面向弱關系社交網絡的博文推薦方法與流程
本發明涉及社交網絡的信息推薦領域,具體是指針對于弱關系的社交網絡的博文推薦方法。
背景技術:
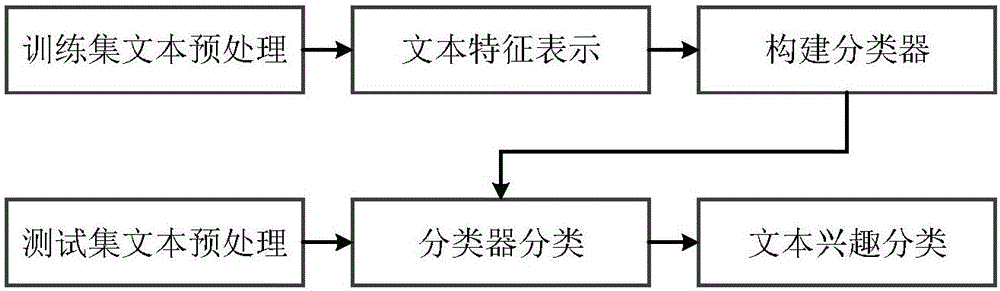
:目前在推薦領域使用的方法很多,比如基于內容的推薦算法(Content-basedFiltering)、基于用戶的協同過濾算法(User-basedCollaborativeFiltering)、基于物品的協同過濾算法(Item-basedCollaborativeFiltering)等等。但是面臨了很多挑戰,比如:數據稀疏性(DataSparsity)、冷啟動問題(ColdStart)、及時性等問題。現有的推薦算法對于解決數據稀疏性和冷啟動存在很大的困難,為解決這些問題,追求推薦算法更高的效率和更優的推薦結果,國內外紛紛都發出高額的獎金去眾包,以提高推薦算法的準確率。技術實現要素:針對上述現有推薦技術存在的數據稀疏性和冷啟動的缺陷,本發明的目的旨在提高算法效率的同時,提高推薦的精準度,能夠更加準確可靠地對弱關系網絡進行信息推薦。為了實現上述發明目的,本發明采用的基本技術方案包括如下內容。一種面向弱關系社交網絡的博文推薦方法,所述方法包括:利用社交網絡中的用戶和博文數據,根據活躍度劃分出活躍用戶群和非活躍用戶群,然后分別面向活躍與非活躍的用戶群,使用基于轉推網絡的推薦方法和基于內容標簽的推薦方法的輸出的用戶-博文的興趣度,最后通過結果的合并,得出用戶-博文的興趣度值。所述基于內容標簽的信息推薦方法,包括:針對于博文的興趣類別,情感傾向特征和時間特征三類標簽的提取和組合,并且對其用向量化表示;基于博文的向量化標簽,構建用戶的特征標簽,并且進行向量化表示;基于用戶和博文的向量化標簽,利用內積計算用戶和博文的興趣匹配度。所述基于轉發網絡的信息推薦方法,包括:構建用戶和博文的矩陣,獲取到博文的轉推關系,得到用戶和用戶之間的關系網絡;基于用戶相似度計算用戶對博文的興趣度,從而預測用戶對每條博文的轉發概率;基于用戶信任度計算用戶對博文的興趣度,從而預測用戶對每條博文的轉發概率;利用加權混合基于用戶相似度和信任度所計算出的興趣度,從而預測用戶對每條博文的轉發概率。基于用戶相似度計算用戶對博文的興趣度的方法包括:將博文做為項,通過用戶-博文的打分矩陣,計算用戶之間的相似度,其計算公式如下:其中分母中的N(u)是指用戶u發布的博文數,N(v)是指用戶v發布的博文數,分母是正則項,能夠使得最后用戶u和用戶v的相似度值在0和1之間,是懲罰因子,表示博文i被轉發的次數越多,該懲罰因子的值會比原始值小;在獲得了用戶-博文的打分矩陣和用戶之間的相似度后,當給定用戶u和博文t后,利用如下公式計算用戶u對博文t的興趣度:其中,S(u,K)包含與用戶u最相似的K個用戶集合,N(t)是指轉發或發布過博文t的用戶集合,用戶v就是指上述兩個集合的用戶交集,rvt是指用戶v是否轉發或發布過博文t。基于用戶信任度計算用戶對博文的興趣度的方法包括,在獲得了用戶-博文的打分矩陣和用戶之間的信任度后,給定用戶u和博文t,利用如下公式計算用戶u對博文t的興趣度:其中,S(u,K)包含用戶u信任度最高的K個用戶集合,N(t)是指轉發或發布過博文t的用戶集合,用戶v就是指上述兩個集合的用戶交集集合。rvt是指用戶v是否轉發或發布過博文t。計算用戶之間的信任度主要包括:基于用戶發布和轉發之間的時間間隔分布衡量用戶之間的信任度,其中時間間隔利用負指數分布;基于博文轉發路徑,用戶之間的信任度是可以進行傳遞,并且路徑越長,信任度度越低。