一種基于svm算法的干細胞活性檢測系統的制作方法
本發明涉及干細胞領域,尤其涉及一種基于svm算法的干細胞活性檢測系統。
背景技術:
細胞凋亡是細胞增殖的反面,探討的是細胞死亡的方式與機制。凋亡一詞來源于希臘語。原指花瓣、葉片的脫落。自1972年kerr首次提出細胞凋亡的概念以來,隨著細胞生物學、免疫學和腫瘤學的研究發展,最近幾年人們對細胞凋亡的重大理論意義和實際意義有了更深的理解。細胞凋亡是指在一定的生理和病理情況下,機體為維護內環境的穩定,通過基因調控而使細胞自動消亡的過程。不同類型的細胞,在發生凋亡時的動力學過程也不一致,存在著一定的形態學和生物化學的差異,但若干基本變化是大同小異的。其特征為:整個胞體呈濃縮狀,有特異性胞漿大泡,胞質、核質深染,核碎裂后被細胞膜包裹而形成凋亡小體。它有別于細胞死亡。在瓊脂糖凝膠電泳上顯示出特殊的dna梯狀圖譜。它的出現主要是由于一種鈣-鎂依賴性核酸內切酶激活后,裂解染色質核小體之間的連接dna,將核小體切割成180bp~200bp或其倍數的片段所致。apo是不可逆的過程,散在分布于組織中,形成的凋亡小體,除核裂解外,外有膜包繞,內有完整的細胞器,凋亡小體在組織中很快被鄰近組織細胞吞噬,并在溶酶體中被降解。因此,apo不引起周圍組織炎癥及損傷。apo是機體自己啟動,由細胞本身主動控制,由基因指導的細胞自我消亡過程。因此,又稱程序性細胞死亡。光鏡下,apo的典型形態學特征是核染色質廣泛凝聚,細胞體積縮小,胞質濃縮,有凋亡小體存在,細胞表面特化結構如微絨毛等丟失及細胞表面明顯的迂曲。體內細胞凋亡過程發展非常迅速,細胞常在數小時內完成apo并降解,凋亡細胞僅出現數分鐘就消失,故不適宜應用形態學方法(普通光學顯微鏡檢測法、熒光顯微鏡檢測法、凋亡小體的電鏡觀察及凋亡指數和細胞活力的定量測定)來檢測。在生物化學方面,利用電泳技術證明核體斷片的“dna梯狀圖譜”作為檢測群體細胞發生凋亡的一個指標。經過人們多年的研究發現,應用原位末端轉移酶標記技術(tdtassayortunelreaction)來檢測細胞凋亡,其靈敏度高,特異性強,能早期顯示未發生典型變化的凋亡細胞。它是檢測單個細胞早期出現凋亡現象的好方法。近幾年,人們又發現了能更快、更敏感、檢測細胞數量更多的并能從更多方面證明凋亡和壞死的流式細胞分析術(flowcytometry,fcm包括亞“g1”峰檢測法和末端轉移酶標記技術)等。
細胞凋亡的發生是由于鈣-鎂依賴性核酸酶進入核小體間切割dna,產生180bp~200bp或其倍數的核小體片段。而核小體由于與組蛋白h2a、h2b、h3和h4形成緊密復合物而不被核酸內切酶切割。采用雙抗體夾心酶免疫法,應用小鼠抗dna和抗組蛋白的單克隆抗體,與核小體片段形成夾心結構,可特異性檢測細胞溶解物中的核小體片段。
材料與試劑1.采用boehringermannheim公司試劑盒,生物標記的小鼠抗組蛋白單克隆抗體。2.過氧化物酶(-pod)標記的小鼠抗dna單克隆抗體3.鏈霉親合素包被的微孔板4.dna-組蛋白復合物,作為陰性對照。5.abts底物6.溶解緩沖液7.溫育緩沖液8.底物緩沖液。
樣品1.培養細胞或離體細胞的裂解物細胞裂解步驟:收集細胞,離心后,用200μl溶細胞緩沖液重新懸浮,室溫下作用30min。2.培養細胞的上清液3.血漿(血清)。
操作方法:1.取樣品離心后(1000r/min,10min),吸取20μl上清液,加入鏈霉親合素包被的培養板孔中。2.另加入80μl免疫反應試劑含抗-dna-pod、抗組蛋白-生物素及溫育緩沖液(按1∶1∶18混合),室溫下孵育2h(置搖床上,250r/min)。3.取上清,用300μl溫育緩沖液洗滌3次,小心移去洗滌液。4.加入100μl底物緩沖液,室溫下孵育使顏色變化至適合(置搖床上)。5.盡快作比色分析(10min~20min內),用底物緩沖液作空白對照,以波長405nm,參考波長492nm進行檢測。
結果判定按下列公式計算細胞釋放的單/低聚核小體片段的特別聚集值:注:mu=吸收值(10-3)=雙孔吸收值的平均od值-底物od值,若樣品的吸收值超過比色測定范圍,應適當稀釋后再檢測。
