一種水質圖像分類方法與流程
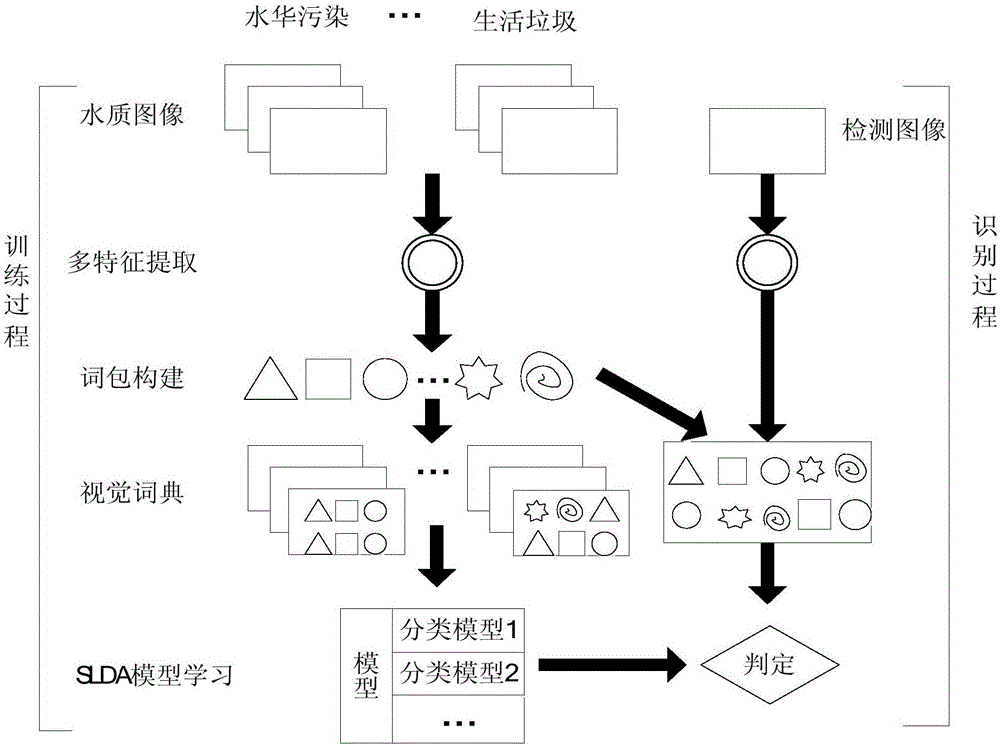
本發明涉及一種圖像分類技術,尤其是涉及一種水質圖像分類方法。
背景技術:
:近年來隨著人們對水環境越來越重視,水資源保護越來越受到關注。對于水資源監測,目前常用的方法有生物式水質監測方法和利用各種傳感器進行水質監測的方法。生物式水質監測方法,例如德國的BBE公司研發的基于動態圖像理解的生物式水質監測系統,其通過水蚤、魚類的行為習慣和分布狀態受水質的影響實現對水質的評價,但是這種方法受實驗環境約束,在復雜的自然水環境下,易產生誤判,同時不能對污染源做出判定。利用各種傳感器進行水質監測的方法,例如利用溫度、溶氧度、PH值等傳感器,這種方法可以得到的水體質量的精確數據,但是成本相對較高且測量參數有限,直觀性不足。運用圖像分析技術進行水質評估,具有成本低廉、通用性強、數據采集便捷等優點,通過調查和采集,水質圖像區域分布具有不規則性,出現的水質異常部分作為感興趣區域,這些感興趣區域作為分類的主要依據。對感興趣區域劃分,大致可分為:正常,水華污染,水葫蘆污染,工廠排污污染,生活垃圾污染5種水質。正常的水質應該通透,無異常顏色,且具有斑駁感。水華污染的水質,顏色呈綠色,通透性弱,有粒狀綠色區域。水葫蘆污染的水質,水面上具有水葫蘆區域。工廠排污的水質,主要是顏色出現異常,甚至會產生許多白色氣泡。生活垃圾污染的水質,水面漂著大量無規則物體,水體渾濁。可見五類水質圖像具有明顯不同的特點。水質圖像分類的難點有兩方面:一是光照變化會使得水面發生很大變化,例如水體的顏色在不同光照下有明顯不同;另一方面,污染區域的紋理在復雜的水情下也會產生變化,例如水華和水葫蘆的紋理容易產生混淆。技術實現要素:本發明所要解決的技術問題是提供一種準確有效的水質圖像分類方法。本發明解決上述技術問題所采用的技術方案為:一種水質圖像分類方法,使用多特征融合的詞包對水質圖像進行分類,具體包括以下步驟:①水質圖像采集,標記水質圖像類別標簽,以指示訓練圖像屬于正常,水華污染,水葫蘆污染,工廠排污污染和生活垃圾污染五種圖像中的哪個類別;②對水質圖像使用圖像金字塔進行關鍵點檢測,并對水質圖像中的關鍵點進行方向梯度直方圖與顏色特征的提取,融合成描述當前關鍵點的特征向量;③使用狄利克雷混合模型進行視覺詞典學習,對圖像生成的各關鍵點特征向量進行編碼生成圖像詞包;④使用圖像詞包和類別標簽訓練監督型主題模型,得到監督型主題模型參數,并將訓練得到的監督型主題模型用于后續的分類任務中;⑤將需要分類的水質圖像作為輸入圖像,根據步驟②的方法對該輸入圖像進行特征提取操作,并量化成詞包,然后使用步驟④得到的訓練后的監督型主題模型進行分類,得到輸入圖像所屬的類別。所述步驟①的具體過程為:①-1、采用高清攝像機或照相機對水面圖像進行采集,將采集的水質圖像分成5類,分別為正常,水華污染,水葫蘆污染,工廠排污污染和生活垃圾污染;①-2、對采集的水質圖像進行初步處理,去掉包含人和船只的圖像。