本發明引入了負指數分布模擬某一條博文發布時間和轉發時間的延遲:trust值是通過負指數分布計算出來的,其中x的定義:這里createdAtv(t)-createdAtu(t)指用戶u轉發博文t時間和用戶v發布博文t時間的延遲,createdAtmax(t)-createdAtmin(t)指在轉推博文時間間隔中最大的延遲,其中用戶u和用戶v是相鄰的,即用戶v直接轉發了用戶u的博文,對于參數λ,使用最大似然估計計算其值:其中是樣本的平均值,用戶u發布博文的時間和用戶v轉發用戶u發布博文的時間越近,則用戶v對用戶u的信任度值越高。對于間接轉發的用戶之間,如果用戶w轉發了用戶v轉發的博文t,用戶v轉發了用戶u發布的博文t,則用戶w對用戶v同樣具有信任度,其計算如下:Patht(w,u)={trust1(w,v),trust2(v,u)},該公式指用戶w和用戶v存在一條轉發路徑,則信任度為即用戶w對用戶v的信任度是指在此轉發路徑上的信任度值的乘積。因為基于用戶相似度計算用戶對博文的興趣度值和基于用戶信任度計算用戶對博文的興趣度值各不相同,所以分別對每個用戶所預測博文集合的相似度興趣值和信任度興趣值做歸一化處理,以便除去誤差,歸一化的公式如下:得到歸一化后的興趣度,再利用加權公式進行最優興趣度的計算:psim_trust(u,t)=α||ptrust*(u,t)||+(1-α)||psim*(u,t)||其中α是值在0到1之間的參數值。本發明使用轉發網絡這一相對于社交網絡更加動態化地捕捉用戶之間的關系的方法,并引入了相似度和信任度兩個指標去刻畫用戶之間關系的強弱,改進了傳統的基于用戶的協同過濾推薦算法。同時,針對非活躍用戶,利用基于內容標簽的推薦方法,解決了轉發網絡推薦方法的數據稀疏性和冷啟動問題。附圖說明圖1是本發明所述推薦方法的流程框圖;圖2是本發明所述基于內容標簽的博文的興趣類別特征抽取流程圖;圖3是本發明所述基于內容標簽的博文的情感傾向特征抽取流程圖;圖4是本發明所述基于轉推網絡的推薦方法數據預處理流程圖;圖5是本發明所述基于內容標簽的推薦方法數據預處理流程圖;圖6是實施例中基于轉發網絡方法中不同的α參數值所對應MAP值變化。具體實施方式下面結合實施例對本發明進一步詳細描述。一種面向弱關系社交網絡的博文推薦方法,包括:利用社交網絡中的用戶和博文數據,根據活躍度劃分出活躍用戶群和非活躍用戶群,然后分別面向活躍與非活躍的用戶群,使用基于轉推網絡的推薦方法和基于內容標簽的推薦方法的輸出的用戶-博文的興趣度,最后通過結果的合并,得出用戶-博文的興趣度值。1、一種基于內容標簽的信息推薦方法,主要包括以下步驟:步驟一,利用Twitter的API采集用戶和博文的數據,同時過濾掉非中文的博文和用戶,以保證對用戶興趣類別的劃分和情感的分類。對得到的非活躍的Twitter博文集進行非中文過濾,過濾流程如圖5所示,從而得到中文博文集。中文過濾的規則主要分為以下幾個步驟:a)將博文按字符遍歷,逐個判斷博文中字符是否為中文字符,計算博文中的中文字符的長度。b)將獲取到的中文字符博文,利用正則表達式,去除中文字符中的重復詞。正則表達式的寫法為:(?s)(.)(?=.*\\1)。這樣就獲取到了去除重復中文字符的博文長度。c)計算中文字符所占博文的長度:d)計算去除重復詞的中文字符所占中文字符博文的長度比例:e)計算博文長度和博文限定最長長度的比例:f)以上三個公式都是對處理字符的博文長度進行歸一化,使其值歸一化的值再計算博文的得分值(score):score=-alogcp-blogcl-clogcnrp(其中:a+b+c=1)博文的得分計算公式包含a,b,c三個參數,是對這三個特征的權重比例。