一種微博賬號分類的方法與流程
本發明涉及一種微博賬號分類的方法。
背景技術:
在當今互聯網高速發展的時代,社交網絡日益成為人們互聯網生活的重要組成部分,其中微博這種社交網絡服務更是成為了最紅火的概念。微博是一個基于用戶關系的信息分享、傳播以及獲取平臺,用戶可以通過WEB、WAP以及各種客戶端組建個人社區,以140字以內的文字更新信息,并實現即時分享。
由于各類微博對用戶的技術門檻都很低,同時微博應用程序編程接口的存在使得用戶可以在各種移動終端上登錄微博發布消息,這也加速了微博的發展。隨著高速發展而來的是各種各樣的問題,僵尸賬號、廣告賬號、機器賬號及其帶來的虛假粉絲、內容污染和輿論誤導等問題日益嚴重。國內外有專家學者已經開始研究異常賬號的檢測和垃圾內容的過濾技術。微博服務提供商也建立了諸如手機號注冊、用戶舉報等措施來限制異常賬號的泛濫。
但是,現有的方法中,都是只能識別出異常賬號跟普通賬號,無法準確識別出賬號具體為哪一種類型的微博賬號,并且識別效率也相當低。
技術實現要素:
本發明主要解決的技術問題是如何提供一種能夠高效準確識別微博賬號類型的方法。
有鑒于此,本發明實施例提供一種微博賬號分類的方法,能夠準確區分普通賬號跟異常賬號,并且還能夠識別出賬號具體屬于哪一類型的賬號。
為解決上述技術問題,本發明采用的一個技術方案是:提供一種微博賬號分類的方法,所述方法包括:獲取未知類型的微博賬號對應的微博數據;對所述微博數據進行特征提取得到微博數據特征;根據所述微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定所述微博賬號的類型。
其中,所述微博賬號的類型為僵尸賬號、廣告賬號、機器賬號或普通賬號中的一種。
其中,所述在獲取微博賬號對應的微博數據之前,還包括:獲取已知類型的微博賬號的微博數據;對所述已知類型的微博賬號的微博數據進行特征提取,得到已知類型的微博賬號的微博數據特征;對所述已知類型的微博賬號的微博數據特征進行機器學習訓練,從而建立按微博數據特征劃分的分類模型。
其中,所述對所述已知類型的微博賬號的微博數據特征進行機器學習訓練,從而建立按微博數據特征劃分的分類模型包括:通過10折交叉驗證的方法,對所述已知類型的微博賬號的微博數據進行機器學習訓練,從而建立按微博數據特征劃分的分類模塊。
其中,所述對所述已知類型的微博賬號的微博數據特征進行機器學習訓練,從而建立按微博數據特征劃分的分類模型包括:分別采用隨機森林、樸素貝葉斯和梯度回歸分類算法中的至少一種,對所述已知類型的微博賬號的微博數據特征進行機器學習訓練,從而建立按微博數據特征劃分的分類模型。
其中,采用隨機森林算法對僵尸賬號的微博數據特征進行機器學習訓練;采用樸素貝葉斯算法對廣告賬號的微博數據特征進行機器學習訓練;采用梯度回歸算法對機器賬號的微博數據特征進行機器學習訓練。
其中,所述獲取微博賬號對應的微博數據包括:通過微博應用程序編程接口或通過網絡爬蟲的方式獲取未知類型微博賬號對應的微博數據。
其中,所述微博數據特征包括用戶資料特征、微博內容特征、交互行為特征和發布行為模式特征中的至少一種。
其中,所述根據所述微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定所述微博賬號的類型之后,還包括:通過分類算法對已確定的僵尸賬號、廣告賬號、機器賬號以及普通賬號進行二分類。
其中,所述通過分類算法對已確定的僵尸賬號、廣告賬號、機器賬號以及普通賬號進行二分類包括:
通過隨機森林分類算法對僵尸賬號和其余三種賬號集合進行二分類;通過樸素貝葉斯分類算法對廣告賬號、普通賬號以及機器賬號的集合進行二分類;以及通過梯度回歸分類算法對機器賬號和普通賬號的集合進行二分類。
本發明的有益效果是:區別于現有技術的情況,本發明通過對微博賬號對應的微博數據進行特征提取得到微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定微博賬號的類型。由于分類模型是通過對數量龐大的已知類型微博賬號對應的微博數據進行機器學習訓練而得到,因此,分類模型非常全面和具有代表性,通過分類模型對微博賬號的類型進行確定,從而可以對微博賬號的識別和分類能夠更加高效和準確。
附圖說明
圖1是本發明實施例提供的一種微博賬號分類的方法的流程圖;
圖2是本發明實施例提供的建立按微博數據特征劃分的分類模型的