原理凋亡細胞是由于內源性核酸內切酶的激活后,將dna切割成許多雙鏈dna片段以及高分子量dna單鏈斷裂點(缺口),暴露出大量3-羥基末端,如用末端脫氧核苷酸轉移酶(tdt)將標記的dutp進行缺口末端標記,則可原位特異地顯示出凋亡細胞。主要應用的是熒光標記法和酶標記法。(二)熒光標記法1.材料與試劑采用德國boehringer-mannheim公司insitucelldeathdetection試劑盒,或美國oncor公司apoptagtm試劑盒,包括:⑴生物素標記的-dutp(biotin-dutp)或地高辛標記的-dutp(digoxingeningll-dutp)1nmol/μl⑵tdt酶(25u/μl)⑶反應緩沖液⑷洗滌緩沖液⑸異硫氰酸熒光素(fitc)標記的親合素或鏈霉親合素(2.5μg/ml)或抗地高辛抗體(1∶30)⑹pi染液(含pi5μg/ml及無dna酶活性的rna酶0.1%)⑺pbs緩沖液⑻塑料蓋玻片2.樣品⑴懸浮生長培養細胞的甩片或涂片⑵貼壁生長的培養細胞⑶冰凍切片⑷常規石蠟切片。
操作方法(1)固定:培養細胞的制片或冰凍切片用4%多聚甲醛固定30min(4℃)后,用80%酒精再固定2h(-20℃)。常規4%中性福爾馬林固定、石蠟包埋之切片進行脫蠟、水化。(2)洗滌:玻片浸入pbs緩沖液,搖床上洗滌5min,三次。(3)反應:洗滌后的玻片用吸水紙吸干細胞或組織周圍水分,按50μl/㎝2滴加反應液(每50μl反應液含tdt酶0.5μl,標記的-dutp1μl),使反應液均勻地覆蓋于所有細胞或組織切片上,蓋上塑料蓋玻片,置濕盒中,37℃孵育1h。(4)終止反應:去掉塑料蓋玻片,將玻片置盛有洗滌緩沖液的染色缸內,洗滌兩次,每次5min。(5)fitc標記:洗滌后的玻片用吸水紙吸去細胞或組織周圍水分,按50μl/㎝2滴加fitc反應液(含fitc2.5μg/ml),室溫下避光孵育10min。(6)洗滌:將玻片置于洗滌緩沖液內,洗兩次,每次5min。(7)pi復染:將玻片置于盛有pi染液的染色缸內,室溫下避光染色30min。(8)封片:用蓋玻片直接蓋在含pi染液的玻片上,亦可用無色指甲油涂于蓋玻片四周邊緣,置暗盒中,盡早鏡檢觀察。4.結果判定:用熒光顯微鏡觀察,選用藍色激發光(波長488nm),所有的細胞核均被pi著色,顯示出紅色熒光,而凋亡細胞被特異地標記上fitc,顯示出黃綠色熒光。(三)酶標記法1.材料與試劑采用美國oncor公司apoptagtm-peroxidase試劑盒,包括:⑴過氧化物酶標記的抗地高辛抗體⑵反應緩沖液⑶tdt酶⑷反應終止/洗滌液⑸平衡緩沖液⑹蛋白酶k消化液:20μg/ml蛋白酶k溶于pbs。⑺30%h2o2⑻dab顯色液:0.05%的diaminobenzidine(dab)溶于pbs,用前過濾并加入0.02%h2o2。⑼甲基綠染液:0.5%甲基綠溶于0.1mol/l枸櫞酸鈉,ph調整到4.0。⑽塑料蓋玻片及玻璃蓋玻片。
樣品同熒光標記法。3.操作方法⑴固定:同熒光標記法。⑵內源性過氧化物封閉玻片置于盛有0.5%h2o2緩沖溶液的染色缸內,室溫下作用20min后,同熒光標記法洗滌。⑶消化:玻片浸于盛有蛋白酶k消化液的染色缸,室溫下消化15min,洗滌同上。⑷平衡處理:將細胞或組織周圍液體用吸水紙吸干,滴加平衡緩沖液(按70μl/cm2)覆蓋細胞或組織表面,蓋上塑料蓋玻片,室溫下作用5min~10min。⑸反應:移去蓋玻片,傾去平衡液,用吸水紙吸干周圍液體,滴加反應液(按50μl/㎝2,18μltdt酶+36μl反應緩沖液),均勻覆蓋在細胞或組織上,蓋上塑料蓋玻片,置于濕盒中,37℃溫育1h。⑹終止反應:移去蓋玻片,將玻片置于盛有終止/洗滌液的染色缸內,37℃下洗滌30min(置搖床上振搖)。然后將玻片置于洗滌緩沖液內,洗兩次,每次5min。⑺地高辛抗體反應:用吸水紙吸干細胞或組織周圍液體,滴加70μl過氧化物酶標記的地高辛抗體,均勻覆蓋,加上塑料蓋玻片,室溫下置于濕盒中,孵育30min。⑻洗滌:置于洗滌緩沖液內,洗兩次,每次5min。⑼用吸水紙吸干細胞或組織周圍液體,滴加新鮮配制的dab顯色液,均勻覆蓋,加上塑料蓋玻片,室溫下作用3min~6min。⑽洗滌:置于蒸餾水中洗滌3次,每次3min~6min。⑾套染:將玻片置于盛有甲基綠染液的染色缸中,室溫染色10min。⑿洗滌:蒸餾水洗滌3次(置于搖床上),每次2min。⒀脫水、封片:100%正丁醇,3次,每次2min。二甲苯,3次,每次2min。明膠甘油封片。4.結果判定光學顯微鏡下觀察,所有的細胞核均著綠色,凋亡的細胞核染色質顯示出特異性的棕黃色。
