用于計算機網絡業務中的信任異常檢測的方法及系統與流程
一般來說,本發明涉及網絡監測及事件管理。更具體來說,本發明涉及處理通過網絡監測獲得的網絡元數據,此可高效地導致有用信息以及時方式報告給元數據的消費者。
網絡監測是企業及服務提供者常用的關鍵信息技術(IT)功能,其涉及觀察正在內部網絡上發生的活動以找出與性能相關的問題、行為不當的主機、可疑用戶活動等。網絡監測由于由各種網絡裝置產生及提供的信息而成為可能。所述信息一般稱為網絡元數據,即,作為經由網絡發射的主信息業務的補充且與其互補的描述網絡上的活動的一類信息。
系統日志(系統日志)是常用于網絡監測的一種類型的網絡元數據。系統日志已變成用于記錄程序消息的標準格式且給原本不能通信的裝置提供向管理者通知問題或性能的方式。系統日志常用于計算機系統管理及安全審核以及一般化信息分析及調試消息。系統日志受各種各樣的裝置(如打印機及路由器)及跨越多個平臺的接收器支持。出于此原因,系統日志可用于將來自計算機系統中的許多不同類型的裝置的日志數據集成為中央存儲庫。
最近,被各種供應商稱為NetFlow、jFlow、sFlow等的另一類型的網絡元數據也已作為標準網絡業務的一部分被引入(下文中一般稱為“NetFlow”)。NetFlow是用于收集已成為用于業務監測的行業標準的IP業務信息的網絡協議。NetFlow可由例如路由器、交換器、防火墻、入侵檢測系統(IDS)、入侵保護系統(IPS)、網絡地址翻譯(NAT)實體等各種網絡裝置及許多其它裝置產生。然而,直到最近,NetFlow網絡元數據排他地用于事后網絡監督目的,例如網絡拓撲發現、定位網絡吞吐量瓶頸、服務級別協議(SLA)確認等。NetFlow元數據的此些有限使用可一般歸因于由網絡裝置產生的高信息量及所述信息的高遞送速率、信息源的多樣性及將額外信息流集成到現有事件分析器中的總體復雜性。更特定來說,NetFlow元數據生產者通常產生消費者可在實時設定中分析及使用多的信息。舉例來說,網絡上的單個中到大交換器可產生400,000個NetFlow記錄/秒。
當今的系統日志收集器、系統日志分析器、安全信息管理(SIM)系統、安全事件管理(SEM)系統、安全信息與事件管理(SIEM)系統等(本文中統稱為“SIEM”系統)不能接收或不能分析NetFlow、局限于處理NetFlow包中所含的基本信息,或以比通常產生NetFlow包的速率低得多的速率處理此些包。
例如NetFlowv9(RFC 3954)及IPFIX(RFC 5101及相關IETF RFC)等穩健網絡監測協議的出現大幅度地擴展了在網絡安全及智能網絡管理領域中使用網絡元數據的機會。同時,由于上文所識別的約束,當今的SIEM系統一般不能超出簡單報告所觀察字節及包計數而利用網絡監測信息。
對計算機網絡的異常檢測是識別不同于預期、所要或正常模式的項目、事件或行為。當在網絡業務的情境中研究時,異常檢測可廣義地分類為兩個類別:
a)中性操作環境中的網絡業務異常;及
b)在存在惡意行動者的情況下的網絡業務異常。
類型(a)網絡業務異常在正常操作條件下由于自然超載的或有缺陷的網絡裝置或者“快閃族(在網絡業務由于合法網絡用戶的大量涌入而充分增加時的良性事件)”而發生。
類型(b)事件可由外部力導致且可在性質上為惡意的。存在攻擊者可造成惡意網絡異常的若干種方式,但拒絕服務(DoS)攻擊及其變體分布式拒絕服務(DDoS)攻擊是目前為止最常見且最容易上演的。關于DoS攻擊,攻擊者的目的是使一或多個網絡資源不可被合法用戶訪問且因此破壞組織的活動。根據2012年1,000IT專業人員調查,其組織遭受DDoS攻擊的每小時造成受害者組織介于$10,000與$50,000之間的收益損失。
為了避免商業及收益的重大損失,應檢測兩種類型的網絡業務異常、將其分類并以及時方式告知網絡操作者。網絡中斷的問題在工業及軍事網絡中當失去通信可導致災難性后果時變得甚至更嚴重。
然而,當受觀察的項目的數目連同每一所觀察項目的復雜性增加時,網絡異常檢測變得異常困難。檢測網絡業務中的異常是復雜異常檢測問題的極端實例中的一者。
網絡異常檢測的傳統方法需要創建歷史基線模式,所述歷史基線模式在評定與正常行為的偏差時與當前模式相當。代替以下考慮,此傳統方法固有地是有問題的:
-網絡業務是動態的,且很少只有單個模式描述其時間特性。此可導致創建在操作環境的稍微改變之后幾乎立即過時的大量時間限制歷史基線的復雜任務。
-網絡自身是動態的,因為新裝置總是被安裝,舊裝置總是被移除且操作裝置總是可被取下以進行維修。在每一改變后,較早確立的基線失去其有效性且必須被重新確立以按每一新網絡配置調整。
-例如軟件虛擬化、軟件定義網絡(SDN)及網絡功能虛擬化(NFV)等趨勢通過創建能夠跨越物理網絡遷移的短暫虛擬網絡而進一步增加網絡的動態性質。即使在不存在任何物理網絡改變的情況下,新網絡業務生產者及消費者的實例化仍立即使所確立業務基線無效。
-網絡生態系統的高改變速率使當前網絡特性與歷史數據的比較容易出錯且極容易導致誤報。
已知先前已利用兩種方法來嘗試檢測DoS及DDoS攻擊;(a)基于簽名的方法及(b)基于基線業務的方法。最近賓夕法尼亞大學研究報告某些當今的DDoS檢測系統(Snort、PHAD、MADAME及MULTOPS)以低效水平操作。特定來說,所述研究明確表達基于簽名的系統(Snort、MADAME)對未知DDoS攻擊的低檢測率、依賴于基線業務信息的系統(PHAD)或依賴于關于業務量變曲線的任何先前假設的系統(MULTOPS)的高錯誤警報率及在業務改變時對完全重新訓練依賴于基線業務信息的系統(PHAD)的要求。
