基于再生碼的分布式存儲系統與處理方法與流程
本申請涉及數據存儲系統與處理方法,具體涉及一種基于再生碼的分布式存儲系統與處理方法。
背景技術:
分布式存儲系統是將數據分散存儲在多臺獨立的設備上。傳統的網絡存儲系統采用集中的存儲服務器存放所有數據,存儲服務器成為系統性能的瓶頸,也是可靠性和安全性的焦點,不能滿足大規模存儲應用的需要。分布式網絡存儲系統采用可擴展的系統結構,利用多臺存儲服務器分擔存儲負荷,利用位置服務器定位存儲信息,它不但提高了系統的可靠性、可用性和存取效率,還易于擴展。
在傳統分布式存儲系統中為提高系統可靠性,因此采用再生碼(regeneratingcodes)的數據恢復。再生碼是一種基于糾錯碼理論的分支。透過網絡在數據傳輸過程中發生錯誤后,數據接收端能透過糾錯碼自行發現錯誤或糾正。再生碼的修復過程中,新節點需要在剩下的存儲節點中連接d個存儲節點并分別從這d個存儲節點中下載p大小的數據,所以再生碼的修復帶寬為d*p。同時給出了再生碼功能修復的模型并提出了再生碼的兩類最佳碼:最小帶寬再生碼(msr,minimum-storageregenerating)和最小修復帶寬再生碼(mbr,minimum-bandwidthregenerating)。
但傳統的分布式存儲系統無法針對存儲數據的特性而對數據的可靠性進行調整。由于傳統的分布式存儲系統中的存儲節點數量是固定的。所以遇到頻繁被存取的數據的情況時,該數據可能發生延遲傳輸的問題。
技術實現要素:
本申請所要解決的技術問題在于提供一種基于再生碼的分布式存儲系統,其特征在于編碼數據傳輸至各節點后,可擴展至指定的節點。
為了解決上述問題,本申請揭示了一種基于再生碼的分布式存儲系統包括數據源端與多個存儲節點。數據源端具有控制模塊與編碼器,該控制模塊對接收的輸入數據組切分成多個數據分塊,該數據分塊通過該編碼器時,該編碼器根據編碼向量輸出子數據條帶,且該些編碼向量彼此為非線性相關。存儲節點網絡連接于該數據源端,該數據源端根據該些編碼向量派送不同的該子數據條帶至對應的該存儲節點。數據源端接收節點擴展命令用于擴展所指定的該存儲節點,該數據源端任意選取至少兩個該存儲節點,該數據源端根據所選取的該些子數據條帶與所屬的該些編碼向量進行線性組合,并輸出擴展節點。
為了解決上述問題,本申請更揭示一種基于再生碼的分布式存儲系統包括以下步驟:數據源端將輸入數據組切分為多個數據分塊;數據源端根據編碼向量將數據分塊編碼轉換為子數據條帶;數據源端根據子數據條帶與相應的編碼向量發送至存儲節點,并將子數據條帶記錄于存儲節點;數據源端接收節點擴展命令,并指定任一存儲節點;數據源端另選取至少兩個以上的存儲節點,數據源端根據所選取的存取節點、編碼向量與子數據條帶生成擴展節點。
與現有技術相比,本申請可以獲得包括以下技術效果:
1)本申請相比傳統的由編碼控制器統一選擇固定的節點進行拓展的辦法,具有消耗帶寬少、編碼效率高、計算成本低及適應高動態變化的網絡狀況等優點。
2)本申請可以應用于塊存儲、基于對象存儲的分布式存儲系統的編解碼和分發模塊。對應的存儲系統更適合一次性寫入、讀頻率不高,但可靠性要求較高場景,例如歸檔系統。
當然,實施本申請的任一產品必不一定需要同時達到以上所述的所有技術效果。
附圖說明
此處所說明的附圖用來提供對本申請的進一步理解,構成本申請的一部分,本申請的示意性實施例及其說明用于解釋本申請,并不構成對本申請的不當限定。
圖1a為本申請的硬體架構示意圖。
圖1b為本申請的數據傳輸架構示意圖。
圖2為本申請的運作步驟示意圖。
圖3a為本申請的數據分塊與編碼的過程示意圖。
圖3b為本申請的存儲節點的數據恢復示意圖。
圖4為本申請的擴展存儲節點的示意圖。
具體實施方式
以下請配合附圖及實施例來詳細說明本申請的實施方式,藉此對本申請如何應用技術手段來解決技術問題并達成技術功效的實現過程能充分理解并據以實施。
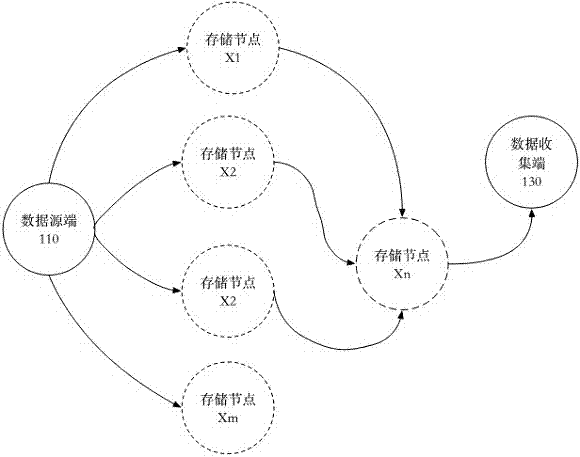
請參考圖1a與圖1b所示,其系為本申請的硬體架構與數據傳輸架構示意圖。本申請的基于再生碼的分布式存儲系統100包括數據源端110與多個存儲節點120。本申請中數據源端110所指的是存儲系統對于數據輸入的前臺接口,數據源端110可以是但不限定為磁盤、因特網(internet)或人機輸入界面(interface)等。數據源端110透過網絡連接于存儲節點120。