annexinv-egfp細胞凋亡檢測試劑盒產品說明:凋亡是一種程序性的細胞死亡,與細胞的壞死有生化和形態等方面的不同。磷酯酰絲氨酸(phosphatidylserine,ps)是細胞膜的一種組成成分,在正常細胞主要分布在細胞膜內側;細胞發生凋亡的早期,ps會外翻到細胞表面,即細胞膜外側。annexinv對ps有高度的親和力,可以選擇性結合和標記ps。本試劑盒采用重組人annexinv-egfp融合蛋白,來檢測細胞凋亡時出現在細胞膜表面的ps,標識出凋亡細胞。由于壞死細胞和凋亡晚期細胞,其膜內側的ps也可以被annexinv結合,通常用另一種活細胞非透過性熒光染料碘化丙啶(propidiumiodide,pi)進行雙重染色,以區別凋亡早期細胞與壞死細胞和凋亡晚期的細胞。用annexinv-egfp和pi染色后,正常的活細胞不被annexinv-egfp和pi著色;凋亡早期的細胞僅被annexinv-egfp著色,pi染色呈陰性;壞死細胞和凋亡晚期的細胞可以同時被annexinv-egfp和pi著色。用流式細胞儀或熒光顯微鏡直接觀察ps外翻這一細胞凋亡的重要特征,是一種快速簡便的細胞凋亡經典檢方法。操作方法:染色液的配制:1)取適量4xannexinv結合液,用雙蒸水稀釋至1xannexinv結合液。后續工作均使用1xannexinv結合液。2)將20μlannexinv-egfp加入1mlannexinv結合緩沖液中,即配成10次測試的annexinv染色液,3)將5μlpi加入5mlannexinv結合緩沖液中,即配成10次測試的pi染色液。annexinv-egfp細胞凋亡檢測試劑盒產品說明:凋亡是一種程序性的細胞死亡,與細胞的壞死有生化和形態等方面的不同。磷酯酰絲氨酸(phosphatidylserineps)是細胞膜的一種組成成分,在正常細胞主要分布在細胞膜內側;細胞發生凋亡的早期,ps會外翻到細胞表面,即細胞膜外側。annexinv對ps有高度的親和力,可以選擇性結合和標記ps。本試劑盒采用重組人annexinv-egfp融合蛋白,來檢測細胞凋亡時出現在細胞膜表面的ps,標識出凋亡細胞。由于壞死細胞和凋亡晚期細胞,其膜內側的ps也可以被annexinv結合,通常用另一種活細胞非透過性熒光染料碘化丙啶(propidiumiodide,pi)進行雙重染色,以區別凋亡早期細胞與壞死細胞和凋亡晚期的細胞。用annexinv-egfp和pi染色后,正常的活細胞不被annexinv-egfp和pi著色;凋亡早期的細胞僅被annexinv-egfp著色,pi染色呈陰性;壞死細胞和凋亡晚期的細胞可以同時被annexinv-egfp和pi著色。用流式細胞儀或熒光顯微鏡直接觀察ps外翻這一細胞凋亡的重要特征,是一種快速簡便的細胞凋亡經典檢方法。操作方法:染色液的配制:1)取適量4xannexinv結合液,用雙蒸水稀釋至1xannexinv結合液。后續工作均使用1xannexinv結合液。2)將20μlannexinv-egfp加入1mlannexinv結合緩沖液中,即配成10次測試的annexinv染色液。3)將5μlpi加入5mlannexinv結合緩沖液中,即配成10次測試的pi染色液。方法很多,下面簡單介紹幾種1.形態觀察,用dapi染色,具體自己看書2.tunnel法。因為凋亡細胞dna會被切斷,所以會出現3’末端,這種方法就是標記3’末端。具體自己翻閱資料3.彗星電泳法,用單個細胞破碎然后電泳,其dna條帶呈彗星狀。4.dna電泳梯度條帶法就不用說了吧,這個最經典5.流式細胞儀法。因為能夠檢測dna含量。具體想了解的話還是自己去看書吧。一、細胞凋亡的形態學檢測細胞凋亡與壞死是兩種完全不同的細胞凋亡形式,根據死亡細胞在形態學、生物化學和分子生物學上的差別,可以將二者區別開來。細胞凋亡的檢測方法有很多,下面介紹幾種常用的測定方法。根據凋亡細胞固有的形態特征,人們已經設計了許多不同的細胞凋亡形態學檢測方法。1光學顯微鏡和倒置顯微鏡(1)未染色細胞:凋亡細胞的體積變小、變形,細胞膜完整但出現發泡現象,細胞凋亡晚期可見凋亡小體。貼壁細胞出現皺縮、變圓、脫落。(2)染色細胞:常用姬姆薩染色、瑞氏染色等。凋亡細胞的染色質濃縮、邊緣化,核膜裂解、染色質分割成塊狀和凋亡小體等典型的凋亡形態。2熒光顯微鏡和共聚焦激光掃描顯微鏡一般以細胞核染色質的形態學改變為指標來評判細胞凋亡的進展情況。常用的dna特異性染料有:ho33342(hoechst33342),ho33258(hoechst33258),dapi。三種染料與dna的結合是非嵌入式的,主要結合在dna的a-t堿基區。紫外光激發時發射明亮的藍色熒光。hoechst是與dna特異結合的活性染料,儲存液用蒸餾水配成1mg/ml的濃度,使用時用pbs稀釋成終濃度為2-5mg/ml。