一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取方法及系統與流程
本發明涉及特征工程技術領域,尤其涉及一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取方法及系統。
背景技術:
乳腺癌是世界各地女性最為常見的一種惡性腫瘤,每年約40萬人死于該病。中國是乳腺癌發病率增長最快的國家之一,尤其近年來乳腺癌已經成為我國女性發病率排名第一位的惡性腫瘤。早期乳腺癌的治療效果好,能在很大程度上挽救患者的生命,因此提高乳腺癌的早期診斷的精度和準確性變得越來越有意義。
目前,乳腺癌臨床診斷主要應用乳腺超聲、鉬靶等影像檢查,診斷者通過腫塊、鈣化、血流信號等影像特征來對圖像進行分析。乳腺超聲檢查已廣泛應用于我國的臨床工作中,其具有操作方便,無放射性、無創傷、對腫塊定位準確以及經濟適用等優點。但是超聲檢查仍存在著許多不足,如早期乳腺癌的圖像常不典型難以分辨,特別是由于診斷者視覺感知的差異,視覺疲勞,不同的特征和診斷標準的使用,缺乏圖像特征的定量度量,導致了不同醫生診斷結果的不同,使得早期乳腺癌的誤診和漏診仍時常發生。
隨著醫學影像技術和計算機技術的不斷發展,利用計算機進行輔助診斷提高診斷的準確性成為可能;比如:利用數字圖像處理技術,提取乳腺超聲圖像中病理相關的的特征,運用SVM等機器學習方法根據這些特征對乳腺腫塊良惡性進行分類識別等。
從計算機輔助診斷乳腺癌的應用現狀來看,計算機輔助診斷的準確度很大程度取決于提取到B超圖像病理相關特征是否有效。目前,用于計算機輔助診斷的醫學圖像特征提取基本上采用手工定位病灶感興趣區域,并通過基本圖像處理的方法提取的一些基礎的常規特征,如:灰度直方圖特征、形狀特征、灰度共生矩陣特征、小波特征等。但上述方法有以下幾個方面的不足:第一、上述基礎常規特征的逐一提取耗時費力;第二、上述單個基礎常規特征本身并非領域相關,和乳腺癌的特定應用關聯度不大;第三、設計有效的可用于計算機輔助診斷乳腺癌的基礎常規特征組合具有嚴重的不確定性。存在上述局限性的本質原因是特征篩選后的特征仍然是醫學圖像的低層特征,與醫學圖像整體上的病理語義高層特征間并無直接的映射關系,因此,最好的解決機制是提供一種可以根據以往乳腺癌B超圖像自動學習出與病理有關且可用于輔助診斷的圖像特征的方法。
技術實現要素:
為此,需要提供一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取方案,解決如何根據以往乳腺癌B超圖像自動學習出與病理有關且可用于輔助診斷的圖像特征的問題。
為實現上述目的,發明人提供了一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取方法,包括以下步驟:
步驟S1:給定一個中等規模以上的乳腺超聲病灶區域圖像集,所述中等規模表示該圖像集至少含有200幅以上的乳腺超聲診斷圖像;
步驟S2:手動提取步驟S1中圖像集里每一張乳腺超聲診斷圖像的病灶區域圖像ROI;
步驟S3:從每一張乳腺超聲病灶區域圖像ROI中提取手工淺層特征作為一個訓練樣本,構成訓練樣本集set_unlabeled={x(1),x(2),…,x(n)},第i個樣本x(i)∈[0,1]d,i=1,2,…,n;其中d表示樣本的特征維度,n表示訓練集樣本個數;
步驟S4:基于訓練樣本集,訓練第一個降噪自編碼器DAE1;
