一種用于提高個性化推薦系統多樣性的方法與流程
本發明屬互聯網、移動互聯網和計算機網絡領域,更具體地,涉及一種用于提高個性化推薦系統多樣性的方法。
背景技術:
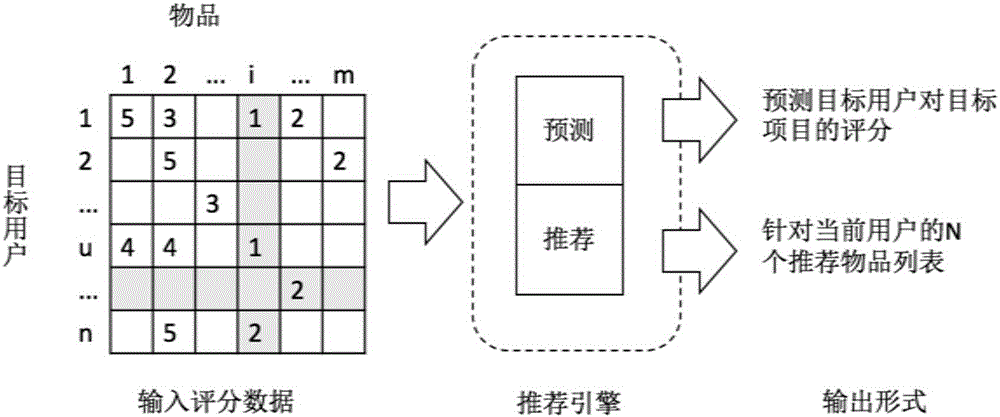
:由于網絡零售商領域存在著長尾效應,即商家銷售額的百分之八十來自于其百分之二十的商品,而如果能夠提零售商長尾物品的銷售,那么網絡零售商的營業額將成倍增長,且能滿足用戶獨特偏好。因此近年來,結合計算機網絡技術和大數據處理技術的個性化推薦系統在電子商務領域中逐步引起了人們的高度重視,并獲得了廣泛的應用。個性化推薦系統是為了實現基于用戶的個人興趣的信息過濾,個性化推薦系統是一個信息過濾系統,對用戶的相關信息和數據進行分析和挖掘,從而發現用戶興趣所在,找到用戶隱含的需求,然后為其推薦。通過長尾理論可知,如果商家所提供的服務或商品能夠完美滿足用戶的個性化需求,用戶對商家滿意度和信任度都極高,那么必然會給商家帶來巨大的利潤,而個性化推薦系統是商家用于滿足用戶的個性化需求的重要手段,同時個性化推薦系統也是解決互聯網零售商的長尾現象的重要手段。目前所廣泛采用的用于個性化推薦系統的方法有基于用戶的協同過濾方法、以及基于物品的協同過濾方法。針對基于用戶的協同過濾方法而言,那些與某些相同物品有交互的用戶被認為處于同一個鄰域中。根據一些統計數據,如果在過去用戶具有相似的偏好,那么在未來他們將繼續擁有相似的偏好。如果有一個用戶購買或者評價了一個新物品,那么這個物品將被推薦給該用戶的鄰居用戶,該方法主要針對如何為大規模的用戶進行推薦和計算用戶之間的相似度。然而,該方法的缺陷在于,該方法并未考慮推薦系統的多樣性問題,從而導致互聯網零售商的長尾物品滯銷。基于物品的協同過濾方法和上述基于用戶的協同過濾方法基本相同,其區別在于,其需要計算物品的相似度,而非計算用戶的相似度。然而該算法也未能考慮推薦系統的多樣性問題,同樣會導致互聯網零售商的長尾物品滯銷。技術實現要素:針對現有技術的以上缺陷或改進需求,本發明提供了一種用于提高個性化推薦系統多樣性的方法,其目的在于,解決現有方法中存在的未考慮個性化推薦系統中的多樣性,從而導致互聯網零售商的長尾物品滯銷的技術問題。為實現上述目的,按照本發明的一個方面,提供了一種提高個性化推薦系統多樣性的方法,包括以下步驟:(1)從網站獲取用戶評分數據集,并且將該用戶評分數據集以文本的方式進行存儲,該用評分數據集中包括有用戶ID、該用戶ID對應的物品ID、以及該用戶對該物品的評分值;(2)使用用于個性化推薦系統的推薦算法對步驟(1)獲取的用戶評分數據集進行預測和推薦處理,從而為用戶評分數據集中的多個用戶分別生成對應的推薦列表,該推薦列表中包括有用戶ID、該用戶ID對應的物品ID、以及該用戶對該物品的預測評分值;(3)對用戶評分數據集,求取其物品的流行程度,該流行程度是由對該物品進行評價的用戶的人數、用戶對該物品的評分值決定,將用戶對物品的預測評分值與控制閾值進行比較,將大于或等于控制閾值的預測評分值對應的物品的流行程度進行排序,以得到最終的排序結果;(4)取排序結果中前端的多個結果作為推薦列表反饋給用戶。優選地,步驟(2)具體包括以下子步驟:(2-1)根據獲取的用戶評分數據集,計算所有用戶之間的相似度:sim(a,b)=Σp∈PR(a,p)R(b,p)Σp∈PR(a,p)2Σp∈PR(b,p)2]]>其中sim(a,b)表示用戶a和b之間的相似度,P表示所有物品的集合,p表示集合P中的物品,R(a,p)和R(b,p)分別表示用戶a和用戶b對于物品p的評分值;(2-2)對于每個用戶而言,選取與該用戶相似度最高的前K個用戶作為該用戶的鄰居用戶,其中K是50到300之間的整數;(2-3)對于每個用戶而言,對其K個鄰居用戶評分過的物品的評分值進行分析,以預測出該用戶最有可能打高分的多個物品,并將該用戶可能打高分的這些物品推薦給用戶。