一種情感新詞的識別方法及裝置與流程
本發明涉及計算機技術領域,尤其涉及一種情感新詞的識別方法及裝置。
背景技術:
大數據是目前一個非常熱門的討論話題,從互聯網的機器實時采集的監測數據,到互聯網上用戶產生的海量的內容數據,都是大數據覆蓋的內容。大數據最核心的價值是:利用數學統計、機器學習、自然語言處理等技術,從大數據中挖掘出有價值的信息知識,從而能夠對事物進行預測。由于web2.0的迅猛發展,用戶在互聯網上產生大量的內容文本信息,例如互聯網上的社會化媒體(社交網站、社區等)數據(評論、社交關系、地理位置等信息)。對文本信息進行分析挖掘都離不開自然語言處理技術,而中文分詞是文本挖掘的基礎,對于輸入的一段中文,成功的進行中文分詞,可以達到電腦自動識別語句含義的效果。
現有的分詞算法可分為三大類:基于字符串匹配的分詞方法、基于理解的分詞方法和基于統計的分詞方法。按照是否與詞性標注過程相結合,又可以分為單純分詞方法和分詞與標注相結合的一體化方法。而隨著微博等新型社交媒體的快速發展,互聯網出現大量富有個人情感表達的新詞。情感新詞是指尚未收錄到詞典中的帶有情感傾向性的新詞。而這些新詞的出現使得現有的分詞方法不能有效的將這些新詞從文本中提取出來,從到導致整篇文本分詞的準確性降低。而現有的對于新詞的判斷與提取,則常用到獨立詞概率(IWP,independent word probability),隱馬爾可夫模型,分類模型,最大熵或條件隨機場等方法提取新詞候選集,然后對候選集進行過濾得到新詞。而這些方法雖然能夠獲取到新詞,但方法的統計特征一般相對獨立,缺少相互關聯和全局信息,不能充分發揮大規模訓練語料的作用而判斷出新詞的情感傾向性。
技術實現要素:
有鑒于此,本發明提供一種情感新詞的識別方法及裝置,主要目的在于實現自動識別新詞的同時判斷新詞的情感傾向性。
為達到上述目的,本發明主要提供如下技術方案:
一方面,本發明提供了一種情感新詞的識別方法,該方法包括:
確定測試文本中的新詞,所述新詞為現有詞典中未收錄的詞;
利用含有所述新詞的詞典,構建詞向量模型,所述詞向量模型用于計算所述詞典中詞的相似度;
利用所述詞向量模型,計算出至少一個與所述新詞相似的情感詞;
根據所述情感詞的情感傾向性,判斷所述新詞的情感傾向性。
另一方面,本發明還提供了一種情感新詞的識別裝置,該裝置包括:
確定單元,用于確定測試文本中的新詞,所述新詞為現有詞典中未收錄的詞;
構建單元,用于利用含有所述確定單元確定的新詞的詞典,構建詞向量模型,所述詞向量模型用于計算所述詞典中詞的相似度;
計算單元,用于利用所述構建單元構建的詞向量模型,計算出至少一個與所述新詞相似的情感詞;
判斷單元,用于根據所述計算單元計算出的情感詞的情感傾向性,判斷所述新詞的情感傾向性。
依據上述本發明所提出的情感新詞的識別方法及裝置,是通過對測試文本進行分詞并根據分詞之間的相關度,確定該測試文本中是否存在有新詞,同時將新詞提取出來添加到原詞典中,再利用含有新詞的詞典對測試文本進行分詞,根據得到的分詞構建詞向量模型。將新詞帶入到該詞向量模型中,計算出與新詞相關度較高的一批相關詞,再將這些相關詞帶入到預置的情感詞典中,判斷相關詞的情感傾向性,由于相關詞具有較高的相關性,因此,這些相關詞的情感傾向性也具有相似性,通過對相關詞的情感傾向性的綜合判斷就能夠確定出新詞的情感傾向性。和現有技術相比,本發明將新詞的識別與對該詞的情感識別通過構建詞向量模型進行關聯,能夠有效的在識別新詞的同時對新詞的情感傾向性進行判斷,從而提高對 測試文本的分析效率。