步驟S5:訓練完第一個降噪自編碼器后,重新輸入訓練樣本集,根據步驟S4訓練好的編碼器提取所有樣本的隱層學習得到的特征表示,構成新的樣本{y(1),y(2),…,y(n)},將其作為第二個降噪自編碼器的輸入,訓練第二個降噪自編碼器DAE2;
步驟S6:將完成訓練的兩個降噪自編碼器DAE1和DAE2堆疊得到三層的SDAE結構,對應第一層為輸入層,維度為d;第二層為DAE1中的隱層,維度為dh1;第三層為DAE2中對應的隱層,維度為dh2;通過該SDAE結構,給定乳腺鉬靶圖像的手工淺層特征,前向反饋后得到基于堆疊降噪自編碼器的高層抽象的語義特征表示
進一步地,所述步驟S3為:分別提取每個ROI圖像的GLCM、小波、小波包、MPEG-7四種手工淺層特征,級聯為一個d維的特征向量作為一個樣本。
進一步地,所述步驟S4中,第一個降噪自編碼器由三層網絡構成,對應輸入層x、隱層y、輸出層z的神經元個數分別為d、dh1、d,其中輸入層的輸入為訓練樣本集中的某個樣本x(i)∈[0,1]d,i=1,2,…,n;輸入層人為地引入了噪聲;參數θ1={W1,b1},θ2={W2,b2},b1、b2為分別為隱層和輸出層的偏置向量,大小分別為dh1和d維,W1、W2分別為輸入層到隱層的權值連接矩陣和隱層到輸出層的權值連接矩陣,大小分別為d×dh1、dh1×d;激活函數均采用sigmoid函數;
步驟S4包括以下步驟:
步驟S41:對訓練樣本集進行分割,具體步驟為:將超聲圖像的訓練樣本集隨機分割為num個batch,每個batchi∈[0,1]batch_size×d,i=1,2,…,num;
步驟S42:網絡參數初始化;具體設置為:
learningrate=1;
b1=0,b2=0;
其中,leanningrate表示學習率,rand(m,n)函數為隨機生成[0,1]的m×n階矩陣;
步驟43:設置最大循環次數NN;
步驟44:外重循環t=1 to NN;
內重循環s=1 to num;
步驟441:腐蝕數據:通過二進制掩蔽噪聲方式,以一定概率將輸入特征向量x中某些值隨機地重設為0;具體為:
batchs=batchs×(rand(batch_size,d)>threashold),一個batchs構成batch_size×d階矩陣,threashold為設定的閾值,具體設定為0.2;如果隨機生成的矩陣A=rand(batch_size,d)中的元素Aij小于threashold,則矩陣batchs中對應位置的元素重設為0;定義batchs中第i個樣本為x(i),腐蝕后為
步驟442:前向反饋:
z(i)=sigmoid(W2Ty(i)+b2),i=1,2,…,batch_size;
步驟443:反向傳輸:
步驟444:更新參數
其中,分別表示第i個樣本對應輸出層和隱層第j個節點的殘差。
本發明提供一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取系統,包括以下模塊:
圖像集給定模塊:用于給定一個中等規模以上的乳腺超聲病灶區域圖像集,所述中等規模表示該圖像集至少含有200幅以上的乳腺超聲診斷圖像;
病灶區域提取模塊:用于手動提取步驟S1中圖像集里每一張乳腺超聲診斷圖像的病灶區域圖像ROI;
樣本訓練模塊:用于從每一張乳腺超聲病灶區域圖像ROI中提取手工淺層特征作為一個訓練樣本,構成訓練樣本集set_unlabeled={x(1),x(2),…,x(n)},第i個樣本x(i)∈[0,1]d,i=1,2,…,n;其中d表示樣本的特征維度,n表示訓練集樣本個數;
