用于圖形處理中的著色器程序執行技術的制作方法
本發明涉及圖形處理系統,且更確切地說,涉及在圖形處理系統中執行著色器程序。
背景技術:
計算裝置通常利用圖形處理單元(GPU)以加速呈現用于顯示的圖形數據。此類計算裝置可以包括例如計算機工作站、移動電話(例如,所謂的智能電話)、嵌入系統、個人計算機、平板計算機和視頻游戲控制臺。GPU通常執行圖形處理管線,所述圖形處理管線包括一起操作以執行圖形處理命令的多個處理級。傳統上,GPU包括固定功能圖形處理管線,其中管道中的每個處理級是通過固定功能硬件(例如,作為硬連線以執行某一組專業化功能且無法執行用戶可下載程序的硬件)實施的。
近年來,圖形處理管線已經轉移到可編程架構,其中管線中的一或多個處理級是可編程處理級并且通過一或多個可編程著色器單元實施。可編程著色器單元中的每一個可經配置以執行著色器程序。用戶應用程序可以在可編程圖形管線中規定待通過可編程處理級執行的著色器程序,由此在現今的GPU的使用中提供更高程度的靈活性。
隨著圖形處理技術的發展,圖形處理管線變得更加精密并且不斷增多的數目的不同類型的可編程處理級被添加到由主要圖形應用程序編程接口(API)規定的標準圖形處理管線。在GPU中通過有限的資源實施這些不同類型的可編程處理級可以帶來相當大的挑戰。
技術實現要素:
本發明描述了用于在圖形處理單元(GPU)中執行著色器程序的技術。著色器程序可以指加載到GPU上并且通過GPU執行的程序,其中一或多個著色器單元包括于GPU中。GPU可以執行著色器程序的多個實例,其中著色器程序的實例中的每一個相對于不同數據項執行相同程序指令。實例數據項可以包括頂點、基元和像素。處理頂點的著色器程序通常經配置以針對通過著色器程序接收的輸入頂點中的每一個產生單個輸出頂點。然而,在一些實例中,本發明的技術可以執行一種著色器程序,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。
執行一種執行頂點著色器處理并且針對由著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序相對于當著色器程序僅用來產生針對每個輸入頂點的單個輸出頂點時需要的數目的線程可以減少處理特定集合的輸入頂點需要的線程的數目。減少用于處理頂點的線程的數目可以減少由GPU使用的處理資源和/或減少GPU的電力消耗。此外,允許執行頂點著色器處理的著色器程序產生針對每個輸入頂點的多個輸出頂點可以改進GPU的編程靈活性。以此方式,可以改進執行可編程頂點處理的GPU的性能、電力消耗和/或編程靈活性。
在一個實例中,本發明描述一種方法,所述方法包括通過圖形處理器的著色器單元執行一種著色器程序,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。
在另一個實例中,本發明描述一種包括圖形處理單元(GPU)的裝置,所述圖形處理單元包括著色器單元,所述著色器單元經配置以執行一種著色器程序,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。
在另一個實例中,本發明描述一種設備,所述設備包括圖形處理器,所述圖形處理器包括著色器單元。所述設備進一步包括用于通過圖形處理器的著色器單元執行著色器程序的裝置,所述著色器程序執行頂點著色器處理并且針對通過著色器程序接收的每個輸入頂點產生多個輸出頂點。
在另一個實例中,本發明描述一種存儲指令的非暫時性計算機可讀存儲媒體,在通過一或多個處理器執行所述指令時使得一或多個處理器通過圖形處理器的著色器單元執行一種著色器程序,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。
在附圖和以下描述中闡述本發明的一或多個實例的細節。本發明的其它特征、對象和優點將從所述描述和圖式以及權利要求書中顯而易見。
附圖說明
圖1是說明可以通過使用本發明的著色器程序執行技術實施的實例圖形管線的概念圖。
圖2是可用于實施本發明的著色器程序執行技術的實例GPU的方塊圖。
圖3是說明可以用于圖2的GPU中的實例著色器單元的方塊圖。
圖4是說明可以使用本發明的實例著色器程序執行技術處理的實例三角形條帶的概念圖。
圖5是說明根據本發明可用于執行合并頂點/幾何著色器程序的多個實例以用于處理圖4中所示的三角形條帶的實例線程配置的概念圖。
圖6是說明根據本發明與執行合并頂點/幾何著色器程序相關聯的實例處理流程的概念圖。
圖7說明根據本發明與執行合并頂點/幾何著色器程序相關聯的偽代碼。
圖8是說明可用于實施本發明的著色器程序執行技術的實例計算裝置的方塊圖。
圖9是說明根據本發明用于執行著色器程序的實例技術的流程圖。
圖10是說明根據本發明根據復制模式和非復制用于執行合并頂點/幾何著色器程序的實例技術的流程圖。
圖11是根據本發明用于選擇復制模式和非復制中的一個以用于執行合并頂點/幾何著色器程序的實例技術的流程圖。
具體實施方式
本發明描述了用于在圖形處理單元(GPU)中執行著色器程序的技術。著色器程序可以指加載到GPU上并且通過GPU執行的程序,其中一或多個著色器單元包括于GPU中。GPU可以執行著色器程序的多個實例,其中著色器程序的實例中的每一個相對于不同數據項執行相同程序指令。實例數據項可以包括頂點、基元和像素。處理頂點的著色器程序通常經配置以針對通過著色器程序接收的輸入頂點中的每一個產生單個輸出頂點。然而,在一些實例中,本發明的技術可以執行一種著色器程序,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。
執行一種執行頂點著色器處理并且針對由著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序相對于當著色器程序僅用來產生針對每個輸入頂點的單個輸出頂點時需要的數目的線程可以減少處理特定集合的輸入頂點需要的線程的數目。減少用于處理頂點的線程的數目可以減少由GPU使用的處理資源和/或減少GPU的電力消耗。以此方式,可以改進執行可編程頂點處理的GPU的性能和/或電力消耗。
此外,允許執行頂點著色器處理的著色器程序產生針對每個輸入頂點的多個輸出頂點可以改進GPU的編程靈活性。通常,頂點著色器編程模型規定頂點著色器程序針對每個輸入頂點被調用一次并且頂點著色器程序產生針對頂點著色器程序的每次調用的單個輸出頂點。本發明的技術可用于實施將針對頂點著色器程序的每次調用產生的允許多個輸出頂點的頂點著色器編程模型。以此方式,可以改進通過GPU執行的可編程頂點處理的靈活性。
在一些實例中,執行頂點著色器處理并且針對通過著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序可以是合并頂點/幾何著色器程序。合并頂點/幾何著色器程序可以指相對于基元相對于頂點和幾何著色器處理可配置以執行頂點著色器處理的著色器程序。幾何著色器程序通常經配置以接收輸入基元并且響應于接收輸入基元輸出0或大于0的輸出基元。因為由幾何著色器程序產生的輸出基元中的每一個可以包括一個以上頂點,所以如果合并頂點/幾何著色器程序針對每個輸入頂點僅產生單個輸出頂點,那么合并頂點/幾何著色器程序的多個實例可能需要針對基元中的每一個執行以便為基元執行幾何著色器處理。然而,執行根據本發明的技術針對由著色器程序接收的每個頂點產生多個輸出頂點的合并頂點/幾何著色器程序在一些實例中可能允許針對基元中的每一個的幾何著色器處理通過每個基元的合并頂點/幾何著色器程序的單個實例執行。
允許幾何著色器處理通過每個基元的合并頂點/幾何著色器程序的單個實例執行可以相對于需要針對每個基元執行的合并頂點/幾何著色器程序的多個實例的技術減少處理特定集合的基元需要的合并頂點/幾何著色器程序的實例的數目。減少用于處理基元的合并頂點/幾何著色器程序的實例的數目可以減少由GPU使用的處理資源、減少通過GPU執行的資源分配的數目和/或減少GPU所消耗的電力。以此方式,可以通過合并頂點/幾何著色器程序改進執行可編程頂點著色和可編程幾何著色的GPU的性能和/或電力消耗。
在一些實例中,用于執行著色器程序的技術可以包括使用非復制模式的執行來執行合并頂點/幾何著色器程序。使用非復制模式的執行來執行合并頂點/幾何著色器程序可以涉及將多個基元中的每一個分配到合并頂點/幾何著色器程序的相應的實例以用于幾何著色器處理,并且使得合并頂點/幾何著色器程序的實例中的每一個通過對應于合并頂點/幾何著色器程序的幾何著色器程序輸出M個頂點,其中M對應于針對每個基元產生的頂點的數目。根據本發明針對通過著色器程序接收的每個輸入頂點產生多個輸出頂點的合并頂點/幾何著色器程序可以在根據非復制模式的執行來執行合并頂點/幾何著色器程序時使用。
相比之下,用于執行合并頂點/幾何著色器程序的復制模式的執行可以涉及分配待處理的基元中的每一個到合并頂點/幾何著色器程序的N個實例,并且使得合并頂點/幾何著色器程序的實例中的每一個輸出單個頂點。在一些實例中,N可以等于對應于合并頂點/幾何著色器程序的幾何著色器程序所規定的最大輸出頂點計數值。
用于執行合并頂點/幾何著色器程序的非復制模式可以使用每個基元的合并頂點/幾何著色器程序的一個實例來執行幾何著色器處理,而用于執行合并頂點/幾何著色器程序的復制模式可以使用每個基元的合并頂點/幾何著色器程序的N個實例來執行幾何著色器處理。因此,使用用于執行合并頂點/幾何著色器程序的非復制模式可以相對于復制模式減少處理特定集合的基元需要的合并頂點/幾何著色器程序的實例的數目。如上文已經論述的,減少用于處理基元的合并頂點/幾何著色器程序的實例的數目可以減少由GPU所使用的處理資源、減少通過GPU執行的資源分配的數目和/或減少GPU所消耗的電力。以此方式,可以通過合并頂點/幾何著色器程序改進執行可編程頂點著色和可編程幾何著色的GPU的性能和/或電力消耗。
在其它實例中,用于在GPU中執行著色器程序的技術可以包括用于允許著色器單元在用于執行合并頂點/幾何著色器程序的非復制模式與用于執行合并頂點/幾何著色器程序的復制模式之間切換的技術。允許著色器單元在用于執行合并頂點/幾何著色器程序的非復制模式與復制模式之間切換可以為圖形處理器的用戶提供額外的控制和/或靈活性以便選擇根據特定處理需求定制的特定執行模式,比如(例如),性能需求、電力消耗需求等。
在額外實例中,用于執行著色器程序的技術可以包括用于在用于執行合并頂點/幾何著色器程序的非復制模式與復制模式之間進行選擇并且使得著色器單元根據所選定的著色器程序執行模式來執行合并頂點/幾何著色器程序的技術。在一些實例中,用于在非復制模式與復制模式之間選擇的技術可以基于存儲與對應于合并頂點/幾何著色器程序的幾何著色器程序的一個應用程序編程接口(API)調用相關聯的輸出頂點所需要的存儲空間的總量和/或基于對應于合并頂點/幾何著色器程序的通過幾何著色器程序執行的頂點放大的量在非復制模式與復制模式之間進行選擇。
一般來說,用于在著色器單元中存儲輸出頂點的存儲空間(例如,通用注冊(GPR))的量可以是有限的。因為用于執行合并頂點/幾何著色器程序的非復制模式允許多個頂點由合并頂點/幾何著色器程序的實例中的每一個產生,所以存儲用于非復制模式的輸出頂點需要的存儲空間的量可以大于復制模式需要的存儲空間的量。如果包括于著色器單元中的存儲空間的量并不足以存儲用于待并行地執行的合并頂點/幾何著色器程序的示例的給定集合的輸出頂點,那么可能需要執行外部存儲器存取,這可能會顯著降低著色器單元的性能。
如上文所論述,用于執行合并頂點/幾何著色器程序的非復制模式可以提供更好的性能和/或減小的電力消耗以用于并行地執行合并頂點/幾何著色器程序的示例的給定集合。然而,如果與執行合并頂點/幾何著色器程序的示例的集合相關聯的輸出頂點存儲空間需求大于在著色器單元中可供使用的輸出頂點存儲空間的量,那么通過不復制幾何著色器處理獲得的性能和/或電力改進可能被由外部存儲器存取引起的性能的減少超過。
