目標知識點的獲取方法及裝置與流程
本申請涉及計算機技術領域,尤其涉及一種目標知識點的獲取方法及裝置。
背景技術:
知識點可以是指互聯網中的一些熱門話題,通常在未接收到用戶輸入的任何信息的情況下,就可以將這些知識點推送給用戶,如,在自動問答平臺中,在開啟自動問答平臺的聊天窗口后,就可以將這些知識點的標題顯示到聊天窗口中,若這些知識點中包含了用戶想了解的內容,則用戶只需要點擊相應知識點的標題從而鏈接到該知識點的相關內容,即可對這些知識點進行了解,由此方便了用戶對互聯網中熱門話題的了解,進而提升了用戶的體驗。
現有技術中,獲取目標知識點(如,熱門話題)的過程為:在預設時間段內統計多個知識點的點擊數;之后根據點擊數,從多個知識點中獲取目標知識點。然而該方法并未考慮知識點對用戶問題的解答效果,有可能用戶只是誤點擊或者出于好奇點擊了某些知識點,用戶誤點擊或者出于好奇點擊知識點的情況,會影響知識點的點擊數統計的準確性,進而會影響目標知識點獲取的準確性,由此會造成所推薦的目標知識點與用戶的實際訴求存在偏差,從而用戶需要手動輸入問題來尋求解答,這使得用戶了解熱門知識點的過程比較繁瑣,不能滿足用戶想要快速了解熱門知識點的需求。
技術實現要素:
本申請實施例提供了一種目標知識點的獲取方法及裝置,可以提高目標 知識點獲取的準確性,從而可以滿足用戶想要快速了解熱門知識點的需求。
第一方面,提供了一種目標知識點的獲取方法,該方法包括:
收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案,每個知識點歸屬于一個預設類目;
根據預設的算法,確定所述多次會話內容中各個知識點與對應的問題的匹配度值,并將所述匹配度值作為所述各個知識點的第一分數值;
根據所述各個知識點的第一分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
第二方面,提供了一種目標知識點的獲取方法,該方法包括:
收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值;
對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定所述每個知識點的類目衰減因子;
根據該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對所述每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第二分數值;
根據所述各個知識點的第二分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
第三方面,提供了一種目標知識點的獲取方法,該方法包括:
收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值;
對每次會話內容中的每個知識點,根據當前時間、該知識點所屬問答對的創建時間以及預設閾值,確定所述每個知識點的時間衰減因子;
根據所述每個知識點的時間衰減因子,對所述每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第三分數值;
根據所述各個知識點的第三分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
第四方面,提供了一種目標知識點的獲取裝置,該裝置包括:
收集單元,用于收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案,每個知識點歸屬于一個預設類目;
確定單元,用于根據預設的算法,確定所述收集單元收集的所述多次會話內容中各個知識點與對應的問題的匹配度值,并將所述匹配度值作為所述各個知識點的第一分數值;
獲取單元,用于根據所述確定單元確定的所述各個知識點的第一分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
第五方面,提供了一種目標知識點的獲取裝置,該裝置包括:
收集單元,用于收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值;
確定單元,用于對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定所述每個知識點的類目衰減因子;
