用于智能終端的語音控制方法及智能終端與流程
本公開一般涉及語音控制領域,尤其涉及用于智能終端的語音控制方法。
背景技術:
目前,智能終端上有很多語音助手,通過語音識別接入本地或者云服務中進行語音語料指令匹配,從而達到語音控制智能終端的功能。這樣的語音控制一般作為輸入法和檢索工具。例如:蘋果手機的siri語音控制功能,科大訊飛公司的語音輸入法等。
大多語音控制需要龐大的語料庫支撐,有時會導致指令匹配不準確,例如:當用戶說:“蘋果”時,語音匹配無法確定說的究竟是水果還是手機。同時進行大量語音語料匹配時,需要占用大量后臺資源。
技術實現要素:
鑒于現有技術中的上述缺陷或不足,期望提供一種準確率高且占用資源少的語音控制方法。為了實現上述的一個或多個目的,本申請提供了一種用于智能終端的語音控制方法及智能終端。
第一方面,提供一種用于智能終端的語音控制方法,所述方法包括:
確定與所述智能終端關聯的光標當前所處的應用場景,所述應用場景具有對應的語音指令集合;
獲取語音信息;
在所述應用場景對應的語音指令集合中確定與所述語音信息匹配的語音指令;以及
執行所述語音指令。
第二方面,提供一種智能終端,所述終端包括:
確定應用場景單元:確定與所述智能終端關聯的光標當前所處的應用場景,所述應用場景具有對應的語音指令集合;
獲取語音信息單元,用于獲取語音信息;
匹配單元,在所述應用場景對應的語音指令集合中確定與所述語音信息匹配的語音指令;以及
執行單元,執行所述語音指令。
根據本申請實施例提供的技術方案,通過確定應用場景縮小了語音指令匹配范圍,能夠解決語音指令匹配不準備和占用大量資源的問題。進一步的,根據本申請的某些實施例,通過引入光標資源,還能解決語音在位置控制上定位不精準的問題,獲得移動對象準確定位的效果。
附圖說明
通過閱讀參照以下附圖所作的對非限制性實施例所作的詳細描述,本申請的其它特征、目的和優點將會變得更明顯:
圖1示出了根據本申請一實施例的用于智能終端的語音控制方法的流程圖。
圖2a示出了根據本申請用于智能終端的語音控制識別方法的一應用場景示意圖。
圖2b示出了根據本申請用于智能終端的語音控制識別方法的另一應用場景示意圖。
圖3示出了根據本申請一實施例的智能終端的結構示意圖。
具體實施方式
下面結合附圖和實施例對本申請作進一步的詳細說明。可以理解的是,此處所描述的具體實施例僅僅用于解釋相關發明,而非對該發明的限定。另外還需要說明的是,為了便于描述,附圖中僅示出了與發明相關的部分。
需要說明的是,在不沖突的情況下,本申請中的實施例及實施例中的特征可以相互組合。下面將參考附圖并結合實施例來詳細說明本申請。
請參考圖1,示出了根據本申請一實施例的用于智能終端的語音控制方法的流程圖。
如圖1所示,在步驟101中,確定與所述智能終端關聯的光標當前所處的應用場景,所述應用場景具有對應的語音指令集合。
在一些優選實施例中,應用場景包括光標當前所指向的顯示區域內操控對象,還包括基于所述操控對象的人機交互,或者以所述操控對象為中心預定范圍內的人機交互。
下面為了便于說明結合實際應用場景來說明。
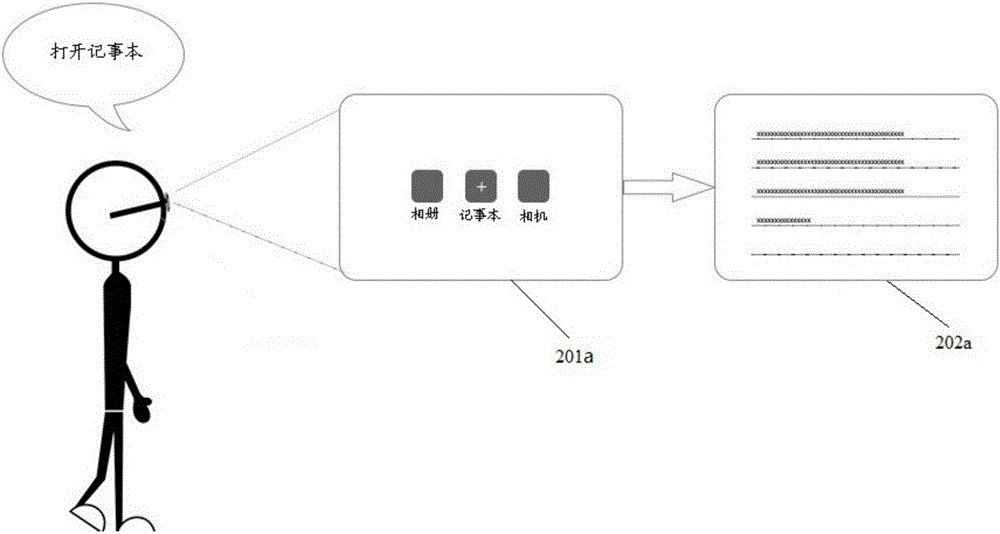
