一種面向能耗數據并發采集的三階段優化方法與流程
本發明涉及數據采集調度技術領域,尤其涉及一種面向能耗數據并發采集的三階段優化方法。
背景技術:
智能能效制造(Smart energy efficient manufacturing,SEEM)需要感知能源消耗、能源質量、設備操作、環境狀態等參數。為了滿足感知需求,工廠必須裝備一個由傳感器、網絡設備和應用服務器組成的大型傳感網絡,并實現數據的自動采集。能源數據的實時性對于SEEM的優化分析而言極其重要,許多用戶要求在數秒之內得到數據,而隨著傳感器數量的增加,利用有限的計算資源滿足能源數據的變得越來越具有挑戰性。
在能源傳感網絡(Energy Sensor Network,ESN)中,RS485因為拓撲結構簡單、通信穩定、通信距離長凳優點而成為通用的通信標準,實際應用中,絕大部分智能傳感設備提供RS485接口。由于復雜的車間環境和有限的通信容量,一個能源傳感網絡往往由多組RS485總線構成,每組RS485總線具有不同的傳輸質量,連接不同數量的傳感設備。數據采集一般由一臺或多臺主機完成。隨著服務器架構從提高單線程程序性能轉向通過指令集并行和線程級并行提高程序性能,多核處理器環境下的多線程并發采集是提升數據實時性的有效手段。因此,數據采集調度,即如何將采集任務分配到多個處理器中并發執行,使其完成時間最短,成為備受關注的問題;而數據采集調度問題是一類任務-處理器映射問題,處理器負荷均衡是該問題的關鍵,因為不均衡的處理器負荷將會導致整個系統等待處理負荷最大的處理器;目前,研究者們去向于在Petri網建模的基礎上,采用遺傳算法和啟發式算法來優化類似處理器調度問題,在最近30年來對負荷均衡問題的研究成果,認為簡單高效的貪婪算法是最流行的求解方法;但數據采集調度問題具有兩個特點:(1)不同RS485總線上的采集任務之間不存在通信約束;(2)采集任務之間不存在嚴格的順序約束;因此,在實際應用中,通常假定共享同一總線的采集任務是完全串行的,將問題簡化為總線-處理器之間的映射并采用貪婪算法求解,但如果總線負荷不均衡時,將會導致很低的并發效率,極端的例子是若能源網絡中只有一條總線,但是有多個處理器,那么在數據采集過程中只會有一個處理器得到利用,而其他處理器均處于空閑狀態,大大限制了多處理器的并發采集效率。
技術實現要素:
本發明的目的在于提出一種并發效率更高、數據采集時間更短的面向能耗數據并發采集的三階段優化方法。
為達此目的,本發明采用以下技術方案:
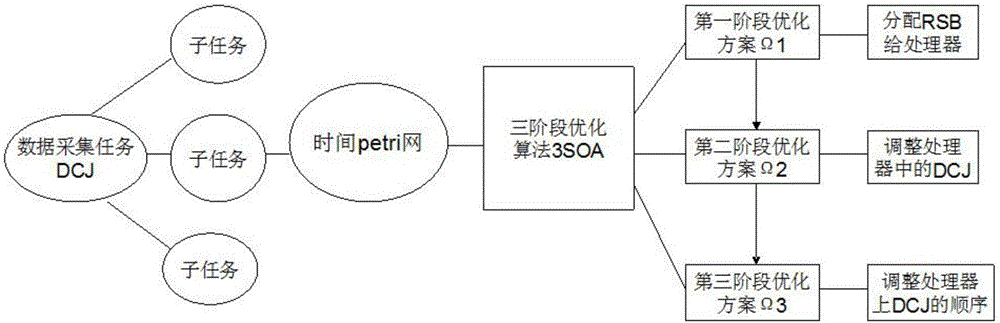
一種面向能耗數據并發采集的三階段優化方法,基于大型能源傳感網絡中,包括若干個能源節點和能源管理網,所述能源管理網包括能源主控機、數據采集終端和時間處理系統,由數據采集終端將數據采集任務DCJ進一步細分為多個獨立的子任務,并在時間處理系統建立一個支持DCJ并發仿真的時間Petri網;在所述時間Petri網模擬的基礎上,以DCJ的最小完成時間為目標,由能源主控機基于貪婪算法和遺傳算法提出一種數據采集任務在處理器之間分配的三階段優化算法3SOA,來求解DCJ的調度問題;
所述三階段優化算法3SOA包括以下三個階段:
(1)第一階段優化:采用貪婪算法將DCJ被RS485總線RSB分組后分配給處理器,使處理器負載平衡,獲得方案Ω1;
(2)第二階段優化:根據Ω1,采用貪婪算法在處理器之間調整DCJ從高載荷的處理器轉向低載荷的處理器,使處理器負載平衡,獲得方案Ω2;
(3)第三階段優化:根據Ω2,采用遺傳算法優化調整每個處理器上的DCJ的排列順序,使若干個會話的等待時間最小化,獲得方案Ω3。