流程圖;
圖3a是性別特征分析示意圖;
圖3b是頭像特征分析示意圖;
圖3c是簡介特征分析示意圖;
圖3d是昵稱特征分析示意圖;
圖3e是微博書CDF圖;
圖3f是粉絲數CDF圖;
圖3g是粉絲度CDF圖;
圖3h是粉絲關注比CDF圖;
圖4是微博內容特征分析示意圖;
圖5a是原創微博數CDF圖;
圖5b是評論數CDF圖;
圖6是發布行為特征分析圖示意圖;
圖7是特征重要度對比圖示意圖;
圖8是用戶成分分析示意圖;
圖9是本發明實施例提供的微博賬號分類的裝置的結構示意圖。
具體實施方式
請參閱圖1,圖1是本發明實施例提供的一種微博賬號分類的方法的流程圖,如圖所示,本實施例的微博賬號分類的方法包括以下步驟:
S101:獲取未知類型的微博賬號對應的微博數據。
本發明實施例中,微博數據的獲取可以采用微博應用程序編程接口(Application Programming Interface,API)和網絡爬蟲兩種方法。但微博API接口對訪問頻率和屬性獲取有較大限制。因此作為本發明的優選實現方案,采用網絡爬蟲的方式獲取微博數據。基于網絡爬蟲原理實現完成了微博爬蟲工具,該爬蟲工具能夠獲得微博頁面上所有能呈現出的所有微博數據,并且將獲得的原始微博數據進行預處理,最終存入數據庫。
在具體實現時,微博數據的獲取除了完成基本屬性值數據的獲取,同時獲取每個賬號的最新500條微博,若微博數不足500條的,將其所有微博內容全部獲取。爬取過程可以采取多臺計算機分擔微博數據爬取任務,避免爬取時間造成的屬性差異。
S102:對微博數據進行特征提取得到微博數據特征。
根據當前微博特點,本發明實施例抽取并擴展出4類微博數據特征:用戶資料特征、微博內容特征、交互行為特征和發布行為模式特征,綜合考慮多種類型賬號特征能夠提高賬號類型識別準確率。
其中,本發明實施例所述擴展出的4類微博數據特征的特征集合請參閱下表1(加※為本發明新提出的特征):
表1:微博數據特征的特征集合
S103:根據微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定微博賬號的類型。
其中,本發明實施例中的微博賬號的類型為僵尸賬號、廣告賬號、機器賬號或普通賬號中的一種。
分類模型的目的是建立一個能夠描述給定賬號在賬號類型中的出現頻次或概率的分布。即利用分類模型,可以確定某一賬號為哪個類型 賬號的可能性更大。通過分類模型,可以對未知類型的賬號進行類型識別與區分。
具體針對一個未知類型賬號進行分類時,首先輸入該賬號的用戶身份證明(User Identification,UID),然后通過微博爬蟲工具獲取其相關數據,基于數值型特征集合生成基于數值型特征集合生成特征向量1和特征向量3,基于用戶發布過得微博文本內容,生成特征向量2,根據特征向量,通過分類模型采用排除法確定賬號類型。
舉例而言,1)使用特征向量1判斷是否是僵尸賬號,若是,則停止判斷,若不是,則繼續下一步;2)基于用戶發布過得微博文本內容,生成特征向量2;3)使用特征向量2判斷是否是廣告賬號,若是,則停止判斷,若不是,則繼續下一步;4)使用特征向量3判斷是否是機器賬號,若是,則停止判斷,若不是,則判定為普通賬號。
為了進一步確保分類的準確性,本發明實施例的方法在通過分類模型初步確定賬號類型后,進一步通過分類算法對已確定類型的賬號(即僵尸賬號、廣告賬號、機器賬號以及普通賬號)進行二分類。
其中,針對僵尸賬號和機器賬號的識別均采用抽取出的數值型特征集合構成特征向量,分別通過分類算法進行普通賬號和僵尸賬號、普通賬號和機器賬號的二分類。
其中,作為本發明實施例的一種優選的實現方案,通過隨機森林分類算法對僵尸賬號和其余三種賬號的集合進行二分類,通過樸素貝葉斯分類算法對廣告賬號、普通賬號以及機器賬號的集合進行二分類,以及通過梯度回歸分類算法對機器賬號和普通賬號的集合進行二分類。
作為一種優選,采用文本分類的通用方法進行普通賬號和廣告賬號的二分類,以進一步確定賬號為普通賬號還是廣告賬號。
文本分類要做如下4個預處理動作:
1、選擇微博廣告和非廣告文本數據集;
2、微博文本預處理:分詞、去停用詞、建立詞袋模型;
3、選擇文本分類使用的特征向量:詞頻表征特征權重;
4、量化訓練數據集和測試數據集文件。
