一種基于加速度計和陀螺儀的空中手寫字符識別方法與流程
本發明涉及模式識別與人工智能
技術領域:
,具體涉及一種基于加速度計和陀螺儀的三維空間空中手寫字符識別方法。
背景技術:
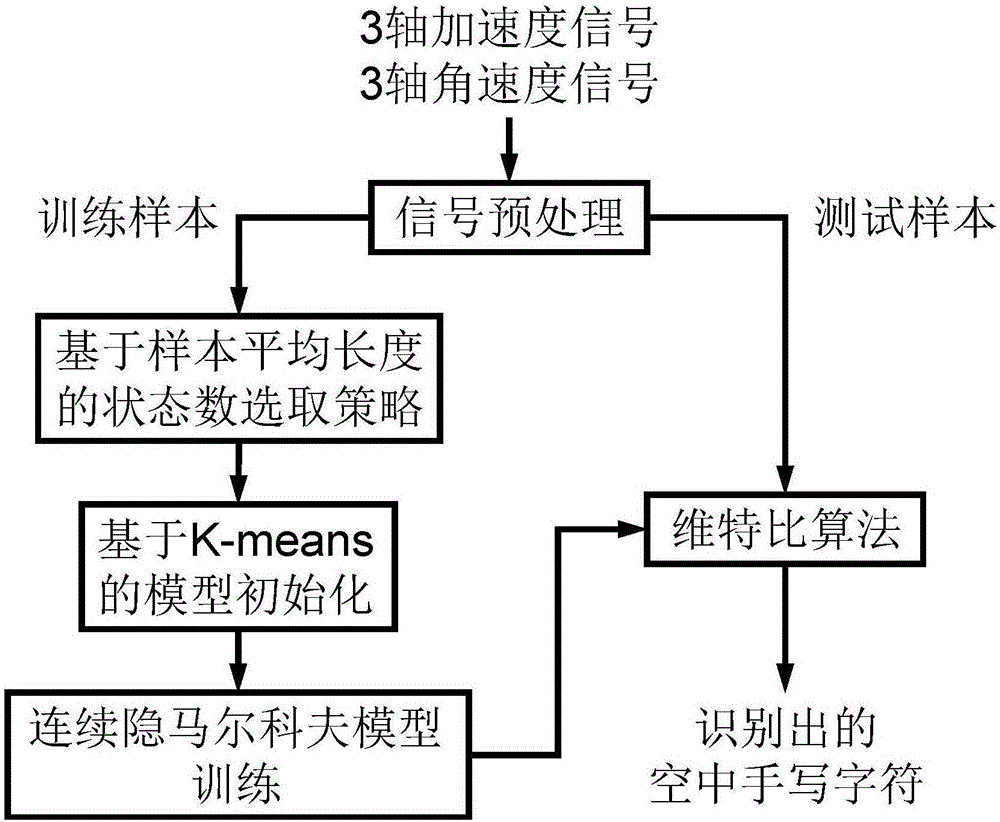
:基于加速度計和陀螺儀的空中手寫識別是近年來計算機領域中新興起的研究前沿方向之一,利用用戶身上可穿戴設備或集成在手機以及手柄等手持設備上的加速度計和陀螺儀采集手寫數據,通過分析手寫過程產生的加速度和角速度信號來識別用戶的書寫內容,它屬于穿戴式計算(WearableComputing)和普適計算(UbiquitousComputing)的重要研究內容之一。目前,基于加速度計和陀螺儀的空中手寫識別主要包括書寫內容識別和書寫人識別。書寫內容識別主要是識別書寫的字符、單詞、短語、句子等具體的內容;書寫人識別則主要是實現書寫者的身份區分,可用于手寫簽名鑒定等領域。基于加速度計和陀螺儀的空中手寫字符識別的關鍵在于模型的選取,所選模型需要具有對時序序列良好的建模能力;另外由于信號波形很不直觀,很難單純通過肉眼觀察波形對書寫內容加以區分,而且由于不同人書寫習慣的差異,同一個字符的信號波形也有較大差異,因此模型需要能夠挖掘信號潛在的變化規律而非僅根據數值變化做出判別。技術實現要素:本發明的目的是為了解決現有技術中的上述缺陷,提供一種基于加速度計和陀螺儀的三維空間空中手寫字符識別方法,能對10個阿拉伯數字(0-9)、26個大寫英文字母(A-Z)和26個小寫英文字母(a-z)實現建模和識別。本發明的目的可以通過采取如下技術方案達到:一種基于加速度計和陀螺儀的空中手寫字符識別方法,所述空中手寫字符識別方法包括:S1、數據預處理步驟,對采集的原始信號進行滑動平均濾波,以及對每一維數據分別Z-score標準化;S2、模型參數初始化步驟,需要預先確定的模型參數包括隱藏狀態數N、各隱藏狀態對應的高斯概率分布個數M、連續隱馬爾科夫模型(ContinuousHiddenMarkovModel,簡稱CHMM)的模型參數λ=[π,A,B,μ,Σ,C],其中π為初始狀態概率分布、A為狀態轉移概率分布、B為觀察值概率分布、μ是高斯概率分布均值、Σ是高斯概率分布協方差、C是高斯概率分布權重,其中,模型參數初始化策略包括基于樣本平均長度的CHMM隱藏狀態數選取方法和基于K-均值聚類的連續隱馬爾科夫模型-高斯混合模型參數初始化策略;S3、CHMM模型訓練步驟,使用前向-后向算法和Baum-Welch算法,對于特定的空中手寫字符,給定訓練數據,以及已初始化的模型參數N、M與π、A、C、μ和Σ,迭代訓練使得模型生成訓練樣本的概率不斷增大直至收斂;S4、空中手寫字符識別步驟,給定已訓練的所有空中手寫字符CHMM模型,以及測試數據,用維特比算法計算每個測試樣本屬于每一類字符的概率,最后通過快速排序獲得可能性最大的類別,完成識別。進一步地,所述S2、模型參數初始化步驟具體如下:S21、從預處理后的數據中隨機選取部分作為訓練樣本,按字符類別分類,計算每類別的樣本的平均長度,設置模型的隱藏狀態數N;S22、用K-均值算法初始化模型參數,將當前類別每一個樣本在時間上均分為N段,各段序列的所有6維特征向量分別歸于N個集合Seti,接著分別對每個Seti,i=1,2,...,N用K-均值聚類聚成M簇gim,m=1,2,...,M,以表示屬于各狀態的M個高斯概率分布;最后對總共M×N個簇計算統計信息,初始化模型參數。