優選地,步驟(2-3)具體使用以下公式:R*(u,i)=R(u)‾+kΣv∈N(u)(R(v,i)-R(v)‾)×sim(u,v)]]>其中k=1Σv∈N(u)sim(u,v);]]>將其代入上述公式后得到:R*(u,i)=R(u)‾+Σv∈N(u)(R(v,i)-R(v)‾)×sim(u,v)Σv∈N(u)|sim(u,v)|]]>其中R*(u,i)表示用戶u對于物品i的預測評分值,是用戶u對于其所有物品的平均評分值,k為歸一化因子,N(u)表示用戶u的所有鄰居用戶的集合。優選地,步驟(3)具體包括以下子步驟:(3-1)對用戶評分數據集,根據對該用戶評分數據集中物品進行評價的用戶的人數、用戶對該物品的評分值求取其物品的流行程度;(3-2)將用戶對物品的預測評分值與控制閾值進行比較,將大于或等于控制閾值的預測評分值對應的物品的流行程度進行排序,以得到最終的排序結果。優選地,步驟(3-1)中獲取物品的流行程度的過程可表示為其中rankPopularity(i)表示使用物品流行程度排序的方法,表示對于所有用戶的集合U中的每個用戶u而言,存在用戶u對物品i的評分值R(u,i)的個數。優選地,步驟(3-1)中獲取物品的流行程度的過程可表示為rankReversePrediction(i)=R*(u,i)其中rankReversePrediction(i)表示使用預測評分值倒序的方法,該預測評分值可表示物品的流行程度。優選地,步驟(3-1)中獲取物品的流行程度的過程可表示為rankAverageRating(i)=R(i)‾]]>其中有R(i)‾=1|U(i)|Σu∈U(i)R(u,i)]]>rankAverageRating(i)表示使用物品平均評分值排序的方法;優選地,步驟(3-1)中獲取物品的流行程度的過程可表示為rankAbsoluteLikeability(i)=|UH(i)|其中UH(i)={u∈U(i)|R(u,i)≥TH}rankAbsoluteLikeability(i)表示使用物品的絕對受歡迎程度,{u∈U(i)|R(u,i)≥TH}表示物品i被用戶u打的評分值大于閾值TH的數量。優選地,步驟(3-1)中獲取物品的流行程度的過程可表示為rankRelativeLikeability(i)=|UH(i)/U(i)|其中rankRelativeLikeability(i)表示物品相對受歡迎程度。優選地,步驟(3-1)中獲取物品的流行程度的過程可表示為rankRatingVariance(i)=1|U(i)|Σu∈U(i)(R(u,i)-R(i)‾)2]]>其中rankRatingVariance(i)表示用戶對物品的評分值偏離該物品平均評分值的程度。優選地,步驟(3-2)具體是采用以下公式:rankx(i,TR)=rankx(i),R*(u,i)∈[TR,Tmax]rankStandard(i),R*(u,i)∈[TH,TR)]]>其中,rankx(i,TR)表示使用控制閾值TR對物品i進行排序的函數,rankx(i)表示上物品的流行程度,Tmax表示評分值的上限(例如在5分制的打分系統中,該值就等于5),控制閾值TR∈[TH,Tmax],rankStandard(i)為現有標準的排序方法,且有:rankStandard(i)=R*(u,i)-1。按照本發明的另一方面,提供了一種提高個性化推薦系統多樣性的系統,包括:第一模塊,用于從網站獲取用戶評分數據集,并且將該用戶評分數據集以文本的方式進行存儲,該用評分數據集中包括有用戶ID、該用戶ID對應的物品ID、以及該用戶對該物品的評分值;第二模塊,用于使用用于個性化推薦系統的推薦算法對第一模塊獲取的用戶評分數據集進行預測和推薦處理,從而為用戶評分數據集中的多個用戶分別生成對應的推薦列表,該推薦列表中包括有用戶ID、該用戶ID對應的物品ID、以及該用戶對該物品的預測評分值;第三模塊,用于對用戶評分數據集,求取其物品的流行程度,該流行程度是由對該物品進行評價的用戶的人數、用戶對該物品的評分值決定,將用戶對物品的預測評分值與控制閾值進行比較,將大于或等于控制閾值的預測評分值對應的物品的流行程度進行排序,以得到最終的排序結果;第四模塊,用于取排序結果中前端的多個結果作為推薦列表反饋給用戶。