經過實驗得到最優結果時的參數,分別選取0.18,0.61和0.21作為a,b,c的值。設定當score值小于0.65時,確認為非中文博文并進行過濾。步驟二,特征標簽的抽取。特征標簽包括興趣類別標簽、情感傾向標簽和時序行為標簽。其中興趣類別標簽包括社會(A),軍事(B),政治(C),經濟(D),娛樂生活(E)和其他(F),情感傾向標簽包括中立、支持、反對。從博文內容的角度出發,興趣類別標簽應該和情感傾向標簽組合生成新標簽,那么組合標簽就是A+中立、A+支持、A+反對、B+中立、B+支持、B+反對等18個特征標簽,它們代表著用戶對每一類別博文的情感傾向。對于興趣類別特征抽取,使用支持向量機算法,具體流程如圖2所示,最終得到tinterest_tag={wA,wB,wC,wD,wE,wF},表示博文的每個興趣類別權重;對于情感傾向特征抽取,使用詞向量,利用文本分類算法,對博文情感傾向進行分類,具體流程如圖3所示,最終得到tsentiment_tag={wpositive,wnegative,wneutral},表示博文的每個情感類別的權重;則ti={wAwpositive,wAwnegative,wAwneutral,…,wFwpositive,wFwnegative,wFwneutral}就是通過以上兩特征的表示,計算出博文i的組合標簽,該組合標簽一共有18組,每種標簽計算出的值可以理解成博文對于每個興趣情感類別的權重值。權重值最大的就是博文所屬的興趣情感類別。針對于用戶的興趣情感特征,則可以通過統計用戶發布博文的興趣情感類別得出的。則用戶的興趣情感特征標簽表示為:每種特征值表示用戶對于該特征的博文占他發布所有博文的百分比。時序行為特征主要根據Twitter用戶所在時區,將時間序列分為4類:Morning(6-12點),Afternoon(12-18點),Evening(18-24點)和Night(0-6點)進行分類,所以共有4種時序行為特征標簽。對于博文有4種時序類型,博文的特征表示為:ttime_tag={w1,w2,w3,w4},然后針對用戶的時序行為,需要對每個用戶發布博文的數據進行統計,則用戶的每個時序特征值就是發帖百分比,即該即該用戶未來在這個時間段在線的概率:綜上,將用戶和博文用標簽向量化表示為:u=(w1,w2,..,w22)(用戶多標簽向量化表示)t=(w1,w2,..,w22)(推文多標簽向量化表示)其中1~18維是興趣情感組合標簽,19~22維是時序行為標簽,ci指第i維標簽的特征值。綜上,就獲取了用戶和博文的特征標簽。步驟三,基于多標簽的興趣匹配度計算。將用戶和博文用標簽向量化的方式表示后,用戶u對博文t的興趣度計算使用最簡單實用的內積計算,計算公式如下:p(u,t)=u·t這里,u是用戶的標簽向量化表示,t是博文的標簽向量化表示。兩向量的內積就是用戶對該博文的興趣匹配度。2、一種基于轉發網絡的推薦方法。其特征主要是構建用戶和博文的矩陣,利用博文轉發的動態網絡,提出了用戶相似度和信任度的概念,改進了傳統協同過濾的方法。1)數據預處理。基于轉發網絡的推薦方法數據預處理流程如圖4所示。步驟一,活躍度過濾。首先該方法需要構建用戶-博文的轉推矩陣,但對于轉推行為頻率較低的用戶和被轉推頻率較低的博文,會使得轉推矩陣更加稀疏,并且大幅度降低算法效率,同時很大程度上會影響算法的結果。所以針對該方法,需要采用如下規則對用戶和博文數據進行活躍度的過濾:a)用戶在該月必須轉發至少10條博文,以保證用戶的相對活躍度;b)為了獲取到博文的轉推信息,所以該月的博文一定被轉發過。