一種基于可分解詞包模型的圖像檢索方法與流程
本申請涉及一種圖像檢索方法,尤其涉及一種基于可分解詞包模型的圖像檢索方法,屬于計算機視覺和模式識別領域。
背景技術:
隨著多媒體技術的發展,數字圖像因其直觀形象的表現形式,在互聯網、衛星系統、信息管理以及各類監控系統中得到廣泛應用。在數字圖像大規模應用的背景下,其數量在急劇增長。因此,面對這樣一個巨大的、實時擴展、時刻變化的圖像數據庫,如何有效地組織和管理,并且在浩如煙海的圖像數據庫中找到所需圖像,成為相關領域的研究熱點。
針對基于本文檢索的傳統圖像檢索效率低下且無法在圖像內容層面上對圖像進行檢索的局限性,基于內容的圖像檢索(CBIR,Content-based Image Retrieval)應運而生。CBIR首先選擇合適的特征來表示圖像,并對已有圖像建立特征數據庫。在對圖像進行查詢的時候,提取待查詢圖像的相應特征,然后與數據庫中的圖像特征進行比對,返回特征數據上相似的圖像作為候選圖像。
特征索引是加速CBIR過程的重要技術手段。在檢索的過程中,待檢索圖像先與索引項進行比對,過濾掉大部分不相似的圖像,然后再對索引項下的圖像逐一匹配,從而得到候選圖像。詞包模型(BoW,Bag of Words)是基于內容的圖像檢索中廣泛應用的特征索引方法。BoW來源于文本檢索,在計算機視覺中,BoW將圖像看作是一篇文檔(Document),而其特征則是文檔中的單詞(Word)。BoW通過聚類等手段將在度量空間上距離相近的特征歸入同一個詞條,將所有的詞條組成詞典(Codebook),所有的圖像均由詞條來表示。詞包模型以詞匯樹(Vocabulary Tree)的形式組織所有單詞,以詞條作為索引項用于檢索,或者以詞頻統計直方圖對文檔進行編碼,然后以倒排的方式建立索引。
針對大規模圖像數據,除了數據量在動態變化之外,圖像的類型也隨著數據量的增長而增加。傳統的詞包模型針對的一類圖像適用的單種特 征無法應對動態圖像的復雜性。因此多特征的圖像檢索在提升檢索準確率方面是至關重要的。
針對此問題,許多研究者從如下兩個方面進行解決:基于特征級融合的檢索,即在建立索引之前對多種特征進行有效的融合,使得融合成的新特征能夠包含多種特征的信息,從而提升檢索準確率;基于決策級融合的檢索,首先在全庫中篩選出多個候選集,然后通過某種準則對候選目標進行檢索聚合,從而給出符合條件的檢索結果。
在大規模多特征數據的應用背景下,現有的檢索方法存在以下兩個方面不足:
(1)基于多特征融合的方法容易受特征間的相互影響干擾
針對多特征數據,特征的融合必然帶來多特征之間的相互影響。簡單的特征融合難以保證這種影響能夠有利于提高檢索準確率。一方面,當顯著的特征與不顯著的特征融合在一起,可能造成檢索準確率的下降(如圖2所示);另一方面,面向不同信息類型的特征,由于數據形式大相庭徑,簡單融合可能引發其中某些特征所攜帶信息的埋沒(如圖3所示)。根據圖2、圖3中對比較兩種特征單獨檢索與經過簡單拼接的融合后的檢索結果可知,簡單地融合多個特征并不能保證最終的檢索準確率高于原有的單個特征。
針對以上問題,雖然前人在特征融合技術上已有較為成熟的研究,融合的特征也常被用在CBIR系統中建立索引,然而特征融合需要大量的先驗知識作為背景。在大規模圖像數據上,先驗知識較少,不利于進行多特征的融合。使用固定的融合特征,則會隨著圖像數據集的改變而無法確定特征的有效性。其他基于決策融合的方法,也存在一定的局限性。例如,基于統計排序的方法沒有考慮特征本身的檢索效果,僅以簡單的中位數作為最終的檢索結果。