總體而言,通過本發明所構思的以上技術方案與現有技術相比,能夠取得下列有益效果:1、與以往的個性化推薦系統中的方法比較,本發明是針對提高個性化推薦系統中的多樣性而設計,在提高多樣性指標上有顯著提高,從而降低了互聯網零售商的長尾效應所帶來的物品滯銷問題。2、本發明使用靈活,可以方便地被添加到現有的個性化推薦系統中,而不會改變該個性化推薦系統的核心架構,不會給原有的系統帶來巨大的改變和負擔。3、通過采用本發明方法中的步驟(3),保證了個性化推薦系統的準確性和多樣性。4、通過本發明的步驟(3),可在較少犧牲推薦準確度的同時,大幅度提高推薦結果總體多樣性。附圖說明圖1是本發明所適用的個性化推薦系統的處理結構圖。圖2是本發明基于用戶的推薦系統的推薦流程示意圖。圖3是本發明選擇鄰居用戶的示意圖。圖4是本發明基于閾值的排序算法的一般思想示意圖。圖5是本發明的實驗設計圖。圖6是排序算法對準確度和多樣性的影響的結果圖,其中:(a)是使用基于流行度的方法,(b)是使用平均評分方法,(c)是使用絕對受歡迎程度方法,(d)是使用相對受歡迎程度方法,(e)是使用評分方差法,(f)是使用評分倒序法。圖7是準確度損失和多樣性之間關系結果圖。圖8是推薦物品中長尾物品所占比例圖。圖9是本發明用于提高個性化推薦系統多樣性的方法的流程圖。具體實施方式為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。此外,下面所描述的本發明各個實施方式中所涉及到的技術特征只要彼此之間未構成沖突就可以相互組合。本發明的整體思路在于,首先獲取用戶評分數據集,然后在評分數據集上使用常用推薦算法進行推薦,接下來對推薦結果進行閾值控制與排序,再將最終結果呈現給用戶。通過對推薦結果進行重新排序,能夠改變最終推薦結果的列表內容,從而能夠提高系統多樣性,同時在排序時使用閾值控制的方法,使得推薦物品盡可能為用戶所喜歡物品,保證推薦系統的預測準確度。典型的個性化推薦系統處理結構如圖1所示。在整個系統中,假設U(用戶,即user)為參與到個性化推薦系統中的所有用戶的集合,I(物品,即item)為系統中所有物品(如書籍、電影、音樂等)的集合,然后每個用戶u∈U和物品i∈I的關系可以看做是R(u,i),R(u,i)和U、I之間的關系如下式所示:R:U×I→RatingR從實際意義上來看是一個評分,表明了一個用戶u對物品i的偏愛程度。推薦系統包含兩個步驟:預測和推薦。在推薦系統的第一步即預測任務是使用已知的評分數據來預測用戶對沒有評分物品的可能的分數。如圖9所示,本發明提高個性化推薦系統多樣性的方法包括以下步驟:(1)從網站獲取用戶評分數據集,并且將該用戶評分數據集以文本的方式進行存儲,該用評分數據集中包括有用戶ID、該用戶ID對應的物品ID、以及該用戶對該物品的評分值;具體而言,在本發明中是采用網絡爬蟲的方法獲取用戶評分數據集;(2)使用用于個性化推薦系統的推薦算法對步驟(1)獲取的用戶評分數據集進行預測和推薦處理,從而為用戶評分數據集中的多個用戶分別生成對應的推薦列表,該推薦列表中包括有用戶ID、該用戶ID對應的物品ID、以及該用戶對該物品的預測評分值;(3)對用戶評分數據集,求取其物品的流行程度,該流行程度是由對該物品進行評價的用戶的人數、用戶對該物品的評分值決定,將用戶對物品的預測評分值與控制閾值進行比較,將大于或等于控制閾值的預測評分值對應的物品的流行程度進行排序,以得到最終的排序結果;(4)取排序結果中前端的多個結果作為推薦列表反饋給用戶;在本發明中,取位于排序結果前端的5個結果作為推薦列表反饋給用戶。