第一編碼器訓練模塊:用于基于訓練樣本集,訓練第一個降噪自編碼器DAE1;
第二編碼器訓練模塊:用于訓練完第一個降噪自編碼器后,重新輸入訓練樣本集,根據步驟S4訓練好的編碼器提取所有樣本的隱層學習得到的特征表示,構成新的樣本{y(1),y(2),…,y(n)},將其作為第二個降噪自編碼器的輸入,訓練第二個降噪自編碼器DAE2;
語義特征生成模塊:用于將完成訓練的兩個降噪自編碼器DAE1和DAE2堆疊得到三層的SDAE結構,對應第一層為輸入層,維度為d;第二層為DAE1中的隱層,維度為dh1;第三層為DAE2中對應的隱層,維度為dh2;通過該SDAE結構,給定乳腺鉬靶圖像的手工淺層特征,前向反饋后得到基于堆疊降噪自編碼器的高層抽象的語義特征表示
進一步地,所述樣本訓練模塊:還用于分別提取每個ROI圖像的GLCM、小波、小波包、MPEG-7四種手工淺層特征,級聯為一個d維的特征向量作為一個樣本。
進一步地,所述第一編碼器訓練模塊中,第一個降噪自編碼器由三層網絡構成,對應輸入層x、隱層y、輸出層z的神經元個數分別為d、dh1、d,其中輸入層的輸入為訓練樣本集中的某個樣本x(i)∈[0,1]d,i=1,2,…,n;輸入層人為地引入了噪聲;參數θ1={W1,b1},θ2={W2,b2},b1、b2為分別為隱層和輸出層的偏置向量,大小分別為dh1和d維,W1、W2分別為輸入層到隱層的權值連接矩陣和隱層到輸出層的權值連接矩陣,大小分別為d×dh1、dh1×d;激活函數均采用sigmoid函數;
第一編碼器訓練模塊包括以下單元:
樣本分割單元:用于對訓練樣本集進行分割,具體步驟為:將超聲圖像的訓練樣本集隨機分割為num個batch,每個batchi∈[0,1]batch_size×d,i=1,2,…,num;
網絡參數初始化單元:用于網絡參數初始化;具體設置為:
learningrate=1;
b1=0,b2=0;
其中,leanningrate表示學習率,rand(m,n)函數為隨機生成[0,1]的m×n階矩陣;
循環次數設置單元:用于設置最大循環次數NN;
內外重循環設置單元:用于設置外重循環t=1 to NN;
用于設置內重循環s=1 to num;
腐蝕數據單元:用于腐蝕數據:通過二進制掩蔽噪聲方式,以一定概率將輸入特征向量x中某些值隨機地重設為0;具體為:
batchs=batchs×(rand(batch_size,d)>threashold),一個batchs構成batch_size×d階矩陣,threashold為設定的閾值,具體設定為0.2;如果隨機生成的矩陣A=rand(batch_size,d)中的元素Aij小于threashold,則矩陣batchs中對應位置的元素重設為0;定義batchs中第i個樣本為x(i),腐蝕后為
前向反饋單元:用于前向反饋:
z(i)=sigmoid(W2Ty(i)+b2),i=1,2,…,batch_size;
反向傳輸單元:用于反向傳輸:
更新參數單元:用于更新參數
其中,分別表示第i個樣本對應輸出層和隱層第j個節點的殘差。
區別于現有技術,上述技術方案基于中等規模的腺鉬靶病灶區域圖像,訓練得到兩個自編碼器,并根據兩個自編碼器得到SDAE結構,并最終得到語義特征,實現了乳腺超聲圖像特征的提取,從而為臨床診斷提供有價值的“參考意見”,提高乳腺癌診斷的準確率和效率。
附圖說明