dapi為半通透性,用于常規固定細胞的染色。儲存液用蒸餾水配成1mg/ml的濃度,使用終濃度一般為0.5-1mg/ml。結果評判:細胞凋亡過程中細胞核染色質的形態學改變分為三期:ⅰ期的細胞核呈波紋狀(rippled)或呈折縫樣(creased),部分染色質出現濃縮狀態;ⅱa期細胞核的染色質高度凝聚、邊緣化;ⅱb期的細胞核裂解為碎塊,產生凋亡小體。3透射電子顯微鏡觀察結果評判:凋亡細胞體積變小,細胞質濃縮。凋亡ⅰ期(pro-apoptosisnuclei)的細胞核內染色質高度盤繞,出現許多稱為氣穴現象(cavitations)的空泡結構,ⅱa期細胞核的染色質高度凝聚、邊緣化;細胞凋亡的晚期,細胞核裂解為碎塊,產生凋亡小體。
特征選擇技術是在計算機、信息論等快速發展的背景下,為解決大規模高維數據問題而衍生的,是探索數據規律和提高數據可理解性的重要手段。通過特征選擇,縮減的數據集可以降低算法復雜度、簡化分類模型。機器學習算法與特征選擇都是數據挖掘的重要工具與手段。
特征選擇也稱為屬性選擇或變量選擇。作為一種常見的降維方式,選擇技術已得到深入研究和廣泛應用,但目前特征選擇并沒有一個固定的模式和統一完善的數學定義,因研究對象和任務要求的不同,特征選擇算法所關注的側重點也不一樣,即使對于一個相對明確的問題,特征選擇的含義或者目的也可能不同,眾多研究者從問題的不同角度出發。將其大致分為四種不同定義:
理想定義:尋找必要的、足以識別目標函數的最小維數特征子集1.9j;
經典定義:從最初的階特征中選出ⅳ爪特征組成的子集(n≤f),并最優化一個特定的評估準91,ilt,其中ⅳ是指定的維數;
提高預測性能定義:在不降低分類器預測精度的前提下,選擇盡量小的特征子集;
相似類分布定義:選擇盡可能小的特征子集,并保證選擇后的數據類分布與原始數據類分布相似。
盡管特征選有著不同層面的理解方式,但無論哪種定義,特征選擇都是從原始數據特征空間出發,按給定的評價準則選擇一個特征子集,使其與目標概念最相關的過程。
綜上所述,針對現有技術存在的缺陷,特別需要一種基于svm算法的干細胞活性檢測系統,以解決現有技術的不足。
技術實現要素:
本發明的目的是提供一種基于svm算法的干細胞活性檢測系統,通過消除冗余、無關特征,選擇出對分類器有用的特征組成子集,即從原始外特征中選擇外有效特征組成最優子集,使選擇出來的特征子集構造的分類或者回歸模型更加簡化,并能獲得更高的分類準確率。
本發明為解決其技術問題所采用的技術方案是,
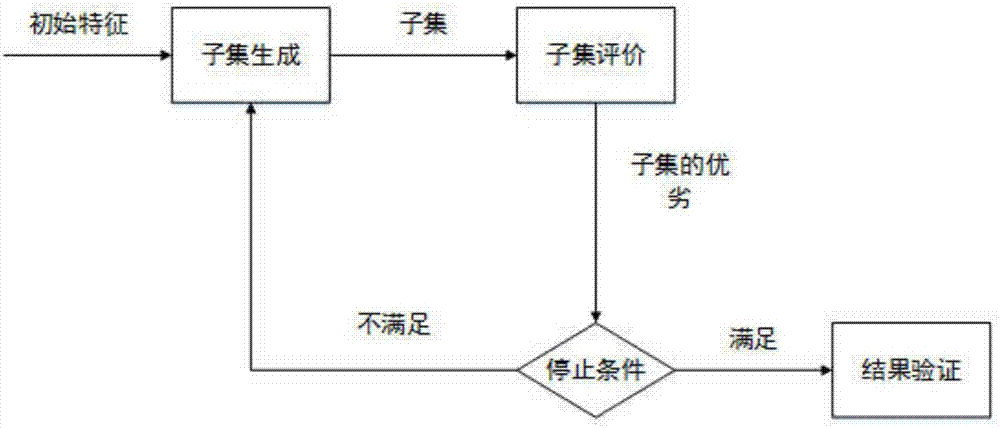
一種基于svm算法的干細胞活性檢測系統,該系統包括有子集生成單元、子集評價單元、停止條件單元、結果驗證單元;
子集生成單元實質上是一個搜索的過程,從搜索點出發,在一定的范圍內適當地添加或者移除不同特征以產生新的子集,提供給評價函數,不同的搜索方法意味著不一樣的搜索效率和不一樣的選擇結果;
子集評價單元根據特定的評估準則來判斷每個子集的優良程度,不同的評價標準可能導致不一樣的最優子集,在特征選擇過程中,每進行一次新的子集評價,都要將新的評價值和之前的最優評價值進行比較,再選出當前評價值最優的子集;
停止條件單元是指特征選擇算法滿足一定條件下停止搜索,否則子集搜索過程一直持續,常用的停止準則有三種:
a)達到了用戶事先設定的最大迭代次數或指定特征數;
b)特征子集數目的增加或減少都不能獲得更好的評價指標;
c)已經找到當前評價函數或用戶需求的最優子集;
結果驗證單元是驗證所選特征子集的有效性,最直接的驗證方法就是分別對原始數據集和經過特征選擇后得到的數據集進行訓練、預測,然后比較前后兩種訓練模型的復雜度和預測精度。
進一步,在模式識別領域,支持向量機最初是在研究線性可分問題中提出的,對于大小為z的數據集{(xi,yi),i=1,2,….,l},xi是d是d維輸入向量y的樣本標簽為{一1,1},如果存在最優分類面y=w.x+6能將樣本正確分成兩類,則定義d維特征空間中的線性判別函數為,(x)=w.x+b,
此時任意樣本x.到最優分類面的距離為
εi=yi(w·xi+b)=|w·xi+b|。
進一步,類間隔(margin)就是劇與加之間的距離,并使兩類樣本都滿足:
fxi≥1,,
再將歸一化后得到不同類之間的距離(幾何間隔)
因為樣本的誤分次數n與分類間隔萬存在著如下關系
n≤2rδ2
所以我們以最大化分類間隔為目標,換取最小的誤差上界,而最大化分類間:
2||w||就是最小化||w||.
