一種智能的問答系統的制作方法
本申請涉及人機智能交互技術領域,尤其涉及一種智能的問答系統。
背景技術:
自動問答系統是指以自然語言理解技術為核心,使得計算機能夠理解用戶的談話內容,實現人與計算機之間的有效交流溝通,并且提供強大的搜索能力,準確回答用戶的問題。其中,目前在計算機客服系統中普遍采用的智能問答系統就是一種自動問答系統,它是一種通過自然語言技術,能夠理解用戶的問題,并且提供準確的答案的人工智能系統。
本發明能夠應對Jeopardy中的挑戰,節目的比賽以一種獨特的問答形式進行,問題設置的涵蓋面非常廣泛,涉及到歷史、文學、藝術、流行文化、科技、體育、地理、文字游戲等等各個領域。根據以答案形式提供的各種線索,參賽者必須以問題的形式做出簡短正確的回。與一般問答節目相反,Jeopardy中以答案形式提問、提問形式作答。參賽者需具備歷史、文學、政治、科學和通俗文化等知識,還得會解析隱晦含義、反諷與謎語等,而電腦并不擅長進行這類復雜思考。本智能問答系統能夠很好的符合該邏輯思路,并且具備從海量的數據源中找到正確答案的能力,還對參考答案的可信度進行打分排名。
技術實現要素:
為實現上述目的,本發明采用的技術方案為一種智能的問答系統,該系統包括內容獲取模塊、問題分析模塊、假設生成模塊、軟過濾模塊、證據打分模塊、答案合并和排名模塊。
步驟一、內容獲取模塊,用于確認和匯集與答案相關的內容,對問題空間的問題進行分析并且分類,自動拓展資料庫;
步驟二、問題分析模塊,用于分析輸入的問題信息,確定問題類型、發覺問題間的關系和分解問題;
步驟三、假設生成模塊,用于從數據源中盡可能多的搜索與答案相關的內容作為參考答案;
步驟四、軟過濾模塊,對大量的參考答案進行篩選,分出很可能是正確答案的一類和有可能是正確答案的一類;
步驟五、證據打分模塊,根據打分對象對參考答案進行詳細的打分,確定其接近參考答案的程度;
步驟六、答案合并和排名模塊,將分拆的答案合并,計算可信度,并且排名,排名最靠前的即為系統認為的最佳答案。
附圖說明
圖1智能問答系統構架原理圖。
圖2智能問答系統流程圖1。
圖3智能問答系統流程圖2。
圖4答案合并和排名模型。
具體實施方式
下面結合附圖和具體的實施例對本發明做進一步的闡述。
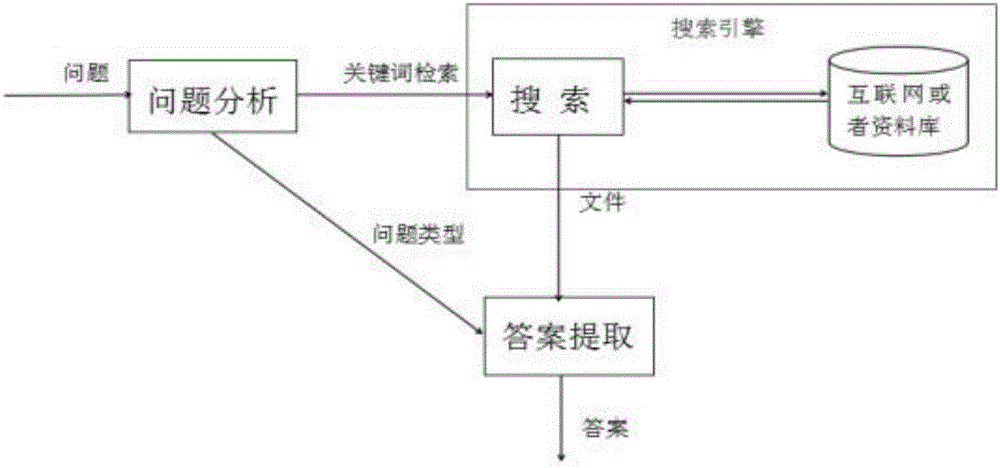
整體的系統構架有四部分組成:問題分析、搜索、答案提取和數據庫,如圖1所示。對于系統進一步分解,如圖2所示。對于輸入到系統的問題,具體流程圖如圖3所示,具體如下:
S301、本系統有一個圖形界面,設計用戶輸入框來接收用戶輸入的問題。
S302、對問題進行分析,判斷問題的類型,后期會根據問題的類型采取不同的檢索和打分方案,并且將問題自動添加到對應的數據庫中,自動拓展數據庫。
S303、對于一些可分的長問題可以分成若干個小問題,根據語法和分詞結果提取出多個問題。
S304、對于分出的每一個小問題都從數據庫中搜索相關答案,作為參考答案,相關性的計算如公式1、公式2所示。