數據源端110包括控制模塊111與編碼器112。控制模塊111將接收的輸入數據組切分成多個數據分塊。編碼器112記錄編碼向量矩陣,編碼向量矩陣記錄多筆編碼向量。數據分塊通過編碼器112時,由編碼器112從編碼向量矩陣中選擇任一編碼向量。編碼器112根據編碼向量輸出相應數據分塊的子數據條帶,且這些編碼向量彼此為非線性相關。數據源端110根據不同的編碼向量并派送子數據條帶至對應的存儲節點120。存儲節點120的種類為硬盤、固態硬盤或閃存等。存儲節點120用于存儲子數據條帶。
在圖1b中的左側系為數據源端110(datasource),最右側系為數據收集端130(datacollector)。在數據源端110與數據收集端130之間存在多個存儲節點120。數據收集端130包括譯碼器131。譯碼器131根據所接獲部分的子數據條帶反譯回指定的數據分塊。在圖1b中的存儲節點120以xi表示,其中i為編號。在圖1b中以存在的存儲節點120以短虛線表示,而欲擴展的存儲節點120以長虛線表示。
假設輸入數據組的數據大小為b,d為擴展節點時所需的存儲節點120的個數,α為每個存儲節點120所存儲的子條帶數據的數量。以b=4,α=2,d=3為例,意即輸入數據組b包括4個數據分塊。每一個存儲節點120可以存儲1個子數據條帶,而一個子數據條帶記錄2個數據分塊(意即為α)。產生一個新的擴展節點需要連接3個存儲節點120(意即為d)。
為清楚說明輸入數據組的數據分塊與子數據條帶的產生過程,本申請以一個存儲節點120并可記錄兩個子條帶數據作為說明,但并非僅局限于說明中的數量或順序。請參考圖2所示,其系為本申請的運作步驟示意圖。
步驟s210:數據源端將輸入數據組切分為多個數據分塊;
步驟s220:數據源端根據編碼向量將數據分塊編碼轉換為子數據條帶;
步驟s230:數據源端根據子數據條帶與相應的編碼向量發送至存儲節點,并將子數據條帶記錄于存儲節點;
步驟s240:數據源端接收節點擴展命令,并指定任一存儲節點;以及
步驟s250:數據源端另選取至少兩個以上的存儲節點,數據源端根據所選取的存取節點、編碼向量與子數據條帶生成擴展節點。
首先,數據源端110接收輸入數據組并將輸入數據組切分成多個數據分塊。在此假設共有k個存儲節點120,且存儲節點120記作nodei,其中i表示第i個存儲節點且i≦k(未避免所有的存儲節點均使用同一標號,因此后文以存儲節點的標號作為區分)。再以b=4,α=2,d=3為例,輸入數據組包括4個數據分塊,分別為u11,u12,u13與u14。此一說明中,存儲節點中可記錄1個子數據條帶,每一個子數據條帶包括2個數據分塊,請配合參考圖3a所示。前述的數據分塊u11,u12,u13與u14可兩兩組成一組向量
數據源端110再把經過編碼后的子數據條帶與所屬的編碼向量發送至存儲節點,并令存儲節點記錄子數據條帶與編碼向量。當數據收集端130發現份任一存儲節點毀損時,數據收集端130可根據現有的存儲節點與所存子數據條帶對已毀損的存儲節點進行數據恢復,請配合參考圖3b所示。當存儲節點nodem發生毀損,數據收集端130從其它存活的存儲節點選擇至少兩個以上的存儲節點,在此分別定義存儲節點為nodei與nodej。存儲節點nodei與nodej各自存儲兩子數據條帶,而兩子數據條帶分別為
前述的矩陣在符合滿秩的條件時,可以透過線性消去的方式進一步得到u11,u12,u13與u14四個數據分塊。而由于
本申請除了存儲節點的數據恢復外,更可以針對指定的存儲節點進行擴展。本申請的節點擴展的作用在于可透過其它存儲節點的資訊來克隆所指定的存儲節點與所屬資料,并請配合圖4。
在此以存儲節點a、存儲節點b與存儲節點c作為新存儲節點的擴展依據,而欲擴展的存儲節點則定義為存儲節點d。存儲節點a、存儲節點b與存儲節點c分別記錄數據分塊
解(1),可以得到下述兩等式(3)與(4)
由于
代入(4)中,有:
方便起見,記作:
任意給定一對k3≠0,??3的值,即可通過該方程解出組合系數k1,k2,k3以及??1,??2,??3(其中
接下來,解第二個方程:
解(10)得到:
所述裝置與前述的方法流程描述對應,不足之處參考上述方法流程的敘述,不再一一贅述。上述說明示出并描述了本申請的若干優選實施例,但如前所述,應當理解本申請并非局限于本文所披露的形式,不應看作是對其它實施例的排除,而可用于各種其它組合、修改和環境,并能夠在本文所述發明構想范圍內,通過上述教導或相關領域的技術或知識進行改動。而本領域人員所進行的改動和變化不脫離本申請的精神和范圍,則都應在本申請所附權利要求的保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!