一種改進的中文自動分詞算法的制作方法
本發明涉及中文語義網絡技術領域,具體涉及一種改進的中文自動分詞算法。
背景技術:
自上世紀八十年代初,中文信息處理領域提出中文自動分詞課題以來,就一直吸引著來自計算機界、數學界、信息檢索界、語言界的,無數的專家和學者。他們經過幾十年的不懈努力和艱苦探索,已經取得了一些重要的進展和實用性的成果。可以把這些方法概括的分為三大類。第一,基于詞典的中文分詞方法,其過程簡單、易于理解,但也對多義詞、歧義詞和嵌套詞的切分效果不太理想。第二,基于統計的中文分詞方法,該類方法,通過選取合適的數學統計模型,依靠大量的語料來對其進行訓練,待模型穩定以后,再利用訓練好的模型實現漢字串的自動分詞。最后,基于理解的中文分詞方法,基于理解的分詞方法就是借助于人工智能中的相關技術,將事先已經提取好的關于漢語構詞的一些規則和知識加入到推理過程中,利用這些規則和知識結合不同的推理機制,實現最終的中文分詞,目前為止基于理解的分詞系統還處在試驗階段。
中文自動文詞指的是將一個漢字序列按照其出現的上下文中的實際意義,有機的切分成一個個獨立的詞過程。它是計算機能夠自動理解中文語義的基礎,是中文信息處理中最重要的預處理技術。在中文里面,計算機不容易明白“她喜歡吃水果”中的“水果”是一個詞。只有當自然語言中無意義的漢字串,被正確轉化為有意義的詞之后,計算機才能正確理解自然語言,進而進行下一步工作。為提高中文自動分詞的準確性,本發明提供了一種改進的中文自動分詞算法。
技術實現要素:
針對中文自動分詞的準確性不高問題,本發明提供了一種改進的中文自動分詞算法。
為了解決上述問題,本發明是通過以下技術方案實現的:
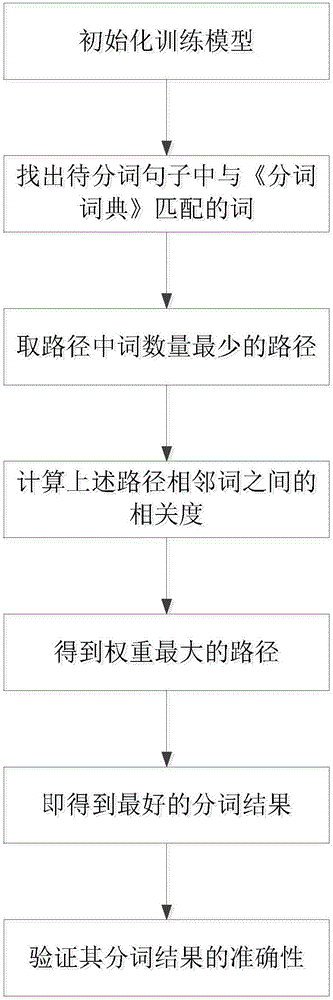
步驟1:初始化訓練模型,可以是《分詞詞典》或相關領域的語料庫,或是兩者結合模型。
步驟2:根據《分詞詞典》找到待分詞句子中與詞典中匹配的詞。
步驟3:依據概率統計學,將待分詞句子拆分為網狀結構,即得n個可能組合的句子結構,把此結構每條順序節點依次規定為SM1M2M3M4M5E。
步驟4:利用統計學概念理論知識,給上述網狀結構每條邊賦予一定的權值。
步驟5:找到權值最大的一條路徑,即為待分詞句子的分詞結果。
步驟6:驗證此分詞結果的準確率和召回率。
本發明的有益效果是:
1、中文預處理的速度較基于分詞詞典的方法快。
2、此方法較基于分詞詞典的方法有更好的精度。
3、此方法較基于統計學方法有更好的準確度。
4、此方法實用性更大,更符合經驗值。
5、此方法為后續自然語言處理技術提供了極大地應用價值。
附圖說明
圖1為一種改進的中文自動分詞算法結構流程圖。
圖2為n元語法分詞算法圖解。
具體實施方式
本發明提出了一種改進的中文自動分詞算法。
為了提高中文自動分詞的準確性,結合圖1-圖2對本發明進行了詳細說明,其具體實施步驟如下:
步驟1:初始化訓練模型,可以是《分詞詞典》或相關領域的語料庫,或是兩者結合模型。
步驟2:根據《分詞詞典》找到待分詞句子中與詞典中匹配的詞,其具體描述如下:
把待分詞的漢字串完整的掃描一遍,在系統的詞典里進行查找匹配,遇到字典里有的詞就標識出來;如果詞典中不存在相關匹配,就簡單地分割出單字作為詞;直到漢字串為空。
步驟3:依據概率統計學,將待分詞句子拆分為網狀結構,即得n個可能組合的句子結構,把此結構每條順序節點依次規定為SM1M2M3M4M5E,其結構圖如圖2所示。
步驟4:利用統計學概念理論知識,給上述網狀結構每條邊賦予一定的權值,其具體計算過程如下:
步驟4.1)取路徑中詞的數量最少min()
根據《分詞詞典》匹配出的字典詞與未匹配的單個詞,第i條路徑包含詞的個數為ni。即n條路徑詞的個數集合為(n1,n2,…,nn)。
得min()=min(n1,n2,…,nn)
步驟4.2)計算相鄰兩個詞(C1,C2)相關度RE(C1,C2)
將兩個詞(C1,C2)映射到概念模型中,得到相應的概念(g1,g2),即概念(g1,g2)的相關度RE(g1,g2)即為相鄰兩個詞(C1,C2)相關度。
RE(C1,C2)=RE(g1,g2)