背景技術:
本發明揭示用于檢測網絡業務異常并將網絡業務異常分類的系統及方法。所述系統包含:輸入模塊,其接收含有與網絡業務相關的信息的數據流;一個或多個數據流分析器及相關模塊。所述相關模塊接收由所述分析器進行的數據流分析的結果且確定潛在異常是假的還是真的。
參考
杰克遜希金斯K.(Jackson Higgings,K.),DDoS會使你付出什么(What a DDoS Can Cost),信息周刊黑暗閱讀(Information Week Dark Reading),2012年5月5日
林,D.(Lin,D.),網絡入侵檢測及對拒絕服務攻擊的緩解(Network Intrusion Detection and Mitigation against Denial of Service Attack),賓夕法尼亞大學,2013年
馬丹妮E.H.(Mamdani,E.H.),使用語言綜合將模糊邏輯應用于近似推論(Application of Fuzzy Logic to Approximate Reasoning Using Linguistic Synthesis),IEEE計算機學報,第26卷,第12號,第1182頁到第1191頁,1977年12月
山野道夫(Sugeno,Michio),模糊測量的進步:理論與應用(Advances in Fuzzy Measures:Theory and Applications),第一屆模糊信息處理國際會議,夏威夷,1984年7月
扎德L.A.(Zadeh L.A.)、科扎克J.(Kacprzyk,J.),字計算(Computing with Words),自然史出版社,海德爾堡,1999年
貝斯維爾,M.(Basseville,M.)、尼基弗羅夫,L(Nikiforov,L),檢測突然改變:理論與應用(Detection of Abrupt Changes:Theory and Application),普倫蒂斯·霍爾出版社,1993年
崔(Chui)、查爾斯K.(Charles K.),小波簡介(An Introduction to Wavelets),學術出版社,1992年
科爾特斯C,(Cortes,C,)、瓦普尼克V.(Vapnik,V.),支持向量網絡(Support-vector networks),機器學習,第20卷,第273頁到第297頁,1995年
馬可夫斯基I.(Markovsky,I.)、凡胡夫S.(Van Huffel S.),總最小二乘方法概述(Overview of total least squares methods),信號處理,第87卷,第2283頁到第2302頁,2007年
向農克勞德E.(Shannon,Claude E.),數學通信理論,伊利諾斯州大學出版社,1949年
馬丁納撒尼爾F.G.(Martin,Nathaniel F.G.)、英格蘭吉姆斯W.(England,James W.),數學熵理論(Mathematical Theory of Entropy),劍橋大學出版社,2011年
技術實現要素:
本發明通過消除對歷史確立的基線或先前假設的依賴而解決了與傳統基線異常檢測方法相關聯的許多問題。替代地,本發明的實施例能夠通過檢測瞬間改變及評估所觀察業務特性的趨勢而識別異常。
本發明的實施例通過以下方式引入新穎方法:計算所觀察網絡業務特性的趨勢,及在多維論域的情形中,計算所觀察網絡業務特性的較高級趨勢且將所計算較高級趨勢分類為人類容易理解的語言類別。
本發明的實施例通過以下方式減少網絡異常檢測中所經歷的誤報的數目:一次評定多個網絡業務特性,將多個數學異常檢測方法應用于多個網絡業務特性,及將網絡節點健康的基于模糊邏輯的模型應用于由多個數學異常檢測方法產生的結果。
本發明的實施例能夠跟蹤重要網絡連結點(例如聯網裝置的接口)中的異常業務模式,評定網絡裝置及聯網設施作為整體的當前健康,且確定網絡元件健康的趨勢,因此預測可能網絡故障。基于網絡健康趨勢分析,操作者能夠優化網絡資源且避免中斷。或者,可自動地做出網絡優化或維護決策。
本發明的實施例進一步能夠識別重要網絡安全問題,例如實時檢測拒絕服務(DoS)及分布式拒絕服務(DDoS)攻擊。及時攻擊檢測在如由操作者確定或預定的攻擊檢測的信任水平充分時,準許緩解系統對此類攻擊的自動或人工警告。
本發明的實施例可以流式傳輸方式操作而不尋求于事后分析,且實時提供關于關鍵網絡元件狀況的信息。應了解,本發明中所揭示的方法也適用于靜止網絡數據。
本發明的實施例還可迅速地部署到服務中,因為其不對操作者強加緩慢且高成本基線業務信息獲取預處理。
附圖說明
為更清楚地確定本發明,現在將參考附圖以實例方式描述一些實施例,在附圖中:
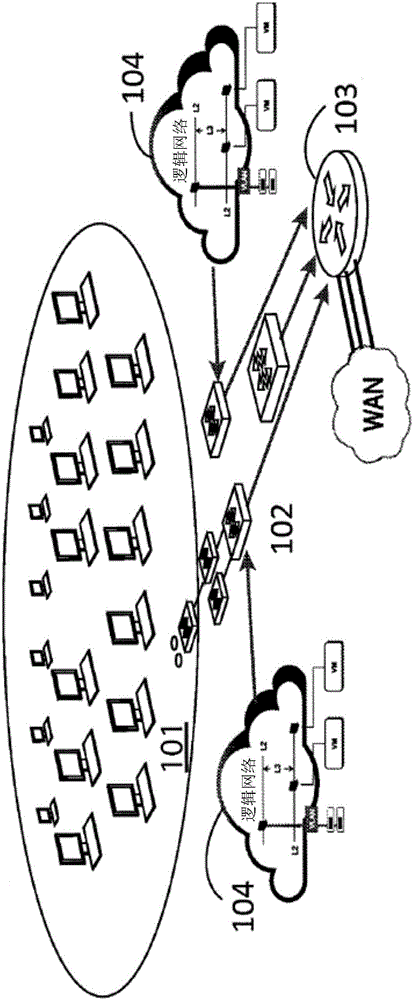
圖1圖解說明示范性簡單計算機網絡,其中例如但不限于路由器103及交換器102的網絡裝置提供例如物理主機計算機101或在物理主機計算機101上執行的虛擬機104等端點之間的連接性;
圖2圖解說明如圖1上所展示的示范性計算機網絡,其中添加了接收并分析呈流式傳輸模式的網絡業務數據的業務數據分析器(NetFlow集成器(“NFI”))110及接收分析的結果的類屬后端系統111;
圖3圖解說明可用于表征流動通過網絡節點的網絡業務的示范性模糊分類器;
圖4圖解說明將所觀察業務參數語言值映射到注意力水平論域的示范性模糊推理矩陣;
圖5提供在恒定業務量及呈5%增量的可變相對包速率下的注意力水平計算的示范性結果;
圖6圖解說明應用于取樣觀察數據集的CUSUM算法的結果;