因此,如果用于存儲輸出頂點的存儲空間需求相對較小(例如,如果輸出頂點存儲空間需求小于或等于包含于著色器單元中的輸出頂點存儲空間的量),那么用于執行合并頂點/幾何著色器程序的非復制模式可以提供更好的性能和/或減小的電力消耗。另一方面,如果用于存儲輸出頂點的存儲空間需求相對較高(例如,如果,輸出頂點存儲空間需求大于包含于著色器單元中的輸出頂點存儲空間的量),那么用于執行合并頂點/幾何著色器程序的復制模式可以提供更好的性能。
在基于存儲與幾何著色器程序的一個API調用相關聯的輸出頂點所需要的存儲空間的總量和/或基于通過幾何著色器執行的頂點放大的量在非復制模式與復制模式之間進行選擇可以允許圖形系統在存儲輸出頂點需要的存儲空間的量相對較小時使用用于執行合并頂點/幾何著色器程序的非復制模式,并且在存儲輸出頂點需要的空間的量相對較大時使用用于執行合并頂點/幾何著色器程序的復制模式。以此方式,可以獲得用于具有相對較小輸出頂點存儲裝置需求的著色器程序的使用非復制模式的益處同時避免在著色器單元的存儲空間不足以存儲與著色器程序相關聯的輸出頂點的情況下與外部存儲器存取相關聯的性能缺點。
在其它實例中,用于執行著色器程序的技術可以包括用于產生針對合并頂點/幾何著色器程序的編譯代碼的技術,其中編譯代碼包括使得著色器單元基于待用于執行著色器程序的模式的信息指示根據非復制模式或復制模式選擇性地執行合并頂點/幾何著色器程序的指令。將指令放置在用于能夠選擇性地執行任一模式的合并頂點/幾何著色器程序的編譯代碼中可以允許著色器單元的處理模式發生改變而無需將新的著色器程序重新加載到著色器單元中。此外,將指令放置在用于能夠選擇性地執行任一模式的合并頂點/幾何著色器程序的編譯代碼中也可以簡化合并頂點/幾何著色器程序的編譯。
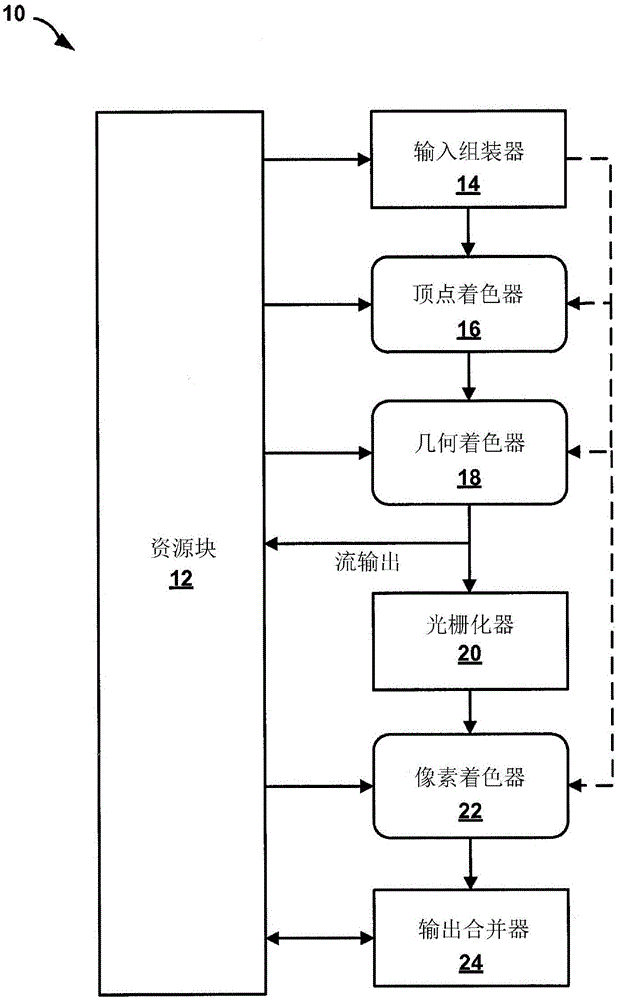
圖1是說明可以通過使用本發明的著色器程序執行技術實施的實例圖形管線10的概念圖。在一些實例中,圖形管線10可對應于DirectX(DX)10圖形管線。在其它實例中,圖形管線10可以對應于棋盤形布置停用的DX 11圖形管線。
圖形管線10經配置以將一或多個圖形基元呈現為呈現目標。圖形管線10包括資源塊12、輸入組裝器14、頂點著色器16、幾何著色器18、光柵化器20、像素著色器22和輸出合并器24。
資源塊12對應于由圖形管線10中的管線級使用的一或多個存儲器資源,比如(例如)一或多個紋理和/或一或多個緩沖器(例如,頂點緩沖器、幀緩沖器等)。圖1中以直拐角所描繪的處理級表示固定功能處理級,且圖1中以圓形拐角所描繪的處理級表示可編程處理級。舉例來說,如圖1中所示,輸入組裝器14、光柵化器20和輸出合并器24是固定功能處理級,并且頂點著色器16、幾何著色器18和像素著色器22是可編程處理級。
可編程處理級可以指其經配置以執行程序(例如,著色器程序)的處理級,所述程序由通過使用GPU的主機裝置實施圖形管線10的GPU限定、編譯和/或加載到所述GPU上。在一些情況下,程序可以由在主機裝置上執行并且通過在主機裝置上執行的GPU驅動程序加載到GPU上的用戶水平圖形應用程序限定。固定功能處理級可以包括經配置以從主機裝置接收和執行程序的硬件。包括于固定功能處理級中的硬件可以是硬連線的以執行某些功能。雖然包括于固定功能處理級中的硬件可以是可配置的,但是硬件的可配置性是基于一或多個控制信號的,這與基于程序(例如,著色器程序)的相反。
圖形管線10中所示的可編程級中的每一個可經配置以執行特定類型的著色器程序。舉例來說,頂點著色器16可經配置以執行頂點著色器程序,幾何著色器18可經配置以執行幾何著色器程序,并且像素著色器22可經配置以執行像素著色器程序。
實施圖形管線10的GPU可以包括一或多個著色器單元,這些著色器單元經配置以執行不同類型的著色器程序。不同類型的著色器程序中的每一個可以在GPU的實施圖形管線10的共用著色器單元上和/或在專用于執行一或多個特定類型的著色器程序的一或多個專用著色器單元上執行。
在一些實例中,頂點著色器程序和幾何著色器程序可以合并到合并頂點/幾何著色器程序中并且實施圖形管線10的GPU中的著色器單元可以執行合并頂點/幾何著色器程序,如稍后在本發明中進一步詳述描述的。在此類實例中,著色器單元可以在一些實例中進一步經配置以在合并頂點/幾何著色器程序并不在著色器單元上執行時將像素著色器程序作為單獨程序執行。
現在將描述圖形管線10的一般操作。圖形管線10響應于接收指示一或多個待呈現的繪制調用命令和數據開始呈現基元的集合。指示待呈現的基元的數據可包括例如一或多個頂點緩沖器、一或多個指數緩沖器和/或指示待呈現的類型的基元的一或多個狀態配置。在一些實例中,頂點緩沖器和/或指數緩沖器可以存儲在資源塊12中。
輸入組裝器14可以從資源塊12中檢索一或多個頂點、基于頂點形成幾何形狀(例如,基元),并且將頂點發布到頂點著色器16以用于進一步處理。輸入組裝器14也可以為頂點中的每一個產生一或多個系統產生值并且將所述系統產生值供應到頂點著色器16和/或幾何著色器18。舉例來說,輸入組裝器14可以產生唯一地識別特定繪制調用中的頂點中的每一個的頂點識別值并且將所述頂點識別值供應到頂點著色器16和/或幾何著色器18。作為另一實例,輸入組裝器14可以產生唯一地識別特定繪制調用中的基元中的每一個的基元識別值,并且將基元識別值供應到幾何著色器18。
頂點著色器16可以基于從輸入組裝器14接收的頂點且基于頂點著色器程序產生輸出頂點。從編程的觀點來看,為了產生輸出頂點,頂點著色器16可以針對從輸入組裝器14接收的頂點中的每一個執行頂點著色器程序的相應的實例。在一些實例中,頂點著色器程序可以在輸入頂點上執行每個頂點處理以產生輸出頂點。每個頂點處理可以指獨立地針對于被處理的頂點中的每一個執行的處理。每個頂點處理可包括例如執行頂點變換、執行照明操作、執行霧操作、執行頂點著色等。
幾何著色器18可以基于通過幾何著色器18接收的輸入基元且基于幾何著色器程序產生輸出基元。通過幾何著色器18接收的輸入基元可以基于由頂點著色器16產生的輸出頂點形成。從編程的角度,為了產生輸出基元,幾何著色器18可以執行幾何著色器程序的相應的實例以用于通過幾何著色器18接收的基元中的每一個。在一些實例中,幾何著色器程序可以在輸入基元上執行每個基元處理以產生輸出基元。每個基元處理可以指獨立地針對于被處理的基元中的每一個執行的處理。每個基元處理可包括例如添加或刪除頂點、添加或刪除由幾何著色器18輸出的用于每個輸入基元的數目的基元等。
光柵化器20可以基于從幾何著色器18接收的基元產生源像素。舉例來說,對于從幾何著色器18接收的基元中的每一個,光柵化器20可以光柵化基元以產生對應于基元的多個源像素。光柵化基元可以涉及例如在基元上執行掃描轉換以基于基元的頂點的屬性確定哪些像素對應于基元和/或用于對應于基元的像素的插入屬性。
像素著色器22可以基于從光柵化器20接收的輸入源像素像素且基于像素著色器程序產生輸出源像素。從編程的角度,為了產生輸出源像素,像素著色器22可以執行像素著色器程序的相應的實例以用于從光柵化器20接收的像素中的每一個。在一些實例中,像素著色器程序可以在輸入源像素上執行每像素處理以產生輸出源像素。每像素處理可以指獨立地針對于被處理的像素中的每一個執行的處理。每像素處理可包括例如執行像素著色、執行紋理映射等。
輸出合并器24可以基于從像素著色器22接收的源像素產生目的地像素。在一些實例中,輸出合并器24可以合并從像素著色器22接收的源像素中的每一個與存儲在呈現目標中的對應的目的地像素以產生對應的目的地像素的更新版本。如果目的地像素在呈現目標中具有與源像素的像素位置相同的像素位置,那么目的地像素可以對應于源像素。為了合并源像素與目的地像素,輸出合并器24可以相對于待合并的源像素和目的地像素執行混合操作、合成操作和光柵操作中的一或多個。
所得目的地像素存儲在呈現目標中,呈現目標在一些實例中,可以是幀緩沖器。呈現目標可以形成資源塊12的一部分。存儲在呈現目標中的數據可以對應于通過圖形管線10接收的基元的光柵化的合成版本。
如上文所論述,從編程的角度(例如,從API的角度),頂點著色器程序通常針對每個傳入頂點通過圖形管線調用一次并且經配置以為每個調用產生一個輸出頂點。像素著色器程序通常為每個傳入像素調用一次并且經配置以為每個調用產生一個輸出像素。幾何著色器程序通常為每個傳入基元(例如,點、線、三角形)調用一次,并且經配置以為每個調用產生零、一個、兩個或大于兩個輸出基元。
圖形管線10的可編程著色器級通常在GPU上通過一或多個著色器單元實施。著色器單元中的每一個可以包括并行執行用于特定著色器程序的多個線程的多個處理元件(例如,算術邏輯單元(ALU))。在一些情況下,著色器單元可以是單個指令、多個數據(SIMD)著色器單元,其中著色器單元中的處理元件中的每一個同時相對于不同數據執行著色器程序的相同指令。
時常,相同組的著色器單元可以實施包括于圖形管線10中的多個不同類型的著色器級。在幾何著色器的研發之前,圖形呈現管線中的唯一的可編程處理級通常是頂點著色器和像素著色器。頂點著色器和像素著色器在單個輸入/單個輸出編程接口下操作,其中單個輸入頂點或像素是針對每個著色器調用接收的并且單個輸出頂點或像素是針對每個著色器調用產生的。針對頂點著色器和像素著色器這兩者的單個輸入/單個輸出編程接口允許兩種類型的著色器通過共用的單個輸入/單個輸出硬件接口在共用硬件著色器單元上執行。
然而,用于著色器單元的單個輸入/單個輸出硬件接口的一個缺點在于此類接口并不允許頂點著色器程序產生每調用的多個頂點。這限制了可以針對圖形呈現API實施的頂點著色器編程模型的靈活性。
用于著色器單元的單個輸入/單個輸出硬件接口的另一缺點在于幾何著色器并不符合此類接口。更確切地說,幾何著色器經配置以針對通過幾何著色器接收的每個輸入基元輸出任何數目的基元(在規定限制內),并且所述基元中的每一個可以包括任何數目的頂點。因此,幾何著色器并不符合單個輸入/單個輸出編程接口。這使得通過頂點著色器和/或像素著色器在實施單個輸入/單個輸出硬件接口的共用硬件著色器單元上執行幾何著色器是困難的。
解決幾何著色器編程接口不符合單個輸入/單個輸出硬件接口的困難的一個解決方案是將頂點和幾何著色器程序合并到單個合并頂點/幾何著色器程序中并且執行合并頂點/幾何著色器程序作為共用著色器線程的一部分。合并頂點/幾何著色器程序可以包括頂點著色器功能,所述頂點著色器功能通過頂點著色器程序規定,隨后是通過幾何著色器程序規定的幾何著色器功能。合并頂點/幾何著色器程序可以進一步包括插入在頂點著色器功能與幾何著色器功能之間的補丁代碼以適當地管理由頂點著色器功能產生的輸出數據項以及由幾何著色器功能接收的輸入數據項。
為了允許合并頂點/幾何著色器程序在上述實例中實施單個輸入/單個輸出接口,可以針對待執行幾何著色器處理的基元中的每一個例示合并頂點/幾何著色器程序的多個實例,并且合并頂點/幾何著色器程序的實例中的每一個可經配置以接收單個頂點并且輸出單個頂點。由合并頂點/幾何著色器的多個實例產生的輸出頂點的集合可以共同地對應于由合并頂點/幾何著色器程序實施的幾何著色器級的一個API示例產生的輸出基元的頂點。
舉例來說,對于通過圖形處理管線處理的輸入基元中的每一個,合并頂點/幾何著色器程序可以例示N次,其中N等于通過對應于合并頂點/幾何著色器程序的幾何著色器程序規定的每個基元的最大數目的輸出頂點。通過幾何著色器程序規定的輸出頂點中的不同的一個可以通過不同示例中的每一個發出使得合并頂點/幾何著色器程序的總共N個示例輸出由對應于合并頂點/幾何著色器程序的幾何著色器程序限定的全部的輸出頂點。因為在此實例中合并頂點/幾何著色器程序的示例中的每一個接收單個輸入頂點并且輸出單個輸出頂點,所以合并頂點/幾何著色器可以在實施單個輸入/單個輸出硬件接口的著色器單元上執行。