就是最小化||w||,因此滿足約束條件下的目標函數為;
即該問題最終用二次規劃求得
其中,xi和xj為兩個類別中任意一對支持向量,決策函數為:
其中,x是待測試的樣本。
進一步,支持向量機利用一些具有特殊性質的核函數,將特征空間中的內積運算轉化為低維空間中的非線性運算,從而巧妙地避免了高維空間中的計算問題,引入核函數后,非線性判別函數對應的對偶問題變為:
最終的決策函數變為:
幾種常用的核函數如下:
(1)線性核函數
k(xi,x)=xi·x
(2)多項式核函數
k(xi,x)=[(xi·x)+1]d
(3)徑向基核函數(rbf)
(4)sigmoid核函數
k(xi,x)=tanh(v(xi·x)+c)
其中線性核函數k(薯,x)=薯·x是非線性的一種特殊情況,它最終實現的是線性支持向量分類器。
進一步,數據歸一化構建預測模型之前,需要先對數據進行預處理,一般情況下,因為數據類型的不同,其參數所使用的單位也不同,并且在數值上也不是在同樣的數量級上,在數值上會有較大的差距,盡管原始數據的范圍已經定在1~10之間,但是直接作為原始數據輸入,在數學建模的過程中所占據的相對比較大的權重,會影響到模型的性能,為了可以保證在度量空間這個范圍上數據點能夠分布的比較均勻,非常有必要首先對數據進行歸一化的處理,將訓練集中的數據與測試集中的數據運用歸一化方法處理,運用下面的歸一化方法;
式中,x,y∈r”,xmin=min(x),xmax=max(x),因此原始數據就規化到[0,1]區間內,即:y,∈[0,1],f=1,2,…,,2,該歸一化方法稱作[0,1]區間歸~化,除此之外,還有[一l,1]區間歸一化,其映射如下:
式中,
x,y∈r",xmin。=min(x),x...=max(x):。
本發明的優點在于:支持向量機己廣泛應用于機器學習各領域,它不僅可以解決分類、模式識別相關問題,還能有效地處理回歸、擬合、密度估計等問題。與其他現有的許多機器學習算法相比,svm不僅具有堅實的理論基礎,其研究與應用也更加廣泛,主要優勢表現在:(1)svm是在統計學習理論基礎上發展起來的小樣本學習算法,以結構風險最小化為目標提高其泛化能力,它在有限樣本信息下就可獲得問題的最優解。
附圖說明
下面結合附圖和具體實施方式來詳細說明本發明:
圖1是本發明基本框架圖;
圖2是本發明系統邏輯結構圖;
圖3是本發明svm最優超平面示意圖;
圖4是本發明最大間隔分類超平面圖;
圖5是本發明線性不可分情形的噪音數據圖;
圖6是本發明線性不可分的數據圖;
圖7是本發明svc參數選擇結果等高線圖;
圖8是本發明svc參數選擇結果圖;
圖9是本發明等高線圖;
圖10是本發明svc參數選擇結果圖;
具體實施方式
為了使本發明實現的技術手段、創作特征、達成目的與功效易于明白了解,下面結合圖示與具體實施例,進一步闡述本發明。
參見圖1、圖2,一種基于svm算法的干細胞活性檢測系統,該系統包括有子集生成單元、子集評價單元、停止條件單元、結果驗證單元;
子集生成單元實質上是一個搜索的過程,從搜索點出發,在一定的范圍內適當地添加或者移除不同特征以產生新的子集,提供給評價函數,不同的搜索方法意味著不一樣的搜索效率和不一樣的選擇結果;
子集評價單元根據特定的評估準則來判斷每個子集的優良程度,不同的評價標準可能導致不一樣的最優子集,在特征選擇過程中,每進行一次新的子集評價,都要將新的評價值和之前的最優評價值進行比較,再選出當前評價值最優的子集;
停止條件單元是指特征選擇算法滿足一定條件下停止搜索,否則子集搜索過程一直持續,常用的停止準則有三種:
d)達到了用戶事先設定的最大迭代次數或指定特征數;
e)特征子集數目的增加或減少都不能獲得更好的評價指標;
f)已經找到當前評價函數或用戶需求的最優子集;
結果驗證單元是驗證所選特征子集的有效性,最直接的驗證方法就是分別對原始數據集和經過特征選擇后得到的數據集進行訓練、預測,然后比較前后兩種訓練模型的復雜度和預測精度。
整個特征選擇的具體流程是先從原始特征空間中生成一個初始特征子集,并用特定的目標函數對其進行優劣評價,若滿足終止條件,則算法結束,并驗證所選子集的分類性能;否則繼續搜索,再產生新的候選子集并對其評價,直到滿足終止條件。因此一個完整的特征選擇過程主要包括:子集的產生一一子集評價一一停止條件一一結果驗證,現今機器學習領域普遍以這一流程來進行特征選擇。
顯然,子集生成即搜索策略和子集評價是特征選擇兩個最重要的步驟,直接影響著學習算法的分類性能和子集選擇結果,因為一個好的搜索方法可以提高算法選擇效率,快速找到最優子解,而好的評價標準能降低誤選擇,選出具有更豐富信息的子集。支持向量機由vapnik等人[52】于1995年提出的,它是一種有監督的機器學習算法,是統計學習理論中最年輕、最實用的內容,以結構風險最小化為目標,通過訓練樣本信息在分類模型復雜度和學習能力之間尋找最佳折中,以獲得更好的推廣能力。雖然svm最初是通過分類問題提出的,但它同樣能推廣到函數擬合等其它機器學習問題中。svm的基本思想是:將輸入空間經過非線性變化到高維空間中,并在新的高維空間中尋找最優分類超平面(optimalhyperplane),而這個非線性變化則是通過內積函數(核函數)來實現的,且核函數的引入使原輸入空間中線性不可分的問題映射到高維空間后變為線性可分,并保證兩類樣本正確分開的同時最大化不同類之間的分類間隔。最大化分類間隔就是置信范圍最小化的具體體現,不同樣本的正確分類就是保證經驗風險最小。