圖7圖解說明應用于取樣觀察數據集的小波變換的結果;
圖8圖解說明應用于取樣觀察數據集的SVM方法的結果;
圖9圖解說明其中評估兩個數據觀察域A及B的改變的本發明的示范性實施例;
圖10圖解說明本發明的示范性實施例,其中使用數據收集間隔dtk與dtcur之間的所評定網絡節點健康得分(NHS)值評估網絡節點健康趨勢;
圖10(a)圖解說明本發明的示范性實施例,其中使用最佳擬合線表達網絡節點健康趨勢以圖解說明其中網絡節點健康趨勢落在下降類別中的情形;
圖10(b)圖解說明其中網絡節點健康得分(NHS)經擴展以量化網絡裝置作為整體的健康的本發明的示范性實施例;
圖10(c)圖解說明其中網絡節點健康得分(NHS)經擴展以量化網絡服務的健康的本發明的示范性實施例;
圖11圖解說明應用于檢測及報告DDoS攻擊同時最小化誤報的數目的本發明的實施例;
圖12圖解說明本發明的實施例,其中在從觀察過程開始檢測到第一改變點之后,所觀察不完整TCP/IP會話的計數可變為用于后續測量的初始基線值;
圖13圖解說明本發明的實施例,其中在檢測到一個或多個改變點之后,可檢查緊接在最右邊所檢測改變點之后的接下來的K個觀察是否比當前基線值超出預配置閾值;
圖14圖解說明本發明的實施例,其中當檢測到后續改變點時,可確立新基線值且將前一當前基線值推到已知基線值堆上;
圖15圖解說明其中代理可報告在報告間隔內所觀察不完整TCP/IP會話的數目的本發明的實施例;
圖16圖解說明其中采取步驟來評定網絡業務異常的性質的本發明的實施例;
圖17圖解說明本發明的實施例,其中如果在數據收集間隔dtk、dtk-1或dtk+1中檢測到新IP地址到達率中的改變點且檢測到流計數中的改變點,那么可將數據收集間隔dtk指定為網絡業務異常;
圖18圖解說明本發明的實施例,其中采取步驟來評定根據圖17的實施例檢測的網絡業務異常的性質;
圖19圖解說明其中采取步驟來跟蹤熵偏差的本發明的實施例;
圖20圖解說明本發明的實施例,其中當在觀察間隔上檢測到一或多個改變點時,代理采取最近所檢測改變點且從檢測到改變點時數據收集間隔處開始到當前數據收集間隔而計算熵值趨勢;及
圖21圖解說明計算考慮到最近報告及由流信息源報告的先前事件的累積異常信任度量的本發明的實施例。
具體實施方式
一般來說,本發明涉及網絡監測及事件管理。更具體來說,本發明涉及處理由于網絡監測活動而獲得的網絡元數據及所述元數據的后續處理,其可導致有用信息以及時方式報告給操作者及/或事件管理系統。
現在將參考如附圖中所圖解說明的本發明的幾個實施例而詳細描述本發明。在以下描述中,陳述眾多具體細節以便提供對本發明的實施例的透徹理解。然而,所屬領域的技術人員將明了,可在不具有這些具體細節中的一些或全部細節的情況下實踐實施例。在其它實例中,未詳細描述眾所周知的過程步驟及/或結構以便不會不必要地使本發明模糊。參考以下圖式及論述可更好地理解實施例的特征及優點。
結合附圖將更佳地理解關于以下描述的本發明的示范性實施例的各方面、特征及優點。所屬領域的技術人員應明了,本文中所提供的本發明的所描述實施例僅為說明性的而非限制性的,僅以實例方式呈現。除非另有明確陳述,否則本描述中所揭示的所有特征可由充當相同或類似目的的替代特征代替。因此,預期本發明的修改的眾多其它實施例,因為其屬于如本文中所界定的本發明及其等效物的范圍內。因此,絕對及/或順序術語(例如,舉例來說,“將”、“將不”、“應”、“不應”、“必須”、“不必”、“首先”、“最初”、“接下來”、“隨后”、“之前”、“之后”、“最后”及“最終”)的使用不打算限制本發明的范圍,因為本文中所揭示的實施例僅為示范性的。
在以下描述中,僅出于說明的目的而在網絡元數據處理的情境中揭示本發明。然而,將了解,本發明適合于更廣泛的各種應用及使用,且本發明的某些實施例適用于除網絡元數據處理之外的情境。舉例來說,本文中所揭示的方法可應用于通過調節十字路口處的交通燈的持續時間而控制城市交通流。在另一實例中,本文中所揭示的方法可適合于控制電力網。還應了解,本文中所揭示的方法在不具有關于實際網絡業務自身的限制的情況下適用。
在本發明的一個實施例中,方法及系統可使用NetFlow集成器(“NFI”)(實現呈版本1到8、NetFlow v9、jFlow、sflowd、sFlow、NetStream、IPFIX的NetFlow業務及類似(“NetFlow”)業務的集成的軟件程序)的一或多個實例與能夠存儲及/或處理呈系統日志格式的網絡元數據的任何系統一起實施。所述集成可通過將由網絡上的NetFlow生產者產生的網絡元數據轉化成網絡監測系統(系統日志)的通用語而實現。NetFlow信息到對應系統日志信息的映射可根據由NFI管理者確立的策略、規則及優先權而執行。
應了解,使用系統日志來報告網絡元數據是示范性的,且可使用其它數據表示及遞送方法,例如但不限于CEF或JSON。
網絡健康評定
圖1圖解說明示范性簡單計算機網絡,其中例如但不限于路由器103及交換器102的網絡裝置提供例如物理主機計算機101或在物理主機計算機101上執行的虛擬機104等端點之間的連接性。
典型計算機網絡是其中可靠性隨著聯網裝置的數目及網絡業務量增加而降低的復雜系統。且隨著網絡大小增加,理解網絡狀態及評定個別網絡節點的狀況的任務兩者均變得更困難及更重要。
圖2圖解說明如圖1上所展示的示范性計算機網絡,其中添加了接收并分析呈流式傳輸模式的網絡業務數據的業務數據分析器(NetFlow集成器(“NFI”))110及接收分析的結果的類屬后端系統111。在本發明的一個實施例中,使用NetFlow協議112收集關于網絡業務的信息。
