用于控制數據中心中的服務器過高分配的機制的制作方法
本發明涉及一種用于管理數據中心的系統和方法以及一種合并過載管理功能的數據中心。
具體地說,本發明涉及一種用于管理在虛擬化數據中心中的資源過高分配的系統和方法,所述管理包括最佳過高分配比率的估計以及過載管理功能。
背景技術:
云數據中心為遠程用戶提供通過向數據中心提交計算工作以供數據中心計算來購買將使用的計算資源的可能性。
在云數據中心中,用戶提交他希望將被執行的工作。用戶可以預先指定該工作的優先度和資源估計,所述資源估計就CPU時間、存儲器使用等來詳述用戶預計該工作將消耗的資源的量。
云數據中心執行該工作,并且將結果返回給用戶。
每個工作被封裝在虛擬容器——比如虛擬機——中,并且一個或者更多個工作共位于一個物理服務器上。每個工作可以具有限制該工作可以被分配到的物理服務器集合的放置約束。例如,約束可以指定特定的機器架構、特定的操作系統、特定的物理位置或者特定的安全約束集合。
隨著共位于一個物理服務器上的虛擬容器的數量增加,虛擬容器之間對于該服務器的物理資源的競爭也增加。高競爭可能導致工作的頻繁交換和/或資源的低效使用。該現象,被稱為性能干擾,對在虛擬容器中運行的工作的執行速率可能有不利的影響。
已經發現,用戶通常過高估計所需資源的量,這可能是期望避免工作由于缺乏分配的資源而被延遲的結果,或者是因為缺乏關于他們的工作在運行時期間的實際要求的準確理解。這導致大量空閑資源,并且影響數據中心的能量效率。為了降低這些負面影響,數據中心管理者可以在知道實際所用資源不應超過物理服務器的容量的情況下手動地過高分配可用資源。使物理資源的容量過載可能導致共處一處的工作的性能降低,因此影響客戶的滿意度。
本發明的目的是解決上述缺點。
技術實現要素:
根據本發明,提供了一種如所附權利要求書中所述的設備和方法。本發明的其他特征從從屬權利要求以及下面的描述將是清晰的。
根據本發明的一方面,提供了一種控制數據中心的方法,所述數據中心包括執行多個工作的多個服務器,所述方法包括:
從用戶接收執行工作的請求;
確定在其上執行所述工作的分配的服務器;以及
在所述分配的服務器上執行所述工作,
其中所述確定的步驟包括:
根據所述工作的資源要求來對所述工作進行分類;
選擇所述服務器中的滿足所述工作的資源要求的子集;
確定可以以有利的能量效率執行所述工作的分配的服務器,
并且其中對時常在所述服務器上運行的所有工作的總資源估計超過所述服務器中的至少一個的資源。
所述多個工作可以是多個異類工作。
來自用戶的執行工作的請求可以包括資源估計。所述資源估計可以給出指示,或者可以指定所述工作的資源要求。
所述有利的能量效率可以是最高能量效率,所述最高能量效率可以基于工作的完成速度,工作的完成速度與所用功率的量、因此能量效率相關。
確定可以以最高能量效率執行所述工作的服務器的步驟可以包括:
計算所述服務器子集中的每個服務器的過高分配比率OAR;
在OAR給定的情況下確定每個服務器是否具有可用于執行所述工作的資源;
確定每個服務器的估計能量效率,如果所述工作被分派給所述服務器的話;以及
在具有可用資源以及最高估計能量效率的所述服務器上執行所述工作。
計算OAR的步驟可以包括:計算所述服務器的超賣利潤率;建立所述用戶的類別;使用超賣利潤率(P)從描述所述用戶的類別的過高估計模式的統計分布計算OAR。
可以根據以下公式來計算超賣利潤率:
其中R是由將所述工作分配給所述服務器引起的能量效率(EE)差,并且其中C是分配之后的EE乘以估計的EE變化。
