數據表連接方法及裝置與流程
【技術領域】
本申請涉及數據庫技術領域,尤其涉及一種數據表連接方法及裝置。
背景技術:
隨著互聯網的發展,數據呈現爆發式增長,數據結構也開始多元化,數據含有的信息量越來越多,數據倉庫在這樣的背景下發揮著巨大的作用。由于大數據時代的降臨,數據倉庫轉成為分布式架構,以滿足爆發式增長的計算及存儲的需求。分布式數據倉庫一般使用列式存儲,并以文件的形式保存數據,因此,采用分布式數據倉庫可提高大數據的存儲及計算性能。
在分布式數據倉庫的查詢過程中,經常需要進行數據表之間的連接(join)計算。現有技術在處理數據表之間的join計算時,一般都是先將所有待join的數據表通過mapreduce的方式做洗牌(shuffle)排序,然后在reducer端對已經排過序的數據表進行歸并操作。shuffle排序實際上是指將map端各個待join的數據表按照join條件進行分區并分配到不同reducer端的過程。
在典型的“星型”join場景下,假設待join數據表包括一個主表和n個輔表,主表包含m條數據記錄,那么在對主表和n個輔表進行join計算時,shuffle排序需要處理的總數據量包括shuffle主表需要處理的數據量即m*n和shufflen個輔表需要處理的數據量,這會消耗很多計算資源。
技術實現要素:
本申請的多個方面提供一種數據表連接方法及裝置,用以降低數據表連接操作消耗的計算資源。
本申請的一方面,提供一種數據表連接方法,包括:
接收數據表連接任務,所述數據表連接任務指示按照連接條件對第一數據表和第二數據表進行連接操作;
根據所述連接條件,將所述第二數據表中的數據記錄加載到分布式系統中至少兩個節點上;
讀取所述第一數據表中的數據記錄作為當前數據記錄,根據所述當前數據記錄對應的連接條件,從所述至少兩個節點中確定目標節點,并讀取所述目標節點上存儲的所述第二數據表中的數據記錄作為目標數據記錄;
對所述當前數據記錄和所述目標數據記錄進行連接操作。
本申請的另一方面,提供一種數據表連接裝置,包括:
接收模塊,用于接收數據表連接任務,所述數據表連接任務指示按照連接條件對第一數據表和第二數據表進行連接操作;
加載模塊,用于根據所述連接條件,將所述第二數據表中的數據記錄加載到分布式系統中至少兩個節點上;
讀取模塊,用于讀取所述第一數據表中的數據記錄作為當前數據記錄,根據所述當前數據記錄對應的連接條件,從所述至少兩個節點中確定目標節點,并讀取所述目標節點上存儲的所述第二數據表中的數據記錄作為目標數據記錄;
連接模塊,用于對所述當前數據記錄和所述目標數據記錄進行連接操作。
在本申請中,在處理數據表連接任務時,首先根據其中的連接條件,將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上,之后,可以直接讀取第一數據表中的數據記錄,并根據所讀取的第一數據表中的數據記錄對應的連接條件,從相應節點上讀取所需的第二數據表中的數據記錄,之后對讀取到的兩個數據表中的數據記錄進行連接操作。由此可見,本申請只需將第二數據表按照連接條件分布到不同節點上,不需要將第一數據表分布到不同節點上,減少了shuffle排序需要處理的數據量,有利于降低連接操作所消耗的計算資源。
【附圖說明】
為了更清楚地說明本申請實施例中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作一簡單地介紹,顯而易見地,下面描述中的附圖是本申請的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本申請一實施例提供的數據表連接方法的流程示意圖;
