用于訓練混合模型的方法和設備與流程
本公開的實施例涉及機器學習領域,并且更具體地涉及用于訓練混合模型的方法和設備。
背景技術:
混合模型是一種使用混合分布的用于密度估計的概率模型,混合模型可以包括多個子模型。混合模型的示例包括但不限于高斯混合模型、分段線性混合模型,等等。這些模型已被廣泛應用于多種領域,諸如圖像分類、文檔分類、模糊圖像分割等。
混合模型的模型選擇是一個非常重要而又具有挑戰性的問題。已知的方法例如包括分解漸進貝葉斯推理(factorizedasymptoticbayesianinference,fab)等。然而,以fab為代表的傳統混合模型訓練方法是一類批量學習算法,使其無法滿足流數據之類的新型數據模式。例如,傳統的混合模型訓練方法通常需要重復訪問全部數據集來獲得準確的學習效果,并且無法快速地發現數據集中的新的模式或概念。因此,傳統的混合模型訓練方法均無法有效地解決流數據等新型數據模式的混合模型選擇問題。
技術實現要素:
本公開的實施例提供了一種用于訓練混合模型的方法和設備,能夠實現在流數據背景下在線訓練針混合模型。
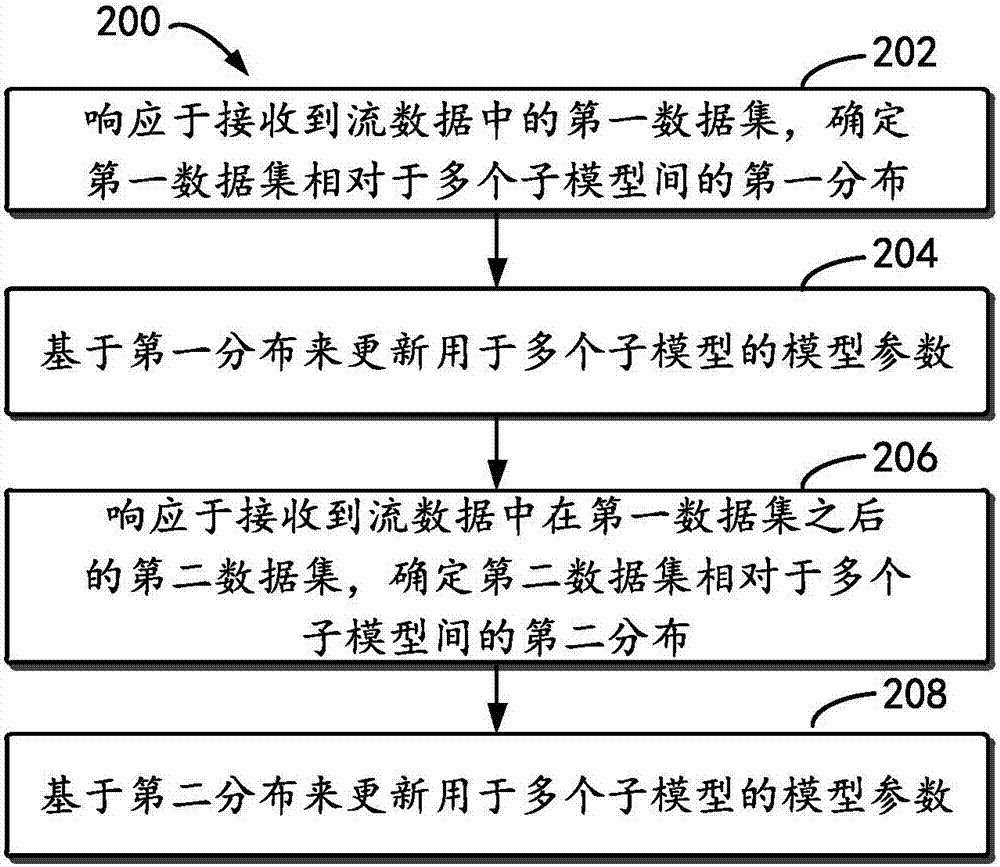
根據本公開的一個方面,提供了一種用于訓練混合模型的方法,該混合模型包括多個子模型。該方法包括:響應于接收到流數據中的第一數據集,確定第一數據集相對于多個子模型間的第一分布;以及基于第一分布來更新用于多個子模型的模型參數。該方法還包 括:響應于接收到流數據中在第一數據集之后的第二數據集,確定第二數據集相對于多個子模型間的第二分布;以及基于第二分布來更新用于多個子模型的模型參數。
根據本公開的另一方面,提供了一種用于訓練混合模型的設備,該混合模型包括多個子模型。該設備包括至少一個存儲單元和至少一個處理單元,該至少一個處理單元耦合到所述至少一個存儲單元并且被配置為:響應于接收到流數據中的第一數據集,確定第一數據集相對于多個子模型間的第一分布;以及基于第一分布來更新用于多個子模型的模型參數。該至少一個處理單元還被配置為:響應于接收到流數據中在第一數據集之后的第二數據集,確定第二數據集相對于多個子模型間的第二分布;以及基于第二分布來更新用于多個子模型的模型參數。
根據本公開的又一方面,提供了一種計算機可讀存儲介質。該計算機可讀存儲介質具有存儲在其上的計算機可讀程序指令。這些計算機可讀程序指令可以用于執行根據本公開中的各個實施例所描述的方法的步驟。
提供發明內容部分是為了簡化的形式來介紹對概念的選擇,它們在下文的具體實施方式中將被進一步描述。發明內容部分無意標識本公開的關鍵特征或主要特征,也無意限制本公開的各個實施例的范圍。
附圖說明
通過結合附圖對本公開示例性實施例進行更詳細的描述,本公開的上述以及其它目的、特征和優勢將變得更加明顯,其中,在本公開示例性實施例中,相同的參考標號通常代表相同部件。
圖1示出了根據本公開的實施例的用于訓練混合模型的架構100的框圖;
圖2示出了根據本公開的實施例的用于訓練混合模型的方法200的流程圖;
圖3示出了根據本公開的實施例的用于迭代地更新模型參數的方法300的流程圖;
圖4示出了根據本公開的實施例的用于擴展混合模型的方法400的流程圖;以及
圖5示出了可以用來實施本公開的實施例的示例設備500的示意性框圖。
具體實施例