進一步說明,對所述時間Petri網進行建模,首先建立基本網,再合并冗長的節點,包括如下步驟:
A建立基本網:
(1)為每一個s∈S創建一個RSB庫所;
(2)對一個DCJ分解的三個子類DCJ,j=<ja,jb,jc>(j∈J)分別創建三個變遷,λa,λb,λc是一個變遷的時間響應τ;
(3)為每個s∈S在s之間增加一個輸入弧和輸出弧,對于j∈J(s)每一個弧的權重為1;
(4)對每一個c∈C,為每一個處理器創建一個處理器庫所,為每個j∈J(c)的DCJ子模塊創建處理庫所,按照順序為庫所和變遷增加弧,每個弧的權重為1。
(5)若P是RSB庫所或者每個處理器的庫所,那么M0(p)=1,else M0(p)=0,即所有的RSB和處理器在開始時均為閑置狀態;
B合并冗長的節點:
(1)對于處理器C,若ji+1和ji在順序上相鄰,那么jci和jai+1兩種變遷可以合并,那么jci和jai+1之間的庫所取消,新變遷的時間函數是λci+λai+1。
(2)若被同一處理器處理的連續DCJ之間在RSB上不存在競爭資源的關系,則相應的變遷也可以合并成一個新的變遷,合并后減少中間的庫所,新變遷的時間函數為其處理時間的總和;后續的DCJ處理器分配算法將確定需要被合并的DCJ。
進一步說明,所述數據采集任務(DCJ)調度的完成時間(π),在所述時間Petri網模擬的基礎上,采用并行仿真算法進行模擬,包括如下步驟:
(1)給定一個通過J→C映射Ω,構建對應的時間Petri網模型;
(2)參數的定義和初始化,初始值為E=φ,M=M0,x=0;其中E為根據完成時間排列的使能變遷序列,M為當前標識,π(t)為變遷t的完成時間;
(3)對于每個在M0標識狀態下的使能變遷,令集合π(t)=λ(t),將t加入到E中;
(4)如E不為空,則執行循環
t=dequeue(E)(將t移出隊列E),x=π(t),M=M-I(t)+O(t);
(5)輸出量x為DCJ調度問題π(Ω)的解。
進一步說明,所述第一階段優化采用貪婪算法將DCJ由RS485總線RSB分組后分配給處理器,包括如下步驟:
(1)輸入一個ESN;
(2)參數定義和初始化,setλ(c)=0;
(3)根據λ(s)排序的RSB的集合S;
(4)對每個s∈S執行循環;
(4.1)尋找處理器c的λ(c)的最大值;
(4.2)給J(s)分配c;
(4.3)λ(c)=λ(c)+λ(s);
(5)循環結束,輸出Ω1。
進一步說明,所述第二階段優化采用貪婪算法在處理器之間調整DCJ從高載荷的處理器轉向低載荷的處理器,包括如下步驟:
(1)輸入ESN和Ω1;
(2)對每個J(s)(s∈S),其子模塊DCJ根據λb排序;
(3)獲取最高負載ch和最低負載cl;
(4)獲取J(ch)的頭元素,jx=getqueue(J(ch));(jx移出隊列J(ch));
(5)重置移動標志bm=false;
(6)如果λ(ch)-λ(jx)>λ(J)/l且λ(cl)+λ(jx)<λ(J)/l
(6.1)將jx從ch移動到cl,并設定bm=true;
(6.2)更新處理器負載,λ(ch)=λ(ch)-λ(jx),λ(cl)=λ(cl)+λ(jx);
(6.3)返回(5);
(7)如果bm為真,返回(5);
(8)輸出結果Ω2,結束。
進一步說明,所述第三階段優化采用遺傳算法優化調整每個處理器上的DCJ的排列順序,遵從遺傳算法的基本結構,進行編碼和解碼、親和度評價、初始化種群、篩選、交叉選擇和突變來獲取最優的方案Ω3。