在本發明的一個實施例中,網絡節點健康評定方法可遵守以下程序:
1.確立業務數據收集間隔dt。在所述方法的一個實施例中,可將數據收集間隔長度選擇為介于10秒與60秒之間。
2.確立業務觀察間隔T。T是dt的倍數:T=N*dt。在所述方法的一個實施例中,將業務觀察間隔長度選擇為介于dt的20倍到40倍之間。在利用基于小波系列算法的改變檢測方法的示范性實施例中,由于小波變換要求,所述倍數是N=2n。因此在所述方法的一個實施例中,可選擇N=32。
3.在數據信息收集間隔dt內收集關于通過網絡接口的業務的多元信息。在示范性實施例中,多個所收集網絡業務參數在不具有限制的情況下由業務量及包速率測量組成。
4.可重復所述觀察N次:R1、...、RN(其中Ri為在第i間隔期間收集的信息)。
5.在收集時間間隔N+1結束時,將至少一個改變檢測方法直接(或在小波變換的情形中,聯合用作模板的時間系列R1、...、RN)應用于時間系列R2、...、RN+1。
6.識別由每一所應用改變檢測方法檢測到的改變點,且針對從最右邊所識別改變點數據收集間隔開始到當前數據收集間隔的每一數據收集間隔計算網絡節點健康得分(“NHS”)。
7.估計網絡接口NHS值作為針對當前數據收集間隔計算的NHS值。
8.基于在從最右邊所識別改變點數據收集間隔開始到當前數據收集間隔的數據收集間隔內的NHS值變化模式而估計網絡接口NHS趨勢。
應了解,數據收集間隔dt的持續時間是可配置參數且可取決于用戶的所要知曉及/或精確程度而微調。通過選擇較短數據收集間隔,用戶可受益于較早收到關于負NHS值趨勢的通知,代價是可能接收到關于網絡業務中可能不重要的短尖峰的外來通知。選擇延長的數據收集間隔過濾掉短網絡業務尖峰但可能延遲通知的遞送。
應了解,本發明的此實施例的顯著益處源于實現評定網絡故障風險的對節點健康趨勢的情境監測。還應了解,所揭示方法可在N+1個數據收集間隔之后完全操作,所述數據收集間隔在實踐中可跨少至15到20分鐘。因此,此實施例的方法及系統可經采用且在不具有與確立長且不可靠歷史基線相關聯的延遲的情況下幾乎立即變得可操作。
所觀察數據預處理
應了解,所觀察網絡數據的短暫急劇改變可導致增加的誤報的出現。為了緩解此潛在問題,可將指數平滑過程應用于所觀察數據:
其中
是經平滑第i觀察值
X(t)是實際第i觀察值
α是平滑系數。在示范性實施方案中,平滑系數可為α=0.35或操作者基于例如對潛在網絡麻煩的較可靠指示的期望對抗對較早指示的期望等因素而偏好的其它值。
網絡節點健康得分(NHS)
在所揭示實施例中,節點健康得分(NHS)可為提供關于特定網絡節點(例如網絡裝置接口)的狀況的指導的單個度量。圖3圖解說明可用于表征流動通過網絡節點的網絡業務的示范性模糊分類器。每一模糊分類器的x軸可表示[0,1]間隔上的經分類參數的相對值,其中在參數達到其最大值時達到值1。每一模糊分類器的y軸可測量給定參數值屬于特定語言分類的程度。
參考圖3,業務量模糊分類器可表示流動通過網絡節點的業務量的語言分類。標記為低120、中121及高122的區域分別對應于在語言上可表征為低、中及高的業務水平。
進一步參考圖3,包速率模糊分類器可表示包流動通過網絡節點的速率的語言分類。標記為低123、中124及高125的區域分別對應于在語言上可表征為低、中及高的包速率水平。
進一步參考圖3,注意力水平模糊分類器可表示網絡節點需要的操作者的注意力水平的語言分類。標記為低126及高125的區域分別對應于在語言上可表征為正常及麻煩的操作者的注意力的不同程度。
在網絡節點健康評定的第一步驟中,所揭示方法可輸入通過節點的所觀察網絡業務特性的相對值(“清晰輸入(crisp input)”)且找出所觀察值中的每一者屬于其論域中的特定語言類別的程度。
在網絡節點健康評定的第二步驟中,所揭示方法可輸入所觀察值中的每一者屬于其論域中的特定語言類別的經計算程度,且使用圖4上所呈現的模糊推理矩陣將這些值映射到注意力水平模糊分類器上。所述方法可包含(例如)使用馬丹妮及山野模糊推理方法計算所需注意力水平值AL的步驟。節點健康系數可計算為:
NHS=1-AL
參考圖4,示范性模糊推理矩陣可將所觀察業務參數語言值映射到注意力水平論域。在圖4中所展示的示范性模糊推理矩陣中,行對應于所觀察相對包速率值且列對應于通過節點的所觀察相對業務量,其中每一單元表示對應模糊分類規則的語言值:
如果業務量是X且包速率是Y,那么注意力水平是Z
舉例來說,當通過網絡節點的業務量在語言上分類為低(“L”)且流動通過網絡節點的包速率在語言上分類為低(“L”),那么此節點的所需注意力水平可分類為高(“H”),從而指示輕負載的網絡節點正經歷硬件問題的高概率。
圖5提供在恒定業務量140及呈5%增量的可變相對包速率141下的注意力水平計算的示范性結果。使用馬丹妮及山野方法按比例縮放到間隔[0,100]的注意力水平計算的結果分別呈現于列142及143中。在所揭示方法的示范性實施方案中,有效注意力水平值被計算為使用馬丹妮方法計算的注意力水平值ALM與使用山野方法計算的注意力水平值ALS的平均值:
應了解,圖3上所展示的模糊分類器是示范性的,且可包含其它語言分類(例如“極”)或具有總體的其它語言分類。還應了解,圖4上所展示的模糊推理矩陣是示范性,且在不具有限制的情況下可包含額外語言分類及觀察域。
計算相對節點負載
網絡節點健康得分(NHS)計算可涉及以相對項目表達業務參數。在所揭示方法的示范性實施例中,通過網絡節點的相對業務量可計算為:
其中
B是在數據收集間隔期間通過網絡節點的雙向IP等級3業務量(以字節為單位)