下面將參照附圖更詳細地描述本公開的優選實施例。雖然附圖中顯示了本公開的優選實施例,然而應該理解,可以以各種形式實現本公開而不應被這里闡述的實施例所限制。相反,提供這些實施例是為了使本公開更加透徹和完整,并且能夠將本公開的范圍完整地傳達給本領域的技術人員。
在本文中使用的術語“包括”及其變形表示開放性包括,即“包括但不限于”。除非特別申明,術語“或”表示“和/或”。術語“基于”表示“至少部分地基于”。術語“一個示例實施例”和“一個實施例”表示“至少一個示例實施例”。術語“另一實施例”表示“至少一個另外的實施例”。術語“第一”、“第二”等可以指代不同的或相同的對象。下文還可能包括其他明確的和隱含的定義。
在本公開實施例中,“隱變量”可以表示不能被直接觀測到、而需要通過樣本數據推導得出的變量。隱變量的變分分布可以用于描述樣本數據被聚類到對應類別的概率。應當注意的是,在本發明實施例中,“隱變量”并不限于一種變量,而是可以包含“隱變量的變分分布”和/或其他適當的信息。在本公開中,隱變量可以包括初始化隱變量、更新后的隱變量等,其中初始化隱變量表示用于進行訓練的隱變量,而更新的隱變量表示訓練后得到隱變量。
在本公開的實施例中,“模型”一般是指混合模型,例如候選模型、中間模型以及目標模型等。模型可以基于初始化隱變量通過對樣本數據進行訓練來生成。如此生成的模型可以包括更新的隱變量的變 分分布、模型參數、模型結構等。模型參數可以根據混合模型的類型不同而不同,混合模型通常是一類模型的總稱。一個混合模型可由多個子模型組合而成,子模型也可以被稱為組件(component)。由此,模型參數與具體的混合模型的類型相關聯。
舉例而言,對于高斯混合模型而言,模型參數可以包括每個子模型所服從的高斯分布的均值和方差。對于分片線性模型而言,模型參數則可以包括門節點的條件控制參數和葉子節點的回歸系數及偏差。模型結構也與混合模型的類型相關聯。舉例而言,對于高斯混合模型而言,模型結構可以包括子模型的個數及子模型混合比率等。對于分片線性模型而言,模型結構則可以包括學習出的樹結構。應當理解,上述示例僅僅是出于討論之目的,無意以任何方式限制本公開的范圍。
如上文提及,分解漸進貝葉斯推理(fab)是一種模型貝葉斯近似推理方法,其通過迭代優化來計算隱變量的變分分布和模型參數以最大化目標函數的下界。在線分解漸進貝葉斯推理(onlinefactorizedasymptoticbayesianinference,ofab)是一種支持在線處理的fab,能夠適應針對流數據的混合模型選擇。分解信息范式(fic)是邊際對數似然的漸進近似,其表示混合模型的目標函數。fab已被用于混合模型,隱馬爾可夫模型、貝葉斯主成分分析模型等。
然而,fab以及其他傳統的模型訓練方法均無法有效地為流數據等新型數據模式選擇模型。流數據是指連續到達的數據序列,它已經逐漸成為大數據時代的常態數據模式。流數據的出現為模型選擇帶來了諸多新挑戰。例如,流數據可被視為一個隨時間延續而增長的動態數據集合,它動態出現、數據量大、到達速度快。而且,通常無法對全部流數據進行本地存儲。這導致數據是一次通過的。換言之,對于流數據中以不同批次到達的數據集通常只能進行一次處理,已經處理過的流數據不能再次被訪問和處理。又如,生成流數據的數據源往往是動態變化的,這使得新的數據模型可能動態出 現,而先前的數據模型則會失效。
