用于核回歸模型的集體的設備和方法與流程
本申請要求35 U.S.C.§119(e)下的對2014年9月12日提交的題為APPARATUS AND METHOD FOR ENSEMBLES OF KERNEL REGRESSION MODELS的美國臨時申請號62/049558的權益,其內容通過引用整體結合在本文中。
背景技術:
技術領域
本申請涉及建模,并且更具體地,涉及基于建模獲得參數的行為的估計。
背景技術
核回歸是用于確定數據集中的值之間的非線性函數或關系的建模形式,并且用于監測機器或系統以確定機器或系統的情況(condition)。對于基于序列相似性建模(SSM),多個傳感器信號測量機器、系統或被監測的其它對象的物理相關參數以提供傳感器數據。參數數據可以包括來自信號或不管是否基于傳感器信號的其他計算數據的實際值或當前值。然后,參數數據由經驗模型處理以提供那些值的估計。然后將估計與實際值或當前值進行比較,以確定在被監測的系統中是否存在故障。
更具體地,該模型使用表示已知操作狀態的傳感器值的選擇的歷史模式的參考庫來生成估計。這些模式也被稱為向量、快照或觀察,并且包括來自多個傳感器的值或指示在時間瞬間被監測的機器的情況的其他輸入數據。在來自參考庫的參考向量的情況下,向量通常指示被監測的機器的正常操作。模型將來自當前時間的向量與來自參考庫的已知狀態的多個選擇的學習向量進行比較,以估計系統的當前狀態。一般來說,將當前向量與由來自參考庫的選擇的向量組成的矩陣進行比較以形成權重向量。在進一步步驟中,將權重向量乘以矩陣以計算估計值的向量。然后將估計向量與當前向量進行比較。如果向量中的估計值和實際值不足夠相似,則這可以指示在被監測的對象中存在故障。
核回歸建模的另一種形式是基于變量相似性建模(VBM)。在VBM中,首先從表示機器、過程或系統的測量或傳感器獲取參考數據觀察。然后,從表示性數據與來自相同傳感器或測量的當前觀察的組合計算模型。該模型采用建模的系統的每個新觀察重新計算。模型的輸出是表征建模的系統的狀態的至少一個傳感器、測量或其他分類或資格參數的估計。
雖然上面提到的方法可以被利用來獲得估計,但是以這種方式獲得估計存在一些限制。在一些工業中存在問題,在所述工業中使用回歸模型來估計未對重要時間段測量或者根本不能測量(因為正在估計未來響應)的關鍵傳感器或操作參數的響應。置信界限的精確計算對于這些問題是特別有益的,因為估計和相關聯的置信界限會是可用于關鍵參數的僅有數據。
上面提到的工業問題的一個示例涉及泵輔助的油和氣提取。井中和電潛泵上的井下(down hole)傳感器提供諸如儲層溫度、儲層壓力和泵速度的參數的連續測量,但是沒有用于確定提取的油和氣的體積的關鍵井性能參數。在井測試期間以不規則的間隔測量關鍵性能參數,例如體積流率和含水率(即,與從油井產生的總液體的體積相比所產生的水的比率)。因此,當前方法在獲得這些類型的估計方面沒有做出足夠或可接受的工作。
這些問題已經造成了對先前方法的一些普遍的用戶不滿意。
技術實現要素:
本方法創建用于從被監測的對象或過程接收的傳感器數據的每個觀察向量的核回歸模型的集體(ensemble)(族)。集體中的模型從與當前情況相似但是彼此獨立的數據而創建。每個模型生成用于每個模型變量的估計向量。統計量從生成的用于每個變量的估計的分布計算。在一個方面,計算估計分布的平均值,并且這提供了比由任何單個模型產生的當前情況的估計更魯棒的估計。在另一方面,計算分布的中值。由于獨立模型的總體(population)與傳感器和過程誤差相關,所以估計分布的寬度的測量(例如,標準偏差)提供了對于當前觀察向量的模型估計的不確定性的指示。