是節點的最大標稱速度(以位/秒“bps”為單位),且
dt是數據收集間隔(以秒為單位)。
在所揭示方法的示范性實施方案中,網絡包流動通過網絡節點的相對速率可計算為:
其中
是在數據收集間隔期間的平均網絡包大小(以字節為單位):
其中
P是在數據收集間隔期間觀察的沿兩個方向的包的數目
針對基于IP的網絡,層2=41-層2標題的大小(17字節),幀間間隙的大小(12字節)及報頭的大小(8字節)。層2信息的大小可取為標準層2標題(14字節)、具有VLAN標簽的層2標題(16字節)及具有MPLS標記的層2標題(20字節)的平均值。
應了解,以上計算是示范性的,且相對業務量及網絡包流動通過網絡節點的相對速率可使用不同公式計算。
改變點檢測算法
改變檢測是嘗試識別隨機過程或時間系列的概率分布的改變的統計分析方法。一般來說,改變檢測問題暗示檢測是否已發生一或多個改變及識別此些改變的時間。
在示范性實施例中,累積求和(“CUSUM”)算法、小波變換(“小波”)及支持向量機(“SVM”)算法可應用于流動通過網絡節點的網絡業務的所觀察業務特性。應用多個改變點檢測算法的目的是實現對改變的信任檢測。應了解,其它改變點檢測算法可應用于所觀察網絡業務特性且CUSUM、小波及SVM算法的選擇是示范性的。
累積求和(CUSUM)算法
圖6圖解說明應用于取樣觀察數據集151的CUSUM算法的結果。點150指示在所評估原始數據集151中通過CUSUM算法發現的改變點。進一步參考圖6,在示范性再現中,y軸表示改變點信任度量(0到100),此度量的值越接近100,越信任地識別出改變點。
小波變換算法
圖7圖解說明應用于取樣觀察數據集151的小波變換的結果。原始數據160的小波變換將所觀察值151圍繞y=0正規化且過濾掉所觀察值151中的高頻率分量(通常稱為噪聲)。改變點是經變換數據的絕對值超出特定預設定閾值yT處的點,|yT|=Δy,162。應了解,改變點檢測概率隨經變換數據yT的絕對值變大而增加。
由于在觀察間隔開始時的認為突然改變,在幾個最左邊數據收集間隔Δx 163上識別的偏差優選地被丟棄。依據算法定義,小波變換應用于其的數據收集間隔N的數目應等于2n,其中n是整數(例如,N=32,n=5)。
支持向量機(SVM)算法
SVM是識別不同觀察的類似性的分類方法。SVM使用第一數據集作為模板,且對照第一數據集將第二數據集分類。圖8圖解說明應用于取樣觀察數據集151的SVM方法的結果。
如同圖7上所圖解說明的小波變換,SVM分類算法包含選擇閾值Δy 172以識別經變換數據170的突然改變。應了解,經選擇用于通過SVM算法170變換的數據的閾值172與經選擇用于小波變換算法的閾值163無關。
網絡節點健康評定
參考圖9,在所揭示方法的示范性實施例中,可針對以最右邊所檢測改變點開始到當前數據收集間隔的數據收集間隔dt 182計算網絡節點健康度量。圖9圖解說明其中評估兩個數據觀察域A及B中的改變的方法的示范性實施例。本文中所揭示的方法可在不具有限制的情況下擴展到任意數目個數據觀察域。
進一步參考圖9,如果遇到其中在所有觀察域中檢測到改變點的情形,那么針對從在其上檢測到改變點的最右邊數據收集間隔開始的數據收集域計算NHS。舉例來說,參考圖9,如果在數據收集間隔dtk 183處檢測到域A 180中的改變點且在數據收集間隔dtk-j 184(j>0)處檢測到域B 181中的改變點,那么針對dtk與當前數據收集間隔之間(包含dtk及當前數據收集間隔)的所有數據收集間隔計算NHS。
在其中僅在一個數據域中存在改變點的情形中,可針對以在其上檢測到所觀察數據中的改變點的最右邊數據收集間隔開始到當前數據收集間隔(包含最右邊數據收集間隔及當前數據收集間隔)的所有數據收集間隔計算NHS。在其中未檢測到改變點的情形中,可僅針對當前數據收集間隔計算NHS。
網絡節點健康趨勢評估
參考圖10,在所揭示方法的示范性實施例中,使用數據收集間隔dtk 183與dtcur 198之間的所評定網絡節點健康得分(NHS)值評估網絡節點健康趨勢,其中數據收集間隔dtk 183是在其上觀察到當前觀察間隔190中的最后改變點的數據收集間隔且dtcur 198是當前數據收集間隔。
進一步參考圖10,網絡節點健康趨勢可與在點191之間繪制的最佳擬合線192的斜率相關聯,點191表示以數據收集時間間隔183開始的每一數據收集時間間隔上的網絡節點健康得分(NHS)值,其中檢測到當前觀察間隔190中的最后改變點。在示范性實施方案中,使用總最小二乘(“TLS”)方法計算最佳擬合線192。應了解,除TLS外的擬合方法可用于所述目的。
進一步參考圖10,基于最佳擬合線192的斜率,網絡節點健康趨勢可分類成相異定性類別,例如,稱作峰值195、改善194、中性193、降級196及下降197。在其中在當前數據收集間隔dtcur 198期間檢測到當前觀察間隔190中的最后改變點的退化情形中,網絡節點健康趨勢可分類為中性。
進一步參考圖10,使用最佳擬合線192表達的示范性所描繪網絡節點健康趨勢圖解說明當網絡節點健康趨勢落到改善194類別中時的情形。改善194趨勢分類歸因于NHS值191由于最近所觀察改變點而繼續穩定增長的事實。
參考圖10a,使用最佳擬合線199表達的示范性所描繪網絡節點健康趨勢圖解說明當網絡節點健康趨勢落到下降197類別中時的情形。下降197趨勢分類歸因于網絡節點得分(NHS)值198由于最近所觀察改變點而急劇下降的事實。
網絡裝置健康評定
