遮蔽、車輛品牌(或型號)、車牌號、火光、浪涌等,屬于特征層的范疇。
步驟03,對經過前端處理后的層級數據進行后端處理,形成監控對象狀態的語義表達數據,并將形成的數據結果存入后端數據層。
步驟03中,后端數據層包括語義層。語義層,用于存儲對前端數據層進行后端處理后所得的與身份、跌倒、碰撞、穿越、聚集、傷害、交通違規、停車場計時、火警、汛情等相關的語義表達數據。
其中,后端處理包括后端智能分析,基于機器學習技術來實現。
舉例說明,面部特征,輔以衣著可判斷監控場景中人的身份;姿態、行走速度、方向、遮蔽等特征可以判斷某人的行為;數量、是否停留等特征可以判斷某一場景中是否存在人群聚集擁擠現象。
又比如,車輛的運動方向和速度、以及是否遮蔽道路標線,則可以判斷該車輛是否存在交通違法行為,輔以車輛牌號和品牌識別,即可記錄其違法行為。
亦或是,場景中某監控目標(如重要建筑)突然出現火光,則判斷有火警;場景中某監控目標(如堤壩)附近出現異常的浪涌,則判斷有汛情。
以上這些舉例數據都屬于語義層的范疇。
步驟04,綜合語義表達數據和各類數據,進行實時智能分析,形成可交互的控制或反饋數據層,即可交互數據層。
步驟04中,可交互數據層設置為決策/理解層。決策/理解層,用于存儲對以上各數據層處理后作出的決策和/或理解,包括為監控人員提供參考性質的決策建議,理解監控人員的指令,并對相應內容進行檢索。
以上步驟02、步驟03、步驟04三步驟隸屬于“將基本場景數據層進行實時分層處理,形成層級數據,按需輸出”步驟。
對于前述各語義層具體情景,利用機器學習技術訓練的判斷模型可以給出不同的決策建議供監控人員參考;同時,監控人員還可以利用系統發出指令,以查詢各層數據中相應的內容,這些屬于決策/理解層。其中,判斷模型以及通過其判斷得到的決策建議,屬于決策范疇。監控人員在觀察過程中,向系統發出某種指令以查詢某一事件中,具備某類特征的目標,系統將其指令解釋成符合本結構模型的描述方式,對其所掌握的數據進行檢索,屬于理解范疇。
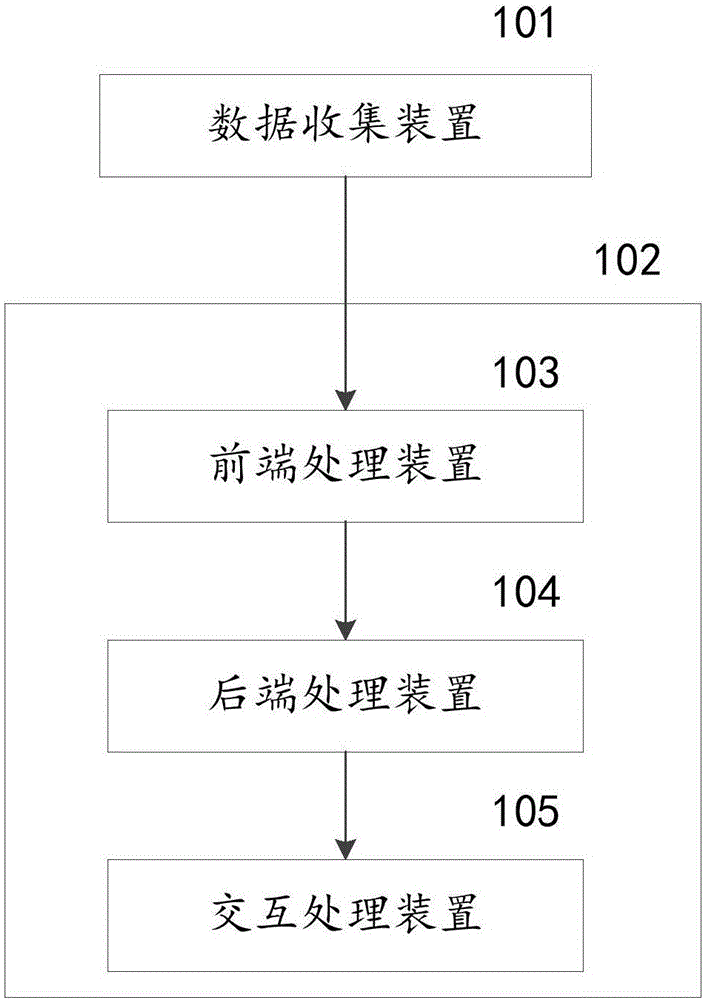
圖2所示為本發明一實施例提供的一種視頻信息結構組織系統的裝置示意圖。如圖2所示,該視頻信息結構組織系統的裝置包括:
數據收集裝置101,用于收集視頻現場原始數據,構建基本場景數據層。
前端處理裝置103,用于對基本場景數據層進行前端處理,形成地理標志數據和對象數據,形成與監控對象數據關聯的特征數據,并將形成的數據結果存入前端數據層。
后端處理裝置104,用于對經過前端處理后的層級數據進行后端處理,形成監控對象狀態的語義表達數據,并將形成的數據結果存入后端數據層。
交互處理裝置105,用于綜合語義表達數據和各類數據,進行實時智能分析,形成可交互的控制或反饋數據層,即可交互數據層。
上述前端處理裝置103、后端處理裝置104、交互處理裝置105三裝置隸屬于分層處理裝置102。
另外,圖3所示的視頻信息結構組織方法模型具備個性化層級配置機制,即:針對不同的應用需要,可選配模型中各層次的配置參數。比如,在停車場計費系統中,模型可僅保留環境感知層、特征層、語義層,即可滿足業務需要。
本發明中一實施例給出的視頻信息結構組織方法和系統,收集的原始數據更加全面具體,并將部分智能分析任務布置于監控系統的前端數據層,使得整個系統具備實時性,同時,可交互數據層中設置的決策和理解機制使該系統具備雙向交互能力,即:“前端”到“后端”(監控)、“后端”到“前端”(指令跟蹤、查詢、檢索等)。
圖4所示為本發明另一實施例提供的一種視頻信息結構組織方法的流程示意圖。如圖4所示,該視頻信息結構組織方法具體涉及車輛占道行駛智能監控方法,包括:
步驟201:實時采集視頻監控數據。