如圖2所示,本發明方法的步驟(2)具體包括以下子步驟:(2-1)根據獲取的用戶評分數據集,計算所有用戶之間的相似度;具體而言,本步驟是采用以下公式:sim(a,b)=Σp∈PR(a,p)R(b,p)Σp∈PR(a,p)2Σp∈PR(b,p)2]]>其中sim(a,b)表示用戶a和b之間的相似度,P表示所有物品的集合,p表示集合P中的物品,R(a,p)和R(b,p)分別表示用戶a和用戶b對于物品p的評分值;(2-2)對于每個用戶而言,選取與該用戶相似度最高的前K個用戶作為該用戶的鄰居用戶;在本實施方式中,K的取值范圍是50到300之間的整數;如圖3所示。(2-3)對于每個用戶而言,對其K個鄰居用戶評分過的物品的評分值進行分析,以預測出該用戶最有可能打高分的多個物品,并將該用戶可能打高分的這些物品推薦給用戶;具體而言,本步驟中是具體使用以下公式:R*(u,i)=R(u)‾+kΣv∈N(u)(R(v,i)-R(v)‾)×sim(u,v)]]>其中,將其代入上述公式后得到:R*(u,i)=R(u)‾+Σv∈N(u)(R(v,i)-R(v)‾)×sim(u,v)Σv∈N(u)|sim(u,v)|]]>其中R*(u,i)表示用戶u對于物品i的預測評分值,是用戶u對于其所有物品的平均評分值,k為歸一化因子,N(u)表示用戶u的所有鄰居用戶的集合;本發明方法的步驟(3)具體包括以下子步驟:(3-1)對用戶評分數據集,根據對該用戶評分數據集中物品進行評價的用戶的人數、用戶對該物品的評分值求取其物品的流行程度;具體而言,本發明獲取物品的流行程度的過程可以采用以下六種方法進行計算:第一種、其中rankPopularity(i)表示使用物品流行程度排序的方法,表示對于所有用戶的集合U中的每個用戶u而言,存在用戶u對物品i的評分值R(u,i)的個數。第二種、rankReversePrediction(i)=R*(u,i)其中rankReversePrediction(i)表示使用預測評分值倒序的方法,該預測評分值可表示物品的流行程度。第三種、其中有R(i)‾=1|U(i)|Σu∈U(i)R(u,i)]]>rankAverageRating(i)表示使用物品平均評分值排序的方法,第四種、rankAbsoluteLikeability(i)=|UH(i)|其中UH(i)={u∈U(i)|R(u,i)≥TH}rankAbsoluteLikeability(i)表示使用物品的絕對受歡迎程度,{u∈U(i)|R(u,i)≥TH}表示物品i被用戶u打的評分值大于閾值TH的數量,在本實施方式中,閾值TH的取值可以自由設定,該值越小,表示用戶對于物品的評分標準越嚴格,反之則表示越寬松,在本發明中其取值為3.5(在標準5分制滿分的前提下);第五種、rankRelativeLikeability(i)=|UH(i)/U(i)|其中rankRelativeLikeability(i)表示物品相對受歡迎程度。第六種、其中rankRatingVariance(i)表示用戶對物品的評分值偏離該物品平均評分值的程度。(3-2)將用戶對物品的預測評分值與控制閾值進行比較,將大于或等于控制閾值的預測評分值對應的物品的流行程度進行排序,以得到最終的排序結果。本步驟具體是采用以下公式:rankx(i,TR)=rankx(i),R*(u,i)∈[TR,Tmax]rankStandard(i),R*(u,i)∈[TH,TR)]]>其中,rankx(i,TR)表示使用控制閾值TR對物品i進行排序的函數,rankx(i)表示上述步驟(3-1)中所獲取的物品的流行程度,Tmax表示評分值的上限(例如在5分制的打分系統中,該值就等于5),控制閾值TR∈[TH,Tmax],rankStandard(i)為現有標準的排序方法,且有:rankStandard(i)=R*(u,i)-1在這里,當引入了控制閾值TR后,使得那些預測評分高于TR的按照原有的rankx(i)的結果進行排序,而那些預測評分低于TR的,則使用rankStandard(i)來進行排序。