更新單元,用于根據所述確定單元確定的該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對所述每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第二分數值;
獲取單元,用于根據所述更新單元更新得到的所述各個知識點的第二分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
第六方面,提供了一種目標知識點的獲取裝置,該裝置包括:
收集單元,用于收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值;
確定單元,用于對每次會話內容中的每個知識點,根據當前時間、該知識點所屬問答對的創建時間以及預設閾值,確定所述每個知識點的時間衰減因子;
更新單元,用于根據所述確定單元確定的所述每個知識點的時間衰減因子,對所述每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第三分數值;
獲取單元,用于根據所述更新單元更新得到的所述各個知識點的第三分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
本申請提供的目標知識點的獲取方法及裝置,收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,該知識點是指對應于所述問題的答案,每個知識點歸屬于一個預設類目;根據預設的算法,獲得多次會話內容中各個知識點與對應的問題的匹配度值,并將該匹配度值作為各個知識點的第一分數值;根據各個知識點的第一分數值,從多次會話內容中的多個知識點中獲取目標知識點。也即本申請中,考慮了知識點對用戶問題的實際解答效果,由此可以提高目標知識點獲取的準確性,進而可以滿足用戶想要快速了解熱門知識點的需求。
附圖說明
圖1為本申請一種實施例提供的目標知識點的獲取方法流程圖;
圖2為本申請另一種實施例提供的目標知識點的獲取方法流程圖;
圖3為本申請再一種實施例提供的目標知識點的獲取方法流程圖;
圖4為本申請又一種實施例提供的目標知識點的獲取方法流程圖;
圖5為本申請一種實施例提供的目標知識點的獲取裝置示意圖;
圖6為本申請另一種實施例提供的目標知識點的獲取裝置示意圖;
圖7為本申請再一種實施例提供的目標知識點的獲取裝置示意圖。
具體實施方式
下面結合附圖,對本發明的實施例進行描述。
本申請實施例提供的目標知識點的獲取方法及裝置,適用于對互聯網中的熱門知識點進行獲取的場景,尤其適用于對自動問答平臺中的熱門知識點進行獲取的場景。其中,自動問答平臺主要是通過具有即時通訊功能的問答機器人來對用戶問題進行解答,問答機器人是在對大量預先收集的問答語料學習的基礎上來對實時接收的用戶問題進行解答的;其可以具有一定的業務背景。如,其可以為支付寶系統中的自動問答平臺,也可以為淘寶網中的自動問答平臺等。
本申請的知識點可以理解為自動問答平臺根據用戶問題推送的答案。在具有業務背景的自動問答平臺中,知識點通常具有以下三個特點:
1)長尾效應:不同知識點的點擊數服從長尾分布,熱門知識點集中了較高點擊數,而冷門知識點依然存在少量點擊;
2)時效性:部分知識點具有時效性,在特定的時間段內會被大量點擊,而其余時間段內的點擊數明顯降低;
3)關聯性:不同知識點間存在關聯性,當某些知識點被大量點擊時,與其具有相似主題或業務背景的知識點也將會有較大的點擊數。
如果依賴人工進行熱門知識點的統計,會存在如下問題:
1)人力消耗:用戶會話涉及大量的數據,依賴人工會帶來較大的工作量;
2)主觀性:人工會不可避免地帶有主觀感情色彩,導致統計出的熱門知識點不一定能真實反映出用戶的訴求;
3)滯后性:人工統計的時間周期較長,統計出的知識點往往滯后于當下的熱點話題,無法反映出知識點的時效性;
4)趨同性:人工統計較難避免知識點間的關聯性,因此統計出的知識點具有相同或相似的主題背景,導致不同業務的覆蓋率差異較大。
針對上述的知識點的特點以及人工統計存在的問題,通過技術手段對熱門知識點的獲取方法進行研究存在一定的實際價值。
圖1為本申請一種實施例提供的目標知識點的獲取方法流程圖。所述方法的執行主體可以為具有處理能力的設備:服務器或者系統或者裝置,如圖1所示,所述方法具體可以包括:
步驟110,收集用戶與問答機器人的多次會話內容。