為了應對流數據等新型數據模式給模型選擇帶來的上述以及其他潛在挑戰,本公開的實施例提供了一種用于訓練混合模型的方法。根據本公開的實施例,進入的流數據被在線處理隨后被丟棄。因此,無需本地存儲所有流數據,實現了針對流數據的在線混合模型訓練。此外,在本公開的另一些實施例中,用于訓練混合模型的方法能夠快速地發現數據集中的新的模式或概念。
圖1示出了根據本公開的實施例的用于訓練混合模型的架構100的框圖。如圖1所示,架構100可以包括混合模型訓練系統120,其用于訓練混合模型。應當理解,本公開的實施例適用于各種混合模型,包括但不限于高斯混合模型(gmm),分片線性模型,主元分析(pca)模型、二值矩陣分解模型,等等。實際上,任何目前已知或者將來開發的包括多個子模型的混合模型均可利用本公開的實施例來加以訓練。僅僅出于討論方便之目的,下文的某些實施例可能參考高斯混合模型來描述,但這并非以任何方式限制本公開的范圍。
混合模型訓練系統120可以連續地接收流數據110。為討論方便起見,數據流110可以表示為b={x1,x2,…,xn},其中xi表示第i個樣本,n表示樣本的數目。流數據110將被用來訓練混合模型,從而輸出混合模型130和混合模型130的模型參數。模型參數可以表示為
數據分布確定模塊122被配置為接收流數據110,并且確定流數據110相對于混合模型中多個子模型間的分布(表示為q(zb))。為討論方便,現在考慮一個示例。在此示例中,流數據110可以是由n副圖像構成的圖像集合,xi表示第i個圖像樣本。在一個實施例中,xi=(x1,…,xd),其表示一個高維向量,d表示向量的維度,其中每一維 可以是圖像中的一個像素的值。在一些實施例中,數據分布確定模塊122可以連續地接收流數據110中的第一數據集b(m-1)(m=1,2,3……)和在第一數據集b(m-1)之后的第二數據集b(m),并且順序地對第一數據集b(m-1)和第二數據集b(m)進行混合模型訓練。如上所述,混合模型包括多個子模型。例如,當流數據110為圖像集合時,混合模型訓練系統120可以將圖像集合聚類成多個圖像分類(例如聚類、簇),每個圖像分類可以表示混合模型中的一個子模型。例如,圖像的分類可以包括建筑、風景、人物、動物、植物等。因此,當流數據110為圖像集合時,數據分布確定模塊122可以接收圖像集合并且確定這些圖像的初始分類。
模型參數更新模塊124被配置為基于流數據110相對于混合模型中多個子模型間的分布q(zb)來更新多個子模型的模型參數θ。例如,當流數據110為圖像集合時,模型參數更新模塊124可以基于圖像的初始分類來更新多個圖像分類子模型的模型參數θ。在一些實施例,模型參數更新模塊124可以迭代地更新分布q(zb)和模型參數θ。例如,可以基于分布q(zb)來更新模型參數θ,并且基于更新后的模型參數θ來更新分布q(zb)。在一些實施例中,在迭代完成更新分布q(zb)和模型參數θ之后,混合模型訓練系統120可以輸出混合模型130和混合模型130的模型參數θ。
圖2示出了根據本公開的實施例的用于訓練混合模型的方法200的流程圖,該混合模型包括多個子模型。方法200可以由如圖1所示的混合模型訓練系統120來執行。應當理解的是,方法200還可以包括未示出的附加步驟和/或可以省略所示出的步驟。本公開的范圍在此方面不受限制。