圖2為本申請另一實施例提供的分布式系統的架構示意圖;
圖3為本申請又一實施例提供的數據表連接裝置的結構示意圖;
圖4為本申請又一實施例提供的數據表連接裝置的結構示意圖。
【具體實施方式】
為使本申請實施例的目的、技術方案和優點更加清楚,下面將結合本申請實施例中的附圖,對本申請實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本申請一部分實施例,而不是全部的實施例。基于本申請中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本申請保護的范圍。
在分布式數據倉庫的查詢過程中,經常需要進行數據表之間的連接(join)計算。現有技術在處理數據表之間的join操作時,由于待join的數據表比較大,所以一般都是先將所有待join的數據表通過mapreduce的方式做shuffle排序,然后在reducer端對已經排過序的數據表進行歸并操作。shuffle排序實際上是指將map端各個待join的數據表按照join條件進行分區并分配到不同reducer端的過程。由于需要對所有待join的數據表進行shuffle排序,消耗的計算資源較多。
針對上述技術問題,本申請提供一種解決方案,即通過將第二數據表分布存儲到多個節點上,成為一個分布式的緩存,對第一數據表處理時,通過網絡獲取遠程節點上存儲的第二數據表中的數據記錄,從而進行分布式的哈希映射 連接(hashmapjoin),使得無需對主表進行shuffle排序,這樣可以節約對第一數據表進行shuffle排序消耗的計算資源。
圖1為本申請一實施例提供的數據表連接方法的流程示意圖。如圖1所示,該方法包括:
101、接收數據表連接任務,該數據表連接任務指示按照連接條件對第一數據表和第二數據表進行連接操作。
102、根據上述連接條件,將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上。
103、讀取第一數據表中的數據記錄作為當前數據記錄,根據當前數據記錄對應的連接條件,從至少兩個節點中確定目標節點,并讀取目標節點上存儲的第二數據表中的數據記錄作為目標數據記錄。
104、對當前數據記錄和目標數據記錄進行連接操作。
本實施例提供一種數據表連接方法,可由數據表連接裝置來執行,用以進行數據表之間的join操作,同時盡量降低所消耗的計算資源。本實施例提供的方法適用于分布式系統,這里的分布式系統中的不同機器可以分別作為一個節點。本實施例并不限制分布式系統的實現架構,例如可以是但不限于mapreduce架構。
當需要進行數據表之間的join操作時,可以向數據表連接裝置發送數據表連接任務;數據表連接裝置接收數據表連接任務。該數據表連接任務指示按照連接條件對第一數據表和第二數據表進行join處理。這里的第一數據表和第二數據表實際上是待連接的數據表。
在具體實現上,該數據表連接任務攜帶有連接條件、第一數據表的標識、第二數據表的標識、第一數據表的存儲位置、以及第二數據表的存儲位置等信息。其中,數據表連接裝置可以對數據表連接任務進行解析,獲取連接條件、第一數據表的標識、第二數據表的標識、第一數據表的存儲位置、以及第二數據表的存儲位置等信息,并根據第一數據表的標識和第二數據表的標識確定需要進行join操作的數據表,另外,可以根據第一數據表的存儲位置和第二數據 表的存儲位置讀取第一數據表和第二數據表。
在一種實際應用中,第一數據表可以作為主表,第二數據表可以作為輔表實現。其中,輔表的數量可以是一個或多個。