對于出現兩類及以上污染的水質圖像,將其所屬污染區域分割開,作為多幅訓練圖像;①-3、使用圖像縮放方法,對圖像大小進行調整,將其調整為400*400大小的圖像;①-4、對5類水質圖像給定訓練標簽:正常標簽為1,水華污染標簽為2,水葫蘆污染標簽為3,工廠排污污染標簽為4,生活垃圾污染標簽為5。所述步驟②的具體過程為:②-1、使用圖像金字塔標定水質圖像的關鍵點;②-2、計算以當前關鍵點為中心的24*24鄰域窗口內的所有像素點的R、G、B三個顏色通道顏色均值;②-3、將256顏色通道轉換為64顏色通道,將第c個顏色通道的顏色均值映射到64色顏色空間后的值記為blockc,其中,1≤c≤3,c=1時第c個顏色通道為R顏色通道,c=2時第c個顏色通道為G顏色通道,c=3時第c個顏色通道為B顏色通道,block表示第c個顏色通道的顏色均值,colork表示64色顏色空間中的第k種顏色,1≤k≤64,符號“||||”為求歐氏距離符號,表示取使得||block-colork||的值最小的一種顏色,將最小的顏色取為當前通道的顏色值,三個通道共形成三個顏色特征;②-4、采用Gamma校正法對輸入圖像進行顏色空間的歸一化;②-5、將當前關鍵點所在的24*24的像素區域分化成16個cell,(6*6像素/cell),計算單個cell中每個像素的梯度方向和梯度大小這里x和y表示該像素點的坐標,f(x,y)表示像素在x和y的灰度值,統計每個cell的梯度直方圖,形成每個cell的描述;將相鄰4*4的cell組成一個block,并將一個block內所有的cell的特征串聯起來,得到該關鍵點的方向梯度直方圖特征描述。所述步驟③的具體過程為:設模型的后驗概率為K為取值1000,將其作為每個關鍵點可能屬于的類別數,是參數為γk,1,γk,2的貝塔分布,Vk是該分布的隨機變量,為一實值隨機數;是參數為的高斯威沙特分布,其中為一個35維的列向量,ak為實值,Bk為35*35的矩陣,I為35*35的單位矩陣,是該分布的隨機變量,分別取兩個隨機向量,一個是35維的列向量,一個是35*35的矩陣;是參數為的多項式分布,表示第n個樣本屬于1000個類別中第1個類別的概率,zn是該分布的隨機變量,為一實值整數隨機數;③-1、將類別數K作為初始化類別數,給定一個初始化模型參數λ,λ取高斯威沙特分布的四個參數,分別為均值參數0,方差矩陣,取35*35的方差矩陣I,自由度參數D,取值為35,尺度矩陣,取35*35的單位矩陣I,隨機初始化參數表示每個樣本屬于K個樣本的概率,總概率相加為1;③-2、對于訓練樣本中的每個關鍵點,記其特征為Xi,計算后驗概率中的貝塔分布參數以及共軛分布參數γk,1=1+Σiφzi,k]]>γk,2=α+ΣiΣj>kφzi,j]]>ak=2+D+Σiφzi,k]]>vuk=(I+BkΣiφzi,k)-1(akBkΣiφzi,kXi)]]>Bk=((Σiφzi,k+1)I+Σiφzi,k(Xi-vuk)(Xi-vuk)T)-1]]>其中D為關鍵點特征維數,取值為35,表示第i個樣本屬于k類別的后驗概率,γk,1,γk