對所述工作進行分類的步驟可以包括:在歷史跟蹤日志數據的訓練集合上訓練決策樹分類器;并且用決策樹分類器對所述工作進行分類。
選擇服務器的子集的步驟可以包括:計算服務器特征集合與工作約束集合之間的空間距離;并且選擇相似性程度等于或者大于預定最小相似性值的服務器。
所述方法可以進一步包括:檢測所述多個服務器中的至少一個中的過載事件;通過驅逐、暫停或者遷移具有最低優先度、最短運行時間的工作來解決檢測到的過載事件。
估計的EE變化可以使用估計的性能干擾來計算。
估計的性能干擾可以是共位于所述服務器上的所述多個工作生成的性能干擾的估計總計,所述估計總計是基于位于所述服務器上的每個工作的種類的。
根據本發明的另一個方面,提供了一種用于管理包括多個服務器的計算機數據中心的計算機管理系統CMS,其中每個服務器包括至少一個虛擬容器VC,所述CMS包括:
協調器服務模塊,所述協調器服務模塊被配置為:從用戶接收執行工作的請求,控制CMS確定在其上將執行所述工作的服務器,并且控制CMS執行所述工作;
工作分類服務模塊,所述工作分類服務模塊可操作來根據所述工作的資源要求來對所述工作進行分類;
資源描述推理器模塊,所述資源描述推理器模塊可操作來選擇滿足所述工作的約束集合的服務器子集;
動態狀態主機監視器模塊,所述動態狀態主機監視器模塊可操作來將每個服務器的狀態記錄在數據中心中;
數據中心通信模塊,所述數據中心通信模塊可操作來與所述多個服務器進行通信;以及
過高分配策略服務模塊,所述過高分配策略服務模塊可操作來從所述服務器子集以及所述工作的種類確定可以以有利的能量效率執行所述工作的所述服務器。
所述系統可以另外還包括用戶分類服務模塊,所述用戶分類服務模塊可操作來建立用戶的類別并且確定描述用戶的類別的過高估計模式的統計分布。
所述系統另外還包括過載管理器,所述過載管理器可操作來檢測所述多個服務器中的至少一個中的過載事件并且通過驅逐、暫停或者遷移具有最低優先度、最短運行時間的工作來解決檢測到的過載事件。
過高分配策略服務可以可操作來:計算服務器子集中的每個服務器的過高分配比率OAR;在OAR給定的情況下確定每個服務器是否具有可用于執行所述工作的資源;確定每個服務器的估計能量效率,如果所述工作被分派給所述服務器的話。
過高分配策略服務可以進一步可操作來:計算所述服務器的超賣利潤率;使用超賣利潤率(P)從描述用戶的類別的過高估計模式的統計分布計算OAR。
過高分配策略服務可以可操作來根據以下公式計算超賣利潤率:
其中R是由將所述工作分配給所述服務器引起的能量效率(EE)差,并且其中C是分配之后的EE乘以估計的EE變化。
過高分配策略服務可以使用估計的性能干擾來計算估計的EE變化。
估計的性能干擾是共位于所述服務器上的所述多個工作生成的性能干擾的估計總計,所述估計總計是基于位于所述服務器上的每個工作的種類的。
資源描述推理器可以可操作來:計算服務器特征集合與工作約束集合之間的相似性程度;并且選擇相似性程度等于或者大于預定最小相似性值的服務器。
根據本發明的另一個方面,提供了一種包括多個服務器的計算機數據中心,其中每個服務器包括至少一個虛擬容器VC,其中所述計算機數據中心合并前一方面的計算機管理系統CMS。
根據本發明的另一個方面,提供了一種具有計算機可執行組件的計算機可讀存儲介質,所述計算機可執行組件當被執行時使計算裝置執行第一個方面的方法。
附圖說明
為了更好地理解本發明以及示出本發明的實施方案可以如何付之實行,現在將以舉例的方式參照附圖,在附圖中:
圖1a是圖示根據示例性實施方案的云計算數據中心的結構的示意圖;
圖1b是圖示根據示例性實施方案的云管理系統的結構的框圖;
圖2是根據示例性實施方案的干擾和客戶知曉過高分配模塊的框圖;
圖3a是詳述根據示例性實施方案的計算過高分配比率的方法的流程圖;
圖3b是詳述根據示例性實施方案的計算過高分配比率的方法的流程圖;
圖4是詳述根據示例性實施方案的將工作分配給服務器的方法的流程圖;以及
圖5是示出根據示例性實施方案的解決過載事件的方法的流程圖。
具體實施方式
圖1a示出了包括多個服務器計算機2以及云管理系統(CMS)3的云數據中心1。
云數據中心1可以對應于位于同一個建筑物中或者位于同一個地點處的多個服務器2。可替換地,云數據中心1可以改為包括廣泛分散的并且由廣域網(比如互聯網)連接的多個服務器。
所述多個服務器2中的每個服務器2均可以包括至少一個中央處理單元(CPU)(未示出)、存儲器(未示出)以及儲存器(未示出)。所述多個服務器2中的每個服務器2進一步包括虛擬容器管理器(未示出)或者管理程序(未示出)。虛擬容器管理器(未示出)或者管理程序(未示出)可以由操作系統(OS)(未示出)(例如Linux或者Windows)托管,或者可以改為直接在服務器2的硬件上運行。
此外,所述多個服務器2中的每個服務器2均包括一個或者更多個虛擬容器21,以下稱為VC 21。
每個VC 21是計算機的虛擬的基于軟件的仿真,就如同它是物理計算機一樣提供可操作來執行至少一個軟件程序的模擬的計算機環境。
給定服務器2上多個VC 21的提供使得工作可以并行執行,并且可以提供共享比如CPU和存儲器的計算資源的高效手段。
VC 21可以被分配在服務器的資源的可以不被在VC 21中運行的任何軟件超過的固定部分上。例如,服務器2可以包括四個VC 21a-21d,每個VC被分配服務器資源的25%。
本領域技術人員將理解,服務器資源的分配可以是不均勻的,例如,服務器2的資源中分配給VC 21a的百分比可以大于VC 21b。本領域技術人員將進一步理解,資源的消耗比率可以隨著時間變化。
在根據現有技術的云數據中心中,用戶4可以向CMS 3提交他希望將被數據中心1執行的工作。用戶4可以預先指定工作的優先度以及資源估計,所述資源估計就CPU時間、存儲器使用等來詳述用戶預計該工作將消耗的資源的量。
根據該估計,CMS 3通過在服務器2上創建執行工作的VC 21來將工作分配給適當的服務器2。該分配可以至少部分基于優先度和資源估計。
依賴于資源估計的常見問題是用戶非常經常地大大地過高估計工作所需的資源。最近的研究表明,超過90%的工作被過高估計,并且在一些情況下,分配的資源的多達98%被浪費。
為了解決這個問題,CMS 3可以簡單地假定資源估計是過高估計,并且因此過高分配服務器2的資源。
圖1a還示出了被過高分配的VC 22。分配給VC 21以及被過高分配的VC 22的資源超過服務器2的實際資源。然而,簡單地假定,由于用戶4的總額過高估計,服務器2不可能用完物理資源。
過高分配的資源與實際資源的比率被稱為服務器的過高分配比率(OAR):
在現有技術(例如由或者Apache CloudStackTM管理的)的數據中心中,OAR對于所有服務器都是均勻設置的,并且是只有系統管理員可以改變的固定值。可以基于電子表格模型或者經驗法則來計算OAR。
與此相反,CMS 3可操作來對于至少一個服務器2獨立于任何其他服務器改變OAR。CMS 3可操作來至少基于以下中的一個來改變OAR:性能干擾影響、客戶過高估計模式以及能量效率度量。