數據表連接裝置接收到數據表連接任務之后,可以獲知需要按照連接條件對第一數據表和第二數據表進行join操作。之后,在執行join操作之前,首先根據連接條件,將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上,實現分布式存儲。
優選的,位于至少兩個節點中每個節點上的第二數據表中的數據記錄,其數據量小于單個節點的內存限制,也就是說,分布到至少兩個節點中每個節點上的第二數據表中的數據記錄,均能夠全部放到相應節點的存儲空間(優選為內存)中。
在一可選實施方式中,上述連接條件包括連接所需的至少一個目標鍵,這里的目標鍵實際上就是鍵值對(key-value)中的鍵(key)。基于此,數據表連接裝置具體可以分別對至少一個目標鍵中的各目標鍵進行哈希運算,以獲取各目標鍵的哈希值;根據各目標鍵的哈希值和上述用于存儲第二數據表中的數據記錄的至少兩個節點的數量,確定各目標鍵對應的節點;將第二數據表中對應于各目標鍵的數據記錄分別加載到各目標鍵對應的節點上。
進一步,數據表連接裝置可以利用各目標鍵的哈希值對上述用于存儲第二數據表中的數據記錄的至少兩個節點的數量取模,根據取模結果確定各目標鍵對應的節點。具體的,可以將取模結果代表的節點作為目標鍵對應的節點。或者,
數據表連接裝置可以根據上述用于存儲第二數據表中的數據記錄的至少兩個節點的數量和目標鍵的數量,將各目標鍵均分到各節點上,在均分過程中,可以根據各目標鍵的哈希值,將哈希值相近的目標鍵分到相同節點。這里的哈希值相近可以是指哈希值之差小于預設門限,但不限于此。
進一步,在上述加載第二數據表中的數據記錄到至少兩個節點上的過程中,具體可以將第二數據表中的數據記錄加載到至少兩個節點的內存中。第二數據 表中的數據記錄存儲在節點的內存中,可以隨時讀取,讀取速度較快,有利于提高join操作的效率。
值得說明的是,優選的,可以將第二數據表中的數據記錄加載到上述至少兩個節點的內存中,但并不限于內存,還可以是節點的固態硬盤(solidstatedrives,ssd)或者其他存儲介質中。
在一可選實施方式中,在根據連接條件,將第二數據表中的數據記錄加載到分布式系統中的至少兩個節點上之前,可以判斷第二數據表的數據量是否大于單個節點的內存限制;若判斷結果為是,即第二數據表的數據量大于單個節點的內存限制,這意味著第二數據表中的數據記錄不能全部放在單個節點的內存中,因此可以根據連接條件,將第二數據表中的數據記錄加載到至少兩個節點中,使得分布到每個節點上的第二數據表中的數據記錄均能全部放到相應節點的內存中,實現分布式存儲。簡單的說,分布到每個節點上的第二數據表中的數據記錄,其數據量小于單個節點的內存限制。
若上述判斷結果為否,即第二數據表的數據量小于或等于單個節點的內存限制,這意味著第二數據表中的數據記錄可以全部放在單個節點的內存中,較為優選的,可以將第二數據表的數據記錄全部放到單個節點的內存中,從而節省對第二數據表的數據記錄進行shuffle排序,節約計算資源。
上述將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上,這相當于將第二數據表變成了多個小表,每個小表可以全部在相應節點的內存中放得下,形成分布式的kv存儲,使得可以做分布式的hashmapjoin,而不需要做排序合并連接(sortmergejoin)。做分布式的hashmapjoin,不需要對第一數據中的數據記錄進行排序,可以直接讀取第一數據表中的數據記錄,并根據所讀取的第一數據表中的數據記錄對應的連接條件,從相應節點上讀取所需的第二數據表中的數據記錄,之后對讀取到的兩個數據表中的數據記錄進行join操作。
其中,本實施例中分布式的hashmapjoin與現有hashmapjoin的區別在于:在對第一數據表處理時,不是在本地內存中查找第二數據表中的數據記 錄,而是通過網絡獲取遠程節點上存儲的第二數據表中的數據記錄。
