一種基于云計算框架的交通大數據清洗方法與流程
本發明屬于智能交通系統范疇,涉及一種基于云計算框架的交通大數據清洗方法。
背景技術:
智能交通系統有助于改善交通通行情況,對于受交通擁堵困擾的城市,交通擁堵問題越來越受到人們的關注。交通傳感器是智能交通系統數據的重要來源。但是受設備精度、設備故障、采集環境等多種因素的影響,往往會采集到異常或出錯的數據。這將降低智能交通系統大部分應用(比如交通狀態估計、交通狀態預測)的準確性。因此,需要對交通數據進行清洗,填補缺失數據、剔除出錯數據、修正異常數據。目前使用的交通傳感器種類多、采樣頻率高,系統將面對海量的交通數據,在清洗過程中需要考慮處理效率。
Map/Reduce是一種編程模型,用于大規模數據集的并行運算。它極大地方便了編程人員在不會分布式并行編程的情況下,將程序運行在分布式系統上。針對具體應用,實現該模型需要指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。因此,采用Map/Reduce框架時,重點是設計Map和Reduce兩個函數。
通過調研發現,現有交通數據清洗方面的工作包括:王曉原等《交通流數據清洗與狀態辨識及優化控制關鍵理論方法》結合中國高速公路道路交通基礎設施現狀和未來發展的需要,對我國的交通流狀態辨識框架及其關鍵理論和方法進行了研究,提出了交通流數據清洗的方法;他們的文章《交通流數據清洗規則研究》也提出了交通數據清洗的規則。這些規則都是結合交通流理論提出,適合高速路等道路的情況,本專利從數據本身出發,采用了聚類獲取交通運行規律的方法,適用于城市道路等交通復雜度高的情況;專利《基于時空分析的交通流數據清洗方法》采用交通流在時間和空間上的關系,提出了數據清洗的方法;國外的研究工作者還提出了狀態相空間重構模型、小波分解模型、神經網絡、支持向量機等方法,但是復雜度都較高,很難實際應用于處理大數據。同時,上述工作都沒有考慮面對T級別(日處理量大于500G)交通大數據的情況,包括如何進行高效數據處理。
現有的傳感器采集交通數據存在數據缺失、數據異常和數據錯誤等問題,所指的數據缺失為由于傳感器或網絡通信原因智能交通系統未采集到數據或缺失了某一維的數據;數據異常為由于傳感器本身設備誤差或環境偶發因素引起的數據偏離正常值;數據錯誤為采集或傳輸出錯,導致的數據嚴重偏離正常值,出現錯誤。
技術實現要素:
為了克服已有交通數據清洗方式的處理效率較低、無法適用于大數據的不足,本發明提供了一種提升處理效率、有效適用于大數據的基于云計算框架的交通大數據清洗方法,在云計算(Hadoop的Map/Reduce)框架下,針對交通數據高維、海量、數據更新快的特點,利用集群系統的并行計算能力來解決面臨的海量交通數據的快速清洗問題,能夠快速且有效的挖掘交通數據相似性特征,用于清洗異常數據。
本發明解決其技術問題所采用的技術方案是:
一種基于云計算平臺的交通大數據清洗方法,包括以下步驟:
步驟1:缺失數據補全
掃描整個數據源,若存在缺失數據,根據相同路段數據所在維的均值填充;需要根據數據產生的位置進行分發,由不同的子節點并行處理;
步驟2:聚類獲取路段特征數據
將具有相似數據變化規律的數據聚成一類,獲得該路段數據的特征值,所述特征值為聚類中心為;每個聚類過程由不同節點完成,特征值的獲取由reduce步驟完成,步驟如下:
步驟2.1:根據路段標號r對數據集τ進行分割,獲得N個數據塊,然后,每個數據塊分割為M個子數據塊,獲得N×M個子數據塊,并分發給子節點;
步驟2.2:子節點把數據塊分配給N×M個Map函數,每個MAP任務處理一個子數據塊;
步驟2.3:在Map函數中,首先,對子數據塊進行聚類,獲得聚類中心ci(i=1,2,3,...,K),聚類中心數目K由壓縮因子α確定,K=floor(α*N),floor表示向下取整;然后,離散化聚類中心,以道路標號(r)為鍵值構造數據對象進行分發,數據對象屬性包含鍵值、聚類中心ci和中心點數目K、傳感器數據集合、數據元素和位置信息,所述鍵值為路段標號r;
步驟2.4:在Reduce函數中,合并多個子數據塊的聚類中心,獲得特征值xl(l=1,2,3,...,K′),K′為特征值個數,步驟為:
2.4.1)計算兩個聚類中心(ci、cj)之間的歐式距離lij,獲得兩個聚類中心之間的最小歐式距離lmin,lmin=min(|ci-cj|),其中i,j∈K且i≠j,|*|表示歐式距離;
2.4.2)特征值計算采用:xl=avg(c1,c2,...,ck),k為滿足合并條件的聚類中心個數,當多個聚類中心ck滿足合并條件lij<(1+α)*lmin時,特征值為多個聚類中心的平均值,當一個聚類中心ck與其他聚類中心的歐式距離都不滿足合并條件時,特征值為它自身;
2.4.3)若K′<K,聚類過程結束;反之,調整壓縮因子α=α*1.5,擴大壓縮因子繼續聚類,重新進行步驟2.2到步驟2.4;
步驟2.5:將特征值xl寫入以路段標號為行標的數據集到分布式文件系統,完成數據清洗過程。
進一步,所述清洗方法還包括以下步驟:
步驟3:更新和剔除異常數據,步驟如下:
步驟3.1:根據道路標號r分發數據集給子節點;
步驟3.2:在Map函數中,首先讀取數據d,找出距離最小的聚類中心編號,搜索特征值xl(l=1,2,3,...,K′),當|xl-d|距離最小時,將i賦值給m;然后,以聚類中心編號m為鍵值構造對象進行分發,對象屬性包括聚類中心編號m、聚類中心差值|xm-d|、數據本身d、傳感器數據集合和位置信息;
步驟3.3:在Reduce函數中,若聚類中心差值(|xm-d|<α*|xm|),正常數據不處理;若聚類中心差值(|xm-d|>5α*|xm|),剔除數據;若不符合這兩種情況,更新數據,如下公式:d′=d-(d-xm)*α,最后,數據d′寫入以路段標號為行標的數據到分布式文件系統,清洗過程完成。
再進一步,所述步驟1中,缺失數據補全的步驟如下:
步驟1.1:在Map函數中,首先,讀入歷史數據,獲取數據元素的數值;然后,解析出數據產生的位置信息,獲得路段標號r;最后,以r為鍵值構造數據對象并分發,數據對象屬性包含鍵值、傳感器數據集合、缺失信息、數據元素和位置信息;
步驟1.2:在Reduce函數中,首先,計算子數據塊各維的均值μ和標準差δ;選取(μ-δ,μ+δ)范圍的子數據進行計算均值獲得μ2,填充缺失數據;最后,寫入以路段標號為行標的數據集τ到分布式文件系統。
本發明的有益效果主要表現在:本發明利用云計算平臺的并行計算能力來解決交通大數據清洗時的計算速度問題;以數據清洗為目標,以聚類方法為基礎,提出了新的交通數據清洗思路和方法;該方法能快速聚類,挖掘交通數據相似性特征,實現對異常的交通數據的分布式處理,保障后續針對數據的各項應用的準確性和魯棒性。
附圖說明