進一步地,所述步驟S22具體如下:S221、初始狀態概率πi等于Seti集合大小與字符訓練樣本向量總數之比;S222、初始狀態轉移概率矩陣A按照從左到右型隱馬爾科夫模型的結構初始化:任意一個隱藏狀態只能向下一個狀態轉化或保持不變,最后的狀態不能向其他狀態轉化;S223、初始高斯混合模型權值Cjm等于簇gjm的大小與集合Setj大小之比;S224、初始高斯元均值向量μjm等于簇gjm的均值;S225、初始高斯混合元協方差向量Ujm即計算簇gjm的協方差。進一步地,所述S3、CHMM模型訓練步驟中的前向-后向算法采用逐時刻歸一化前向變量與后向變量的方法對前向變量α與后向變量β進行逐時刻歸一化,具體如下:在計算完某時刻t的前向變量α之后,先進行歸一化:即該時刻各狀態的前向變量α分別除以該時刻各狀態的前向變量α的和,再進行時刻t+1的計算,后向變量β先計算時刻t+1的值,后計算前一時刻t的值,逐時刻歸一化公式如下:進一步地,所述采集的原始信號包括三維加速度信號和三維角速度信號。進一步地,所述S1、數據預處理步驟具體為:對于采集到的三維加速度信號和三維角速度信號,首先對各維數據用滑動平均濾波器去噪,然后進行Z-score標準化處理,使每一維數據均值為0、標準差為1。進一步地,所述S3、CHMM模型訓練步驟中,若迭代訓練中兩次迭代所得的參數的差異小于預定的閾值,則認定訓練樣本收斂。本發明相對于現有技術具有如下的優點及效果:本發明公開的一種基于加速度計和陀螺儀的三維空間空中手寫識別方法提供了一種全新的手寫方式,其不同于傳統的二維平面書寫,不具有書寫過程中觸覺和視覺的反饋,但它既不受某個特定的書寫平面的限制(如手寫板、觸摸屏),也不需要其他外掛設備(如攝像頭),工作空間的限制小,對環境變化、光照、膚色等因素不敏感,使用者只需要手持嵌入三軸加速度計與陀螺儀的書寫設備在空中自由書寫。附圖說明圖1是本發明公開的基于加速度計和陀螺儀的空中手寫識別方法的流程圖;圖2是本發明在數據庫二號規定的書寫筆畫順序;圖3是本發明的實施例基于數據庫一號的5折交叉驗證混淆矩陣;圖4是本發明的實施例基于數據庫二號的5折交叉驗證混淆矩陣;圖5是本發明的實施例基于數據庫三號的5折交叉驗證混淆矩陣。具體實施方式為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。實施例本發明實施例公開了一種基于加速度計和陀螺儀的空中手寫字符識別方法,能對10個阿拉伯數字(0-9)、26個大寫英文字母(A-Z)和26個小寫英文字母(a-z)實現建模和識別。實施本發明所用的輸入設備是嵌入三軸加速度計和陀螺儀的裝置,可以是智能手機、Wii手柄等。基于連續隱馬爾科夫模型-高斯混合模型的空中手寫字符識別算法的系統流程圖如附圖1所示,具體步驟包括:S1、信號預處理對于采集到的三維加速度信號和三維角速度信號,首先對各維數據用滑動平均濾波器去噪,以減少無意識的人為抖動和硬件因素帶來的高頻噪聲,然后進行Z-score標準化處理,使每一維數據均值為0、標準差為1,以減少采集者書寫力度和重力的影響。S2、模型參數初始化需要預先確定的模型參數包括隱藏狀態數N、各隱藏狀態對應的高斯概率分布個數M、連續隱馬爾科夫模型(ContinuousHiddenMarkovModel,簡稱CHMM)的模型參數λ=[π,A,B,μ,Σ,C],其中π為初始狀態概率分布,A為狀態轉移概率分布,B為觀察值概率分布,μ是高斯概率分布均值,Σ是高斯概率分布協方差,C是高斯概率分布權重。