綜上,該預處理是不斷迭代的過程,直到數據集中的數據都滿足以上的兩個條件。步驟二,博文的哈希處理。獲取到活躍度過濾后的轉推博文集和用戶集后,需要獲取每條博文的轉推用戶集。為提高算法效率,本專利對轉推博文做哈希處理。這里的哈希處理使用了ApplebyAustin提出的Murmurhash算法,具體有以下幾步:a)因為在Twitter中,博文的轉發往往會追加很多格式的內容,造成了相同的博文內容不一致,所以需要用正則表達式去除一些元素,包括“RT”、“rt”、“@”、標簽符號;b)去除博文中轉發用戶的用戶名;c)使用非加密的hash算法Murmurhash算法作為哈希函數,輸入為剩余的有效字符,輸出是提取出的hash簽名。步驟三,抽取轉推關系。最后需要獲取到博文的轉推關系,從而得到用戶和用戶之間的關系網絡,以便計算用戶之間的相似度和信任度。因為博文的來源各異,包括Twitter的手機端,網頁端和其他第三方應用,導致博文內容的結構各異。經過對各種轉推博文進行分析和實驗,得出有以下幾種情況:a)RT@sb:content常規情況;b)(RT@sb:){n}contenteg:RT@sb:RT@sb:RT@sb:content;c)(RT@sb:content){n}eg:RT@sb:contentRT@sb:content;d)content.(RT@sb:content){n}eg:contentRT@sb:contentRT@sb:content。以上4中情況的content中可能會包含@sb的標識。在總結過博文的結構后,定義了正則表達式抽取出了轉發用戶的關系,正則表達式為“(?<=(rt|RT)\\s@).*?(?=[(:|\\s)])”,功能是抽取出轉發的用戶,從而構建轉發用戶的關系。抽取結果樣本如圖6(a)和圖6(b)。2)基于用戶相似度的推薦方法。步驟一,將博文做為項,通過用戶-博文的打分矩陣,計算用戶之間的相似度。這個打分矩陣只包含0和1。如果博文被轉發則為1,沒有轉發為0。用戶相似度的計算是信息推薦的重要步驟,其計算公式如下:其中分母中的N(u)是指用戶u發布的博文數,N(v)是指用戶v發布的博文數,分母是正則項,能夠使得最后用戶u和用戶v的相似度值在0和1之間。是懲罰因子,表示博文i被轉發的次數越多,該懲罰因子的值會比原始值小。這也就意味著如果博文i非常熱門,那么該博文不足以直接反應用戶之間相似程度。相反,如果博文轉發次數很少比較冷門,那么這條博文就比熱門博文更能反應轉發這條博文的用戶之間的相似度。步驟二,在獲得了用戶-博文的打分矩陣和用戶之間的相似度后,當給定用戶u和博文t后,就可以利用如下公式計算用戶u對博文t的興趣度:其中,S(u,K)包含與用戶u最相似的K個用戶集合,N(t)是指轉發或發布過博文t的用戶集合,那么用戶v就是指上述兩個集合的用戶交集。rvt是指用戶v是否轉發或發布過博文t(1為轉發或發布過,0為未轉發或發布過)。3)基于用戶信任度的推薦方法。相似度刻畫了用戶之間的無向邊屬性,與此同時,我們引入了信任度去刻畫用戶之間有向邊的屬性。信任度特征是指當用戶v轉發了用戶u發布或轉發的博文,那么就認為用戶v對用戶u有一定的信任度。步驟一,計算用戶間的信任度。從直觀上來看,如果用戶u發布了博文t,用戶v轉發了博文t,那么這就意味著用戶v比較喜歡博文t并且愿意去和他的粉絲分享,或者說用戶v重視對用戶u的網絡關系。無論從哪方面看,用戶v對用戶u都是有一定的信任度。并且用戶v越快時間轉帖,說明用戶v和用戶u的時序行為很接近,會更大可能地關注用戶u發布的博文。