其中廣告微博內容涉及各種電商賣家廣告、代購廣告、微商廣告等,廣告內容類型多樣,但其中含有一些共同的明顯的營銷詞匯,比如打折、優惠、包郵、購買、正品、限量等,這些具有區分性的詞匯便是文本分類的關鍵。同時,將所有不具有廣告意圖的微博內容歸為普通用戶發布的非廣告微博。
本發明通過針對僵尸賬號、廣告賬號和機器賬號這三種異常賬號,結合普通賬號樣本集,分別做二分類測試,對比不同分類算法分類效果,詳見表2-表4。
表2:廣告賬號識別分類算法的分類效果對比
表3:僵尸賬號識別分類算法的分類效果對比
表4:機器賬號識別分類算法的分類效果對比
由上表2-表4的效果對比可以發現,對于廣告賬號和普通賬號的進一步識別中用到的文本分類算法,樸素貝葉斯分類算法效果較好;對于僵尸賬號和機器賬號的進一步識別中用到的分類算法,隨機森林和梯度回歸算法更有效。
當然,基于以上分類效果對比,在具體應用過程中,可以根據賬號類型分別選取準確率(或F-score)最高的3個分類算法對賬號進行二分類。
經過本發明的方法,可以確定微博賬號的分布趨勢,圖8是本發明實施例對預定數量的賬號進行分類后所統計的用戶分布示意圖。
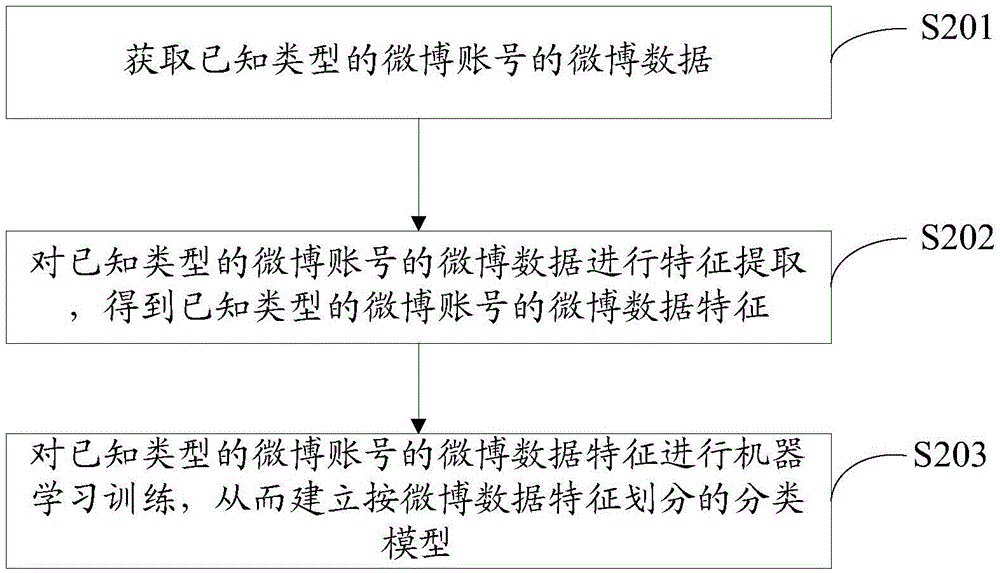
本發明中的分類模型是基于已知類型賬號的微博數據不斷通過機器學習和訓練而得到。本發明實施例進一步提供建立按微博數據特征劃分的分類模型的方法。請參閱圖2,圖2是本發明實施例提供的建立按微博數據特征劃分的分類模型的流程圖,如圖所示,建立按微博數據特征劃分的分類模型包括以下步驟:
S201:獲取已知類型的微博賬號的微博數據。
其中,已知類型的微博賬號來源于人工標記或者電商購買的標記樣本。人工標記,即手動查看每個微博賬號的資料及微博動態來判定賬號類型。電商購買,隨著微博的盛行,電子商務網站上已經出現了很多微博服務商品,比如可以購買微博粉絲、微博賬號,甚至一條微博的轉發 量和點贊數都可以買到,其中賣家出售的微博粉絲,其中就是低級粉絲即僵尸賬號,高級粉絲即機器賬號,通過直接購買粉絲的方式,可以減少大量人力。
在本實施例具體實現時,僵尸賬號共標記2000個,其中1500個來自兩個淘寶賣家的低級微博粉絲,另外500個通過人工標記。標記的依據是:1)無頭像或系統默認頭像;2)關注數遠大于粉絲數;3)微博數較少且無轉發和評論;4)用戶昵稱為簡單的字母和數字組合或漢字和數字組合;5)用戶資料填寫內容少或無。綜合考慮以上5個方面來判斷一個賬號是否為僵尸賬號。通過觀察微博,發現很多娛樂明星和認證公司(推銷商品)的粉絲中存在大量僵尸賬號,有的娛樂明星希望通過百萬甚至千萬級的粉絲數來提高自己的知名度,認證公司希望購買僵尸賬號提高粉絲數,從而吸引普通微博用戶的關注,所以僵尸賬號的收集目標就集中在娛樂明星和認證公司的粉絲列表中。
廣告賬號共標記1000個,全部來自人工標記。標記的依據是:1)微博內容以廣告、促銷和抽獎等為主;2)用戶簡介中有店鋪鏈接、微信號或商品介紹;3)微博中的鏈接多為商品買賣鏈接。
機器賬號共標記2000個,其中1500個來自淘寶購買的高級微博粉絲,400個通過人工標記,100個來自相關研究中使用到的機器賬號樣本。人工標記的依據是:1)微博發布時間規律性強,每隔一定時間發布一條微博;2)微博內容主題是心靈雞湯、名人名言、笑話、天氣、星座運勢等,微博內容也可能以廣告為主,有很大嫌疑是通過調用現成的語料庫來自動發布這些內容微博;3)微博內容重復度高,不同的機器賬號可能使用同一些語料庫;4)微博發布平臺種類少,部分機器賬號的微博發布平臺能明顯的說明使用了第三方軟件,如皮皮時光機、云中小鳥、孔明社交管理等。
普通賬號共標記3000個,全部來自人工標記。標記依據是:1)粉絲數和微博數較多;2)用戶頭像是真實照片;3)用戶資料填寫詳細;4)微博內容有日常生活氣息,如有個人生活內容分享;5)微博有被轉發或評論,同時又回復。收集方法:一是從自己的現實好友出發,然后 再判斷現實好友的粉絲和關注,接著遞歸判斷粉絲的粉絲和關注、關注的粉絲和關注。而是從熱門微博和熱門話題下面尋找積極評論和互動的賬號。
微博數據的獲取可以采用微博應用程序編程接口(Application Programming Interface,API)和網絡爬蟲兩種方法。但微博API接口對訪問頻率和屬性獲取有較大限制。因此作為本發明的優選實現方案,采用網絡爬蟲的方式獲取微博數據。基于網絡爬蟲原理實現完成了微博爬蟲工具,該爬蟲工具能夠獲得微博頁面上所有能呈現出的所有微博數據,并且將獲得的原始微博數據進行預處理,最終存入數據庫。
