對URL進行分類的方法和裝置與流程
本發明涉及大數據和互聯網技術領域,尤其是一種對URL(Uniform Resource Locator,統一資源定位符)進行分類的方法和裝置。
背景技術:
目前,基于DPI(Deep Packet Inspection,深度包檢測)數據分析用戶的上網行為主要是通過URL地址庫匹配用戶訪問的網址,然后對用戶打標簽來實現。
URL地址庫一般采用網頁內容提取和識別技術來對URL進行分類來構建,但是,本發明的發明人發現,采用網頁內容提取和識別技術對URL進行分類的方式具有如下缺點:
一是由于需要針對不同的網站設計個性化算法,因此,對URL進行分類時的工作量大,效率低;
二是在不同的網站改版后,需要通過人工辨別或重新識別來重新對URL進行分類,URL地址庫無法自動更新。
技術實現要素:
本發明實施例所要解決的其中一個技術問題是:解決URL分類效率低的問題。
根據本發明的一方面,提供一種對URL進行分類的方法,包括:獲取訪問URL的各用戶的用戶特征信息和各用戶訪問該URL的訪問次數,所述用戶特征信息包括基于用戶歷史上網行為確定的用戶標簽和各用戶標簽的權重;根據獲取到的各用戶的用戶特征信息和各用戶訪問URL的訪問次數確定URL特征信息,所述URL特征信息包括URL的 網頁類型和各網頁類型的權重;根據所述URL特征信息對所述URL進行分類。
在一個實施例中,所述根據獲取到的各用戶的用戶特征信息和各用戶訪問URL的訪問次數確定URL特征信息包括:根據uj=(xj1×kj1,xj2×kj2,…xjn×kjn)×pj/P計算訪問該URL的每個用戶j的標簽向量uj,其中j為正整數,1≤j≤S,S為訪問該URL的用戶總數,xjn為用戶j的用戶標簽,kjn為用戶標簽xjn的權重,jn為正整數,pj為用戶j訪問該URL的訪問次數,P為所有用戶訪問該URL的總訪問次數;將各用戶j的標簽向量uj中相同用戶標簽的權重累加,并按累加后的用戶標簽的系數的大小對用戶標簽進行排序,得到該URL的標簽向量y=(x1×c1,x2×c2,…,xt×ct),其中xt為用戶標簽,用戶標簽xt的系數ct為S個用戶的標簽向量uj中與xt相同的用戶標簽的權重之和;從URL的標簽向量y中選擇用戶標簽的系數最大的前m個用戶標簽x1,x2,…xm作為該URL的網頁類型,并將作為網頁類型xi的權重。
在一個實施例中,所述根據所述URL特征信息對所述URL進行分類包括:選擇各網頁類型的權重中最大的一個或多個網頁類型作為所述URL的網頁類型,以對所述URL進行分類。
在一個實施例中,所述方法還包括:從采集的DPI數據中篩選出總訪問次數大于預設閾值的URL作為所述URL。
在一個實施例中,所述方法還包括:采集所述URL的網頁內容,并根據所述URL的網頁內容和特定算法識別所述URL的網頁類型,以對所述URL進行分類;將分類結果與根據所述URL特征信息對所述URL進行分類的分類結果進行比較;根據比較結果調整所述預設閾值的大小。
根據本發明的另一方面,提供一種對URL進行分類的裝置,包括:用戶特征信息獲取模塊,用于獲取訪問URL的各用戶的用戶特征信息和各用戶訪問該URL的訪問次數,所述用戶特征信息包括基于用戶歷史上網行為確定的用戶標簽和各用戶標簽的權重;URL特征信息確定 模塊,用于根據獲取到的各用戶的用戶特征信息和各用戶訪問URL的訪問次數確定URL特征信息,所述URL特征信息包括網頁類型和各網頁類型的權重;URL分類模塊,用于根據所述URL特征信息對所述URL進行分類。
