健康數據處理方法、裝置及服務器集群與流程
本申請涉及大數據處理技術領域,尤其涉及一種健康數據處理方法、裝置及服務器集群。
背景技術:
隨著可穿戴設備的快速發展,用戶可以通過可穿戴設備實現各種應用功能,例如通過可穿戴設備監測用戶的運動量、用戶的睡眠情況等。
現有技術中,一般通過步數、里程、卡路里等數據來衡量用戶的運動量,通過用戶的睡眠中的翻身次數等來衡量用戶的睡眠質量,但是由于這些健康數據缺乏專業的參考標準,因此用戶一般無法根據這些健康數據確定自己的運動量是否合理,睡眠質量是否比較好等,因此現有技術提供的數據對用戶沒有很大的參考價值,對用戶的健康指導效果差。
技術實現要素:
有鑒于此,本申請提供一種新的技術方案,可以解決現有技術提供的數據對用戶沒有很大的參考價值,對用戶的健康指導效果差的技術問題。
為實現上述目的,本申請提供技術方案如下:
根據本申請的第一方面,提出了一種健康數據處理方法,該方法包括:
接收可穿戴設備在預設時間周期內采集的用戶數據,所述用戶數據包括用戶基本信息和健康衡量數據;
根據所述用戶基本信息,確定所述健康衡量數據對應的維度組合;
基于所述維度組合對應的分布模型和所述健康衡量數據,確定用戶在所述預設時間周期內的健康衡量數據在所述維度組合中的排序。
根據本申請的第二方面,提出一種健康數據處理方法,可包括:
接收可穿戴設備在預設時間周期內采集的用戶數據,所述用戶數據包括健康衡量數據;
基于分數計算模型和所述健康衡量數據,確定所述用戶在所述預設時間周期內的健康衡量數據對應的健康分數;
基于分數分布模型和所述用戶在所述預設時間周期內的健康衡量數據對應的健康分數,確定用戶在所述預設時間周期內的健康衡量數據對應的健康分數的排序。
根據本申請的第三方面,提出了一種健康數據處理裝置,可包括:
第一接收模塊,用于接收可穿戴設備在預設時間周期內采集的用戶數據,所述用戶數據包括用戶基本信息和健康衡量數據;
組合確定模塊,用于根據所述第一接收模塊接收到的所述用戶基本信息,確定所述健康衡量數據對應的維度組合;
指標排序模塊,用于基于所述組合確定模塊確定的所述維度組合對應的分布模型和所述第一接收模塊接收到的所述健康衡量數據,確定用戶在所述預設時間周期內的健康衡量數據在所述維度組合中的排序。
根據本申請的第四方面,提供了一種健康數據處理裝置,可包括:
第二接收模塊,用于接收可穿戴設備在預設時間周期內采集的用戶數據,所述用戶數據包括健康衡量數據;
分數計算模塊,用于基于分數計算模型和所述第二接收模塊接收到的所述健康衡量數據,確定所述用戶在所述預設時間周期內的健康衡量數據對應的健康分數;
分數排序模塊,用于基于分數分布模型和所述分數計算模塊確定的所述用戶在所述預設時間周期內的健康衡量數據對應的健康分數,確定用戶在所述預設時間周期內的健康衡量數據對應的健康分數的排序。
根據本申請的第五方面,提出了一種服務器集群,可包括:
處理器;用于存儲所述處理器可執行指令的存儲器;
其中,所述處理器,被配置為執行上述權利要求所述的健康數據處理方法。
根據本申請的第六方面,提出了一種服務器集群,可包括:
處理器;用于存儲所述處理器可執行指令的存儲器;
其中,所述處理器,被配置為執行上述權利要求所述的健康數據處理方法。
由以上技術方案可見,本申請可以對可穿戴設備獲得的健康衡量數據按照維度組合進行分析,并確定出用戶的健康衡量數據在對應的維度組合中的排序,以便在用戶可以根據自己在相似人群中的健康排序確定自己的健康狀態,使得數據的參考價值更高,優化數據對用戶的健康指導效果;此外,本申請還可以對可穿戴設備獲得的健康衡量數據進行分數計算,并確定出用戶的分數排名,以便用戶可以根據的得分確定自己的健康狀態。
