數據的同步方法和裝置與流程
本發明涉及互聯網領域,具體而言,涉及一種數據的同步方法和裝置。
背景技術:
Skytools是一個最初由Skype開發的軟件包,是一個工具與服務的集合。這個工具用于解決多個PostgreSQL數據庫之間的復制,同步傳輸等問題。
在現有技術中,Skytools可以滿足同構系統(即PostgreSQL數據庫)之間的實時增量數據同步。但是,隨著計算機技術的發展,異構系統(比如消息系統Kafka、搜索引擎系統Elasticsearch、nosql數據庫系統Mongodb、緩存系統Redis、大數據計算引擎系統Impala等等)的出現,PostgreSQL數據庫與這些異構系統之間的實時增量數據同步的需求也越來越強烈。然后Skytools的現有功能并不能滿足這些需求。
針對相關技術中數據庫與異構系統之間不能進行實時增量數據同步的技術問題,目前尚未提出有效的解決方案。
技術實現要素:
本發明實施例提供了一種數據的同步方法和裝置,以至少解決相關技術中數據庫與異構系統之間不能進行實時增量數據同步的技術問題。
根據本發明實施例的一個方面,提供了一種數據的同步方法,該方法包括:在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;將增量數據同步至配置信息所指示的一個或多個系統,其中,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。
進一步地,將增量數據同步至配置信息所指示的一個或多個系統包括:將增量數據發送至消息系統,由消息系統將增量數據同步至一個或多個系統,其中,消息系統為Kafka消息系統。
進一步地,將增量數據發送至消息系統包括:利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統,其中,第一應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
進一步地,方法還包括在利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統之后,接收第一應用程序編程接口的回應信息,其中,在接收到回應信息的情況下,確認將增量數據發送至消息系統的操作執行成功。
進一步地,一個或多個系統包括以下至少之一:搜索引擎系統Elasticsearch、數據庫系統Mongodb、緩存系統Redis以及大數據計算引擎系統Impala。
進一步地,獲取增量數據包括:利用Skytools工具集中的第二應用程序編程接口讀取目標數據庫中的增量數據,其中,第二應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
進一步地,目標數據庫包括PostgreSQL類型的數據庫。
根據本發明實施例的另一個方面,提供了一種數據的同步裝置,該裝置包括:獲取單元,用于在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;同步單元,用于將增量數據同步至配置信息所指示的一個或多個系統,其中,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。
進一步地,同步單元還用于將增量數據發送至消息系統,由消息系統將增量數據同步至一個或多個系統,其中,消息系統為Kafka消息系統。
進一步地,同步單元包括:發送模塊,用于利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統,其中,第一應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
通過上述實施例,在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;將增量數據同步至配置信息所指示的一個或多個系統,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。從而解決了相關技術中數據庫與異構系統之間不能進行實時增量數據同步的技術問題,實現了在數據庫與異構系統之間進行實時增量數據同步的技術效果。
附圖說明
此處所說明的附圖用來提供對本發明的進一步理解,構成本申請的一部分,本發明的示意性實施例及其說明用于解釋本發明,并不構成對本發明的不當限定。在附圖中:
圖1是根據本發明實施例的數據的同步方法的流程圖;
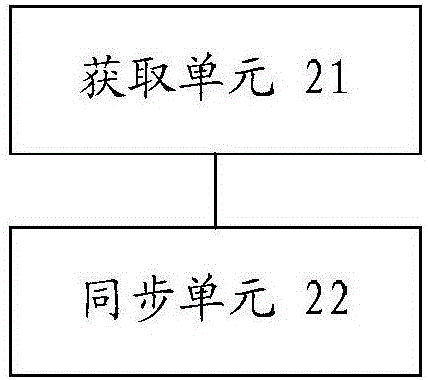
圖2是根據本發明實施例的數據的同步裝置的示意圖。
具體實施方式
下文中將參考附圖并結合實施例來詳細說明本發明。需要說明的是,在不沖突的情況下,本申請中的實施例及實施例中的特征可以相互組合。
需要說明的是,本發明的說明書和權利要求書及上述附圖中的術語“第一”、“第二”等是用于區別類似的對象,而不必用于描述特定的順序或先后次序。
首先,在對本發明實施例進行描述的過程中出現的部分名詞或術語適用于如下解釋:
PostgreSQL:是一個開源的、社區驅動的、自由的且符合標準的對象-關系型數據庫系統。
Kafka:Apache Kafka是由Apache軟件基金會開發的一個開源消息系統項目,由Scala寫成。Kafka最初是由LinkedIn開發,并于2011年初開源的軟件系統。
Elasticsearch:ElasticSearch是一個基于Lucene的搜索服務器。它提供了一個具備分布式多用戶能力的全文搜索引擎,基于RESTful web接口實現。Elasticsearch是用Java開發的,并作為Apache許可條款下的開放源碼發布,是當前流行的企業級搜索引擎。