初始化策略包括基于樣本平均長度的CHMM隱藏狀態數選取方法,以及基于K-均值聚類的CHMM-GMM參數初始化策略。具體如下:S21、從預處理后的數據中隨機選一部分作為訓練樣本,按字符類別分類。計算每類別的樣本的平均長度,設置模型的隱藏狀態數N,平均長度越長,N越大。S22、用K-均值算法初始化其他模型參數:將當前類別每一個樣本在時間上均分為N段,各段序列的所有6維特征向量分別歸于N個集合Seti,接著分別對每個Seti,i=1,2,...,N用K-均值聚類聚成M簇gim,m=1,2,...,M,以表示屬于各狀態的M個高斯概率分布;最后對總共M×N個簇計算統計信息,初始化模型參數。具體數值計算方法如下:S221、初始狀態概率πi等于Seti集合大小與字符訓練樣本向量總數之比;S222、初始狀態轉移概率矩陣A按照從左到右型隱馬爾科夫模型的結構初始化:任意一個隱藏狀態只能向下一個狀態轉化或保持不變,最后的狀態不能向其他狀態轉化;S223、初始高斯混合模型權值Cjm等于簇gjm的大小與集合Setj大小之比;S224、初始高斯元均值向量μjm等于簇gjm的均值;S225、初始高斯混合元協方差向量Ujm即計算簇gjm的協方差。S3、模型訓練CHMM訓練過程包括前向-后向算法和Baum-Welch算法,對于特定的空中手寫字符,給定訓練數據,以及已初始化的模型參數N、M與π、A、C、μ和Σ,迭代訓練使得模型生成訓練樣本的概率不斷增大直至收斂:即兩次迭代所得的參數的差異小于預定的閾值。在前向-后向算法中提出逐時刻歸一化前向變量與后向變量的方法,以避免數據下溢。前向-后向算法采用的對前向變量α與后向變量β逐時刻歸一化方法具體如下:在計算完某時刻t的前向變量α之后,先進行歸一化:即該時刻各狀態的前向變量α分別除以該時刻各狀態的前向變量α的和,再進行時刻t+1的計算。相似地,β先計算時刻t+1的值,后計算前一時刻t的值。逐時刻歸一化方法:S4、空中手寫字符識別給定已訓練的所有空中手寫字符CHMM模型,以及測試數據,用維特比算法計算每個測試樣本屬于每一類字符的概率,最后通過快速排序獲得可能性最大的類別,完成識別。當空中手寫完成,系統給出快速排序所得可能性最大的前N個字符以供選擇,能有效提高識別率。本發明公開的基于加速度計和陀螺儀的空中手寫字符識別方法的優異性能通過大樣本的實驗得到了證實。下面描述采用本發明所述的空中手寫字符建模與識別方法,對大量三維空間書寫樣本進行相關實驗的結果,字符類別包括10個阿拉伯數字0-9,26個大寫英文字母A-Z,26個小寫英文字母a-z。本實施例利用三個空中手寫字符庫,下面是數據庫的介紹:a)、數據庫一號3軸加速度信號數據庫一號由實驗者采集,包含1130條序列,10個阿拉伯數字各113個樣本,樣本維度為3。共有40名采集者(全部男性)參與了數據采集,每人書寫每個字符3次,有3人只寫了1次或2次。采集者利用Wii手柄在100Hz的采樣率下采集加速度信號,控制器上有一個被編程為“按下以書寫”書寫模式的標記按鈕,“按下以書寫”模式用于提供提筆和落筆信息,該書寫模式表示采集者按下該按鈕以開始空中手寫,完成一個字符后釋放按鈕。這個數據庫最大的特點是沒有書寫的限制,實驗者不要求采集者在一個想象的方框中書寫,不限制筆畫順序、書寫速度和范圍。