圖1是一種基于云計算框架的交通大數據清洗方法的流程圖。
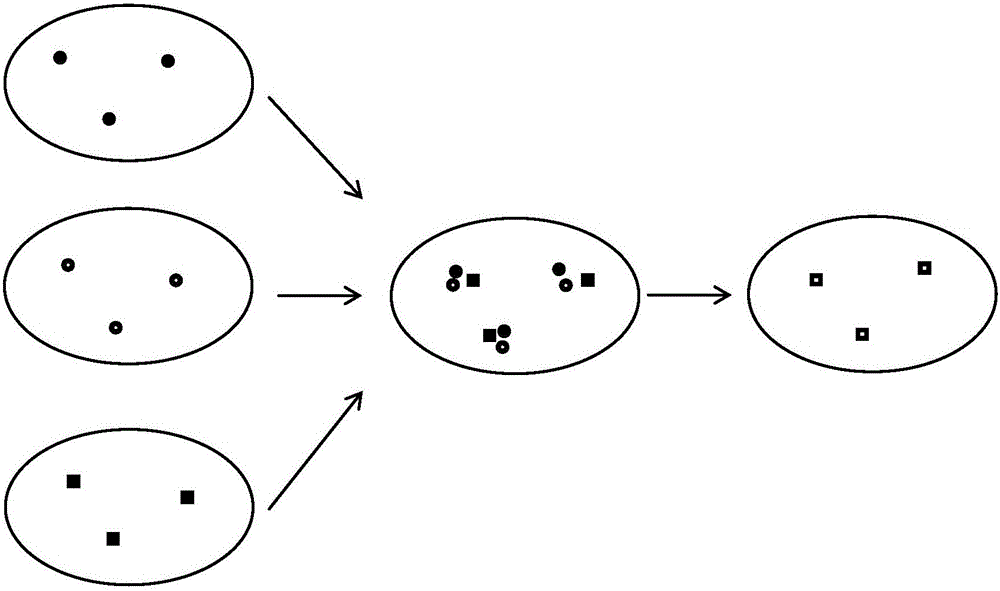
圖2是合并多個子數據塊的聚類中心示意圖
具體實施方式
下面結合附圖對本發明作進一步描述。
參照圖1和圖2,一種基于云計算平臺的交通大數據清洗方法,包括以下步驟:
步驟1:缺失數據補全
掃描整個數據源,若存在缺失數據,根據相同路段數據所在維的均值填充。整個過程,需要根據數據產生的位置(數據采集的路段)進行分發,由不同的子節點并行處理。具體步驟如下:
步驟1.1:在Map函數中,首先,讀入歷史數據,獲取數據元素的數值;然后,解析出數據產生的位置信息,獲得路段標號(r);最后,以r為鍵值構造數據對象并分發,數據對象屬性包含鍵值、傳感器數據集合、缺失信息、數據元素和位置信息,所述鍵值為路段標號r;
步驟1.2:在Reduce函數中,首先,計算子數據塊各維的均值(μ)和標準差(δ);選取(μ-δ,μ+δ)范圍的子數據進行計算均值獲得μ2,填充缺失數據;最后,寫入以路段標號為行標的數據集(τ)到分布式文件系統。
步驟2:聚類獲取路段特征數據
將具有相似數據變化規律的數據聚成一類,獲得該路段數據的特征值(聚類中心)。為提高計算效率,每個聚類過程由不同節點完成。因為節點不能直接通信,所以最后特征值的獲取由reduce步驟完成。具體步驟如下:
步驟2.1:根據路段標號(r)對數據集(τ)進行分割,獲得N個數據塊。然后,每個數據塊分割為M個子數據塊,獲得N×M個子數據塊,并分發給子節點;
步驟2.2:子節點把數據塊分配給N×M個Map函數,每個MAP任務處理一個子數據塊;
步驟2.3:在Map函數中,首先,對子數據塊進行聚類(可選用Kmeans、層次聚類等能產生聚類中心的聚類方法),獲得聚類中心ci(i=1,2,3...,K)。聚類中心數目K由壓縮因子α(初始值為常數,小于1,比如0.05)確定,K=floor(α*N),floor表示向下取整;然后,離散化聚類中心,以道路標號(r)為鍵值構造數據對象進行分發,數據對象屬性包含鍵值(r)、聚類中心(ci)和中心點數目(K)、傳感器數據集合、數據元素和位置信息;
步驟2.4:在Reduce函數中,合并多個子數據塊的聚類中心,獲得特征值xl(l=1,2,3,...,K′),K′為特征值個數,步驟為:
2.4.1)計算兩個聚類中心(ci、cj)之間的歐式距離lij,獲得兩個聚類中心之間的最小歐式距離lmin,lmin=min(|ci-cj|),其中i,j∈K且i≠j,|*|表示歐式距離;
2.4.2)特征值計算采用:xl=avg(c1,c2,...,ck),k為滿足合并條件的聚類中心個數,當多個聚類中心ck滿足合并條件lij<(1+α)*lmin時,特征值為多個聚類中心的平均值,當一個聚類中心ck與其他聚類中心的歐式距離都不滿足合并條件時,特征值為它自身。
2.4.3)若K′<K,聚類過程結束;反之,調整壓縮因子α=α*1.5,擴大壓縮因子繼續聚類,重新進行步驟2.2到步驟2.4。
步驟2.5:將特征值xl寫入以路段標號為行標的數據集到分布式文件系統
步驟3:更新和剔除異常數據
新采集的需要清洗的數據被分發到各個子節點,首先,進行缺失數據補全。然后,查找異常數據;最后,進行異常數據的更新或剔除。具體步驟如下:
步驟3.1:根據道路標號(r)分發數據集給子節點;