附圖說明
圖1A示出了根據本發明的一示例性實施例的健康數據處理方法的流程示意圖;
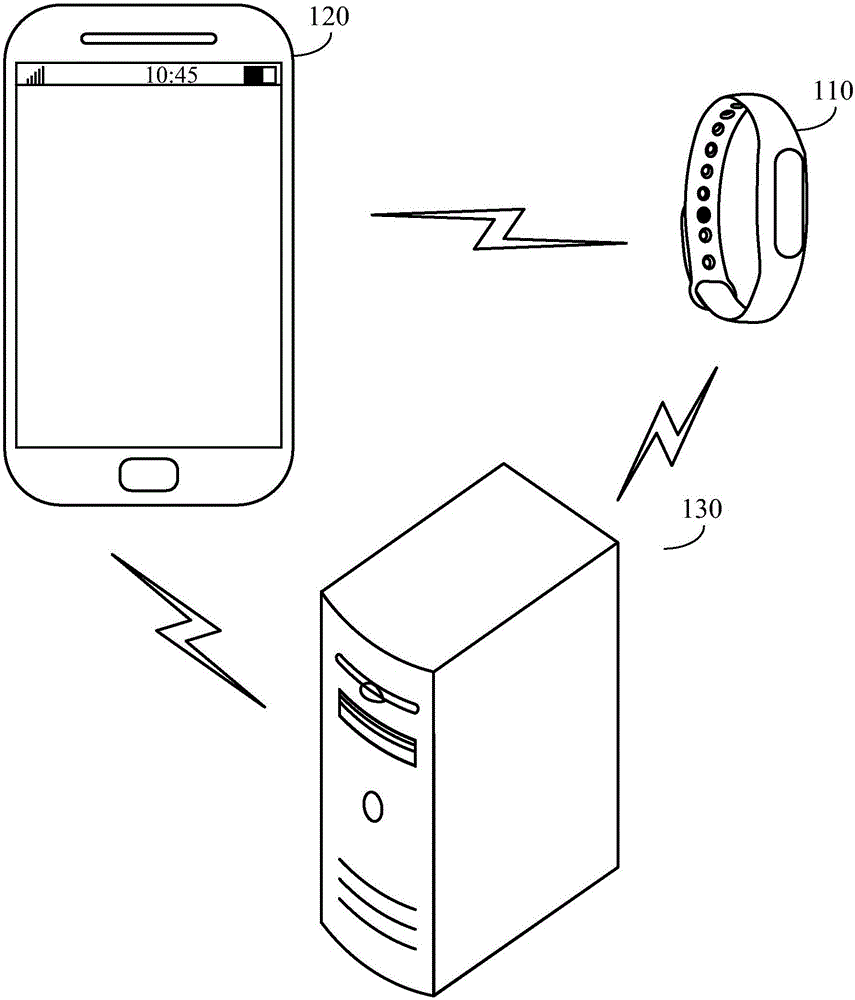
圖1B示出了根據本發明的一示例性實施例的健康數據處理方法的應用場景示意圖;
圖2A示出了根據本發明的又一示例性實施例的確定每一個維度組合中每一項指標的指標分布模型的流程圖;
圖2B示出了根據本發明的又一示例性實施例的步驟203的方法流程圖;
圖2C示出了根據本發明的又一示例性實施例的實時更新指標分布模型的方法流程圖;
圖3示出了根據本發明的又一示例性實施例的健康數據處理方法的流程圖;
圖4A示出了根據本發明的又一示例性實施例的確定用戶在所述預設時間周期內的健康衡量數據對應的健康分數的方法流程圖;
圖4B示出了根據本發明的又一實施例的根據用戶的歷史健康分數確定用戶的身體變化狀態的流程圖;
圖5示出了根據本發明的一示例性實施例的服務器集群中每臺服務器的結構示意圖;
圖6示出了根據本發明的一示例性實施例的健康數據處理裝置的框圖;
圖7示出了根據本發明的又一示例性實施例的健康數據處理裝置的框圖;
圖8示出了根據本發明的一示例性實施例的健康數據處理裝置的框圖;
圖9示出了根據本發明的又一示例性實施例的健康數據處理裝置的框圖。
具體實施方式
這里將詳細地對示例性實施例進行說明,其示例表示在附圖中。下面的描述涉及附圖時,除非另有表示,不同附圖中的相同數字表示相同或相似的要素。以下示例性實施例中所描述的實施方式并不代表與本申請相一致的所有實施方式。相反,它們僅是與如所附權利要求書中所詳述的、本申請的一些方面相一致的裝置和方法的例子。
在本申請使用的術語是僅僅出于描述特定實施例的目的,而非旨在限制本申請。在本申請和所附權利要求書中所使用的單數形式的“一種”、“所述”和“該”也旨在包括多數形式,除非上下文清楚地表示其他含義。還應當理解,本文中使用的術語“和/或”是指并包含一個或多個相關聯的列出項目的任何或所有可能組合。
應當理解,盡管在本申請可能采用術語第一、第二、第三等來描述各種信息,但這些信息不應限于這些術語。這些術語僅用來將同一類型的信息彼此區分開。例如,在不脫離本申請范圍的情況下,第一信息也可以被稱為第二信息,類似地,第二信息也可以被稱為第一信息。取決于語境,如在此所使用的詞語“如果”可以被解釋成為“在……時”或“當……時”或“響應于確定”。
為對本申請進行進一步說明,提供下列實施例:
圖1A示出了根據本發明的一示例性實施例的健康數據處理方法的流程示意圖,圖1B示出了根據本發明的一示例性實施例的健康數據處理方法的應用場景示意圖;如圖1A所示,包括如下步驟:
步驟101,接收可穿戴設備在預設時間周期內采集的用戶數據,用戶數據包括用戶基本信息和健康衡量數據。
在一實施例中,預設時間周期可以為一天、兩天、一周等時間間隔。
在一實施例中,用戶基本信息可包括但不限于以下維度:用戶的地理位置、用戶的年齡、性別、BMI(Body Mass Index,身體質量指數)等。
在一實施例中,健康衡量數據可包括用戶的睡眠數據和運動數據;在一實施例中,睡眠數據可包括但不限于以下指標數據:入睡時間、起床時間、睡眠時長、深睡時長、淺睡時長、中間起夜時長、中間起夜次數、翻身次數、快速眼動期時長等;在又一實施例中,運動數據可包括但不限于以下指標數據:總步數、總距離、運動消耗卡路里、總消耗卡路里、跑步步數、跑步時長、跑步距離、跑步消耗卡路里、就坐時間等。