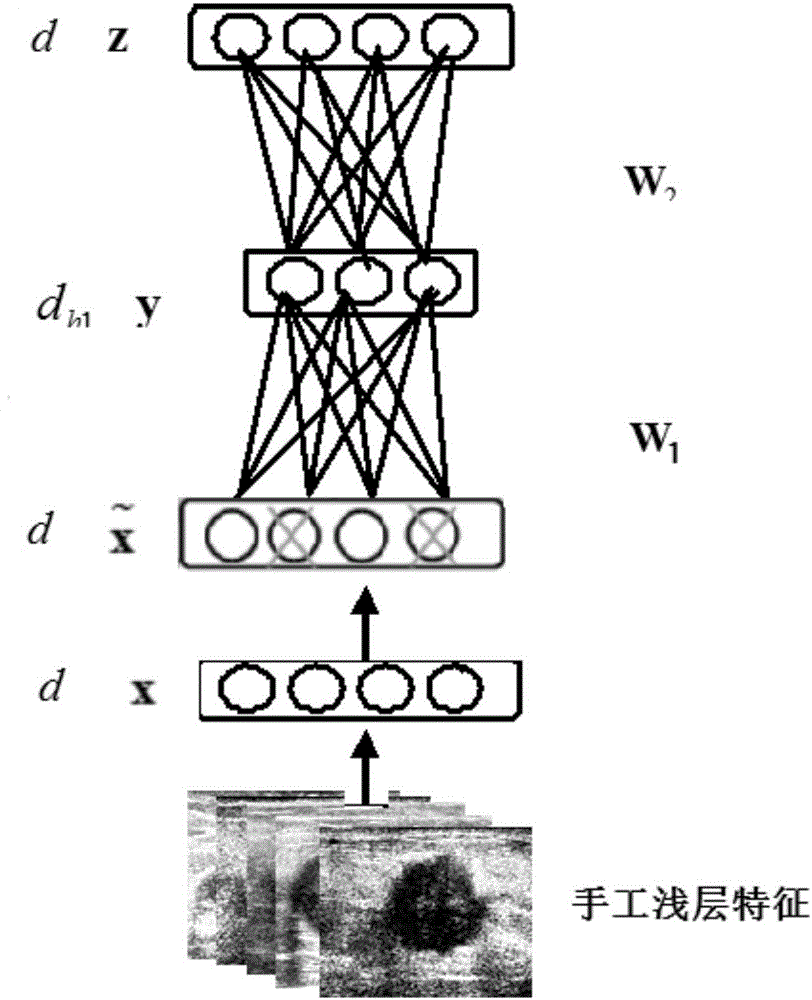
圖1為本發明實施例中乳腺超聲圖像特征深度學習的單個降噪自編碼器訓練過程;
圖2為本發明實施例中堆疊降噪自編碼器訓練過程。
具體實施方式
為詳細說明技術方案的技術內容、構造特征、所實現目的及效果,以下結合具體實施例并配合附圖詳予說明。
請參閱圖1到圖2,本實施例本實施例提供了一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取方法,具體如下:
步驟S1:給定一個中等規模以上的乳腺超聲病灶區域圖像集,所述中等規模表示該圖像集至少含有200幅以上的乳腺鉬靶診斷圖像;
步驟S2:手動提取步驟S1中圖像集里每一張乳腺超聲診斷圖像的乳腺鉬靶病灶區域圖像ROI(Region of interest,感興趣區域);其中所述乳腺超聲病灶區域圖像ROI的大小為150×150;
步驟S3:從每一張乳腺超聲病灶區域圖像ROI中提取手工淺層特征作為一個訓練樣本,構成訓練樣本集set_unlabeled={x(1),x(2),…,x(n)},第i個樣本x(i)∈[0,1]d,i=1,2,…,n。其中d表示樣本的特征維度,n表示訓練集樣本個數。
步驟S4:基于訓練樣本集,訓練第一個降噪自編碼器DAE1,其中DAE為Denoising Autoencoder,降噪自編碼器。
步驟S5:訓練完第一個降噪自編碼器后,重新輸入set_unlabeled樣本即訓練樣本集,根據步驟S4訓練好的模型DAE1提取所有樣本的隱層學習得到的特征表示,構成新的樣本{y(1),y(2),…,y(n)},將其作為第二個降噪自編碼器的輸入,訓練第二個降噪自編碼器DAE2。
步驟S6:將完成訓練的兩個降噪自編碼器(DAE1、DAE2)堆疊得到三層的SDAE(stacked Denoising Autoencoder)結構,如圖2所示。對應第一層為輸入層,維度為d;第二層為DAE1中的隱層,維度為dh1;第三層為DAE2中對應的隱層,維度為dh2。通過該模型,給定乳腺超聲圖像的手工淺層特征,前向反饋后即可以得到基于堆疊降噪自編碼器的高層抽象的語義特征表示這樣得到語義特征,實現了乳腺超聲圖像特征的提取,從而為臨床診斷提供有價值的“參考意見”,提高乳腺癌診斷的準確率和效率。
進一步地,所述步驟S3為:分別提取每個ROI圖像的GLCM((灰度共生矩陣,Gray-level co-occurrence matrix)、小波、小波包、MPEG-7(Moving Picture Experts Group,動態圖像專家組)四種手工淺層特征,級聯為一個d維的特征向量作為一個樣本。考慮到某些特征屬性實際最大值和最小值是未知的,并且存在離群點的可能性,首先采取z-score的規范化方法,規范化公式如下:
其中x表示某一維度特征的觀測值,mean為該維度特征觀測值的均值,std為該維度特征觀測值的標準差,x'為x進行z-score規范后的結果。考慮到訓練自編碼過程中神經元是以概率形式存在,繼續進行Min-Max規范化到[0,1]區間。規范化公式如下:
其中x'表示某一維度特征的觀測值,min為該維度特征觀測值的最小值,max為該維度特征觀測值的最大值,x”為x'進行Min-Max規范后的結果。
在步驟S3中,其重點在于其中的級聯,一般來說,GLCM、小波、小波包、MPEG-7這四種淺層特征都只提取了圖像的部分物理特征,不夠全面,為了保證后續可以從全面的物理特征中學習出更好的高層特征,將這四種不同的淺層特征級聯在一起做為后續工作的學習基礎,以最大程度地包含ROI圖像的物理信息。