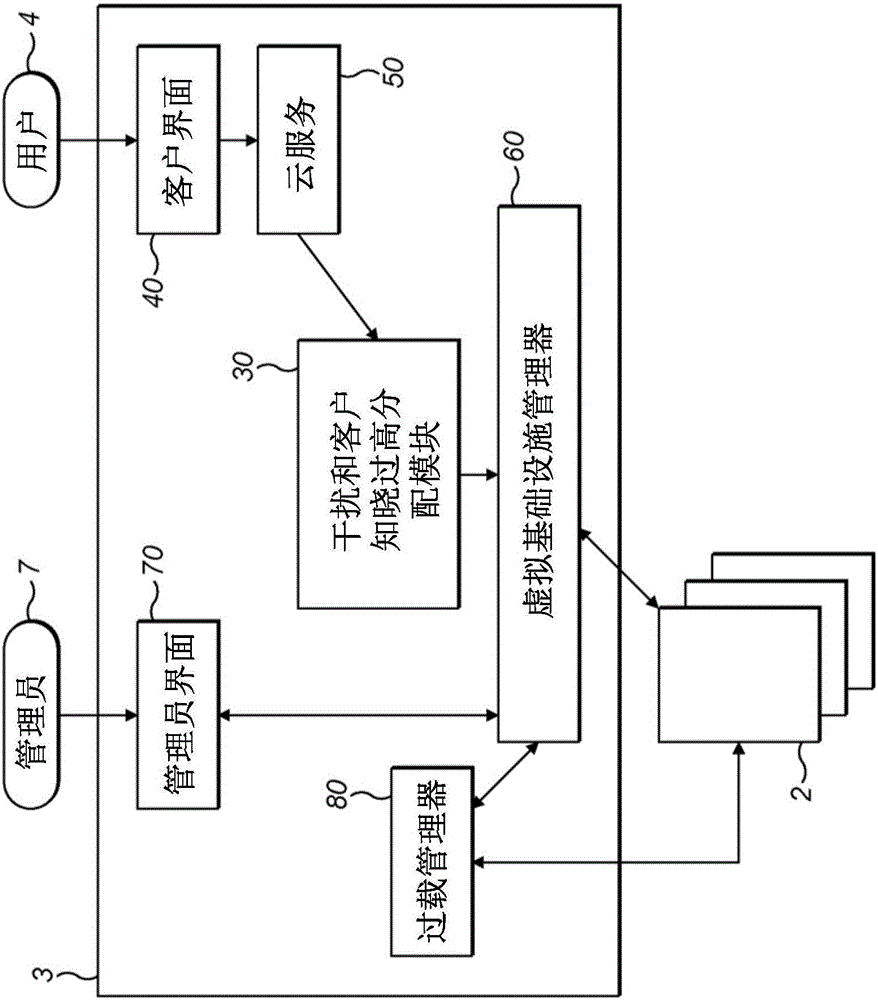
圖1b是圖示根據本發明的示例性實施方案的CMS 3的框圖。
CMS 3包括管理員界面70、客戶界面40、云服務50、干擾和客戶知曉過高分配模塊(ICAO)30以及虛擬基礎設施管理器60。
客戶界面40可操作來與至少一個用戶4進行通信并且從這些用戶4接收工作請求。
管理員界面70可操作來與管理員7進行通信。管理員7可以與管理員界面70進行通信,例如以便更新和/或修改許可、訪問權限、配額等。
虛擬基礎設施管理器60將信息發送到云數據中心1、安置在云數據中心1中的多個服務器2以及安置在所述多個服務器2中的多個VC 21,并且從它們接收信息。該信息可以包括用于控制服務器2和VC 21的控制信息以及關于服務器2和VC 21的狀態的狀態信息。
虛擬基礎設施管理器可操作來管理所述多個服務器2以及安置在所述多個服務器2上的VC 21。具體地說,虛擬基礎設施管理器60可以在所述多個服務器2上創建新的VC 21,并且在每個VC 21上執行工作。
云服務器50提供來自用戶4的工作請求與CMS 3的其他模塊之間的界面。云服務50可操作來從用戶4接收工作請求,并且對這些請求進行格式化以使得它們可以被CMS 3的其他模塊解釋。
ICAO 30可操作來選擇在其上執行工作的最高效的服務器2。ICAO 30進一步可操作來請求虛擬基礎設施管理器3在最高效的服務器1上創建VC 21并且CMS 3在該VC 21上執行工作。下面參照圖2來更詳細地描述ICAO 30。
圖2示出了根據示例性實施方案的ICAO 30的詳細視圖。
ICAO 30包括工作分類服務(JCS)31、協調器服務(COS)32、資源描述推理器(RDR)33、過高分配策略服務(OAPS)34、動態狀態主機監視器(DSM)35、資源信息服務(RIS)36以及數據中心通信模塊(DCM)38。
DCM 38可操作來與虛擬基礎設施管理器進行通信,以便將信息發送到云數據中心1、安置在云數據中心1中的多個服務器2以及安置在所述多個服務器2上的多個VM 21并且從它們接收信息。
COS 32可操作來經由云服務50從至少一個用戶4接收在數據中心1中執行工作的至少一個請求。COS 32控制ICAO 30的其他模塊以便適當地選擇在其上執行工作的最高效的服務器2。COS 32隨后請求CMS 3在最高效的服務器2上創建VC 2并且CMS 3在該VC 2上執行工作。
工作可以對應于單個軟件程序或者多個軟件程序。工作不限于任何特定類型的軟件程序,并且就它們的目的和它們的資源消耗這二者來說,可以是異類的。
RIS 36提供訪問并且利用使用模式數據的界面,該數據是通過監視所述多個服務器2對于JCS 31的資源利用模式而收集的。該數據是經由數據中心通信模塊38從所述多個服務器2收集的。該數據可以由監視器(未示出)收集,所述監視器比如允許監視VC 21的資源的Libvirt API。
RIS 36可以進一步包括資源監視數據庫(未示出)以便存儲資源使用模式。
JCS 31接收描述工作的特性的數據,根據工作的特性來對工作進行分類,并且將分類發送到COS 32。特性數據可以包括關于任務長度、CPU時間和所需存儲器的信息。
JCS 31將工作分類為小型的、中等的或者大型的。將理解,JCS 31可以可替換地將工作分類為更多的或者更少的種類。所用種類的數量可以取決于數據中心1的工作負荷特性。