請參考圖2a,示出了根據本申請用于智能終端的語音控制識別方法的一應用場景示意圖。
如圖2a中所示,一個佩戴智能眼鏡的使用者進入了一主界面201a,主界面201a中包括有相冊、記事本和相機等應用軟件。智能終端接收使用者身體部位的移動控制光標移動,當光標移動到一個應用時,確定了該主界面的一操控對象,例如記事本。當前應用場景僅包含針對記事本的語音指令集合,例如打開記事本、刪除記事本、移動記事本等。
另外,使用者進入一個視頻播放應用(圖中未標出)時,針對當前播放的視頻,常用的操作有播放/暫停、音量增大/減小、快進/快退、切換至下一個視頻/退回至上一個視頻等。操控視頻播放的人機交互是一個應用場景,當前應用場景的上述操作對應的語音指令是該應用場景的語音指令集合,例如有播放、暫停、音量增大、音量減少、快進、快退、切換至下一個視頻和退回至上一個視頻等。
在不同領域,不同的應用軟件存在不同的操控指令,針對每個應用軟件設定相應的語音指令集合。在一個限定應用場景中進行語音控制,使指令指向性更強,占用系統資源少,且指令匹配更精準。
通過上述說明可以理解,確定與所述智能終端關聯的光標當前所處的應用場景包括:確定所述光標當前所指向的顯示區域內的操控對象;以及基于所述操控對象和/或以所述操控對象為中心預定范圍內的人機交互。本實施例中涉及的人機交互包括智能終端通過接收使用者身體部位移動信息實現的人機交互,還包括通過接收使用者語音信息實現的人機交互。
另外,圖2a的智能眼鏡僅是一種適用于本申請的智能終端,接收頭部移動信息來控制光標移動。所述的智能終端是接收使用者身體部位的移動信息控制光標移動的裝置,可以為可穿戴設備,例如指環式設備、手環式設備、頭戴式設備等。
接著,在步驟102中,獲取語音信息。
基于步驟101中的應用場景,智能終端通過麥克獲取使用者的語音信息。
接著,在步驟103中,在所述應用場景對應的語音指令集合中確定與所述語音信息匹配的語音指令。
接著參考圖2a,智能眼鏡接收使用者頭部移動信息,光標移動至記事本圖標區域,并接收到使用者發出“打開記事本”的信息。該應用場景中對應的語音指令集合包括打開記事本、刪除記事本、移動記事本等指令,智能眼鏡確定該語音指令集合中是否包含有所述“打開記事本”的語音信息。
最后,在步驟104中,執行所述語音指令。
在步驟103中,獲得判斷結果為語音指令集合中存在匹配的語音指令時,執行該語音指令。即如圖2a的應用場景的語音指令集合中包含有“打開記事本”的語音指令,智能眼鏡執行打開記事本指令,畫面202a為顯示了打開后的記事本。
請參考圖2b,示出了根據本申請用于智能終端的語音控制識別方法的另一應用場景示意圖。
如圖2b所示,智能眼鏡(圖中未標出)接收使用者頭部的移動信息,當前光標位于記事本應用區域,接收到智能者發出的“移動記事本”語音。當前應用場景的對應的語音指令集合包括打開記事本、刪除記事本、移動記事本等指令,智能眼鏡判斷該語音指令集合中是否包含有所述“移動記事本”的語音信息。當判斷結果為“是”時,執行移動指令,光標鎖定記事本圖標,記事本圖標隨著光標的移動而移動,接收到使用者下一個語音指令為“確定”時,記事本圖標結束移動。畫面202b顯示了移動完成后的主界面。