附圖說明
通過閱讀下文優選實施方式的詳細描述,各種其他的優點和益處對于本領域普通技術人員將變得清楚明了。附圖僅用于示出優選實施方式的目的,而并不認為是對本發明的限制。而且在整個附圖中,用相同的參考符號表示相同的部件。在附圖中:
圖1示出了本發明實施例提出的一種情感新詞的識別方法的流程圖;
圖2示出了本發明實施例提出的另一種情感新詞的識別方法的流程圖;
圖3示出了本發明實施例提出的一種情感新詞的識別裝置的組成框圖;
圖4示出了本發明實施例提出的另一種情感新詞的識別裝置的組成框圖。
具體實施方式
下面將參照附圖更詳細地描述本發明的示例性實施例。雖然附圖中顯示了本發明的示例性實施例,然而應當理解,可以以各種形式實現本發明而不應被這里闡述的實施例所限制。相反,提供這些實施例是為了能夠更透徹地理解本發明,并且能夠將本發明的范圍完整的傳達給本領域的技術人員。
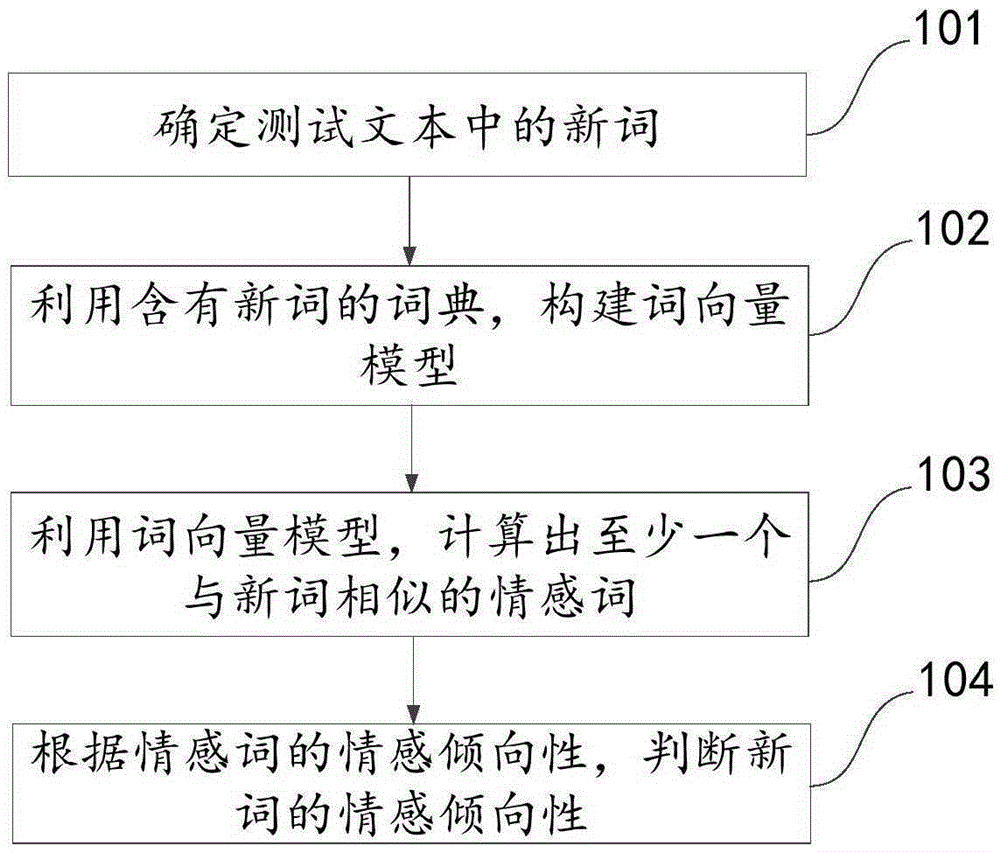
本發明實施例提供了一種情感新詞的識別方法,如圖1所示,具體步驟包括:
101、確定測試文本中的新詞。
伴隨著時代發展與技術的進步,大量新詞的出現已經成為不可避免的語言現象。這些新詞是現有的詞典中未收錄的詞匯,即新詞是指隨時代發展而新出現或舊詞新用的詞,如“非典”、“山寨”等。對于舊詞新用這類的新詞需要在字典中改變或增加其原有的意思,并且需要對其情感傾向性做重新的定義。而對于新出現的詞匯,由于現有的詞典中并未收錄,因此,在做文本分詞時是無法將其從測試文本中提取出來的,更無法進一步判斷其情感傾向性。
對于新詞的提取,現有的方法總體上分為兩種:基于規則的方法和基于統計的方法。前者利用構詞學原理、配合語義信息或詞性信息來構造模板,然后通過匹配來發現新詞;而后者是通過對語料中的詞條組成或特征信息進行統計來識別新詞。基于規則方法的優點是準確率高,針對性強,但手工編寫和維護規則困難,且規則一般是領域相關的,所以適應性和移植性比較差;基于統計方法的優點是靈活、適應能力強,可移植性好,但需要大規模語料進行模型訓練。較為常用的新詞提取方法包括獨立詞概率,隱馬爾可夫模型,分類模型,最大熵或條件隨機場等方法。本發明實施例對于新詞的提取不限定具體的實現方式,在本步驟中,只要能夠將測試文本中的新詞選取出來即可。
102、利用含有新詞的詞典,構建詞向量模型。
將101中提出的新詞加入到現有的詞典中,利用含有新詞的詞典對測試文本進行分詞就可以將新詞進行有效的劃分。并且利用分詞所得到的結果可以構建對應的詞向量模型。在該模型中,文本中的每一個詞都有相對應的向量值。通過向量值的比較就可得出不同詞之間的相關程度,即相似性。
所謂詞向量,就是由計算機對自然語言中的詞匯加以識別及運算的一種數學化的符號。最常用的方法是將每個詞表示為一個很長的向量,這個向量的維度是詞表大小,其中絕大多數元素為0,只有一個維度的值為1,這個維度就代表了當前的詞。通過將詞進行向量化的表示后,構建低緯度的詞向量模型,而該模型的主要目的在于通過計算詞與詞之間的距離來表示兩者之間的相關性或近似性,而兩個詞的距離在該模型中可以表示為兩個向量之間的距離,可以使用最傳統的歐式距離衡量,也可以用余弦夾角來計算。
103、利用詞向量模型,計算出至少一個與新詞相似的情感詞。