方法200以步驟202開始。在步驟202中,響應于接收到流數據中的第一數據集,確定第一數據集相對于多個子模型間的分布(稱為“第一分布”)。例如,流數據110中的第一數據集可以表示為b(m-1)={xi,xi+1,…,xi+j},m=1,2,……,xi表示第一數據集b(m-1)中的樣本,j表示第一數據集b(m-1)中的樣本的數目,xi=(x1,…,xd)表示一個向 量,d表示向量的維度。響應于接收到第一數據集,數據分布確定模塊122可以確定第一數據集b(m-1)相對于多個子模型間的第一分布。例如,在一個實施例中,第一數據集相對于子模型的分布可以由第一數據集b(m-1)的隱變量的變分分布來表示。隱變量的變分分布可以表示為q(zb)(m-1)={q(zi),q(zi+1),……q(zi+j)},其中z∈{0,1}c,其表示z在c維向量上每個元素的值為0或1,c表示混合模型中的現有的子模型的數目。例如,在一個實施例中,當xn屬于第c個子模型時,znc可以被設置為1,當xn不屬于第c個子模型時,znc可以被設置為0。
仍然考慮上文描述上的流數據110為圖像集合的示例。此時,第一數據集b(m-1)可以為多幅圖像,每副圖像表示一個高維向量,其中每一維可以是圖像中的一個像素。在一些實施例中,在接收到第一數據集b(m-1)之后,可以基于混合模型中的當前的子模型來隨機地初始化隱變量的變分分布q(zb)(m-1),例如,可以將第一數據集b(m-1)中的所有樣本隨機地分布到c個子模型中。
接下來,方法200進行到步驟204,在此基于第一分布q(zb)(m-1)來更新用于多個子模型的模型參數θ。不同的模型可以具有不同的模型參數。例如,高斯混合模型的模型參數可以包括均值μ和方差σ2。又如,分片線性模型的模型參數可以包括門節點的條件控制參數和葉子節點的回歸系數及偏差。
在一個實施例中,模型參數可以表示為
其中n表示已經接收到的數據集中的樣本總數,xn表示第n個樣本,zn表示樣本xn的隱變量,q(zn)表示樣本xn的隱變量的變分分布,θ表示模型參數,c表示混合模型中的第c個子模型,c表示混合模型中的子模型的數目,dc表示第c個子模型中的模型參數的個數,znc表示樣本xn對第c個子模型的隸屬度,znc∈{0,1},
方法200繼續進行到步驟206,響應于接收到流數據中在第一數據集b(m-1)之后的第二數據集b(m),確定第二數據集相對于多個子模型間的分布(稱為“第二分布”)。與第一分布類似,第二分布例如可以由隱變量的變分分布q(zb)(m)來表示。在一些實施例中,在數據分布確定模塊122接收到第二數據集b(m)之后,可以基于混合模型中的當前的子模型來隨機地初始化隱變量的變分分布q(zb)(m),例如,可以將第二數據集b(m)中的所有樣本隨機地分布到c個子模型中。
在步驟208,基于第二分布q(zb)(m)來更新用于多個子模型的模型參數θ。針對第二數據集b(m)的處理方式可以與針對第一數據集b(m-1)的步驟202和204相同。在一些實施例中,在第二數據集b(m)之后,還可以以與步驟202和204相同的方式來處理流數據110中的第三數據集b(m+1)、第四數據集b(m+2)等。
根據用于訓練混合模型的方法200,混合模型訓練系統120順序地接收數據流中的數據集,并且通過針對當前數據集進行混合模型訓練,以便估計混合模型的子模型結構和子模型參數,從而能夠實現在線訓練針對流數據的混合模型。