圖形API(比如(例如)DX 10和DX 11)限定幾何著色器級作為針對每個傳入基元執行一次的級。然而,對于上文所述的合并頂點/幾何著色器程序執行技術,可以針對每個傳入基元執行合并頂點/幾何著色器程序的N個不同實例。換句話說,針對幾何著色器的每個API調用,幾何著色器處理有效地復制N次。因此,用于執行合并頂點/幾何著色器的上文描述的技術可被稱為用于執行合并頂點/幾何著色器的復制模式。
用于執行合并頂點/幾何著色器的復制模式的一個缺點在于通過幾何著色器處理執行的計算可以針對合并頂點/幾何著色器程序的每個示例重復。舉例來說,在一些情況下,用于合并頂點/幾何著色器程序的幾何著色器處理可以包含程序控制環路使得輸出頂點以特定次序得到計算,并且在一些實例中,用于合并頂點/幾何著色器程序的幾何著色器處理可以使用瀑布機制操作。在使用瀑布機制時,對于合并頂點/幾何著色器程序的給定示例,用于幾何著色器功能的程序控制環路可以針對輸出頂點中的每一個執行直至計算待由特定示例發出的特定頂點為止。在計算通過特定示例發出的頂點之后,用于幾何著色器處理的控制流可以中止執行控制環路。
換句話說,在使用瀑布機制時,合并頂點/幾何著色器程序的第一實例可以執行用于幾何著色器功能的程序控制環路一次并且輸出對應于控制環路的單個迭代的頂點,合并頂點/幾何著色器程序的第二實例可以執行用于幾何著色器功能的程序控制環路兩次并且輸出對應于控制環路的第二迭代的頂點,合并頂點/幾何著色器程序的第三實例可以執行用于幾何著色器功能的程序控制環路三次并且輸出對應于控制環路的第三迭代的頂點等。
使用瀑布機制可以減少當合并頂點/幾何著色器的多個實例針對每個基元例示時發生的重復計算中的一些,但是此類機制仍會引起重復計算。舉例來說,通過幾何著色器功能計算的第一頂點將被計算N次,第二頂點將被計算N-1次等。頂點的此類重復計算可以降低著色器單元的效率和/或增加著色器單元的電力消耗。
用于執行合并頂點/幾何著色器的復制模式的另一缺點在于需要針對幾何著色器的每個調用分配資源(例如,通用寄存器(GPR))引起重復的資源分配。重復的資源分配也可以降低著色器單元的效率和/或增加著色器單元的電力消耗。
用于執行合并頂點/幾何著色器的復制模式的另一缺點在于此類模式并不能夠重復使用由多個基元共享的頂點以便降低頂點著色器的處理需求。不允許頂點重復使用可能增加電力消耗和/或增加存儲器帶寬使用。
根據本發明的一些方面,描述了用于執行著色器程序的技術,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。多個輸出頂點可以基于包含于著色器程序中的程序指令產生。舉例來說,執行一種執行頂點著色器處理并且針對由著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序可以允許幾何著色器處理通過合并頂點/幾何著色器程序執行而無需針對幾何著色器的每個API調用跨越執行的多個線程的幾何著色器處理的復制。
舉例來說,可以調用合并頂點/幾何著色器程序的單個實例以針對幾何著色器的每個API調用執行幾何著色器處理而不是如上文相對于復制模式所論述的N個頂點/幾何著色器實例。合并頂點/幾何著色器程序的單個實例可以發出N個頂點,其中N是由對應于合并頂點/幾何著色器程序的幾何著色器程序限定的輸出頂點的數目。由合并頂點/幾何著色器的單個實例產生的N個輸出頂點可以共同地對應于由合并頂點/幾何著色器程序實施的幾何著色器級的一個API示例產生的輸出基元的頂點。以此方式,合并頂點/幾何著色器可以通過著色器單元執行而無需跨越多個執行線程的幾何著色器處理的復制。因為可以調用單個頂點/幾何著色器實例以針對幾何著色器的每個API調用執行幾何著色器處理,所以執行合并頂點/幾何著色器的此模式可被稱為用于執行合并頂點/幾何著色器的非復制模式。
允許合并頂點/幾何著色器通過著色器單元執行而無需復制幾何著色器處理可以減少幾何著色器的每API調用需要的ALU計算的數目、減少通過幾何著色器的每API調用的GPU消耗的資源的數目,和/或減少針對幾何著色器的每個API調用需要發生的資源分配的數目。以此方式,可以改進GPU的性能和/或可以減小GPU的電力消耗。
另外,允許合并頂點/幾何著色器通過著色器單元執行而無需幾何著色器功能的復制可以允許頂點重復使用發生在共享一或多個頂點的基元之間。允許共享頂點重復使用可以節省存儲器帶寬和/或降低電力消耗。
此外,執行針對通過著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序可以增加用于圖形API的頂點著色器編程模型的靈活性。通常,頂點著色器編程模型規定頂點著色器程序針對每個輸入頂點被調用一次并且頂點著色器程序產生針對頂點著色器程序的每次調用的單個輸出頂點。然而,執行一種執行頂點著色器處理并且針對每個輸入頂點產生多個輸出頂點的著色器程序可用于實施允許針對頂點著色器程序的每個調用產生多個輸出頂點的頂點著色器編程模型。以此方式,可以改進通過GPU執行的可編程頂點處理的靈活性。
圖2是可用于實施本發明的著色器程序執行技術的實例圖形處理單元(GPU)30的方塊圖。GPU 30經配置以基于從主機裝置(例如,主中央處理單元(CPU))接收的圖形命令、狀態信息和著色器程序執行圖形處理。GPU 30可以是圖形處理器的實例并且替代地被稱作圖形處理器。GPU 30包括命令引擎32和處理單元34。
在一些實例中,處理單元34中的一或多個可以是可配置的以形成三維(3D)圖形呈現管線。舉例來說,處理單元34中的一或多個可以是可配置的以實施在圖1中說明的圖形管線10。
命令引擎32和處理單元34可以包括專用硬件單元、固件、軟件、著色器單元、處理器和處理元件的任何組合,所述組件經配置以執行歸于此類組件的功能。在一些實例中,GPU 30可經配置以執行指令,所述指令使得GPU 30的一或多個處理器執行本發明中描述的技術中的任一者的全部或部分。
命令引擎32可以從主機裝置接收命令和圖形數據、基于所述命令管理GPU 30的狀態,并且控制處理單元34的操作以基于所述命令呈現圖形數據。舉例來說,響應于接收繪制調用命令,命令引擎32可以控制處理單元34的操作使得處理單元34實施圖形呈現管線(例如,圖1中的圖形管線10),并且使得圖形數據經由圖形呈現管線被呈現到呈現目標中。作為另一實例,命令引擎32可以從主機裝置接收一或多個著色器程序、接收指示GPU 30將著色器程序加載到GPU 30的一或多個命令上,并且使得著色器程序被加載到和/或存儲在與GPU 30中的一或多個著色器單元相關聯的指令高速緩存中。
處理單元34中的每一個可以是可編程處理單元或固定功能處理單元。可編程處理單元可以指經配置以執行程序(例如,著色器程序)的處理單元,所述程序通過使用GPU 30的主機裝置由GPU 30限定、通過GPU 30編譯和/或加載到GPU 30上。固定功能處理單元可以包括并非經配置以從主機裝置接收和執行程序的硬件。雖然包括于固定功能處理級中的硬件可以是可配置的,但是硬件的可配置性是基于一或多個控制信號的,這與基于程序(例如,著色器程序)的相反。
如圖2中所示,處理單元34包括線程調度器36和著色器單元38。在一些實例中,線程調度器36可以是固定功能處理單元。雖然未在圖2中特定地示出,但是處理單元34可以包括可用于實施圖形呈現管線的全部或部分的其它固定功能和/或可編程處理單元。舉例來說,處理單元34可以包括經配置以在圖1的圖形管線10中實施輸入組裝器14、光柵化器20和輸出合并器24的固定功能處理單元。
著色器單元38中的每一個可以是可編程處理單元。在一些實例中,著色器單元38可以實施圖形呈現管線的著色器級中的一或多個。舉例來說,著色器單元38可以實施圖1中所示的圖形管線10的頂點著色器16、幾何著色器18和/或像素著色器22。在一些實例中,著色器單元38的全部或一個子集可以是經配置以僅執行通過圖形呈現管線實施的特定的類型的著色器程序。在其它實例中,著色器單元38的全部或一個子集可以是經配置以執行通過圖形呈現管線實施的著色器程序的類型的全部或一個子集。
線程調度器36經配置以控制著色器程序線程如何在著色器單元38上執行。著色器單元38中的每一個可經配置以執行從主機裝置加載到GPU 30上的著色器程序。著色器程序可以指通過GPU 30的可編程處理級執行的程序。在一些情況下,著色器程序可以由在主機裝置上執行并且通過主機裝置加載到GPU 30上的用戶水平圖形應用程序限定。在額外的情況中,著色器程序可以是寫入在高水平著色語言中的源代碼著色器程序的編譯版本,所述高水平著色語言比如(例如)高級著色語言(HLSL)、OpenGL著色語言(GLSL)、用于圖形的C(Cg)著色語言等。
線程調度器36可以接收指示待由一或多個著色器程序處理的一或多個數據項的信息、確定用于處理數據項的線程配置,并且使得著色器單元38執行一或多個線程以用于基于線程配置處理數據項。數據項可包括例如待通過著色器程序(例如,頂點著色器程序)處理的一或多個頂點、待通過著色器程序(例如,幾何著色器程序)處理的一或多個基元和/或待通過著色器程序(例如,合并頂點/幾何著色器程序)處理的一或多個頂點和一或多個基元。
線程可以指通過著色器單元38中的一個執行的著色器程序的實例(例如,通過包括于著色器單元中的多個處理元件中的一個執行)。特定著色器程序的實例中的每一個可以相對于潛在地不同的數據項執行相同指令。舉例來說,頂點著色器程序的實例中的每一個可以相對于多個頂點中的相應一個執行相同指令。作為另一實例,幾何著色器程序的實例中的每一個可以相對于多個基元中的相應一個執行相同指令。作為另一個實例,合并頂點/幾何著色器程序的實例中的每一個可以相對于多個頂點中的相應一個和多個基元中的相應一個中的一或兩個執行相同指令。在一些情況下,通過合并頂點/幾何著色器程序的實例的子集執行的個體頂點和/或基元可以是相同的。
線程配置可以包括將待通過特定著色器程序處理的數據項分配到由一或多個著色器單元38執行的著色器程序的相應的線程(例如,實例)的信息。舉例來說,對于頂點著色器程序,線程配置可以包括將多個頂點中的相應一個分配到待由一或多個著色器單元38執行的線程中的每一個的信息。作為另一實例,對于幾何著色器程序,線程配置可以包括將多個基元中的相應一個分配到待由一或多個著色器單元38執行的線程中的每一個的信息。作為另一個實例,對于合并頂點/幾何著色器程序,線程配置可以包括將多個頂點中的相應一個和/或多個基元中的相應一個分配到待由一或多個著色器單元38執行的線程中的每一個的信息。舉例來說,合并頂點/幾何著色器程序可以被分配到頂點和基元這兩者,僅分配到頂點或僅分配到基元。
為了使得著色器單元38中的一個基于線程配置執行線程,線程調度器36可以將指示線程配置的信息提供到著色器單元。指示線程配置的信息可以包括指示將待通過特定著色器程序處理的數據項分配到待通過著色器單元執行的著色器程序的相應的線程的信息。數據項可以包括頂點、基元和/或像素。
著色器單元38中的每一個可經配置以接收指示用于處理一或多個數據項的線程配置的信息,并且基于從線程調度器36接收的指示線程配置的信息相對于數據項執行著色器程序的多個實例。在一些實例中,著色器單元38中的每一個可以進一步經配置以基于待通過相應的著色器單元執行的著色器程序和/或基于線程配置在相應的著色器單元中分配寄存器。
波可以指提交到著色器單元38中的一個以通過通過著色器單元并行地執行的一組線程。換句話說,包括于波中的線程可以在著色器單元上同時執行。波中的線程中的每一個可以對應于相同著色器程序的多個實例中的相應一個。在一些實例中,波中的線程中的每一個可被稱為光纖。波的大小可以指包括于波中的纖維的數目。