在具體實現時,微博數據的獲取除了完成基本屬性值數據的獲取,同時獲取每個賬號的最新500條微博,若微博數不足500條的,將其所有微博內容全部獲取。爬取過程可以采取多臺計算機分擔微博數據爬取任務,避免爬取時間造成的屬性差異。
S202:對已知類型的微博賬號的微博數據進行特征提取,得到已知類型的微博賬號的微博數據特征。
根據當前微博特點,本發明實施例抽取并擴展出4類微博數據特征:用戶資料特征、微博內容特征、交互行為特征和發布行為模式特征,綜合考慮多種類型賬號特征能夠提高賬號類型識別準確率。其中,不同微博數據特征的特征集合請參閱上述表1(加※為本發明新提出的特征),在此不再贅述。
用戶資料特征(表1中1-10號特征)來自用戶比較直觀的資料信息。其中微博年齡是從賬號注冊時間到2015年1月1日截止賬號存在天數;
其中,圖3(a)-圖3(h)分別示出用戶基本特征分析示意圖,從圖中可知,四種類型賬號的男女比例分布較為隨機,不具有較好區分性;頭像有無、昵稱和簡介有無填寫能夠較好的區分僵尸賬號和其他類型賬號;機器賬號由于使用自動化程序控制,所以發布微博數更多,僵尸賬號幾乎不發布微博;機器賬號初期會發布大量某一主題微博,如笑話、星座、美景圖片等特定主題類型的機器微博賬號吸引了大量的粉絲,其粉絲數 遠大于關注數,而僵尸賬號關注數遠大于粉絲數,廣告賬號和正常賬號則粉絲數和關注數相當。
微博內容特征(表1中11-14號特征)根據微博內容中包含的特殊內容抽取得來。
其中,圖4是微博內容特征分析示意圖,從圖4可知,機器賬號在大量發布微博同時還會較多地@好友,希望好友能夠轉發該微博或進行評論等,增加機器賬號的人為特性。相反,僵尸賬號幾乎不@好友。所以@數可以作為區分機器賬號和正常賬號、僵尸賬號和正常賬號的特征。
交互行為特征(表1中15-23號特征)表示微博賬號和其他賬號互動情況。圖5(a)-圖5(b)是交互行為特征分析示意圖,從圖5a-圖5b表明,機器賬號由于使用了語料庫,幾乎不轉發微博,大部分為原創微博;80%的機器賬號評論數小于150,而大約60%的正常賬號評論數都超過500,即正常賬號更具有評論交互意向,機器賬號要實現自動評論或回復復雜度較大。
發布行為特征(表1中24-34號特征)代表微博賬號發布行為模式。通過對微博賬號的觀察發現,大部分機器賬號以一定的時間間隔自動發布微博,有的甚至24小時連續定時發布微博,有的會稍有偽裝,避開0-6點休息時間發微博。機器賬號微博發布時間更有規律,普通賬號則顯得無規律可循。使用熵率來度量微博用戶發布微博時間規律性。
隨機變量序列X={Xi}由一個微博用戶所發微博的時間間隔隨機變量組成,Xi表示第i條和第i+1條微博之間的時間間隔隨機變量序列X的熵記為
其中P(xi)是P(Xi=xi)的概率。當已知該序列的前m-1項時,其條件信息熵記為:
CE(Xm|Xm-1)=H(Xm|X1,…,Xm-1)=H(X1,…,Xm)-H(X1,…,Xm-1) (2)
用戶發微博的時間間隔構成的序列都是有限序列,而信息熵衡量的是一個無窮隨機過程,無法直接用來計算有限的序列。引入修正的條件信息熵來解決序列有限性所帶來的問題。修正的條件信息熵的公式如下:
CCE(Xm|X1,...,Xm-1)=CE(Xm|X1,...,Xm-1)+perc(Xm)·EN(X1) (3)
其中perc(Xm)是在長度為m的序列里面只出現過一次的序列所占的比例,EN(X1)是當m=1時的信息熵。當序列長度取[2,m]中的不同值時,分別計算出相應的修正條件信息熵的值,最終熵率取其中最小值。如果該賬號是機器賬號,那它的行為會有一定的規律性,因而其修正條件信息熵的值會較小。與之相反,普通賬號的行為隨機化程度較高,修正的條件信息熵值也會較大。
針對行為模式特征中的信息熵,將機器賬號和普通賬號的發微博時間間隔序列輸入后,利用式(3)得到每位賬號用戶的修正條件。
圖6是機器賬號和普通賬號各自修正條件信息熵的累積分布函數。由圖6可知,機器賬號的修正條件信息熵明顯比普通賬號的修正條件信息熵小,說明賬號的發微博行為存在較強的規律性,而普通賬號的發微博行為比較隨機,驗證了前面對用戶發微博行為的分析結果。