,2是后驗概率q(V,θ*,Z)中貝塔分布的兩個參數,I表示q(V,θ*,Z)中高斯威沙特分布的四個參數,其中I為單位矩陣,k從1取到1000,α為模型參數,取值為0.001;③-3、對于每個樣本,根據以下公式求該樣本對應每個類別的概率:φzi,k=exp(ψ(γk,1)-ψ(γk,1+γk,2)+Eq(logf(Xi|θzi,k*))+Σj<k(ψ(γj,2)-ψ(γj,1+γj,2)))]]>其中的取值如下:Eq(logf(Xi|θzi,k*))=(-D2log2π+12(Σdψ(ak+1-d2)+Dlog2+log|Bk|)-12((Xi-vuk)akBk(Xi-vuk)+ak*tr(Bk))-log2πe)]]>D為關鍵點特征維數,取值為35,e為自然底數,π為圓周率常數,ψ()為伽馬函數的二階導數。是參數為的高斯分布,包含兩個參數,分別是均值向量和方差矩陣;③-4、觀察的變化情況,若該值不變,則停止更新,否則轉③-2重新計算,當停止更新時,記住此時的變分后驗概率參數γk,1,γk,2,對于對應的所有N個樣本,用狄利克雷混合模型估算得出N個樣本所屬類別,并將不同的類別數記為H,然后將H個不同的類別記為視覺詞典;③-5、對于每個關鍵點特征Xi,使用訓練得到的估算特征Xi屬于每個類別的后驗概率:φzi,k=exp(ψ(γk,1)-ψ(γk,1+γk,2)+Eq(logf(Xi|θzi,k*))+Σj<k(ψ(γj,2)-ψ(γj,1+γj,2)))]]>Eq(logf(Xi|θzi,k*))=(-D2log2π+12(Σdψ(ak+1-d2)+Dlog2+log|Bk|)-12((Xi-vk)akBk(Xi-vk)+ak*tr(Bk))-log2πe)]]>③-6、找到當前關鍵點特征Xi在視覺詞典中所屬的視覺單詞wi,估算公式如下:wi=argmaxkφzi,k]]>在該編碼中,找到使得最大的k值將其作為當前關鍵點特征Xi在視覺詞典中的視覺單詞wi,將其作為當前關鍵點特征Xi所屬的視覺單詞;③-7、對于每幅水質圖像,首先使用圖像金字塔得到所有的關鍵點,然后得到每個關鍵點的35維特征向量,重復步驟③-5、③-6得到所有關鍵點屬于詞典中的哪個視覺單詞,形成水質圖像的視覺詞包。所述步驟④、⑤的具體過程為:④-1、輸入每一副圖像的視覺詞包,將其記為r,以及對應的水質圖像類別標簽,將其記為C;④-2、在監督型主題模型中,使用變分方法學習得到訓練后的監督型主題模型;⑤-1、將攝像頭采集的水質圖像進行特征提取,得到圖像的每個關鍵點特征Xi的特征向量;⑤-2、對于每個關鍵點特征Xi,估算Xi屬于每個類別的概率:φzi,k=exp(ψ(γk,1)-ψ(γk,1+γk,2)+Eq(logf(Xi|θzi,k*))+Σj<k(ψ(γj,2)-ψ(γj,1+γj,2)))]]>其中的取值如下:Eq(logf(Xi|θzi,k*))=(-D2log2π+12(Σdψ(ak+1-d2)+Dlog2+log|Bk|)-12((Xi-vk)akBk(Xi-vk)+ak*tr(Bk))-log2πe)]]>然后計算當前關鍵點特征Xi在視覺詞典中所屬的視覺單詞wi,估算公式如下:wi=argmaxkφzi,k]]>對當前水質圖像的所有關鍵點特征Xi,計算其所屬視覺單詞wi,然后形成圖像詞包;⑤-3、將該幅水質圖像的圖像詞包代入訓練后的監督型主題模型中,得到類別標簽。