一種分布式數據庫及其數據運算的管理方法與流程
本發明屬于分布式數據庫技術領域,尤其是涉及一種分布式數據庫及其數據運算的管理方法。
背景技術:
分布式數據庫是指利用高速計算機網絡將物理上分散的多個數據存儲單元連接起來組成一個邏輯上統一的數據庫。分布式數據庫的基本思想是將原來集中式數據庫中的數據分散存儲到多個通過網絡連接的數據存儲節點上,以獲取更大的存儲容量和更高的并發訪問量。近年來,隨著數據量的高速增長,分布式數據庫技術也得到了快速的發展,傳統的關系型數據庫開始從集中式模型向分布式架構發展,基于關系型的分布式數據庫在保留了傳統數據庫的數據模型和基本特征下,從集中式存儲走向分布式存儲,從集中式計算走向分布式計算。
在分布式數據庫系統中一般都是采用多臺機器存儲數據,即將用戶數據根據hash或者隨機分布算法把數據分布到數據庫的各個工作機器中,這樣來減少單臺數據庫工作機器所存儲的數據量,減少每一臺機器的存儲與計算壓力。該分布式數據庫系統首先把數據按照hash或者隨機分布的方式把數據分發到集群運算節點中,當SQL中運算都涉及到hash分布列時,因為節點數據具有本地local性,因此可把SQL下發給各個運算節點,運算會在各個節點并行執行,當SQL中的運算是非hash分布列,則運算就不具有本地local性,該SQL就不可以直接在各個節點并行執行,必須在集群的所有運算節點上對數據重新進行動態重分布后分布到集群的所有運算節點上或者在集群的所有運算節點上把執行結果匯總到單個節點后,數據才具有本地local性,以上兩種運算方式存在如下缺陷:方式1:在集群的所有運算節點上對數據重新進行動態重分布后分布到集群的所有運算節點上的運算對所有的節點的資源都占用,而且涉及到點到點的網狀通訊,當節點數較多時(例如查過100),則每個節點都會產生大量的連接和線程進行數據的發送和接收,因此資源消耗將很大;方式2:在集群的所有運算節點上把執行結果匯總到單個節點的運算對匯總節點的資源占用將較高,但集群中的所有運算節點的硬件配置基本相同,而且運行時資源占用也基本相同,如果匯總節點相對其他運算節點有更多地資源占用,則在硬件配置基本相同的情況下,該匯總節點將成為整個集群的瓶頸節點。
技術實現要素:
本發明實施例提供了一種分布式數據庫及其數據運算的管理方法,以解決分布式數據庫運算節點資源消耗不均衡的技術問題。
一方面,本發明實施例提供了一種分布式數據庫系統,包括:
管理集群,用于接收用戶的指令,并解析優化所述指令,生成執行計劃和調度;
基礎運算層集群,用于接收管理集群接收執行計劃,基于分布在節點上的業務表進行運算;
匯總結果運算層集群,用于接收來自基礎運算層集群分發的數據進行運算。
另一方面,本發明實施例提供了一種分布式數據庫的數據運算的管理方法,包括:
在所述用戶的指令中包括哈希分布列時,管理集群直接將接收到的用戶的指令發送至基礎運算層集群,并接收基礎運算層集群返回的執行結果。
進一步的,一種分布式數據庫的數據運算的管理方法,包括:
在所述用戶的指令中不包括哈希分布列時,管理集群將接收到的用戶的指令發送至基礎運算層集群,基礎運算層集群完成計算后,生成中間結果數據,并將中間結果數據分發至匯總結果運算層集群,由匯總結果運算層群上傳至管理集群。
進一步的,一種分布式數據庫的數據運算的管理方法,包括:
在所述用戶的指令中不包括哈希分布列時,需要產生中間結果,則把產生的數據分發給中間結果或匯總結果運算層集群進行后續的操作,基于以上中間表或者匯總表的后續運算將在該集群上運行,運行的結果如果需要繼續和基礎運算層節點集群上的表進行交互時,運行的結果將會分發到基礎運算層節點集群上繼續后續的操作,如果基礎運算層集群上的后續操作又需要產生中間表,則把產生的數據分發給匯總結果運算層集群進行。