參考圖10b,網絡節點健康得分(NHS)的概念可進一步擴展到量化網絡裝置400作為整體的健康。在網絡裝置的此計算NHS的示范性實施例中,可將NHSD評定為裝置的網絡節點401的最小NHS:
其中
是第i裝置節點的網絡健康得分,且
n是部署于裝置上的網絡節點的總數目。
進一步參考圖10b,網絡裝置400NHS的以上示范性量化由以下事實證明為合理的:部署于裝置400上的網絡節點401是裝置400的組成部分,且如此是相互依賴的,且每一網絡節點401的性能受部署于裝置上的其它網絡節點的性能影響。
進一步參考圖10b,應了解,可考慮用以量化網絡裝置400健康評定的其它方法,例如基于網絡節點標稱吞吐量而使每一網絡節點401的相對加權相關聯。
網絡服務可用性評定
參考圖10c,在本發明的論域中,網絡裝置410是將網絡業務傳遞到網絡服務411的一個或多個中介機構,例如但不限于路由器、交換器及防火墻。網絡服務411是在經由應用層網絡協議提供數據處理、存儲、表示及其它能力的網絡應用層處運行的應用。
進一步參考圖10c,網絡服務411可用性取決于將網絡業務轉發到網絡服務411的網絡裝置410的可用性。在網絡裝置410性能不良的情形中或在網絡裝置410故障的情形中,網絡服務的可用性降級或網絡服務變得不可訪問。由于網絡服務411對企業商業的重要性,因此檢測通向網絡服務411的網絡路徑中的故障且基于所述網絡路徑的健康而量化其可用性是重要的。
進一步參考圖10c,考慮具有m個網絡路徑412的網絡服務411,經由所述網絡路徑網絡業務流動到服務及從服務流動。在本發明的精神內,可使用網絡節點健康得分(NHS)表達網絡服務411的可用性。在示范性實施例中,網絡服務411可用性的NHS值NHSSVC可計算為將網絡業務轉發到所述網絡服務411的每一網絡裝置410的NHS值的經加權平均值:
其中
是將網絡業務轉發到網絡服務411的第i網絡裝置410的網絡健康得分
m是將網絡業務轉發到網絡服務411的網絡裝置410的總數目
ωi是通過每一網絡裝置410流動到網絡服務411及從網絡服務411流動的網絡業務的份額。所述份額通過以下步驟計算:觀察通過第i網絡裝置410去往及來自網絡服務411的網絡業務流Vi,累加在數據收集周期內在每一流中的網絡業務量,及將其除以在數據收集周期內去往及來自網絡服務411的總業務量V:
網絡服務的NHS值計算提供用于向網絡操作者報告聯網資源的狀況的穩健機制。
應了解,可考慮用以量化網絡服務可用性的其它方法,例如在裝置加權計算中包含網絡裝置的標稱性能。
檢測異常業務
拒絕服務(“DoS”)攻擊是使網絡資源不可用于其既定用戶的嘗試。分布式拒絕服務(“DDoS”)攻擊是DOS攻擊的變體,其中多個受危及系統用于將單個系統定為目標且導致DoS攻擊。
在DDoS攻擊期間,涌入目標的傳入業務通常源于許多不同源,這使得難以區分合法用戶業務與跨越大量源點傳播的攻擊業務。
在示范性實施例中,本文中所揭示的方法可應用于檢測及報告DDoS攻擊同時最小化誤報的數目。參考圖11,所揭示方法利用含有關于網絡業務的信息及考慮到多個網絡業務特性的網絡業務描述212,所述多個網絡業務特性中的每一者由多個專門模塊(“代理”)210評估。實施所揭示方法的系統將描述網絡業務的信息遞送到每一代理210且每一代理210可以專門方式處理此信息。
進一步參考圖11,一旦代理210收集足以做出結論的信息(或響應于計時器),代理210便可將其發現報告給事件相關處理器(“ECP”)211,ECP 211發揮功能以做出關于事件是否是肯定的或事件是否是否定的最終決策。
應了解,在代理210中實施的將輸入提供到ECP 211最終決策制定程序中的算法集合可變化,且除本文中所揭示的算法外的算法可用于提供此輸入。還應了解,下文中所論述的代理210的列表僅出于圖解說明的目的且不構成對所揭示方法的任何限制。
盡管如本文中所揭示的方法的示范性實施例分析貫穿網絡的網絡業務,但應了解,其可在不具有限制的情況下應用于到特定IP地址的網絡業務,因此檢測以特定網絡服務或多個網絡服務為目標的DDoS攻擊。
代理A:TCP/IP業務分析器
進一步參考圖11,代理A可專門用于檢測基于TCP/IP的DoS淹沒攻擊及將觀察報告給ECP 211。
TCP/IP淹沒攻擊是實踐中可見的最普遍的DDoS攻擊分類中的一者。最常見類型的TCP/IP淹沒攻擊是SYN淹沒攻擊,在SYN淹沒攻擊期間攻擊者發送具有受破壞主機的源IP地址或受騙IP地址的大量TCP/IP SYN包。
當在兩個通信對等點A與B之間起始TCP/IP會話時,發生標準TCP/IP SYN-SYN/ACK–ACK消息交換。此通信的發起者A首先發送TCP/IP SYN包且響應者B以TCP/IP SYN/ACK包響應。在正常情況下,發起者A然后以TCP/IP ACK包響應且可開始將數據發送到響應者B。在其中發起者A是惡意實體的情形中,其可抑制將TCP/IP ACK包發送到響應者B,因此捆綁住為了創建新TCP/IP會話而分配的響應者的資源。
應了解,存在其它類型的TCP/IP淹沒攻擊(例如反射型SYN/ACK淹沒及TCP/IP FIN淹沒),且本文中所揭示的方法在不具有任何限制的情況下還適用于那些類型的攻擊。
代理A監測不完整TCP/IP會話(即,其中響應者B未響應于所發送TCP/IP SYN/ACK包而接收到TCP/IP ACK包的所起始TCP/IP會話)的數目。舉例來說,代理A可計算在每一數據收集間隔dt上未應答的TCP/IP SYN/ACK響應的數目。
在示范性實施例中,為了檢測初期TCP/IP SYN淹沒攻擊,可選擇滑動觀察間隔T=dt×N,N是整數。此選擇形成分析其中的值改變的多個所觀察數據。CUSUM算法此后可應用于針對每一數據收集間隔dt識別所述系列的不完整TCP/IP會話計數中的改變點。