進一步說明,所述編碼是將DCJ由處理器按照順序進行分組編碼,方程式表示為:Zi=<ki-1+1,ki-1+2,...,ki-1+ki>,其中,ki為第i個處理器ci(i=0,1,2,…,l,k0=1)上DCJ的編號;L子序列組成的自然數序列作為染色體,即初始染色體由方程式表示為:Z=<Z1,Z2,...,Zi,...,Zl>;一種新的染色體可以通過重構Zi產生;所述解碼是映射ki到相應的DCJ。
進一步說明,所述親和度評價是將一個Z染色體通過解碼轉換成一個候選解Ω,x(Ω)通過所述并行仿真算法進行評價;x(Ω)的相反數被視為Z的親和力,其值越大則解決方案更優。
進一步說明,所述初始化種群是將DCJ的優先順序由處理器隨機生成,將Zi隨機置換并轉換成Z'i,按照從ki-1+1到ki-1+ki的整數的隨機排列形成Z'i=<Z'1,Z'2,…,Z'i,…,Z'l>,獲得新的染色體Z'。
進一步說明,所述交叉選擇是從父種群中隨機選擇兩個不同的個體染色體,再通過父種群個體交叉創建兩個不同的子染色體,其交叉位點只定位在一個子序列的開始。
本發明的有益效果:本發明通過數據采集終端將數據采集任務DCJ進一步細分為多個獨立的子任務,并且能在時間Petri網上進行時間仿真,評價一個工作單元的完成時間,同時為了使一個工作單元的完成時間最小化,通過能源主控機在仿真中基于貪婪算法和遺傳算法,利用所述三階段優化算法(3SOA)來求解數據采集任務的調度問題,獲得DCJ的最小完成時間,優化DCJ的調度的方案;并且通過計算測試表明,相比現有僅采用第一階段優化的傳統算法,所述3SOA能夠顯著降低采集完成時間,提升并發效率;并且通過應用表明,所述3SOA能使數據采集的周期從9.8秒降至6秒,并發效率提升了34.45%。
附圖說明
圖1是本發明一個實施例的一種面向能耗數據并發采集的三階段優化方法的示意圖;
圖2是本發明一個實施例的大型能源傳感網絡的示意圖;
圖3是本發明一個實施例的Ω1,Ω2和Ω3中并行率η的直方圖;
圖4是本發明一個實施例的Ω1,Ω2和Ω3之間不同的η(Δη)的曲線圖;
圖5是本發明一個實施例的Ω1,Ω2和Ω3的η-σp散點圖;
圖6是本發明一個實施例的能源管理系統的能耗檢測器的顯示屏所顯示的EDC3.0采集的數據。
具體實施方式
下面結合附圖并通過具體實施方式來進一步說明本發明的技術方案。
一種面向能耗數據并發采集的三階段優化方法,基于大型能源傳感網絡中,包括若干個能源節點和能源管理網,所述能源管理網包括能源主控機、數據采集終端和時間處理系統,由數據采集終端將數據采集任務DCJ進一步細分為多個獨立的子任務,并在時間處理系統建立一個支持DCJ并發仿真的時間Petri網;在所述時間Petri網模擬的基礎上,以DCJ的最小完成時間為目標,由能源主控機基于貪婪算法和遺傳算法提出一種數據采集任務在處理器之間分配的三階段優化算法3SOA,來求解DCJ的調度問題;
所述三階段優化算法3SOA包括以下三個階段:
(1)第一階段優化:采用貪婪算法將DCJ被RS485總線RSB分組后分配給處理器,使處理器負載平衡,獲得方案Ω1;
(2)第二階段優化:根據Ω1,采用貪婪算法在處理器之間調整DCJ從高載荷的處理器轉向低載荷的處理器,使處理器負載平衡,獲得方案Ω2;
(3)第三階段優化:根據Ω2,采用遺傳算法優化調整每個處理器上的DCJ的排列順序,使若干個會話的等待時間最小化,獲得方案Ω3。