步驟3.2:在Map函數中,首先讀取數據d,找出距離最小的聚類中心編號,搜索特征值xl(l=1,2,3,...,K′,當|xl-d|距離最小時,將i賦值給m;然后,以聚類中心編號(m)為鍵值構造對象進行分發,對象屬性包括聚類中心編號(m)、聚類中心差值(|xm-d|)、數據本身(d)、傳感器數據集合和位置信息
步驟3.3:在Reduce函數中,若聚類中心差值(|xm-d|<α*|xm|),正常數據不處理;若聚類中心差值(|xm-d|>5α*|xm|),剔除數據;若不符合這兩種情況,更新數據,如下公式:d′=d-(d-xm)*α。最后,數據d′寫入以路段標號為行標的數據到分布式文件系統,清洗過程完成。
本實施例的數據來自安裝浙江省杭州市天目山路和余杭塘路,紫金花路和莫干山路之間400多條路段的傳感器,或者行駛在這些路段的GPS浮動車。傳感器包括浮動車GPS、SCATS線圈、微波雷達和卡口視頻數據。四源數據只采用了速度或速率的結果,作為本實施例的輸入。數據采集時間為2013年7月,共30天數據,原始數據總量共473.2GB。其中,前28天的數據用于聚類獲取路段特征數據,后2天數據用于對方法效果的測試。在性能測試中,采用的是8臺物理計算機(16核,1.6GHz CPU)。
步驟101,原始數據清洗。在Map函數中,首先,讀入一行數據,獲取數據元素的數值;然后,解析出數據產生的位置信息,獲得路段標號(r);最后,以r為鍵值構造數據對象并分發,數據對象屬性包含鍵值(r)、傳感器數據集合、缺失信息和位置信息。以莫干山路-文二路-文一路為例,獲得路段標號為267,以r為鍵值構造數據對象并分發。
步驟102:在Reduce函數中,首先,計算子數據塊速度的均值(μ)、標準差(δ);然后,選取(μ-δ,μ+δ)范圍數據進行均值計算獲得μ2,填充缺失數據;最后,寫入以路段標號為行標的數據到分布式文件系統。
步驟103:根據路段標號(r)對數據集進行分割,獲得30個數據塊。然后,每個數據塊分割為20個子數據塊,獲得30*20個子數據塊,并分發給子節點。子節點把數據塊分配給30*20個Map函數,每個MAP任務處理一個子數據塊;這里的數據以一個數據塊為例。
步驟104:在Map函數中,首先,對子數據塊進行聚類(實施過程中采用Kmeans),獲得初始值聚類中心。聚類中心數目K=80;然后,以道路標號(r)為鍵值構造數據對象進行分發,數據對象屬性包含鍵值(r)、聚類中心(ci)和中心點數目(K);
步驟105:在Reduce函數中,合并多個子塊的聚類中心(ci),獲得特征值xl(l=1,2,3,...,K′);
步驟106:在Map函數中,首先,計算每一行數據(d)和聚類中心的聚類,找出距離最小的聚類中心編號m;然后,以聚類中心編號m為鍵值構造對象進行分發,對象屬性包括聚類中心編號(m)、聚類中心差值(|xm-d|)、數據本身(d)。
步驟107:在Reduce函數中,若聚類中心差值(|xm-d|<α*|xm|),正常數據不處理;若聚類中心差值(|xm-d|>5α*|xm|),剔除數據;若不符合這兩種情況,更新數據,如下公式:d′=d-(d-xm)*α。最后,數據d′寫入以路段標號為行標的數據到分布式文件系統。
以上所述僅為本發明的優選實施例而已,并不用于限制本發明,對于本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!