圖3示出了根據本公開的實施例的用于更新模型參數的方法300的流程圖。將會理解,方法300可以視作上文參考圖2描述的方法200中的步驟204的一個示例實現。在圖3所示的實施例中,模型參 數基于第一分布被確定或更新,而后第一分布相應地更新。這個過程迭代地進行,直到預定的收斂條件被滿足。
具體而言,在步驟302,可以基于變分分布q(t-1)來更新混合模型的模型參數θ,其中
其中t-1表示上一次迭代,q(t-1)表示上一次迭代時隱變量的變分分布,θ表示混合模型的模型參數,xn表示第n個樣本,εt表示超參數,dkl表示上一次迭代時模型參數θ(t-1)與當前迭代時的模型參數θ之間的kl散度(kullback–leiblerdivergence)。將會理解,公式(1)中的目標函數
在步驟304,基于更新后的模型參數θ來更新針對數據集b的變分分布q(t)。在一些實施例中,例如可以通過以下公式(3)并基于模型參數θ來更新隱變量的變分分布q(t)(znc)。
其中∝表示正比關系,t表示當前迭代,xn表示第n個樣本,
方法300繼續進行到步驟306,判斷是否滿足收斂條件。在一些實施例中,收斂條件可以是迭代的次數已經達到預定次數。也就是 說,步驟302和304已經重復執行預定次數。備選地或附加地,在一些實施例中,收斂條件可以為隱變量的變分分布q(zb)的變化量低于第一預定閾值。又如,收斂條件也可以為模型參數θ的變化量低于第二預定閾值。備選地或附加地,收斂條件還可以為混合模型的目標函數的變化量低于第三預定閾值。也就是說,當隱變量的變分分布q(zb)、模型參數θ和混合模型的目標函數中的一個或多個開始收斂時,可以確定滿足收斂條件。
在一些實施例中,通過以上所描述的公式(2)和公式(3)迭代地更新第一分布q(zb)(m-1)和模型參數θ,可以實現第一數據集b(m-1)相對于多個子模型間的分布q(zb)(m-1)。在一些實施例中,當流數據110為圖像集合時,例如可以將第一副圖像分類為風景,第二副圖像分類為建筑等,并且還能夠確定各個圖像分類(例如,風景、建筑、人物等)子模型的模型參數和混合比率。
如果在步驟306確定沒有滿足收斂條件,則方法300返回步驟302和304繼續下一輪迭代,直到滿足收斂條件。如果在步驟306確定已經滿足收斂條件,則方法300進行到步驟308,在此判斷流數據中是否還有其他的數據集。如果流數據中還有其他的數據集,方法300返回步驟302-306以處理流數據中的下一數據集。如果流數據中的所有數據集都已經被處理完或者收到了系統的模型輸出請求,則可以在步驟310,輸出混合模型130。
在某些實施例中,可選地,可以在模型訓練之后或者過程中對模型進行收縮。例如,在某些實施例中,當混合模型130被調用時,可以確定該混合模型中是否存在不活躍子模型。在此使用的術語“不活躍子模型”是指在其上分布的數據量小于閾值量的子模型。例如,通過移除不活躍子模型來收縮混合模型,并且輸出經收縮的混合模型。在一些實施例中,可以設置閾值δ,并且如果以下公式(4)成立,則確定混合模型中的第c個子模型是不活躍的子模型。
其中znc表示樣本xn對第c個子模型的隸屬度,znc∈{0,1},q(znc)表示隱變量znc的變分分布,εt表示超參數,αc(t)表示當前迭代時子模型c的混合比率,δ表示閾值。