目前智能能效制造(Smart energy efficient manufacturing,SEEM)需要依賴于大型傳感網絡和實時數據采集,而RS485總線(RS485Bus,RSB)是目前傳感網絡通用的通信接口,其通信的串行性制約了多處理器的并發采集效率;本發明通過數據采集終端將數據采集任務(Data Collection Job,DCJ)的調度問題描述為一個時間Petri網,一個數據采集任務DCJ將被進一步細分為多個獨立的子任務,并且能在時間Petri網上進行時間仿真,評價一個工作單元的完成時間,同時為了使一個工作單元的完成時間最小化,通過能源主控機在仿真中基于貪婪算法和遺傳算法,利用所述三階段優化算法(the Three-stage Optimization Algorithm,3SOA)來求解數據采集任務的調度問題,獲得DCJ的最小完成時間,優化DCJ的調度的方案;并且通過計算測試表明,相比現有僅采用第一階段優化的傳統算法,所述3SOA能夠顯著降低采集完成時間,提升并發效率;并且通過應用表明,所述3SOA能使數據采集的周期從9.8秒降至6秒,并發效率提升了34.45%。
進一步說明,對所述時間Petri網進行建模,首先建立基本網,再合并冗長的節點,包括如下步驟:
A建立基本網:
(1)為每一個s∈S創建一個RSB庫所;
(2)對一個DCJ分解的三個子類DCJ,j=<ja,jb,jc>(j∈J)分別創建三個變遷,λa,λb,λc是一個變遷的時間響應τ;
(3)為每個s∈S在s之間增加一個輸入弧和輸出弧,對于j∈J(s)每一個弧的權重為1;
(4)對每一個c∈C,為每一個處理器創建一個處理器庫所,為每個j∈J(c)的DCJ子模塊創建處理庫所,按照順序為庫所和變遷增加弧,每個弧的權重為1。
(5)若P是RSB庫所或者每個處理器的庫所,那么M0(p)=1,else M0(p)=0,即所有的RSB和處理器在開始時均為閑置狀態;
B合并冗長的節點:
(1)對于處理器C,若ji+1和ji在順序上相鄰,那么jci和jai+1兩種變遷可以合并,那么jci和jai+1之間的庫所取消,新變遷的時間函數是λci+λai+1。
(2)若被同一處理器處理的連續DCJ之間在RSB上不存在競爭資源的關系,則相應的變遷也可以合并成一個新的變遷,合并后減少中間的庫所,新變遷的時間函數為其處理時間的總和;后續的DCJ處理器分配算法將確定需要被合并的DCJ。
所述時間Petri網是一個7元集合TPN=(P,T,I,O,W,M0,τ),P是庫所的集合,T是變遷的集合,I=P×T是輸入弧的集合,O=T×P是輸出弧的集合,M0是初始標記,W是所有弧的權重,τ是關于時間變遷的時間函數;其中在建立基本網中,RSB視為庫所,DCJ視為變遷,RSB和DCJ之間的依賴關系視為庫所和變遷的輸入弧和輸出弧,處理器視為用來標記處理狀態的庫所序列。
通過建立一個支持數據采集任務DCJ并發仿真的時延Petri網模型,為后續得到數據采集任務分配到多個處理器中并發執行,使其完成時間最短的解提供基礎條件。
進一步說明,所述數據采集任務(DCJ)調度的完成時間(π),在所述時間Petri網模擬的基礎上,采用并行仿真算法進行模擬,包括如下步驟:
(1)給定一個通過J→C映射Ω,構建對應的時間Petri網模型;
(2)參數的定義和初始化,初始值為E=φ,M=M0,x=0;其中E為根據完成時間排列的使能變遷序列,M為當前標識,π(t)為變遷t的完成時間;
(3)對于每個在M0標識狀態下的使能變遷,令集合π(t)=λ(t),將t加入到E中;
(4)如E不為空,則執行循環
t=dequeue(E)(將t移出隊列E),x=π(t),M=M-I(t)+O(t);
(5)輸出量x為DCJ調度問題π(Ω)的解。
將所述DCJ的調度問題通過在所述時間Petri網進行時間仿真,通過所述并行仿真算法,增強了對完成時間的仿真能力,從而實現對基于JPM的執行并性仿真的完成時間的有效評估。
