一種基于HOG和視覺詞袋的相似圖像搜索方法和裝置與流程
本發明涉及一種相似圖像搜索方法,尤其涉及一種基于HOG和視覺詞袋的相似圖像搜索方法和裝置。
背景技術:
互聯網的普及以及搜索引擎技術的巨大發展為人們的生活帶來了極大的便利,人們可以快速、準確地在互聯網上找到所需要的東西。
圖像搜索是一個新興的搜索模式,而互聯網上有約數以百億的圖像,并且每天都在以數百萬的速度增長,要快速有效地識別所搜索的圖像,其相關技術條件不是非常成熟,具有較好的發展空間。
方向梯度直方圖特征,簡稱HOG特征是通過計算和統計圖像局部區域的梯度方向直方圖來構成特征,HOG特征結合SVM分類器已經被廣泛應用于圖像識別中,尤其在行人檢測中獲得了極大的成功;詞袋模型已被應用到圖像處理領域,用來進行圖像分類,即通過將一幅圖像看成是由一系列視覺單詞組成的文章,實現圖像的高速分類,是一種有效的基于圖像語義特征提取與描述的圖像分類算法,但是,目前還未有一種將HOG特征提取和視覺詞袋模型結合在一起,來提高相似圖像搜索準確率的方法和裝置。
鑒于上述缺陷,本發明創作者經過長時間的研究和實踐終于獲得了本發明。
技術實現要素:
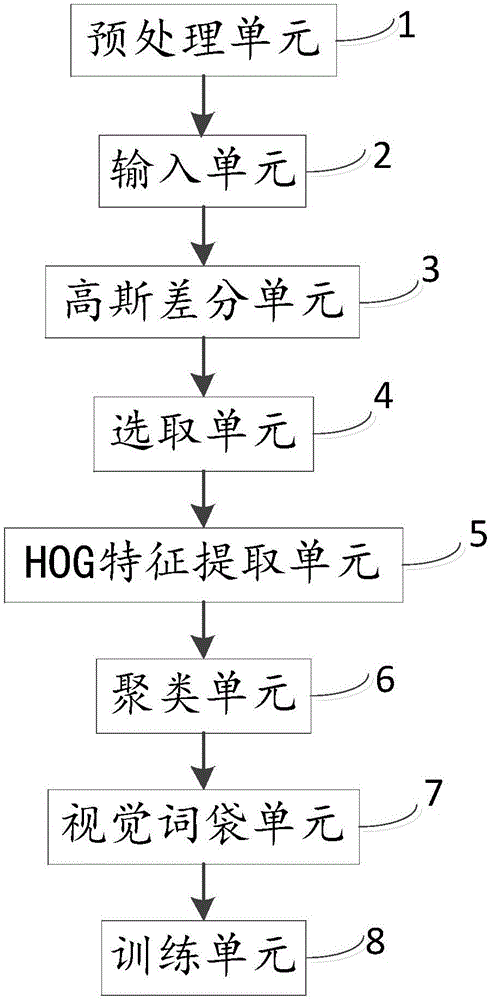
為解決上述問題,本發明采用的技術方案在于,一方面提供一種基于HOG和視覺詞袋的相似圖像搜索裝置,包括預處理單元、輸入單元、高斯差分單元、選取單元、HOG特征提取單元、聚類單元、視覺詞袋單元和訓練單元;
所述預處理單元,用于將訓練的圖像進行分類作為訓練集圖像,并對測試圖像和所述訓練集圖像的大小進行歸一化;
所述輸入單元,用于輸入歸一化后的所述測試圖像和所述訓練集圖像;
所述高斯差分單元,用于通過高斯差分算法尋找所述輸入單元中的所述測試圖像和所述訓練集圖像中每一幅圖像的穩定關鍵點;
所述選取單元,用于選取所述測試圖像和所述訓練集圖像中每一幅圖像的穩定關鍵點的最密集的前N個區域;
所述HOG特征提取單元,用于對所述最密集的前N個區域進行HOG特征提取;
所述聚類單元,用于通過K-Means聚類算法對所述訓練集圖像中的所述HOG特征進行聚類,得到的n個聚類中心為視覺詞袋的n個視覺單詞;
所述視覺詞袋單元,用于在所述訓練集圖像的視覺單詞中尋找與所述測試圖像中的每一個特征最近鄰的視覺單詞,并統計所述測試圖像中所找到的所有視覺單詞出現的頻率,得到的頻率直方圖為所述測試圖像的視覺詞袋;
所述訓練單元,用于使用支持向量機分類器對所述訓練集圖像的視覺詞袋進行訓練,得到的模型對所述測試圖像的視覺詞袋進行測試,得到所述測試圖像的分類結果,反饋同一類別的圖片。
進一步,所述高斯差分單元包括分層模塊、差分模塊、比較模塊、第一刪除模塊和第二刪除模塊;
所述分層模塊,用于對所述相應圖像f(x,y)加入高斯濾波Gσ1(x,y)、Gσ2(x,y),得到兩幅圖像g1(x,y)和g2(x,y):
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
所述差分模塊,用于將得到的兩幅圖像g1(x,y)、g2(x,y)進行相減,得到高斯差分圖像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
所述比較模塊,用于將高斯差分圖像中每一個像素點與其所有的相鄰點進行比較,若每一個所述像素點比其圖像域和尺度域中的相鄰點都大或都小,那該所述像素點則為極值點;
所述第一刪除模塊,用于去除對比度低的所述極值點,利用高斯差分函數在尺度空間Taylor展開式分別對所述高斯差分空間的多層圖像的行、列及尺度三個分量進行修正,Taylor展開式為:
對所述Taylor展開式進行求導并令其為0,得到:
將結果代入所述Taylor展開式中得:
式中,x表示所述極值點,D表示所述極值點處的Harris響應值,T表示轉秩,若則所述極值點保留,否則刪除所述極值點;
所述第二刪除模塊,用于去除邊緣不穩定的所述極值點,所述高斯差分函數的極值點在橫跨邊緣的方向有較大的主曲率,在垂直邊緣的方向有較小的主曲率,主曲率通過計算所述極值點位置尺度的二階Hessian矩陣求出:
式中,D表示所述極值點處的Harris響應值,H表示二階Hessian矩陣,所述D的主曲率和所述H的特征值成正比,令α為較大的所述特征值,β為較小的所述特征值,則
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的時候最小,隨著r的增大而增大,因此當不滿足下式時,所述極值點刪除,反之保留,保留下來的所述極值點是穩定關鍵點:
式中,H表示Hessian矩陣,Tr(H)代表Hessian矩陣的對角線元素之和,Det(H)代表Hessian矩陣的行列式。
進一步,所述HOG特征提取單元包括第一處理模塊、第二處理模塊、劃分模塊、第一計算模塊、第一串聯模塊、第二串聯模塊和轉換模塊;
所述第一處理模塊,用于將所述測試圖像或所述訓練集圖像中每一幅圖像的所述前N個區域中的每一塊區域視為一個圖像,進行灰度化;
所述第二處理模塊,用于通過Gamma校正法對灰度化后的每一塊區域對應的每一個圖像進行顏色空間的歸一化;
所述劃分模塊,用于將歸一化后的所述每一個圖像劃分為單元格,每2×2個像素點組成一個單元格;
所述第一計算模塊,用于計算所述每一個圖像中每個像素點(x,y)的梯度,捕獲輪廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分別代表所述像素點(x,y)處的水平方向梯度、垂直方向梯度和像素值;
所述像素點(x,y)處的梯度幅值和梯度方向分別為:
采用無符號(0-180)形式,并將(0-180)分成9等分,每個所述單元格產生9維的特征;
所述第一串聯模塊,用于將每2×2個所述單元格組成一個塊,一個塊內所有單元格的所述特征向量串聯起來后歸一化,便得到該塊的HOG特征;
所述第二串聯模塊,用于將所述每一個圖像中的所有塊的HOG特征串聯起來就得到所述每一個圖像的HOG特征;
變換模塊,用于將所述每一個圖像的HOG特征進行歸一化,所述歸一化的過程為:對所述HOG特征提取后的特征向量v進行特征變換,如下式:
v←v/255
式中,v為特征向量,ε為常數。
進一步,所述聚類單元包括集合模塊、確定模塊和第二計算模塊;
所述集合模塊,用于將所述訓練集圖像中的所有圖像的HOG特征用矩陣集合統一表示;
所述確定模塊,用于根據應用需求確定聚類中心數值n;
所述第二計算模塊,用于對所述訓練集圖像的矩陣集合進行K-Means均值聚類計算,得到的n個聚類中心即為視覺詞袋的n個視覺單詞。
進一步,所述視覺詞袋單元包括替換模塊和統計模塊;
所述替換模塊,用于利用歐式距離法計算所述測試圖像的每個HOG特征與所述視覺詞袋中每個視覺單詞的相似度,將所述測試圖像中的所述HOG特征用所述視覺詞袋中相似度最高的視覺單詞近似代替,歐氏距離為:
其中,Ha,Hb分別為所述測試圖像中的一個HOG特征向量和所述視覺詞袋中的一個視覺單詞向量,i表示所述測試圖像的HOG特征的維數;
所述統計模塊,用于統計所述測試圖像中找到的所有視覺單詞出現的頻率,得到的頻率直方圖即為所述測試圖像的視覺詞袋。