在著色器單元38中的一個包括多個單個指令、多數據(SIMD)處理元件的實例中,著色器單元可以執行波使得波中的纖維中的每一個在多個SIMD處理元件中的相應的一個上執行。在此類實例中,著色器單元中的SIMD處理元件的數目可以大于或等于通過著色器單元執行的波的大小(即,波中的纖維的數目)。
在一些實例中,為了通過著色器程序確定用于處理數據項的特定集合的線程配置,線程調度器36可以確定用于處理數據項的集合的波配置。波配置可以包括將待通過特定著色器程序處理的數據項分配到包括于線程的波中的相應的線程以在著色器單元38中的一個上并行地執行相應的線的信息。在此類實例中,指示通過線程調度器36提供到著色器單元的線程配置的數據可以包括指示用于處理數據項的集合的波配置的數據。
在一些實例中,線程調度器36和/或著色器單元38可經配置以執行本發明中描述的技術中的一些或全部。舉例來說,線程調度器36可經配置以根據本發明的技術確定線程配置和/或波配置。作為另一實例,著色器單元38中的每一個可經配置以根據本發明的技術執行提交到相應的著色器單元的一或多個線程和/或波。在相對于圖3描述著色器單元38中的一個的實例之后稍后將在本發明中描述考慮線程調度器36和著色器單元38如何操作的進一步的細節。
圖3是說明可以用于圖2的GPU中的實例著色器單元40的方塊圖。在一些實例中,著色器單元40可以對應于圖2中所示的著色器單元38中的一個。著色器單元40經配置以基于指示線程配置的信息執行一或多個不同類型的著色器程序。著色器單元40包括控制單元42、指令存儲裝置44、處理元件46A-46H(統稱為“處理元件46”)、寄存器48和本地存儲器50。
控制單元42可以接收指示用于處理數據項的線程配置的信息,和并且使得一或多個線程基于著色器程序并且基于指示線程配置的信息在處理元件46上執行。著色器程序可以存儲在指令存儲裝置44中。舉例來說,數據項可以存儲在寄存器48、本地存儲器50和/或外部存儲器中。在一些實例中,控制單元42可以進一步經配置以基于待通過著色器單元40執行的著色器程序和/或基于線程配置將寄存器48分配到處理元件46A-46H。
指令存儲裝置44經配置以存儲待通過著色器單元40執行的一或多個著色器程序(例如,著色器程序指令)的全部或部分。指令存儲裝置44可以是任何類型的存儲單元包括,例如,易失性存儲器、非易失性存儲器、高速緩存、隨機存取存儲器(RAM)、靜態RAM(SRAM)、動態RAM(DRAM)等。當指令存儲裝置44是高速緩存時,指令存儲裝置44可以高速緩存存儲于著色器單元40外部的存儲器中的一或多個著色器程序。雖然將指令存儲裝置44說明為在著色器單元40的內部,但在其它實例中,指令存儲裝置44可在著色器單元40外部。
處理元件46經配置以執行著色器程序的線程。處理元件46中的每一個可執行不同線程。線程可以指相對于針對線程特定的數據項執行的著色器程序的實例。因此,處理元件46中的每一個可稱為相對于潛在地不同的數據項執行著色器程序的實例。在共同時間點在處理元件46A-46H上并行地執行的線程的集合可被稱為線程波。
在圖3的實例著色器單元40中,處理元件46可為單指令多數據(SIMD)處理元件。SIMD處理元件指代當經激活時經配置以相對于不同數據同時執行同一指令的處理元件。這樣可以允許處理元件46相對于不同數據項并行執行著色器程序的多個線程。在一些情況下,處理元件46中的每一個可以基于指向指令存儲裝置44中包含的指令的共用程序計數器執行著色器程序的指令。
如果處理元件46中的一或多個經去激活,那么這些處理元件46在給定指令周期中并不執行程序指令。在一些情況下,控制單元42可解除激活處理元件46中的一或多個以實施條件性分支指令,其中分支條件對于一些線程得到滿足且對于其它線程得不到滿足。
在一些實例中,處理元件46中的每一個可以包括和/或對應于算術邏輯單元(ALU)。在其它實例中,處理元件46中的每一個可以實施ALU功能性。ALU功能性可以包括添加、減去、倍增等。在額外實例中,處理元件46中的每一個可以是標量ALU或向量ALU。標量ALU可在標量數據項上操作,且向量ALU可在向量數據項上操作。標量數據項可以包括對應于標量的單個分量的單個值。向量數據項可以包括對應于向量的多個分量的多個值。在其中處理元件46是標量ALU的實例中,如果向量數據項通過著色器單元40處理,那么在一些實例中,向量的組分中的每一個可以通過處理元件46的子集并行處理。舉例來說,處理元件46A、46B、46C和46D可以并行處理四組分向量。
處理元件46中的每一個可以從指令存儲裝置44中讀取指令和/或從寄存器48、本地存儲器50和外部存儲器中的一或多個中讀取數據項。處理元件46中的每一個可將輸出數據寫入到寄存器48、本地存儲器50和外部存儲器中的一或多個。
寄存器48可以被動態地分配到各種處理元件46。在一些情況下,寄存器48中的一些或全部可以充當輸入寄存器和/或輸出寄存器以用于在著色器單元40上執行的各種線程。輸入寄存器可以指存儲用于著色器程序的輸入數據項(例如,輸入頂點、輸入基元)的寄存器,并且輸出寄存器可以指存儲輸出數據項(例如,輸出頂點、輸出基元)的寄存器以用于著色器程序。
本地存儲器50可以是任何類型的存儲器包括例如易失性存儲器、隨機存取存儲器(RAM)、靜態RAM(SRAM)、動態RAM(DRAM)等。在一些實例中,用于本地存儲器50的地址空間可以是對包括于著色器單元40中的處理元件46為本地的。換句話說,GPU 30的其它著色器單元和/或其它部分可能無法直接存取本地存儲器50。類似地,主機裝置可能無法直接地存取本地存儲器50。在一些實例中,本地存儲器50可以在與著色器單元40和/或GPU 30相同的芯片上實施。
現在將描述線程調度器36和著色器單元40的一般操作。GPU 30(例如,命令引擎32)將著色器程序加載到指令存儲裝置44中或加載到指令存儲裝置44可訪問的存儲空間中。線程調度器36接收指示一或多個數據項的信息以通過著色器程序處理、確定相對于數據項用于執行著色器程序的線程配置,并且提供指示線程配置的信息到著色器單元40。線程配置可以規定數據項中的每一個到待通過著色器單元40執行的著色器程序的一或多個實例的分配。著色器程序的實例中的每一個可經配置以相對于分配到著色器程序的相應的實例的數據項執行著色器處理(例如,執行著色器程序的指令)。
控制單元42接收指示線程配置的信息,并且使得處理元件46A-46H基于線程配置執行著色器程序的一或多個實例。為了使得處理元件46A-46H基于線程配置執行著色器程序的一或多個實例,控制單元42可以在執行著色器程序實例之前用與待執行的線程相關聯的輸入數據項(例如,輸入頂點)來加載處理元件46A-46H的輸入寄存器。舉例來說,一或多個輸入寄存器可以被分配到處理元件46A-46H中的每一個,并且對于待執行的著色器程序的實例中的每一個,控制單元42可以用待通過相應的著色器實例執行的輸入數據項來加載對應于相應的著色器實例的輸入寄存器。以此方式,可以通過著色器單元40執行著色器程序的多個實例。
根據本發明,著色器單元40可經配置以執行著色器程序,所述著色器程序執行頂點著色器處理并且針對由著色器程序接收的每個輸入頂點產生多個輸出頂點。舉例來說,著色器單元40可以執行著色器程序的多個實例使得著色器程序的實例中的每一個接收多個輸入頂點中的相應一個并且響應于接收多個輸入頂點中的相應一個產生多個輸出頂點。著色器程序的實例中的每一個可以通過處理元件46A-46H中的相應一個執行。
在一些實例中,針對通過著色器程序接收的輸入頂點中的每一個產生多個輸出頂點執行著色器程序可以允許用于執行針對輸入頂點的特定集合的著色器程序的處理元件46A-46H的數目減少。減少用于執行著色器程序的處理元件46A-46H的數目可以減少由GPU 30使用的處理資源和/或減少通過GPU 30消耗的電力。以此方式,可以改進GPU 30的性能和/或電力消耗。
此外,在其它實例中執行針對通過著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序可用于實施頂點著色器編程模型,所述頂點著色器編程模型允許多個輸出頂點針對頂點著色器程序的每個調用產生。通常,頂點著色器編程模型規定頂點著色器程序針對每個輸入頂點被調用一次并且頂點著色器程序產生針對頂點著色器程序的每次調用的單個輸出頂點。實施允許多個輸出頂點針對頂點著色器程序的每個調用產生的頂點著色器編程模型可以增加可以由圖形程序員使用的頂點著色器編程的靈活性。
另外,在其它實例中,執行針對通過著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序允許針對待通過每個基元的合并頂點/幾何著色器程序的單個實例執行的基元中的每一個的幾何著色器處理。允許幾何著色器處理通過每個基元的合并頂點/幾何著色器程序的單個實例執行可以相對于需要針對每個基元執行的合并頂點/幾何著色器程序的多個實例的技術減少處理特定集合的基元需要的合并頂點/幾何著色器程序的實例的數目。減少用于處理基元的合并頂點/幾何著色器程序的實例的數目可以減少由GPU 30使用的處理資源、減少通過GPU 30執行的資源分配的數目,和/或減少由GPU 30消耗的電力。以此方式,可以改進通過合并頂點/幾何著色器程序執行可編程頂點著色和可編程幾何著色的GPU 30的性能和/或電力消耗。
圖4是說明可以使用本發明的實例著色器程序執行技術處理的實例三角形條帶的概念圖。如圖4中所示,實例三角形條帶包括八個頂點(v0、v1、v2、v3、v4、v5、v6、v7)和六個基元(p0、p1、p2、p3、p4、p5)。圖4的三角形條帶中的若干個基元共享頂點。換句話說,同一頂點可以形成兩個或大于兩個基元的一部分。
圖5是說明根據本發明可用于執行合并頂點/幾何著色器程序的多個實例以用于處理圖4中所示的三角形條帶的實例線程配置52、54的概念圖。線程配置52是可用于根據復制的著色器程序執行模式執行合并頂點/幾何著色器程序的多個實例的線程配置的實例。線程配置54是可用于根據非復制的著色器程序執行模式執行合并頂點/幾何著色器程序的多個實例的線程配置的實例。
線程配置52包括波配置56、58、60。線程配置54包括波配置62。波配置56、58、60、62中的每一個可以對應于通過著色器單元40(例如,著色器單元40的處理元件46A-46H)并行處理的合并頂點/幾何著色器程序的實例的波。波配置56、58、60、62中的每一個可以指示數據項到包括于相應的波中的合并頂點/幾何著色器程序的實例的分配。單個波中的合并頂點/幾何著色器程序的實例中的每一個可以在著色器單元40中的處理元件46A-46H中的單獨的一個上執行。合并頂點/幾何著色器程序的實例中的每一個可以替代地被稱作線程和/或光纖。
如圖5中所示,波配置56、58、60、62中的每一個的第一行規定光纖標識(光纖ID)、波配置56、58、60、62中的每一個的第二行規定頂點標識(頂點ID),并且波配置56、58、60、62中的每一個的第三行規定基元標識(基元ID)。單個波中的合并頂點/幾何著色器程序的實例中的每一個可以對應于唯一的相應的光纖ID值。頂點ID值中的每一個對應于圖4的三角形條帶中的類似地數目的頂點。類似地,基元ID值中的每一個對應于圖4的三角形條帶中的類似地數目的基元。
波配置56、58、60、62的列中的每一個表示頂點和基元中的一或兩個到特定光纖的分配。舉例來說,波配置56的第一列表示頂點v0和基元p0到光纖0的分配,并且波配置56的第六列表示頂點v3和基元p1到光纖5的分配。
并不包括任何值的波配置56、58、60、62中的方框指示不存在分配到光纖的特定類型的數據項。舉例來說,波配置56的第八列表示基元p1到光纖7的分配以及沒有頂點到光纖7的分配,并且波配置62的第八列表示頂點v7到光纖7的分配以及沒有基元到光纖7的分配。