進一步說明,所述第一階段優化采用貪婪算法將DCJ由RS485總線RSB分組后分配給處理器,包括如下步驟:
(1)輸入一個ESN;
(2)參數定義和初始化,setλ(c)=0;
(3)根據λ(s)排序的RSB的集合S;
(4)對每個s∈S執行循環;
(4.1)尋找處理器c的λ(c)的最大值;
(4.2)給J(s)分配c;
(4.3)λ(c)=λ(c)+λ(s);
(5)循環結束,輸出Ω1。
在第一個階段,一個J(s)視為一個基本的調度單元,DCJ調度問題則視為一個純粹的負載平衡問題;通過所述第一階段優化,獲得方案Ω1,從而保證處理器負載平衡,若同一RSB的DCJ分配到了同一個處理器時則不會有通訊等待。
進一步說明,所述第二階段優化采用貪婪算法在處理器之間調整DCJ從高載荷的處理器轉向低載荷的處理器,包括如下步驟:
(1)輸入ESN和Ω1;
(2)對每個J(s)(s∈S),其子模塊DCJ根據λb排序;
(3)獲取最高負載ch和最低負載cl;
(4)獲取J(ch)的頭元素,jx=getqueue(J(ch));(jx移出隊列J(ch));
(5)重置移動標志bm=false;
(6)如果λ(ch)-λ(jx)>λ(J)/l且λ(cl)+λ(jx)<λ(J)/l
(6.1)將jx從ch移動到cl,并設定bm=true;
(6.2)更新處理器負載,λ(ch)=λ(ch)-λ(jx),λ(cl)=λ(cl)+λ(jx);
(6.3)返回(5);
(7)如果bm為真,返回(5);
(8)輸出結果Ω2,結束。
通過所述二階段優化,調整DCJ從高載荷的處理器轉向低載荷的處理器,以適應處理器,并且同時盡可能保證同一個RSB上的DCJ在同一個處理器上,獲得方案Ω2,從而保證處理器負載平衡,即處理器的平均負載為λ(J)/l。
進一步說明,所述第三階段優化采用遺傳算法優化調整每個處理器上的DCJ的排列順序,遵從遺傳算法的基本結構,進行編碼和解碼、親和度評價、初始化種群、篩選、交叉選擇和突變來獲取最優的方案Ω3。為了保證第一階段的優化,在第二階段還未被移動的DCJ將在第三個階段優化保持靜止,因此將會被處理器合并成為一個變遷組,在一定程度上減小了Petri網的規模,而其他的DCJ在第三階段優化是可調的,所述第三階段優化根據Ω2,通過遺傳算法優化每個處理器上的DCJ的排列順序,獲得方案Ω3,從而實現若干個會話的等待時間最小化,從而獲得DCJ的調度問題的最優解,即DCJ的最小完成時間。
進一步說明,所述編碼是將DCJ由處理器按照順序進行分組編碼,方程式表示為:Zi=<ki-1+1,ki-1+2,...,ki-1+ki>,其中,ki為第i個處理器ci(i=0,1,2,…,l,k0=1)上DCJ的編號;L子序列組成的自然數序列作為染色體,即初始染色體由方程式表示為:Z=<Z1,Z2,...,Zi,...,Zl>;一種新的染色體可以通過重構Zi產生;所述解碼是映射ki到相應的DCJ。
進一步說明,所述親和度評價是將一個Z染色體通過解碼轉換成一個候選解Ω,x(Ω)通過所述并行仿真算法進行評價;x(Ω)的相反數被視為Z的親和力,其值越大則解決方案更優。
進一步說明,所述初始化種群是將DCJ的優先順序由處理器隨機生成,將Zi隨機置換并轉換成Z'i,按照從ki-1+1到ki-1+ki的整數的隨機排列形成Z'i=<Z'1,Z'2,…,Z'i,…,Z'l>,獲得新的染色體Z'。
進一步說明,所述交叉選擇是從父種群中隨機選擇兩個不同的個體染色體,再通過父種群個體交叉創建兩個不同的子染色體,其交叉位點只定位在一個子序列的開始。所述交叉選擇由簡單的交叉創建的子染色體打破了對處理器依賴的約束,其交叉位點定位在一個子序列的開始,不同于傳統遺傳算法的單點交叉中的隨機選擇交叉位點,從而保持子染色體的有效性。