與現有技術相比,本發明的優點在于:1)本發明方法首先采用高斯金字塔檢測圖像中的極值點,這樣有利于消除圖像特征中的冗余像素,提高識別精度;2)在建立視覺詞典時,本發明方法使用狄利克雷混合模型進行水質圖像視覺詞典生成,相比于傳統視覺詞典學習中的傳統的確定大小的模型相比,該算法能自動估算視覺詞典數目,有利于消除視覺詞典中視覺單詞間的相關和冗余性;3)在進行識別時,利用視覺詞典首先得到圖像視覺詞包模型,然后再訓練監督型主題模型,引入該模型使得水質圖像識別框架在統計角度描述了水質圖像中的隨機因素,同時在語義層次描述水質圖像的各類特征,從而提高水質圖像識別率。附圖說明圖1為本發明方法水質圖像分類過程示意圖;圖2為本發明方法中不同尺度的高斯金字塔描述示意圖;圖3為本發明監督型主題模型圖示意圖;圖4為狄利克雷混合模型概率圖示意圖;圖5為不同污染水質的示意圖片。具體實施方式以下結合附圖實施例對本發明作進一步詳細描述。一種水質圖像分類方法,使用多特征融合的詞包對水質圖像進行分類,具體包括以下步驟:①-1、采用高清攝像機或照相機,對正常水面、水華污染水面、水葫蘆污染水面、工廠排污污染水面和生活垃圾污染水面分別進行M次圖像采集,得到每種水面的M幅水質圖像,將采集的水質圖像分成5類,分別為正常,水華污染,水葫蘆污染,工廠排污污染和生活垃圾污染;在圖像采集時,正常水面、水華污染水面、水葫蘆污染水面、工廠排污污染水面和生活垃圾污染水面是通過人眼判定的,對每種水質圖像采集最好在多個不同的地方采集,在此要求采集圖片數目M≥100,這樣可有效提高該水質圖像分類方法的魯棒性,在此基礎上,M越大越好。①-2、對采集的水質圖像進行初步處理,去掉包含人和船只的圖像。對于出現兩類及以上污染的水質圖像,將其所屬污染區域分割開,作為多幅訓練圖像;①-3、使用現有的圖像縮放方法,對得到的所有水質圖像大小進行調整,將其調整為像素為400*400大小的圖像,使所有水質圖像的大小一致;①-4、對5類水質圖像給定訓練標簽:正常標簽為1,水華污染標簽為2,水葫蘆污染標簽為3,工廠排污污染標簽為4,生活垃圾污染標簽為5;②-1、使用圖像金字塔標定水質圖像的關鍵點,得到每幅水質圖像中的每個關鍵點的位置信息,圖2給出了采用高斯金字塔提取關鍵點的位置信息示意圖;②-2、計算以當前關鍵點為中心的24*24鄰域窗口內的所有像素點的R、G、B三個顏色通道顏色均值;②-3、將256顏色通道轉換為64顏色通道,將第c個顏色通道的顏色均值映射到64色顏色空間后的值記為blockc,其中,1≤c≤3,c=1時第c個顏色通道為R顏色通道,c=2時第c個顏色通道為G顏色通道,c=3時第c個顏色通道為B顏色通道,block表示第c個顏色通道的