JCS 31使用決策樹分類器以便對工作進行分類。決策樹分類器是使用歷史數據中心跟蹤日志信息的數據集合來進行訓練的。所用的歷史信息是由RIS 36提供的使用模式數據。
將理解,任何適當的算法可以被用來對工作進行分類,包括任何監督或者半監督的機器學習算法或者一套手動制定規則。
在示例性實施方案中,ICAO 30還包括用戶分類服務(UCS)39。
UCS 39可以使用統計模型來確定共存的用戶4的最小過高估計模式。該統計模型包括多個分布,每個分布對應于用戶4的類別。
用戶4的類別是通過歷史工作和用戶數據的分析來建立的。在示例性實施方案中,歷史數據的k均值聚類被用來建立用戶4的類別。
歷史數據包括與用戶4所擁有的工作的提交比率、估計的CPU使用以及估計的存儲器使用相關的信息。它還包括與用戶4所擁有的工作的實際CPU使用和實際存儲器使用相關的信息。歷史數據可以由RIS 36提供。
將理解,其他算法,比如監視或者半監督的機器學習算法或者一套手動制定規則,可以被用來對用戶數據進行歸類。該算法然后基于工作特性來選擇用戶類別。
每個用戶類別的過高估計分布可以是不同的,并且可以包括比如廣義極值、對數、正態、Wakeby或者3參數對數正態的分布。UCS 39可操作來將擬合優度測試應用于與每個用戶類別對應的數據以便為每個用戶類別建立適當的分布。
用戶和/或對應于他們的分布的類別被周期性地重新計算。分布可以在進一步的數據被產生時被動態地更新。
RDR 33預先選擇服務器2中的滿足傳入的工作的約束的子集。約束可以是前述特性數據和/或任何其他的用戶指定的約束。RDR 33包括維護數據中心1中的所有服務器2以及它們的特征的庫的案例庫(未示出)。
RDR 33獲取庫中所描述的服務器特征F={f1,f2,f3,...,fn}以及工作約束集合C={c1,c2,c3,...,cn},并且通過使用基于案例的推理(CBR)的檢索階段來確定它們的相似性。
CBR是人工智能技術,其中過去的案例的庫被直接用來解決問題,與通過訓練數據來形成規則或者歸納、然后使用這些規則或者歸納來解決問題的機器學習技術相反。CBR是四步處理:(1)從案例庫檢索與當前問題最相似的一個案例或者多個案例;(2)重復使用檢索的案例(一個或者更多個)來試圖解決當前問題;(3)如果必要,修訂并且改動所提出的解決方案;(4)將最終解決方案作為新案例的一部分保留。
RDR 33返回與要求匹配的預選服務器2的列表。可替換地,RDR 33可以返回相似性等于或者大于預定最小相似性值的服務器2的列表。最小相似性值由系統管理員設置,并且可以由系統管理員調整以便增強軟約束和硬約束這二者的滿足。
將理解,可以使用用于預選服務器2的任何合適的算法,并且可以利用任何相似性計算。
DSM 35將每個服務器2的狀態記錄在數據中心1中。每次VC 21被部署或者被從特定服務器2移除時,該服務器2的特性就被DSM 35確定,然后被存儲。當COS 32請求關于服務器2的特性的數據時,DSM 35可操作來將該數據發送到COS 32。服務器2的特性可以使用散列圖結構來存儲以使得能夠對服務器列表進行索引搜索。
DSM 35確定的特性可以包括資源可用性、能量效率以及組合干擾得分(CIS),所有這些都在下面描述。
服務器s的資源可用性A可以針對每個資源r={CPU,memory,disk,bandwidth}基于最大服務器可用性Max(r,s)以及對于每個部署的VC的Alloc(r,vc)的當前分配的和來確定。最大服務器可用性Max(r,s)考慮到服務器s的物理容量以及對服務器s估計的OAR。可以根據以下公式來計算資源可用性A:
服務器的能量效率EE按照正被計算的工作w(其可以就百萬指令數來測量)與以瓦特為單位的所用功率P(u)的比率來計算。可以根據以下公式來計算能量效率:
P(u)=ΔPow.u+(P(α)-ΔPow.α)
其中u是系統使用率,α和β是根據預定服務器剖析處理的使用率下水平和上水平。
CIS是單個物理服務器2上的多個VC 21a-d之間的干擾的測量。隨著給定服務器2上的VC 21的數量增加,VC 21之間對于服務器2的物理資源的競爭也增加。高競爭可能導致工作的頻繁交換和/或資源的低效使用。因此,性能干擾可能對在VC 21中運行的工作的執行速度有負面影響。
根據以下公式計算CIS:
其中n是共位于服務器s中的VC的總數,Pi是當VCi與其他VC組合時VCi的性能,而Bi是當VCi隔離運行時VCi的性能。
COS 32從JCS 31、RDR 33和DSM 35接收信息,并且將該信息提供給OAPS 34。COS32還可以從UCS 39接收信息,并且將該信息提供給OAPS 34。OAPS 34可操作來確定適合于用戶4請求的工作的分配的服務器2。
OAPS 32就過高分配的資源的量計算具有最高預期能量效率的服務器2,并且將工作分配給該服務器。
此外,OAPS 32可操作來確定適合于服務器2的過高分配比率(OAR)。OAR可以參照描述如下比率的統計模型來計算,在該比率,特定類型的客戶端過高估計它們的所需資源。
下面參照圖3a、3b和4來詳細描述OAPS 32用來計算OAR的算法。
圖3a是示出計算給定服務器2的OAR的方法的流程圖。
首先,在步驟S301中,使用UCS 39來確定用戶類別。第二,在步驟S302中,所述算法計算超賣利潤率P。最后,在步驟S303中,所述算法從P和用戶類別計算過高分配比率。
下面參照圖3b來更詳細地解釋計算OAR的方法。
首先,在步驟S311中,使用UCS 39來確定用戶類別。
第二,在步驟S312中,使用JCS 31來確定工作的種類。
第三,在步驟S313中,所述算法計算與超賣相關聯的能量效率收益R的估計。R被定義為由將工作分配給給定服務器2引起的能量效率(EE)差:
R=EE(afterAllocation)-EE(current)
其中EE是根據與以上參照DSM 35的函數定義的相同公式來計算的。
第四,在步驟S314中,所述算法計算與超賣相關聯的能量效率成本C的估計。
C是分配之后的EE乘以估計的EE變化(EstΔEE)。估計的EE變化(EstΔEE)考慮到就CIS(EstCIS)測量的估計的性能干擾:
C=EE(afterAllocation)*EstΔEE
EstΔEE=EstΔEE(EstCIS)
EstCIS是如果工作被分配給服務器,CIS的估計。具體地說,EstCIS是共位于特定服務器2上的所有工作生成的總計干擾的估計,該估計是基于位于服務器2上的每個工作的種類的。每個工作的種類可以由JCS 31建立。
在示例性實施方案中,通過測量與工作種類的每個可能的配對組合相關聯的CIS來推導EstCIS。給定表示小型工作、中等工作和大型工作的三個工作種類,對于以下配對組合來測量CIS:(小型,小型)、(小型,中等)、(小型,大型)、(中等,中等)、(中等、大型)、(大型、大型)。然后從這些配對-組合CIS測量計算特定服務器2的EstCIS。
EstCIS可以通過相關配對的簡單加法來計算。例如,具有大型工作、小型工作和中等工作的服務器的EstCIS可以通過測量的與配對組合(小型,大型)、(小型,中等)和(中等,大型)相關聯的CIS的加法來計算。