所述篩選是在兩個不同的級別上運行,父類種群中的一定數量的染色體去填補子類種群,其他的父類種群個體則采用輪盤賭輪策略,單個染色體依據概率的大小去填充子種群;所述突變則用來維持種群的遺傳多樣性;每一個用于交叉選擇的個體染色體都有可能發生突變,處理器是隨機選擇的,及其對應的序列可如初始化種群一樣重新排列。
定義補充說明:
(1)能源傳感網(Energy Sensor Network,ESN)的規則
ESN是一個三元組(C,S,J),其中C={c1,c2,...,cl}是處理器的集合,S={s1,s2,...,sm}是RSB的集合,J={j1,j2,..,jn}是DCJ的集合,l是處理器的數量,m是RSB的數量,n是DCJ的數量。J和S之間存在一對多的映射關系J→S,s(j)表示RSB連接著DCJ的狀態,J(s)表示在RSB上的DCJ的結合。
(2)DCJ的調度問題
DCJ處理器的映射(Job-Processor Mapping,JPM)是一個多對一關系映射Ω:J→C,其代表了一個DCJ的調度問題,c(j)表示處理器c正在執行DCJ j,J(c)表示處理器上的DCJ的順序,λ(j)表示j的處理時間,λ(c)表示處理器c的負載。
(3)關于Ω的評價指標
A:DCJ處理時間(λ),λ表示DCJ的處理時間,λ(j)表示DCJ j的處理時間,λ(J)表示J的整個處理周期的時間,λ(s)表示RSB s的處理時間,λ(c)表示處理器c的負載,其相互關系為:λ(J)=∑λ(j),j∈J;λ(s)=∑λ(j),j∈J(s);λ(c)=Σλ(j),j∈J(c)。
B:DCJ的完成時間(π),給定一個JPMΩ,π(Ω)表示處理過程從開始到結束之間的時間間隔;在開始時間為0的情況下,π(Ω)可以表示DCJ的完成時間。
C:加速率(γ),命名一個JPM為Ω,γ(Ω)由方程表示為:γ(Ω)=λ(J)/π(Ω);同時λ(J)也表示同一個處理器上DCJ的完成時間,π(Ω)表示在l個處理器上DCJ的完成時間。
D:并行率(η),命名一個JPM為Ω,η(Ω)由方程表示為η(Ω)=λ(J)/(lπ(Ω));則所述DCJ的調度問題本質上為使π(Ω)最小,同時使γ(Ω)或η(Ω)最大。
4、DCJ子任務
DCJ被分解了三個子任務,即一個DCJ分解為了一個三個子類DCJ,j=<ja,jb,jc>,其中ja表示裝配指令,jb表示通訊會話,jc表示分辨率響應,它們的處理時間分別為λa,λb,λc。實際上整個DCJ執行過程中只有jb占用了RSB,而λb和λc一般消耗較長在數據庫訪問上;根據Amdahl加速率定律,任務分解降低了連續子任務的比率,加大了加速率。
另外DCJ調度問題設有三個約束條件和兩個假設,所述三個約束條件為(1)一個處理器只能一次處理一個DCJ;(2)一個RSB一次只能允許一個通訊會話;(3)一個DCJ的子任務必須按照一定的次序連續不斷地處理;所述兩個假設為所有的處理器都有相同的計算能力和所有的計算器都處于待處理狀態。
本發明通過計算與測試驗證,進一步驗證所述3SOA提高能源數據采集速度的優化效果;并通過應用型案例進行進一步驗證。
1、計算與測試驗證
在MATLAB R2013a環境下對3SOA進行編程且在擁有4GBRAM和Windows 7操作系統的個人電腦上進行測試驗證;還對各階段的并發性能指標進行了評價,并進行了階段性比較。
1.1測試案例的生成