另一方面,提供一種基于HOG和視覺詞袋的相似圖像搜索方法,包括以下步驟:
S1:用于將訓練的圖像進行分類作為訓練集圖像,并對測試圖像和所述訓練集圖像的大小進行歸一化;
S2:輸入歸一化后的所述測試圖像和所述訓練集圖像,并對所述訓練集圖像中的每幅圖像進行S3-S5的步驟;
S3:通過高斯差分算法尋找相應圖像的穩定關鍵點;
S4:選取所述穩定關鍵點的最密集的前N個區域;
S5:對所述最密集的前N個區域進行HOG特征提取;
S6:在所述訓練集圖像中的每幅圖像進行完S3-S5的步驟后,使用K-Means聚類算法對所述訓練集圖像中的所述HOG特征進行聚類,得到的n個聚類中心為視覺詞袋的n個視覺單詞;
S7:對輸入的所述測試圖像進行S3-S5的操作;
S8:在所述訓練集圖像的視覺單詞中尋找與所述測試圖像中的每一個特征最近鄰的視覺單詞,并統計所述測試圖像中所找到的所有視覺單詞出現的頻率,得到的頻率直方圖為所述測試圖像的視覺詞袋;
S9:使用支持向量機分類器對所述訓練集圖像的視覺詞袋進行訓練,得到的模型對所述測試圖像的視覺詞袋進行測試,得到所述測試圖像的分類結果,反饋同一類別的圖片。
進一步,所述步驟S3具體包括:
步驟S31:對所述相應圖像f(x,y)加入高斯濾波Gσ1(x,y)、Gσ2(x,y),得到兩幅圖像g1(x,y)和g2(x,y):
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
步驟S32:將得到的兩幅圖像g1(x,y)、g2(x,y)進行相減,得到高斯差分圖像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
步驟S33:將高斯差分圖像中每一個像素點與其所有的相鄰點進行比較,若每一個所述像素點比其圖像域和尺度域中的相鄰點都大或都小,那該所述像素點則為極值點;
步驟S34:去除對比度低的所述極值點,利用高斯差分函數在尺度空間Taylor展開式分別對所述高斯差分空間的多層圖像的行、列及尺度三個分量進行修正,Taylor展開式為:
對所述Taylor展開式進行求導并令其為0,得到:
將結果代入所述Taylor展開式中得:
式中,x表示所述極值點,D表示所述極值點處的Harris響應值,T表示轉秩,若則所述極值點保留,否則刪除所述極值點;
步驟S35:去除邊緣不穩定的所述極值點,所述高斯差分函數的極值點在橫跨邊緣的方向有較大的主曲率,在垂直邊緣的方向有較小的主曲率,主曲率通過計算所述極值點位置尺度的二階Hess i an矩陣求出:
式中,D表示所述極值點處的Harris響應值,H表示二階Hessian矩陣,所述D的主曲率和所述H的特征值成正比,令α為較大的所述特征值,β為較小的所述特征值,則
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的時候最小,隨著r的增大而增大,因此當不滿足下式時,所述極值點刪除,反之保留,保留下來的所述極值點是穩定關鍵點:
式中,H表示Hessian矩陣,Tr(H)代表Hessian矩陣的對角線元素之和,Det(H)代表Hessian矩陣的行列式。
進一步,所述步驟S5具體包括:
步驟S51:將所述相應圖像中所述前N個區域的每一塊區域視為一個圖像,進行灰度化;
步驟S52:采用Gamma校正法對灰度化后的每一塊區域對應的每一個圖像進行顏色空間的歸一化;
步驟S53:將歸一化后的所述每一個圖像劃分為單元格,每2×2個像素點組成一個單元格;