本領域技術人員將理解,任何合適的算法可以可替換地被用來基于共位于特定服務器2上的工作的特性來估計CIS。
隨后,在步驟S315中,所述算法計算超賣利潤率P。根據以下公式來計算P:
利潤率P隨后被用作統計模型中的參數,以便計算服務器2的OAR。
隨后,在步驟S316中,使用UCS 39來確定考慮到所有的共處一處的用戶和新用戶的用戶類別的最小過高估計模式。
最后,在步驟S317中,根據以下公式來計算OAR:
OAR=1+inverseCDF(minOverestimation,P)
其中inverseCDF是最小用戶過高估計模式的分布的逆累積分布函數。
將理解在替換示例性實施方案中,可以從OAR的計算省略UCS 39進行的用戶分類。在這些替換示例性實施方案中,可以改為對所有用戶都假定單個用戶類別。
如圖4的流程圖所示,OAPS 34計算數據中心1中的每個服務器2的OAR。
首先,在步驟401中,將表示最大EE(afterAllocation)的值設置為-1,該值被稱為maxEE。
對于數據中心1中的每一個服務器2,計算OAR(S403)。使用圖3b所示的以及在上面描述過的方法來計算OAR。
如果鑒于計算的OAR,服務器2不具有可用于接手工作的資源,則所述方法移到數據中心1中的下一個服務器2(S404)。服務器2的資源的可用性可以由DSM 35建立。
如果另一方面,服務器2具有可用資源,則確定EE(afterAllocation)是否大于目前存儲的maxEE(S405)。
如果EE(afterAllocation)小于或者等于maxEE,則所述方法移到下一個服務器2。如果EE(afterAllocation)大于maxEE,則在移到下一個服務器2之前用EE(afterAllocation)的值取代目前存儲的maxEE。
當所有服務器2都已經被分析(S402)時,對應于maxEE的服務器2被分配工作(S407)。
由此,具有可用來執行工作的資源和最大EE(afterAllocation)的服務器2被分配工作。
因此,OAPS 34能夠以節省數據中心能量消耗并且還考慮到用戶4過高估計工作所需資源的趨勢以及由競爭工作引起的性能干擾這二者的方式將工作分配給服務器2。
此外,OAPS 34能夠計算數據中心2中的每個服務器2的OAR,OAR反映用戶資源過高估計。
OAPS 34將將被分配工作的服務器2的身份提供給COS 32。COS 32然后將服務器2的身份提供給CMS 3,CMS 3在服務器2上執行工作。
返回到圖1b,CMS 3可以進一步包括過載管理器(OM)80。OM 80負責檢測并且緩解過載事件的發生。
當所需資源的量超過給定服務器2上的資源的物理限值時,過載事件發生。
OM 80從數據中心1中的每個服務器2接收數據。該數據包括關于共處一處的工作負荷的資源消耗的信息,并且可以由監視器(未示出)收集,所述監視器比如Libvirt API。
OM 80然后使用該數據來確定服務器2中的哪個(如果有的話)過載。過載然后通過OM 80重復地移除優先度最低的那些工作來停止。如果多于一個的工作具有相同的優先度,則驅逐運行時間最短的工作。
參照圖5來描述解決過載事件的方法。
OM 80可以遍歷數據中心1中的服務器2的列表來迭代進行。在步驟S501中,開始檢查列表上的下一個服務器的過程。
在步驟S502中,確定正被檢查的服務器是否正在經歷過載事件。
