基于多模態融合的智能高容錯視頻識別系統及其識別方法與流程
本發明涉及一種識別系統與識別方法,尤其涉及一種視頻的識別系統與識別方法。
背景技術:
隨著網絡技術的發展以及云端服務的普及化,許多業者會將視頻上傳至網絡,以令用戶可以得到比文字更為豐富的內容。
一般來說,業者于上傳各類視頻,例如音樂錄音帶、廣告、電影等時,會同時為各該視頻編寫一段文字描述。當用戶要尋找一段視頻時,主要是在網絡平臺上輸入該視頻的關鍵詞,若用戶輸入的關鍵詞存在于該視頻的文字描述中,用戶就可以成功搜尋到該視頻。
如上所述,現今業者在上傳視頻時,需以人工方式為每一段視頻分別撰寫對應的文字描述,因此需耗費相當高的成本。再者,上述文字描述通常是依據該視頻的主要劇情或是導演要表達的內容來撰寫,不一定和該視頻中實際出現的元素(例如人物、場景、音樂等)有實際的關聯。因此,即使用戶以該視頻中出現的人物、場景或音樂的名稱做為關鍵詞來進行搜尋,也不見得能成功搜尋到該視頻。
有鑒于此,如何令業者以最節省成本的方式來為視頻產生對應的文字描述,以及令用戶能以視頻中實際出現的元素的名稱做為關鍵詞來準確搜尋所需的視頻片段,即為本技術領域的技術人員所潛心研究的方向。
技術實現要素:
本發明的主要目的是在于提供一種基于多模態融合的智能高容錯視頻識別系統及其識別方法,可識別出視頻中包含的多個元素的名稱,以及各個元素在視頻中出現的時間,藉此可供用戶以文字進行所需視頻片段的搜尋動作。
本發明的另一主要目的,在于提供一種基于多模態融合的智能高容錯視 頻識別系統及其識別方法,可對同一時間出現的多個元素進行多模態融合識別,以提升各個元素的識別準確率與容錯性。
為了達成上述目的,本發明提供一種基于多模態融合的智能高容錯視頻識別方法,其特征在于,包括下列步驟:
a)輸入一視頻;
b)對該視頻進行分析,以擷取該視頻中的多個元素,以及各該元素出現的時間;
c)對各該元素進行分類;
d)通過多個算法分別對分類后的各該元素進行識別,其中各該算法分別對應至多個類別的其中之一;
e)對多個該元素進行交叉識別以提升各該元素的識別準確率與容錯性;及
f)依據識別完成的各該元素為該視頻產生可供文字搜尋的一索引文件,其中該索引文件包含各該元素的類別、名稱以及于該視頻中出現的時間。
承上所述,該基于多模態融合的智能高容錯視頻識別方法更包括下列步驟:
g)步驟c后,判斷是否有識別準確率不足的一特定元素;及
h)于判斷有識別準確率不足的該特定元素時執行該步驟e。
承上所述,該步驟e是將該特定元素與同一時間出現的其他元素進行交叉識別,或是對出現在多個不同時間點中的該特定元素進行交叉識別。
承上所述,該基于多模態融合的智能高容錯視頻識別方法更包括一步驟i:依據識別完成的各該元素為該視頻產生具有邏輯性的一影片敘述。
承上所述,該基于多模態融合的智能高容錯視頻識別方法更包括下列步驟:
j)步驟f后,依據場景切換、分鏡改變或時間區間經過將該視頻區分為多個片段;及
k)依據各該片段中出現的各該元素,分別為各該片段產生具有邏輯性的該影片敘述。
承上所述,該步驟i與該步驟k是通過自然語音處理算法對各該元素進行處理,以產生具有邏輯性的該影片敘述。
承上所述,該索引文件與該影片敘述中不包含識別準確率低于一標準值 的一或多個該元素。
承上所述,該多個類別至少包括人臉、影像、文字、聲音、動作、物件及場景中的任意兩種。
本發明另外提供一種基于多模態融合的智能高容錯視頻識別系統,其特征在于,包括:
一影片輸入子系統,接收一視頻的輸入;
一元素擷取與分類子系統,連接該影片輸入子系統,對該視頻進行分析,以擷取該視頻中的多個元素以及各該元素出現的時間,并且對擷取出來的該多個元素進行分類;
多個元素識別子系統,連接該元素擷取與分類子系統,各該元素識別子系統分別對應至多個類別的其中之一,并且采用對應的一算法對所屬類別的各該元素進行識別,并且該多個元素識別子系統對多個該元素進行交叉識別以提升各該元素的識別準確率及容錯性;及
一索引文件產生子系統,連接該多個元素識別子系統,依據識別完成的各該元素為該視頻產生可供文字搜尋的一索引文件,其中該索引文件包含各該元素的類別、名稱以及于該視頻中出現的時間。
承上所述,該多個元素識別子系統是于一特定元素的識別準確率不足時,將該特定元素與同一時間出現的其他元素進行交叉識別,或是對出現在多個不同的時間點中的該特定元素進行交叉識別。
承上所述,該基于多模態融合的智能高容錯視頻識別系統更包括一分類數據庫,連接該元素擷取與分類子系統,該分類數據庫儲存多個類別的多個特征,該元素擷取與分類子系統將各該元素與該些特征進行比對,以確認各該元素分別屬于哪個類別。
承上所述,該基于多模態融合的智能高容錯視頻識別系統更包括多個元素數據庫,分別連接該多個元素識別子系統的其中之一,與所連接的該元素識別子系統屬于同一類別,并且儲存所屬類別的元素數據。
承上所述,該基于多模態融合的智能高容錯視頻識別系統更包括:
一語料庫,儲存多個語法規則;及
一影片敘述產生子系統,連接該多個元素識別子系統及該語料庫,依據識別完成的各該元素及該多個語法規則,為該視頻產生具有邏輯性的一影片 敘述。
承上所述,該影片敘述產生子系統依據場景切換、分鏡改變或時間區間經過將該視頻區分為多個片段,再依據各該片段中出現的各該元素,分別為各該片段產生具有邏輯性的該影片敘述。
承上所述,該影片敘述產生子系統為一自然語言處理系統。
承上所述,該基于多模態融合的智能高容錯視頻識別系統更包括一主數據庫,連接該影片輸入子系統、該索引文件產生子系統及該影片敘述產生子系統,儲存該視頻、該索引文件及該影片敘述。
承上所述,該多個類別至少包括人臉、影像、文字、聲音、動作、物件及場景中的任意兩種。
本發明對照現有技術所能達成的技術功效在于,識別系統會為識別完成的視頻產生專屬的一索引文件,該索引文件中記錄了該視頻中出現的所有元素,以及各個元素于該視頻中出現的時間。如此一來,當一用戶以文字進行所需元素,例如人物、場景、音樂、動作等的搜尋時,可直接得到包含有該些元素的視頻,以及該些元素于該視頻中出現的片段,相當便利。
另外,本發明是對各個元素進行分類后,再依據對應的算法來分別對各個類別的元素進行識別,如此可以同時對視頻中出現的多個類別的元素進行識別。并且,本發明還可以將同一時間出現的多個元素進行交叉識別,以及對出現在多個不同時間的同一個元素進行交叉比對。如此一來,可以有效提升各個元素的識別準確率與容錯性。
附圖說明
圖1為本發明的第一具體實施例的視頻識別平臺架構圖。
圖2為本發明的第一具體實施例的識別系統方塊圖。
圖3為本發明的第一具體實施例的識別流程圖。
圖4為本發明的第一具體實施例的元素識別示意圖。
圖5為本發明的第一具體實施例的元素出現時間示意圖。
圖6為本發明的第一具體實施例的元素搜尋流程圖。
其中,附圖標記:
1…基于多模態融合的智能高容錯視頻識別系統
11…影片輸入子系統