參考圖12,當從觀察過程的開始檢測到第一改變點220時,所觀察不完整TCP/IP會話的計數可變為用于后續測量的初始基線值221b0。應了解,除選擇對應于第一改變點220的值外的方法可用于確立初始基線值。本文中所描述的方法是示范性的,且可由設定固定初始基線值、采取在第一改變點220之前的數據收集間隔的平均值及/或其它方法代替。
參考圖13,在其中檢測到一個或多個改變點的情形中,可檢查緊接在最右邊所檢測改變點223之后的接下來的K個觀察222是否比當前基線值225超出預配置閾值δ(224)。代理A可在(舉例來說)滿足以下條件中的一者的情況下報告事件:
1)CK≥CK-1≥...≥C0
2)ave(Ci)≥CO,i=1、...、K
其中
C0是改變點223處不完整TCP/IP會話的數目
Ci是在第i連續數據收集間隔dt(i=1、...、K)期間不完整TCP/IP會話的數目
ave是平均函數。
參考圖14,當檢測到后續改變點230時,可確立新基線值231且可將前一當前基線值225推到已知基線值堆上。
考圖15,代理A可報告在報告間隔240內所觀察不完整TCP/IP會話的數目,報告間隔240可在所觀察不完整TCP/IP會話的數目超出當前閾值241時的第一數據收集間隔處開始直到所觀察不完整TCP/IP會話的數目下降到低于當前作用中基線242時的所檢測減少改變點243為止。
進一步參考圖15,當檢測到減少改變點時,可提取已知基線值堆的頂部處的基線值且其值然后變成當前作用中基線242。在其中已知基線值堆非空的情形中,代理A可繼續報告所觀察不完整TCP/IP會話的數目。如果已知基線值堆是空的,那么代理A可停止報告。
代理B:類屬網絡業務特性分析器
代理B可為網絡業務特性的智能分析器。代理B可監測并分析導致絕大多數DoS攻擊的IP層協議的業務。在示范性實施例中,代理B監測并分析利用TCP/IP、UDP及ICMP協議的網絡業務。應了解,代理B可在不具有限制的情況下監測例如GRE、IGMP及其它等其它IP層協議的業務特性。
當監測網絡業務特性時,代理B對經合并信息單位(本文中稱為“流”)操作。在示范性實施例中,流是由IP層協議以及其來源及目的地點表征的網絡包的單向序列。應了解,例如服務類型(ToS)、自主系統號(ASN)或類似信息等其它網絡業務特性可表征流。
可針對每一所監測IP層協議在每一收集時間間隔dt的持續時間內評定以下網絡業務特性:
1)平均字節數目/包
2)平均包數目/流
3)平均字節數目/流,及
4)獨特源IP地址的數目。
為了檢測網絡業務特性的改變,可選擇滑動觀察間隔T:
T=dt×M,M=2n,
其中n是整數。在觀察時間間隔T結束時,可將小波變換應用于M個特性(1)到(4)的所收集序列中的每一者。優選地將在其上特性的經變換值超出閾值τ的收集時間間隔dt標記為可疑的。
在示范性實施例中,使用以下函數來計算所收集網絡業務特性(1)到(4)中的每一者的信任值:
其中xi是第i數據收集間隔dt,且
yi是第i時間間隔上的經變換特性的值。
可將相關信任度量計算為個別信任值的和:
可將具有超出預設定閾值σ的信任度量的數據收集間隔指定為網絡業務異常的候選點。
在示范性實施例中,除收集網絡業務特性(1)到(4)外,還可在每一數據收集間隔dt上收集以下累積網絡業務特性:
5)累積字節數目
6)累積包數目,及
7)累積所管擦流數目。
參考圖16,為了評定網絡業務異常的性質,可選擇最近所觀察候選改變點,且可計算網絡業務特性(4)到(7)中的每一者的趨勢250到253,然后可將每一所計算趨勢線視為單位向量且將總體趨勢254計算為網絡業務特性趨勢250到253的向量和。
進一步參考圖16,為了評估網絡業務特性的總體趨勢254,將總體趨勢254分類為多個定性特性,例如但不限于增加255、可持續256及減少257。如果將總體趨勢254分類為增加255定性類別,那么代理B優選地報告網絡業務異常事件以及當前網絡業務特性(4)到(7)的值及總體趨勢斜率值。
應了解,總體趨勢分類可不同于示范性實施例中的分類,使得可持續256類別為任選的或分類框架可含有較多數目個定性類別。
代理C:新IP地址到達率分析器
由于DDoS攻擊通常借助于受破壞網絡主機或通過欺騙用于籌劃攻擊的網絡包中的源IP地址而完成,因此DDoS攻擊的開始通常由先前未見過的訪問者的涌入表征。代理C可觀察每一數據收集間隔dt中兩個觀察域中的改變:
8)新IP地址到達率,及
9)所觀察流的數目。
為了檢測此類網絡業務特性改變,可選擇滑動觀察間隔T:
T=dt×N
其中N是整數,且CUSUM算法可應用于識別每一數據收集間隔dt上的新IP地址的到達率及所觀察流計數的改變點。
參考圖17,在所揭示方法的示范性實施例中,如果在數據收集間隔dtk 260、dtk-1 262或dtk+1 263中在新IP地址到達率261中檢測到改變點且在流計數264中檢測到改變點,那么可將數據收集間隔dtk 260指定為網絡業務異常。
應了解,通過分析網絡業務特性(8)及(9)(如本文中所描述),代理C能夠提供用于區分DDoS攻擊與歸因于合法用戶的涌入的稱作“快閃族”的現象的機制。快閃族的典型實例是在發布新產品時到商業網站的業務增加或在工作日開始時網絡業務中的尖峰。
進一步參考圖17,代理C可通過強加在數據收集間隔dtk 260、dtk-1 262或dtk+1 263中的流計數264中的改變點伴隨有新IP地址到達率261中的改變點的要求而區分快閃族與DDoS攻擊。此相依性的原因是網絡資源的合法使用導致與網絡資源的較長交互,因此相比于DDoS攻擊的情形形成較少流,在DDoS攻擊期間會形成大量流。