本發明實施例提供的分布式數據庫及其數據運算的管理方法,通過增加用于接收來自基礎運算層集群分發的數據進行運算的匯總結果運算層集群。在數據不具有本地性時,可以實現匯總和交互數據,減少節點之間網絡資源的使用,并可使得分布式數據庫運算節點資源更加均衡。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明實施例一提供的分布式數據庫的結構示意圖;
圖2是本發明實施例二提供的分布式數據庫的數據運算的管理方法的流程示意圖;
圖3是本發明實施例三提供的分布式數據庫的數據運算的管理方法的流程示意圖;
圖4是本發明實施例四提供的分布式數據庫的數據運算的管理方法的流程示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
圖1是本發明實施例一提供的分布式數據庫的結構示意圖,參見圖1,所述分布式數據庫系統,包括:管理集群,用于接收用戶的指令,并解析優化所述指令,生成執行計劃和調度;基礎運算層集群,用于接收管理集群接收執行計劃,基于分布在節點上的業務表進行運算;匯總結果運算層集群,用于接收來自基礎運算層集群分發的數據進行運算。
在Shared-nothing架構中,整個系統包括管理集群和計算集群。在本實施例中,計算集群被分為基礎運算層集群和匯總結果運算層集群,可以進行不同功能的運算,以使得原來由單一節點完成的匯總等計算操作分配給多個節點組成的匯總結果運算層集群來實現,可以減少節點之間網絡資源的使用,并可使得分布式數據庫運算節點資源更加均衡。
實施例二
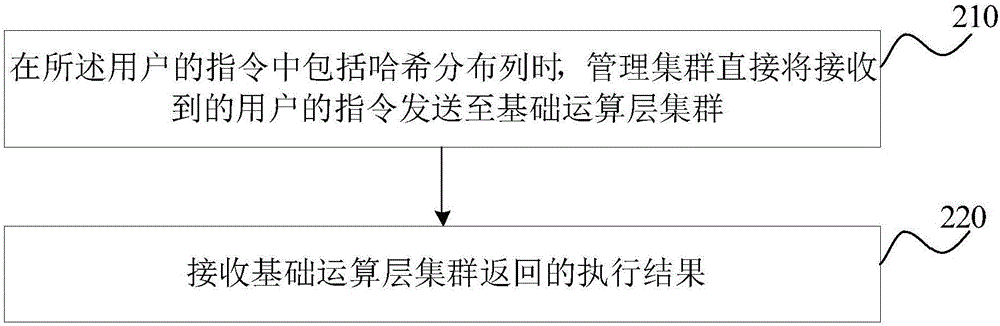
圖2是本發明實施例二提供的分布式數據庫的數據運算的管理方法的流程示意圖,本實施例可適用于在分布式數據庫系統中計算集群被分為基礎運算層集群和匯總結果運算層集群時,對分布式數據庫數據運算進行管理的情況,該方法可以由分分布式數據庫的數據運算的管理裝置來執行,該裝置可由軟件/硬件方式實現,并可集成于分布式數據庫系統中。
參見圖2,所述分布式數據庫的數據運算的管理方法,包括:
S210,在所述用戶的指令中包括哈希分布列時,管理集群直接將接收到的用戶的指令發送至基礎運算層集群。
示例性的,所述用戶的指令為sql操作。通過統一的管理節點集群的任何一個節點作為入口接收用戶的指令,管理節點集群負責接收用戶的SQL,負責SQL解析、SQL優化、分布式執行計劃生成、執行調度。集群中所有業務表按照hash分布或者隨機分布的方式把數據分布到基礎運算層集群的節點中,基礎運算層集群的節點負責從管理集群的節點接收SQL,基于分布在節點上的業務表進行運算。
S220,接收基礎運算層集群返回的執行結果。
在sql中的操作都包含hash分布列時,則數據具有本地性,從管理集群節點接收到的SQL可直接下發給基礎運算層集群的節點執行,執行結果直接返回給管理集群的入口節點,然后返回用戶。在該場景下匯總結果運算層集群不參與運算。
本實施例提供的分布式數據庫的數據運算的管理方法,在數據具有本地性時,通過基礎運算層集群可直接運算得到結果。可以減少節點之間網絡資源的使用。
實施例三
圖3是本發明實施例三提供的分布式數據庫的數據運算的管理方法的流程示意圖,本實施例可適用于在分布式數據庫系統中計算集群被分為基礎運算層集群和匯總結果運算層集群時,對分布式數據庫數據運算進行管理的情況,該方法可以由分分布式數據庫的數據運算的管理裝置來執行,該裝置可由軟件/硬件方式實現,并可集成于分布式數據庫系統中。
參見圖3,所述分布式數據庫的數據運算的管理方法,包括:
S310,在所述用戶的指令中不包括哈希分布列時,管理集群將接收到的用戶的指令發送至基礎運算層集群。
示例性的,所述用戶的指令為sql操作。通過統一的管理節點集群的任何一個節點作為入口接收用戶的指令,管理節點集群負責接收用戶的SQL,負責SQL解析、SQL優化、分布式執行計劃生成、執行調度。集群中所有業務表按照hash分布或者隨機分布的方式把數據分布到基礎運算層集群的節點中,基礎運算層集群的節點負責從管理集群的節點接收SQL,基于分布在節點上的業務表進行運算。