進一步地,所述步驟S4為:如圖1所示,整個降噪自編碼器由三層網絡構成,對應輸入層x、隱層y、輸出層z的神經元個數分別為d、dh1、d,其中輸入層的輸入為訓練集set_unlabeled中的某個樣本x(i)∈[0,1]d,i=1,2,…,n。輸入層人為地引入了噪聲。參數θ1={W1,b1},θ2={W2,b2},b1、b2為分別為隱層和輸出層的偏置向量,大小分別為dh1和d維,W1、W2分別為輸入層到隱層的權值連接矩陣和隱層到輸出層的權值連接矩陣,大小分別為d×dh1、dh1×d。激活函數均采用sigmoid函數。
具體包括以下步驟:
步驟S41:對訓練樣本集進行分割,具體步驟為:將超聲圖像的訓練樣本集set_unlabeled隨機分割為num個batch(塊),每個batchi∈[0,1]batch_size×d,i=1,2,…,num;
步驟S42:網絡參數初始化;具體設置為:
learningrate=1;
b1=0,b2=0;
其中,leanningrate表示學習率,rand(m,n)函數為隨機生成[0,1]的m×n階矩陣;
步驟43:設置最大循環次數NN;
步驟44:外重循環t=1 to NN;
內重循環s=1 to num;
步驟441:腐蝕數據:通過二進制掩蔽噪聲方式,以一定概率將輸入特征向量x中某些值隨機地重設為0;具體為:
batchs=batchs×(rand(batch_size,d)>threashold),一個batchs構成batch_size×d階矩陣,threashold為設定的閾值,具體設定為0.2;如果隨機生成的矩陣A=rand(batch_size,d)中的元素Aij小于threashold,則矩陣batchs中對應位置的元素重設為0;定義batchs中第i個樣本為x(i),腐蝕后為
步驟442:前向反饋:
z(i)=sigmoid(W2Ty(i)+b2),i=1,2,…,batch_size;
步驟443:反向傳輸:
步驟444:更新參數
其中,分別表示第i個樣本對應輸出層和隱層第j個節點的殘差。本實施例的好處在于,傳統的GLCM、小波、小波包、MPEG-7這些淺層特征其實都只是常規的圖像物理特征,和超聲圖像做為醫學圖像來進行輔助診斷時候需要的病理特征并沒有直接關聯,所以用GLCM、小波、小波包、MPEG-7這些淺層特征做為超聲圖像病理上的描述表征具有不可靠性。而通過學習器學習所得的特征比物理特征更高一層,更加接近圖像的語義特征,與超聲圖像的病理關聯度更大,更加適合做為超聲圖像病理上的描述表征。
本發明提供一種基于堆疊降噪自編碼器的乳腺超聲圖像特征自學習提取系統,包括以下模塊:
圖像集給定模塊:用于給定一個中等規模以上的乳腺超聲病灶區域圖像集,所述中等規模表示該圖像集至少含有200幅以上的乳腺超聲診斷圖像;
病灶區域提取模塊:用于手動提取步驟S1中圖像集里每一張乳腺超聲診斷圖像的病灶區域圖像ROI;
樣本訓練模塊:用于從每一張乳腺超聲病灶區域圖像ROI中提取手工淺層特征作為一個訓練樣本,構成訓練樣本集set_unlabeled={x(1),x(2),…,x(n)},第i個樣本x(i)∈[0,1]d,i=1,2,…,n;其中d表示樣本的特征維度,n表示訓練集樣本個數;
第一編碼器訓練模塊:用于基于訓練樣本集,訓練第一個降噪自編碼器DAE1;