步驟102,根據用戶基本信息,確定健康衡量數據對應的維度組合。
在一實施例中,可將用戶基本信息根據各個維度的值進行組合,得到多個維度組合,例如將“地理位置為北京、年齡為20~25歲、性別為男、BMI為20~23”確定為一個維度組合1,將“地理位置為北京、年齡為26~30歲、性別為女、BMI為20~23”確定為一個維度組合2,由此可看出通過將年齡相近或者相同、性別相同、地域相同、BMI指數相同或者相近的用戶劃分為同一個維度組合,可以實現每一個維度組合中的用戶組成了一個相似人群。
在一實施例中,當接收到用戶數據時,可先根據用戶基本信息確定用戶的維度組合。例如,如果用戶A為一個30歲的北京女孩,BMI指數為22,則可確定用戶A對應的維度組合為上述維度組合2。
在一實施例中,維度組合的劃分可由服務器集群根據人群常規分類方法進行劃分,也可以由服務器集群根據大數據分析得到,例如,可盡量使得每個維度組合的用戶數相近,本發明實施例不對維度組合的具體劃分進行限定。
在一實施例中,本實施例中服務器集群可包括多臺服務器,每臺服務器上部署了大數據平臺軟件,實現各自對應的功能。
步驟103,基于維度組合對應的分布模型和健康衡量數據,確定用戶在預設時間周期內的健康衡量數據在維度組合中的排序。
在一實施例中,可通過確定健康衡量數據中每一項指標數據在對應的指標分布模型中的排序,確定健康衡量數據在維度組合中的排序。例如,在維度組合1中,睡眠時長指標數據的分布模型為“5小時,10%”,“6小時30%”,“7小時,70%”,“8小時,80%”,“10小時,90%”,“12小時,96%”,則說明在北京的20-25歲的、BMI指數正常的男性用戶中,睡眠時長小于7小時的用戶有70%,也就是說睡眠為7小時時,打敗了70%的同類用戶,睡眠時長小于6小時的用戶有30%,也就是說睡眠為6小時時,打敗了30%的同類用戶。
在一實施例中,通過將每一項指標數據在對應的指標分布模型中的排序進行權重加和,可得到用戶在預設時間周期內的健康衡量數據在維度組合中的排序。例如,用戶的睡眠時長打敗了70%的用戶,深睡時長打敗了75%的用戶,入睡時間打敗了75%的用戶,則將這三項指標數據的排序計算權重加和,可得到70%*0.4+75%*0.3+75%*0.3=73%。在一實施例中,每一項指標數據的排序的權重可由服務器集群根據大數據分析并且結合醫學參考數據統計得到,本發明并不對每一項指標數據的排序的權重進行限定。
在一實施例中,指標分布模型的生成方法可參見圖2A實施例,這里先不詳述。
在一示例性實施例中,參見圖1B,可穿戴設備110(這里以手環示意)將預設時間周期內采集的健康衡量數據發送到關聯的移動設備120(這里以智能手機示意),移動設備120接收到數據之后即可通過服務接口發送至服務器集群130,服務器集群即可根據接收到的數據對健康衡量數據進行分析和處理,可穿戴設備110也可直接將采集的健康衡量數據發送至服務器集群130。
由上述描述可知,本發明實施例可以對可穿戴設備獲得的健康衡量數據按照維度組合進行分析,并確定出用戶的健康衡量數據在對應的維度組合中的排序,以便在用戶可以根據自己在相似人群中的健康排序確定自己的健康狀態,使得數據的參考價值更高,優化數據對用戶的健康指導效果。
圖2A示出了根據本發明的又一示例性實施例的確定每一個維度組合中每一項指標的指標分布模型的流程圖,圖2B示出了根據本發明的又一示例性實施例的步驟203的方法流程圖,圖2C示出了根據本發明的又一示例性實施例的實時更新指標分布模型的方法流程圖;如圖2A所示,包括如下步驟:
步驟201,統計在第一設定時間段內接收到的健康衡量數據,健康衡量數據包括多項指標數據。
在一實施例中,第一設定時間段可以為三個月、半年等一個比較長的時間段。
在一實施例中,健康衡量數據可包括用戶的睡眠數據和運動數據,睡眠數據和運動數據所包括的指標數據可參見圖1A步驟101的描述,這里不再詳述。
步驟202,對健康衡量數據按照維度組合進行分組。
在一實施例中,維度組合的劃分可由服務器集群根據人群常規分類方法進行劃分,也可以由服務器集群根據大數據分析得到,例如,可盡量使得每個維度組合的用戶數相近,本發明實施例不對維度組合的具體劃分進行限定。
步驟203,基于每一個維度組合和對應維度組合中的健康衡量數據的每一項指標數據,確定每一個維度組合中每一項指標的指標分布模型。
在一實施例中,步驟203的詳細描述可參見圖2B所示的實施例,如圖2B所示,包括以下步驟:
步驟211,將每一個維度組合中的健康衡量數據的每一項指標數據進行分桶。
在一實施例中,分桶可以理解為分段。例如,對于睡眠時長指標數據,可以按照時間間隔分桶,如按10分鐘分,420~430分鐘為睡眠時長分桶1、430~440分鐘為睡眠時長分桶2,等等;對于其他指標數據也可按照相似的劃分方法進行分桶。
步驟212,計算每一個分桶中指標數據的個數,得到對應分桶的分桶值。
在一實施例中,可通過計算劃分到對應分桶的用戶指標數據的個數,得到對應分桶的分桶值。例如:例如睡眠時長為420~430分鐘的指標數據為30個,則為睡眠時長分桶1的分桶值為30。
步驟213,將每一個維度組合中每一項指標數據的所有分桶值按照指標數據從小到大的順序進行累加和歸一化處理,得到每一個維度組合中每一項指標的指標分布模型。
在一實施例中,可先將每一個維度組合中每一項指標數據的所有分桶值按照指標數據從小到大的順序進行排序,再按照排序進行累加和歸一化處理。例如:統計了24個用戶的總步數,其中0~1000步對應于步數分桶1,1001~2000步對應于步數分桶2,2001~3000步對應于步數分桶3,3001~5000步對應于步數分桶4,其中步數分桶1的分桶值為3,步數分桶2的分桶值為5,步數分桶3的分桶值為9,步數分桶4的分桶值為7,按照指標數據從小到大的順序排序,即可得到排序3,5,9,7,按照排序累加和歸一化處理,即可得到3,8,17,24,即步數分步模型為步數小于1000的用戶占1/8,步數小于2000步的用戶占1/3,步數小于3000步的用戶占17/24。
在一實施例中,采用上述技術方案也可得到其他指標數據的指標分布模型。
在一實施例中,指標分布模型還可實時更新,可參見圖2C實施例,如圖2C所示,包括如下步驟:
步驟221,統計在第二設定時間段內接收到的健康衡量數據。
在一實施例中,第二設定時間段可以為1天、2天等比較短的一個時間段。例如,統計今天內接收到的健康衡量數據。
步驟222,基于在第二設定時間段內接收到的健康衡量數據,對每一個維度組合中每一項指標的指標分布模型進行更新。
在一實施例中,可通過移動設備將可穿戴設備采集到的數據上傳到服務器集群,服務器集群可根據每一個用戶的用戶信息數據確定用戶的維度組合,并且根據健康衡量數據的指標數據增加對應分桶的計數,進而根據更新后的分桶值更新指標分布模型。
本實施例中,通過對統計到的用戶數據的各項指標數據進行分析,可得到對應的指標分布模型,進而能夠在后續接收到用戶的健康衡量數據時根據該指標分布模型量化用戶的睡眠和運動指標,為用戶提供其睡眠運動數據在相似人群中的排序,指導用戶調整自己的睡眠和運動。