Redis:是一個開源的、支持網絡的、基于內存的鍵值對存儲數據庫,使用ANSI C編寫。根據相關數據顯示,Redis是最流行的鍵值對存儲數據庫。
Mongodb:MongoDB是一種文檔導向的數據庫管理系統,由C++撰寫而成,以此來解決應用程序開發社區中的大量問題。
Impala:Impala是一種新型查詢系統,它提供SQL語義,能查詢存儲在Hadoop的HDFS和HBase中的PB級大數據。Impala的最大特點是的速度快。
為了可以滿足PostgreSQL數據庫與異構系統,比如消息系統(Kafka)、搜索引擎系統(Elasticsearch)、nosql數據庫系統(Mongodb)、緩存系統(Redis)、大數據計算引擎系統(Impala)之間的實時增量同步數據。根據本發明實施例,提供了一種數據的同步方法的方法實施例,需要說明的是,在附圖的流程圖示出的步驟可以在諸如一組計算機可執行指令的計算機系統中執行,并且,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同于此處的順序執行所示出或描述的步驟。
圖1是根據本發明實施例的數據的同步方法的流程圖,如圖1所示,該方法包括如下步驟:
步驟S101,在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息。
步驟S102,將增量數據同步至配置信息所指示的一個或多個系統,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。
通過上述實施例,在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;將增量數據同步至配置信息所指示的一個或多個系統,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。從而解決了相關技術中數據庫與異構系統之間不能進行實時增量數據同步的技術問題,實現了在數據庫與異構系統之間進行實時增量數據同步的技術效果。
可選地,一個或多個系統包括以下至少之一:搜索引擎系統Elasticsearch、數據庫系統Mongodb、緩存系統Redis以及大數據計算引擎系統Impala。上述的目標數據庫包括PostgreSQL類型的數據庫。
在步驟S101中,獲取增量數據包括:利用Skytools工具集中的第二應用程序編程接口讀取目標數據庫中的增量數據,其中,第二應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
具體地,在Skytools工具集中,有個子集,叫做pgq。使用python語言實現,調用消息系統(Kafka)的相關應用程序接口api,將實時增量數據同步到消息系統中。并且通過api調用成功后進行標記,api調用失敗以后不斷進行重試,來保證數據不會漏傳輸也不會重復傳輸,每條數據都傳輸一次,而且僅僅被傳輸一次。
在步驟S102中,將增量數據同步至配置信息所指示的一個或多個系統包括:將增量數據發送至消息系統,由消息系統將增量數據同步至一個或多個系統,其中,消息系統為Kafka消息系統。
具體地,將增量數據發送至消息系統包括:利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統,其中,第一應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
可選地,在利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統之后,接收第一應用程序編程接口的回應信息,其中,在接收到回應信息的情況下,確認將增量數據發送至消息系統的操作執行成功。
在Skytools工具集中,有個子集,叫做pgq,可使用python語言實現,調用搜索引擎系統(Elasticsearch)的相關api,將實時增量數據同步到消息系統中。并且通過api調用成功后進行標記,api調用失敗以后不斷進行重試,來保證數據不會漏傳輸也不會重復傳輸,每條數據都被傳輸一次,而且僅僅被傳輸一次。
在Skytools工具集中,有個子集,叫做pgq,可使用python語言實現,調用nosql數據庫系統(Mongodb)的相關api,將實時增量數據同步到消息系統中。并且通過api調用成功后進行標記,api調用失敗以后不斷進行重試,來保證數據不會漏傳輸也不會重復傳輸,每條數據都被傳輸一次,而且僅僅被傳輸一次。
在Skytools工具集中,有個子集,叫做pgq,使用python語言實現,調用緩存系統(Redis)的相關api,將實時增量數據同步到消息系統中。并且通過api調用成功后進行標記,api調用失敗以后不斷進行重試,來保證數據不會漏傳輸也不會重復傳輸,每條數據都被傳輸一次,而且僅僅被傳輸一次。
在Skytools工具集中,有個子集,叫做pgq,使用python語言實現,調用大數據計算引擎系統(Impala)的相關api,將實時增量數據同步到消息系統中。并且通過api調用成功后進行標記,api調用失敗以后不斷進行重試,來保證數據不會漏傳輸也不會重復傳輸,每條數據都被傳輸一次,而且僅僅被傳輸一次。
需要說明的是,在步驟S101之前,通過自定義的配置文件,可以配置哪些數據需要進行同步,哪幾個異構系統需要進行同步。靈活配置,便于修改,便于運維。