通過將新詞帶入到102中所構建的詞向量模型中進行計算,可以計算出與新詞相近似的若干相關詞,而這些相關詞在不同的領域中都會具有一定的情感傾向性,而不論其情感傾向性的方向與程度如何,均可以稱這些具有情感傾向性的相關詞為情感詞。
104、根據情感詞的情感傾向性,判斷新詞的情感傾向性。
由于103中得到的情感詞是通過詞向量模型計算出的相關詞,因此,該新詞與所述情感詞在一定程度上是具有相同的情感傾向性的,所以通過判斷情感詞的情感傾向性,就可以確定新詞的情感傾向性。而對于情感詞的情感傾向判斷,則可以利用現有的情感詞典判斷。由于情感詞在不同領域中所表現得情感傾向性會有所差異,因此,不同領域中會有不同情感詞典,本發明實施例可以根據測試文本所屬的領域選擇適合的情感詞典。
結合上述的實現方式可以看出,本發明實施例所采用的情感新詞的識別方法,是通過對測試文本進行分詞并根據分詞之間的相關度,確定該測試文本中是否存在有新詞,同時將新詞提取出來添加到原詞典中,再利用含有新詞的詞典對測試文本進行分詞,根據得到的分詞構建詞向量模型。將新詞帶入到該詞向量模型中,計算出與新詞相關度較高的一批相關詞,再將這些相關詞帶入到預置的情感詞典中,判斷相關詞的情感傾向性,由于相關詞具有較高的相關性,因此,這些相關詞的情感傾向性也具有相似性,通過對相關詞的情感傾向性的綜合判斷就能夠確定出新詞的情感傾向性。和現有技術相比,本發明將新詞的識別與對該詞的情感識別通過構建詞向量模型進行關聯,能夠有效的在識別新詞的同時對新詞的情感傾向性進行判斷,從而提高對測試文本的分析效率。
為了更加詳細地說明本發明提出的一種情感新詞的識別方法,本發明實施例通過具體的實現方式進行具體說明,如圖2所示,該方法所包括的步驟為:
201、利用互信息確定測試文本中準新詞的候選詞集。
在本實施例中,確定新詞的方式是先對測試文本使用現有的詞典進行分詞,分詞后再通過計算相鄰分詞之間的互信息來確定相鄰的兩個分詞組合成新詞的概率,將互信息的概率達到預置的概率閾值的分詞組合添加到準新詞候選詞集中。
其中,互信息是計算語言學模型分析的常用方法,它度量兩個對象之間的相互性。在過濾問題中用于度量特征對于主題的區分度。互信息的定義與交叉嫡近似。互信息本來是信息論中的一個概念,用于表示信息之間 的關系,是兩個隨機變量統計相關性的測度,使用互信息理論進行特征抽取是基于如下假設:在某個特定類別出現頻率高,但在其他類別出現頻率比較低的詞條與該類的互信息比較大。通常用互信息作為特征詞和類別之間的測度,如果特征詞屬于該類的話,它們的互信息量最大。由于該方法不需要對特征詞和類別之間關系的性質作任何假設,因此非常適合于文本分類的特征和類別的配準工作。需要說明的是,在本發明實施例中的互信息概率閾值是預先進行設定的,該值為經驗值,是能夠根據需要得出新詞的概率進行動態調整的。此外,在候選詞集中,準新詞的組成可以是兩個分詞,還可以是多個分詞,并且同一個分詞還可以作為不同準新詞的組成部分。
202、通過計算候選詞集中準新詞的鄰接熵來確定新詞。
在確定了候選詞集后,再判斷每個準新詞的鄰接熵,鄰接熵在信息論中的定義是用來衡量變量的不確定性,即統計該準新詞在測試文本中與其他詞進行搭配的種類。如果熵值越大,說明該準新詞在文本中與其他詞的組合種類就越豐富,那么該準新詞成為新詞的概率就越大。相反的,如果熵值小,說明該準新詞所搭配的其他詞的種類就少,那么該準新詞是其他詞組的一部分的可能性就高,而成為獨立的新詞的可能性就小。而將準新詞確定為新詞的熵值與互信息的概率閾值一樣,都是可以預先設置的一個經驗值,并且該熵值閾值可以進行動態的調整。