圖3示出了根據本發明的又一示例性實施例的健康數據處理方法的流程圖;如圖3所示,包括如下步驟:
步驟301,接收可穿戴設備在預設時間周期內采集的用戶數據,用戶數據包括健康衡量數據。
在一實施例中,健康衡量數據可包括用戶的睡眠數據和運動數據;在一實施例中,睡眠數據可包括但不限于以下指標數據:入睡時間、起床時間、睡眠時長、深睡時長、淺睡時長、中間起夜時長、中間起夜次數、翻身次數、快速眼動期時長等;在又一實施例中,運動數據可包括但不限于以下指標數據:總步數、總距離、運動消耗卡路里、總消耗卡路里、跑步步數、跑步時長、跑步距離、跑步消耗卡路里、就坐時間等。
步驟302,基于分數計算模型和健康衡量數據,確定用戶在預設時間周期內的健康衡量數據對應的健康分數。
在一實施例中,分數計算模型可包括多個指標分數計算模型,針對每一項指標數據,可以使用對應的指標分數計算模型來計算每個用戶的指標數據的指標分數,然后再將每一項指標分數計算權重加和,得到該用戶的健康分數。例如:用戶入睡時間得分為80分,入睡時間得分為75分,深睡時間得分為75分,清醒時長得分為80分,并且睡眠時長、入睡時間、深睡、清醒時長的權重分別為0.4、0.3、0.1、0.2,則健康分數為:
80*0.4+75*0.3+75*0.1+80*0.2=78分
在一實施例中,確定用戶在預設時間周期內的健康衡量數據對應的健康分數的方法可參見圖4A所示實施例,這里先不詳述。
步驟303,基于分數分布模型和用戶在預設時間周期內的健康衡量數據對應的健康分數,確定用戶在預設時間周期內的健康衡量數據對應的健康分數的排序。
在一實施例中,確定分數分布模型的方法可參考確定指標分布模型的方法,即:將所有用戶的健康分數按照分數段進行分桶,統計每個分桶內的健康分數的個數,得到對應的分桶值,將所有分桶值按照健康分數從小到大的順序進行累加和歸一化處理,得到分數分布模型。例如,假設健康分數滿分為100分,計算得到了100個用戶的健康分數,按照20分的間隔將健康分數分桶,0~20分對應分桶1、分桶值為10,21~40分對應分桶2、分桶值為10,41~60分對應分桶3、分桶值為20,61~80分對應分桶4、分桶值為40,81~100分對應分桶5、分桶值為20,則對應的分布模型為:“20分,10%”、“40分,20%”,“60分,40%”,“80分,80%”,“100分,100%”,則說明分數為80分的用戶打敗了80%的用戶。
在一實施例中,本實施例中可以針對睡眠數據計算出一個分數,并使用睡眠分數分布模型確定出睡眠排序;在又一實施例中,也可以針對運動數據計算出一個分數,并使用運動分數分布模型確定出運動排序;在再一實施例中,還可以針對睡眠數據和運動數據計算一個總分數,并分數分布模型確定出健康排序,由此可以使得用戶確定自己哪一項排序比較低,有針對性地確定調整健康狀態的方向。
本實施例中,通過計算每個用戶的健康分數,可以確定健康分數在所有用戶中的排序,以便用戶可以根據自己的健康排序確定自己的健康狀態,使得數據的參考價值更高,優化數據對用戶的健康指導效果。
圖4A示出了根據本發明的又一示例性實施例的確定用戶在預設時間周期內的健康衡量數據對應的健康分數的方法流程圖,圖4B示出了根據本發明的又一實施例的根據用戶的歷史健康分數確定用戶的身體變化狀態的流程圖;如圖4A所示,包括如下步驟:
步驟401,通過健康衡量數據中每一項指標對應的指標分數計算模型計算每一項指標數據的指標分數。