同時,還會控制所有預測評分高于TR的物品都排在所有預測評分低于TR的物品的前面。那么,當增大TR的值時,將篩選出更高準確度和更低多樣性的物品(因為這樣會越來越接近標準排序;若減小TR的值,那么會使得函數rankX(i,TR)更接近于rankx(i),這種情況下會提高系統的準確度并降低其多樣性。因此,可以通過選擇不同的控制閾值TR,來實現準確度和多樣性之間的關系平衡。基于閾值的排序算法的一般思想如圖4所示。如圖4(a)所示,使用標準的排序方法,按照預測評分直接對候選物品進行排序,預測評分值越高,物品排序越靠前。然后選擇預測評分最高的前5個物品推薦給用戶,并且為保證所推薦物品都符合用戶偏好,選擇物品的評分都在TH之上,推薦系統整體的推薦質量如旁邊直方圖所示。如圖4(b)所示,使用了排序函數rankx(i),此處使用的是基于流行度的排序方法,然后得到了一組新的推薦列表,將流行度較低,但預測評分在TH之上的物品推薦給用戶。在這組列表中,用戶會看到一些小眾物品,這部分的物品在整個推薦系統中處于長尾部分,雖然它們的流行度不高,但是用戶對這些物品的評價可能是喜歡(預測評分值高于TH),說明這些物品和用戶的相關程度還不錯,使用了這種排序的方法之后,能夠提高系統的多樣性,同時也降低了系統的準確度,系統的整體推薦質量仍如旁邊直方圖所示。如圖4(c)所示,通過調整控制閾值TR,可以選擇將不同的物品推薦給用戶,達到盡量減少降低準確度的同時,提高系統的多樣性的目的。為了能夠進行公平合理的性能評估,本發明給出個性化推薦系統評價過程中幾個定量評價指標的定義。(1)準確度在的評分數據中,評分區間值為1~5,較高的數值代表用戶更加偏愛這個物品。根據一般的推薦系統的定義,將評分高于3.5(高評分物品的閾值,記為TH)的作為“高排名”物品,將評分低于3.5的記為“非高排名”的物品。此外,在實際的推薦系統中,因為用戶通常只關注于幾個最相關的推薦物品,因此推薦系統通常會給出排名最高的N個物品,將推薦給用戶u的N個物品記為:LN(u)={i1,...,iN}其中,R*(u,ik)≥TH,k∈{1,2,...,N}因此在的文章中,評估推薦系統的準確度基于真正的高排名物品所占比例,高排名物品所占比例記為correct(LN(u)),在這中間找出N個最相關的“高排名”物品推薦給用戶,即為precision-in-top-N(即前N位推薦物品的準確度),公式如下:precision-in-top-N=Σu∈U|correct(LN(u))|Σu∈U|LN(u)|]]>其中,correct(LN(u))={i∈LN(u)|R(u,i)≥TH}但是依靠準確度并不能很好的找到用戶所需的推薦物品。推薦系統不僅僅需要準確,還需要有實用價值。接下來,引入個性化推薦系統的另一個評價指標,即推薦系統的多樣性。(2)多樣性多樣性用于評估推薦系統對長尾物品的發掘能力。多樣性可以用不同的方法來進行評估,在本文中,使用推薦系統能夠推薦的所有不同物品的數量來進行評估,公式如下:diversity-in-top-N=|∪u∈ULN(u)|]]>其中diversity-in-top-N表示前N位推薦物品的多樣性。當系統的多樣性較高時可以保證將更多的物品展示給用戶,對于熱門推薦來說,由于熱門物品所占的比例很大,所以導致多樣性很低。對于一個好的個性化推薦系統,應該需要比較高的多樣性,這樣才能讓更多的物品獲得被推薦的機會。同時多樣性也是產品提供商非常關心的指標,多樣性越高的系統可以將每個物品都推薦給至少一個用戶。實驗實例為了驗證所基于閾值控制個性化推薦系統排序方法確實能夠在損失極小準確度的情況下提升推薦系統的多樣性,通過以下實驗步驟來驗證方案的可行性:(1)獲取MovieLens和Netflix原始數據集。