進一步的,在判斷準新詞的鄰接熵時,可以將鄰接熵的計算分為左鄰接熵與右鄰接熵,分別加以計算,并且對于熵值閾值也可以進行分別的設置加以判斷,從而提高新詞判斷的準確性。
203、利用含有新詞的詞典,構建詞向量模型。
將新詞從測試文本中提取出來后,將新詞添加到詞典中。使用更新有新詞的詞典對測試文本進行重新分詞,就能夠將測試文本中的新詞有效的提取出來。利用此次的分詞結果來構建詞向量模型。
204、利用詞向量模型,計算出至少一個與新詞相似的情感詞。
在構建好詞向量模型后,還需要對該模型中的一些具體參數進行設置,從而來調節模型的計算結果。如設置結果相關詞的個數、模型學習的速率、 設置窗口大小,即設置輸入的新詞在進行計算時所考慮的前后詞的個數。
通過對模型具體參數的設置,模型會根據輸入的新詞在測試文本中位置,來抽取該詞前后的若干詞,并根據若干詞的相關性以及排列的順序,查找出具有相同順序以及位置的相關詞。即通過該模型的計算可以得到與輸入新詞的向量值相似度的已有相關詞。在得到的相關詞中,按照相似度由高至低的順序將相關詞依次帶入到預置的情感詞典中進行匹配,判斷這些相關詞是否具有情感傾向性。并且將具有情感傾向性的相關詞提取出來。
205、根據情感詞的情感傾向性,判斷新詞的情感傾向性。
根據204中相關詞所具有的情感傾向性,通過綜合計算,就可以得到新詞的情感傾向性。具體的可以通過將相關詞的情感傾向性以及與新詞的相似度向結合,通過加權計算的方式得出新詞的情感傾向性。本實施例對于具體的計算方式不作具體限定。因為相關詞本身是通過詞向量模型計算的得出的具有相似度的詞,所以只要確定了相關詞的情感傾向性,根據相似原則就可以判斷出新詞的情感傾向性。
通過本實施例所述的方法,通過互信息與鄰接熵來判斷測試文本中的新詞,不僅大大提高了新詞的識別準確率,并且能夠在識別新詞的同時通過詞向量模型與情感詞典的配合將該詞的情感傾向一同判斷出來,從而為提高測試文本的情感分析效率提供了保障。
進一步的,作為對上述方法的實現,本發明實施例提供了一種情感新詞的識別裝置,該裝置實施例與前述方法實施例對應,為便于閱讀,本裝置實施例不再對前述方法實施例中的細節內容進行逐一贅述,但應當明確,本實施例中的裝置能夠對應實現前述方法實施例中的全部內容。如圖3所示,該裝置包括:
確定單元31,用于確定測試文本中的新詞,所述新詞為現有詞典中未收錄的詞;
構建單元32,用于利用含有所述確定單元31確定的新詞的詞典,構建詞向量模型,所述詞向量模型用于計算所述詞典中詞的相似度;
計算單元33,用于利用所述構建單元32構建的詞向量模型,計算出至少一個與所述新詞相似的情感詞;
判斷單元34,用于根據所述計算單元33計算出的情感詞的情感傾向性,判斷所述新詞的情感傾向性。
進一步的,如圖4所示,所述裝置的確定單元31包括:
分詞模塊311,用于將所述測試文本進行分詞處理;
計算模塊312,用于利用由所述分詞模塊311得到的相鄰分詞之間的互信息計算所述相鄰分詞組成新詞的概率值;
組合模塊313,用于根據預置的概率閾值,將由所述計算模塊312計算的概率值大于所述概率閾值的相鄰分詞組成準新詞;
確定模塊314,用于通過計算所述組合模塊313組成的準新詞的鄰接熵,將所述鄰接熵符合預置條件的準新詞確定為新詞。
進一步的,如圖4所示,該裝置的確定模塊314包括:
計算子模塊3141,用于分別計算所述準新詞的左鄰接熵與右鄰接熵;
