一種實體消歧方法及裝置與流程
本發明涉及實體消歧技術領域,特別涉及一種實體消歧方法及裝置。
背景技術:
實體消歧是為了解決自然語言中廣泛存在的命名實體(后文中簡稱“實體”)的歧義(一詞多義)問題,屬于詞義消歧的一部分,是自然語言處理中非常重要的基礎性工作。在視頻搜索引擎中存在大量的影視劇名的實體,而影視劇名存在大量的歧義,歧義分為兩個方面:其一,影視劇名是一個普通詞語或短語(例如:“少帥”既是一個普通的詞語也是一部影視劇名稱,類似的還有“大丈夫”、“蘋果”、“臥虎藏龍”等);其二,一個影視劇名對應多個影視劇實體(例如:“非誠勿擾”即是一部電影的名稱,也是一檔綜藝節目的名稱,電影“美人魚”有多個不同的版本)。每一個不同概念意義事物的敘述內容稱為義項,如果能準確識別有歧義的實體,準確的對歧義實體消歧,即區分實體的真正義項,將對于視頻搜索引擎的優化有很大的幫助。
實體消歧可以分為有監督學習方法和無監督學習方法。前者從標注了義項的大規模訓練數據中抽取歧義詞義項的特征屬性,然后根據實體詞在文本中出現位置的上下文,給出匹配度最高的歧義詞義項作為消歧的結果,而后者對大量未標注義項的語料中通過聚類方法將歧義詞聚類出不同的義項,同一聚類類別中的特征作為該義項的特征。
對于有監督學習方法,需要對訓練數據做大量地人工標注工作,如:確定歧義詞存在的候選義項,以及標注大量用于抽取歧義詞義項特征的訓練數據,這無疑需要大量的人工成本,而且有監督方法無法很好解決沒有出現在標注集中的歧義詞的消歧。而基于聚類的無監督學習方法,最終的類別(義項)數是不確定的,聚類類別與實際義項也無法一一對應,導致基于無監督學習方法的消歧準確度不高,進而導致搜索的準確度不高。
技術實現要素:
本發明實施例的目的在于提供一種實體消歧方法及裝置,以提高搜索的準確度。
為達到上述目的,本發明實施例公開了一種實體消歧方法,方法包括:
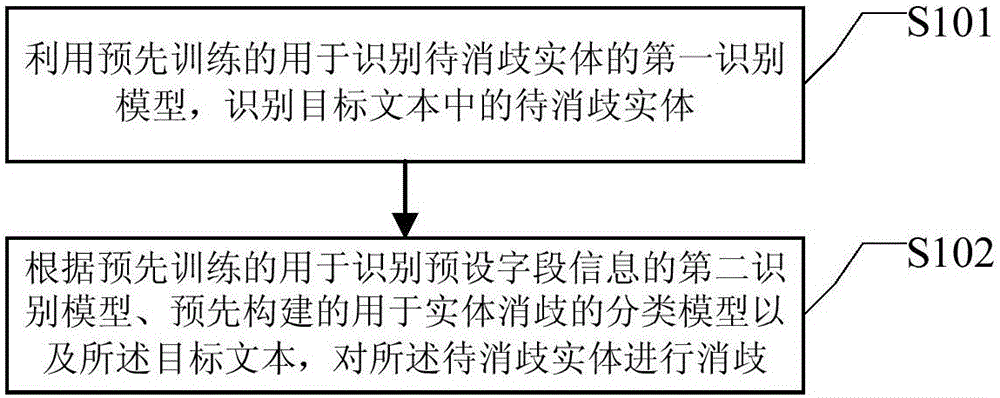
利用預先訓練的用于識別待消歧實體的第一識別模型,識別目標文本中的待消歧實體;
根據預先訓練的用于識別預設字段信息的第二識別模型、預先構建的用于實體消歧的分類模型以及所述目標文本,對所述待消歧實體進行消歧。
較佳的,所述根據預先訓練的用于識別預設字段信息的第二識別模型、預先構建的用于實體消歧的分類模型以及所述目標文本,對所述待消歧實體進行消歧,包括:
利用預先訓練的用于識別預設字段信息的第二識別模型,從所述目標文本中識別所述待消歧實體上下文中的預設字段信息;
計算所識別的預設字段信息與所述待消歧實體的每一義項的預設字段信息的匹配度;
根據所述匹配度以及所述分類模型,對所述待消歧實體進行消歧。
較佳的,所述根據匹配度以及所述分類模型,對所述待消歧實體進行消歧,包括:
將最高匹配度對應的義項,確定為所述待消歧實體的實際義項。
較佳的,所述根據匹配度以及所述分類模型,對所述待消歧實體進行消歧,包括:
在所有匹配度中存在不小于預設第一閾值的匹配度的情況下,將匹配度不小于預設第一閾值對應的義項,確定為所述待消歧實體的實際義項。
較佳的,所述根據匹配度以及所述分類模型,對所述待消歧實體進行消歧,還包括:
在所有匹配度均小于預設第一閾值的情況下,根據所述分類模型、所述待消歧實體的每一義項、所述待消歧實體的上下文詞,對所述待消歧實體進行消歧。
為達到上述目的,本發明實施例公開了一種實體消歧裝置,裝置包括:
識別模塊,用于利用預先訓練的用于識別待消歧實體的第一識別模型,識別目標文本中的待消歧實體;
消歧模塊,用于根據預先訓練的用于識別預設字段信息的第二識別模型、預先構建的用于實體消歧的分類模型以及所述目標文本,對所述待消歧實體進行消歧。
較佳的,所述消歧模塊,包括:
識別單元,用于利用預先訓練的用于識別預設字段信息的第二識別模型,從所述目標文本中識別所述待消歧實體上下文中的預設字段信息;