針對廣告賬號的識別,只需要檢測賬號發布微博內容是否為廣告內容即可,所以使用發布微博文本內容這一特征,實際在文本分類中又將這一特征分解為文本特征向量;針對僵尸粉的識別,根據特征分析,選擇使用是否有頭像、是否填寫簡介、昵稱是否包含數字、粉絲數、關注數、微博數這6個數值型特征即可;針對機器賬號的識別根據特征分析,選擇使用是否填寫簡介、昵稱是否包含數字、粉絲數、關注數、微博數、微齡、粉絲度、關注度、粉絲關注比、微博含圖片數、原創數、 轉發數、評論數、被評論數、回復數、自轉數、微博發布時間間隔熵、日均發布微博數、0-6點的平均微博數、6-12點的平均微博數、12-18點的平均微博數、18-24點的平均微博數、發布平臺數、發布IP數、發布ISP數、發布省份數、發布城市數共29個數值型特征。特征數據分析不僅通過條形圖、CDF圖來展示,還通過具體分類模型計算了特征的重要。
圖7是用于普通賬號和機器賬號分類的34個特征的重要性排名前20對比圖,通過特征重要度排名,可以進一步進行特征選擇,在保證分類準確度的基礎上加快賬號分類速度。實際應用中可以綜合考慮分類準 確度和分類速度兩個指標,選擇可接受的分類準確度和分類速度。
S203:對已知類型的微博賬號的微博數據特征進行機器學習訓練,從而建立按微博數據特征劃分的分類模型。
在具體實現時,可以采用10折交叉驗證的方法,使用已標記樣本數據集,訓練分類模型,通過實驗實際測試各個分類算法在微博賬號分類中的效果。
其中,利用第三方機器學習工具包Scikit-Learn,對不同的分類算法進行性能測試。Scikit-Learn是操作簡單、高效的機器學習和數據分析工具,其中包含的機器學習模型非常豐富,包括支持向量機SVM,決策樹,隨機森林,梯度回歸分類算法、樸素貝葉斯,GBDT,鄰近算法KNN等等,可以根據數據特征選擇合適的模型進行機器學習訓練得到分類模型。
以上是本發明實施例提供的一種微博賬號分類的方法的詳細說明,可以理解,本發明通過對微博賬號對應的微博數據進行特征提取得到微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定微博賬號的類型。由于分類模型是通過對數量龐大的已知類型微博賬號對應的微博數據進行機器學習訓練而得到,因此,分類模型非常全面和具有代表性,通過分類模型對微博賬號的類型進行確定,從而可以對微博賬號的識別和分類能夠更加高效和準確。
本發明的方法是建立在分析用戶的基本資料、微博內容、交互行為、發布行為4類特征上,這4類特征可有效的描述一個微博用戶的特點,實現微博賬號的識別與多分類,使得賬號的識別具有更高的主動性和精確性。并且能夠對賬號進行細分到具體的類型。
請進一步參閱圖9,圖9是本發明實施例提供的一種微博賬號分類的裝置的結構示意圖,本實施例的微博賬號分類的裝置用于執行上述實施例的方法。如圖所示,本實施例的微博賬號分類的裝置100包括獲取模塊11、特征提取模塊12以及確定模塊13,其中:
獲取模塊11用于獲取未知類型的微博賬號對應的微博數據。
本發明實施例中,獲取模塊11可以采用微博應用程序編程接口(Application Programming Interface,API)和網絡爬蟲兩種方法獲取微 博數據。但微博API接口對訪問頻率和屬性獲取有較大限制。因此作為本發明的優選實現方案,采用網絡爬蟲的方式獲取微博數據。基于網絡爬蟲原理實現完成了微博爬蟲工具,該爬蟲工具能夠獲得微博頁面上所有能呈現出的所有微博數據,并且將獲得的原始微博數據進行預處理,最終存入數據庫。
在具體實現時,微博數據的獲取除了完成基本屬性值數據的獲取,同時獲取每個賬號的最新500條微博,若微博數不足500條的,將其所有微博內容全部獲取。爬取過程可以采取多臺計算機分擔微博數據爬取任務,避免爬取時間造成的屬性差異。
特征提取模塊12對微博數據進行特征提取得到微博數據特征。
根據當前微博特點,本發明實施例抽取并擴展出4類微博數據特征:用戶資料特征、微博內容特征、交互行為特征和發布行為模式特征,綜合考慮多種類型賬號特征能夠提高賬號類型識別準確率。特征提取模塊12對微博數據進行特征提取,根據微博數據特征生成微博數據特征值向量。
確定模塊13根據微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定微博賬號的類型。
其中,本發明實施例中的微博賬號的類型為僵尸賬號、廣告賬號、機器賬號或普通賬號中的一種。