在一實施例中,服務器集群通過大數據分析確定出健康衡量數據中的每一項指標的指標數據的分布滿足一定的規律,例如:對于入睡時間(即開始睡眠時間)、睡眠時長、清醒時間等指標數據的分布滿足正態分布,而對于深睡比例、步數、卡路里、跑步距離等指標數據的分布可滿足類正態分布。
在一實施例中,可將式(1-1)和式(1-2)確定為入睡時間(即開始睡眠時間)、睡眠時長、清醒時間等指標數據的分數計算模型,x用于表示要計算分數的用戶對應的指標數據,例如在計算用戶的睡眠時長的分數時,x為該用戶的睡眠時長,f(x)用于表示用戶的分數,當x≥μ時使用式(1-1)計算分數,當x<μ時使用式(1-2)計算分數:
在一實施例中,μ是標準值,可以定義為一個常量或者以年齡為參數的函數,用于表示該項指標能得到滿分的指標數值;σ是標準差,其在標準兩側的值是不同的,分別為σ1和σ2,用于消除取值范圍在標準值兩側范圍不同的影響。
在一實施例中,μ可以定義為一個以年齡為參數的函數,例如,以睡眠時長為例,μ可以作為年齡a的函數,例如,對于1歲的兒童,μ可以取12.5小時,對于21歲的青年,μ可以取8.5小時。根據醫學上參考的睡眠與年齡關系,可以擬合得到一個年齡和標準睡眠時長的對應關系,例如:μ=12.925a-0.127。
在一實施例中,當指標數據與年齡沒有相應的對應關系時,也可直接將μ定義為一個常數,例如,入睡時間,不管是兒童還是老年,一般在晚上10點之前入睡為佳,則可以將μ定義為晚上10點。
在一實施例中,可將式(2)確定為深睡比例、步數、卡路里、跑步距離等指標數據的指標分數計算模型:
在一實施例中,μ可以取值為0,σ為標準差。
步驟402,將每一項指標數據的指標分數進行權重加和,得到健康衡量數據對應的健康分數。
在一實施例中,可針對睡眠數據的各項指標數據計算出一個權重加和,得到睡眠總分,其中,每項指標的權重可以通過海量的用戶健康數據并參考醫學數據得到并存儲在服務器集群中。
在又一實施例中,也可以針對運動數據計算出一個權重加和,得到睡眠總分。
在再一實施例中,還可以針對睡眠數據和運動數據計算權重加和,得到一個健康總分。
在一實施例中,上面只示例了其中8項指標數據的指標分數計算模型,其他指標數據的指標分數計算模型也可以通過相應的方式統計分析得到,本實施例不再對此詳述。
在一實施例中,為了使得用戶能夠根據自己的歷史分數與現在的分數進行對比以便更準確地表現用戶身體健康狀態,參見圖4B,包括以下步驟:
步驟411,將用戶在當前預設時間周期內的健康衡量數據對應的健康分數以及歷史的健康分數進行權重加和,得到用戶當前的健康分數。
在一實施例中,歷史的健康分數用于表示歷史預設時間周期對應的當前的健康分數;當前的健康分數在計算下一個預設時間周期對應的當前的健康分數時,將變為下一個預設時間周期的歷史的健康分數。
在一實施例中,可使用式(3)計算第n天的當前的健康分數:
其中,n表示第n天,Sn表示第n天的當前的健康分數,ai表示第i天根據健康衡量數據計算得到的健康分數,a0用于表示第一天內所有用戶的得分的平均值,P表示前一個歷史的健康分數占的權重,Q表示當前預設時間周期計算得到的健康分數所占的權重。在一實施例中,歷史的健康分數占的權重P與當前預設時間周期計算得到的健康分數所占的權重Q的和為1,本申請并不對P和Q各自的具體取值進行限定。
步驟412,基于用戶當前的健康分數以及歷史的健康分數,確定用戶的分數變化狀態。
在一實施例中,可以根據每個預設時間周期內的歷史健康分數可以確定出分數變化狀態。例如,如果第一天的歷史健康分數為S1=a0=60,第二天的歷史健康分數為75分,第三天的歷史健康分數為76分,第四天的歷史健康分數為77分……,根據每天的歷史健康分數可以看出用戶的歷史健康分數是逐步增加的。