如果服務器過載,則從服務器驅逐優先度最低、運行時間最短的工作(S503)。
如果服務器仍過載,則重復所述處理,直到過載停止為止。
當過載停止時,OM 80移到列表中的下一個服務器,并且開始檢查過程。如果沒有剩下更多的服務器要檢查,則所述處理結束(S504)。
被OM 80驅逐的這些工作可以被重新發送到ICAO 30以供用于重新分配。
本領域技術人員將理解,OM 80識別的工作可以改為被暫停或者被遷移。
OM 80可以被周期性地執行,并且只需要與虛擬基礎設施管理器60和所述多個服務器2進行交互來執行所需的驅逐。
上述系統和方法可以有利地使得數據中心1可以通過過高分配物理資源2的容量來克服用戶4對于所需資源的過高估計。
有利地,所述系統和方法可以允許對數據中心1中的每個服務器2計算過高分配比率,而不是單個比率應用于整個數據中心1中的每個服務器2。
另外,過高分配比率可以反映數據中心1的用戶4的過高分配模式。過高分配比率還可以反映由在服務器2上運行的工作的數量和類型引起的性能干擾。過高分配比率還可以考慮到所做的分配的能量效率,從而便利能量效率更高的數據中心1。
有利地,過載管理器37可以解決由錯誤的過高分配引起的過載事件,從而改進數據中心1的性能。
本文中所描述的示例實施方案中的至少一些可以部分地或者整個地通過使用專用的特殊用途的硬件來構造。本文中所使用的比如“組件”、“模塊”或者“單元”的術語可以包括但不限于執行某些任務或者提供相關聯的功能的硬件裝置,比如分立組件或者集成組件的形式的電路、現場可編程門陣列(FPGA)或者專用集成電路(ASIC)。
在一些實施方案中,所描述的元素可以被配置為駐留在有形的、持久的、可尋址的存儲介質上,并且可以被配置為在一個或者更多個處理器上執行。在一些實施方案中,這些功能元素可以包括舉例來說組件(比如軟件組件、面向對象的軟件組件、類組件以及任務組件)、處理、功能、屬性、過程、子例程、程序代碼段、驅動器、固件、微代碼、電路、數據、數據庫、數據結構、表格、數組以及變量。
盡管已經參照本文中所討論的組件、模塊和單元描述了示例實施方案,但是這樣的功能元素可以被組合為更少的元素或者被劃分為附加的元素。本文中已經描述了可選特征的各種組合,將意識到,所描述的特征可以按任何合適的組合進行組合。具體地說,任何一個實例實施方案的特征可以視情況與任何其他實施方案的特征組合,除了這樣的組合相互排斥的情況之外。在整個本說明書中,術語“包括”意指包括所指定的組件(一個或者更多個),但是不排除其他組件的存在。
注意與有關本申請的本說明書同時提交的或者之前提交的并且通過本說明書向公眾開放查閱的所有論文和文件,所有這樣的論文和文件的內容都通過引用并入本文。
本說明書(包括任何所附權利要求書、摘要和附圖)中所公開的所有特征和/或如此公開的任何方法或者處理的所有步驟都可以按任何組合進行組合,除了這樣的特征和/或步驟中的至少一些相互排斥的組合之外。
本說明書(包括任何所附權利要求書、摘要和附圖)中所公開的每個特征可以被提供相同的、等同的或者相似的目的的替換特征取代,除非另有明確陳述。因此,除非另有明確陳述,所公開的每個特征都僅僅是等同或者相似特征的一般系列的一個實施例。
本發明不限于前述實施方案(一個或者更多個)的細節。本發明擴展到本說明書(包括任何所附權利要求書、摘要和附圖)中所公開的特征的任何新穎的發明或者任何新穎的組合以及如此公開的任何方法或者處理的步驟的任何新穎的發明或者任何新穎的組合。
- 還沒有人留言評論。精彩留言會獲得點贊!