在用于訓練混合模型的方法300中,可以通過確定隱變量的變分分布、模型參數和混合模型的目標函數中的一個或多個是否收斂,來確定是否滿足收斂條件,有效地保證了模型訓練的高準確性。備選地或附加地,也可以通過設置預定的迭代次數,能夠加快數據集被處理的速度,從而能夠在高準確性和快處理速度之間進行平衡,以滿足針對大量連續出現的流數據的混合模型訓練。
此外,不同于傳統模型訓練方案,本公開的實施例還可以隨著流數據的處理而擴展混合模型。圖4示出了根據本公開的實施例的用于擴展混合模型的方法400的流程圖。
在步驟402中,確定多個子模型中的活躍子模型的數目。在此使用的術語“活躍子模型”是指其上分布的數據量超過閾值量的子模型。在一些實施例中,可以設置閾值δ,并且如果以下公式(5)成立,則確定混合模型中的第c個子模型是活躍的子模型。
其中znc表示樣本xn對第c個子模型的隸屬度,znc∈{0,1},q(znc)表示隱變量znc的變分分布,εt表示超參數,αc(t)表示當前迭代時子模型c的混合比率,δ表示閾值。
方法400繼續進行到步驟404,基于活躍子模型的數目來確定飽和度,飽和度表示混合模型中當前子模型的飽和程度,較高的飽和度說明需要添加新的子模型。在一個實施例中,可以將活躍子模型的數目與動態閾值k之間的比值確定為飽和度。
在步驟406,確定混合模型的飽和度是否超過閾值水平。閾值水平可以根據需要進行設置,作為示例,閾值水平可以設置為例如1。當然,特定的數值僅僅是為了說明之目的,任何其他的數值同樣是 可行的。也就是說,如果活躍子模型的數目與動態閾值k之間比值大于等于1(即,活躍子模型的數目大于動態閾值k時),則認為子模型過于飽和;否則認為子模型欠飽和。
如果混合模型的飽和度超過閾值水平,則方法400進入步驟408,在此通過向混合模型添加新的子模型來擴展混合模型。新的子模型表示混合模型訓練過程中所感知的新的模式或概念。在某些實施例中,在步驟410中,響應于混合模型被擴展,可以動態地提高飽和度的閾值水平k。例如,可以將閾值水平k增加新添加的子模型的個數。當然,步驟410處對閾值的動態調整并非必須的,而是可選的。例如,可以在混合模型擴展達到預定次數之后再提高閾值水平k的數值,也可以由用戶手動調整閾值,等等。在步驟412中,在混合模型中添加完新的子模型之后,確定混合模型中的子模型。另一方面,如果在步驟406確定混合模型的飽和度沒有超過閾值水平,則方法400從步驟406直接進入步驟412,直接確定混合模型中的子模型,而無需在混合模型中添加子模型。
現在考慮一個具體的示例。假設流數據為圖像集合,初始的混合模型可能僅包括針對“建筑”、“風景”、“人物”、“動物”、“植物”這些圖像分類的子模型。隨著新的圖像集合的出現,例如,出現了關于食物的子模型,可以根據用于擴展混合模型的方法400,將食物子模型和食物子模型的模型參數添加混合模型中。
在本公開的一些實施例中,在針對流數據的混合模型訓練過程中,僅添加子模型而不刪除子模型,以便更好地適應流數據的特點。這是因為,過早的刪除子模型可能導致隨后到達的數據沒有適當的子模型。在這樣的示例中,例如可以僅在混合模型被調用時,才刪除混合模型中不活躍的子模型。以此方式,本公開的實施例不但能夠保證及時地發現新的模式或概念,而且也能避免潛在活躍的子模型過早的被刪除。其中潛在活躍的子模型針對當前數據集可能屬于不活躍子模型,但是針對后續的數據集可能屬于活躍子模型。