(2)因原始數據集中包含部分與本算法無關的信息數據,并且userId和movieId的值過大,不利于計算機進行運算,因此需要對原始數據集進行去中心化處理,即去掉數據集中的類型、時間戳等多余信息,并將評分數據重新進行映射,使得userId和movieId的值從1開始計數。(3)將源數據集分為訓練集(包含60%源數據)和測試集(包含40%源數據),并保證測試集中至少包含一個用戶的5條電影評分數據。(4)在訓練集上分別使用基于用戶的推薦算法、基于物品推薦算法和基于奇異值分解推薦算法,得到MovieLens和Netflix的總計六組評分預測數據列表。(5)在以上推薦列表上使用基于排序的方法,得到推薦列表的重排列表,即呈現給用戶的推薦列表。(6)評估提出解決方案的性能,precision-in-top-N和diversity-in-top-N。實驗設計如圖5所示。實驗分別在MovieLens數據集和Netflix數據集上對比使用6種不同排序方法對推薦結果的影響及推薦系統的預測準確度和多樣性的變化。實驗中推薦系統的評測指標是precision-in-top-N和diversity-in-top-N。在實驗過程中,使用的是離線驗證的方法進行實驗,同時使用到了交叉驗證的方法來做實驗。在離線驗證的一般實驗方法中,首先要將數據集劃分為訓練集(TrainingSet)和測試集(TestSet)兩個部分,訓練集中包含60%的原始評分數據,測試集中包含40%的原始評分數據。然后基于訓練集中的評分數據,使用推薦算法對推薦結果進行預測,并將預測結果與測試集中的實際結果進行比較,計算出預測準確度和多樣性等評測指標。在實驗過程中,隨機生成5組訓練集和5組測試集,最后將5次實驗結果的平均值作為實驗的整體結果,最大程度上覆蓋了每條評分數據,保證實驗數據的準確性。圖6通過步驟(3-1)中六種方法得到的預測準確度和多樣性的性能比較,驗證了本發明提出的個性化推薦系統中多樣性解決方案設計和基于控制閾值的個性化推薦系統排序方法的可行性。圖中數據均為在Netflix數據集上使用不同的推薦算法再進行控制閾值排序后得到的多樣性和準確度之間的關系。本發明的控制閾值排序方法可以在不同程度上提高多樣性,同時預測的最佳結果取決于所選擇的數據集和所選用的推薦方法。同時,個性化推薦系統的設計人員可以根據不同的應用場景及搜集到的數據來靈活地選擇各種排序方式從而達到最佳推薦效果。圖7提供了本發明步驟(3-1)中所采用的六種方法中損失準確度和多樣性之間的關系。圖中比較了所有的基于控制閾值的排序算法之間的準確度損失和多樣性增益之間的關系。從圖中可以看出,所提出的算法可以通過犧牲系統的預測準確度來提高多樣性,使用不同的推薦算法和排序方法在不同的數據集上表現情況并不相同。在本次實驗中,分別選擇基于流行度的排序方法和基于物品相對受歡迎程度排序方法可以獲得較好的多樣性增益。圖8是使用本發明方法后對于個性化推薦系統長尾效應的性能評估。圖中計算了長尾物品在所有用戶推薦物品中的百分比。因為評估個性化推薦系統的多樣性是通過計算所有不同的推薦物品的個數,因此可以通過推薦一些新物品給少部分用戶來提高多樣性,因而無法確定本文所提出的方法是否真的能夠改變物品的長尾分布。在這里,評估了排序算法對長尾分布的影響。根據長尾分布的“二八法則”,定義20%的物品為暢銷物品,剩下的80%為長尾物品。從圖中可以看出,提出的重新排序算法能夠明顯提高長尾物品的推薦百分比。因此,在這里就證明了所提出的排序算法不僅僅提高的是多樣性的指標,而且能夠有效改善長尾物品的占比。這樣便能夠從整體上改善長尾物品的分布。本領域的技術人員容易理解,以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護范圍之內。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1