其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,該知識點是指對應于問題的答案,每個知識點歸屬于一個預設類目。
此處,問答機器人是指自動問答平臺中能實時對接收的用戶問題進行解答的機器模型,其可以是在對大量預先收集的問答對(包括問題和答案)學習的基礎上得到的,如,阿里巴巴集團的小蜜以及百度的度秘等。具體地,可以由服務器預先從自動問答平臺的后臺數據庫中收集在預設時間段內(如,01:00-24:00)的用戶與問答機器人的多次會話內容。
本申請的一次會話可以以用戶在自動問答平臺中開啟一個聊天窗口開始,至用戶關閉該聊天窗口結束。在一個聊天窗口開啟至結束的過程中,用戶可以與問答機器人進行至少一次聊天,其中,每次聊天會形成一條聊天記錄,該聊天記錄也可以稱為一個問答對,該問答對可以包括用戶提問的一個問題以及問答機器人推送的一個知識點,或者也可以包括用戶提問的一個問 題以及問答機器人推送的多個知識點。具體地,如果問答機器人能對用戶問題進行準確定位,也即問答機器人預先學習了與用戶問題相關的問答語料,則可以向用戶推送與該用戶問題對應的一個知識點,否則可以向用戶推送多個知識點。
需要說明的是,本申請中可以預先為收集的多個知識點中每個知識點設置其所屬的類目。此處,預設的類目的個數可以為一個或多個,以預設的類目的個數為兩個為例來說,該兩個類目可以包括一級子類目和二級子類目。以支付寶系統中的知識點為例來說,假設某個知識點為“余額寶收益計算”,那么其歸屬的一級子類目可以為“余額寶”,而其歸屬的二級子類目則可以為“余額寶收益”。
可選地,在收集到多次會話內容中的多個知識點之后,可以將每個知識點的初始分數值設置為1。
在一個例子中,收集的多次會話內容可以如表1所示。
表1
在此說明,受限于篇幅,表1只列出了較少的例子,實際上收集的會話內容可能包含上萬個知識點。
步驟120,根據預設的算法,確定多次會話內容中各個知識點與對應的問題的匹配度值,并將匹配度值作為各個知識點的第一分數值。
此處,預設的算法可以為詞頻位置加權排序算法等,通過該預設的算法確定的知識點與對應的問題的匹配度值,可以用于衡量知識點與對應的問題的相關性。具體地,當匹配度值較大時,則知識點與對應的問題的相關性較高;而當匹配度值較小時,則知識點與對應的問題的相關性較弱。此處,知識點與對應的問題的匹配度值的獲取過程屬于預設的算法的一個簡單應用,本申請在此不復贅述。
在確定各個知識點與對應的問題的匹配度值之后,可以直接將該匹配度值作為各個知識點的第一分數值;或者,在已經為各個知識點設置初始分數值時,直接將其初始分數值更新為上述匹配度值。
需要說明的是,上述步驟120主要是為了解決現有技術在對知識點進行打分時,不考慮問題與知識點的相關性,從而影響目標知識點獲取的準確性的問題。
步驟130,根據各個知識點的第一分數值,從多次會話內容中的多個知識點中獲取目標知識點。
具體地,在確定各個知識點的第一分數值之后,可以按照第一分數值從大到小的順序對各個知識點進行排序,將排序靠前的前k個知識點作為目標知識點。需要說明的是,對不同會話內容中的相同知識點,可以直接將該知識點的多個第一分數值進行求和、求平均值求、加權平均值或者貝葉斯評分等方式,來獲得該知識點的最終分數值。
需要說明的是,本申請中收集的知識點具有類目屬性,這些類目可被看作是知識點的主題,同時,用戶一次會話內容中的聊天記錄存在一定的依賴關系且主題相近。一次會話內容中的知識點所屬的類目跳轉時表明:1)前文 答復的知識點與用戶原意不符;2)用戶隨手點擊了推薦知識點。因此可將會話內容中后續知識點的類目跳轉作為度量前文知識點分數值的因素之一,即隨著知識點的類目跳轉對前續知識點的分數值進行衰減,可以提高目標知識點獲取的準確性。因此,在執行本申請實施例中的步驟130之前,還可以執行如下步驟:
步驟a:對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定每個知識點的類目衰減因子。
以下將對確定一次會話內容中的一個知識點的類目衰減因子的過程進行說明:
以支付寶系統中的自動問答平臺為例來說,預先收集的一次會話內容可以如下所示:
問題1:紅包的規則是什么?
知識點1:支付寶春晚紅包活動一共送出8億現金紅包,其中,前四輪咻一咻拼手氣紅包,每一輪紅包都超過1億現金。
問題2:怎么沒有敬業福?
知識點2:集五福活動結束后,到目前為止已經有超過78萬人集齊五福,…,游戲強較強。非常感謝您參與支付寶搶紅包活動。
問題3:我集齊五福了,但是沒有分到現金?