圖5示出了可以用來實施本公開的實施例的示例設備500的示 意性框圖。如圖所示,設備500包括中央處理單元(cpu)501,其可以根據存儲在只讀存儲器(rom)502中的計算機程序指令或者從存儲單元508加載到隨機訪問存儲器(ram)503中的計算機程序指令,來執行各種適當的動作和處理。在ram503中,還可存儲設備500操作所需的各種程序和數據。cpu501、rom502以及ram503通過總線504彼此相連。輸入/輸出(i/o)接口505也連接至總線504。
設備500中的多個部件連接至i/o接口505,包括:輸入單元506,例如鍵盤、鼠標等;輸出單元507,例如各種類型的顯示器、揚聲器等;存儲單元508,例如磁盤、光盤等;以及通信單元509,例如網卡、調制解調器、無線通信收發機等。通信單元509允許設備500通過諸如因特網的計算機網絡和/或各種電信網絡與其他設備交換信息/數據。
上文所描述的各個過程和處理,例如方法200、300和/或400,可由處理單元501執行。例如,在一些實施例中,方法200、300和/或400可以被實現為計算機軟件程序,其被有形地包含于機器可讀介質,例如存儲單元508。在一些實施例中,計算機程序的部分或者全部可以經由rom502和/或通信單元509而被載入和/或安裝到設備500上。當計算機程序被加載到ram503并由cpu501執行時,可以執行上文描述的方法200、300和/或400中的一個或多個步驟。
本公開可以是系統、方法和/或計算機程序產品。計算機程序產品可以包括計算機可讀存儲介質,其上載有用于執行本公開的各個方面的計算機可讀程序指令。
計算機可讀存儲介質可以是可以保持和存儲由指令執行設備使用的指令的有形設備。計算機可讀存儲介質例如可以是――但不限于――電存儲設備、磁存儲設備、光存儲設備、電磁存儲設備、半導體存儲設備或者上述的任意合適的組合。計算機可讀存儲介質的更具體的例子(非窮舉的列表)包括:便攜式計算機盤、硬盤、隨機存取存儲器(ram)、只讀存儲器(rom)、可擦式可編程只讀存 儲器(eprom或閃存)、靜態隨機存取存儲器(sram)、便攜式壓縮盤只讀存儲器(cd-rom)、數字多功能盤(dvd)、記憶棒、軟盤、機械編碼設備、例如其上存儲有指令的打孔卡或凹槽內凸起結構、以及上述的任意合適的組合。這里所使用的計算機可讀存儲介質不被解釋為瞬時信號本身,諸如無線電波或者其他自由傳播的電磁波、通過波導或其他傳輸媒介傳播的電磁波(例如,通過光纖電纜的光脈沖)、或者通過電線傳輸的電信號。
這里所描述的計算機可讀程序指令可以從計算機可讀存儲介質下載到各個計算/處理設備,或者通過網絡、例如因特網、局域網、廣域網和/或無線網下載到外部計算機或外部存儲設備。網絡可以包括銅傳輸電纜、光纖傳輸、無線傳輸、路由器、防火墻、交換機、網關計算機和/或邊緣服務器。每個計算/處理設備中的網絡適配卡或者網絡接口從網絡接收計算機可讀程序指令,并轉發該計算機可讀程序指令,以供存儲在各個計算/處理設備中的計算機可讀存儲介質中。