步驟202:從視頻監控數據中截取車輛所處區域的區域視頻監控數據。
通過從視頻監控數據中截取區域視頻監控數據,去掉了與當前監控車輛無關的區域的視頻監控數據,減少了后續提取車輛特征信息和車道信息的計算量,減輕硬件分析資源的計算負擔。
應當理解,該區域視頻監控數據的區域大小可由開發人員根據實際場景需求而定,例如前端視頻采集設備的監控范圍包括兩個街區,而監控人員所關注的僅為其中的一個街區的違章占道情況,此時便可從視頻監控數據中截取當前一個街區的區域視頻監控數據。或者,該區域的大小也可由所監視的車輛的圖像大小而定。然而,本發明對該區域視頻監控數據的區域大小的確定方式并不做限定。
步驟203:從區域視頻監控數據中提取車輛特征信息和車道信息。
由于原始的視頻監控數據已經被截取為了區域視頻監控數據,因此車輛特征信息和車道信息的提取過程的計算量得到了降低,減輕了硬件分析資源的計算負擔。車輛特征信息和車道信息的具體提取方式可通過預訓練模型實現。
在本發明一實施例中,考慮到車輛特征信息的提取僅關注監控視頻中的車輛,車道信息的提取關注監控視頻中的車道,而車輛在監控視頻中所占的區域要小于車道所占的區域,因此也可以僅從區域視頻監控數據中提取車輛特征信息,而車道信息仍從原始采集的視頻監控數據中提取。然而,本發明實施例對車輛特征信息和車道信息的提取基礎并不做具體限定。
步驟204:基于實時提取的車輛特征信息和車道信息生成語義分析結果。
例如,車輛的特征信息包括車輛A為非公共汽車,車道信息包括B路段內的公交車專用道C,則所生成的語義分析結果可表示為非公共汽車車輛A在B路段內占用的車道為公交車專用道C。
本發明一實施例還提供一種可交互的查詢方法,當接收到以車輛特征信息或車道信息為查詢條件的查詢指令時,調取與車輛特征信息對應的所有車道信息,或調取與車道信息對應的所有車輛特征信息。例如,若接收到以公交車專用道C為查詢條件的查詢指令時,便可調出當前視頻監控數據中占用該公交車專用道C的所有車輛的特征信息。
步驟205:基于語義分析結果以及違章條款的機器描述的預訓練模型,實時判斷車輛是否違法占用了所行駛的車道。
應當注意,盡管出于簡化說明的目的將本發明實施例所述的方法表示和描述為一連串動作,但是應理解和認識到要求保護的主題內容將不受這些動作的執行順序所限制,因為一些動作可以按照與這里示出和描述的順序不同的順序出現或者與其它動作并行地出現,同時一些動作還可能包括若干子步驟,而這些子步驟之間可能出現時序上交叉執行的可能。例如,在本發明一實施例中,如圖4’所示,在實時采集視頻監控數據后(步驟201’),車道信息可直接從所采集的視頻監控數據中提取(步驟202’),然后再從視頻監控數據中截取車輛所處區域的區域視頻監控數據(步驟203’)以及從區域視頻監控數據中提取車輛特征信息(步驟204’),之后基于所提取到的車道信息和車輛特征信息生成語義分析結果(步驟205’),并最終基于語義分析結果和違章條款的機器描述的預訓練模型,實時判斷車輛是否違法占用了所行駛的車道(步驟206’)。
圖5所示為本發明另一實施例提供的一種視頻信息結構組織方法的裝置示意圖。如圖5所示,該裝置示意圖具體涉及車輛占道行駛智能監控系統,包括:
環境感知裝置301,隸屬于數據收集裝置101,配置為實時采集視頻監控數據;
對象特征分析裝置302,隸屬于前端處理裝置103,配置為根據環境感知裝置301所采集的視頻監控數據,實時提取車輛的車輛特征信息;
地理標志分析裝置303,隸屬于前端處理裝置103,配置為根據環境感知裝置301所采集的視頻監控數據,實時提取車輛所行駛車道的車道信息;
決策裝置304,隸屬于交互處理裝置105,配置為根據對象特征分析裝置302所實時提取的車輛特征信息和地理標志分析裝置303所實時提取的車道信息判斷所述車輛是否存在違章占道行為。