具體的,在將第二數據表中的數據記錄加載到分布式系統中至少兩個節點之后,數據表連接裝置可以到第一數據表的存儲位置讀取第一數據表中的數據記錄,將讀取到的數據記錄作為當前數據記錄,根據當前數據記錄對應的連接條件,從上述至少兩個節點中確定目標節點,這里的目標節點是指與當前數據記錄進行join操作所需的第二數據表中的數據記錄所在的節點,然后讀取目標節點上存儲的第二數據表中的數據記錄作為目標數據記錄,這里的目標數據記錄是指與當前數據記錄進行join操作所需的第二數據表中的數據記錄。
在讀取到當前數據記錄以及與當前數據記錄進行join操作所需的目標數據記錄之后,對當前數據記錄與目標數據記錄進行join操作。由于如何對當前數據記錄與目標數據記錄進行join操作不是本申請的重點,在此不再詳述,可參考現有技術中有關join操作的處理流程。
在一可選實施方式中,考慮到數據表連接裝置的本地緩存中可能會存在與當前數據記錄進行join操作所需的目標數據記錄,基于此,在根據當前數據記錄對應的連接條件,從至少兩個節點中確定目標節點,并讀取目標節點上存儲的第二數據表中的數據記錄作為目標數據記錄之前,可以根據當前數據記錄對應的連接條件,判斷本地緩存中是否存在目標數據記錄,若判斷結果為否,則執行根據當前數據記錄對應的連接條件,從至少兩個節點中確定目標節點,并讀取目標節點上存儲的第二數據表中的數據記錄作為目標數據記錄的操作;若判斷結果為是,則可以從本地緩存中獲取目標數據記錄,這樣可以更加快速的獲取目標數據記錄,節約獲取目標數據記錄所消耗的網絡資源,提高join操作的效率。
進一步,上述當前數據記錄對應的連接條件可以是目標鍵,則一種根據當前數據記錄對應的連接條件,從至少兩個節點中確定目標節點的實施方式包括:
對當前數據記錄對應的目標鍵進行哈希運算,以獲得當前數據記錄對應的目標鍵的哈希值;根據當前數據記錄對應的目標鍵的哈希值和上述至少兩個節點的數量,確定當前數據記錄對應的目標鍵對應的節點作為目標節點。
更進一步,在通過目標鍵確定從某個節點上取目標數據的過程中,若目標鍵有多個,則可以進行批量操作,這樣可以充分發揮分布式系統的優勢,提高處理性能。
由上述分析可見,本實施例在處理數據表連接任務時,首先根據其中的連接條件,將第二數據表中的數據記錄加載到至少兩個節點上,這相當于變成了一個分布式的kv存儲(即會有分布式的哈希表),這樣不需要做sortmergejoin,使得可以做分布式的hashmapjoin,即不需要對第一數據中的數據記錄進行排序,而是可以直接讀取第一數據表中的數據記錄,并根據所讀取的第一數據表中的數據記錄對應的連接條件,從相應節點上讀取所需的第二數據表中的數據記錄,之后對讀取到的兩個數據表中的數據記錄進行join操作。由此可見,本實施例只需將第二數據表按照連接條件分布到不同節點上,不需要將第一數據表分布到不同節點上,減少了shuffle排序需要處理的數據量,有利于降低連接操作所消耗的計算資源。
下面通過對比sortmergejoin與分布式的hashmapjoin消耗的計算資源,以說明本申請技術方案帶來的優勢。
假設主表是a,其數據大小是100t,假設輔表有2個分別是b和c,輔表b的數據大小為10g,輔表c的數據大小為100g。
若采用現有sortmergejoin,其shuffle排序階段需要將主表a和輔表b進行一次排序處理,還需要將主表a和輔表c進行一次排序處理,每次排序處理包括通過網絡io讀數據表以及通過cpu進行排序,所以每次排序處理的資源消耗包括:排序所占cpu和讀表所占的網絡io。為便于描述,通過處理的數據量表示資源消耗,在這里,考慮到cpu排序處理的數據量也就是通過網絡io讀取的數據量,故以一份數據量來表示每次排序處理的資源消耗,則shuffle排序階段需要總資源消耗為:(100t+10g)+(100t+100g)=2*100t+10g+100g。