通過語音控制與隨身體部位移動而移動的光標控制的結合實現了傳統語音控制難以實現的移動操控。
另一方面,本申請還提供了一種智能終端300。
請參考圖3,示出了根據本申請一實施例的智能終端的結構示意圖;
如圖3所示,該終端包括:確定應用場景單元301,確定與所述智能終端關聯的光標當前所處的應用場景,所述應用場景具有對應的語音指令集合;獲取語音信息單元302,用于獲取語音信息;匹配單元303,在所述應用場景對應的語音指令集合中確定與所述語音信息匹配的語音指令;以及執行單元304,執行所述語音指令。
優選地,所述的智能終端是接收使用者身體部位的移動信息控制光標移動的裝置,可以為可穿戴設備,例如指環式設備、手環式設備、頭戴式設備等。圖2a的智能眼鏡僅是一種適用于本申請的智能終端,接收頭部移動信息來控制光標移動。
在一些優選實現中,確定應用場景單元301包括:確定操控對象單元,用于確定所述光標當前所指向的顯示區域內的操控對象;以及人機交互單元,用于接收基于所述操控對象和/或以所述操控對象為中心預定范圍內的人機交互。本實施例中涉及的人機交互單元包括智能終端通過接收使用者身體部位移動信息完成的人機交互,實現方式上一般采用運動感應器接收身體部位的移動信息,經處理器的處理控制光標的移動。還包括智能終端通過接收使用者語音信息完成的人機交互,實現方式上一般采用麥克接收語音信息,處理器判斷該語音信息中是否含有光標處對應語音指令集合中的語音指令。
優選地,所述語音指令包括:移動操作指令,其中,移動操作的開始和結束由所述語音指令控制;并且所述移動操作的移動路徑由所述光標控制。
附圖中的流程圖和框圖,圖示了按照本發明各種實施例的終端、方法和計算機程序產品的可能實現的體系架構、功能和操作。在這點上,流程圖或框圖中的每個方框可以代表一個模塊、程序段、或代碼的一部分,所述模塊、程序段、或代碼的一部分包含一個或多個用于實現規定的邏輯功能的可執行指令。也應當注意,在有些作為替換的實現中,方框中所標注的功能也可以以不同于附圖中所標注的順序發生。例如,兩個接連地表示的方框實際上可以基本并行地執行,它們有時也可以按相反的順序執行,這依所涉及的功能而定。也要注意的是,框圖和/或流程圖中的每個方框、以及框圖和/或流程圖中的方框的組合,可以用執行規定的功能或操作的專用的基于硬件的系統來實現,或者可以用專用硬件與計算機指令的組合來實現。
描述于本申請實施例中所涉及到的單元或模塊可以通過軟件的方式實現,也可以通過硬件的方式來實現。所描述的單元或模塊也可以設置在處理器中,例如,可以描述為:一種處理器包括匹配單元、執行單元。其中,這些單元或模塊的名稱在某種情況下并不構成對該單元或模塊本身的限定,例如,執行單元還可以被描述為“用于實現語音指令的單元”。
以上描述僅為本申請的較佳實施例以及對所運用技術原理的說明。本領域技術人員應當理解,本申請中所涉及的發明范圍,并不限于上述技術特征的特定組合而成的技術方案,同時也應涵蓋在不脫離所述發明構思的情況下,由上述技術特征或其等同特征進行任意組合而形成的其它技術方案。例如上述特征與本申請中公開的(但不限于)具有類似功能的技術特征進行互相替換而形成的技術方案。
- 還沒有人留言評論。精彩留言會獲得點贊!