第二編碼器訓練模塊:用于訓練完第一個降噪自編碼器后,重新輸入訓練樣本集,根據步驟S4訓練好的編碼器提取所有樣本的隱層學習得到的特征表示,構成新的樣本{y(1),y(2),…,y(n)},將其作為第二個降噪自編碼器的輸入,訓練第二個降噪自編碼器DAE2;
語義特征生成模塊:用于將完成訓練的兩個降噪自編碼器DAE1和DAE2堆疊得到三層的SDAE結構,對應第一層為輸入層,維度為d;第二層為DAE1中的隱層,維度為dh1;第三層為DAE2中對應的隱層,維度為dh2;通過該SDAE結構,給定乳腺鉬靶圖像的手工淺層特征,前向反饋后得到基于堆疊降噪自編碼器的高層抽象的語義特征表示這樣得到語義特征,實現了乳腺超聲圖像特征的提取,從而為臨床診斷提供有價值的“參考意見”,提高乳腺癌診斷的準確率和效率。
進一步地,所述樣本訓練模塊:還用于分別提取每個ROI圖像的GLCM、小波、小波包、MPEG-7四種手工淺層特征,級聯為一個d維的特征向量作為一個樣本。樣本訓練模塊重點在于其中的級聯,一般來說,GLCM、小波、小波包、MPEG-7這四種淺層特征都只提取了圖像的部分物理特征,不夠全面,為了保證后續可以從全面的物理特征中學習出更好的高層特征,將這四種不同的淺層特征級聯在一起做為后續工作的學習基礎,以最大程度地包含ROI圖像的物理信息。
進一步地,所述第一編碼器訓練模塊中,第一個降噪自編碼器由三層網絡構成,對應輸入層x、隱層y、輸出層z的神經元個數分別為d、dh1、d,其中輸入層的輸入為訓練樣本集中的某個樣本x(i)∈[0,1]d,i=1,2,…,n;輸入層人為地引入了噪聲;參數θ1={W1,b1},θ2={W2,b2},b1、b2為分別為隱層和輸出層的偏置向量,大小分別為dh1和d維,W1、W2分別為輸入層到隱層的權值連接矩陣和隱層到輸出層的權值連接矩陣,大小分別為d×dh1、dh1×d;激活函數均采用sigmoid函數;
第一編碼器訓練模塊包括以下單元:
樣本分割單元:用于對訓練樣本集進行分割,具體步驟為:將超聲圖像的訓練樣本集隨機分割為num個batch,每個batchi∈[0,1]batch_size×d,i=1,2,…,num;
網絡參數初始化單元:用于網絡參數初始化;具體設置為:
learningrate=1;
b1=0,b2=0;
其中,leanningrate表示學習率,rand(m,n)函數為隨機生成[0,1]的m×n階矩陣;
循環次數設置單元:用于設置最大循環次數NN;
內外重循環設置單元:用于設置外重循環t=1 to NN;
用于設置內重循環s=1 to num;
腐蝕數據單元:用于腐蝕數據:通過二進制掩蔽噪聲方式,以一定概率將輸入特征向量x中某些值隨機地重設為0;具體為:
batchs=batchs×(rand(batch_size,d)>threashold),一個batchs構成batch_size×d階矩陣,threashold為設定的閾值,具體設定為0.2;如果隨機生成的矩陣A=rand(batch_size,d)中的元素Aij小于threashold,則矩陣batchs中對應位置的元素重設為0;定義batchs中第i個樣本為x(i),腐蝕后為
前向反饋單元:用于前向反饋:
z(i)=sigmoid(W2Ty(i)+b2),i=1,2,…,batch_size;
反向傳輸單元:用于反向傳輸:
更新參數單元:用于更新參數