在這些實施例的許多實施例中,感測表示與實體或過程相關聯的物理參數的信息。感測的信息被收集到當前模式或當前模式序列中。將當前模式或當前模式序列與歷史數據進行比較,以便獲得最佳匹配的總體。基于最佳匹配的總體創建多個核回歸模型。使用多個核回歸模型生成用于至少一個感興趣的傳感器的估計值的至少一個分布。分析針對感興趣的一個或多個傳感器的估計值的分布以獲得針對感興趣的傳感器的每個的估計分布的中心的測量和估計分布的寬度的測量。
在一些方面,創建包括在單個和當前時間點創建多個核回歸模型。在其他方面,創建包括創建用于以單個和當前時間點結束的相關時間點的時間序列的多個核回歸模型。
在一些示例中,估計分布的中心的測量包括平均值。在其他示例中,估計分布的中心的測量包括中值。在其他方面,估計分布寬度的測量包括標準偏差。在一些其他示例中,基于預定準則來選擇地除去多個模型中的至少一個。
在這些實施例的其他實施例中,用于獲得估計的設備包括接口和處理器。接口包括輸入和輸出,并且輸入配置成接收表示與實體或過程相關聯的物理參數的感測的信息。感測的信息被收集到當前模式或當前模式序列中。
處理器耦合到接口。處理器配置成將當前模式或當前模式序列與歷史數據進行比較,以便獲得最佳匹配的總體。處理器配置成基于最佳匹配的總體創建多個核回歸模型并且使用多個核回歸模型生成感興趣的傳感器的估計值的至少一個分布。所述處理器還被配置成分析感興趣的傳感器的估計值的至少一個分布,以獲得至少一個估計分布的中心的測量和至少一個估計分布的估計分布寬度的測量。處理器在輸出呈現至少一個估計分布的中心的測量和至少一個估計分布的估計分布寬度的測量。
附圖說明
為了更完整地理解本公開,應對以下詳細描述和附圖進行參考,其中:
圖1包括根據本發明的各種實施例的用于獲得估計的系統的框圖;
圖2包括示出根據本發明的各種實施例的估計的值的不同統計方面的圖;
圖3包括根據本發明的各種實施例的用于獲得估計的方法的流程圖;
圖4包括根據本發明的各種實施例的用于獲得估計的設備的框圖。
本領域技術人員將意識到,為了簡單和清楚起見,示出圖中的元件。將進一步意識到,可以以具體的發生的順序描述或描繪某些動作和/或步驟,而本領域技術人員將理解,相對于序列的此類特性實際上不是要求的。還將理解,本文使用的術語和表達具有如與相對于其對應的調查和研究的相應的領域的此類術語和表達相一致的普通含義(除非在本文中以其它方式闡述特定含義的地方)。
具體實施方式
本方法利用作為隨機建模方法(如隨機森林和梯度提升模型)的區別特性的集體學習和隨機化特征選擇屬性。但是,與利用諸如決策樹的弱學習器的這些傳統集體學習算法不同,本方法利用局部(localized)核回歸模型的比較強的學習算法。
兩種形式的核回歸建模算法利用局部學習算法,并且可以根據本方法使用這兩種建模技術。這些建模算法的第一形式的示例,也稱為基于變量相似性建模(VBM),在美國專利號7,403,869中描述,其通過引用整體結合在本文中。第二形式的核回歸算法的示例,也稱為基于序列相似性建模(SSM),在美國專利號8,602,853中描述并且這也通過引用整體結合在本文中。