計算單元,用于計算所識別的預設字段信息與所述待消歧實體的每一義項的預設字段信息的匹配度;
消歧單元,用于根據所述匹配度以及所述分類模型,對所述待消歧實體進行消歧。
較佳的,所述消歧單元,具體用于:
將最高匹配度對應的義項,確定為所述待消歧實體的實際義項。
較佳的,所述消歧單元,具體用于:
在所有匹配度中存在不小于預設第一閾值的匹配度的情況下,將匹配度不小于預設第一閾值對應的義項,確定為所述待消歧實體的實際義項。
較佳的,所述消歧單元,還具體用于:
在所有匹配度均小于預設第一閾值的情況下,根據所述分類模型、所述待消歧實體的每一義項、所述待消歧實體的上下文詞,對所述待消歧實體進行消歧。
由上述的技術方案可見,本發明實施例提供的一種實體消歧方法及裝置,利用預先訓練的用于識別待消歧實體的第一識別模型,識別目標文本中的待消歧實體;根據預先訓練的用于識別預設字段信息的第二識別模型、預先構建的用于實體消歧的分類模型以及所述目標文本,對所述待消歧實體進行消歧。
可見,預先構建多個實體識別和分類模型,利用數據庫作為唯一數據源,無需進行人工標注訓練數據,不再需要標注集,解決了沒有出現在標注集中的歧義詞的消歧問題,也節省了人工成本。而且可以通過數據庫自動抽取待消歧實體的不同義項和義項特征,義項類別與實際的義項類別可以一一對應,提高了實體消歧的準確度,進而提高了搜索的準確度。
當然,實施本發明的任一產品或方法必不一定需要同時達到以上所述的所有優點。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例提供的一種實體消歧方法的流程示意圖;
圖2為本發明實施例提供的一種實體消歧裝置的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
下面首先對本發明實施例提供的一種實體消歧方法進行詳細說明。
參見圖1,圖1為本發明實施例提供的一種實體消歧方法的流程示意圖,可以包括如下步驟:
S101,利用預先訓練的用于識別待消歧實體的第一識別模型,識別目標文本中的待消歧實體;
具體的,命名實體(簡稱實體)是指人名、機構名、地名以及其他所有以名稱為標識的實體。其中,待消歧實體可以為音樂實體、影視劇實體等等。利用中文分詞技術對目標文本進行分詞,抽取目標文本中的實體詞和實體上下文詞,將實體詞和實體上下文詞輸入預先訓練好的第一識別模型,識別出目標文本的待消歧實體,以便后續對待消歧實體進行消歧。例如,對于目標文本“非誠勿擾電影第二部”,對該文本分詞后得到實體詞“非誠勿擾”,上下文詞為“電影”和“第二部”。將“非誠勿擾”、“電影”和“第二部”輸入第一識別模型,從而識別出待消歧實體為“非誠勿擾”。其中,中文分詞技術為現有技術,本發明實施例在此不對其進行贅述。
具體的,以待消歧實體為影視劇實體為例,預先訓練用于識別待消歧實體的第一識別模型的過程可以為:從視頻數據庫中抽取所有影視劇實體名稱,將影視劇實體名稱與分詞系統中的普通詞典對比,得到沒有在普通詞典中出現的影視劇實體列表(記為L),L即為無歧義的影視劇實體列表。利用視頻數據庫中的所有視頻標題,將包含L中無歧義影視劇實體的視頻標題作為樣本,訓練第一識別模型。本發明實施例可以使用基于向量空間模型的相似度匹配技術,對上述樣本抽取并統計影視劇實體的上下文特征。可以使用基于模板的特征抽取技術抽取樣本中影視劇實體的上下文特征,然后可以使用TF-IDF技術(用于信息檢索與數據挖掘的加權技術)統計抽取的特征,最終得到可用于識別待消歧實體的第一識別模型。其中,基于向量空間模型的相似度匹配技術、基于模板的特征抽取技術以及TF-IDF(term frequency–inverse document frequency)技術均為現有技術,本發明實施例在此不對其進行贅述。