12…元素擷取與分類子系統
121…分類數據庫
13…元素識別子系統
131…第一元素識別子系統
132…第二元素識別子系統
13n…第n元素識別子系統
14…元素數據庫
141…第一元素數據庫
142…第二元素數據庫
14n…第n元素數據庫
15…索引文件產生子系統
16…影片敘述產生子系統
161…語料庫
17…主數據庫
2…臺式計算機
3…筆記本電腦
4…行動裝置
5…視頻
61…第一元素
62…第二元素
63…第三元素
64…第四元素
65…第五元素
S10~S26…識別步驟
S30~36…搜尋步驟
具體實施方式
茲就本發明的一較佳實施例,配合圖式,詳細說明如后。
參閱圖1,為本發明的第一具體實施例的視頻識別平臺架構圖。本發明主 要揭露一基于多模態融合的智能高容錯視頻識別系統1(下面簡稱為該系統1),以及該系統1使用的一基于多模態融合的智能高容錯視頻識別方法(下面簡稱為該方法)。
如圖1所示,該系統1主要用于建置一云端平臺。當用戶通過各式用戶終端,例如臺式計算機2、筆記本電腦3或行動裝置4連接該云端平臺并上傳一視頻時,該系統1可為該視頻進行分析。待分析完成后,該視頻即可被用戶以文字、圖像或影片的方式進行搜尋,如此將有助于該視頻于網絡上的流傳,進而能有效提高該視頻的能見度。
更甚者,該系統1可于分析后確認該視頻中包含有哪些元素(components),并且依據該些元素來為該視頻產生具有邏輯性的一段影片敘述。這些元素可例如但不局限于:人臉、商標、文字、音樂、語音、動作、物件、場景…等,但不以此限定。如此一來,提供該視頻的業者不需要以人工方式為該視頻撰寫影片敘述,因此可有效節省所需耗費的成本。
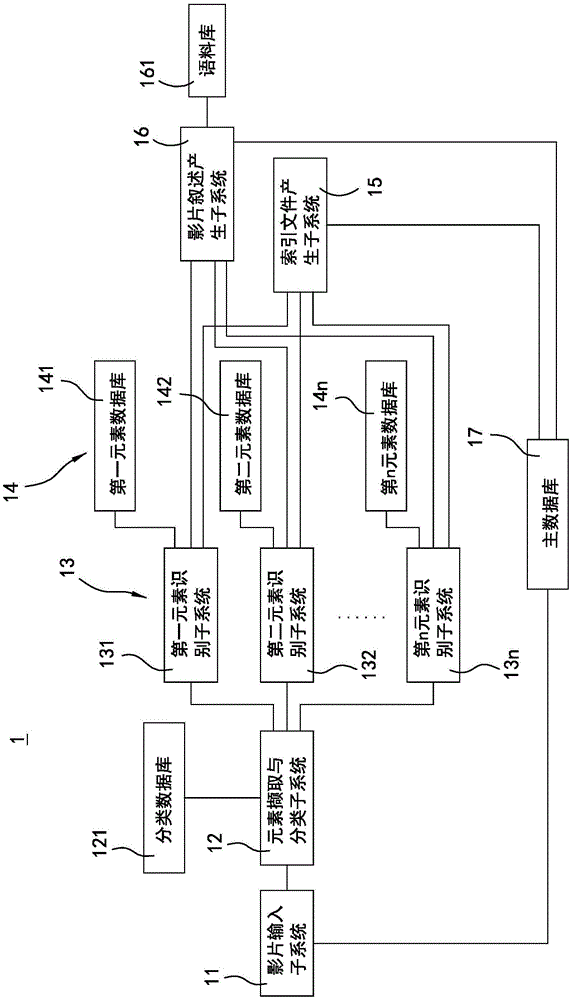
參閱圖2,為本發明的第一具體實施例的識別系統方塊圖。如圖2所示,該系統1主要包括一影片輸入子系統11、連接該影片輸入子系統11的一元素擷取與分類子系統12、連接該元素擷取與分類子系統12的多個元素識別子系統13及連接該多個元素識別子系統13的一索引文件產生子系統15。
該影片輸入子系統11用以接收一視頻的輸入。本實施例中,該影片輸入子系統11可經由網絡接收用戶上傳的該視頻,然而于其他實施例中,該影片輸入子系統11亦可經由有線傳輸方式或無線傳輸方式(例如經由藍牙(Bluetooth)、射頻(RF)或紫蜂(Zigbee)等),由周邊的電子裝置、硬盤或數據庫接收該視頻,不加以限定。
該元素擷取與分類子系統12由該影片輸入子系統11接收該視頻,并且對該視頻進行第一階段分析。具體而言,于該第一階段分析中,該元素擷取與分類子系統12是可擷取出該視頻中出現的所有元素,以及各該元素于該視頻中出現的時間。
于該視頻中的所有元素皆被擷取出來之后,該元素擷取與分類子系統12進一步對各該元素進行分類,以確認該些元素分別屬于哪一個類別。本實施例中,該元素擷取與分類子系統12主要可依據一算法將各該元素區分為人臉(Face)、影像(Image)、文字(Text)、聲音(Audio)、動作(Motion)、物件(Object) 及場景(Scene)等類別,但不加以限定。
更具體而言,該系統1還包括連接該元素擷取與分類子系統12的一分類數據庫121,該分類數據庫121中儲存該多個類別所對應的多個特征。具體而言,各個類別的元素都有特定的特征,因此本實施例中,該元素擷取與分類子系統12主要是將該些元素與該分類數據庫121中的該些特征進行比對,藉此判斷各該元素分別屬于哪一個類別。