在一個實施例中,所述URL特征信息確定模塊包括:用戶標簽計算單元,用于根據uj=(xj1×kj1,xj2×kj2,…xjn×kjn)×pj/P計算訪問該URL的每個用戶j的標簽向量uj,其中j為正整數,1≤j≤S,S為訪問該URL的用戶總數,xjn為用戶j的用戶標簽,kjn為用戶標簽xjn的權重,jn為正整數,pj為用戶j訪問該URL的訪問次數,P為所有用戶訪問該URL的總訪問次數;URL標簽計算單元,用于將各用戶j的標簽向量uj中相同用戶標簽的權重累加,并按累加后的用戶標簽的系數的大小對用戶標簽進行排序,得到該URL的標簽向量y=(x1×c1,x2×c2,…,xt×ct),其中xt為用戶標簽,用戶標簽xt的系數ct為S個用戶的標簽向量uj中與xt相同的用戶標簽的權重之和;URL特征信息確定單元,用于從URL的標簽向量y中選擇用戶標簽的系數最大的前m個用戶標簽x1,x2,…xm作為該URL的網頁類型,并將作為網頁類型xi的權重。
在一個實施例中,所述URL分類模塊,具體用于選擇各網頁類型的權重中最大的一個或多個網頁類型作為所述URL的網頁類型,以對所述URL進行分類。
在一個實施例中,所述裝置還包括:DPI數據分析模塊,用于從采集的DPI數據中篩選出總訪問次數大于預設閾值的URL作為所述URL。
在一個實施例中,所述裝置還包括:網頁內容采集模塊,用于采集所述URL的網頁內容,并根據所述URL的網頁內容和特定算法識別URL的網頁類型,以對所述URL進行分類;比較模塊,用于將分類結果與根據所述URL特征信息對所述URL進行分類的分類結果進行比較;調整模塊,用于根據比較結果調整所述預設閾值的大小。
本發明通過獲取訪問URL的各用戶的用戶特征信息可以確定URL的特征信息,從而可以確定URL的網頁類型,以對URL進行分類。這 種分類方式一方面,無需針對不同的URL網站設計個性化算法,分類效率高;另一方面,在不同的URL網站改版后,即網頁類型發生變化時,由于可以根據訪問該URL的用戶特征信息得到URL的特征信息,從而可以及時對URL重新進行分類,自動更新URL地址庫。
下面通過附圖和實施例,對本發明的技術方案做進一步的詳細描述。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明對URL進行分類的方法一個實施例的流程示意圖;
圖2是本發明對URL進行分類的方法一個例子的示意圖;
圖3是本發明對URL進行分類的裝置一個實施例的結構示意圖;
圖4是本發明對URL進行分類的裝置另一個實施例的結構示意圖;
圖5是本發明對URL進行分類的裝置又一個實施例的結構示意圖;
圖6是本發明對URL進行分類的裝置再一個實施例的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
除非另外具體說明,否則在這些實施例中闡述的部件和步驟的相對布置、數字表達式和數值不限制本發明的范圍。
同時,應當明白,為了便于描述,附圖中所示出的各個部分的尺寸并不是按照實際的比例關系繪制的。
對于相關領域普通技術人員已知的技術、方法和設備可能不作詳細討論,但在適當情況下,所述技術、方法和設備應當被視為授權說明書的一部分。
在這里示出和討論的所有示例中,任何具體值應被解釋為僅僅是示例性的,而不是作為限制。因此,示例性實施例的其它示例可以具有不同的值。
應注意到:相似的標號和字母在下面的附圖中表示類似項,因此,一旦某一項在一個附圖中被定義,則在隨后的附圖中不需要對其進行進一步討論。
本發明的發明人發現,在大數據統計的基礎上,當訪問一個URL網址的用戶量較大時,URL網頁的內容體現了訪問用戶的共同需求,而不是單個用戶的特殊需求。因此,提出根據訪問URL的各用戶的用戶特征信息反向標記URL的特征信息。本發明可用于電信DPI用戶的行為分析,能夠快速對訪問量大的URL進行分類,識別新增URL的類別,在現有人工審核、基于網頁分析的URL特征識別基礎上,能夠進一步提高URL分類的質量和數量。