步驟S54:計算所述每一個圖像中每個像素點(x,y)的梯度,捕獲輪廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分別代表所述像素點(x,y)處的水平方向梯度、垂直方向梯度和像素值;
所述像素點(x,y)處的梯度幅值和梯度方向分別為:
采用無符號(0-180)形式,并將(0-180)分成9等分,每個所述單元格產生9維的特征;
步驟S55:將每2×2個所述單元格組成一個塊,一個塊內所有單元格的所述特征向量串聯起來后歸一化,便得到該塊的HOG特征;
步驟S56:將所述每一個圖像中的所有塊的HOG特征串聯起來就得到所述每一個圖像的HOG特征;
步驟S57:將所述每一個圖像的HOG特征進行歸一化,所述歸一化的過程為:對所述HOG特征提取后的特征向量v進行特征變換,如下式:
v←v/255
式中,v為特征向量,ε為常數。
進一步,所述步驟S6具體包括:
步驟S61:將所述訓練集圖像中的所有圖像的HOG特征用矩陣集合統一表示;
步驟S62:根據應用需求確定聚類中心數值n;
步驟S63:對所述訓練集圖像的矩陣集合進行K-Means均值聚類計算,得到的n個聚類中心即為視覺詞袋的n個視覺單詞。
進一步,所述步驟S8具體包括:
步驟S81:利用歐式距離法計算所述測試圖像的每個HOG特征與所述視覺詞袋中每個視覺單詞的相似度,將所述測試圖像中的所述HOG特征用所述視覺詞袋中相似度最高的視覺單詞近似代替,歐氏距離為:
其中,Ha,Hb分別為所述測試圖像中的一個HOG特征向量和所述視覺詞袋中的一個視覺單詞向量,i表示所述測試圖像的HOG特征的維數;
步驟S82:統計所述測試圖像中找到的所有視覺單詞出現的頻率,得到的頻率直方圖(n維)即為所述測試圖像的視覺詞袋。
與現有技術比較本發明的有益效果在于:
1.使用高斯差分算子尋找穩定關鍵點并確定特征提取區域,減少了傳統使用HOG特征提取時對整幅圖像進行滑窗掃描操作,既節省了時間,又提高了效率;
2.使用HOG特征可以讓圖像局部像素點之間的關系得到很好的表征,除此之外,位置和方向空間的量化在一定程度上抑制了平移和旋轉帶來的影響;
3.使用視覺詞袋模型,相對基于文本的相似圖像搜索,更好地避免了語義鴻溝的問題。
附圖說明
圖1為本發明基于HOG和視覺詞袋的相似圖像搜索裝置的功能框圖;
圖2為本發明預處理單元的功能框圖;
圖3為本發明高斯差分單元的功能框圖;
圖4為本發明選取單元的功能框圖;
圖5為本發明HOG特征提取單元的功能框圖;
圖6為本發明聚類單元的功能框圖;
圖7為本發明視覺詞袋單元的功能框圖;
圖8為本發明基于HOG和視覺詞袋的相似圖像搜索方法的流程圖。
具體實施方式
以下結合附圖,對本發明上述的和另外的技術特征和優點作更詳細的說明。
實施例一
如圖1所示,其為本發明一種基于HOG和視覺詞袋的相似圖像搜索裝置的功能框圖,一種基于HOG和視覺詞袋的相似圖像搜索裝置包括:預處理單元1、輸入單元2、高斯差分單元3、選取單元4、HOG特征提取單元5、聚類單元6、視覺詞袋單元7和訓練單元8;
所述預處理單元1,用于將訓練的圖像進行分類作為訓練集圖像,并對測試圖像和所述訓練集圖像的大小進行歸一化;
所述輸入單元2,用于輸入歸一化后的所述測試圖像和所述訓練集圖像;
所述高斯差分單元3,用于通過高斯差分(DoG)算法尋找所述輸入單元中的所述測試圖像和所述訓練集圖像中每一幅圖像的穩定關鍵點;
所述選取單元4,用于選取所述測試圖像和所述訓練集圖像中每一幅圖像的穩定關鍵點的最密集的前N個區域;
所述HOG特征提取單元5,用于對所述最密集的前N個區域進行HOG特征提取;
所述聚類單元6,用于通過K-Means聚類算法對所述訓練集圖像中的所述HOG特征進行聚類,得到的n個聚類中心為視覺詞袋的n個視覺單詞;