當頂點和基元被分配到光纖時,光纖可以相對于分配到光纖的頂點執行頂點著色器處理并且相對于分配到光纖的基元執行幾何著色器處理。舉例來說,波配置56中的光纖0可以相對于頂點v0執行頂點著色器處理并且相對于基元p0執行幾何著色器處理。
當基元被分配到光纖且頂點并未被分配到光纖時,光纖可以相對于基元執行幾何著色器處理并且可以未必執行任何頂點著色器處理。舉例來說,波配置56中的光纖7可以不執行任何頂點著色器處理并且可以相對于基元p1執行幾何著色器處理。
當基元被分配到光纖且頂點并未被分配到光纖時,光纖可以相對于基元執行幾何著色器處理并且可以未必執行任何頂點著色器處理。舉例來說,波配置56中的光纖7可以不執行任何頂點著色器處理并且可以相對于基元p1執行幾何著色器處理。
當頂點被分配到光纖且基元并未被分配到光纖時,光纖可以相對于頂點執行頂點著色器處理并且可以未必執行任何幾何著色器處理。舉例來說,波配置62中的光纖7可以相對于頂點v7執行頂點著色器處理并且可以不執行任何幾何著色器處理。
對于復制的著色器程序執行模式(即,波配置56、58、60),纖維中的每一個接收單個頂點并且輸出單個頂點。因此,多個纖維針對基元中的每一個執行幾何著色器處理。在圖5的具體實例中,針對每個基元執行四個纖維(即,合并頂點/幾何著色器的四個實例)。
應注意此實例可以使用三個纖維(即,包括于用于幾何著色器級的輸出基元中的每一個中的頂點的數目)而不是四個纖維。然而,在此實例中幾何著色器程序限定最大輸出頂點計數為四,即使輸出頂點中的一個并不使用也是如此。在一些實例中,幾何著色器可以限定在1個和1024個頂點之間的最大輸出頂點計數。最大輸出頂點計數可以未必等于輸入基元類型的頂點的數目。
對于非復制模式(即,波配置62),纖維中的每一個接收單個頂點并且可以輸出多個頂點。因此,對于基元中的每一個,單個光纖用于為基元執行幾何著色器處理。在圖5的實例中,每個光纖(例如,合并頂點/幾何著色器程序的實例)可以輸出三個頂點。通過纖維中的每一個輸出的三個頂點的每一集合可以對應于圖4中所示的三角形基元中的一個。
如圖5中所示,對于復制模式(即,波配置56、58、60),針對基元中的每一個的幾何著色器處理的重復執行造成重復的ALU操作和重復的資源分配的發生。這樣可能降低GPU 30的性能和/或增加GPU 30的電力消耗。此外,幾何著色器處理的重復執行消耗每個基元多個纖維/處理元件,這樣可能進一步降低GPU 30的性能。另外,頂點沒有在復制模式中重復使用,這防止了GPU 30利用頂點重復使用的電力、性能和存儲器帶寬改進。
相比之下,非復制模式(即,波配置62)針對由幾何著色器處理的基元中的每一個執行幾何著色器功能的單個實例,這可以減少每個基元執行ALU操作的數目、減少每個基元執行資源分配的數目,和/或減少每個基元消耗的纖維/處理元件的數目。減少每個基元ALU操作、每個基元資源分配和/或每個基元消耗的纖維/處理元件可以改進GPU的性能和/或減少GPU的電力消耗。此外,頂點重復使用可以在非復制模式中發生,由此減少每個基元執行的頂點處理的量。減少頂點處理的量可以在圖形處理系統中改進性能、節省電力和/或減少存儲器帶寬。
雖然非復制模式可以就改進幾何著色器處理的性能和電力消耗而言且就允許頂點重復使用的發生而言提供若干優勢,但是對于對非復制模式而言可能存在缺點。舉例來說,因為每個光纖可以輸出多個頂點,所以針對頂點/幾何著色器纖維的單個波存儲輸出頂點需要的芯片上存儲空間(例如,著色器單元40的寄存器48)的總量可能是相當大的,特別是在幾何著色器執行相對較大量的頂點放大的情況下。雖然芯片外存儲器可以用于存儲頂點,但是使用此類存儲器可以使著色器單元40的性能顯著降級。
在圖5的實例中,每個光纖能夠輸出最多四個頂點,引起針對每個波的32頂點分配芯片上存儲空間需要。相比之下,復制模式輸出每個光纖的單個頂點。因此,對于單個波,在此實例中存儲空間可以限制為八個頂點。
一般而言,在著色器單元40中用于存儲輸出頂點的存儲空間(例如,寄存器48)的量可能是有限的。因為用于執行合并頂點/幾何著色器程序的非復制模式允許多個頂點由光纖中的每一個產生,所以存儲用于非復制模式的輸出頂點需要的存儲空間的量可以大于復制模式需要的存儲空間的量。如果包括于著色器單元40中的存儲空間的量并不足以存儲用于波中的纖維的給定集合的輸出頂點,那么可能需要執行外部存儲器存取,這樣可以顯著降低著色器單元40的性能。
如上文所論述,用于執行合并頂點/幾何著色器程序的非復制模式可以提供用于執行波中的給定纖維集合的更好的性能和/或減小電力消耗。然而,如果與在波中執行光纖相關聯的輸出頂點存儲空間需求大于在著色器單元40中可供使用的輸出頂點存儲空間的量,那么通過不復制幾何著色器處理獲得的性能和/或電力改進可以被由外部存儲器存取引起的性能的降低超過。
因此,如果用于存儲輸出頂點的存儲空間需求相對較小(例如,如果輸出頂點存儲空間需求小于或等于包含于著色器單元40中的輸出頂點存儲空間的量),那么用于執行合并頂點/幾何著色器程序的非復制模式可以提供更好的性能和/或減小的電力消耗。另一方面,如果用于存儲輸出頂點的存儲空間需求相對較高(例如,如果,輸出頂點存儲空間需求大于包含于著色器單元40中的輸出頂點存儲空間的量),那么用于執行合并頂點/幾何著色器程序的復制模式可以提供更好的性能。
根據本發明,著色器單元40可經配置以在用于執行合并頂點/幾何著色器程序的非復制模式與用于執行合并頂點/幾何著色器程序的復制模式之間選擇性地切換。允許著色器單元40在非復制模式與復制模式之間切換以用于執行合并頂點/幾何著色器程序可以提供額外的控制和/或靈活性給GPU 30的用戶,以便選擇針對特定處理需求,比如(例如)性能需求、電力消耗需求等定制的特定執行模式。
在一些實例中,為了在非復制模式與復制模式之間切換以用于執行合并頂點/幾何著色器程序,著色器單元40可經配置以接收指示著色器程序執行模式的信息以用于執行合并頂點/幾何著色器程序。指示待用于執行著色器程序的著色器程序執行模式的信息可包括(例如)指示是否非復制模式將用于執行合并頂點/幾何著色器程序的信息和/或指示是否復制模式將用于執行合并頂點/幾何著色器程序的信息。響應于接收指示著色器程序執行模式將用于執行合并頂點/幾何著色器程序的信息,著色器單元40(例如,控制單元42)可以基于著色器程序執行模式在著色器單元40中配置一或多個組件以基于著色器程序執行模式執行合并頂點/幾何著色器程序。
在其它實例中,為了在用于執行合并頂點/幾何著色器程序的非復制模式與復制模式之間切換,線程調度器36可經配置以基于選擇的著色器程序執行模式(例如,非復制模式或復制模式)確定和/或產生線程配置。舉例來說,線程調度器36可以分配多個基元和多個頂點中的每一個到對相應的光纖,并且基于所述分配產生線程配置。線程調度器36可以提交線程配置到著色器單元38以使得著色器單元38基于線程配置執行合并頂點/幾何著色器程序。
在額外實例中,為了在用于執行合并頂點/幾何著色器程序的非復制模式與復制模式之間進行切換,合并頂點/著色器程序可以包括基于所選定的著色器程序執行模式(例如,復制模式對非復制模式)選擇性地執行各種操作的代碼。舉例來說,著色器代碼可以選擇性地使得合并頂點/幾何著色器的實例針對非復制模式發出一個頂點并且針對復制模式發出多個頂點。作為另一實例,著色器代碼可以選擇性地使得合并頂點/幾何著色器的實例根據取決于所述選定著色器程序執行模式的不同技術計算用于存儲和/或檢索頂點著色頂點的本地存儲器位置。
舉例來說,如果選擇非復制模式,那么線程調度器36可以產生線程配置使得多個基元中的每一個被分配到N個光纖(每個基元)以用于幾何著色器處理。另一方面,如果選擇復制模式,那么線程調度器36可以產生線程配置使得多個基元中的每一個被分配到用于幾何著色器處理的一個光纖(每個基元)。
在一些實例中,N可以是大于或等于2的整數。在其它實例中,N可以等于由合并頂點/幾何著色器程序實施的幾何著色器程序所規定的最大輸出頂點計數值。最大輸出頂點計數值可以指示待由幾何著色器程序針對由幾何著色器程序處理的每個基元產生的輸出頂點的最大數目。
作為另一實例,如果選擇非復制模式,那么線程調度器36可以產生線程配置使得光纖中的每一個發出和/或輸出一個輸出頂點(每個光纖)。另一方面,如果選擇復制模式,那么線程調度器36可以產生線程配置使得光纖中的每一個發出和/或輸出M個輸出頂點(每個光纖)。
在一些實例中,M可以是大于或等于2的整數。在其它實例中,M可以等于多少個頂點是針對通過由合并頂點/幾何著色器程序實施的幾何著色器級處理的基元中的每一個產生的。在額外實例中,M可以小于或等于N。
作為另一個實例,如果選擇非復制模式,那么線程調度器36可以產生線程配置,使得多個頂點中的每一個被分配到一個光纖(例如,每個波一個光纖)以用于頂點著色器處理。另一方面,如果選擇復制模式,那么線程調度器36可以產生線程配置使得多個頂點中的每一個被分配到K個光纖以用于頂點著色器處理,其中K是等于多少個基元包含相應的頂點的整數。
換句話說,如果選擇非復制模式,那么線程調度器36可以產生線程配置以允許頂點重復使用,并且如果選擇復制模式,那么線程調度器36可以產生線程配置以不允許頂點重復使用。頂點重復使用可以指允許相對于不同基元執行幾何著色器處理的著色器程序的實例以使用由執行頂點著色器處理的著色器程序的單個實例產生的頂點著色頂點的處理技術。
舉例來說,當第一光纖相對于多個頂點中的一個執行頂點著色器處理時可以發生頂點重復使用以產生頂點著色頂點,第二光纖基于由第一光纖產生的頂點著色頂點相對于第一基元執行幾何著色器處理,并且第三光纖基于由第一光纖產生的頂點著色頂點相對于第二基元執行幾何著色器處理。如圖4中所示,頂點v1包括于基元p0和p1中,并且如圖5中所示,用于光纖0和1的幾何著色器處理可以共享頂點著色頂點v1,所述頂點著色頂點由光纖1產生。
根據本發明的一些方面,用于執行著色器程序的技術可以包括用于在用于執行合并頂點/幾何著色器程序的非復制模式與復制模式之間進行選擇并且使得著色器單元40根據所選定的著色器程序執行模式來執行合并頂點/幾何著色器程序的技術。在一些實例中,用于在非復制模式與復制模式之間進行選擇的技術可以基于指示存儲輸出頂點所需要的存儲空間的總量的信息在非復制模式與復制模式之間進行選擇,所述輸出頂點與通過合并頂點/幾何著色器程序實施的幾何著色器程序的一或多個API調用相關聯。如果用于合并頂點/幾何著色器程序的編譯代碼是基于幾何著色器程序產生的,那么幾何著色器程序可以通過合并頂點/幾何著色器程序實施。
在此類實例中,如果存儲輸出頂點所需要的存儲空間的總量相對較小(例如,小于或等于閾值),那么用于在非復制模式與復制模式之間進行選擇的技術可以選擇非復制模式作為選定的著色器程序執行模式以用于執行合并頂點/幾何著色器程序。這可以允許圖形處理系統獲得非復制模式的增大的性能和/或減小電力消耗益處而無需用于頂點著色頂點的芯片外存儲器存取。另一方面,如果存儲輸出頂點所需要的存儲空間的總量相對較大(例如,大于閾值),那么用于在非復制模式與復制模式之間進行選擇的技術可以選擇復制模式作為選定著色器程序執行模式以用于執行合并頂點/幾何著色器程序。這可以允許圖形處理系統避免如果非復制模式用于此類情況中,那么則可能需要的芯片外存儲器存取,并且避免與此類芯片外存儲器存取相關聯的性能缺點。
在一些實例中,可以基于由幾何著色器程序的一或多個API調用產生的輸出頂點的總數和存儲輸出頂點中的每一個所需要的存儲空間的總量確定存儲輸出頂點所需要的存儲空間的總量。舉例來說,存儲輸出頂點所需要的存儲空間的總量可以等于由幾何著色器程序的一或多個API調用產生的頂點的總量與存儲輸出頂點中的每一個所需要的存儲空間的總量的乘積。在一些情況下,由幾何著色器程序的一或多個API調用產生的頂點的總量可以對應于包括于由幾何著色器程序的一或多個API調用產生的輸出基元的集合中的頂點的總數。