S320,基礎運算層集群完成計算后,生成中間結果數據,并將中間結果數據分發至匯總結果運算層集群。
sql中的操作不都包含hash分布列,則數據不具有本地local性,從管理集群節點接收到的SQL下發給基礎運算層集群的節點執行后,需要產生中間結果的數據,則把產生的數據分發給匯總結果運算層集群進行后續的操作。
S330,匯總結果運算集群上傳至管理集群。
后續操作的結果不需要和基礎運算層節點集群上的表進行交互,則把運算結果直接返回給管理集群的入口節點,管理集群入口節點再把結果返回用戶。
本實施例提供的分布式數據庫的數據運算的管理方法,在數據不具有本地性時,通過基礎運算層集群運算,并將結果傳送給匯總結果運算層集群。無需再次信息交互,可以減少節點之間網絡資源的使用。
實施例四
圖4是本發明實施例四提供的分布式數據庫的數據運算的管理方法的流程示意圖,本實施例可適用于在分布式數據庫系統中計算集群被分為基礎運算層集群和匯總結果運算層集群時,對分布式數據庫數據運算進行管理的情況,該方法可以由分分布式數據庫的數據運算的管理裝置來執行,該裝置可由軟件/硬件方式實現,并可集成于分布式數據庫系統中。
參見圖4,所述分布式數據庫的數據運算的管理方法,包括:
S410,在所述用戶的指令中不包括哈希分布列時,管理集群將接收到的用戶的指令發送至基礎運算層集群。
示例性的,所述用戶的指令為sql操作。通過統一的管理節點集群的任何一個節點作為入口接收用戶的指令,管理節點集群負責接收用戶的SQL,負責SQL解析、SQL優化、分布式執行計劃生成、執行調度。集群中所有業務表按照hash分布或者隨機分布的方式把數據分布到基礎運算層集群的節點中,基礎運算層集群的節點負責從管理集群的節點接收SQL,基于分布在節點上的業務表進行運算。
S420,把產生的數據分發給匯總結果運算層集群進行后續的操作,基于所述產生的數據后續運算在匯總結果運算層集群上運行。
從管理集群節點接收到的SQL下發給基礎運算層集群的節點執行后,需要產生中間結果,例如中間表或者匯總表的數據,則把產生的數據分發給匯總結果運算層集群進行后續的操作。
S430,如果需要繼續和基礎運算層節點集群上的表進行交互時,運行的結果將會分發到基礎運算層節點集群上繼續后續的操作。
基于以上中間表或者匯總表的后續運算將在該集群上運行,運行的結果如果需要繼續和基礎運算層節點集群上的表進行交互時,運行的結果將會分發到基礎運算層節點集群上繼續后續的操作,無需管理集群向基礎運算層節點集群分發任務。
S440,如果基礎運算層集群上的后續操作又需要產生數據,則把產生的數據分發給匯總結果運算層集群運行。
如果基礎運算層集群上的后續操作又需要產生中間表,則把產生的數據分發給中間結果或匯總結果運算層集群進行,按照以上邏輯執行完所有的后續步驟后,運算結果或者從基礎運算層集群的節點返回給管理集群的入口節點,或者從中間結果或匯總結果運算層集群的節點返回給管理集群的入口節點,然后管理集群入口節點再把結果返回用戶。
本實施例提供的分布式數據庫的數據運算的管理方法,在數據不具有本地性時,通過基礎運算層集群運算,并將結果傳送給匯總結果運算層集群。在需要再次信息交互時,匯總結果運算層集群即可分發任務,可以實現復雜的邏輯任務,并可以減少節點之間網絡資源的使用。
本領域普通技術人員可以理解:實現上述各方法實施例的全部或部分步驟可以通過程序指令相關的硬件來完成。前述的程序可以存儲于一計算機可讀取存儲介質中。該程序在執行時,執行包括上述各方法實施例的步驟;而前述的存儲介質包括:ROM、RAM、磁碟或者光盤等各種可以存儲程序代碼的介質。
最后應說明的是:以上各實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述各實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分或者全部技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!