分類模型的目的是建立一個能夠描述給定賬號在賬號類型中的出現頻次或概率的分布。即利用分類模型,可以確定某一賬號為哪個類型賬號的可能性更大。通過分類模型,可以對未知類型的賬號進行類型識別與區分。
具體針對一個未知類型賬號進行分類時,首先輸入該賬號的用戶身份證明(User Identification,UID),然后通過微博爬蟲工具獲取其相關數據,基于數值型特征集合生成基于數值型特征集合生成特征向量1和特征向量3,基于用戶發布過得微博文本內容,生成特征向量2,根據特征向量,通過分類模型采用排除法確定賬號類型。
舉例而言,1)使用特征向量1判斷是否是僵尸賬號,若是,則停 止判斷,若不是,則繼續下一步;2)基于用戶發布過得微博文本內容,生成特征向量2;3)使用特征向量2判斷是否是廣告賬號,若是,則停止判斷,若不是,則繼續下一步;4)使用特征向量3判斷是否是機器賬號,若是,則停止判斷,若不是,則判定為普通賬號。
為了進一步確保分類的準確性,本發明實施例的確定模塊在通過分類模型初步確定賬號類型后,進一步通過分類算法對已確定類型的賬號(即僵尸賬號、廣告賬號、機器賬號以及普通賬號)進行二分類。
其中,確定模塊13在對以確定類型的賬號進行二分類時,針對僵尸賬號和機器賬號的識別均采用抽取出的數值型特征集合構成特征向量,分別通過分類算法進行普通賬號和僵尸賬號、普通賬號和機器賬號的二分類。
其中,作為本發明實施例的一種優選的實現方案,通過隨機森林分類算法對僵尸賬號和其余三種賬號的集合進行二分類,通過樸素貝葉斯分類算法對廣告賬號、普通賬號以及機器賬號的集合進行二分類,以及通過梯度回歸分類算法對機器賬號和普通賬號的集合進行二分類。
作為一種優選,采用文本分類的通用方法進行普通賬號和廣告賬號的二分類,以進一步確定賬號為普通賬號還是廣告賬號。
文本分類要做如下4個預處理動作:
1、選擇微博廣告和非廣告文本數據集;
2、微博文本預處理:分詞、去停用詞、建立詞袋模型;
3、選擇文本分類使用的特征向量:詞頻表征特征權重;
4、量化訓練數據集和測試數據集文件。
其中廣告微博內容涉及各種電商賣家廣告、代購廣告、微商廣告等,廣告內容類型多樣,但其中含有一些共同的明顯的營銷詞匯,比如打折、優惠、包郵、購買、正品、限量等,這些具有區分性的詞匯便是文本分類的關鍵。同時,將所有不具有廣告意圖的微博內容歸為普通用戶發布的非廣告微博。
通過實驗發現,對于廣告賬號和普通賬號的進一步識別中用到的文本分類算法,樸素貝葉斯分類算法效果較好;對于僵尸賬號和機器賬號 的進一步識別中用到的分類算法,集成分類算法隨機森林RandomForest、AdaBoost相比較與KNN、SVM、樸素貝葉斯等單模型算法更有效。
當然,基于以上分類效果對比,在具體應用過程中,可以根據賬號類型分別選取準確率(或F-score)最高的3個分類算法對賬號進行二分類。
其中,本發明實施例提供的微博賬號分類的裝置還可以進一步用于建立按微博數據特征劃分的分類模型。本發明中的分類模型是基于已知類型賬號的微博數據不斷通過機器學習和訓練而得到。
在具體實現過程中,獲取模塊12用于獲取已知類型的微博賬號的微博數據。
其中,已知類型的微博賬號來源于人工標記或者電商購買的標記樣本。人工標記,即手動查看每個微博賬號的資料及微博動態來判定賬號類型。電商購買,隨著微博的盛行,電子商務網站上已經出現了很多微博服務商品,比如可以購買微博粉絲、微博賬號,甚至一條微博的轉發量和點贊數都可以買到,其中賣家出售的微博粉絲,其中就是低級粉絲即僵尸賬號,高級粉絲即機器賬號,通過直接購買粉絲的方式,可以減少大量人力。
在本實施例具體實現時,僵尸賬號共標記2000個,其中1500個來自兩個淘寶賣家的低級微博粉絲,另外500個通過人工標記。標記的依據是:1)無頭像或系統默認頭像;2)關注數遠大于粉絲數;3)微博數較少且無轉發和評論;4)用戶昵稱為簡單的字母和數字組合或漢字和數字組合;5)用戶資料填寫內容少或無。綜合考慮以上5個方面來判斷一個賬號是否為僵尸賬號。通過觀察微博,發現很多娛樂明星和認證公司(推銷商品)的粉絲中存在大量僵尸賬號,有的娛樂明星希望通過百萬甚至千萬級的粉絲數來提高自己的知名度,認證公司希望購買僵尸賬號提高粉絲數,從而吸引普通微博用戶的關注,所以僵尸賬號的收集目標就集中在娛樂明星和認證公司的粉絲列表中。
廣告賬號共標記1000個,全部來自人工標記。標記的依據是:1)微博內容以廣告、促銷和抽獎等為主;2)用戶簡介中有店鋪鏈接、微 信號或商品介紹;3)微博中的鏈接多為商品買賣鏈接。