知識點3:活動結束后,78萬人統計準確,目前2.15億現金已全部送出,由于目前是現金周轉的高峰期,所以可能會延遲到賬,請您耐心等候。
…
在上述例子中,“知識點1”即為“知識點2“的前一知識點。可以理解的是,“知識點1”沒有前一知識點。
在一個例子中,可以根據公式1確定一次會話內容中一個知識點的類目衰減因子:
其中,jumpj為一次會話內容中某個知識點的類目衰減因子,以該知識點為第i個知識點為例來說,j表示第i個知識點在一次會話內容中出現的順序,如前述例子,“知識點3”在一次會話內容中的排序為第三位,因此,j的值就為3;catj為一次會話內容中排在第j位的知識點所屬的類目,也即第i個知識點所述的類目,catj-1為一次會話內容中排在第j-1位的知識點所屬的類目,也即一次會話內容中位于第i個知識點之前的前一知識點所屬的類目,lcp(catj-1,catj)為一次會話內容中排在第j位的知識點所屬的類目與排在第j-1位的知識點所屬的類目的最長公共前綴,minlen(catj-1,catj)為一次會話內容中排在第j位的知識點所屬的類目與排在第j-1位的知識點所屬的類目的最小字符串長度。
關于前述最長公共前綴以及最小字符串長度將通過以下例子進行說明。以表1中會話內容1中的知識點1和知識點2為例來說,該兩個知識點均具有三級子類目,且其一級子類目和二級子類目相同,三級子類目不相同,所以該兩個知識點的最長公共前綴為“余額寶+余額寶收益”,也即lcp(知識點1,知識點2)=8。再以表1中會話內容1中的知識點2和知識點3為例來說,知識點2具有三級子類目,而知識點3只有兩級子類目,且前兩級子類目均相同,因此該兩個知識點的最小字符串為“余額寶+余額寶收益”,也即minlen(知識點2,知識點3)=8。
需要說明的是,當某個知識點排在一次會話內容的首位時,也即當j=0時,因為該知識點在該次會話內容中不存在前一知識點,因此,可以將該次會話內容中該知識點的類目衰減因子設置為一個閾值,該閾值的取值范圍可以為[0,1]。
根據上述一次會話內容中一個知識點的類目衰減因子的確定方法,就可以確定多次會話內容中各個知識點的類目衰減因子。如根據公式1,可以獲得表1中會話內容1中知識點1、知識點2和知識點3的類目衰減因子;并且可以獲得會話內容2中知識點4的類目衰減因子等。當然,在實際應用中,因 為知識點1和知識點4不存在前一知識點,無法應用公式1,因此可以將其類目衰減因子設定為一個閾值,也即當某個知識點排在一次會話內容的首位時,則將該次會話內容中該知識點的類目衰減因子設置為一個閾值。
步驟b:根據該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對每個知識點的第一分數值進行更新,得到多次會話內容中的各個知識點的第二分數值。
在一個例子中,可以根據公式2獲得一次會話內容中某個知識點的第二分數值。
其中,score2(i)為第i個知識點的第二分數值,score1(i)為第i個知識點的第一分數值,m為一次會話內容中知識點的個數,jumpn為一次會話內容中排在第n位的知識點的類目衰減因子。可以理解的是,上述公式即為:score2(i)=score1(i)*jumpj*jumpj+1*...*jumpm,也即在計算一次會話內容中第i個知識點的第二分數值時,綜合考慮了同一會話內容中后續知識點的類目跳轉情況,如,考慮了一次會話內容中排在第j+1、j+2、…、m位的知識點的類目跳轉情況,其中,j為第i個知識點在該會話內容中的排序位置,也即增加了目標知識點的衡量因素。
根據上述一次會話內容中一個知識點的第二分數值的確定方法,就可以確定多次會話內容中各個知識點的第二分數值。如根據公式2,可以獲得表1中會話內容1中知識點1、知識點2和知識點3的第二分數值;并且可以獲得會話內容2中知識點4的第二分數值等。
在獲得各個知識點的第二分數值之后,則可以將步驟130替換為步驟c:根據各個知識點的第二分數值,從多次會話內容中的多個知識點中獲取目標知識點。
此處,根據各個知識點的第二分數值,獲取目標知識點的過程與步驟130中根據各個知識點的第一分數值,獲取目標知識點的過程類似,本申請在此 不復贅述。