其中,分別表示第i個樣本對應輸出層和隱層第j個節點的殘差。本實施例的好處在于,傳統的GLCM、小波、小波包、MPEG-7這些淺層特征其實都只是常規的圖像物理特征,和超聲圖像做為醫學圖像來進行輔助診斷時候需要的病理特征并沒有直接關聯,所以用GLCM、小波、小波包、MPEG-7這些淺層特征做為超聲圖像病理上的描述表征具有不可靠性。而通過學習器學習所得的特征比物理特征更高一層,更加接近圖像的語義特征,與超聲圖像的病理關聯度更大,更加適合做為超聲圖像病理上的描述表征。
需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者終端設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者終端設備所固有的要素。在沒有更多限制的情況下,由語句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者終端設備中還存在另外的要素。此外,在本文中,“大于”、“小于”、“超過”等理解為不包括本數;“以上”、“以下”、“以內”等理解為包括本數。
本領域內的技術人員應明白,上述各實施例可提供為方法、裝置、或計算機程序產品。這些實施例可采用完全硬件實施例、完全軟件實施例、或結合軟件和硬件方面的實施例的形式。上述各實施例涉及的方法中的全部或部分步驟可以通過程序來指令相關的硬件來完成,所述的程序可以存儲于計算機設備可讀取的存儲介質中,用于執行上述各實施例方法所述的全部或部分步驟。所述計算機設備,包括但不限于:個人計算機、服務器、通用計算機、專用計算機、網絡設備、嵌入式設備、可編程設備、智能移動終端、智能家居設備、穿戴式智能設備、車載智能設備等;所述的存儲介質,包括但不限于:RAM、ROM、磁碟、磁帶、光盤、閃存、U盤、移動硬盤、存儲卡、記憶棒、網絡服務器存儲、網絡云存儲等。
上述各實施例是參照根據實施例所述的方法、設備(系統)、和計算機程序產品的流程圖和/或方框圖來描述的。應理解可由計算機程序指令實現流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框圖中的流程和/或方框的結合。可提供這些計算機程序指令到計算機設備的處理器以產生一個機器,使得通過計算機設備的處理器執行的指令產生用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。
這些計算機程序指令也可存儲在能引導計算機設備以特定方式工作的計算機設備可讀存儲器中,使得存儲在該計算機設備可讀存儲器中的指令產生包括指令裝置的制造品,該指令裝置實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。
這些計算機程序指令也可裝載到計算機設備上,使得在計算機設備上執行一系列操作步驟以產生計算機實現的處理,從而在計算機設備上執行的指令提供用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。
盡管已經對上述各實施例進行了描述,但本領域內的技術人員一旦得知了基本創造性概念,則可對這些實施例做出另外的變更和修改,所以以上所述僅為本發明的實施例,并非因此限制本發明的專利保護范圍,凡是利用本發明說明書及附圖內容所作的等效結構或等效流程變換,或直接或間接運用在其他相關的技術領域,均同理包括在本發明的專利保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!