判斷子模塊3142,用于判斷由所述計算子模塊3141計算左鄰接熵與右鄰接熵的熵值是否大于預置的熵值閾值;
確定子模塊3143,用于當所述判斷子模塊3142的判斷結果為大于所述熵值閾值時,確定所述準新詞為新詞。
進一步的,如圖4所示,所述裝置的構建單元32包括:
分詞模塊321,用于利用含有所述新詞的詞典,對所述測試文本進行分詞;
構建模塊322,用于根據由所述分詞模塊321獲得的分詞結果構建所述詞向量模型。
進一步的,如圖4所示,所述裝置的計算單元33包括:
設置模塊331,用于設置所述詞向量模型的計算參數;
計算模塊332,用于由所述詞向量模型根據所述設置模塊331設置的計算參數計算出至少一個與所述新詞相似的情感詞。
進一步的,如圖4所示,所述裝置的判斷單元34包括:
確定模塊341,用于根據預置的情感詞典,確定所述情感詞的情感傾向性;
判斷模塊342,用于根據所述確定模塊341確定的情感詞的情感傾向性 以及所述情感詞與新詞的相關度,判斷所述新詞的情感傾向性。
綜上所述,本發明實施例所采用的情感新詞的識別方法及裝置,是通過對測試文本進行分詞并根據分詞之間的相關度,確定該測試文本中是否存在有新詞,同時將新詞提取出來添加到原詞典中,再利用含有新詞的詞典對測試文本進行分詞,根據得到的分詞構建詞向量模型。將新詞帶入到該詞向量模型中,計算出與新詞相關度較高的一批相關詞,再將這些相關詞帶入到預置的情感詞典中,判斷相關詞的情感傾向性,由于相關詞具有較高的相關性,因此,這些相關詞的情感傾向性也具有相似性,通過對相關詞的情感傾向性的綜合判斷就能夠確定出新詞的情感傾向性。和現有技術相比,本發明將新詞的識別與對該詞的情感識別通過構建詞向量模型進行關聯,能夠有效的在識別新詞的同時對新詞的情感傾向性進行判斷,從而提高對測試文本的分析效率。
所述情感新詞的識別裝置包括處理器和存儲器,上述確定單元、構建單元、計算單元和判斷單元等均作為程序單元存儲在存儲器中,由處理器執行存儲在存儲器中的上述程序單元來實現相應的功能。
處理器中包含內核,由內核去存儲器中調取相應的程序單元。內核可以設置一個或以上,通過調整內核參數來實現自動識別新詞的同時判斷新詞的情感傾向性。
存儲器可能包括計算機可讀介質中的非永久性存儲器,隨機存取存儲器(RAM)和/或非易失性內存等形式,如只讀存儲器(ROM)或閃存(flash RAM),存儲器包括至少一個存儲芯片。
本申請還提供了一種計算機程序產品,當在數據處理設備上執行時,適于執行初始化有如下方法步驟的程序代碼:確定測試文本中的新詞,所述新詞為現有詞典中未收錄的詞;利用含有所述新詞的詞典,構建詞向量模型,所述詞向量模型用于計算所述詞典中詞的相似度;利用所述詞向量模型,計算出至少一個與所述新詞相似的情感詞;根據所述情感詞的情感傾向性,判斷所述新詞的情感傾向性。
本領域內的技術人員應明白,本申請的實施例可提供為方法、系統、或計算機程序產品。因此,本申請可采用完全硬件實施例、完全軟件實施 例、或結合軟件和硬件方面的實施例的形式。而且,本申請可采用在一個或多個其中包含有計算機可用程序代碼的計算機可用存儲介質(包括但不限于磁盤存儲器、CD-ROM、光學存儲器等)上實施的計算機程序產品的形式。