步驟413,根據分數變化狀態,確定用戶的身體變化狀態。
在一實施例中,如果用戶的歷史健康分數是逐步增加的,則可確定用戶的睡眠運動越來越好,身體狀態也越來越好;在又一實施例中,如果用戶的歷史健康分數是逐步減小的,則可確定用戶的睡眠運動越來越差,身體狀態也越來越差。
本實施例中,通過計算每個用戶的健康分數,可以確定健康分數在所有用戶中的排序,以便用戶可以根據自己的健康排序確定自己的健康狀態,使得數據的參考價值更高,優化數據對用戶的健康指導效果;并且還可以通過用戶本身的歷史數據確定用戶的健康狀態變化情況,進而使得用戶了解自己的健康數據的動態變化情況,優化數據對用戶的健康指導效果。
對應于上述的健康數據處理方法,本申請還提出了圖5所示的根據本申請的一示例性實施例的服務器集群中每臺服務器的示意結構圖。請參考圖5,在硬件層面,該可穿戴設備包括處理器、內部總線、網絡接口、內存以及非易失性存儲器,當然還可能包括其他業務所需要的硬件。處理器從非易失性存儲器中讀取對應的計算機程序到內存中然后運行,在邏輯層面上形成運動軌跡數據的處理的裝置。當然,除了軟件實現方式之外,本申請并不排除其他實現方式,比如邏輯器件抑或軟硬件結合的方式等等,也就是說以下處理流程的執行主體并不限定于各個邏輯單元,也可以是硬件或邏輯器件。
圖6為根據本發明的一示例性實施例的健康數據處理裝置的框圖;如圖6所示,該健康數據處理裝置可以包括:第一接收模塊61、組合確定模塊62、指標排序模塊63。其中:
第一接收模塊61,用于接收可穿戴設備在預設時間周期內采集的用戶數據,用戶數據包括用戶基本信息和健康衡量數據;
組合確定模塊62,用于根據第一接收模塊61接收到的用戶基本信息,確定健康衡量數據對應的維度組合;
指標排序模塊63,用于基于組合確定模塊62確定的維度組合對應的分布模型和第一接收模塊61接收到的健康衡量數據,確定用戶在預設時間周期內的健康衡量數據在維度組合中的排序。
圖7示出了根據本發明的又一示例性實施例的健康數據處理裝置的框圖;如圖7所示,在上述圖6所示實施例的基礎上,在一實施例中,指標排序模塊63包括:
第一排序單元631,用于基于維度組合中每一項指標對應的指標分布模型和接收模塊接收到的健康衡量數據中對應的指標數據,確定健康衡量數據中每一項指標數據在對應的指標分布模型中的排序;
第二排序單元632,用于將第一排序單元631確定的每一項指標數據在對應的指標分布模型中的排序進行權重加和,得到用戶在預設時間周期內的健康衡量數據在維度組合中的排序。
在一實施例中,裝置還包括:
第一統計模塊64,用于統計在第一設定時間段內接收到的健康衡量數據,健康衡量數據包括多項指標數據;
分組模塊65,用于對第一統計模塊64統計到的健康衡量數據按照維度組合進行分組;
指標模型確定模塊66,用于基于分組模塊65分組得到的每一個維度組合和對應維度組合中的健康衡量數據的每一項指標數據,確定每一個維度組合中每一項指標的指標分布模型。
在一實施例中,指標模型確定模塊66包括:
分桶單元661,用于將每一個維度組合中的健康衡量數據的每一項指標數據進行分桶;
分桶值計算單元662,用于計算分桶單元661分桶得到的每一個分桶中指標數據的個數,得到對應分桶的分桶值;
歸一化單元663,用于將分桶值計算單元662計算得到的每一個維度組合中每一項指標數據的所有分桶值按照指標數據從小到大的順序進行累加和歸一化處理,得到每一個維度組合中每一項指標的指標分布模型。