在本方法所利用的局部學習算法中,將被監測系統的當前狀態與學習狀態的大得多的參考陣列中的狀態進行比較。應用相似性算子或其他模式匹配函數以提供當前狀態和參考陣列中的每個狀態之間的模式重疊的數值分數。將具有最高分數的參考狀態的小集合(例如10個)收集在訓練矩陣中以創建模型。該模型用于生成當前狀態的估計。
在VBM算法的上下文中,狀態是觀察向量,而在SSM的上下文中,狀態是時間上相關的觀察向量的序列。在本公開的許多中,許多討論涉及利用VBM算法的本方法的應用。但是在不失一般性的情況下,應當理解,本方法同樣適用于并且可以利用SSM算法。
因為參考陣列中的向量的數量趨向于大于系統的唯一操作狀態的數量,所以僅選擇與當前觀察向量良好匹配的參考向量的小部分。此外,產生最高模式匹配的參考向量趨向于具有與觀察向量的隨機波動一致的隨機波動的那些參考向量。復合信號中隨機元素的這個對準增加了模型過擬合數據的噪聲分量的趨勢。
本文描述的基于集體核回歸模型的方法抵消局部學習算法創建通過從與觀察向量良好匹配的較大的參考向量總體中隨機選擇訓練向量來過擬合的模型的趨勢。多次執行用于創建回歸模型的參考向量的隨機選擇,例如,50次。
每個回歸模型生成估計向量。對由核回歸模型的集體生成的估計向量的集合進行平均,以產生估計向量(其比任何組成向量更少由噪聲上色(colored))。模型的集體的精確度通過估計向量分布的變化的測量來提供,例如標準偏差或分布的第5百分位和第95百分位之間的差。對于模型中的每個變量計算這些統計量。
因為訓練向量是隨機選擇的,所以有可能集體模型將不良地執行。在一些方面,利用修剪算法來除去任何不良執行集體模型。在一個示例中,修剪算法利用統計量(該統計量被稱為全局相似性并且在美國專利號6,859,739中描述,其通過引用整體結合在本文中)。存在其他類型的修剪算法。一般來說,這些算法提供模型質量或擬合優度的統計測量。此類統計測量包括作為根均方誤差和確定系數(也稱為R平方統計量)的測量。修剪算法將模型質量測量應用于每個集體模型的輸出(即,估計向量),并且除去任何集體模型(其質量小于某個預定義閾值)。
由于模型估計從一系列相關模型的平均響應導出,因此集體核回歸模型提供了比創建觀察向量的單個估計的標準核回歸模型更加魯棒的系統響應的估計,因為影響單個模型的傳感器噪聲和過程通過跨集體求平均而減少。但是更有益的是,跨集體的模型輸出的變化是總的模型響應的置信的直接測量。不僅集體核回歸模型可以提供所有模型變量的響應的估計,而且它們可以對獨立估計提供上置信界限和下置信界限。
參照圖1,估計系統100(其可以是結合時域信息的VBM系統或SSM系統)可以以一個或多個模塊的形式體現在計算機程序中,并且在一個或多個計算機上和/或通過一個或多個處理器執行。
計算機或處理器可以具有一個或多個存儲器存儲裝置(無論是內部還是外部)以永久??地或臨時地保持傳感器數據和/或計算機程序。在一種形式中,獨立計算機運行專用于從儀表化(instrumented)機器、過程或包括生物、測量參數(溫度,壓力等)的其它對象上的傳感器接收傳感器數據的程序。被監測的對象雖然沒有具體限制,但可以是風力農場中的一個或多個風力渦輪機、與海底油井相關的裝備、工業工廠中的一個或多個機器、一個或多個車輛或車輛上的具體機器(例如舉一些示例,噴氣發動機)。傳感器數據可以通過有線或無線地通過計算機網絡或因特網傳送到例如執行數據收集的計算機或數據庫。具有一個或多個處理器的一個計算機或處理器可以執行所有模塊的所有監測任務,或者每個任務或模塊可以具有執行該模塊的其自己的計算機或處理器。因此,將理解,處理可以在單個位置發生,或者處理可以在全部通過有線或無線網絡連接的許多不同位置發生。