S102,根據預先訓練的用于識別預設字段信息的第二識別模型、預先構建的用于實體消歧的分類模型以及所述目標文本,對所述待消歧實體進行消歧。
具體的,以待消歧實體為影視劇實體為例,預設字段可以為特定字段,例如頻道、年代和語言版本等。預先訓練用于識別預設字段信息的第二識別模型的過程可以為:從視頻數據庫獲取所有影視劇實體的名稱,將同一名稱(W)的不同影視劇實體聚在一起,確定為該名稱的不同義項(例如:W#1表示影視劇名稱W的第一個義項、W#2表示影視劇名稱W的第二個義項,以此類推)。
具體的,在獲取目標影視劇實體的名稱時,有些影視劇可能存在多個名稱,或者有別名、簡稱等。例如,江蘇衛視的綜藝節目《非誠勿擾》在視頻數據庫中的完整名稱為“緣來非誠勿擾”,而人們習慣成為“非誠勿擾”,所以在視頻標題中或者用戶查詢詞中的“非誠勿擾”很多都是指的“緣來非誠勿擾”,這種情況下可以獲取該影視劇實體的別名“非誠勿擾”,確定為目標影視劇實體的名稱。有的影視劇實體名稱包含一些附加信息,例如有一條影視劇實體的名稱為“笑傲江湖呂頌賢版”,而該影視劇實體的別名中沒有“笑傲江湖”,因此如果不做特殊處理,該條實體無法成為一個義項。本發明實施例可以使用實體識別模塊加模板匹配的方式進行處理。實體識別模塊能對影視劇實體的標題進行分詞并識別其中的影視劇名實體,例如:識別“笑傲江湖呂頌賢版”中的“笑傲江湖”為影視劇名實體,標記為“nz_ALBUM”,“nz”表示詞性為實體,ALBUM表示實體類型為影視劇。本發明實施例配置了一些模板,例如:“nz_ALBUM+人名(版)”、“nz_ALBUM+年代(版)”、“nz_ALBUM+之**”等等。當影視劇實體的標題匹配某個模板時,將nz_ALBUM部分抽取出確定為該影視劇實體的別名用于義項抽取,例如上文中的“笑傲江湖呂頌賢版”符合實例模板“nz_ALBUM+人名(版)”,所以抽取“笑傲江湖”確定為其別名。
具體的,影視劇名實體上下文存在大量表示影視劇特定字段(如:頻道、年代、語言版本等)的特征,這些特征對于匹配具體義項實體時是非常有用的,例如上文提到的“非誠勿擾”有一個電影版本的實體和一個綜藝版本的實體,如果文本為“非誠勿擾電影第二部”,此時頻道特征“電影”可以用來確定應該匹配的義項實體為“非誠勿擾(電影)”。
具體的,對于頻道特征的抽取,首先從視頻數據庫獲取無頻道歧義的影視劇名,具體地,可以抽取僅在一個頻道中存在實體的影視劇名即無頻道歧義影視劇名,例如“花千骨”只有電視劇頻道一個實體,則將“花千骨”確定為無頻道歧義的電視劇頻道數據。使用這些無頻道歧義的影視劇實體,再次利用視頻數據庫,抽取并統計各頻道影視劇實體的上下文特征,得到頻道識別的特征,例如電影頻道的“電影版”、“影院版”、“票房”等特征。在實際應用中,可以使用卡方檢驗技術、TF-IDF技術(用于信息檢索與數據挖掘的加權技術)以及人工整理的方法,抽取并統計各頻道影視劇實體的上下文特征。其中,年代、語言版本等特定字段的特征抽取可以使用正則表達式技術及人工整理的方法就可以完成,例如年代特征“*2016”、“83版”等,語言版本特征“粵語版”、“國粵雙語”、“國語”等。其中,卡方檢驗技術、TF-IDF技術及正則表達式技術均為現有技術,本發明實施例在此不對其進行贅述。
具體的,以待消歧實體為影視劇實體為例,預先構建用于實體消歧的分類模型的過程可以為:
抽取初始義項特征:抽取出待消歧實體不同義項的字段信息(如:導演、演員、角色)作為義項的初始特征,例如:抽取非誠勿擾(綜藝)的字段信息,得到該義項的初始特征:“孟非”(主持人)、“黃菡”(嘉賓)、“樂嘉”(嘉賓)、“江蘇衛視”(播出頻道)等;抽取非誠勿擾(電影)的字段信息,得到該義項的初始特征:“馮小剛”(導演)、“葛優”(演員)、“舒淇”(演員)、“范偉”(演員)等;