在本發明一實施例中,該車輛占道行駛智能監控系統進一步包括:語義分析裝置305,隸屬于后端處理裝置104,配置為基于對象特征分析裝置302和地理標志分析裝置303所分別實時提取的車輛特征信息和車道信息生成語義分析結果;
其中決策裝置304進一步配置為:
基于語義分析裝置305所生成的語義分析結果以及違章條款的機器描述的預訓練模型,實時判斷所述車輛是否違法占用了所行駛的車道。
在本發明一實施例中,該決策裝置304進一步配置為:
接收以車輛特征信息或車道信息為查詢條件的查詢指令;以及調取與車輛特征信息對應的所有車道信息,或調取與車道信息對應的所有車輛特征信息。
在本發明一實施例中,決策裝置304進一步配置為:
若車輛不存在違章占道行為,并不保存與車輛對應的車輛特征信息和車道信息。
在本發明一實施例中,該車輛占道行駛智能監控系統進一步包括:
對象區域提取裝置306,隸屬于前端處理裝置103,配置為從環境感知裝置301所采集的視頻監控數據中截取車輛所處區域的區域視頻監控數據;
其中對象特征分析裝置302進一步配置為:從區域視頻監控數據中提取車輛特征信息。
在本發明另一實施例中,地理標志分析裝置303也可進一步配置為:從區域視頻監控數據中提取車道信息。
在本發明一實施例中,對象特征分析裝置302進一步配置為:基于對車輛特征信息的預訓練模型,從視頻監控數據中提取車輛特征信息;和/或,
地理標志分析裝置303進一步配置為:基于對車道信息的預訓練模型,從視頻監控數據中提取車道信息。
由此可見,該實施例所提供的車輛占道行駛智能監控系統是基于視頻信息結構組織方法模型實現的。該視頻信息結構組織方法模型中的信息流可分為不同的層面提取,而且相鄰的層面之間存在一定的依賴關系,如圖6所示。環境感知層中存儲視頻、地理位置、時間信息;通過對環境感知層進行前端處理得出相應信息存入地理標志層、對象層、特征層,即存入前端數據層;通過對前端數據層進行后端處理,得出相應信息存入語義層,即存入后端數據層;通過對環境感知層、前端數據層、后端數據層的實時綜合分析處理,給出決策信息,得出決策層,即可交互數據層。
在環境感知裝置301采集視頻監控數據的過程中,將視頻和現場感知數據(如:聲音、時間、相機的地理位置、溫度、氣象、相機位姿等)存入環境感知層,這些信息是傳統視頻監控和智能視頻監控提供監控場景的基本要素,為頂層決策提供必要的支持。在前端處理過程中,將原始采集的視頻監控數據進行初步處理(包括基于機器學習方法實現的預處理和前端智能分析等),并將初步處理的結果存入特征層、地理標志層和對象層,分別對應對象特征分析裝置302提取車輛的車輛特征信息的過程、地理標志分析裝置303提取車輛所行駛車道的車道信息的過程以及對象區域提取裝置306從原始采集的視頻監控數據中截取區域視頻監控數據的過程。在后端處理過程中,將根據不同的應用需要,綜合前述的相應各層,利用機器學習技術進行分析和處理,將相關的語義分析結果存入語義層,對應語義分析裝置305生成語義分析結果的過程。對于語義分析裝置305中的語義分析結果,利用機器學習技術訓練的判斷模型可以給出不同的決策建議供監控人員參考;同時,監控人員還可以向系統發出指令,以查詢監控數據中相應的內容,這些屬于決策/理解層。其中的判斷模型以及通過其判斷得到的決策建議,屬于決策范疇。監控人員在觀察過程中,向監控系統發出某種指令以查詢某一事件中,具備某類特征的目標,系統將其指令解釋成符合本結構模型的描述方式,對其所掌握的數據進行檢索,屬于理解范疇。