用于執行本公開操作的計算機程序指令可以是匯編指令、指令集架構(isa)指令、機器指令、機器相關指令、微代碼、固件指令、狀態設置數據、或者以一種或多種編程語言的任意組合編寫的源代碼或目標代碼,所述編程語言包括面向對象的編程語言—諸如smalltalk、c++等,以及常規的過程式編程語言—諸如“c”語言或類似的編程語言。計算機可讀程序指令可以完全地在用戶計算機上執行、部分地在用戶計算機上執行、作為一個獨立的軟件包執行、部分在用戶計算機上部分在遠程計算機上執行、或者完全在遠程計算機或服務器上執行。在涉及遠程計算機的情形中,遠程計算機可以通過任意種類的網絡—包括局域網(lan)或廣域網(wan)—連接到用戶計算機,或者,可以連接到外部計算機(例如利用因特網服務提供商來通過因特網連接)。在一些實施例中,通過利用計算機可讀程序指令的狀態信息來個性化定制電子電路,例如可編程邏輯電路、現場可編程門陣列(fpga)或可編程邏輯陣列(pla),該電子電 路可以執行計算機可讀程序指令,從而實現本公開的各個方面。
這里參照根據本公開實施例的方法、裝置(系統)和計算機程序產品的流程圖和/或框圖描述了本公開的各個方面。應當理解,流程圖和/或框圖的每個方框以及流程圖和/或框圖中各方框的組合,都可以由計算機可讀程序指令實現。
這些計算機可讀程序指令可以提供給通用計算機、專用計算機或其它可編程數據處理裝置的處理單元,從而生產出一種機器,使得這些指令在通過計算機或其它可編程數據處理裝置的處理單元執行時,產生了實現流程圖和/或框圖中的一個或多個方框中規定的功能/動作的裝置。也可以把這些計算機可讀程序指令存儲在計算機可讀存儲介質中,這些指令使得計算機、可編程數據處理裝置和/或其他設備以特定方式工作,從而,存儲有指令的計算機可讀介質則包括一個制造品,其包括實現流程圖和/或框圖中的一個或多個方框中規定的功能/動作的各個方面的指令。
也可以把計算機可讀程序指令加載到計算機、其它可編程數據處理裝置、或其它設備上,使得在計算機、其它可編程數據處理裝置或其它設備上執行一系列操作步驟,以產生計算機實現的過程,從而使得在計算機、其它可編程數據處理裝置、或其它設備上執行的指令實現流程圖和/或框圖中的一個或多個方框中規定的功能/動作。
附圖中的流程圖和框圖顯示了根據本公開的多個實施例的系統、方法和計算機程序產品的可能實現的體系架構、功能和操作。在這點上,流程圖或框圖中的每個方框可以代表一個模塊、程序段或指令的一部分,所述模塊、程序段或指令的一部分包含一個或多個用于實現規定的邏輯功能的可執行指令。在有些作為替換的實現中,方框中所標注的功能也可以以不同于附圖中所標注的順序發生。例如,兩個連續的方框實際上可以基本并行地執行,它們有時也可以按相反的順序執行,這依所涉及的功能而定。也要注意的是,框圖和/或流程圖中的每個方框、以及框圖和/或流程圖中的方框的組 合,可以用執行規定的功能或動作的專用的基于硬件的系統來實現,或者可以用專用硬件與計算機指令的組合來實現。
以上已經描述了本公開的各實施例,上述說明是示例性的,并非窮盡性的,并且也不限于所披露的各實施例。在不偏離所說明的各實施例的范圍和精神的情況下,對于本技術領域的普通技術人員來說許多修改和變更都是顯而易見的。本文中所用術語的選擇,旨在最好地解釋各實施例的原理、實際應用或對市場中技術的技術改進,或者使本技術領域的其它普通技術人員能理解本文披露的各實施例。
- 還沒有人留言評論。精彩留言會獲得點贊!