顏色均值,colork表示64色顏色空間中的第k種顏色,1≤k≤64,符號“||||”為求歐氏距離符號,表示取使得||block-colork||的值最小的一種顏色,將最小的顏色取為當前通道的顏色值,三個通道共形成三個顏色特征;②-4、采用Gamma校正法對輸入圖像進行顏色空間的歸一化;②-5、將當前關鍵點所在的24*24的像素區域分化成16個cell,(6*6像素/cell),計算單個cell中每個像素的梯度方向和梯度大小這里x和y表示該像素點的坐標,f(x,y)表示像素在x和y的灰度值,統計每個cell的梯度直方圖,形成每個cell的描述;將相鄰4*4的cell組成一個block,并將一個block內所有的cell的特征串聯起來,得到該關鍵點的方向梯度直方圖特征描述;設模型的后驗概率為K為取值1000,將其作為每個關鍵點可能屬于的類別數,是參數為γk,1,γk,2的貝塔分布,Vk是該分布的隨機變量,為一實值隨機數;是參數為的高斯威沙特分布,其中為一個35維的列向量,ak為實值,Bk為35*35的矩陣,I為35*35的單位矩陣,是該分布的隨機變量,分別取兩個隨機向量,一個是35維的列向量,一個是35*35的矩陣;是參數為的多項式分布,表示第n個樣本屬于1000個類別中第1個類別的概率,zn是該分布的隨機變量,為一實值整數隨機數;③-1、將類別數K作為初始化類別數,給定一個初始化模型參數λ,λ取高斯威沙特分布的四個參數,分別為均值參數0,35*35的方差單位矩陣I,自由度參數D,取值為35,尺度矩陣,取為35*35的單位矩陣I,隨機初始化參數表示每個樣本屬于K個樣本的概率,總概率相加為1;③-2、對于訓練樣本中的每個關鍵點,記其特征為關鍵點特征Xi,計算后驗概率中的貝塔分布參數以及共軛分布參數γk,1=1+Σiφzi,k]]>γk,2=α+ΣiΣj>kφzi,j]]>ak=2+D+Σiφzi,k]]>vuk=(I+BkΣiφzi,k)-1(akBkΣiφzi,kXi)]]>Bk=((Σiφzi,k+1)I+Σiφzi,k(Xi-vuk)(Xi-vuk)T)-1]]>其中D為關鍵點特征維數,取值為35,表示第i個樣本屬于k類別的后驗概率,γk,1,γk,2是后驗概率q(V,θ*,Z)中貝塔分布的兩個參數,I表示q(V,θ*,Z)中高斯威沙特分布的四個參數,其中I為單位矩陣,k從1取到1000,α為模型參數,取值為0.001;③-3、對于每個關鍵點Xi,根據以下公式求該樣本對應每個類別的概率:φzi,k=exp(ψ(γk,1)-ψ(γk,1+γk,2)+Eq(logf(Xi|θzi,k*))+Σj<k(ψ(γj,2)-ψ(γj,1+γj,2)))]]>其中的取值如下:Eq(logf(Xi|θzi,k*))=(-D2log2π+12(Σdψ(ak+1-d2)+Dlog2+log|Bk|)-12((Xi-vuk)akBk(Xi-vuk)+ak*tr(Bk))-log2πe)]]>D為關鍵點特征維數,e為自然常數,ψ()為伽馬函數的二階導數。