所述視覺詞袋單元7,用于在所述訓練集圖像的視覺單詞中尋找與所述測試圖像中的每一個特征最近鄰的視覺單詞,并統計所述測試圖像中所找到的所有視覺單詞出現的頻率,得到的頻率直方圖(n維)為所述測試圖像的視覺詞袋;
所述訓練單元8,用于使用支持向量機(SVM)分類器對所述訓練集圖像的視覺詞袋進行訓練,得到的模型對所述測試圖像的視覺詞袋進行測試,得到所述測試圖像的分類結果,反饋同一類別的圖片。
如圖2所示,為本發明預處理單元的功能框圖,所述預處理單元1包括分類模塊11和預處理模塊12;
所述分類模塊11,用于對要訓練的圖像進行分類,添加類別標簽,并從每類中挑選相同數目的圖像作為訓練集圖像;
所述預處理模塊12,用于對測試圖像和所述訓練集圖像進行尺寸大小歸一化。
如圖3所示,為本發明高斯差分單元3的功能框圖,所述高斯差分單元3包括分層模塊31、差分模塊32、比較模塊33、第一刪除模塊34和第二刪除模塊35;
所述分層模塊31,用于對所述測試圖像f(x,y)或所述訓練集圖像中的每一幅訓練圖像f(x,y)加入高斯濾波Gσ1(x,y)、Gσ2(x,y),得到兩幅圖像g1(x,y)和g2(x,y),如下式:
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
其中,σ1,σ2表示不同的高斯濾波;
所述差分模塊32,用于將得到的兩幅圖像g1(x,y)、g2(x,y)進行相減,得到高斯差分(DOG)圖像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
所述比較模塊33,用于將高斯差分圖像中每一個像素點與其所有的相鄰點進行比較,若每一個所述像素點比其圖像域和尺度域中的相鄰點都大或都小,那該所述像素點則為極值點,其中,所述圖像域為每一個所述像素點所在的層面,所述尺度域為與所述圖像域相鄰上下兩層所在的層面;
所述第一刪除模塊34,用于去除對比度低的所述極值點,利用高斯差分函數(DOG)在尺度空間Taylor展開式分別對所述高斯差分(DOG)金字塔空間的多層圖像的行、列及尺度三個分量進行修正,Taylor展開式為:
對所述Taylor展開式進行求導并令其為0,得到:
將結果代入所述Taylor展開式中得:
式中,x表示所述極值點,D表示所述極值點處的Harris響應值,T表示轉秩,若則所述極值點保留,否則刪除所述極值點;
所述第二刪除模塊35,用于去除邊緣不穩定的所述極值點,所述高斯差分函數的極值點在橫跨邊緣的方向有較大的主曲率,在垂直邊緣的方向有較小的主曲率,主曲率通過計算所述極值點位置尺度的二階Hessian矩陣求出:
式中,D表示所述極值點處的Harris響應值,H表示二階Hessian矩陣,所述D的主曲率和所述H的特征值成正比,令α為較大的所述特征值,β為較小的所述特征值,則
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的時候最小,隨著r的增大而增大,因此當不滿足下式時,所述極值點刪除,反之保留,保留下來的所述極值點是穩定關鍵點:
式中,H表示Hessian矩陣,Tr(H)代表Hessian矩陣的對角線元素之和,Det(H)代表Hessian矩陣的行列式。
如圖4示,為本發明選取單元4的功能框圖,所述選取單元4包括分割模塊41和選擇模塊42;
所述分割模塊41,用于將所述測試圖像或所述訓練集圖像中的每一幅圖像按照m×m(m<M,M=km,k∈Z)大小進行分塊,統計每一塊中的所述穩定關鍵點的個數,其中,M代表所述測試圖像的邊長或所述訓練集圖像中每一幅圖像的邊長;