本申請是參照根據本申請實施例的方法、設備(系統)、和計算機程序產品的流程圖和/或方框圖來描述的。應理解可由計算機程序指令實現流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框圖中的流程和/或方框的結合。可提供這些計算機程序指令到通用計算機、專用計算機、嵌入式處理機或其他可編程數據處理設備的處理器以產生一個機器,使得通過計算機或其他可編程數據處理設備的處理器執行的指令產生用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。
這些計算機程序指令也可存儲在能引導計算機或其他可編程數據處理設備以特定方式工作的計算機可讀存儲器中,使得存儲在該計算機可讀存儲器中的指令產生包括指令裝置的制造品,該指令裝置實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。
這些計算機程序指令也可裝載到計算機或其他可編程數據處理設備上,使得在計算機或其他可編程設備上執行一系列操作步驟以產生計算機實現的處理,從而在計算機或其他可編程設備上執行的指令提供用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。
在一個典型的配置中,計算設備包括一個或多個處理器(CPU)、輸入/輸出接口、網絡接口和內存。
存儲器可能包括計算機可讀介質中的非永久性存儲器,隨機存取存儲器(RAM)和/或非易失性內存等形式,如只讀存儲器(ROM)或閃存(flash RAM)。存儲器是計算機可讀介質的示例。
計算機可讀介質包括永久性和非永久性、可移動和非可移動媒體可以由任何方法或技術來實現信息存儲。信息可以是計算機可讀指令、數據結構、程序的模塊或其他數據。計算機的存儲介質的例子包括,但不限于相 變內存(PRAM)、靜態隨機存取存儲器(SRAM)、動態隨機存取存儲器(DRAM)、其他類型的隨機存取存儲器(RAM)、只讀存儲器(ROM)、電可擦除可編程只讀存儲器(EEPROM)、快閃記憶體或其他內存技術、只讀光盤只讀存儲器(CD-ROM)、數字多功能光盤(DVD)或其他光學存儲、磁盒式磁帶,磁帶磁磁盤存儲或其他磁性存儲設備或任何其他非傳輸介質,可用于存儲可以被計算設備訪問的信息。按照本文中的界定,計算機可讀介質不包括暫存電腦可讀媒體(transitory media),如調制的數據信號和載波。
還需要說明的是,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、商品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、商品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括要素的過程、方法、商品或者設備中還存在另外的相同要素。
本領域技術人員應明白,本申請的實施例可提供為方法、系統或計算機程序產品。因此,本申請可采用完全硬件實施例、完全軟件實施例或結合軟件和硬件方面的實施例的形式。而且,本申請可采用在一個或多個其中包含有計算機可用程序代碼的計算機可用存儲介質(包括但不限于磁盤存儲器、CD-ROM、光學存儲器等)上實施的計算機程序產品的形式。
以上僅為本申請的實施例而已,并不用于限制本申請。對于本領域技術人員來說,本申請可以有各種更改和變化。凡在本申請的精神和原理之內所作的任何修改、等同替換、改進等,均應包含在本申請的權利要求范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!