語料聚合:在得到了待消歧實體的不同義項以及不同義項的初始特征,此時,消歧可以看作分類問題,歧義實體的不同義項即為分類類別,義項的初始特征即為類別的初始特征。分類問題中,最主要的是需要大量的語料數據,可以通過初始義項特征從視頻數據庫中聚合語料,然后使用語料繼續擴展義項特征,如此迭代使得義項特征和義項語料不斷豐富,其中,語料是指在統計自然語言處理中實際上不可能觀測到大規模的語言實例,人們簡單地用文本作為替代,并把文本中的上下文關系作為現實世界中語言的上下文關系的替代品。我們把一個文本集合稱為語料庫(Corpus),在本發明實施例中聚合的語料可以為視頻數據庫中包含待消歧實體的視頻數據。語料聚合問題已轉化為語料分類的問題,可以使用基于向量空間模型的相似度匹配技術來聚合語料,該項技術為現有技術,本發明實施例在此不對其進行贅述;
義項特征擴充:在通過不同義項的初始特征從視頻數據庫中聚合語料后,待消歧實體的不同義項下都對應一批屬于該義項類別的語料數據,即為視頻數據(包括標題、字段信息、評論、彈幕等)。可以使用卡方檢驗和TF-IDF技術,構建特征抽取模型對這些視頻數據進行特征抽取,用抽取的特征來擴充義項的初始特征。在實際應用中,可以循環執行幾次語料聚合和義項特征擴充,不斷擴充義項特征,最終得到包含待消歧實體的不同義項和義項特征的分類模型。
具體的,在實際應用中,可以利用預先訓練的用于識別預設字段信息的第二識別模型,從所述目標文本中識別所述待消歧實體上下文中的預設字段信息;計算所識別的預設字段信息與所述待消歧實體的每一義項的預設字段信息的匹配度;根據所述匹配度以及所述分類模型,對所述待消歧實體進行消歧。
具體的,在實際應用中,可以將最高匹配度對應的義項,確定為所述待消歧實體的實際義項。
示例性的,對于目標文本“非誠勿擾電影第二部”,待消歧實體為“非誠勿擾”,待消歧實體上下文為“電影”和“第二部”。利用第二識別模型,從視頻數據庫中抽取待消歧實體的不同義項,得到兩個義項:其一是葛優主演的電影《非誠勿擾》(表示為“非誠勿擾#1”),其二是江蘇衛視的一檔綜藝節目《緣來非誠勿擾》,常被稱為“非誠勿擾”(表示為“非誠勿擾#2”)。利用第二識別模型,識別待消歧實體上下文中的預設字段信息為“電影”,計算所識別的預設字段信息“電影”與待消歧實體“非誠勿擾”的每一義項的預設字段信息的匹配度,得到的匹配度分別為90%和20%,將最高匹配度對應的義項“非誠勿擾#1”,確定為待消歧實體“非誠勿擾”的實際義項。
具體的,在實際應用中,可以在所有匹配度中存在不小于預設第一閾值的匹配度的情況下,將匹配度不小于預設第一閾值對應的義項,確定為所述待消歧實體的實際義項。
示例性的,對于目標文本“A電影中文版”,待消歧實體為A,利用第二識別模型,從視頻數據庫抽取A的不同義項為:A#1(特定字段信息:電影、國語版)、A#2(特定字段信息:電視劇、國語版)、A#3(特定字段信息:電影、粵語版)、A#4(特定字段信息:電視劇、粵語版),計算所識別的特定字段信息“電影”“中文版”與待消歧實體A的每一義項的特定字段信息的匹配度,得到的匹配度分別為90%、30%、85%、20%,預設第一閾值設為80%,則將匹配度不小于預設第一閾值對應的義項A#1和A#3,確定為待消歧實體A的實際義項。
具體的,在實際應用中,可以在所有匹配度均小于預設第一閾值的情況下,根據所述分類模型、所述待消歧實體的每一義項、所述待消歧實體的上下文詞,對所述待消歧實體進行消歧。