所以基于這個原因,本章引入了負指數分布去模擬某一條博文發布時間和轉發時間的延遲:trust值是通過負指數分布計算出來的,其中x的定義如下所示:這里createdAtv(t)-createdAtu(t)指用戶u轉發博文時間和用戶v發布博文時間的延遲。createdAtmax(t)-createdAtmin(t)指在轉推博文時間間隔中最大的延遲。這里有一個前提,用戶u和用戶v必須是相鄰的,即用戶v直接轉發了用戶u的博文,后續將具體分類討論。對于參數λ,使用最大似然估計計算其值:這里,是樣本的平均值。同時,上述針對相鄰(直接轉發關系)的用戶,對于間接轉發的用戶之間,同樣可以計算信任度的值,這里做出一個假設:即信任度的值是可以傳遞,意味著如果用戶w轉發了用戶v轉發的博文t,用戶v轉發了用戶u發布的博文t,則用戶w對用戶v同樣具有信任度,其計算如下:Patht(w,u)={trust1(w,v),trust2(v,u)}上述公式指用戶w和用戶v存在一條轉發路徑,則信任度的計算如下:通過公式說明用戶w對用戶v的信任度是指在此轉發路徑上的信任度值的乘積。以上是針對一條博文計算用戶間的信任度值。最后將所有轉發博文的所計算出的信任度值求和,從而得到用戶w和用戶u之間的信任度:由此計算出了用戶之間的信任度,構建了用戶之間的信任度矩陣和有向邊網絡。步驟二,基于用戶信任度計算用戶對博文的興趣度,類似于基于用戶相似度計算興趣度的方式。在獲得了用戶-博文的打分矩陣和用戶之間的信任度后,給定用戶u和博文t,就可利用如下公式計算用戶u對博文t的興趣度:其中,S(u,K)包含用戶u信任度最高的K個用戶集合,N(t)是指轉發或發布過博文t的用戶集合,用戶v就是指上述兩個集合的用戶交集集合。rvt是指用戶v是否轉發或發布過博文t(1為轉發或發布過,0為未轉發或發布過)。根據以上定義,計算用戶u對博文t的興趣度,重要的是獲取到用戶v集合。根據用戶v集合的要求,必須是用戶u對其信任度最高的K個用戶集合和發布或轉發過博文t的用戶集合的交集,那么用戶v一定轉發或發布了博文t,則rvt的值一定為1。計算興趣度的公式可以簡寫成如下形式:根據計算出的用戶對博文的興趣度值,就可以得到對每個用戶的Top-N博文推薦列表。4)基于用戶相似度和信任度的混合推薦方法。步驟一,因為根據兩種方法獲取到的用戶對博文的興趣值各不相同,所以分別對每個用戶所預測博文集合的相似度興趣值和信任度興趣值做歸一化處理,以便除去誤差。歸一化的公式如下:步驟二,得到歸一化后的興趣度,再利用加權公式進行最優興趣度的計算:psim_trust(u,t)=α||ptrust*(u,t)||+(1-α)||psim*(u,t)||如上公式,其中α是值在0到1之間的參數值,算法不斷在測試集上調整優化α,從而達到最優的結果。本發明前提是針對國內外流行的弱關系社交平臺,只是基于內容標簽的方法可以根據語言種類的不同,使用對應的分詞器,即可應用本發明。實施例1:以Twitter平臺為例,利用Twitter官方的API,實驗選取了一些用戶作為種子節點,然后基于種子節點,通過采集用戶的好友關系和粉絲關系擴展種子節點庫,同時過濾掉好友數量小于15的用戶。因為在本發明中這樣的用戶的信息很少,沒有研究的價值。在2014年3月到6月期間采集了平均46636個用戶和這些用戶在這四個月發布的11803979條的博文。本發明將4個月的數據作為該方法實驗的數據集。如表1所示:表1:數據集描述時間用戶數博文數2014.034064817952682014.046153651919172014.054943633924232014.06349251424371第二步,訓練集和測試集的構建。