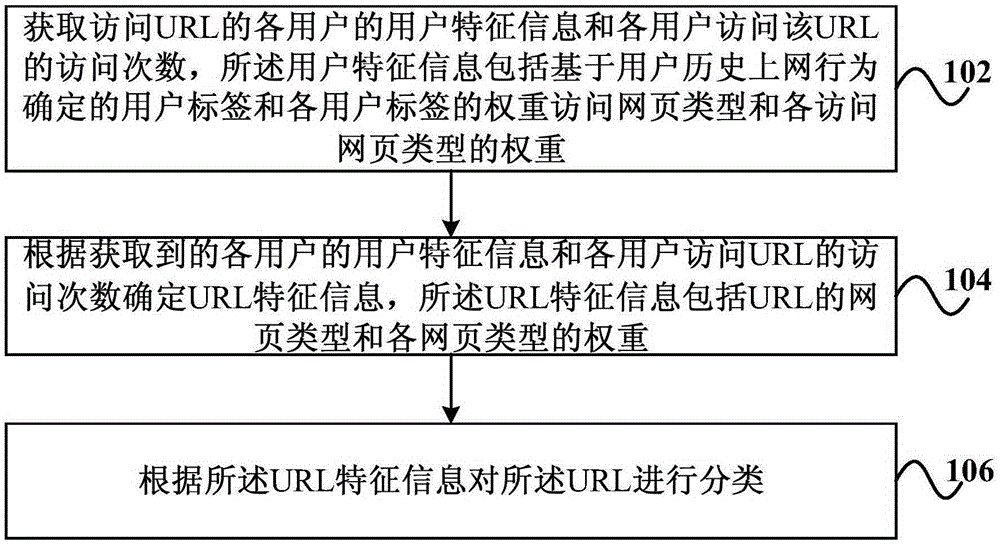
圖1是本發明對URL進行分類的方法一個實施例的流程示意圖。如圖1所示,該方法包括:
步驟102,獲取訪問URL的各用戶的用戶特征信息和各用戶訪問該URL的訪問次數,其中,用戶特征信息包括基于用戶歷史上網行為確定的用戶標簽和各用戶標簽的權重。
這里,根據用戶的歷史上網行為可以得到各用戶的用戶特征信息,例如,用戶經常訪問財經網站和體育網站,則可以給該用戶打上兩個用戶標簽,一個是財經網站,一個是體育網站。根據用戶訪問這兩個網站的次數可以得到這兩個用戶標簽的權重,從而得到用戶特征信息。例如,用戶特征信息可以包括如下內容:用戶標簽為財經網站和體育網站,財經網站的權重為20%,體育網站的權重為80%。
另外,可以對用戶特征信息中的用戶標簽的數量進行調整,例如減少用戶標簽的數量,從而調整最終URL特征信息中的網頁類型的數量。
步驟104,根據獲取到的各用戶的用戶特征信息和各用戶訪問URL的訪問次數確定URL特征信息,該URL特征信息包括URL的網頁類型和各網頁類型的權重。
各用戶的用戶特征信息可以反應URL特征信息,后文將給出示例性的詳細說明。
步驟106,根據URL特征信息對該URL進行分類。
在得到URL的特征信息后,即得到了URL的網頁類型和每個網頁類型的權重,在一個實施例中,可以選擇各網頁類型的權重中最大的一個或多個網頁類型作為URL的網頁類型,以對URL進行分類。
本實施例通過獲取訪問URL的各用戶的用戶特征信息可以確定URL的特征信息,從而可以確定URL的網頁類型,以對URL進行分類。這種分類方式一方面,無需針對不同的URL網站設計個性化算法,分類效率高;另一方面,在不同的URL網站改版后,即網頁類型發生變化時,由于可以根據訪問該URL的用戶特征信息得到URL的特征信息,從而可以及時對URL重新進行分類,自動更新URL地址庫。
作為一個具體實施例,圖1所示步驟104可以通過如下方式來實現:
首先,根據uj=(xj1×kj1,xj2×kj2,…xjn×kjn)×pj/P計算訪問該URL的每個用戶j的標簽向量uj,其中j為正整數,1≤j≤S,S為訪問該URL的用戶總數,xjn為用戶j的用戶標簽,kjn為用戶標簽xjn的權重,jn為正整數,pj為用戶j訪問該URL的訪問次數,P為所有用戶訪問該URL的總訪問次數。
然后,將各用戶j的標簽向量uj中相同用戶標簽的權重累加,并按累加后的用戶標簽的系數的大小對用戶標簽進行排序,例如升序或降序排列,從而得到該URL的標簽向量y=(x1×c1,x2×c2,…,xt×ct),其中如果各用戶的用戶標簽均不相同,則xt為用戶標簽,用戶標簽xt的系數ct為S個用戶的標簽向量uj中與xt相同的用戶標簽的權重之和。具體地,當xt=xjh時,ct可以表示為以下公式:其中kjh∈(kj1,kj2,…kjn),xjh∈(xj1,xj2,…xjn)。
之后,從URL的標簽向量y中選擇用戶標簽的系數最大的前m個用戶標簽x1,x2,…xm作為該URL的網頁類型,并將作為網頁類型xi的權重。即,分別為網頁類型x1,x2,…xm的權重。
本實施例中,通過用戶特征信息和各用戶訪問該URL的訪問次數可以得到各用戶的標簽向量,根據各用戶的標簽向量可以得到URL的標簽向量,從而得到URL的特征信息。
應理解,雖然上述實施例通過標簽向量的方式實現了圖1所示步驟104,然而這并非是限制性的,本領域技術人員可以采用其他方式根據各用戶的用戶特征信息和各用戶訪問URL的訪問次數確定URL特征信息。