本實施例中,該多個元素識別子系統13是用于對該視頻進行第二階段分析,其中該多個元素識別子系統13的數量是對應至該元素擷取與分類子系統12能夠分析的類別數量。經過該第二階段分析后,該系統可以確定各該元素的實際名稱(label)。
如圖2所示,本實施例中該元素擷取與分類子系統12可以區分n個類別的元素,故該多個元素識別子系統13是以一第一元素識別子系統131、一第二元素識別子系統132、………、至一第n元素識別子系統13n為例,其中,該第一元素識別子系統131用以對一第一類別的一或多個元素進行識別、該第二元素識別子系統132用以對一第二類別的一或多個元素進行識別、……、該第n元素識別子系統13n用以對一第n類別的一或多個元素進行識別,以此類推。
值得一提的是,于一較佳實施例中,該視頻中的該些元素主要可以被區分為上述的人臉(Face)、影像(Image)、文字(Text)、聲音(Audio)、動作(Motion)、物件(Object)及場景(Scene)等七個類別,因此,相應地,該多個元素識別子系統13的數量較佳為七個,但不加以限定。
如上所述,該多個元素識別子系統13分別對應該多個類別的其中之一,并且采用對應的一算法對該類別的元素進行識別。舉例來說,該第一元素識別子系統131可采用臉部辨識算法,對被分類至人臉類別的一或多個元素進行識別,以確認該些元素分別對應至哪個人物。再例如,該第二元素識別子系統132可采用物件辨識算法,對被分類至物件類別的一或多個元素進行識別,以確認該些元素分別是什么物件,例如為汽車、飛機、包包、手表等等。
該系統1還包括多個元素數據庫14,該多個元素數據庫14的數量對應至該多個元素識別子系統13的數量。各該元素數據庫14分別連接至該多個元素識別子系統13的其中之一,并且與所連接的該元素識別子系統13屬于同一類 別。
更具體地,各該元素數據庫14分別儲存有所屬的類別的元素數據。于執行該第二階段分析時,各該元素識別子系統13是將該些元素分別與所屬類別的元素數據進行比對,以確認該些元素的名稱。
值得一提的是,該多個元素識別子系統13還可對不同類別的多個元素進行交叉識別(或稱多模態融合識別),以提升該些元素的識別準確率以及容錯性。具體來說,該多個元素識別子系統13是在一特定元素的準確率不足(例如低于70%或80%)時,將該特定元素與同一時間出現的其他元素進行交叉比對,藉此提升該特定元素的識別準確率以及容錯性。
舉例來說,若該第一元素識別子系統131識別一第一元素(人臉)后,判斷該第一元素的名稱為“周杰倫”,但準確率只有70%,則此識別結果可能會因為準確率不足而不被該系統1所采用。然,若該第二元素識別子系統132于同一時間識別一第二元素(例如聲音)的名稱為“七里香”而準確率為99%,且該第n元素識別子系統13n于同一時間識別一第三元素(例如物件)的名稱為“鋼琴”而準確率為95%,則該多個元素識別子系統13可經由交叉識別演算(周杰倫善于鋼琴,且七里香為周杰倫的創作歌曲),提升該第一元素的名稱為“周杰倫”的識別結果的準確率(例如提升為85%)。而當準確率提升并超過一標準值后,該識別結果即可被該系統1所采用。
于上述實施例中,該系統1是于該特定元素的識別準確率不足時執行上述交叉識別,然而于其他實施例中,該系統1亦可常態地執行上述交叉識別,以進一步確定各該元素的實際態樣。