所述選擇模塊42,用于選擇所述測試圖像或所述訓練集圖像中每一幅圖像的穩定關鍵點的最密集的前N個區域,其中,N取整數。
本發明使用高斯差分算子尋找穩定關鍵點并確定特征提取區域,減少了傳統使用HOG特征提取時對整幅圖像進行滑窗掃描操作,既節省了時間,又提高了效率。
如圖5示,為本發明HOG特征提取單元5的功能框圖,所述HOG特征提取單元5包括第一處理模塊51、第二處理模塊52、劃分模塊53、第一計算模塊54、第一串聯模塊55、第二串聯模塊56和轉換模塊57。
所述第一處理模塊51,用于將所述測試圖像或所述訓練集圖像中每一幅圖像的所述前N個區域中的每一塊區域視為一個圖像,進行灰度化;
所述第二處理模塊52,用于通過Gamma校正法對灰度化后的每一塊區域對應的每一個圖像進行顏色空間的歸一化,這樣,可以調節所述每一個圖像的對比度,降低所述每一個圖像局部的陰影和光照變化所造成的影響,同時抑制噪音的干擾;
所述劃分模塊53,用于將歸一化后的所述每一個圖像劃分為單元格,每2×2個像素點組成一個單元格;
所述第一計算模塊54,用于計算所述每一個圖像中每個像素點(x,y)的梯度,捕獲輪廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分別代表所述像素點(x,y)處的水平方向梯度、垂直方向梯度和像素值。
所述像素點(x,y)處的梯度幅值和梯度方向分別為:
梯度方向分為有符號(0-360)和無符號(0-180)兩種形式,本裝置采用的是無符號的形式,并將(0-180)分成9等分,所以,所述每一個圖像中每個所述單元格的梯度方向都分成9個方向塊,使用所述單元格中的梯度方向和大小對9個方向塊進行加權投影,最后,每個所述單元格產生9維的特征。
所述第一串聯模塊55,用于將每2×2個所述單元格組成一個塊,一個塊內所有單元格的所述特征向量串聯起來后歸一化,便得到該塊的HOG特征;
所述第二串聯模塊56,用于將所述每一個圖像中的所有塊的HOG特征串聯起來就得到所述每一個圖像的HOG特征;
變換模塊57,用于將所述每一個圖像的HOG特征進行歸一化,所述歸一化的過程為:對所述HOG特征提取后的特征向量v進行特征變換,如下式:
v←v/255
式中,v為特征向量,ε為常數。
本發明使用HOG特征可以讓圖像局部像素點之間的關系得到很好的表征,除此之外,位置和方向空間的量化在一定程度上抑制了平移和旋轉帶來的影響。
如圖6示,為本發明聚類單元6的功能框圖,所述聚類單元6包括集合模塊61、確定模塊62和第二計算模塊63;
所述集合模塊61,用于將所述訓練集圖像中的所有圖像的HOG特征用矩陣集合統一表示;
所述確定模塊62,用于根據應用需求確定聚類中心數值n;
所述第二計算模塊63,用于對所述訓練集圖像的矩陣集合進行K-Means均值聚類計算,得到的n個聚類中心即為視覺詞袋的n個視覺單詞。
如圖7示,為本發明視覺詞袋單元7的功能框圖,所述視覺詞袋單元7包括替換模塊71和統計模塊72;
所述替換模塊71,用于利用歐式距離法計算所述測試圖像的每個HOG特征與所述視覺詞袋中每個視覺單詞的相似度,將所述測試圖像中的所述HOG特征用所述視覺詞袋中相似度最高的視覺單詞近似代替。歐氏距離為:
其中,Ha,Hb分別為所述測試圖像中的一個HOG特征向量和所述視覺詞袋中的一個視覺單詞向量,i表示所述測試圖像的HOG特征的維數。
所述統計模塊72,用于統計所述測試圖像中找到的所有視覺單詞出現的頻率,得到的頻率直方圖(n維)即為所述測試圖像的視覺詞袋。