S305、對參考答案進行打分,越是相關性高的打分越高,打分的方法如公式3、公式4所示。
S306、對分數進行判斷,如果大于閾值,就直接跳轉到排位階段,如果小于閾值,還需要進行S307步驟。原因是S305的打分方法與上下文的關系不大,所以可能對答案的可靠性不高。
S306、根據參考答案所在的數據源的位置進行上下文檢測,匹配比較,綜合其它的因素,如數據的流行度、可靠性度。再一次打分。
S306、對各個分數按照一定的權值計算賦予權值,求和,得出參考答案的總分。
S307、到這里所有的參考答案都會有一個對應的分數,根據分數的高低排名
S308、根據算法計算出可信度,結合S307,具體過程如圖4所示,會用到機器學習的方法訓練出模型,自動進行可信度計算。
內容獲取模塊具體包括:針對面向的領域對問題的類型進行歸類分類,總結出面向的領域的特色,從各種文本中搜索與答案相關的內容。將問題分詞,記為ti,分詞ti在一處數據源的分數記為pi,當文本中包含分詞ti,wij=idf(tj);否則wij=0。
其中,
c(t)表示包含分詞t的文件數目,N表示在數據源中所有文件的數目。
所述問題分析模塊具體包括:確認問題類型,對問題進行分類,針對不同類型的問題有不同的處理方法,并且發覺問題間的關系,然后分解問題。
所述發覺問題間的關系模塊具體包括:將輸入的問題與數據庫中的問題進行比較,挖掘問題間語法上的主謂賓關系以及語義上聯系,有的問題答案從這一步直接產生。
所述分解問題模塊具體包括:通過分解問題更快更準確的找到答案,將一個復雜句式的問題分成多個簡單的問題,并行處理每一個問題,并分別為答案的可行度打分。
所述假設生成模塊具體包括:從數據源中盡可能多的搜索與答案相關的內容,針對不同類型的問題使用不同的搜索算法,所有相關的內容都做為參考答案。
所述軟過濾模塊具體包括:運用輕量級的打分算法對參考答案進行篩選,通過過濾器的參考答案需要進入打分模塊,未通過過濾器的參考答案進入合并排名模塊。
所述打分模塊具體包括:從進入打分模塊的參考答案的上下文中找到支持參考答案的額外證據,根據語義、語法的聯系及多種打分算法對參考答案進行打分,越可能是參考答案打分越高。打分的對象為位置、文字支持度、流行度、信息可靠性。具體方法為:
首先創建兩個一維數組P,Q,一個二維數組score;P和Q中存放分詞的符號,score中存放分數并初始化score[i][j]=0;
然后計算每一個score[i][j],運用以下公式
其中
if t1=t2
特別sim(FOCUS,CANDIDATE)=log(N).
所述合并排名模塊具體包括:將拆分的問題分數按照一定的權值合并,計算出總分;通過機器學習算法訓練出自信度估計模型,基于問題的總分自動生成自信度估計,并排名。
對輸入的問題進行處理,在各種不同的數據源中進行搜索參考答案,并且對參考答案進行拆分、打分、合并處理,最后得到參考答案的排名和可信度,輸出答案。
- 還沒有人留言評論。精彩留言會獲得點贊!