由于熱門知識點具有時效性,若單純計數則統計粒度過大,導致知識點的時效屬性被湮沒,因此本申請的實施例中在確定各知識點的最終分數值時,還可以考慮時間衰減因子,以保證最近被點擊的知識點具有較高的權重。因此,在執行本實施例中的步驟c之前,還可以執行如下步驟:
步驟x:對每次會話內容中的每個知識點,根據當前時間、該知識點所屬問答對的創建時間以及預設閾值,確定每個知識點的時間衰減因子。
在一個例子中,可以根據公式3獲得一次會話內容中每個知識點的時間衰減因子。
timefactori=(currtime-chattimei+2)g(公式3)
其中,timefactori為一次會話內容中第i個知識點的時間衰減因子,currtime為當前時間,chattimei為一次會話內容中第i個知識點所屬問答對的創建時間,g為預設閾值,也可以稱為重力因子。
如根據公式3,可以獲得表1中會話內容1中知識點1、知識點2和知識點3的時間衰減因子;并且可以獲得會話內容2中知識點4的時間衰減因子等。
步驟y:根據每個知識點的時間衰減因子,對每個知識點的第二分數值進行更新,得到多次會話內容中的各個知識點的第三分數值。
在一個例子中,可以根據公式4獲得一次會話內容中某個知識點的第三分數值。
score3(i)=score2(i)*timefacteri(公式4)
其中,score3(i)為第i個知識點的第三分數值,score2(i)為第i個知識點的第二分數值,timefactori為一次會話內容中第i個知識點的時間衰減因子。
根據上述一次會話內容中一個知識點的第三分數值的獲得方法,就可以獲得多次會話內容中各個知識點的第三分數值。如根據公式4,可以獲得表1中會話內容1中知識點1、知識點2和知識點3的第三分數值;并且可以獲得 會話內容2中知識點4的第三分數值等。
在獲得各個知識點的第三分數值之后,則可以將步驟c替換為z:根據各個知識點的第三分數值,從多次會話內容中的多個知識點中獲取目標知識點。
此處,根據各個知識點的第三分數值,獲取目標知識點的過程與步驟130中根據各個知識點的第一分數值,獲取目標知識點的過程類似,本申請在此不復贅述。
考慮到不同類目的知識點均分及點擊次數不同,如果依據均分或總分對熱門知識點進行排序,會導致獲取的熱門知識點覆蓋面小且集中于少量的類目,因此本申請還可以采用貝葉斯評分對知識點進行加權評分。因此,在執行本申請實施例中的步驟z之前,還可以執行如下步驟:
步驟a:對多次會話內容中的每個知識點,根據多次會話內容中的該知識點的第三分數值以及點擊次數,確定每個知識點的第一平均分數值。
在一個例子中,可以根據公式5確定每個知識點的第一平均分數值:
其中,
步驟b:根據每個知識點的第一平均分數值以及多次會話內容中的知識 點的總個數,確定每個知識點的第二平均分數值。
在一個例子中,可以根據公式6確定每個知識點的第二平均分數值:
其中,
步驟c:根據每個知識點的點擊次數、第一平均分數值、第二平均分數值以及預設點擊次數,確定多次會話內容中的各個知識點的最終分數值。
在一個例子中,可以根據公式7確定多次會話內容中的各個知識點的最終分數值:
其中,finalscorei為第i個知識點的最終分數值,hiti為第i個知識點的點擊次數,
在表1中各知識點均不相同的情況下,根據上述公式5-公式7,就可以獲得表1中會話內容1中知識點1、知識點2和知識點3的最終分數值;并且可以獲得會話內容2中知識點4的最終分數值等。
在獲得各個知識點的最終分數值之后,則可以將步驟z替換為步驟d:根據各個知識點的最終分數值,從多次會話內容中的多個知識點中獲取目標知識點。
此處,根據各個知識點的最終分數值,獲取目標知識點的過程與步驟130 中根據各個知識點的第一分數值,獲取目標知識點的過程類似,本申請在此不復贅述。
在獲取目標知識點之后,就可以將該目標知識點推送給用戶。如,在自動問答平臺中,在開啟自動問答平臺的聊天窗口后,就可以將目標知識點的標題顯示到聊天窗口中,若目標知識點中包含了用戶想了解的內容,則用戶只需要點擊相應知識點的標題從而鏈接到該知識點的相關內容,即可對這些知識點進行了解,由此方便了用戶對互聯網中熱門話題的了解,進而提升了用戶的體驗。
需要說明的是,本申請還提供了如下幾種獲取目標知識點的方式:
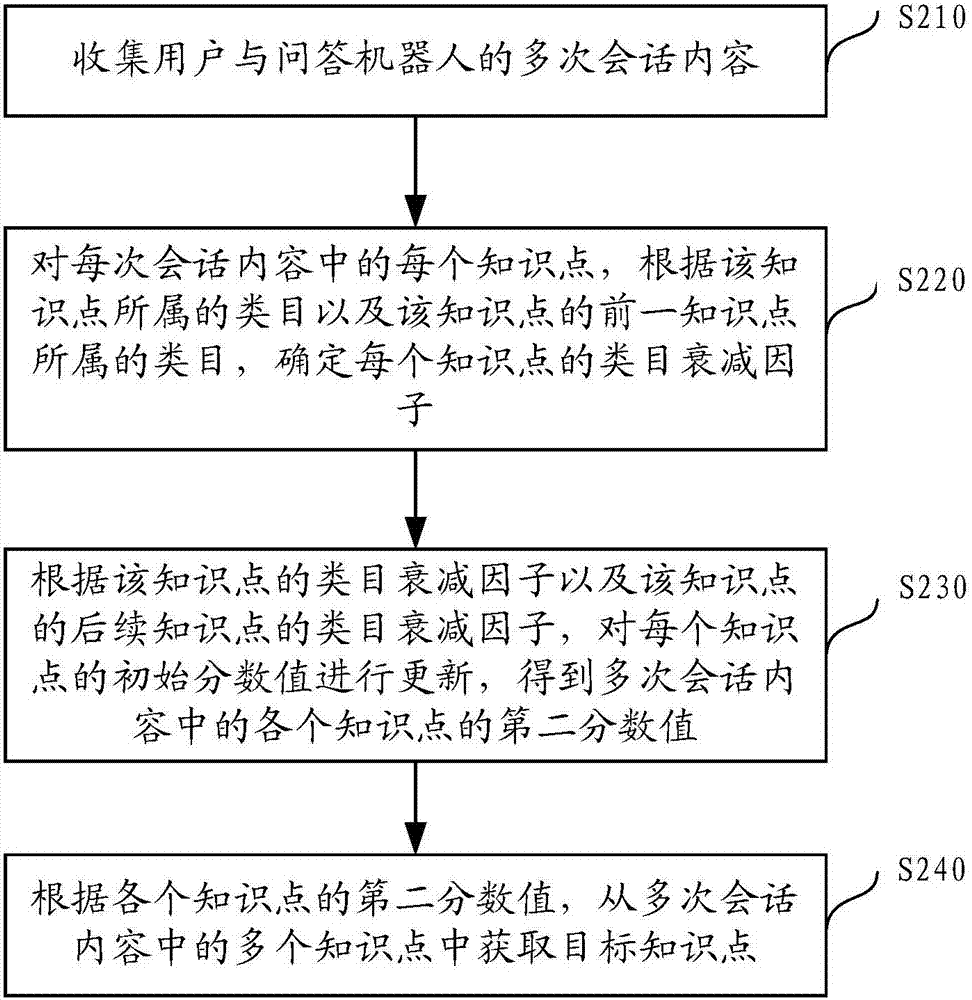
圖2為本申請另一種實施例提供的目標知識點的獲取方法流程圖,如圖2所示,所述方法可以包括如下步驟:
步驟210,收集用戶與問答機器人的多次會話內容。
其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,知識點是指對應于問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值。
步驟220,對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定每個知識點的類目衰減因子。
步驟230,根據該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第二分數值。
步驟240,根據各個知識點的第二分數值,從多次會話內容中的多個知識點中獲取目標知識點。
由于步驟210與前述實施例中的步驟110相同,步驟220和步驟240與前述實施例中的步驟a和步驟c相同,在此不復贅述;步驟230與步驟b相似,其中,相同部分在此不復贅述,不同的是,步驟230中可以根據公式2的變形公式8來得到多次會話內容中的各個知識點的第二分數值。
公式8可以為:
其中,score(i)為第i個知識點的初始分數值,公式8中其它參數與公式2相同,其相應的說明可參見公式2中各參數的說明,在此不復贅述。
可以理解的是,在執行本實施例的步驟240之前,還可以執行前述實施例中的步驟x-步驟y,在執行步驟y-步驟y之后,則可以將步驟240替換為步驟z;此外,在執行步驟y-步驟y之后,在替換步驟240之前,還可以執行步驟a-步驟c,在執行步驟a-步驟c之后,則可以直接將步驟240替換為步驟d。上述兩個方案的執行可以參見前文所述,在此不復贅述。
本實施中將會話內容中后續知識點的類目跳轉作為度量前文知識點分數值的因素之一,即隨著知識點的類目跳轉對前續知識點的分數值進行衰減,由此,可以提高目標知識點獲取的準確性。
圖3為本申請再一種實施例提供的目標知識點的獲取方法流程圖,如圖3所示,所述方法可以包括如下步驟:
步驟310,收集用戶與問答機器人的多次會話內容。
其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,該知識點是指對應于問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值。
步驟320,對每次會話內容中的每個知識點,根據當前時間、該知識點所屬問答對的創建時間以及預設閾值,確定每個知識點的時間衰減因子。
步驟330,根據每個知識點的時間衰減因子,對每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第三分數值。
步驟340,根據各個知識點的第三分數值,從多次會話內容中的多個知識點中獲取目標知識點。
由于步驟310與前述實施例中的步驟110相同,步驟320和步驟340與前述實施例中的步驟x和步驟z相同,在此不復贅述;步驟330與步驟y相 似,其中,相同部分在此不復贅述,不同的是,步驟330中可以根據公式4的變形公式9來得到多次會話內容中的各個知識點的第三分數值。
公式9可以為:
score3(i)=score(i)*timefacteri(公式9)
其中,score(i)為第i個知識點的初始分數值,公式9中其它參數與公式4相同,其相應的說明可參見公式4中各參數的說明,在此不復贅述。
可以理解的是,在執行本實施例的步驟340之前,還可以執行前述實施例中的步驟a-步驟c,在執行步驟a-步驟c之后,可以將步驟340替換為步驟d。該方案的執行可以參見前文所述,在此不復贅述。
本實施中在確定各個知識點的最終分數值時,考慮了知識點的時間衰減因子,以保證最近被點擊的知識點具有較高的權重,從而提高了目標知識點選取的準確性。
圖4為本申請又一種實施例提供的目標知識點的獲取方法流程圖,如圖4所示,該方法可以包括:
步驟410,收集用戶與問答機器人的多次會話內容。
其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案,每個知識點歸屬于一個預設類目