在其它實例中,為了基于存儲與幾何著色器程序的一或多個API調用相關聯的輸出頂點所需要的存儲空間的總量在非復制模式與復制模式之間進行選擇,用于在非復制模式與復制模式之間進行選擇的技術可以確定存儲用于合并頂點/幾何著色器程序的執行的一個波的輸出頂點所需要的存儲空間的總量。合并頂點/幾何著色器程序的執行的一個波可以對應于通過著色器單元40并行地執行的合并頂點/幾何著色器程序的L個實例,其中L等于并行地執行著色器程序的著色器單元40中的處理元件的數目。
在一些實例中,指示存儲用于幾何著色器程序的一或多個API調用的輸出頂點所需要的存儲空間的總量可以對應于存儲用于合并頂點/幾何著色器程序的執行的一個波的輸出頂點所需要的存儲空間的總量。合并頂點/幾何著色器程序的執行的一個波可以對應于通過著色器單元40并行地執行的合并頂點/幾何著色器程序的L個實例,其中L等于并行地執行著色器程序的著色器單元40中的處理元件的數目。
在此類實例中,如果存儲輸出頂點所需要的存儲空間的總量小于或等于閾值,那么用于在非復制模式與復制模式之間進行選擇的技術可以選擇非復制模式作為用于執行合并頂點/幾何著色器程序的所選定的著色器程序執行模式。另一方面,如果存儲輸出頂點所需要的存儲空間的總量大于閾值,那么用于在非復制模式與復制模式之間進行選擇的技術可以選擇復制模式作為所選定的著色器程序執行模式以用于執行合并頂點/幾何著色器程序。在一些情況下,在此類實例中的閾值可以對應于在著色器單元40(例如,寄存器48)中可供使用的存儲空間的總量以存儲與合并頂點/幾何著色器程序的執行的一個波相關聯的輸出頂點。
在額外實例中,指示存儲與幾何著色器程序的一或多個調用相關聯的輸出頂點所需要的存儲空間的總量的信息可以對應于通過由合并頂點/幾何著色器程序實施的幾何著色器程序的API調用執行的頂點放大的量。頂點放大的量可以指與通過合并頂點/幾何著色器程序實施的幾何著色器程序的一個API調用相關聯的輸出頂點對輸入頂點的比率。
在此類實例中,如果頂點放大的量小于或等于閾值,那么用于在非復制模式與復制模式之間進行選擇的技術可以選擇非復制模式作為所選定的著色器程序執行模式以用于執行合并頂點/幾何著色器程序。另一方面,如果頂點放大的量大于閾值,那么用于在非復制模式與復制模式之間進行選擇的技術可以選擇復制模式作為所選定的著色器程序執行模式以用于執行合并頂點/幾何著色器程序。
在一些實例中,用于在非復制模式與復制模式之間進行選擇以用于執行合并頂點/幾何著色器程序的上文所描述的技術中的一或多個可以通過GPU 30外部的主機裝置(例如,主中央處理單元(CPU))實施。舉例來說,用于在非復制模式與復制模式之間進行選擇的技術中的一或多個可以通過在主機裝置上執行的圖形驅動程序實施和/或通過在主機裝置上執行的編譯器實施。在其它實例中,用于在非復制模式與復制模式之間進行選擇的技術中的一或多個可以通過GPU 30實施。舉例來說,一或多個固定功能和/或可編程處理單元可以實施上文描述的選擇技術中的一或多個。
在選擇技術通過主機裝置實施的實例中。本發明的技術可以向GPU 30提供指示用于GPU 30的所選定的著色器程序執行模式的信息。舉例來說,GPU 30可以包括用于存儲指示所選定的著色器程序執行模式的信息(例如,一或多個位和/或一或多個值)的一或多個寄存器,并且主機裝置(例如,CPU)可以提供指示所選定的著色器程序執行模式的信息給GPU 30,方法是將指示所選定的著色器程序執行模式的一或多個值寫入到寄存器。
圖6是說明根據本發明與執行合并頂點/幾何著色器程序相關聯的實例處理流程的概念圖。圖7說明根據本發明與執行合并頂點/幾何著色器程序相關聯的偽代碼。一般而言,圖6中所描繪的操作的流程可以對應于在圖7中說明的指令。
在圖6中所示的實例中,著色器單元40將例如頂點屬性、vertex_id、instance_id、primitive_id、雜項的系統值寫入到一系列寄存器R0、R1和R2(70)中。在一些實例中,寄存器可以對應于著色器單元40的寄存器48。通常,系統值可以存儲到GPU 30的任何其它未分配的存儲器。通過將系統產生值存儲到預定位置中的一系列寄存器,著色器單元40可以針對頂點著色器處理級和幾何著色器處理級中的每一個存取系統產生值。因此,用戶規定的幾何著色器程序并不需要基于用戶規定的頂點著色器程序得到編譯,以便確定其中已經存儲系統產生值。實際上,當執行頂點著色器處理和幾何著色器處理中的每一個時GPU 30可以存取預定存儲器位置以存取系統產生值。
著色器單元40執行頂點著色操作(72)。在頂點著色操作之后,著色器單元40將通用寄存器(GPR)(例如,寄存器48)(例如,從頂點著色器處理的輸出頂點)的內容寫入到本地存儲器50(74)。著色器單元40切換到幾何著色器紋理和恒定偏移(76)以及幾何著色器程序計數器(78)。
著色器單元40讀取本地存儲器50的內容(例如,由合并頂點/幾何著色器程序的一或多個實例的頂點著色器處理產生的頂點著色頂點),并且執行幾何著色操作(80)。當對于包括于光纖中的每個發出根據非復制模式操作時(例如,合并頂點/幾何著色器程序的實例),著色器單元40可以將頂點屬性輸出到頂點參數高速緩存(VPC)、stream_id和任何切割指示。當根據復制模式操作時,著色器單元40可以輸出一個頂點屬性到頂點參數高速緩存(VPC)并且輸出幾何著色頂點的位置的指示、stream_id、任何切割指示和任何解譯值到位置高速緩存。
參考圖7,合并頂點/幾何著色器程序可以包括頂點著色器處理代碼82、幾何著色器處理代碼84和補丁代碼86。編譯器(例如,在主CPU上執行)可以基于由圖形應用程序規定的頂點著色器程序和幾何著色器程序產生合并頂點/幾何著色器程序。在一些實例中,頂點著色器程序和幾何著色器程序可以在產生合并頂點/幾何著色器程序之前獨立地編譯,并且編譯器可以將編譯過的幾何著色器處理代碼84附加到編譯頂點著色器處理代碼82以產生用于合并頂點/幾何著色器程序的編譯代碼。
如圖7中所示,編譯器可以在頂點著色器處理代碼82與幾何著色器處理代碼84之間插入補丁代碼86。補丁代碼86可以使得著色器單元40將由頂點著色器處理代碼82產生的輸出頂點存儲到著色器單元40的寄存器48中,并且執行與將著色器單元40從頂點著色器處理模式切換到幾何著色器處理模式相關聯的操作。與將著色器單元40從頂點著色器處理模式切換到幾何著色器處理模式相關聯的操作可以包括CHMSK操作和CHSH操作。CHMSK操作可以將著色器單元40中的資源指示器切換到幾何著色器資源偏移。CHSH操作可以將著色器單元40中的程序計數器切換到與幾何著色器處理代碼84相關聯的程序計數器值。
根據本發明的額外方面,編譯器可以產生用于合并頂點/幾何著色器程序的編譯代碼使得編譯代碼包括指令,所述指令使得著色器單元40基于指示待用于執行合并頂點/幾何著色器程序的模式的信息根據非復制模式或復制模式選擇性地執行合并頂點/幾何著色器程序。舉例來說,如圖7中所示,編譯器可以產生用于合并頂點/幾何著色器的編譯代碼使得編譯代碼包括代碼段88、90和92。代碼段88、90、92中的每一個可以基于所述選定著色器程序執行模式(例如,復制模式對非復制模式)選擇性地執行各種操作,以便使得著色器單元40根據所選定的著色器程序執行模式操作。
代碼段88可以包括使得著色器單元40基于所選定的著色器程序執行模式選擇性地使用第一本地存儲器地址計算公式和第二集合本地存儲器地址計算公式中的一個的指令。所選定的本地存儲器地址計算公式可用于確定本地存儲器50中的哪個位置用于存儲通過合并頂點/幾何著色器程序執行的頂點著色器處理的輸出(例如,頂點著色頂點)。舉例來說,如果非復制模式被選擇作為著色器程序執行模式,那么編譯代碼可以使得著色器單元40使用第一本地存儲器地址計算公式,所述公式基于用于當前執行光纖的光纖標識值(即,fiber_id_vertex)和輸出頂點的大小(即,VERT_SIZE)計算本地存儲器地址。另一方面,如果復制模式被選擇為著色器程序執行模式,那么編譯代碼可以使得著色器單元40使用第二本地存儲器地址計算公式,所述公式基于分配到當前執行光纖的基元的基元標識值(即,rel_primID)、基元的大小(即,PRIM_SIZE)、分配到當前執行光纖的頂點的頂點標識值(即,rel_vertex)以及輸出頂點的大小(即,VERT_SIZE)計算本地存儲器地址。
代碼段90可以包括使得著色器單元40基于所選定的著色器程序執行模式選擇性地使用第一本地存儲器地址計算公式和第二集合本地存儲器地址計算公式中的一個的指令。所選定的本地存儲器地址計算公式可用于確定從本地存儲器50中的哪個位置加載與通過合并頂點/幾何著色器程序執行的幾何著色器處理相關聯的輸入頂點(例如,頂點著色頂點)。舉例來說,如果非復制模式被選擇作為著色器程序執行模式,那么編譯代碼可以使得著色器單元40使用第一本地存儲器地址計算公式,所述公式基于與待加載的頂點相關聯的頂點標識值(即,vertex_id)和待加載的頂點的大小(即,VERT_SIZE)計算本地存儲器地址。另一方面,如果復制模式被選擇為著色器程序執行模式,那么編譯代碼可以使得著色器單元40使用第二本地存儲器地址計算公式,所述公式基于分配到當前執行光纖的基元(即,rel_primID)、基元的大小(即,PRIM_SIZE)、與待加載的頂點相關聯的頂點標識值(即,rel_vertex)以及頂點的大小(即,VERT_SIZE)計算本地存儲器地址。
代碼段92可以包括使得著色器單元40基于所選定的著色器程序執行模式輸出一個頂點或多個頂點的指令。舉例來說,如果非復制模式被選擇為著色器程序執行模式,那么編譯代碼可以使得著色器單元40針對合并幾何著色器程序的每個實例發出多個頂點。另一方面,如果復制模式被選擇為著色器程序執行模式,那么編譯代碼可以使得著色器單元40針對合并幾何著色器程序的每個實例發出單個頂點。發出的單個頂點可以對應于其中Gsoutcount==GsoutvertID的頂點。
如圖7中所示,代碼段88和90可以接收“misc->reuse”參數,其可以對應于指示待用于著色器程序的執行的模式的信息。類似地,代碼段92可以接收“optimized_mode”參數,所述參數可以對應于指示待用于合并頂點/幾何著色器程序的執行的模式的信息。在一些實例中,“misc->reuse”參數可以由GPU 30產生,并且“optimized_mode”參數可以由GPU驅動程序產生,并且提供到GPU 30。在一些實例中,“misc->reuse”參數和“optimized_mode”參數可以被實施為單個參數和/或由單個參數產生,所述單個參數指示待用于合并頂點/幾何著色器程序的執行的模式。
將指令放置在用于能夠選擇性地執行任一模式的合并頂點/幾何著色器程序的編譯代碼中可以允許著色器單元40的處理模式發生改變而無需將新的著色器程序重新加載到著色器單元中。此外,將指令放置在用于能夠選擇性地執行任一模式的合并頂點/幾何著色器程序的編譯代碼中也可以簡化合并頂點/幾何著色器程序的編譯。
圖8是說明可用于實施本發明的著色器程序執行技術的實例計算裝置100的方塊圖。計算裝置100可包括個人計算機、臺式計算機、膝上型計算機、計算機工作站、視頻游戲平臺或控制臺、無線通信裝置(比如(例如),移動電話、蜂窩式電話、衛星電話和/或移動電話手持機)、陸線電話、互聯網電話、手持式裝置(例如,便攜式視頻游戲裝置或個人數字助理(PDA))、個人音樂播放器、視頻播放器、顯示裝置、電視機、電視機頂盒、服務器、中間網絡裝置、主機計算機,或處理和/或顯示圖形數據的任何其它類型的裝置。