在一實施例中,裝置還包括:
第二統計模塊67,用于統計在第二設定時間段內接收到的健康衡量數據;
模型更新模塊68,用于基于第二統計模塊67統計得到的在第二設定時間段內接收到的健康衡量數據,對每一個維度組合中每一項指標的指標分布模型進行更新。
圖8為根據本發明的一示例性實施例的健康數據處理裝置的框圖;如圖8所示,該健康數據處理裝置可以包括:第二接收模塊81、分數計算模塊82、分數排序模塊83。其中:
第二接收模塊81,用于接收可穿戴設備在預設時間周期內采集的用戶數據,用戶數據包括健康衡量數據;
分數計算模塊82,用于基于分數計算模型和第二接收模塊81接收到的健康衡量數據,確定用戶在預設時間周期內的健康衡量數據對應的健康分數;
分數排序模塊83,用于基于分數分布模型和分數計算模塊82確定的用戶在預設時間周期內的健康衡量數據對應的健康分數,確定用戶在預設時間周期內的健康衡量數據對應的健康分數的排序。
圖9示出了根據本發明的又一示例性實施例的健康數據處理裝置的框圖;如圖9所示,在上述圖8所示實施例的基礎上,在一實施例中,分數計算模塊82包括:
計算單元821,用于通過健康衡量數據中每一項指標對應的指標分數計算模型計算每一項指標數據的指標分數;
權重加和單元822,用于將計算單元821計算得到的每一項指標數據的指標分數進行權重加和,得到健康衡量數據對應的健康分數。
在一實施例中,裝置還包括:
歷史分數融合模塊84,用于將用戶在當前預設時間周期內的健康衡量數據對應的健康分數以及歷史的健康分數進行權重加和,得到用戶當前的健康分數;
分數變化確定模塊85,用于基于歷史分數融合模塊84得到的用戶當前的健康分數以及歷史的健康分數,確定用戶的分數變化狀態;
身體變化確定模塊86,用于根據分數變化確定模塊85確定的分數變化狀態,確定用戶的身體變化狀態。
上述實施例可見,本申請可以對可穿戴設備獲得的健康衡量數據按照維度組合進行分析,并確定出用戶的健康衡量數據在對應的維度組合中的排序,以便在用戶可以根據自己在相似人群中的健康排序確定自己的健康狀態,使得數據的參考價值更高,優化數據對用戶的健康指導效果;此外,本申請還可以對可穿戴設備獲得的健康衡量數據進行分數計算,并確定出用戶的分數排名,以便用戶可以根據的得分確定自己的健康狀態。
本領域技術人員在考慮說明書及實踐這里公開的發明后,將容易想到本申請的其它實施方案。本申請旨在涵蓋本申請的任何變型、用途或者適應性變化,這些變型、用途或者適應性變化遵循本申請的一般性原理并包括本申請未公開的本技術領域中的公知常識或慣用技術手段。說明書和實施例僅被視為示例性的,本申請的真正范圍和精神由下面的權利要求指出。
還需要說明的是,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、商品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、商品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括要素的過程、方法、商品或者設備中還存在另外的相同要素。
以上僅為本申請的較佳實施例而已,并不用以限制本申請,凡在本申請的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本申請保護的范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!