舉例來說,該第n元素識別子系統13n識別一第四元素(例如物件)后,可能識別出該第四元素的名稱為“汽車”且準確率為99%,但無法確定該汽車的廠牌或款式。此時,若該第二元素識別子系統132于同一時間識別一第五元素(例如聲音)的名稱為“寶馬”且準確率為99%,則該多個元素識別子系統13可經由交叉識別演算后,識別出該第四元素的名稱為“寶馬”且準確率為99%。
如上所述,本發明主要是同時采用多種算法,分別對視頻中的不同類別的元素同時進行識別,進而可增加識別后可得的結果。同時,本發明還可于必要時由多種算法對不同類別的元素進行交叉識別,如此一來,只要同一時間出現的多個元素彼此之間具有關聯性,就可以有效提升各個元素的識別準確率。惟, 上述僅為本發明的一具體實施范例,不應以此為限。
值得一提的是,上述的交叉識別亦可運用于同一個元素,具體說明如下。由于同一個元素可能會連續或不連續地出現在同一段視頻的不同時間點中,因此,當各該元素識別子系統13對一特定時間中出現的元素進行識別但識別準確率不足時,可進一步對連續或不連續的多個時間點(或時間段)中出現的同一元素進行交叉識別。在進行了多次識別后,只要其中有任何一幀的識別準確率足夠,就可以歸納確定這些時間點中出現的該元素的內容為何。藉此,可大幅提升該元素的識別準確率及容錯性。
該索引文件產生子系統15主要是由該多個元素識別子系統13接收該些元素的識別結果,并且依據識別完成的該些元素進行多模態融合,藉此為該視頻產生可供文字搜尋的一索引文件(index)。更具體而言,該索引文件產生子系統15是依據識別準確率高于該標準值(例如80%)的識別結果產生該索引文件,換句話說,該索引文件中不會包含識別準確率低于該標準值的元素,但不加以限定。
本實施例中,該索引文件主要可包含各該元素的類別、名稱以及于該視頻中出現的時間。舉例來說,該索引文件的內容可例如為{id:1,type:人臉,name:周杰倫,time:00:13~01:28}{id:2,type:物件,name:汽車,time:00:10~01:00}{id:3,type:場景,name:沙灘,time:01:00~01:35}等等。
如上所述,于本發明中,該索引文件主要是用于供用戶以關鍵詞進行的搜尋,因此不需要以用戶可以理解的方式來呈現。
于一實施例中,該系統1更包括連接該多個元素識別子系統13的一影片敘述產生子系統16,以及連接該影片敘述產生子系統16的一語料庫161,該語料庫161中儲存有多個語法規則。
本實施例中,該影片敘述產生子系統16是由該多個元素識別子系統13分別取得識別完成的多個元素,并且依據該些識別完成的元素,以及該多個語法規則,為該視頻產生具有邏輯性的一影片敘述。本實施例中,該影片敘述產生子系統16主要是一自然語言處理(Natural Language Processing,NLP)系統,并且采用自然語音處理算法來對該些識別完成的元素進行邏輯處理,以產生具有邏輯性的該影片敘述。
更甚者,考慮到某些視頻的時間長度可能太長(例如微電影約30分鐘,正 規電影約2小時),若要以單一句或單一段影片敘述來描述單一視頻實有困難。因此,該影片敘述產生子系統16還可于必要時產生多個影片敘述來描述單一視頻。
具體而言,于另一實施例中,該影片敘述產生子系統16可依據該視頻的場景切換、分鏡改變或是時間區間經過,將該視頻區分為多個片段。并且,再依據各該片段中出現且已識別完成的多個元素,分別為各該片段產生具有邏輯性的該影片敘述。換句話說,每一片段皆具有一影片敘述,而該視頻具有多個片段以及多個影片敘述。惟,上述僅為本發明的另一實施范例,不應以此為限。