如圖8的實例中所說明,計算裝置100包括用戶接口102、CPU 104、存儲器控制器106、存儲器108、GPU 30、顯示接口110、顯示器112和總線114。用戶接口102、CPU 104、存儲器控制器106、GPU 30及顯示接口110可使用總線114彼此通信。在一些實例中,GPU 30可以對應于在圖2中說明的GPU 30。應注意,圖8中所示的不同組件之間的總線和通信接口的特定配置僅是示例性的,并且具有相同或不同組件的計算裝置和/或其它圖形處理系統的其它配置可用于實施本發明的技術。
CPU 104可包括控制計算裝置100的操作的通用或專用處理器。用戶可以提供輸入到計算裝置100以使得CPU 104執行一或多個軟件應用程序。在CPU 104上執行的軟件應用程序可包含(例如)圖形應用程序、文字處理器應用程序、電子郵件應用程序、總分析表應用程序、媒體播放器應用程序、視頻游戲應用程序、圖形用戶接口應用程序、操作系統或任何其它類型的程序。用戶可經由一或多個輸入裝置(未示出)(例如,鍵盤、鼠標、麥克風、觸摸墊或經由用戶接口102耦合到計算裝置100的另一輸入裝置)將輸入提供到計算裝置100。
在CPU 104上執行的軟件應用程序可以包括一或多個圖形呈現指令,其指示GPU 30將圖形數據呈現到幀緩沖器以供在顯示器112上顯示。在一些實例中,圖形呈現指令可符合圖形應用程序編程接口(API),比如(例如)開放圖形庫API、開放圖形庫嵌入系統(OpenGL ES)API、Direct3D API、X3D API、RenderMan API、WebGL API或任何其它公共或專有標準圖形API。為了處理圖形呈現指令,CPU 104可將一或多個圖形呈現命令發布到GPU 30以使得GPU 30執行圖形數據的呈現中的一些或全部。在一些實例中,待呈現的圖形數據可以包括例如點、線、三角形、四邊形、三角形條帶等圖形基元的列表。
如圖8中所示,CPU 104包括GPU驅動程序116和編譯器118。GPU驅動程序116可以從軟件應用程序(例如,圖形應用程序)接收指令,并且控制GPU 30的操作以服務于指令。舉例來說,GPU驅動器116可調配一或多個命令,將命令放置到存儲器108中,且指示GPU 30執行所述命令。
編譯器118可以接收用于一或多個不同類型的著色器程序的源代碼并且產生用于著色器程序的編譯源代碼。舉例來說,編譯器118可以接收用于頂點著色器程序的源代碼和用于幾何著色器程序的源代碼、基于用于頂點著色器程序的源代碼產生用于頂點著色器程序的編譯代碼,并且基于用于幾何著色器程序的源代碼產生用于幾何著色器程序的編譯代碼。編譯器118也可以基于用于頂點著色器程序和幾何著色器程序的編譯代碼產生合并頂點/幾何著色器程序。GPU驅動程序116可以將編譯著色器程序中的一或多個加載到GPU 30上(例如,著色器單元40的指令存儲裝置44)以用于通過GPU 30的著色器單元40執行。
存儲器控制器106有助于進出存儲器108的數據的傳送。舉例來說,存儲器控制器106可以接收存儲器讀取和寫入命令,且服務相對于存儲器系統108的此類命令以便為計算裝置100中的組件提供存儲器服務。存儲器控制器106以通信方式耦合到存儲器108。雖然存儲器控制器106在圖8的實例計算裝置100中被說明為與CPU 104和存儲器108兩者分開的處理模塊,但在其它實例中,存儲器控制器106的功能性中的一些或全部可實施于CPU 104和存儲器108中的一或兩者上。
存儲器108可存儲可由CPU 104存取以用于執行的程序模塊和/或指令及/或由在CPU 104上執行的程序使用的數據。舉例來說,存儲器108可存儲與在CPU 104上執行的應用程序相關聯的程序代碼和圖形數據。存儲器108可另外存儲由計算裝置100的其它組件使用和/或產生的信息。舉例來說,存儲器108可充當用于GPU 30的裝置存儲器且可存儲將在GPU 30上操作的數據以及由GPU 30執行的操作而產生的數據。舉例來說,存儲器108可存儲紋理緩沖器、深度緩沖器、模板緩沖器、頂點緩沖器、幀緩沖器、呈現目標或其類似者的任何組合。另外,存儲器108可存儲命令流以供GPU 30處理。存儲器108可包括一或多個易失性或非易失性存儲器或存儲裝置,例如,隨機存取存儲器(RAM)、靜態RAM(SRAM)、動態RAM(DRAM)、只讀存儲器(ROM)、可擦除可編程ROM(EPROM)、電可擦除可編程ROM(EEPROM)、快閃存儲器、磁性數據媒體或光學存儲媒體。
GPU 30可經配置以執行由CPU 104發布到GPU 30的命令。由GPU 30執行的命令可以包括圖形命令、繪制調用命令、GPU狀態編程命令、時戳請求、存儲器傳送命令、通用計算命令、內核執行命令等。
在一些實例中,GPU 30可經配置以執行圖形操作以將一或多個圖形基元呈現到顯示器112。在此類實例中,當在CPU 104上執行的軟件應用程序中的一個需要圖形處理時,CPU 104可將圖形數據提供到GPU 30且將一或多個圖形命令發布到GPU 30。圖形命令可以包括例如繪制調用命令、GPU狀態編程命令、存儲器傳送命令、傳圖命令等。圖形數據可以包括頂點緩沖器、紋理數據、表面數據等。在一些實例中,CPU 104可通過將命令和圖形數據寫入到可由GPU 30存取的存儲器108而將所述命令和圖形數據提供到GPU 30。
在其它實例中,GPU 30可經配置以針對在CPU 104上執行的應用程序執行通用計算。在此類實例中,當在CPU 104上執行的軟件應用程序中的一個決定將計算任務卸載到GPU 30時,CPU 104可將通用計算數據提供到GPU 30,并且將一或多個通用計算命令發布到GPU 30。通用計算命令可以包括例如內核執行命令、存儲器傳送命令等。在一些實例中,CPU 104可通過將命令和數據寫入到可由GPU 30存取的存儲器108而將命令和通用計算數據提供到GPU 30。
在一些情況下,GPU 30可內置有與CPU 104相比提供對向量操作更高效的處理的高度并行的結構。舉例來說,GPU 30可以包括多個處理元件,其經配置以用并行方式在多個頂點、控制點、像素和/或其它數據上進行操作。GPU 30的高度并行本質在一些情況下可允許GPU 30與使用CPU 104呈現圖像相比更快速地將圖形圖像(例如,GUI和二維(2D)和/或三維(3D)圖形場景)呈現到顯示器112上。另外,GPU 30的高度并行本質可允許GPU 30與CPU 104相比更快速地處理用于通用計算應用程序的某些類型的向量和矩陣運算。
在一些情況下,GPU 30可以集成到計算裝置100的主機板中。在其它情況下,GPU 30可以存在于圖形卡上,所述圖形卡安裝在計算裝置100的主機板中的端口中或可以其它方式并入經配置以與計算裝置100交互操作的外圍裝置內。在其它情況下,GPU 30可位于與CPU 104相同的微芯片上,從而形成芯片上系統(SoC)。GPU 30可以包括一或多個處理器,例如,一或多個微處理器、專用集成電路(ASIC)、現場可編程門陣列(FPGA)、數字信號處理器(DSP)或其它等效的集成或離散邏輯電路。
在一些實例中,GPU 30可以包括GPU高速緩存,其可針對存儲器108的全部或一部分提供高速緩存服務。在此類實例中,GPU 30可使用高速緩存來使用本地存儲裝置代替芯片外存儲器而本地處理數據。這通過減少在每個讀取和寫入命令期間對于GPU 30經由總線114存取存儲器108(其可經歷繁重總線業務)的需要而允許GPU 30以更高效的方式操作。然而,在一些實例中,GPU 30可能不包括單獨的高速緩存,而是替代地經由總線114利用存儲器108。GPU高速緩存可以包括一或多個易失性或非易失性存儲器或存儲裝置,比如(例如),隨機存取存儲器(RAM)、靜態RAM(SRAM)、動態RAM(DRAM)等。
CPU 104和/或GPU 30可將光柵化圖像數據存儲在存儲器108內所分配的幀緩沖器中。顯示接口110可從幀緩沖器檢索數據且配置顯示器112以顯示由光柵化圖像數據表示的圖像。在一些實例中,顯示接口110可以包括經配置以將從幀緩沖器檢索的數字值轉換為可由顯示器112消耗的模擬信號的數/模轉換器(DAC)。在其它實例中,顯示接口110可將數字值直接傳遞到顯示器112以進行處理。
顯示器112可以包括監視器、電視、投影裝置、液晶顯示器(LCD)、等離子顯示面板、發光二極管(LED)陣列、陰極射線管(CRT)顯示器、電子紙、表面傳導電子發射顯示器(SED)、激光電視顯示器、納米晶體顯示器或另一類型的顯示單元。顯示器112可以集成在計算裝置100內。舉例來說,顯示器112可為移動電話手持機或平板計算機的屏幕。替代地,顯示器112可為經由有線或無線通信鏈路而耦合到計算機裝置2的獨立裝置。舉例來說,顯示器112可為經由纜線或無線鏈路而連接到個人計算機的計算機監視器或平板顯示器。
總線114可使用總線結構和總線協議的任何組合來實施,包括第一、第二和第三代總線結構和協議、共享總線結構和協議、點對點總線結構和協議、單向總線結構和協議以及雙向總線結構和協議。可用以實施總線114的不同總線結構和協議的實例包括例如超傳輸總線、InfiniBand總線、高級圖形端口總線、外圍組件互連(PCI)總線、PCI高速總線、高級微控制器總線架構(AMBA)、高級高性能總線(AHB)、AMBA高級外圍總線(APB),和AMBA高級eXentisible接口(AXI)總線。也可使用其它類型的總線結構和協議。
根據本發明,計算裝置100(例如,CPU 104和/或GPU 30)可經配置以執行本發明中描述的著色器程序執行技術中的任一個。舉例來說,GPU 30(例如,GPU 30的著色器單元40)可經配置以執行著色器程序,所述著色器程序根據本發明中描述的技術中的一或多個執行頂點著色器處理并且針對通過著色器程序接收的每個輸入頂點產生多個輸出頂點。作為另一實例,GPU 30可經配置以如本發明中所描述的根據執行的復制模式和執行的非復制模式中的一或兩個執行合并頂點/幾何著色器程序。作為另一實例,GPU 30可經配置以在使用復制模式與非復制模式之間選擇性地切換以用于根據本發明中描述的技術中的一或多個執行合并頂點/幾何著色器程序。
在額外實例中,CPU 104、編譯器118和/或GPU 30可經配置以在非復制模式與復制模式之間進行選擇以用于執行合并頂點/幾何著色器程序并且使得GPU 30中的著色器單元根據本發明中描述的技術中的一或多個根據所選定的著色器程序執行模式執行合并頂點/幾何著色器程序。在其它實例中,CPU 104、編譯器118和/或GPU 30可經配置以根據本發明中描述的技術中的一或多個針對合并頂點/幾何著色器程序產生編譯代碼。舉例來說,CPU 104、編譯器118和/或GPU 30可以產生編譯代碼使得編譯代碼包括指令,所述指令使得著色器單元基于指示待用于執行著色器程序的模式的信息根據非復制模式或復制模式選擇性地執行合并頂點/幾何著色器程序。
圖9是說明根據本發明用于執行著色器程序的實例技術的流程圖。CPU 104(例如,GPU驅動程序116)可以將著色器程序加載到GPU 30(140)上。著色器程序可以執行頂點著色器處理并且可以針對通過著色器程序接收的每個輸入頂點產生多個輸出頂點。GPU 30(例如,著色器單元40)可以執行著色器程序,所述著色器程序執行頂點著色器處理并且針對通過著色器程序接收的每個輸入頂點產生多個輸出頂點(142)。
在一些實例中,GPU 30(例如,著色器單元40)可以執行著色器程序的多個實例使得著色器程序的實例中的每一個接收多個輸入頂點中的相應一個并且響應于接收多個輸入頂點中的相應一個產生多個輸出頂點。在一些情況下,GPU 30(例如,著色器單元40)可以并行執行著色器程序的多個實例和/或作為執行的波的一部分執行著色器程序的多個實例。在一些實例中,并行執行實例可以包括執行實例使得實例中的每一個相對于不同數據項同時在著色器單元中的多個處理元件中的相應一個上執行。