在模式識別領域,支持向量機最初是在研究線性可分問題中提出的,對于大小為z的數據集{(xi,yi),i=1,2,….,l},xi是d是d維輸入向量y的樣本標簽為{一1,1},如果存在最優分類面y=w.x+6能將樣本正確分成兩類,則定義d維特征空間中的線性判別函數為,(x)=w.x+b,
此時任意樣本x.到最優分類面的距離為
εi=yi(w·xi+b)=|w·xi+b|。
圖3是一個兩維的二分類問題,圓形和方形代表兩種不同的訓練樣本,在數據分類問題中,數據分為線性可分和線性不可分數據。對于線性可分的數據一般可通過一個超平面對其進行劃分,圖4a中表示的是一個二分類,問題。對于這樣~個線性可分的問題,可以有多個分類超平面對其進行劃分,如何找到一個如圖4b最有效的超平面來劃分數據,是首先需要考慮的一個問題。常用的方法是通過尋找極大間隔分類超平面來進行分類。
類間隔(margin)就是劇與加之間的距離,并使兩類樣本都滿足:
fxi≥1,,
再將歸一化后得到不同類之間的距離(幾何間隔)
因為樣本的誤分次數n與分類間隔萬存在著如下關系
n≤2rδ2
所以我們以最大化分類間隔為目標,換取最小的誤差上界,而最大化分類間:
就是最小化||w||,因此滿足約束條件下的目標函數為;
即該問題最終用二次規劃求得
其中,xi和xj為兩個類別中任意一對支持向量,決策函數為:
其中,x是待測試的樣本,上面拉格朗日乘子中只有少部分不為0的a才對礦起作用,而這些a值不為0的樣本就是圖3中落在腳和h2線上的點,這些點被稱為支持向量,由此可見svm只由少數的支持向量就可代替整個原始數據集,并求得最優決策面。
如果訓練數據集中有少數噪音或孤立點落在腳和h2之間而不能尋找到較好的最優分類面,針對此情況,可引入松弛變量將模型變為。
min12|w|2+cj=1lξis.t.yiw·xi+b≥1-ξiξi>0,i=1,2,...,l
其中,c為懲罰因子,該參數的調節能實現算法復雜度與錯分樣本比例之間的折中。此時求解過程與式中相同。
當輸入樣本空間無法用線性判別函數進行分類時,svm可通過非線性映射到高維空間,構造非線性向量機,即將映射成,使之成為高維空間的線性可分,可用于滿足mercer條件的核函數代替高維空間的點積運算,即
mercer條件是指對于任意的對稱函數k(薯,x,),使其成為某個特征空間中的內積函數的充分必要條件是,對于任意的
而超平面本身只由少數的幾個支持向量組成,這些數據點就會在svm模型中可以造成很大的影響,如圖5所示。
支持向量機利用一些具有特殊性質的核函數,將特征空間中的內積運算轉化為低維空間中的非線性運算,從而巧妙地避免了高維空間中的計算問題,引入核函數后,非線性判別函數對應的對偶問題變為:
最終的決策函數變為:
幾種常用的核函數如下:
(5)線性核函數
k(xi,x)=xi·x
(6)多項式核函數
k(xi,x)=[(xi·x)+1]d
(7)徑向基核函數(rbf)
(8)sigmoid核函數
k(xi,x)=tanh(v(xi·x)+c)
其中線性核函數k(薯,x)=薯·x是非線性的一種特殊情況,它最終實現的是線性支持向量分類器。
分類器的主要目標就是把線性不可分的數據,按照不同類型的數據區分開來。比如在如圖6的兩類分類問題中,圖6a中明顯是線性不可分的情況,在給定的這兩類訓練樣本中,需要找出一個決策函數把兩類訓練樣本能夠分開如圖6b中一樣也能夠根據這個決策函數決定此后的新輸入數據相對應的類別。
svm算法的求解過程可以轉化成一個凸二次規劃問題,理論上保證了算法的全局最優性,并在一定程度上避免了像神經網絡等其他學習算法的局部最優問題,svm識別模型簡單,與傳統神經網絡反復試湊的網絡結構相比,只需要訓練樣本中的少數支持向量構建,svm擅長處理非線性問題,主要是通過核函數和松弛變量來實現,svm算法的復雜度與樣本維數無關,非線性映射的模型主要由核函數來計算,在一定程度上避免了維數災難,所以該算法能有效地處理小樣本高維數據。
當今正處于大數據時代,醫學數據更是非常之龐大,而且醫學實驗數據與其他領域的數據有所不同,有其特殊之處。醫學實驗機構每天產生出大量的醫學信息數據,而且其中包含的數據形式種類也多種多樣,包括一些純數字的數據(例如一些病原體的檢測結果或特征參數)、波形信號(例如通過儀器測量產生的一些心電信號或腦電信號等等)、圖像(例設備中,其數據格式主要是面向實驗員或設備的。為了有效的利用和識別這些數據,需要將數據轉換成所建模型或智能程序所識別的有效格式,因此,在建立并利用模型對醫療數據進行處理前,首先需要對數據作一定的預處理。數據集介紹在進行基于svm的醫療數據分類模型建模的過程中,本文所用的數據來自公共數據集,該數據集是從世界各個實驗室對干細胞存活環境條件數據的收集的,共收集了195932個案例,也就是195932個樣本,出去幾個不完整的樣本外剩下的樣本中對干細胞存活環境提取了幾個特征值,每個屬性值都被固定在1-19的分為之間,如表1所示,其中,第一列為干細胞標號,2-10都是檢查時候的特征值。
表1
數據歸一化構建預測模型之前,需要先對數據進行預處理,一般情況下,因為數據類型的不同,其參數所使用的單位也不同,并且在數值上也不是在同樣的數量級上,在數值上會有較大的差距,盡管原始數據的范圍已經定在1~10之間,但是直接作為原始數據輸入,在數學建模的過程中所占據的相對比較大的權重,會影響到模型的性能,為了可以保證在度量空間這個范圍上數據點能夠分布的比較均勻,非常有必要首先對數據進行歸一化的處理,將訓練集中的數據與測試集中的數據運用歸一化方法處理,運用下面的歸一化方法;