本發明中,該影片敘述主要是用于令用戶可以在短時間內快速了解該視頻的內容,因此主要是以具有邏輯性、與該視頻所包含的元素直接相關并且用戶可以了解的方式來呈現(容后詳述)。通過本發明的技術方案,業者只需將該視頻上傳至該系統1,即可由該系統1自動為該視頻產生對應的該影片敘述。如此一來,業者可以有效省下人工瀏覽該視頻后再撰寫影片敘述所需耗費的成本。
如圖2所示,該系統1還可包括一主數據庫17,連接該影片輸入子系統11、該索引文件產生子系統15及該影片敘述產生子系統16。該主數據庫17主要用于儲存上述的該視頻、以及該視頻所對應的該索引文件及該影片敘述,但不加以限定。
值得一提的是,上述該該影片輸入子系統11、該元素擷取與分類子系統12、該多個元素識別子系統13、該索引文件產生子系統15與該影片敘述產生子系統16主要可以實體的系統硬件,例如各別的服務器或計算機主機來實現,或是以該系統1內部執行的一或多套軟件來實現,不加以限定。
請同時參閱圖3,為本發明的第一具體實施例的識別流程圖。圖3揭露了本發明的該方法,并且該方法主要是以圖2所示的該系統1來實現。
首先,由該系統1輸入一視頻(步驟S10),并且,該系統1對輸入的該視頻進行分析(多模態識別),以擷取出該視頻中包含的多個元素,以及各該元素出現的時間(步驟S12)。本實施例中,該系統1可于該視頻輸入后立即開始分析,或是先將該視頻暫存于該主數據庫17中,并依據系統排序進行分析,不加以限定。
該步驟S12后,該系統1對擷取出來的多個元素進行分類(步驟S14),并 且通過多個算法分別對各個類別的該元素進行識別,以確認各該元素的名稱(步驟S16)。其中,該多個算法是分別對應至該系統1可區分的該多個類別的其中之一。
接著,該系統1判斷是否有識別準確率不足的一特定元素(步驟S18)。若有識別準確率不足的該特定元素,則該系統1對該特定元素要進行交叉識別(步驟S20),藉此提升該特定元素的識別準確率及容錯性。
較具體地,該步驟S20是將該特定元素與同一時間出現的其他元素進行交叉識別,或是對出現在多個不同的時間點或時間段中的該特定元素進行交叉識別,不加以限定。然而,如前文中所述,該系統1可于該特定元素存在時才執行該交叉識別動作,亦可常態執行該交叉識別動作。換句話說,上述該步驟S18并不必然存在。
于該視頻中的所有元素皆識別完成后,該系統1進一步依據識別完成的該些元素進行多模態融合,藉此為該視頻產生可供文字搜尋的該索引文件(步驟S22),并且如前文所述,該索引文件主要包含了該視頻中出現的所有元素的類別、名稱、以及于該視頻中出現的時間。藉此,只要用戶以該些元素的名稱做為關鍵詞進行搜尋,即可順利找到該視頻。更甚者,當用戶以一元素的名稱做為關鍵詞進行搜尋時,可直接找到該元素于該視頻中出現的片段并且開始播放。
該步驟S22后,該系統1依據該視頻的場景切換、分鏡改變或者時間區間經過,將該視頻區分為多個片段(步驟S24),并且再依據各個片段中已識別完成的多個元素,分別為各個片段產生具有邏輯性的一影片敘述(步驟S26)。本實施例中,該系統1主要是通過自然語音處理(Natural Language Processing,NLP)算法對已識別完成的各該元素進行處理,以產生具有邏輯性的該影片敘述。