一種測試案例主要包括:處理器、RSBs、DCJs和配置有DCJs的RSBs(DR分布)。前三個代表的是ESN的規模,最后一個代表的是RSB負載平衡度。對于DCJs,使得λa從3ms變化到6ms,λb從10ms變化到20ms,λc從8ms變化到15ms。對于DR分布,使得RSB(NDR)上DCJs的數量從1變化到64。RSB負載可由加工時間表示,RSB負載平衡度可由處理時間分布的標準偏差(σp)表示。為了簡化測試用例的生成,將σp用NDR分布的標準差(σn)代替。
一種測試案例通過l×m×n:σn標記:其中,l是處理器的個數,m是RSBs的數目,n是DCJs的數目。當進行測試時,l個處理器和m個RSBs被創建,接著,n個DCJs在子過程時間范圍內被隨機創建,最后,通過如下所述的輪盤賭算法,DCJs被隨機分配給RSBs:
(1)產生一個正態分布的樣本Pr={p1,p2,..,pm},其中,期望為n/m,均偏方差為σn;
(2)對于每個DCJ jk,生成一個在0和1之間的隨機數rk,如果則將jk分配給RSB si。
1.2測試ESN規模對算法的影響
通過對ESN規模的試驗,驗證在不同規模上達到的優化效果。設置σn=6,生成4個案例,分別為2×8×100:6,4×32×200:6,8×64×400:6,16×72×800:6。它們可以通過3SOA完成,Ω1,Ω2和Ω3的π,γ,η可以分別被評估出來。結果列于下面表1中。
Table 1 The results of tests on scale of ESN
從表1中可以看到,在所有情況下,Ω3的π小于Ω2的π,Ω2的π小于Ω1的π。這驗證了優化的第二階段和第三階段的有效性。
雖然γ是優化的一個性能指標,但它和處理器的數量有關。η和其他參數間沒有關聯,在不同情況下評價優化效果,它是一個更具可比性的指標。如圖3所示,為四種情況下Ω1,Ω2和Ω3中并行率η的直方圖;從圖中也可以看出不同階段下的優化效果,同π一樣。對于所有案例,Ω2的η明顯高于Ω1的η,這表明在Ω1中具有很大的優化潛力,其中,將RSB上的所有DCJs當做連續的。Ω2和Ω3之間的下降驗證了解決方案可以通過調整DCJ順序得到改善。如圖4所示,為Ω1,Ω2和Ω3之間不同的η(Δη)的曲線圖;從中可以看到,隨著規模的擴大,Δη呈上升趨勢。隨著ESN規模的擴大,DCJ調度問題變得越來越復雜。如果將RSB上的所有DCJs假定為連續的,處理器的能力將會嚴重浪費且η將變得越來越小,這些同樣可以從圖3中看到。在圖3中,η隨著ESN規模的增加而降低。因此,可以得出結論,在大規模ESN下3SOA可以得到更好的優化效果。
1.3測試RSBs上DCJs分布對算法的影響
對分布有DCJs的RSB進行實驗,目的是為了驗證不同分布的RBS負載的優化效果。在生成測試案例時,尺度參數固定在8×64×400,DR參數σn以1開始從1到20進行迭代。每組參數被復制5次,生成100個測試案例。對案例中的σp進行評估,它們在82.70和512.42間隨機分布。因為σp更具有多樣性,所以用它代替σn作為分配指標。
100個案例通過3SOA得到解決,且通過Ω1,Ω2和Ω3的η進行了評估。如圖5所示,為Ω1,Ω2和Ω3的η-σp散點圖;從圖5中可以看到,在σp低段,η1(Ω1的η)非常高,而且隨著σp的增加迅速下降。這其中的原因是平衡RSB負載產生了Ω1平衡處理器負載,當RSB負載平衡被打破時,平衡處理器負載不能達到,處理器的能力得不到充分利用。
隨著σp的增加,η1,η2和η3之間的差距變得越來越大,這表明在ESN中,RSB負載分布的越廣,3SOA達到的優化效果更好。隨著σp的增加,η2-η1從1.62%增加到38.62%,η3-η2從2.74%增加到11.4%。這驗證了第三階段的優化效果是相當顯著的。擁有廣分布RSB負載的ESN通過3SOA方法可以使得能源數據采集的效率增加50%以上。