下面結合圖2列舉一個例子對本發明對URL進行分類的方法進行詳細說明:
如圖2所示,訪問URL:http://x.x.com的總訪問次數為P=10次。其中,用戶A訪問URL的訪問次數為p1=2次,用戶B訪問URL的訪問次數為p2=8次。
用戶A的用戶特征信息為:新聞,權重為0.6;購物,權重為0.2;體育,權重為0.1。
用戶A的標簽向量為u1=(x1×k11,x2×k12,…x1n×k1n)×p1/P=(新聞×0.6,購物×0.2,體育×0.1)×2/10=(新聞×0.12,購物×0.04,體育×0.02)。
用戶B的用戶特征信息為:購物,權重為0.5;嬰幼,權重為0.3;視頻,權重為0.1。
用戶B的標簽向量為u2=(x1×k21,x2×k22,…x2n×k2n)×p2/P=(購物×0.5,嬰幼×0.3,視頻×0.1)×8/10=(購物×0.4,嬰幼×0.24,視頻×0.08)。
將用戶A的標簽向量為u1和用戶B的標簽向量為u2中相同網頁類型的權重相加(即購物的權重0.04+0.4相加)得到URL:http://x.x.com的標簽向量為:y=(x1×m1,x2×m2,…,xt×mt) =(新聞×0.12,購物×0.44,體育×0.02,嬰幼×0.24,視頻×0.08)。
選擇網頁類型最大的2個,即購物和嬰幼作為URL的網頁類型,或者僅選擇最大的一個,即購物作為URL的網頁類型,以對該URL進行分類。
應理解,圖2示意性地示出了兩個用戶訪問URL的例子,在實際應用中,本發明提供的對URL進行分類的方法尤其適用于訪問次數多的URL,在一個實施例中,可以從采集的DPI數據中篩選出總訪問次數大于預設閾值的URL作為要進行分類的URL,從而增加分類的準確性。例如,計算某一段時間內DPI數據中各URL的訪問次數,排序篩選出總訪問次數大于預設閾值的URL作為要進行分類的URL。
另外,為了驗證分類結果的正確性,在一個實施例中,對URL進行分類的方法還可以包括如下步驟:
步驟S1,采集URL的網頁內容,并根據該URL的網頁內容和特定算法對URL進行分類。
例如,通過人工審核或網頁爬取的方式采集URL的網頁內容,根據該URL的網頁內容,通過文本挖掘算法識別該URL的網頁類型,從而對URL進行分類。這里,對不同的URL需要對文本挖掘算法進行相應的調整。
步驟S2,將步驟S1得到的分類結果與根據URL特征信息對該URL進行分類的分類結果進行比較。
步驟S3,根據比較結果調整預設閾值的大小。
如果兩個結果不一致,則可以將預設閾值的調整為更大的值,從而使得根據URL特征信息對URL進行分類的分類結果更加準確。如果兩個結果一致,則無需調整預設閾值。
本實施例通過對兩種分類結果的比較,可以驗證本發明對URL分類的方法的正確性,根據驗證結果可以適時地調整預設閾值的大小,從而進一步提高分類結果的可靠性。
本發明提供的對URL進行分類的方法同樣適用于對APP地址分類。
本說明書中各個實施例均采用遞進的方式描述,每個實施例重點說 明的都是與其它實施例的不同之處,各個實施例之間相同或相似的部分相互參見即可。對于裝置實施例而言,由于其與方法實施例基本對應,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
圖3是本發明對URL進行分類的裝置一個實施例的結構示意圖。如圖3所示,該裝置包括:
用戶特征信息獲取模塊301,用于獲取訪問URL的各用戶的用戶特征信息和各用戶訪問該URL的訪問次數,其中,用戶特征信息包括基于用戶歷史上網行為確定的用戶標簽和各用戶標簽的權重;