然而,如前文中所述,該系統1可依據該視頻的類型(例如廣告、微電影、電影、音樂錄像帶等)或長度(例如30秒、1分鐘、30分鐘、1小時等),選擇性地先將單一頻視區分為多個片段后,再分段產生多個影片敘述(即,執行該步驟S24),或是直接為單一頻視產生單一影片敘述(即,不執行該步驟S24),不應加以限定。
值得一提的是,本實施例中,該系統1會于識別完成后,舍棄識別準確率 低于上述該標準值的一或多個該元素,并且不記錄于該索引文件與該影片敘述中。藉此,確保提供給用戶進行搜尋或查看的內容都是相當精準的。
請同時參閱圖4與圖5,分別為本發明的第一具體實施例的元素識別示意圖與元素出現時間示意圖。如圖4所示,當一視頻5輸入該系統1后,該系統1會按照播放時間序列,對該視頻5中出現的多個元素進行擷取、分類與識別。
圖4以該視頻5的其中一幀為例,該系統1從該幀中擷取出一第一元素61、一第二元素62、一第三元素63、一第四元素64及一第五元素65,并且經判斷后確認該第一元素61屬于場景類別,該第二元素62屬于物件類別,該第三元素63屬于人臉類別,該第四元素64屬于聲音類別,該第五元素65屬于動作類別。并且在分類完成后,以對應型態的算法分別對該些元素61-65進行識別。
如圖4所示,該第一元素61經過識別后,確認名稱為“沙灘”;該第二元素62經過識別后,確認名稱為“汽車”;該第三元素63經過識別后,確認名稱為“周杰倫”;該第四元素64經過識別后,確認名稱為“七里香”;該第五元素65經過識別后,確認名稱為“唱歌”。
如圖5所示,當該視頻5中的所有元素皆被識別完成后,該系統1除了藉由該索引文件產生子系統15產生可供文字搜尋的該索引文件之外,還可藉由該影片敘述產生子系統16產生能夠代表該視頻5,并且具有邏輯性的該影片敘述,例如“周杰倫坐在沙灘邊的車上,并且唱著七里香”。藉此,用戶可以通過該影片敘述快速得知該視頻的內容為何,以及該視頻中包含了哪些主要的元素。
請參閱圖6,為本發明的第一具體實施例的元素搜尋流程圖。當用戶欲搜尋所需的視頻時,可操作該臺式計算機2、該筆記本電腦3或該行動裝置4,藉由網絡連接至該系統1,并且輸入欲搜尋的元素的關鍵詞(步驟S30)。
接著,該系統1以該關鍵詞查詢該主數據庫17(步驟S32),并且更具體而言,是以該關鍵詞查詢該主數據庫17中儲存的多個索引文件。該步驟S32后,若該系統1查詢到符合的索引文件,則同時取得該索引文件所對應的視頻(步驟34)。并且,該系統1可依據用戶設定,于該視頻識別平臺上顯示出包含有該關鍵詞所對應的元素的該視頻,或是直接于該元素出現的時間開始播放該視頻(步驟S36)。
于另一實施例中,用戶亦可上傳圖像或影片至該系統1。該系統1可經由相同技術識別出該圖像或該影片中包含的元素的名稱,再自動將該名稱做為關鍵詞并查詢該主數據庫17。如此一來,可以實現用戶以圖像或影片來搜尋視頻的技術方案。
通過本發明的技術方案,不但可便于用戶以文字、圖像或影片來搜尋視頻,以提高用戶的搜尋便利性,并且可有效提升整體系統對于視頻中的元素的識別準確率及容錯性。同時,還可省去業者以人工方式為視頻撰寫相關的影片敘述所需耗費的成本,實相當便利。
以上所述僅為本發明的較佳具體實例,非因此即局限本發明所附的權利要求的保護范圍,故舉凡運用本發明內容所為的等效變化,均同理皆包含于本發明所附權利要求的保護范圍內,合予陳明。
- 還沒有人留言評論。精彩留言會獲得點贊!