系統100從如上所描述的被監測的對象106上的傳感器102接收數據或信號。該數據布置到一個或多個輸入向量132中以供系統100使用。本文中,術語輸入、實際和當前可互換使用,并且術語向量、快照和觀察可互換使用。輸入向量(或例如實際快照)表示在單個時刻被監測的機器的操作狀態。在一個示例中,接收一個輸入向量(VBM)。在另一示例中,接收時間上相關向量序列(SSM)。在一個示例中,非常頻繁地獲得若干傳感器值,而不頻繁地獲得其他傳感器值。換句話說,對于當前時間點,一些傳感器值是明確已知的,而其他傳感器值是未知的。
用戶期望在當前時間點從一個或多個感興趣的傳感器獲得不頻繁(未知)傳感器值的估計。還可能期望在未來的時間點從一個或多個感興趣的傳感器獲得不頻繁(未知)傳感器值的估計。對于這兩個結果,期望知道估計的值的統計不確定性。使用本文描述的方法,可以在輸出接口116確定和呈現此信息給用戶。
輸入向量132可以包括可以或可以不基于傳感器數據(或原始數據)計算的計算的數據。這可以包括例如平均壓力或壓力、溫度、風速、流速和任何其它類型的計算的參數的改變。輸入向量132還可以具有表示未由對象106上的傳感器表示的其他變量的值。這可以是例如接收傳感器數據的一年中的一天的平均環境溫度等。
該系統包括歷史數據存儲110、估計模塊112、告警模塊114和輸出接口116。估計模塊112包括比較模塊122、模型創建模塊124、分布模塊126和分析模塊128。將意識到,可以使用硬件和/或計算機軟件的任何組合來實現任何組件。例如,可以使用在處理裝置上執行的計算機指令來實現任何組件。
在操作中,數據由估計模塊112接收。估計模塊提供估計和估計的精確度范圍。估計和精確度范圍可以是針對當前時間點(如果使用VBM方法),或針對一個或多個未來時間點(如果使用SSM方法)。當滿足某個預定準則時,告警模塊114可以向用戶發送告警。可以在輸出接口116顯示告警,連同估計(以及估計的分布/不確定性)。輸出接口116可以是任何類型的裝置(例如計算機、平板、蜂窩電話、顯示器)上的任何類型的接口(例如,顯示屏,觸摸屏)。
現在轉向估計模塊112的特定操作和結構(如所提到的),并且在一個方面,利用四個模塊122、124、126和128來執行其功能性。將意識到,模塊122、124、126和128可以通過硬件和軟件的任何組合來實現。在一個示例中,使用在諸如微處理器的處理裝置上執行的計算機指令來實現模塊122、124、126和128。
比較模塊122將當前模式或當前模式序列(從接收的輸入向量獲得的)與來自歷史數據存儲的歷史數據進行比較,以獲得最佳匹配的總體。最佳匹配可以是滿足預定標準的那些匹配。例如,可以選擇具有高于某個數值閾值的相似性值的向量。
模型創建模塊124基于最佳匹配的總體創建多個核回歸模型。以下等式和討論用于基于相似性模型(SBM)。SBM是核回歸建模的一種形式。將意識到,也可以利用其他形式的核回歸模型。
本文提到的模型指的是可以被實現或存儲為數據結構的數學關系。根據以下等式,從這些模型做出估計,并且獨立于數據的原點做出估計,其中通過除以從相似性算子創建的“權重”的和來對估計進行歸一化:
(1)
在基于相似性建模的推理(inferential)形式中,從根據下式的輸入和學習的觀察來估計推理的參數向量:
(2)
其中Din具有與xin中的實際傳感器值(或參數)相同數量的行,并且Dout具有與包括所推理的參數或傳感器的參數的總數相同數量的行。
在一種形式中,學習模范(examplar)Da的矩陣可以被理解為包含映射到輸入向量xin中的傳感器值的行和映射到各種傳感器的行的聚合矩陣:
(3)
如之前一樣使用權重的和進行歸一化:
(4)
應當注意,通過用學習模范Da的完整矩陣替換Dout,基于相似性的建模可以同時計算輸入傳感器(自動相關聯形式)和推理的傳感器(推理形式)的估計:
(5)
將意識到,當使用VBM方法時,Xin是單個向量并且Da是二維陣列。對于SSM方法,Xin是時間序列向量陣列,并且Da是時間排序的陣列的集合。這樣創建的模型用于生成估計值。例如,可以針對當前時間點(當使用VBM方法時)或針對未來時間點(當使用SSM方法時)獲得所請求的傳感器的估計。
模型創建模塊124還可以利用修剪算法來除去任何不良執行集體模型。修剪算法在一個方面利用稱為全局相似性的統計量,其在已通過引用整體結合在本文中的美國專利號6,859,739中描述。
分布創建模塊126使用多個核回歸模型生成所請求的傳感器值的至少一個分布。現在簡要地轉到圖2,描述了由本方法利用的統計信息的示例。 x軸具有表示感興趣的傳感器的估計值的各種點。每個點是來自單獨的集體模型的單獨估計。 y軸表示給定間隔(在x軸上)上的點的數量。可以看出,獲得給定x軸間隔中的點的數量或頻率的曲線202,并且在一個方面中是類高斯分布。曲線202具有中值206和標準偏差204。兩個標準偏差表示例如所有估計的90%。因此,在一個示例中,中值估計近似為3.8 +/- 1。
分析模塊128分析所請求的傳感器值的分布,以獲得至少一個分布的中心的測量和至少一個分布的寬度的測量。如所提到的,分布創建模塊126使用由模型創建模塊124獲得的模型來計算估計點的分布,以獲得點。在一個示例中,并且利用VBM方法,利用各種模型來實現估計點。每個估計點可以表示用戶期望的傳感器值的估計。分析模塊128可以計算平均值(即,所有估計的和除以估計的數量)、中值和標準偏差(舉幾個示例)。該信息可以經由輸出接口116提供給用戶。
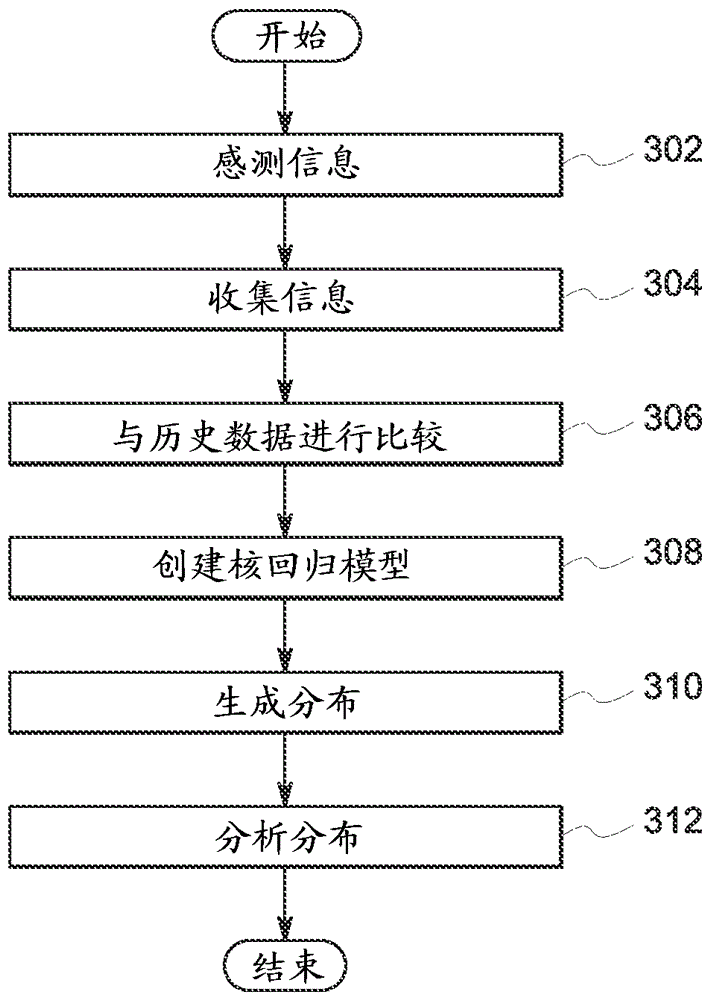
現在參考圖3,描述了一種用于獲得估計的方法。在步驟302,感測表示與實體或過程相關聯的物理參數的信息。
在步驟304,將感測的信息收集到當前模式或當前模式序列中。在步驟306,將當前模式或當前模式序列與歷史數據進行比較,以便獲得最佳匹配的總體。
在步驟308,基于最佳匹配的總體創建多個核回歸模型。在步驟310,使用多個核回歸模型生成用于感興趣的傳感器的估計值的至少一個分布。在步驟312,分析針對感興趣的傳感器的估計值的至少一個分布,以獲得至少一個估計分布的中心的測量和至少一個估計分布的估計分布寬度的測量。
參考圖4,用于獲得估計的設備400包括接口402和處理器404。接口402包括輸入406和輸出408,并且輸入406配置成接收表示與實體或過程相關聯的物理參數的感測的信息。感測的信息被收集到當前模式或當前模式序列410中,