步驟420,根據預設的算法,確定多次會話內容中各個知識點與對應的問題的匹配度值,并將匹配度值作為各個知識點的第一分數值。
步驟430,對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定每個知識點的類目衰減因子。
步驟440,根據該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對每個知識點的第一分數值進行更新,得到多次會話內容中的各個知識點的第二分數值。
步驟450,對每次會話內容中的每個知識點,根據當前時間、該知識點所 屬問答對的創建時間以及預設閾值,確定每個知識點的時間衰減因子。
步驟460,根據每個知識點的時間衰減因子,對每個知識點的第二分數值進行更新,得到多次會話內容中的各個知識點的第三分數值。
步驟470,對多次會話內容中的每個知識點,根據多次會話內容中的該知識點的第三分數值以及點擊次數,確定每個知識點的第一平均分數值。
步驟480,根據每個知識點的第一平均分數值以及多次會話內容中的知識點的總個數,確定每個知識點的第二平均分數值。
步驟490,根據每個知識點的點擊次數、第一平均分數值、第二平均分數值以及預設點擊次數,確定多次會話內容中的各個知識點的最終分數值。
步驟4100,根據各個知識點的最終分數值,從多次會話內容中的多個知識點中獲取目標知識點。
由此,可以提高目標知識點獲取的準確性,進而可以滿足用戶想要快速了解熱門知識點的需求。
與上述一種實施例提供的目標知識點的獲取方法對應地,本申請實施例還提供的一種目標知識點的獲取裝置,如圖5所示,該裝置包括:
收集單元501,用于收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案,每個知識點歸屬于一個預設類目。
確定單元502,用于根據預設的算法,確定收集單元501收集的所述多次會話內容中各個知識點與對應的問題的匹配度值,并將所述匹配度值作為所述各個知識點的第一分數值。
獲取單元503,用于根據確定單元502確定的所述各個知識點的第一分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
可選地,獲取單元503具體可以用于:
對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定所述每個知識點的類目衰減因子;
根據該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對所述每個知識點的第一分數值進行更新,得到多次會話內容中的各個知識點的第二分數值;
根據所述各個知識點的第二分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
可選地,獲取單元503還可以具體用于:
對每次會話內容中的每個知識點,根據當前時間、該知識點所屬問答對的創建時間以及預設閾值,確定所述每個知識點的時間衰減因子;
根據所述每個知識點的時間衰減因子,對所述每個知識點的第二分數值進行更新,得到多次會話內容中的各個知識點的第三分數值;
根據所述各個知識點的第三分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
可選地,獲取單元還可以具體用于:
對每次會話內容中的每個知識點,根據所述多次會話內容中的該知識點的第三分數值以及點擊次數,確定所述每個知識點的第一平均分數值;
根據所述每個知識點的第一平均分數值以及所述多次會話內容中的知識點的總個數,確定所述每個知識點的第二平均分數值;
根據所述每個知識點的點擊次數、所述第一平均分數值、所述第二平均分數值以及預設點擊次數,確定所述多次會話內容中的各個知識點的最終分數值;
根據所述各個知識點的最終分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
本申請實施例裝置的各功能模塊的功能,可以通過上述方法實施例的各步驟來實現,因此,本申請提供的裝置的具體工作過程,在此不復贅述。