每名采集者被允許按照自己的習慣書寫。b)、數據庫二號6維數據(包括3軸加速度與3軸角速度)數據庫二號由實驗者采集。數據庫二號是本實施例三個數據庫中規模最大的,包含10個阿拉伯數字0-9和26個大寫字母A-Z共36種類型,14,530個樣本。共49名采集者(31名男性,18名女性)參與了數據采集,每人書寫每個字符至少8次。在數據庫二號的采集過程中實驗者規定了一套筆畫順序,每個空中手寫字符需一筆完成,如附圖2所示。實驗者實現了有“按下以書寫”功能的安卓程序并安裝于一臺HTC智能手機,其內置傳感器以50Hz的采樣率測量并記錄信號,由于安卓系統的特性,實際采樣率為10到15Hz,且該值與具體手機有關。c)、公開手寫庫:數據庫三號數據庫三號是一個公開的空中手寫字符數據庫,包含10個阿拉伯數字0-9、26個大寫字母A-Z和26個小寫字母a-z共62種字符,8,571條14維的序列。22名采集者(17名男性,5名女性)參與數據采集,使用采樣率60Hz的混合型數據測量框架,每人書寫每個字符10次。該數據庫在書寫限制上不僅規定了筆畫順序,還要求了一塊想象的書寫區域,即限定了手部移動的范圍。實驗者僅僅提取其中的3維加速度和3維角速度用于分析。在試驗中分別用三個數據庫的數據實現了用戶混合(Mixed-User)系統,該系統的特點在于:在訓練與測試樣本選取上,用戶混合系統對數據庫整體按一定比例分為兩部分,其中一部分的樣本用于訓練,另一部分的樣本用于測試。實驗采用5折交叉驗證,即將數據集分為5個大小相等的子集,各子集輪流充當測試集,剩余4個子集充當訓練集,然后訓練5次求得5次識別率并求平均值。實驗測試中采用了“TOP-N”策略:若由維特比算法求得的可能性前N大的字符類別中,含有測試樣本的真實類別,則視作識別正確,否則識別錯誤。實驗記錄了時間消耗,其中識別測試時間指平均識別一個樣本所需時間,記錄了5折交叉驗證平均識別率(見表1至表2)和混淆矩陣(見圖3至圖5)。表1.用戶混合系統5折交叉驗證各階段時間消耗表2.用戶混合系統5折交叉驗證平均識別率TOP-1TOP-3TOP-5數據庫一號全部72.04%93.10%97.62%數據庫二號數字95.30%99.63%99.80%數據庫二號大寫89.11%97.68%98.83%數據庫二號全部87.52%97.42%98.77%數據庫三號數字99.00%100.0%100.0%數據庫三號小寫98.22%99.94%99.94%數據庫三號大寫99.00%100.0%100.0%數據庫三號全部95.59%99.58%99.86%表1顯示,該發明公開的空中字符識別方法識別一條來自三個數據庫的待測樣本所消耗的平均時間都很短,說明一旦完成模型的訓練,空中字符識別方法就能高效準確地工作,因此該發明公開的空中字符識別方法具有較好的實時性。表2顯示,用三個數據庫訓練的CHMM-GMM分類器的5折平均識別率較高,尤其在規范了筆畫順序和書寫范圍后,識別性能優秀,因此該發明公開的空中字符識別方法對空中手寫字符的識別準確性好。上述實施例為本發明較佳的實施方式,但本發明的實施方式并不受上述實施例的限制,其他的任何未背離本發明的精神實質與原理下所作的改變、修飾、替代、組合、簡化,均應為等效的置換方式,都包含在本發明的保護范圍之內。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1