在其它實例中,執行頂點著色器處理并且針對通過著色器程序接收的輸入頂點中的每一個產生多個輸出頂點的著色器程序可以是合并頂點/幾何著色器程序。合并頂點/幾何著色器程序可以是可配置的以執行頂點著色器處理和幾何著色器處理。頂點著色器處理可以通過頂點著色器程序規定并且幾何著色器處理可以通過幾何著色器程序規定。
在一些實例中,GPU 30(例如,著色器單元40)可以執行合并頂點/幾何著色器程序的多個實例使得合并頂點/幾何著色器程序的實例中的每一個產生M個輸出頂點,其中M是大于或等于2的整數。在一些實例中,M可以等于由合并頂點/幾何著色器程序實施的幾何著色器程序所規定的最大輸出頂點計數值。最大輸出頂點計數值可以指示待由幾何著色器程序針對由幾何著色器程序處理的每個基元產生的輸出頂點的最大數目。如果用于合并頂點/幾何著色器程序的編譯代碼是基于幾何著色器程序產生的,那么幾何著色器程序可以通過合并頂點/幾何著色器程序實施。
在其它實例中,合并頂點/著色器程序的實例中的每一個可以是可配置的以相對于分配到合并頂點/著色器程序的相應的實例的基元執行幾何著色器處理。在此類實例中,多個基元中的每一個可以分配到一個合并頂點/幾何著色器實例以進行處理(例如,每個基元的一個合并頂點/幾何著色器實例和/或每個波的一個合并頂點/幾何著色器實例)。
在一些實例中,合并頂點/著色器程序的實例中的每一個可以是可配置的以相對于分配到合并頂點/著色器程序的相應的實例的基元執行幾何著色器處理并且相對于分配到合并頂點/著色器程序的相應的實例的頂點執行頂點著色器處理。在此類實例中,多個基元中的每一個可以分配到一個合并頂點/幾何著色器實例以用于處理(例如,每個基元一個合并頂點/幾何著色器實例和/或每個波一個合并頂點/幾何著色器實例),并且多個頂點中的每一個可以分配到一個合并頂點/幾何著色器實例以用于處理(例如,每個頂點一個合并頂點/幾何著色器實例和/或每個波一個合并頂點/幾何著色器實例)。在一些情況下,合并頂點/幾何著色器程序的實例中的至少一個可經配置以相對于多個頂點中的一個執行頂點著色器處理并且相對于多個基元中的一個執行幾何著色器處理。
在一些實例中,著色器單元40可以允許頂點在待重復使用的基元之間共享。舉例來說,著色器單元40可以執行合并頂點/幾何著色器程序的第一實例、第二實例,和第三實例。合并頂點/幾何著色器程序的第一實例可以相對于多個頂點中的一個執行頂點著色器處理以產生頂點著色頂點。合并頂點/幾何著色器程序的第二實例可以基于由合并頂點/幾何著色器程序的第一實例產生的頂點著色頂點相對于多個基元的第一基元執行幾何著色器處理以產生對應于第一基元的一或多個幾何著色頂點。合并頂點/幾何著色器程序的第三實例可以基于由合并頂點/幾何著色器程序的第一實例產生的頂點著色頂點相對于多個基元的第二基元執行幾何著色器處理以產生對應于第二基元的一或多個幾何著色頂點。
圖10是說明根據本發明根據復制模式和非復制用于執行合并頂點/幾何著色器程序的實例技術的流程圖。一般而言,GPU 30(例如,著色器單元38中的一或多個)可以是可配置的以按非復制著色器程序執行模式操作并且是可配置的以按復制著色器程序執行模式操作。
GPU 30接收指示待用于執行合并頂點/幾何著色器程序的所選定的著色器程序執行模式的信息(144)。GPU 30確定指示所選定的著色器程序執行模式的信息是否指示復制模式將用于執行合并頂點/幾何著色器程序(146)。
如果指示所選定的著色器程序執行模式的信息指示復制模式并不用于執行合并頂點/幾何著色器程序,那么GPU 30可以非復制模式操作。當以非復制模式操作時,著色器單元40可以基于線程配置操作,其中多個基元中的每一個被分配到一個合并頂點/幾何著色器實例以用于幾何著色器處理(148),多個頂點中的每一個被分配到一個合并頂點/幾何著色器實例以用于處理(150),并且合并頂點/幾何著色器程序的實例中的每一個輸出M個輸出頂點(152)。在一些實例中,線程調度器36可以將多個基元中的每一個分配到一個合并頂點/幾何著色器實例以用于幾何著色器處理(148),并且將多個頂點中的每一個分配到一個合并頂點/幾何著色器實例以用于處理(150)。
在一些實例中,M可以是大于或等于2的整數。在其它實例中,M可以等于多少個頂點是針對通過由合并頂點/幾何著色器程序實施的幾何著色器級處理的基元中的每一個產生的。
如果指示所選定的著色器程序執行模式的信息指示復制模式待用于執行合并頂點/幾何著色器程序,那么GPU 30可以復制模式操作。當以復制模式操作時,著色器單元40可以基于線程配置操作,其中多個基元中的每一個被分配到N個合并頂點/幾何著色器實例以用于幾何著色器處理(154),多個頂點中的每一個被分配到K個合并頂點/幾何著色器實例以用于處理(156),并且合并頂點/幾何著色器程序的實例中的每一個輸出一個輸出頂點(158)。在一些實例中,線程調度器36可以分配多個基元中的每一個到N個合并頂點/幾何著色器實例以用于幾何著色器處理(154),并且分配多個頂點中的每一個到K個合并頂點/幾何著色器實例以用于處理(156)。
在一些實例中,N可以是大于或等于2的整數。在其它實例中,N可以等于由合并頂點/幾何著色器程序實施的幾何著色器程序所規定的最大輸出頂點計數值。最大輸出頂點計數值為指示待由幾何著色器程序針對由幾何著色器程序處理的每個基元產生的輸出頂點的最大數目。在額外實例中,M可以小于或等于N。在一些實例中,K可以是等于多少個基元包括相應的頂點的整數。
圖11是根據本發明用于選擇復制模式和非復制中的一個以用于執行合并頂點/幾何著色器程序的實例技術的流程圖。CPU 104和/或GPU驅動程序116確定指示存儲與通過合并頂點/幾何著色器程序實施的幾何著色器程序相關聯的輸出頂點所需要的存儲空間的總量的信息(160)。CPU 104和/或GPU驅動程序116確定指示存儲空間的總量的信息是否大于閾值(162)。
響應于確定指示存儲空間的總量并不大于閾值的信息,CPU 104和/或GPU驅動程序116選擇非復制著色器程序執行模式作為所選定的著色器程序執行模式(164)。響應于確定指示存儲空間的總量大于閾值的信息,CPU 104和/或GPU驅動程序116選擇復制著色器程序執行模式作為所選定的著色器程序執行模式(166)。
一般而言,CPU 104和/或GPU驅動程序116可以選擇非復制著色器程序執行模式和復制著色器程序執行模式中的一個作為選擇的著色器程序執行模式以用于基于指示存儲與通過合并頂點/幾何著色器程序實施的幾何著色器程序相關聯的輸出頂點所需要的存儲空間的總量的信息執行合并頂點/幾何著色器程序。CPU 104和/或GPU驅動程序116可以使得GPU 30的著色器單元40基于所選定的著色器程序執行模式執行合并頂點/幾何著色器程序。
在一些實例中,非復制模式可以使用幾何著色器功能性,所述幾何著色器功能性是針對較小放大優化的但是仍可以支持全部放大。幾何著色器功能性可與若干不同類型的基元一起使用包括例如點子圖形(一個點在內,4個頂點在外)、立方圖(三角形在內,6個三角形在外,即,18個頂點在外)、陰影體積(三角形在內,15個頂點在外)。
在一些實例中,非復制模式可以支持每個幾何著色器實例一個光纖。在其它實例中,非復制模式可以在一些實例中避免重復的ALU計算、避免每個頂點發出的重復的資源分配(例如,GPR)和/或避免實施無序存取視圖(UAV)的專業化處理的需要。在額外實例中,非復制模式可以支持頂點重復使用以用于具有小于4個頂點的輸入基元。
在一些實例中,如在以下實例中所說明,就每個波可以處理的基元的數目而言非復制模式可以提供與復制模式相比更好的性能。根據第一實例,可以處理多個點子圖形基元。輸入拓樸可以是點列表(即,PointList),并且幾何著色器的最大輸出頂點計數可以等于四(即,MaxGSOutputVertex=4)。在此實例中,復制模式可以處理每個波8個基元。然而,非復制模式可以處理每個波32個基元,由此在每個波的基元處理量中提供4倍的改進。
根據第二實例,輸入拓樸是三角形條帶(即,TriangleStrip),并且MaxGSOutputVertex=4。在此實例中,復制模式可以處理每個波8個基元。然而,非復制模式可以處理每個波30個基元,由此在每個波的基元處理量中提供3.75倍的改進。
根據第三實例,輸入拓樸是三角形列表(即,TriangleStrip),并且MaxGSOutputVertex=18(例如,立方圖)。在此實例中,復制模式可以處理每個波2個基元。舉例來說,復制模式可以執行每個波32發出,并且因此一旦波完成則開始處理它們。然而,非復制模式可以處理每個波30個基元,由此在基元處理量中提供3.75倍的改進。舉例來說,非復制模式可以執行每個光纖18個發出(即,每個波576個頂點),并且因此當波完成時處理它們。在一些情況下,有限數目的幾何著色器波能夠發射。然而,用戶能夠進行編程以限制每個波的輸入幾何著色器基元的數目。
根據第四實例,輸入拓樸是10個控制點補丁(即,Patch_10),并且MaxGSOutputVertex=4。在此實例中,復制模式可以處理每個波3個基元,并且非復制模式可以處理每個波3個基元(例如,無頂點重復使用)。因而,就每個波的基元處理量而言可能不存在性能改進。然而,非復制仍然可以提供電力節省,因為波中的其它批次的光纖可能并未運行幾何著色器(即,3個光纖可以運行幾何著色器代碼)。
在一些實例中,每個合并頂點著色器/幾何著色器(VS|GS)光纖可以支持一個基元在內,多頂點在外。在一些實例中,GPU可以輸出具有掩膜標志的頂點的多個波,所述掩膜標志指示哪個光纖具有有效的頂點(例如,每個發出一個波)。在一些實例中,可以執行輸入基元的頂點重復使用檢查以產生用于給定VS|GS波中的輸入基元的唯一頂點的頂點著色器以用于具有小于4個頂點的基元。
本發明中所描述的技術可至少部分在硬件、軟件、固件或其任何組合中實施。舉例來說,所描述技術的各種方面可實施于一或多個處理器中,包括一或多個微處理器、數字信號處理器(DSP)、專用集成電路(ASIC)、現場可編程門陣列(FPGA),或任何其它等效集成或離散邏輯電路,以及此類組件的任何組合。術語“處理器”或“處理電路”可通常指代上述邏輯電路中的任一者(單獨或結合其他邏輯電路)或例如執行處理的離散硬件的任何其它等效電路。
此類硬件、軟件和固件可實施于相同裝置內或單獨裝置內以支持本發明中所描述的各種操作和功能。另外,所描述單元、模塊或組件中的任一者可一起或單獨作為離散但可互操作邏輯裝置而實施。將不同特征描繪為模塊或單元意圖強調不同功能方面且未必暗示此類模塊或單元必須由單獨硬件或軟件組件實現。實際上,與一或多個模塊或單元相關聯的功能性可由單獨硬件、固件和/或軟件組件執行,或集成到共用或單獨硬件或軟件組件內。
本發明中所描述的技術也可存儲、實施或編碼于計算機可讀媒體(例如,存儲指令的計算機可讀存儲媒體)中。嵌入或編碼于計算機可讀媒體中的指令可使得一或多個處理器執行本文中所描述的技術(例如,當由一或多個處理器執行指令時)。在一些實例中,計算機可讀媒體可為非暫時性計算機可讀存儲媒體。計算機可讀存儲媒體可以包括隨機存取存儲器(RAM)、只讀存儲器(ROM)、可編程只讀存儲(PROM)、可擦除可編程只讀存儲器(EPROM)、電可擦除可編程只讀存儲器(EEPROM)、快閃存儲器、硬盤、CD-ROM、軟盤、盒式磁帶、磁性媒體、光學媒體或其它有形計算機可讀存儲媒體。
計算機可讀媒體可以包括計算機可讀存儲媒體,其對應于例如上文所列的有形存儲媒體的有形存儲媒體。計算機可讀媒體也可包括通信媒體,其包括有助于計算機程序從一個地點到另一地點的傳送(例如,根據通信協議)的任何媒體。以此方式,短語“計算機可讀媒體”大體上可對應于(1)非暫時性有形計算機可讀存儲媒體和(2)例如暫時性信號或載波的非有形計算機可讀通信媒體。
已描述各種方面和實例。然而,可在不脫離所附權利要求書的范圍的情況下對本發明的結構或技術作出修改。
- 還沒有人留言評論。精彩留言會獲得點贊!