URL特征信息確定模塊302,用于根據獲取到的各用戶的用戶特征信息和各用戶訪問URL的訪問次數確定URL特征信息,URL特征信息包括網頁類型和各網頁類型的權重;
URL分類模塊303,用于根據URL特征信息對URL進行分類。
示例性地,URL分類模塊303具體用于選擇各網頁類型的權重中最大的一個或多個網頁類型作為URL的網頁類型,以對URL進行分類。
本實施例通過獲取訪問URL的各用戶的用戶特征信息可以確定URL的特征信息,從而可以確定URL的網頁類型,以對URL進行分類。這種分類方式一方面,無需針對不同的URL網站設計個性化算法,分類效率高;另一方面,在不同的URL網站改版后,即網頁類型發生變化時,由于可以根據訪問該URL的用戶特征信息得到URL的特征信息,從而可以及時對URL重新進行分類,自動更新URL地址庫。
圖4是本發明對URL進行分類的裝置另一個實施例的結構示意圖。如圖4所示,本實施例中的URL特征信息確定模塊302可以包括:
用戶標簽計算單元311,用于根據uj=(xj1×kj1,xj2×kj2,…xjn×kjn)×pj/P計算訪問該URL的每個用戶j的標簽向量uj,其中j為正整數,1≤j≤S,S為訪問該URL的用戶總數,xjn為用戶j的用戶標簽,kjn為用戶標簽xjn的權重,jn為正整數,pj為用戶j訪問該URL的訪問次數,P為所有用戶訪問該URL的總訪問次數;
URL標簽計算單元321,用于將各用戶j的標簽向量uj中相同用戶標簽的權重累加,并按累加后的用戶標簽的系數的大小對用戶標簽進行 排序,得到該URL的標簽向量y=(x1×c1,x2×c2,…,xt×ct),其中xt為用戶標簽,用戶標簽xt的系數ct為S個用戶的標簽向量uj中與xt相同的用戶標簽的權重之和;
URL特征信息確定單元331,用于從URL的標簽向量y中選擇用戶標簽的系數最大的前m個用戶標簽x1,x2,…xm作為該URL的網頁類型,并將作為網頁類型xi的權重。
本實施例中,通過用戶特征信息和各用戶訪問該URL的訪問次數可以得到各用戶的標簽向量,根據各用戶的標簽向量可以得到URL的標簽向量,從而得到URL的特征信息。
圖5是本發明對URL進行分類的裝置又一個實施例的結構示意圖。如圖5所示,為了提高分類的準確,該裝置還可以包括:
DPI數據分析模塊501,用于從采集的DPI數據中篩選出總訪問次數大于預設閾值的URL作為所述URL。
圖6是本發明對URL進行分類的裝置再一個實施例的結構示意圖。如圖6所示,該裝置還可以包括:
網頁內容采集模塊601,用于采集URL的網頁內容,并根據URL的網頁內容和特定算法識別URL的網頁類型,以對URL進行分類;
比較模塊602,用于將分類結果與根據URL特征信息對URL進行分類的分類結果進行比較;
調整模塊603,用于根據比較結果調整預設閾值的大小。
本實施例通過對兩種分類結果的比較,可以驗證本發明對URL分類的方法的正確性,根據驗證結果可以適時地調整預設閾值的大小,從而進一步提高分類結果的可靠性。
本領域普通技術人員可以理解:實現上述方法實施例的全部或部分步驟可以通過程序指令相關的硬件來完成,前述的程序可以存儲于一計算機可讀取存儲介質中,該程序在執行時,執行包括上述方法實施例的步驟;而前述的存儲介質包括:ROM、RAM、磁碟或者光盤等各種可以存儲程序代碼的介質。
本發明的描述是為了示例和描述起見而給出的,而并不是無遺漏的 或者將本發明限于所公開的形式。很多修改和變化對于本領域的普通技術人員而言是顯然的。選擇和描述實施例是為了更好說明本發明的原理和實際應用,并且使本領域的普通技術人員能夠理解本發明從而設計適于特定用途的帶有各種修改的各種實施例。
- 還沒有人留言評論。精彩留言會獲得點贊!