通過上述實施例,提供了PostgreSQL數據庫與異構系統之間的實時增量同步數據的整個技術設計和技術實現方案,使得PostgreSQL數據庫與異構系統之間的可以實現實時增量同步數據。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到根據上述實施例的方法可借助軟件加必需的通用硬件平臺的方式來實現,當然也可以通過硬件,但很多情況下前者是更佳的實施方式。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質(如ROM/RAM、磁碟、光盤)中,包括若干指令用以使得一臺終端設備(可以是手機,計算機,服務器,或者網絡設備等)執行本發明各個實施例所述的方法。
實施例2
本發明實施例中還提供了一種數據的同步裝置。該裝置用于實現上述實施例及優選實施方式,已經進行過說明的不再贅述。如以下所使用的,術語“模塊”可以實現預定功能的軟件和/或硬件的組合。盡管以下實施例所描述的裝置較佳地以軟件來實現,但是硬件,或者軟件和硬件的組合的實現也是可能并被構想的。
圖2是根據本發明實施例的數據的同步裝置的示意圖。如圖2所示,該裝置可以包括:獲取單元21和同步單元22。
獲取單元21,用于在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;
同步單元22,用于將增量數據同步至配置信息所指示的一個或多個系統,其中,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。
通過上述實施例,獲取單元在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;同步單元將增量數據同步至配置信息所指示的一個或多個系統,其中,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統,從而解決了相關技術中數據庫與異構系統之間不能進行實時增量數據同步的技術問題,實現了在數據庫與異構系統之間進行實時增量數據同步的技術效果。
可選地,一個或多個系統包括以下至少之一:搜索引擎系統Elasticsearch、數據庫系統Mongodb、緩存系統Redis以及大數據計算引擎系統Impala。上述的目標數據庫包括PostgreSQL類型的數據庫。
可選地,獲取單元還用于利用Skytools工具集中的第二應用程序編程接口讀取目標數據庫中的增量數據,其中,第二應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
在上述實施例中,同步單元還用于將增量數據發送至消息系統,由消息系統將增量數據同步至一個或多個系統,其中,消息系統為Kafka消息系統。
可選地,同步單元包括:發送模塊,用于利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統,其中,第一應用程序編程接口為Skytools工具集的pgq子集中的應用程序編程接口。
上述的發送模塊還用于在利用Skytools工具集中的第一應用程序編程接口發送增量數據至消息系統之后,接收第一應用程序編程接口的回應信息,其中,在接收到回應信息的情況下,確認將增量數據發送至消息系統的操作執行成功。
需要說明的是,上述裝置還包括配置單元,用于通過自定義的配置文件配置需要同步的數據和/或需要同步的異構系統,可以配置哪些數據需要進行同步,哪幾個異構系統需要進行同步。靈活配置,便于修改,便于運維。
需要說明的是,上述各個模塊是可以通過軟件或硬件來實現的,對于后者,可以通過以下方式實現,但不限于此:上述模塊均位于同一處理器中;或者,上述各個模塊以任意組合的形式分別位于不同的處理器中。
實施例3
本發明的實施例還提供了一種存儲介質。可選地,在本實施例中,上述存儲介質可以被設置為存儲用于執行以下步驟的程序代碼:
S1,在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;
S2,將增量數據同步至配置信息所指示的一個或多個系統,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。
可選地,在本實施例中,上述存儲介質可以包括但不限于:U盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、移動硬盤、磁碟或者光盤等各種可以存儲程序代碼的介質。
可選地,在本實施例中,處理器根據存儲介質中已存儲的程序代碼執行:在目標數據庫中存在增量數據的情況下,獲取增量數據和目標數據庫的配置信息;將增量數據同步至配置信息所指示的一個或多個系統,一個或多個系統為配置信息中與增量數據的數據類型對應的異構系統。
可選地,本實施例中的具體示例可以參考上述實施例及可選實施方式中所描述的示例,本實施例在此不再贅述。
顯然,本領域的技術人員應該明白,上述的本發明的各模塊或各步驟可以用通用的計算裝置來實現,它們可以集中在單個的計算裝置上,或者分布在多個計算裝置所組成的網絡上,可選地,它們可以用計算裝置可執行的程序代碼來實現,從而,可以將它們存儲在存儲裝置中由計算裝置來執行,并且在某些情況下,可以以不同于此處的順序執行所示出或描述的步驟,或者將它們分別制作成各個集成電路模塊,或者將它們中的多個模塊或步驟制作成單個集成電路模塊來實現。這樣,本發明不限制于任何特定的硬件和軟件結合。
以上所述僅為本發明的優選實施例而已,并不用于限制本發明,對于本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!