若采用本申請分布式的hashmapjoin,其shuffle排序階段需要將輔表b分布到不同節點上,還需要將輔表c分布到不同節點上,每次將某個表分布到 不同節點上包括通過網絡io讀數據表以及通過cpu進行排序,所以將某個表分布到不同節點上的資源消耗同樣包括:排序所占cpu和讀表所占的網絡io。為便于描述,通過處理的數據量表示資源消耗,在這里,考慮到cpu排序處理的數據量也就是通過網絡io讀取的數據量,故以一份數據量來表示每次排序處理的資源消耗,則shuffle排序階段需要總資源消耗為:10g+100g。
由上述可見,由于本申請技術方案只需將第二數據表按照連接條件分布到不同節點上,不需要將第一數據表分布到不同節點上,減少了shuffle排序需要處理的數據量,有利于降低連接操作所消耗的計算資源。
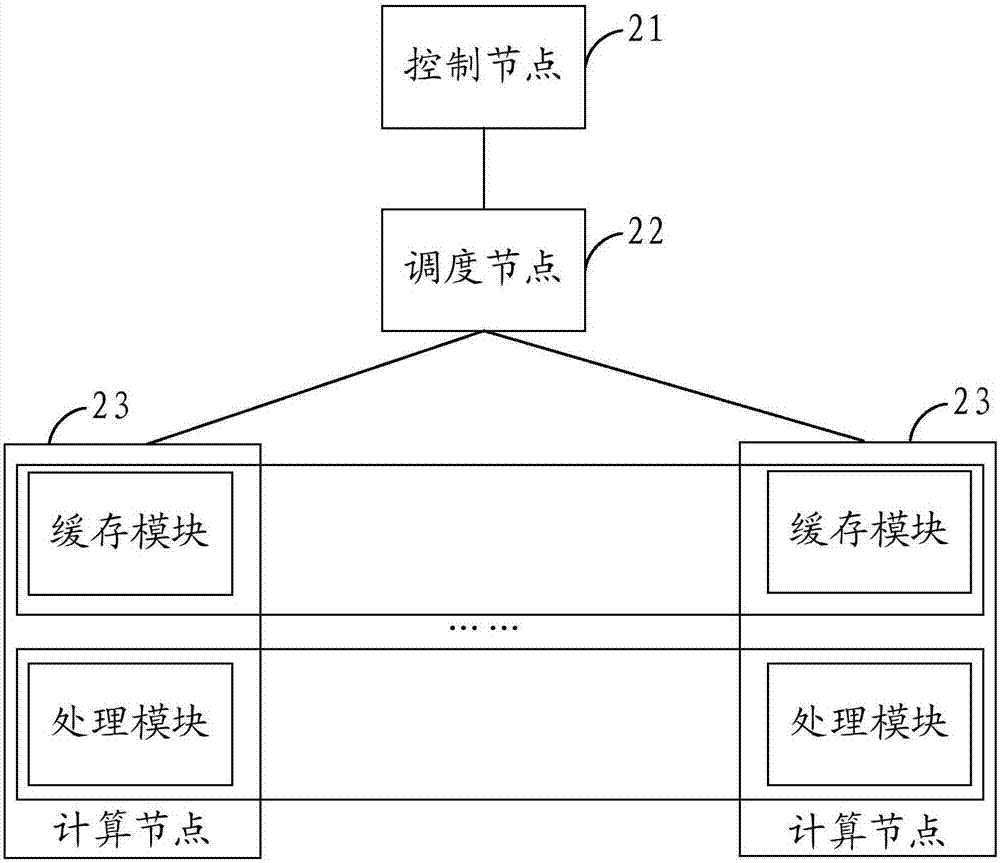
圖2為本申請另一實施例提供的分布式系統的架構示意圖。如圖2所示,該分布式系統包括:控制節點21、調度節點22、以及至少兩個計算節點23。進一步,如圖2所示,計算節點23至少包括緩存模塊和處理模塊。
值得說明的是,圖2所示分布式系統僅為一種示例,并不限于此,例如可以將圖2中的調度節點22省略從而獲得一種更為簡單的分布式系統。
下面將基于圖2所示分布式系統,對本申請技術方案進行詳細說明。
控制節點21負責接收數據表連接任務,根據數據表連接任務獲知需要按照連接條件對第一數據表和第二數據表進行連接操作。
控制節點21可以根據數據表連接任務向調度節點22發送調度指令,控制調度節點22調度分布式系統中可用的計算節點23。調度節點22具體接收控制節點21的調度指令,根據調度指令調度分布式系統中的計算節點23。
在上述調度分布式系統中的計算節點23的過程中,控制節點21通過調度節點22向計算節點23提供后續加載第二數據表中的數據記錄所需的配置文件,該配置文件記載有第二數據表的標識、存儲位置、以及需要加載的數據記錄的標識信息等。
在分布式系統中各計算節點23上部署有加載進程,該加載進程主要根據配置文件,將第二數據表中的數據記錄加載到緩存模塊中。具體的,調度模塊22激活各計算節點23上的加載進程,加載進程根據配置文件,到相應存儲位置讀取第二數據表中的相應數據記錄,將其所讀取的數據記錄加載到緩存模塊中。 值得說明的是,第二數據表可以存儲在分布式系統之外的空間中,但并不限于此。
當所有計算節點23上的加載進程執行完加載操作,即均進入監聽端口狀態時,通過調度節點22向控制節點21返回一個加載結束指令。控制節點21根據該加載結束指令,可以獲知各計算節點23已經將第二數據表中的數據記錄加載到緩存模塊中。
控制節點21向調度節點22發送激活指令,使得調度節點22激活各計算節點23上的處理進程。在各計算節點23上部署有處理進程,處理進程主要用于讀取第一數據表中的數據記錄作為當前數據記錄,根據所讀取的當前數據記錄對應的key,確定該key對應的第二數據表中的數據記錄所在的計算節點23,讀取所確定的計算節點23上存儲的第二數據表中的數據記錄作為目標數據記錄,對所讀取的當前數據記錄和目標數據記錄進行join操作。值得說明的是,第一數據表可以存儲在分布式系統之外的空間中,但并不限于此。