這里考慮了本體間的基本屬性關系、路徑距離與路徑數量、密度與深度等影響因子計算兩本體概念(g1,g2)間的相關度。
步驟4.2.1)構造基于基本屬性關系對兩本體概念(g1,g2)相似度的影響函數RE屬性(g1,g2)
兩本體概念(g1,g2)相似度與屬性相似度成正比,與屬性權重也成正比。
路徑為g1→J1→…→Jn→g2
假設g1、J1、…、Jn、g2的屬性個數各為
每個屬性對相應概念的影響權重是不同的,按照權重系數分別對概念屬性進行排序,對每個概念屬性取前i個屬性權重值。
這里
即得下列屬性權重矩陣(n+2)×i:
從專業領域本體樹中,可以很清楚的知道g1、J1、…、Jn概念中的共有屬性,記為(S1′,S2′,…,Sj′),這里j為共有屬性的個數,j≤i,且
為概念g1、J1、…、Jn、g2中屬性相同,則取出其對應權重值
所以構建的影響函數為:
步驟4.2.2)構造基于路徑距離、與路徑數量對兩本體概念(g1,g2)相似度的影響函數RE路徑(g1,g2)
兩本體概念(g1,g2)相似度與其路徑長度成反比,找到兩本體概念(g1,g2)間最長路徑,其中經過的概念節點有n個,即(J1→…→Jn)。
即經過路徑的長度為L(g1,g2)=n+2
兩本體概念(g1,g2)相似度與路徑數量成反比,即當路徑數量越多,兩本體概念(g1,g2)相似度越大,這里根據專業領域本體樹可知路徑數量為N,如下式。
即
上式r為路徑長度與路徑個數的權重比值,這個可以根據實驗迭代出來。
步驟4.2.3)構造密度與深度對兩本體概念(g1,g2)相似度的影響函數RED(g1,g2)
步驟4.2.3.1)兩本體概念(g1,g2)深度函數
概念節點的深度是指概念在所處的本體樹中的層次深度。在本體樹中,每個概念節點都是對上一層節點的一次細化。因此概念節點處于本體樹中層次越深,則表示的內容越具體,概念間的相似度越大。反之概念間的相似度越小。
這里深度值從根節點開始,根節點的深度值為1,從概念(g1、g2)與共同父節點構成的樹子集中找到同一層中兩本體概念(g1、g2)數量最多的,其對應的深度為h。
如果兩本體概念(g1、g2)不在同一層,則其平均,即有下式:
與分別為從概念(g1、g2)與共同父節點構成的樹子集中兩本體概念(g1、g2)數量最多的深度值。
步驟4.2.3.2)兩本體概念(g1、g2)密度函數
概率節點密度越大,則其直接子節點數目越多,節點細化的越具體,各直接子節點之間的相似度越大。
從概念(g1、g2)的直接子節點中找到共同直接子節點個數,如上為N。
步驟4.2.3.3)由上述步驟可得:
上式α、β分別為深度與密度的權重系數,α+β=1,α越大表示概念深度對相關度的影響越大,反之影響越小。β越大表示概念密度對相關度的影響越大,反之影響越小。γ為平滑因子,α、β、γ可以通過非線回歸迭代估計來確定。
綜上所述,有下式
RE(C1,C2)=RE(g1,g2)=ARE屬性(g1,g2)+BRE路徑(g1,g2)+CRED(g1,g2)
上式A、B、C為相應的影響系數,根據其值大小,影響相關度的程度也不一樣,值越大,對相關度影響也越大,A+B+C=1。
步驟5:找到權值最大的一條路徑,即為待分詞句子的分詞結果,其具體計算過程如下:
有n條路徑,每條路徑長度不一樣,假設路徑長度集合為(L1,L2,…,Ln)。
假設經過取路徑中詞的數量最少操作,排除了m條路徑,m<n。即剩下(n-m)路徑,設其路徑長度集合為
則每條路徑權重為:
上式分別為第1,2到路徑邊的權重值,根據步驟4可以一一計算得出,為剩下(n-m)路徑中第Si條路徑的長度。
權值最大的一條路徑:
步驟6:驗證此分詞結果的準確率和召回率。
準確率:
上式n識為《分詞詞典》識別待分詞句子中字典詞的個數,nz為此方法正確分詞詞的個數。
召回率:
上式n總為待分詞句子中詞的總個數。
最后綜合考慮這兩個因子,判定此系統分詞結果的正確性。
即d=|zhaorate-rate|≤ε
ε為一個很小的閾值,這個由專家給定。當d滿足上述條件,則分詞效果比較理想。
- 還沒有人留言評論。精彩留言會獲得點贊!