因為Twitter的官方API不能直接獲取到用戶的HomeLine(用戶關注好友的博文)。所以唯一方式是模擬用戶的HomeLine,即模擬用戶能看到的博文。在本專利實驗的每月數據集中,收集了好友數量超過15的用戶,將他們關注的好友博文作為模擬用戶能瀏覽到的博文集。之后將模擬每個用戶能瀏覽到的博文,按時間順序排序,前3/4的博文放入訓練集,后1/4的博文的放入測試集中。如表2和表3所示,展示了兩個方法構建的訓練集和測試集中的博文數和用戶數。表2:構建基于轉發網絡的信息推薦方法中訓練集和測試集實驗將活躍用戶的轉推博文放入訓練集中,用于構建相似度矩陣和信任度矩陣;從而基于相似度矩陣、信任度矩陣計算用戶對測試集中博文的興趣度。對于轉發網絡中,對于相似度和信任度的加權參數值變化結果如圖6所示。表3:構建基于內容標簽的信息推薦方法中訓練集和測試集實驗首先將抽取訓練集中博文的興趣類別特征標簽、情感傾向特征標簽和時序行為特征標簽,然后統計用戶的興趣類別特征、情感傾向特征標簽、時序行為特征標簽,最后按方法的對用戶的特征標簽進行向量化表示。對于測試集中的博文,同樣抽取三類特征標簽,進行向量化表示。計算測試集中標簽向量化表示的用戶對測試集中博文的興趣匹配度。最后計算推薦結果的MAP值。同時分別只利用興趣類別標簽、情感傾向標簽和時序行為標簽進行用戶和博文向量化表示,計算推薦結果的MAP值,與多標簽的結果進行對比。第三步,評測方法的結果對比,基于轉發網絡的信息推薦采用的評價標準是平均準確率MAP,其對比結果如下表:當方法參數α在0.2到0.3之間時,方法取到最優的推薦結果。說明在基于用戶相似度和信任度的推薦方法(STBM)中,當相似度的權重大于信任度的權重時,方法的效果最優。于是實驗將基于相似度的推薦方法(SBM)、基于信任度的推薦方法(TBM)、以及選取最優參數的基于相似度和信任度的推薦方法(STBM)三個方法的算法結果進行對比,實驗結果如表4所示:表4:三種方法的MAP值對比(%)時間2014.032014.042014.052014.06SBM61.9148.9364.7869.87TBM57.4643.4157.4253.99STBM62.7450.1065.9370.57基于內容標簽的信息推薦采用的評價標準用戶覆蓋率:統計引入基于內容標簽的推薦方法后,推薦用戶的覆蓋率變化。實驗結果如表5所示:表5:用戶覆蓋率表(%)同時比較抽取不同類型內容標簽,興趣類別(ITBM)、情感傾向(STBM)和時序行為(TTBM)特征,與同時基于三種特征標簽的方法(CTBM),對推薦結果的MAP值進行比較。對比結果如下表所示:表6:不同特征標簽方法的MAP值對比表(%)時間2014.032014.042014.052014.06ITBM59.1140.0851.3363.65STBM31.1124.0335.1155.33TTBM45.3341.1241.2252.36CTBM61.7151.2266.2368.88本實施例詳細說明了針對弱關系網絡Twitter的信息推薦方法的實踐過程,主要是對訓練集和測試集的構造,然后利用基于轉發網絡和內容推薦方法,分析和比較了本發明對于推薦精準度和推薦覆蓋率的提高。基于上述信息推薦的方法,并不局限于本發明所公開的Twitter平臺,還可結合其余社交平臺的相應特征改變具體方法的參數,實現相同的技術效果,因此不脫離本發明的發明構思與精神實質的技術方案,應當認為也屬于本發明所請求保護的范圍,故不重述。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1