可選的,在一種具體實現方式中,上述各計算節點23可以采用服務端/客戶端的方式實現。例如,各計算節點23的緩存模塊可以作為緩存服務端(cacheservice)實現,該緩存服務端還包括一個緩存管理者(cachemanager),各緩存模塊對應一個緩存節點(cachenode);相應的,各計算節點23的處理模塊作為緩存客戶端(cacheclient)實現。
具體的,cachemanager協調管理所有cachenode。cachenode負責加載數據到內存,并提供服務。可選的,第二數據表可以用shard文件的形式進行存儲管理,采用shard文件的目的是因為在故障(failover)時,一但cachenode重啟,只需再次讀入shard文件,使得處理相對簡單。
cacheclient訪問cacheservice,通過對key進行hash計算,并根據計算結果從其中某個cachenode讀取數據。此外,cacheclient中應該有一部分本地緩存,通常會使用近期最少使用算法(leastrecentlyused,lru)等緩存算法將部分已經讀取的數據保存在本地緩存中,這樣cacheclient可以優先從本地緩存中讀取所需的數據,如果在本地緩存中讀取到所需的數據,可以節 約通過網絡從cachenode讀取數據的操作,有利于提高效率、節約資源。
由上述分析可見,本實施例在處理數據表連接任務時,首先根據其中的連接條件,將第二數據表中的數據記錄加載到至少兩個節點上,實現分布式存儲,使得可以直接讀取第一數據表中的數據記錄,并根據所讀取的第一數據表中的數據記錄對應的連接條件,從相應節點上讀取所需的第二數據表中的數據記錄,之后對讀取到的兩個數據表中的數據記錄進行join操作,實現分布式的hashmapjoin。由此可見,本實施例只需將第二數據表按照連接條件分布到不同節點上,不需要將第一數據表分布到不同節點上,減少了shuffle排序需要處理的數據量,有利于降低連接操作所消耗的計算資源。
需要說明的是,對于前述的各方法實施例,為了簡單描述,故將其都表述為一系列的動作組合,但是本領域技術人員應該知悉,本申請并不受所描述的動作順序的限制,因為依據本申請,某些步驟可以采用其他順序或者同時進行。其次,本領域技術人員也應該知悉,說明書中所描述的實施例均屬于優選實施例,所涉及的動作和模塊并不一定是本申請所必須的。
在上述實施例中,對各個實施例的描述都各有側重,某個實施例中沒有詳述的部分,可以參見其他實施例的相關描述。
圖3為本申請又一實施例提供的數據表連接裝置的結構示意圖。如圖3所示,該裝置包括:接收模塊31、加載模塊32、讀取模塊33和連接模塊34。
接收模塊31,用于接收數據表連接任務,該數據表連接任務指示按照連接條件對第一數據表和第二數據表進行連接操作。
加載模塊32,用于根據連接條件,將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上。
讀取模塊33,用于讀取第一數據表中的數據記錄作為當前數據記錄,根據當前數據記錄對應的連接條件,從至少兩個節點中確定目標節點,并讀取目標節點上存儲的第二數據表中的數據記錄作為目標數據記錄。
連接模塊34,用于對當前數據記錄和目標數據記錄進行連接操作。
優選的,位于至少兩個節點中每個節點上的第二數據表中的數據記錄,其 數據量小于單個節點的內存限制,也就是說,分布到至少兩個節點中每個節點上的第二數據表中的數據記錄,均能夠全部放到相應節點的存儲空間(優選為內存)中。
進一步,如圖4所示,該裝置還包括:第一判斷模塊35。
第一判斷模塊35,用于判斷第二數據表的數據量是否大于單個節點的內存限制,以及在判斷結果為是時觸發加載模塊32執行根據連接條件,將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上的操作。