參考圖18,為了評定網絡業務異常的性質,選擇最近所觀察改變點,且可計算網絡業務特性(8)270及(9)271中的每一者的趨勢,然后可將每一所計算趨勢線視為單位向量且可將總體趨勢274計算為網絡業務特性趨勢270及271的向量和。
進一步參考圖18,為了評估網絡業務特性的總體趨勢274,可將總體趨勢274分類成多個定性特性,例如但不限于增加275、可持續276及減少277。如果將總體趨勢274分類為增加275定性類別,那么代理C優選地報告網絡業務異常事件以及當前網絡業務特性(8)及(9)的值及總體趨勢斜率值。
應了解,總體趨勢分類可不同于示范性實施例中的分類,使得可持續276類別是任選的,或分類框架可含有更多數目個定性類別。
代理D:業務熵分析器
熵是信息內容的不可預測性的量度。其還可解釋為系統中的混亂的量度。熵H計算為:
其中是給定源IP地址實例的計數,N是觀察的總數目(N>0)。
由于DDoS攻擊通常借助于受破壞網絡主機或通過欺騙用于籌劃攻擊的網絡包中的源IP地址而完成,因此DDoS攻擊的開始通常由所觀察IP地址的數目的增加及在源IP地址欺騙的情形中每一源IP地址觀察的小數目表征。由于以上考慮,熵分析器提供網絡的信息一致性的穩健估計。
在示范性實施例中,代理D可計算每一數據收集間隔dt的熵。由于熵是隨機變量,因此應計算其均值μ及偏差σ2。為了檢測所觀察網絡熵的改變,優選地選擇滑動觀察間隔T:
T=dt×N
其中N是整數,且CUSUM算法應用于識別每一數據收集間隔dt上所計算熵值中的改變點。熵均值μ及偏差σ可在第一所檢測改變點處計算但優選地不早于發生觀察間隔T的N個移位,且第一改變點計算在2N x dt數據收集間隔之后完成。
參考圖19,為了跟蹤熵偏差,將區μ±ασ指定為正常的,其中μ281表示均值且σ282表示偏差。系數α定義容限帶280,其中網絡業務內容被認為是充足的。舉例來說,選擇α=2 283會將正常網絡業務內容置于95百分位且將所有其它網絡業務內容分類為異常。
參考圖20,當在觀察間隔上檢測到一或多個改變點,代理D采取最近所檢測改變點且以檢測到改變點時的數據收集間隔開始到當前數據收集間隔而計算熵值趨勢290。基于趨勢線的斜率,所計算熵值趨勢可分類為穩定291、增加292及降低293定性類別。如果針對當前數據收集間隔計算的熵值落在容限帶外且趨勢分類為增加292或降低293,那么代理D優選地報告網絡業務異常及相應趨勢分類。
代理D優選地針對每一后續數據收集間隔重復關于網絡異常及趨勢分類的信息直到熵值重新進入容限帶為止。在熵值重新進入容限帶后,代理D即刻優選地報告熵值減少。
網絡業務異常事件相關處理器
參考圖11,所揭示方法的基本優點中的一者是其同時研究網絡業務描述212的多個方面的能力。所述研究由稱作代理210的多個專門專家模塊完成。每一代理分析多個網絡業務參數且做出代理的論域中的網絡業務是否異常的結論。如果代理發現異常,其向事件相關處理器(ECP)211報告其發現。
在示范性實施例中,ECP 211通過為用于分析的流信息源的網絡裝置的id而收集從代理接收的異常報告。在接收到異常報告后,ECP即刻優選地計算考慮到最近報告及由所述流信息源報告的先前事件的累積異常信任度量。
參考圖21,可給每一所報告事件指派權重w。可給由ECP在時間tn 300觀察的最后所報告事件En指派權重w(tn)=1 303,其中n是所報告事件的序列號。針對所有先前所報告事件,權重優選地以指數方式衰減301:
其中μ是指數衰減常數。
累積信任度量計算為所有所觀察事件的權重的和:
出于實際目的,在示范性實施例中,在先前所報告事件的權重變得小于0.01 302時累積信任度量計算終止。當特定流信息源的累積信任度量值C超出特定可配置閾值時,ECP 211優選地警告網絡操作者。
應了解,可基于所報告事件類型給每一所報告事件指派權重ω。在示范性ECP實施例中,累積信任度量C可計算為:
其中
ω是與在時間ti處發生的特定事件類型相關聯的權重。
還應了解,本文中所揭示的示范性ECP能夠使跨越多個網絡裝置的網絡業務異常相關且針對經歷異常網絡業務的多個網絡裝置發布警告。在此相關性的示范性實施例中,ECP可針對基于IP塊分配數據庫或通過一個或多個自主系統號(ASN)分組的特定地理區中的網絡裝置發布警告。
會聚網絡業務異常檢測及網絡裝置健康
應了解,例如掩模DDoS攻擊的網絡業務異常貢獻于網絡裝置的較低網絡節點健康得分(NHS)。參考圖4,應注意,經增加網絡業務水平130及包速率131映射到特定網絡節點的高(“H”)注意力水平,且因此減小其NHS值,此又減小總體網絡裝置的NHS值。在示范性實施例中,具有低NHS值的一個或多個網絡裝置的出現可視為由事件相關處理器(ECP)處理的事件集合中所包含的另一事件。
還應了解,網絡裝置健康信息在由事件相關處理器(ECP)處理的事件集合中的輸入可通過給網絡裝置健康信息指派權重而操縱,因此控制網絡裝置健康信息對異常網絡業務識別的影響。
盡管已就幾個實施例描述本發明,但仍存在歸屬于本發明的范圍內的更改、修改、置換及替代等效物。雖然已提供子章節標題來輔助本發明的描述,但這些標題僅是說明性的且并不打算限制本發明的范圍。
還應注意,存在實施本發明的方法及設備的許多替代方式。因此,打算將所附權利要求書解釋為包含歸屬于本發明的真正精神及范圍內的所有此些更改、修改、置換及替代等效物。
- 還沒有人留言評論。精彩留言會獲得點贊!