本申請實施例提供的目標知識點的獲取裝置,收集單元501收集用戶與問答機器人的多次會話內容;確定單元502根據預設的算法,確定所述多次 會話內容中各個知識點與對應的問題的匹配度值,并將所述匹配度值作為所述各個知識點的第一分數值;獲取單元503根據所述各個知識點的第一分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。由此可以提高目標知識點獲取的準確性,進而可以滿足用戶想要快速了解熱門知識點的需求。
與上述另一種實施例提供的目標知識點的獲取方法對應地,本申請實施例還提供的一種目標知識點的獲取裝置,如圖6所示,該裝置包括:
收集單元601,用于收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值。
確定單元602,用于對每次會話內容中的每個知識點,根據該知識點所屬的類目以及該知識點的前一知識點所屬的類目,確定所述每個知識點的類目衰減因子。
更新單元603,用于根據確定單元602確定的該知識點的類目衰減因子以及該知識點的后續知識點的類目衰減因子,對所述每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第二分數值。
獲取單元604,用于根據更新單元603更新得到的所述各個知識點的第二分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
本申請實施例裝置的各功能模塊的功能,可以通過上述方法實施例的各步驟來實現,因此,本申請提供的裝置的具體工作過程,在此不復贅述。
本實施中將會話內容中后續知識點的類目跳轉作為度量前文知識點分數值的因素之一,即隨著知識點的類目跳轉對前續知識點的分數值進行衰減,由此,可以提高目標知識點獲取的準確性。
與上述再一種實施例提供的目標知識點的獲取方法對應地,本申請實施例還提供的一種目標知識點的獲取裝置,如圖7所示,該裝置包括:
收集單元701,用于收集用戶與問答機器人的多次會話內容,其中,每次會話內容包括至少一個問答對,每個問答對包括一個問題和至少一個知識點,所述知識點是指對應于所述問題的答案;其中,每個知識點歸屬于一個預設類目,且對應一個初始分數值。
確定單元702,用于對每次會話內容中的每個知識點,根據當前時間、該知識點所屬問答對的創建時間以及預設閾值,確定所述每個知識點的時間衰減因子。
更新單元703,用于根據確定單元702確定的所述每個知識點的時間衰減因子,對所述每個知識點的初始分數值進行更新,得到多次會話內容中的各個知識點的第三分數值。
獲取單元704,用于根據更新單元703更新得到的所述各個知識點的第三分數值,從所述多次會話內容中的多個知識點中獲取目標知識點。
本申請實施例裝置的各功能模塊的功能,可以通過上述方法實施例的各步驟來實現,因此,本申請提供的裝置的具體工作過程,在此不復贅述。
本實施中在確定各個知識點的最終分數值時,考慮了知識點的時間衰減因子,以保證最近被點擊的知識點具有較高的權重,從而提高了目標知識點選取的準確性。
專業人員應該還可以進一步意識到,結合本文中所公開的實施例描述的各示例的對象及算法步驟,能夠以電子硬件、計算機軟件或者二者的結合來實現,為了清楚地說明硬件和軟件的可互換性,在上述說明中已經按照功能一般性地描述了各示例的組成及步驟。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本申請的范圍。
結合本文中所公開的實施例描述的方法或算法的步驟可以用硬件、處理器執行的軟件模塊,或者二者的結合來實施。軟件模塊可以置于隨機存儲器 (ram)、內存、只讀存儲器(rom)、電可編程rom、電可擦除可編程rom、寄存器、硬盤、可移動磁盤、cd-rom、或技術領域內所公知的任意其它形式的存儲介質中。
以上所述的具體實施方式,對本申請的目的、技術方案和有益效果進行了進一步詳細說明,所應理解的是,以上所述僅為本申請的具體實施方式而已,并不用于限定本申請的保護范圍,凡在本申請的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本申請的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!