處理器404耦合到接口402。處理器404配置成將當前模式或當前模式序列410與存儲器414中的歷史數據412進行比較,以便獲得最佳匹配的總體。通過“最佳”匹配并且如本文所使用的,意味著滿足或超過給定準則、標準、期望或指南(guideline)的匹配。可以調整準確的準則、標準、期望或指南以適合具體用戶或系統的需要。
處理器404配置成基于最佳匹配的總體創建多個核回歸模型,并使用多個核回歸模型生成感興趣的傳感器的估計值的至少一個分布。
處理器404還配置成分析感興趣的傳感器的估計值的至少一個分布,以獲得至少一個估計分布的中心的測量以及至少一個估計分布的估計分布寬度的測量。處理器404在輸出408呈現至少一個估計分布的中心的測量和至少一個估計分布的估計分布寬度的測量。
提供優于現有方法的商業優點的本方法的應用的一個示例涉及泵輔助的油和氣提取。油井和氣井中的以及電潛泵上的井下傳感器提供對諸如儲層溫度、儲層壓力和泵速度的參數的連續測量,但不提供用于確定提取的油和氣的體積的關鍵井性能參數。在井測試期間以不規則的間隔(最好)測量關鍵性能參數,例如體積流率和水分(即,與從油井產生的總液體的體積相比所產生的水的比率)。通過創建連續傳感器信號和間歇性關鍵性能信號的集體核回歸模型,當沒有執行井測試時(對于當前時間),可以采用相關聯的置信帶估計體積流率和含水率參數。
將意識到,本方法隨機化模型訓練向量的選擇。也就是說,對于給定的模型傳感器集合,獲得包含傳感器值的各種觀察向量。然而,在其他示例中,可隨機化所使用的特征(例如,所使用的傳感器)。也就是說,隨機選擇作為具體集體模型中的變量而包括的傳感器。例如,一個集體模型可以利用來自第一和第二傳感器的數據。在第二集體模型中,可以使用來自另一傳感器群組(第三和第四傳感器)的數據。在第三集體模型中,可以使用來自第三傳感器群組的數據(例如,第一傳感器和第三傳感器)。
如所提到的,本方法使用VBM方法推理當前缺失的測量。在本示例中,這可以是具有+/-范圍的當前值體積流量。在其他方法中,可以根據SSM模型獲得未來測量。例如,將來在兩天和三天的體積流量可以采用+/-范圍估計。
在另一應用中,本方法可以應用于在風力農場中組織的風力渦輪機,以獲得由風力農場中的獨立渦輪機和/或整個風力農場提供的輸出功率的預測。在這些方面,來自農場中的各種渦輪機的歷史風力數據可被存儲并用于創建本文所描述的模型。根據本方法并且在給定的一天,可以在某些時間從風力農場中的某些渦輪機或點(例如,在上午9:00和上午10:00從所有傳感器)取得風速或其他傳感器讀數。使用采用本方法的SSM建模,生成多個模型,并且這些模型被用于生成具體渦輪機的功率輸出的估計和/或可以對于未來的給定時間獲得具有統計公差的整個風力農場的功率輸出(例如,同一天的11:00風力農場將產生99MW +/- 9MW的功率)或對于未來一天獲得連同統計公差的整個風力農場的功率輸出(例如,明天上午11:00風力農場將產生101MW +/- 10MW的功率)。
將意識到,這些僅是應用(其中可以采用和利用本方法)的兩個示例。其他示例是可能的。
本文描述了本發明的優選實施例,包括對發明人已知的用于實施本發明的最佳模式。應當理解,所示的實施例僅僅是示范性的,并且不應當被視為限制本發明的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!