示例性的,對于目標文本“非誠勿擾男嘉賓被滅燈”,待消歧實體為“非誠勿擾”,從視頻數據庫抽取“非誠勿擾”的不同義項,得到兩個義項:其一是葛優主演的電影《非誠勿擾》(表示為“非誠勿擾#1”),其二是江蘇衛視的一檔綜藝節目《緣來非誠勿擾》,常被稱為“非誠勿擾”(表示為“非誠勿擾#2”)。抽取待消歧實體的上下文詞“男嘉賓”和“滅燈”,將待消歧實體的上下文詞輸入分類模型,在分類模型中將上下文詞數據“男嘉賓”和“滅燈”與分類模型中“非誠勿擾”的不同義項以及義項特征數據進行匹配,并計算匹配度,將匹配度最大且高于預設第二閾值的義項,確定為待消歧實體的實際義項。例如,計算得到待消歧實體的上下文詞與“非誠勿擾#1”的義項特征數據的匹配度為20%,與“非誠勿擾#2”的義項特征數據的匹配度為85%,預設第二閾值設為75%,則將“非誠勿擾#2”確定為目標文本“非誠勿擾男嘉賓被滅燈”中待消歧實體“非誠勿擾”的實際義項。
可見,預先構建多個實體識別和分類模型,利用數據庫作為唯一數據源,無需進行人工標注訓練數據,不再需要標注集,解決了沒有出現在標注集中的歧義詞的消歧問題,也節省了人工成本。而且可以通過數據庫自動抽取待消歧實體的不同義項和義項特征,義項類別與實際的義項類別可以一一對應,提高了實體消歧的準確度,進而提高了搜索的準確度。
參見圖2,圖2為本發明實施例提供的一種實體消歧裝置的結構示意圖,與圖1所示的流程相對應,該消歧裝置可以包括:識別模塊201、消歧模塊202。
識別模塊201,用于利用預先訓練的用于識別待消歧實體的第一識別模型,識別目標文本中的待消歧實體;
消歧模塊202,用于根據預先訓練的用于識別預設字段信息的第二識別模型、預先構建的用于實體消歧的分類模型以及所述目標文本,對所述待消歧實體進行消歧。
具體的,消歧模塊202,可以包括:識別單元、計算單元和消歧單元(圖中未示出);
識別單元,用于利用預先訓練的用于識別預設字段信息的第二識別模型,從所述目標文本中識別所述待消歧實體上下文中的預設字段信息;
計算單元,用于計算所識別的預設字段信息與所述待消歧實體的每一義項的預設字段信息的匹配度;
消歧單元,用于根據所述匹配度以及所述分類模型,對所述待消歧實體進行消歧。
具體的,所述消歧單元,具體可以用于:
將最高匹配度對應的義項,確定為所述待消歧實體的實際義項。
具體的,所述消歧單元,具體可以用于:
在所有匹配度中存在不小于預設第一閾值的匹配度的情況下,將匹配度不小于預設第一閾值對應的義項,確定為所述待消歧實體的實際義項。
具體的,所述消歧單元,還具體可以用于:
在所有匹配度均小于預設第一閾值的情況下,根據所述分類模型、所述待消歧實體的每一義項、所述待消歧實體的上下文詞,對所述待消歧實體進行消歧。
可見,預先構建多個實體識別和分類模型,利用數據庫作為唯一數據源,無需進行人工標注訓練數據,不再需要標注集,解決了沒有出現在標注集中的歧義詞的消歧問題,也節省了人工成本。而且可以通過數據庫自動抽取待消歧實體的不同義項和義項特征,義項類別與實際的義項類別可以一一對應,提高了實體消歧的準確度,進而提高了搜索的準確度。
需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
本說明書中的各個實施例均采用相關的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對于裝置實施例而言,由于其基本相似于方法實施例,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
本領域普通技術人員可以理解實現上述方法實施方式中的全部或部分步驟是可以通過程序來指令相關的硬件來完成,所述的程序可以存儲于計算機可讀取存儲介質中,這里所稱得的存儲介質,如:ROM/RAM、磁碟、光盤等。
以上所述僅為本發明的較佳實施例而已,并非用于限定本發明的保護范圍。凡在本發明的精神和原則之內所作的任何修改、等同替換、改進等,均包含在本發明的保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!