更進一步,如圖4所示,該裝置還包括:第二判斷模塊36。
第二判斷模塊36,用于根據當前數據記錄對應的連接條件,判斷本地緩存中是否存在所述目標數據記錄,以及在判斷結果為否時觸發讀取模塊33執行根據當前數據記錄對應的連接條件,從至少兩個節點中確定目標節點,并讀取目標節點上存儲的第二數據表中的數據記錄作為目標數據記錄的操作。
在一可選實施方式中,上述連接條件包括連接所需的至少一個目標鍵。這里的目標鍵實際上是鍵值對中的鍵。
基于上述,加載模塊32具體用于:
分別對所述至少一個目標鍵中的各目標鍵進行哈希運算,以獲取各目標鍵的哈希值;
根據各目標鍵的哈希值和所述至少兩個節點的數量,確定各目標鍵對應的節點;
將所述第二數據表中對應于各目標鍵的數據記錄分別加載到各目標鍵對應的節點上。
在一可選實施方式中,加載模塊32具體用于:
根據所述連接條件,將所述第二數據表中的數據記錄加載到所述至少兩個節點的內存中。第二數據表中的數據記錄存儲在節點的內存中,可以隨時讀取,讀取速度較快,有利于提高join操作的效率。
值得說明的是,優選的,可以將第二數據表中的數據記錄加載到上述至少兩個節點的內存中,但并不限于內存,還可以是節點的ssd或者其他存儲介質 中。
本實施例提供的數據表連接裝置,在處理數據表連接任務時,首先根據其中的連接條件,將第二數據表中的數據記錄加載到分布式系統中至少兩個節點上,這相當于變成了一個分布式的kv存儲,這樣不需要做sortmergejoin,使得可以做分布式的hashmapjoin,即不需要對第一數據中的數據記錄進行排序,而是可以直接讀取第一數據表中的數據記錄,并根據所讀取的第一數據表中的數據記錄對應的連接條件,從相應節點上讀取所需的第二數據表中的數據記錄,之后對讀取到的兩個數據表中的數據記錄進行連接操作。由此可見,采用本實施例提供的數據表連接裝置,只需將第二數據表按照連接條件分布到不同節點上,不需要將第一數據表分布到不同節點上,減少了shuffle排序需要處理的數據量,有利于降低連接操作所消耗的計算資源。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統,裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的系統,裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本申請各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元 中。上述集成的單元既可以采用硬件的形式實現,也可以采用硬件加軟件功能單元的形式實現。
上述以軟件功能單元的形式實現的集成的單元,可以存儲在一個計算機可讀取存儲介質中。上述軟件功能單元存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)或處理器(processor)執行本申請各個實施例所述方法的部分步驟。而前述的存儲介質包括:u盤、移動硬盤、只讀存儲器(read-onlymemory,rom)、隨機存取存儲器(randomaccessmemory,ram)、磁碟或者光盤等各種可以存儲程序代碼的介質。
最后應說明的是:以上實施例僅用以說明本申請的技術方案,而非對其限制;盡管參照前述實施例對本申請進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本申請各實施例技術方案的精神和范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!