機器賬號共標記2000個,其中1500個來自淘寶購買的高級微博粉絲,400個通過人工標記,100個來自相關研究中使用到的機器賬號樣本。人工標記的依據是:1)微博發布時間規律性強,每隔一定時間發布一條微博;2)微博內容主題是心靈雞湯、名人名言、笑話、天氣、星座運勢等,微博內容也可能以廣告為主,有很大嫌疑是通過調用現成的語料庫來自動發布這些內容微博;3)微博內容重復度高,不同的機器賬號可能使用同一些語料庫;4)微博發布平臺種類少,部分機器賬號的微博發布平臺能明顯的說明使用了第三方軟件,如皮皮時光機、云中小鳥、孔明社交管理等。
普通賬號共標記3000個,全部來自人工標記。標記依據是:1)粉絲數和微博數較多;2)用戶頭像是真實照片;3)用戶資料填寫詳細;4)微博內容有日常生活氣息,如有個人生活內容分享;5)微博有被轉發或評論,同時又回復。收集方法:一是從自己的現實好友出發,然后再判斷現實好友的粉絲和關注,接著遞歸判斷粉絲的粉絲和關注、關注的粉絲和關注。而是從熱門微博和熱門話題下面尋找積極評論和互動的賬號。
微博數據的獲取可以采用微博應用程序編程接口(Application Programming Interface,API)和網絡爬蟲兩種方法。但微博API接口對訪問頻率和屬性獲取有較大限制。因此作為本發明的優選實現方案,采用網絡爬蟲的方式獲取微博數據。基于網絡爬蟲原理實現完成了微博爬蟲工具,該爬蟲工具能夠獲得微博頁面上所有能呈現出的所有微博數據,并且將獲得的原始微博數據進行預處理,最終存入數據庫。
在具體實現時,微博數據的獲取除了完成基本屬性值數據的獲取,同時獲取每個賬號的最新500條微博,若微博數不足500條的,將其所有微博內容全部獲取。爬取過程可以采取多臺計算機分擔微博數據爬取任務,避免爬取時間造成的屬性差異。
特征提取模塊12用于對已知類型的微博賬號的微博數據進行特征提取,得到已知類型的微博賬號的微博數據特征。
根據當前微博特點,本發明實施例抽取并擴展出4類微博數據特征:用戶資料特征、微博內容特征、交互行為特征和發布行為模式特征,綜合考慮多種類型賬號特征能夠提高賬號類型識別準確率。其中,不同微博數據特征的特征集合請參閱上述表1(加※為本發明新提出的特征),在此不再贅述。
用戶資料特征(表1中1-10號特征)來自用戶比較直觀的資料信息。其中微博年齡是從賬號注冊時間到2015年1月1日截止賬號存在天數;
微博內容特征(表1中11-14號特征)根據微博內容中包含的特殊內容抽取得來。機器賬號在大量發布微博同時還會較多地@好友,希望好友能夠轉發該微博或進行評論等,增加機器賬號的人為特性。相反,僵尸賬號幾乎不@好友。所以@數可以作為區分機器賬號和正常賬號、僵尸賬號和正常賬號的特征。
交互行為特征(表1中15-23號特征)表示微博賬號和其他賬號互動情況。機器賬號由于使用了語料庫,幾乎不轉發微博,大部分為原創微博;80%的機器賬號評論數小于150,而大約60%的正常賬號評論數都超過500,即正常賬號更具有評論交互意向,機器賬號要實現自動評論或回復復雜度較大。
發布行為特征(表1中24-34號特征)代表微博賬號發布行為模式。通過對微博賬號的觀察發現,大部分機器賬號以一定的時間間隔自動發布微博,有的甚至24小時連續定時發布微博,有的會稍有偽裝,避開0-6點休息時間發微博。機器賬號微博發布時間更有規律,普通賬號則顯得無規律可循。使用熵率來度量微博用戶發布微博時間規律性。
隨機變量序列X={Xi}由一個微博用戶所發微博的時間間隔隨機變量組成,Xi表示第i條和第i+1條微博之間的時間間隔隨機變量序列X的熵記為
其中P(xi)是P(Xi=xi)的概率。當已知該序列的前m-1項時,其條件信息熵記為:
CE(Xm|Xm-1)=H(Xm|X1,…,Xm-1)=H(X1,…,Xm)-H(X1,…,Xm-1) (2)
用戶發微博的時間間隔構成的序列都是有限序列,而信息熵衡量的是一個無窮隨機過程,無法直接用來計算有限的序列。引入修正的條件信息熵來解決序列有限性所帶來的問題。修正的條件信息熵的公式如下:
CCE(Xm|X1,...,Xm-1)=CE(Xm|X1,...,Xm-1)+perc(Xm)·EN(X1) (3)