(2)傳統的詞包模型不能適應特征類型的變化
隨著圖像數據量的不斷增長,原有的圖像數據庫可能需要引入新的圖像類型,從而需要新的特征來對庫中圖像建立高效的索引。例如,在各類監控系統中,運動的目標作為感興趣目標而需要被檢索。在卡口的監控下,行人、車輛甚至船只均是常出現的運動目標,而對這些不同類型的目標,需要不同的特征組合進行檢索。隨著監控需求的變化,檢索的側重點也不盡相同,因此需要對特征數據有動態的選擇。然而傳統的詞包模型則無法應對特征種類變化的需求。
技術實現要素:
本申請提出了一種基于可分解詞包模型的圖像檢索方法。該方法對圖像提取多種特征,并通過聚類為每一種特征建立一個詞包索引。該方法對多特征檢索建立線性判別式,并通過預檢索過程學習每種特征的顯著性權重作為其系數。在檢索過程中,每個特征的詞包索引將獨立地返回候選集,然后利用線性判別式對所有候選集中的目標進行加權評分,將檢索結果聚合成一個有序的候選集,最后根據需要返回得分最高的若干目標作為最終的檢索結果。
為實現上述目的,本申請采用下述技術方案。
基于可分解詞包模型的圖像檢索方法,其特征在于包括如下步驟:
(1)對建庫圖像提取多種特征,并且單獨為每種特征建立索引;
(2)針對上述特征對應的索引,利用詞包模型組織每種特征數據,對所述特征數據進行聚類,以聚類中心作為詞包模型中的詞條,原始圖像以詞包模型中的相應詞條進行表示,從而所述詞條與原始圖像之間構成倒排關系;
(3)為多特征檢索建立線性判別函數,通過預檢索過程以最小均方差準則學習特征的顯著性權重,并作為所述線性判別函數中的系數,以衡量每種特征對最終檢索結果的影響程度;
(4)在檢索過程中,對待檢索圖像提取相應的多種特征,針對每種特征獨立地給出候選集,利用每種特征的顯著性權重,以所述線性判別函數對多種特征的候選集進行檢索聚合。
如上所述的基于可分解詞包模型的圖像檢索方法,其特征在于所述步驟(1)中為了保證多種特征之間的索引在組織結構上互不干擾,采用同樣的索引方法,依次對每種特征進行索引,使得不同特征之間在特征組織結構上沒有橫向關聯。值得注意的是,方法采用的具體多特征類型并不是本專利所需關心的內容,基于可分解詞包模型的圖像檢索方法的重點在于,在已有的多種特征中如何提高檢索準確率。
如上所述的基于可分解詞包模型的圖像檢索方法,其特征在于所述步驟(3)中,學習得到每種特征對建庫圖像的顯著性,對現有數據進行預檢索,首先對數據庫進行隨機抽樣得到訓練數據集,然后對樣本在每種特征上進行檢索,最后對預檢索的結果進行回歸擬合,擬合后的系數則為每種特征的顯著性權重。
如上所述的基于可分解詞包模型的圖像檢索方法,其特征在于所述步驟(4)中,為了根據特征的不同顯著性進行檢索聚合,根據步驟(3)中所學習得到的顯著性權重,利用下列公式計算候選圖像的最后得分:
其中對于N種特征,yi表示第i張圖像的決策級融合得分,xij表示第i張在第j種特征上與待檢索圖像的歐氏距離,βj表示第j種特征通過步驟(3)學習所得的顯著性權重,β0為判別式(1)的偏置系數。
至此,本申請提出了一種基于可分解詞包模型的圖像檢索方法,該方法與當前主流方法相比可以較好地提高檢索準確率,并且適用于實際的大規模圖像檢索應用中。
附圖說明
下面結合附圖和具體實施方式對本申請作進一步的說明。
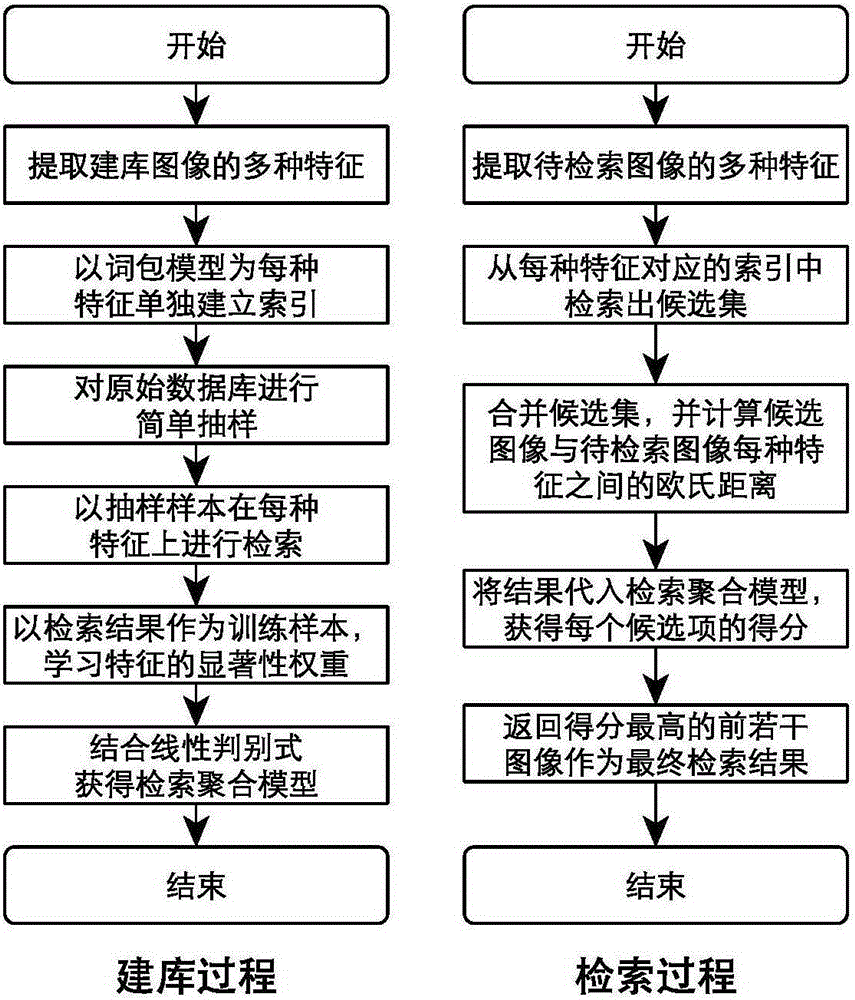
圖1本申請的框架圖