是參數為的高斯分布,包含兩個參數,分別是均值向量和方差矩陣;③-4、觀察的變化情況,若該值不變,則停止更新,否則轉③-2重新計算,當停止更新時,記住此時的變分后驗概率參數γk,1,γk,2,對于對應的所有N個樣本,用狄利克雷混合模型估算得出N個樣本所屬類別,并將不同的類別數為記為H,然后將H個不同的類別記為視覺詞典;③-5、對于每個關鍵點特征Xi,使用訓練得到的估算Xi屬于每個類別的后驗概率:φzi,k=exp(ψ(γk,1)-ψ(γk,1+γk,2)+Eq(logf(Xi|θzi,k*))+Σj<k(ψ(γj,2)-ψ(γj,1+γj,2)))]]>Eq(logf(Xi|θzi,k*))=(-D2log2π+12(Σdψ(ak+1-d2)+Dlog2+log|Bk|)-12((Xi-vk)akBk(Xi-vk)+a*tr(Bk))-log2πe)]]>③-6、找到當前關鍵點特征Xi在視覺詞典中所屬的視覺單詞wi,估算公式如下:wi=argmaxkφzi,k]]>在該編碼中,找到使得最大的k值將其作為當前關鍵點特征Xi在視覺詞典中的視覺單詞wi,將其作為當前關鍵點特征Xi所屬的視覺單詞;③-7、對于每幅水質圖像,首先使用圖像金字塔得到所有的關鍵點,然后得到每個關鍵點的35維特征向量,重復步驟③-5、③-6得到所有關鍵點屬于詞典中的哪個視覺單詞,形成水質圖像的視覺詞包;④-1、輸入每一副圖像的視覺詞包,將其記為r,以及對應的水質圖像類別標簽,將其記為C;④-2、在監督型主題模型中,使用變分方法學習得到監督型主題模型;⑤-1、將攝像頭采集的水質圖像進行特征提取,得到圖像的每個關鍵點特征Xi的特征向量;⑤-2、對于每個關鍵點特征Xi,估算Xi屬于每個類別的概率:φzi,k=exp(ψ(γk,1)-ψ(γk,1+γk,2)+Eq(logf(Xi|θzi,k*))+Σj<k(ψ(γj,2)-ψ(γj,1+γj,2)))]]>其中的取值如下:Eq(logf(Xi|θzi,k*))=(-D2log2π+12(Σdψ(ak+1-d2)+Dlog2+log|Bk|)-12((Xi-vk)akBk(Xi-vk)+a*tr(Bk))-log2πe)]]>然后計算當前關鍵點特征Xi在視覺詞典中所屬的視覺單詞wi,估算公式如下:wi=argmaxkφzi,k]]>對當前水質圖像的所有關鍵點特征Xi,計算其所屬視覺單詞wi,然后形成圖像詞包;⑤-3、將該幅水質圖像的圖像詞包代入訓練后的監督型主題模型中,得到類別標簽。上述實施例中,監督型主題模型及如何通過變分方法學習得到訓練后的監督型主題模型,采用現有技術《WangC,BleiD,LiFF.Simultaneousimageclassificationandannotation[C]//IEEEConferenceonComputerVision&PatternRecognition.2009:1903-1910.)》中的方法。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1