2、應用型案例研究
在計算性測試中驗證了3SOA能夠提高能源數據采集速度,為了再次確認,進一步采用了應用型案例,本案例來源于一個陶瓷制造企業,該企業消耗電能,天然氣,水和壓縮空氣等資源。為了滿足SEEM的需求,該企業建造了一個大規模的ESN自動在設備層面上采集能耗數據和工作狀態。ESN中包含了721個電表,95個燃氣流量計,29個水流量計和25個壓縮空氣流量計。它們由82條RSB連接,采集服務器有8個處理器。電表能計量包括累計電量、電流、電壓、功率因數、諧波等在內的60多個參數,各流量計能測量累計流量、瞬時流量、溫度、壓力等參數。因此,一個表計存在一個或多個DCJ,整個網絡中DCJ總數達2322個。
因為設備分布的復雜性和分散性,通常采用Zigbee無線網關將RSB和數據服務器連接在一起,結果造成RSB之間的通信質量和采集負載方面存在很大的差異。據統計,λa在2到6ms之間變化,λb在8到35ms之間,λc從5到10ms之間變化,λ(J)時43411ms,σn是9.32,σp是628.46,RSB上DCJ的最小數目為1,最大數目是32,RSB的最小工作載荷是28ms,最大工作載荷是992ms.
進行研究之前,能耗數據采集程序使用java語言編寫,只采用DCJ調度的第一階段優化,認為RSB的所有DCJ都是連續的。其平均完成時間(π)將近10秒,一些能耗數據像流量,流動率,壓力等數據不能準確地通過設備層面上的工作狀態體現出來。數據采集的原始版本命名為EDC1.0,后來升級增加了第二階段,命名為EDC2.0,再后來增加了第三階段,命名為EDC3.0。案例中中EDC的這三個版本分別獨立測試,測試的平均性能指標在表2中列出。
Table 2 The average performance indexes of the three versions of EDC
表2中Diff(2.0-1.0)表明EDC2.0和1.0的性能指標差異,Diff(3.0-2.0)和Diff(3.0-1.0)分別表示了EDC3.0和EDC2.0以及EDC3.0和EDC1.0的差異。從表中可以看出EDC3.0的完成時間達到了6055ms(將近6s),和實時需求差了5s。EDC2.0的η比EDC1.0高了20.85%,而EDC3.0又比EDC2.0高了13.60%,這就證實了EDC1.0對于大規模寬分布的ESN還有較大的提升空間。
案例中的制造企業已經采用了用于SEEM的EDC3.0,它顯著提高了能耗數據采集的時效性,如圖6所示,可以看到能源管理系統的能耗檢測器的顯示屏,顯示著從EDC3.0采集來的數據。圖6中的數據是EDC3.0采集的拋光車間的實時能耗數據,并且關閉,閑置,工作等每個設備的工作狀態都可以實時反映出來。越多實時的數據,越能反映出更高的精確度。
綜上所述,3SOA在計算案例和應用案例中測試并得到了以下結論:首先3SOA可以顯著提高能源數據采集的并行效率,而且在一些大規模寬分布的能源傳感網絡中更有效果;其次,在應用案例中,相比于考慮RSB所有過程的傳統算法,增加第二步優化步驟可以提高20.85%的并行效率;最后增加第三步可以提高13.60%的并行效率。
以上結合具體實施例描述了本發明的技術原理。這些描述只是為了解釋本發明的原理,而不能以任何方式解釋為對本發明保護范圍的限制。基于此處的解釋,本領域的技術人員不需要付出創造性的勞動即可聯想到本發明的其它具體實施方式,這些方式都將落入本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!