式中,x,y∈r”,xmin=min(x),xmax=max(x),因此原始數據就規化到[0,1]區間內,即:y,∈[0,1],f=1,2,…,,2,該歸一化方法稱作[0,1]區間歸~化,除此之外,還有[一l,1]區間歸一化,其映射如下:
式中,
x,y∈r",xmin。=min(x),x...=max(x).。
為了解決非線性的數據在高維特征空間中線性可分的問題,svm中引入了核技術的方法。常用的核函數有四種:線性核函數(linearkernelfunction)、多項式核函數(polynomialkernelfunction)、徑向基核函數(radialbasiskernelfunction)、多層感知機核函數(sigmoidkernelfunction)。因此要想使svm達到想要的分類效果,首先要決定選用哪種類型的核函數。
對于選用哪一種核函數作為支持向量機的核函數,能獲得較好的分類結果,目前還沒有相關的理論支持,常用的是根據實際問題,通過多次實驗來挑選或根據經驗來指定,為了獲得更好的分類效果,本文采用的方法是針對待分類數據集逐一驗證各種核函數的分類結果,從中選取~個最佳的核函數。
實驗中所用breastcancerwisconsin(original)數據集的數據,共有696個樣本數據,其中分類號為2的數據,代表存活的干細胞,共457個,分類號為4的數據,代表惡性腫瘤,共239個。通常,訓練集的數目要不少于總樣本數的50%,因此,針對本實驗,訓練集的數據從分類號為2的數據(即存活的干細胞)中順序選取了250個樣本數據,從分類號為4的數據(即凋亡的干細胞)中順序選取100個樣本數據,余下的346個樣本數據作為測試集數據。訓練集和測試集都應該要采用一個比較統一的歸一化方法來進行了處理,這樣可以確保訓練模型的數據和測試結果的數據都能夠使用的是同樣的標準。對于上述的訓練集和測試集,分別進行[-1,1]和【0,1]的規范化,針對每種核函數,進行訓練,得出一個初始模型,并用測試集檢驗該模型分類準確率,如表2中所示。
通過表2的對比,可以看出對于本文所使用breastcancerwisconsin(original)的數據集來說,選徑向基核函數作為核函數,得出的準確率相比較是較高的,不管是在[一1,1]區間中的,還是在【0,1]區間中的。線性核函數在[-1,1]、[0,1】區間中的分類準確率都比較低,而多項式核函數在[-1,1】和[0,1】區間內分類準確率相差較大,在[0,1】區間內的分類準確率是在每種核函數和歸一化方法中最低的,而在[.1,1]區間內的分類準確率卻是在每種。
表2
核函數和歸~化方法中最高的,差別較大,說明它對于數據的分類準確率穩定性不高。多層感知機核函數與徑向基核函數在[-1,1]和[o,1]區間內分類準確率都比較高,而在[o,1]區間內多層感知機核函數得到的分類準確率要比徑向基核函數略微低一點。因此本文確定使用徑向基核函數作為支持向量機的核函數,并且選用[0,1]區間內的歸一化方法作為對所使用數據預處理方法。但是這并不能代表徑向基核函數就是最好的核函數,針對具體問題具體數據來定,甚至如果常用的四種核函數都不能滿足要求,還可以自己構建合理的核函數,使得實驗結果最優化。建立分類預測模型雖然支持向量機有著較完善的理論基礎,但是在實際操作中,仍然需要考慮很多因素,比如:核函數的選擇、參數的確定等問題。在確定使用徑向基核函數后,建立模型的下一步工作就是如何選擇或確定懲罰參數c和核函數參數g。
選擇預測模型的參數:
一般情況下,用svm來做分類都可以達到了比較令人滿意的結果,但是,需要設置一些相關的參數,也就是懲罰參數c和核函數參數g,這些參數該如何選取?有沒有最佳的參數呢?針對這樣的問題,利用交叉驗證(cv,crossvalidation)的思想可獲得最優參數。交叉驗證不僅能夠避免過學習和欠學習的現象,還可以使測試集合的預測準確率比較理想。
1.交叉驗證
交叉驗證是一種統計分析的方法,能用來驗證分類器的性能。該方法的基本思想是:將已知的原始數據劃分成兩個部分,其中的一部分數據作為訓練數據的集合(trainset),接下來剩下的一部分就可以作為測試數據的集合(validationset)。接下來,首先運用訓練數據集合訓練分類器,然后就利用驗證數據集合來測試訓練數據集合得到的分類器模型,用得到的分類準確率作為評價分類器的性能指標。常見的cv方法如下。
(1)hold一0utmethod
該方法是把已知的數據分成任意的兩個部分,一部分作為訓練數據集,剩下的一部分作為驗證數據集,訓練數據集訓練分類器,驗證數據集驗證訓練數據集形成的模型,記下最后得到的分類準確率,用它來評價hold—outmethod下分類器的性能指標。該方法的優點是過程相對較簡單,只要把原始數據任意地分成兩部分就可以,但是嚴格來講,hold.outmethod不能算是真正的cv,就是因為這種方法其實沒有實現交叉,因為它將原始數據隨機分組,導致最后得到的分類準確率與原始數據的分組有著密切的關系,這樣得出的結果不太具有說服力的。
(2)k.foldcrossvalidation(k.cv)
原始的數據可以被分成若干個k組(均分),這些數據中的每一個子集的數據都可以輪流當作一次測試數據的集合,這樣的話剩下的另外k.1組子集就可以當作訓練數據的集合,因此就產生了k個模型,由此就可以分別求出每一個也就是k個模型各自的分類準確率,然后求平均數,這個平均數就可以作為該k—cv分類器的性能標準。這個k值一般意義下要大于或者等于2,但是,從實際操作中看,一般情況下是從3開始取的,若原始數據集合數據量較小的時取2。k.cv能夠減少過學習以及欠學習現象的存在,因而得出的結論也有信服力。