應當理解,當車輛占道行駛智能監控系統包括前端視頻采集設備和后端視頻分析設備時,環境感知裝置301可設置在前端視頻采集設備中,而地理標志分析裝置303、對象區域提取裝置306、對象特征分析裝置302、語義分析結果305、決策裝置304可分別設置在前端視頻采集設備中或設置在后端視頻分析設備中。只要車輛占道行駛智能監控系統中的所有裝置能夠實現各自的分析提取功能以及信息流的逐步提取,以最終達到語義決策的目的即可。本發明實施例對車輛占道行駛智能監控系統中的裝置具體設置在前端視頻采集設備還是后端視頻分析設備并不做限定。
本發明另一實施例給出了基于視頻信息結構組織方法的涉及車輛占道行駛智能監控的具體實例,該實施例說明了視頻信息結構組織方法的具體執行步驟不受限制,一些動作可以按照不同的順序出現或者與其它動作并行地出現,同時一些動作還可能包括若干子步驟,而這些子步驟之間可能出現時序上交叉執行的可能,為系統的實時性充分打好基礎。
應當注意,本發明實施例的各層級數據相鄰層級之間存在直接依賴關系。比如,地理標志層的內容(如:交通標志),是通過對包括視頻在內的環境感知層的基本感知數據進行分析處理獲得的。
還應當注意,本發明實施例的各層級數據不同層級之間還可能存在跨越層級的間接依賴關系。比如,某監控任務中,監控人員明確需要觀察某具體地域的實際情況,則決策/理解層通過分析,檢索環境感知層中的相機地理位置信息,從而給出該地域的監控實況。
還應當注意,在本發明實施例中,針對具體應用需要的不同,可對各層級數據進行按需配置。比如,在停車場計費系統中,模型可僅保留環境感知層、特征層、語義層,即可滿足業務需要。
應當注意,盡管出于簡化說明的目的將本發明所述的方法表示和描述為一連串動作,但是應理解和認識到要求保護的主題內容將不受這些動作的執行順序所限制,因為一些動作可以按照與這里示出和描述的順序不同的順序出現或者與其它動作并行地出現,同時一些動作還可能包括若干子步驟,而這些子步驟之間可能出現時序上交叉執行的可能。
本發明的教導還可以實現為一種計算機可讀存儲介質的計算機程序產品,包括計算機程序代碼,當計算機程序代碼由處理器執行時,其使得處理器能夠按照本發明實施方式的方法來實現如本文實施方式所述的視頻信息結構組織方法。計算機存儲介質可以為任何有形媒介,例如軟盤、CD-ROM、DVD、硬盤驅動器、甚至網絡介質等。
應當理解,雖然以上描述了本發明實施方式的一種實現形式可以是計算機程序產品,但是本發明的實施方式的方法或裝置可以被依軟件、硬件、或者軟件和硬件的結合來實現。硬件部分可以利用專用邏輯來實現;軟件部分可以存儲在存儲器中,由適當的指令執行系統,例如微處理器或者專用設計硬件來執行。本領域的普通技術人員可以理解上述的方法和設備可以使用計算機可執行指令和/或包含在處理器控制代碼中來實現,例如在諸如磁盤、CD或DVD-ROM的載體介質、諸如只讀存儲器(固件)的可編程的存儲器或者諸如光學或電子信號載體的數據載體上提供了這樣的代碼。本發明的方法和裝置可以由諸如超大規模集成電路或門陣列、諸如邏輯芯片、晶體管等的半導體、或者諸如現場可編程門陣列、可編程邏輯設備等的可編程硬件設備的硬件電路實現,也可以用由各種類型的處理器執行的軟件實現,也可以由上述硬件電路和軟件的結合例如固件來實現。
應當理解,盡管在上文的詳細描述中提及了裝置的若干模塊或單元,但是這種劃分僅僅是示例性而非強制性的。實際上,根據本發明的示例性實施方式,上文描述的兩個或更多模塊/單元的特征和功能可以在一個模塊/單元中實現,反之,上文描述的一個模塊/單元的特征和功能可以進一步劃分為由多個模塊/單元來實現。此外,上文描述的某些模塊/單元在某些應用場景下可被省略。
還應當理解,為了不模糊本發明的實施方式,說明書僅對一些關鍵、未必必要的技術和特征進行了描述,而可能未對一些本領域技術人員能夠實現的特征做出說明。
以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!