其中perc(Xm)是在長度為m的序列里面只出現過一次的序列所占的比例,EN(X1)是當m=1時的信息熵。當序列長度取[2,m]中的不同值時,分別計算出相應的修正條件信息熵的值,最終熵率取其中最小值。如果該賬號是機器賬號,那它的行為會有一定的規律性,因而其修正條件信息熵的值會較小。與之相反,普通賬號的行為隨機化程度較高,修正的條件信息熵值也會較大。
針對行為模式特征中的信息熵,將機器賬號和普通賬號的發微博時間間隔序列輸入后,利用式(3)得到每位賬號用戶的修正條件。
針對廣告賬號的識別,只需要檢測賬號發布微博內容是否為廣告內容即可,所以使用發布微博文本內容這一特征,實際在文本分類中又將這一特征分解為文本特征向量;針對僵尸粉的識別,根據特征分析,選擇使用是否有頭像、是否填寫簡介、昵稱是否包含數字、粉絲數、關注數、微博數這6個數值型特征即可;針對機器賬號的識別根據特征分析,選擇使用是否填寫簡介、昵稱是否包含數字、粉絲數、關注數、微博數、微齡、粉絲度、關注度、粉絲關注比、微博含圖片數、原創數、 轉發數、評論數、被評論數、回復數、自轉數、微博發布時間間隔熵、日均發布微博數、0-6點的平均微博數、6-12點的平均微博數、12-18點的平均微博數、18-24點的平均微博數、發布平臺數、發布IP數、發布ISP數、發布省份數、發布城市數共29個數值型特征。特征數據分析不僅通過條形圖、CDF圖來展示,還通過具體分類模型計算了特征的重要。
另外,特征提取模塊12還用于對普通賬號和機器賬號分類的29個特征的重要性進行排名,通過排名,可以進一步進行特征選擇,在保證 分類準確度的基礎上加速賬號分類速度。
確定模塊13對已知類型的微博賬號的微博數據特征進行機器學習訓練,從而建立按微博數據特征劃分的分類模型。
在具體實現時,可以采用10折交叉驗證的方法,使用已標記樣本數據集,訓練分類模型,通過實驗實際測試各個分類算法在微博賬號分類中的效果。
其中,利用第三方機器學習工具包Scikit-Learn,對不同的分類算法進行性能測試。Scikit-Learn是操作簡單、高效的機器學習和數據分析工具,其中包含的機器學習模型非常豐富,包括支持向量機SVM,決策樹,隨機森林,梯度回歸分類算法、樸素貝葉斯,GBDT,鄰近算法KNN等等,可以根據數據特征選擇合適的模型進行機器學習訓練得到分類模型。
以上是本發明實施例提供的一種微博賬號分類的方法及裝置的詳細說明,可以理解,本發明通過對微博賬號對應的微博數據進行特征提取得到微博數據特征,采用已建立的按微博數據特征劃分的分類模型確定微博賬號的類型。由于分類模型是通過對數量龐大的已知類型微博賬號對應的微博數據進行機器學習訓練而得到,因此,分類模型非常全面和具有代表性,通過分類模型對微博賬號的類型進行確定,從而可以對微博賬號的識別和分類能夠更加高效和準確。
本發明的方法是建立在分析用戶的基本資料、微博內容、交互行為、發布行為4類特征上,這4類特征可有效的描述一個微博用戶的特點,實現微博賬號的識別與多分類,使得賬號的識別具有更高的主動性和精確性。并且能夠對賬號進行細分到具體的類型。
在本發明所提供的幾個實施例中,應該理解到,所揭露的系統,裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述模塊或單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其 它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以采用硬件的形式實現,也可以采用軟件功能單元的形式實現。
所述集成的單元如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的全部或部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)或處理器(processor)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光盤等各種可以存儲程序代碼的介質。
以上所述僅為本發明的實施例,并非因此限制本發明的專利范圍,凡是利用本發明說明書及附圖內容所作的等效結構或等效流程變換,或直接或間接運用在其他相關的技術領域,均同理包括在本發明的專利保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!