(3)leave.one.0utcrossvalidation(l00.cv)
l00一cv就相當于n.cv,其中有n個樣本,而且將每個獨立的樣本單獨作一次驗證數據集,剩余的n.1個樣本作為訓練數據集,這樣依次下去,l00.cv就能得到n個不同的模型,像k.cv方法一樣,將得到的這n個模型中每一個模型的分類準確率,然后求得它們的平均數,用這個平均數來作為在l00.cv下判斷分類器的性能標準。跟上面的k.cv相比,loo.cv有兩個突出的特點。
a)由于集合中的每個樣本都被當作一次驗證數據集,因此這種方法與最初的原始樣本最接近,而且得到的評估結果相對可靠。
b)在實驗的過程中,不存在隨機的因素影響實驗,這樣就保證實驗過程可以被復制。
雖然loo.cv優點不少,但是也有一些缺點,例如計算成本相比較高,這是因為它所要建立的模型數量與原始數據樣本數量是一樣的,當原始數據的樣本量較多時,在實際操作中,loo.cv會產生一些困難,也許并不可能實現。若每次訓練分類器時,模型的訓練速度都比較快,或者能用并行化計算來減少所需要的時間。
在交叉驗證的三種方法中,k—fold交叉驗證是較為常用的方法。使用該方法時,k的取值也會影響到參數(c,g)的取值。本文通過不同的k值進行交叉驗證,分別獲取其對應的c和g,最后選定適合本文實驗的k值。
2.網格法尋優
在尋找參數(c,g)時,通常用的一種方法是網格法尋優,即將(c,g)在一定的范圍內進行組合,形成一個參數值的網格,在每一個網格點進行交叉驗證,從中選取最高分類準確率的c和g。本文采用的方法是,先在這樣大的取值范圍內粗略尋找初始優化參數c和g,之后再根據分類的準確率,縮小c和g的取值范圍,進一步尋找最終優化參數。
利用網格法來優化支持向量機參數c和g的步驟如下:
1、需要設置一個搜索的網絡空間。首先,來給網格搜索空間取值,規定c值和g
值它們的取值范圍分別為:c∈[2-10,210],g∈[2-10,210],然后來根據實際情況,
設定搜索這個網絡的步長是1,這樣就可以構造成以c值和g值分別為橫縱坐標的二維網格的一個搜索空間。
2、遍歷每個網格搜索空間。在由c值和g值所構成的二維坐標系中,把每一個網格中的所有可能要取到的坐標點都進行一次遍歷,這些坐標點就相當于是每一個參數對(c,g)的取值組合,然后就可以用k.fold方法來進行交叉驗證訓練數據集,將分類準確率的值進行計算并且對其值進行記錄。
3、一直不斷重復上面的步驟(2),一直到所設定的這個二維網格搜索完畢為止。
4、將每次遍歷之后所記錄的分類準確率作為依據來選取其中最優的參數,然后來把c和g的取值進行確定。
5、根據實驗結果分析,并一步縮小參數對(c,g)的取值范圍,然后重復上面的步驟,從第2步開始,直到得到較優的分類準確率,這時候就可以最終確定c和g的取值。
3.確定模型參數首先在c和g的取值范圍分別為內,使用8折k.fold方法進行交叉驗證,即k的值取8。先在這樣大的范圍內粗略找出參數,然后設置網格的搜索步長為1,圖7就是在粗略范圍內得到的結果,其中的圖6是交叉驗證準確率的等高線圖,橫軸是懲罰參數c的取值范圍,即,縱軸是核參數g的取值范圍,即,圖8是交叉驗證準確率的3d視圖,三個軸分別是:懲罰參數c的取值范圍、核參數g的取值范圍和交叉驗證的準確率值。
由圖8可以看出,經過9折交叉驗證之后,得到測試集交叉驗證準確率為96.2693%,而支持向量機的懲罰參數c和核參數g的取值為c=0.43528,g=0.43528。此次c和g的取值范圍太大,為了尋得最優參數,從圖中找出參數分布比較密集的區域,作為下一次在較精細范圍內尋找參數的取值范圍,即c∈[2-6,22],g∈[2-4,24]此時設置網。
參數c和g的尋優(c∈[2-10,210],g∈[2-10,210])
格的搜索步長為o.5,圖9給出了在支持向量機的懲罰參數c和核參數g在較精細的范圍內找出的參數值。
圖10中得到的參數值即是懲罰參數c和核參數g在較精細的范圍內得到的取值,即c=0.35355,g=0.5。此時得到的交叉驗證的準確率與粗略范圍的變化不大,仍然是96.2963%。為了了解k—fold方法中分組對c和g的影響,我們分別選取k=5,8,10進行c和g的尋優。表3給出了交叉驗iie不n的取值和網格法驗證參數(c,g)的尋優結果。
從表3可以看出,對于交叉驗證中k的取值,造成的測試數據分類準確率影響不是很大,都已經達到96%以上,但是就總體來說當k=8時,測試集的分類準確率是相對較平穩的,都已經達到了96.2963%。并且支持向量機的懲罰參數c和核參數g也都得到了相對較好的值。
2訓練模型
通過上面的步驟,我們已經得到建立svm模型所需的訓練數據和各種參數,訓練數據是在初始化階段從breastcancerwisconsin(original)數據集中提取的部分數據,并進行[o,1]區間內的歸一化處理,核函數使用徑向基核函數,最后,通過交叉驗證和網格法尋優得到c-0.35355,g=0.5。此時,即可建立svm模型。
表3
以上顯示和描述了本發明的基本原理、主要特征和本發明的優點。本行業的技術人員應該了解,本發明不受上述實施例的限制,上述實施例和說明書中描述的只是說明本發明的原理,在不脫離本發明精神和范圍的前提下本發明還會有各種變化和改進,這些變化和改進都落入要求保護的本發明范圍內。本發明要求保護范圍由所附的權利要求書及其等同物界定。
- 還沒有人留言評論。精彩留言會獲得點贊!