本發明使用視覺詞袋模型,相對基于文本的相似圖像搜索,更好地避免了語義鴻溝的問題。
實施例二
如圖8所示,為本發明一種基于HOG和視覺詞袋的相似圖像搜索方法的功能框圖,包括以下步驟:
S1:用于將訓練的圖像進行分類作為訓練集圖像,并對測試圖像和所述訓練集圖像的大小進行歸一化;
S2:輸入歸一化后的所述測試圖像和所述訓練集圖像,并對所述訓練集圖像中的每幅圖像進行S3-S5的步驟;
S3:通過高斯差分(DoG)算法尋找相應圖像的穩定關鍵點;
S4:選取所述穩定關鍵點的最密集的前N個區域;
S5:對所述最密集的前N個區域進行HOG特征提取;
S6:在所述訓練集圖像中的每幅圖像進行完S3-S5的步驟后,使用K-Means聚類算法對所述訓練集圖像中的所述HOG特征進行聚類,得到的n個聚類中心為視覺詞袋的n個視覺單詞;
S7:對輸入的所述測試圖像進行S3-S5的操作;
S8:在所述訓練集圖像的視覺單詞中尋找與所述測試圖像中的每一個特征最近鄰的視覺單詞,并統計所述測試圖像中所找到的所有視覺單詞出現的頻率,得到的頻率直方圖(n維)為所述測試圖像的視覺詞袋;
S9:使用支持向量機(SVM)分類器對所述訓練集圖像的視覺詞袋進行訓練,得到的模型對所述測試圖像的視覺詞袋進行測試,得到所述測試圖像的分類結果,反饋同一類別的圖片。
所述步驟S1具體包括:
步驟S11:對要訓練的圖像進行分類,添加類別標簽,并從每類中挑選相同數目的圖像作為訓練集圖像;
步驟S12:用于對測試圖像和所述訓練集圖像進行尺寸大小歸一化。
所述步驟S3具體包括:
步驟S31:對所述相應圖像f(x,y)加入高斯濾波Gσ1(x,y)、Gσ2(x,y),得到兩幅圖像g1(x,y)和g2(x,y):
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
σ1,σ2表示兩種不同的高斯濾波;
步驟S32:將得到的兩幅圖像g1(x,y)、g2(x,y)進行相減,得到高斯差分(DOG)圖像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
步驟S33:將高斯差分圖像中每一個像素點與其所有的相鄰點進行比較,若每一個所述像素點比其圖像域和尺度域中的相鄰點都大或都小,那該所述像素點則為極值點,其中,所述圖像域為每一個所述像素點所在的層面,所述尺度域為與所述圖像域相鄰上下兩層所在的層面;
步驟S34:去除對比度低的所述極值點,利用高斯差分(DOG)函數在尺度空間Taylor展開式分別對所述高斯差分(DOG)空間的多層圖像的行、列及尺度三個分量進行修正,Taylor展開式為:
對所述Taylor展開式進行求導并令其為0,得到:
將結果代入所述Taylor展開式中得:
式中,x表示所述極值點,D表示所述極值點處的Harris響應值,T表示轉秩,若則所述極值點保留,否則刪除所述極值點;
步驟S35:去除邊緣不穩定的所述極值點,所述高斯差分(DOG)函數的極值點在橫跨邊緣的方向有較大的主曲率,在垂直邊緣的方向有較小的主曲率,主曲率通過計算所述極值點位置尺度的二階Hessian矩陣求出:
式中,D表示所述極值點處的Harris響應值,H表示二階Hessian矩陣,所述D的主曲率和所述H的特征值成正比,令α為較大的所述特征值,β為較小的所述特征值,則
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的時候最小,隨著r的增大而增大,因此當不滿足下式時,所述極值點刪除,反之保留,保留下來的所述極值點是穩定關鍵點:
式中,H表示Hessian矩陣,Tr(H)代表Hessian矩陣的對角線元素之和,Det(H)代表Hessian矩陣的行列式。
所述步驟S4具體包括:
步驟S41:將所述相應圖像按照m×m(m<M,M=km,k∈Z)的大小進行分塊,統計每一塊中的所述穩定關鍵點的個數,其中,M代表所述相應圖像的邊長;
步驟S42:選擇所述相應圖像中的穩定關鍵點的最密集的前N個區域,其中,N取整數。
本發明使用高斯差分算子尋找穩定關鍵點并確定特征提取區域,減少了傳統使用HOG特征提取時對整幅圖像進行滑窗掃描操作,既節省了時間,又提高了效率。
所述步驟S5具體包括:
步驟S51:將所述相應圖像中所述前N個區域的每一塊區域視為一個圖像,進行灰度化;
步驟S52:采用Gamma校正法對灰度化后的每一塊區域對應的每一個圖像進行顏色空間的歸一化,這樣,可以調節所述每一個圖像的對比度,降低所述每一個圖像局部的陰影和光照變化所造成的影響,同時抑制噪音的干擾。
步驟S53:將歸一化后的所述每一個圖像劃分為單元格,每2×2個像素點組成一個單元格;
步驟S54:計算所述每一個圖像中每個像素點(x,y)的梯度,捕獲輪廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分別代表所述像素點(x,y)處的水平方向梯度、垂直方向梯度和像素值。
所述像素點(x,y)處的梯度幅值和梯度方向分別為:
梯度方向分為有符號(0-360)和無符號(0-180)兩種形式,本裝置采用的是無符號的形式,并將(0-180)分成9等分,所以,所述每一個圖像中每個所述單元格的梯度方向都分成9個方向塊,使用所述單元格中的梯度方向和大小對9個方向塊進行加權投影,最后,每個所述單元格產生9維的特征。
步驟S55:將每2×2個所述單元格組成一個塊,一個塊內所有單元格的所述特征串聯起來后歸一化,便得到該塊的HOG特征;
步驟S56:將所述每一個圖像中的所有塊的HOG特征串聯起來就得到所述每一個圖像的HOG特征;
步驟S57:將所述每一個圖像的HOG特征進行歸一化,所述歸一化的過程為:對所述HOG特征提取后的特征向量v進行特征變換,如下式:
v←v/255
式中,v為特征向量,ε為常數。
本發明使用HOG特征可以讓圖像局部像素點之間的關系得到很好的表征,除此之外,位置和方向空間的量化在一定程度上抑制了平移和旋轉帶來的影響。
所述步驟S6具體包括:
步驟S61:將所述訓練集圖像中的所有圖像的HOG特征用矩陣集合統一表示;
步驟S62:根據應用需求在所述矩陣集合中確定聚類中心數值n;
步驟S63:對所述訓練集圖像的矩陣集合進行K-Means均值聚類計算,得到的n個聚類中心即為視覺詞袋的n個視覺單詞。
所述步驟S8具體包括:
步驟S81:利用歐式距離法計算所述測試圖像的每個HOG特征與所述視覺詞袋中每個視覺單詞的相似度,將所述測試圖像中的所述HOG特征用所述視覺詞袋中相似度最高的視覺單詞近似代替。歐氏距離為:
其中,Ha,Hb分別為所述測試圖像中的一個HOG特征向量和所述視覺詞袋中的一個視覺單詞向量,i表示所述測試圖像的HOG特征的維數。
步驟S82:統計所述測試圖像中找到的所有視覺單詞出現的頻率,得到的頻率直方圖(n維)即為所述測試圖像的視覺詞袋。
本發明使用視覺詞袋模型,相對基于文本的相似圖像搜索,更好地避免了語義鴻溝問題。
以上所述僅是本發明的優選實施方式,應當指出,對于本技術領域的普通技術人員,在不脫離本發明方法的前提下,還可以做出若干改進和補充,這些改進和補充也應視為本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!