圖2顯著特征與不顯著特征融合造成的檢索準確率下降
圖3由于數據形式的不同造成的特征顯著性埋沒
圖4基于檢索聚合的多特征索引結構示意圖
圖5本申請所述方法在ZuBuD數據集上的實驗結果
圖6本申請所述方法在CAVIAR4REID數據集上的實驗結果
具體實施方式
下面結合附圖和具體實施方式對本申請作進一步的詳細說明。本申請提出了一種基于可分解詞包模型的圖像檢索方法,方法流程如圖1所示,包括以下四個部分:第一、對圖像提取多種特征,并且單獨為每種特征建立索引;第二、針對上述特征中的索引,利用詞包模型組織每種特征數據,并對特征數據進行聚類,以聚類中心作為詞包模型中的詞條;第三、為多特征檢索建立線性判別函數,通過預檢索過程以最小均方差準則學習特征的顯著性權重,并作為線性判別函數中的系數;第四、在檢索過程中,每種特征均獨立地給出候選集。最終的檢索結果利用每種特征的顯著性權重,以線性判別函數對多特征對檢索結果進行聚合。
本方法尤其適用于大規模圖像應用背景下的圖像檢索工作。下面展開具體說明,圖1展示了根據本申請的一個實施例的流程圖,包括:
首先按照需要對圖像提取多種特征,例如,顏色直方圖、LBP、HoG等,從而使得更多信息被提取出來,以備后續進行決策融合。然后,每一種特征將被獨立地使用詞包模型建立特征到圖像的倒排索引。其中,建立某一種特征的倒排索引的過程如下:
(1)針對上述多種特征中的一種,向所有圖像提取該特征;
(2)通過KMeans聚類提取出的特征,并返回若干聚類中心;
(3)此時,上述聚類中心即為詞包模型的詞條,也即該特征的索引,且每一個聚類中心都不重復地包含了數據庫中的圖像。
針對每一種特征都重復上述(1)-(3)步操作,即可使得每一種特征各自生成一個互不干擾的特征索引。在針對每一種特征的檢索過程中,首先從待檢索圖像上提取相應特征,然后將該特征與特征索引進行一一比較,返 回與待檢索圖像特征歐式距離最小的索引項所關聯的圖像作為候選集。
由于不同特征在顯著性與數據形式上存在差異,簡單地融合多特征數據所帶來的數據相互影響不能保證有利于提高檢索效率。同時針對大規模圖像數據,單一的索引無法滿足多變的檢索需求。因此通過分解多特征數據,使得不同的特征以其原始形式獨立存在,避免了不同特征之間的相互干擾,如圖4所示。
由于對多特征進行了分解,因此會得到多個檢索的候選集,檢索聚合即是在這些候選目標中進行再篩選,從而給出合適的檢索結果。考慮到不同特征存在不同的顯著性,為了提升顯著特征在選擇最終檢索結果時發揮的作用,同時降低非顯著特征的干擾,本申請所述方法,從每個特征本身對數據的檢索準確率作為特征顯著性的度量,量化特征的顯著性作為權重,給候選目標進行評分,從而對不同候選集中的候選目標進行再排序,給出最終檢索結果。
具體的做法是,在建立多特征分解索引后,對庫中的目標進行預檢索,從返回的檢索結果中收集候選目標與檢索目標在各個特征上的歐氏距離,形成訓練數據如(1)所示。根據最小均方差回歸,以線性判別式(2)對特征距離進行訓練,從而獲得對各個特征距離的權重系數。在正式的檢索時,根據訓練后的判別式為候選目標打分,從而獲得最終的檢索結果。
其中X是訓練數據集,Y是目標結果集,其中yi表示第i張圖像的決策級融合得分,xij表示第i張圖在第j種特征上與待檢索圖像的歐氏距離,M是訓練樣本數量,N是特征種類個數。
其中yi,xij的含義同(1),βj表示第j種特征通過步驟(3)學習所得的顯著性權重,β0為判別式(2)的偏置系數,β={β0,β1,…,βN}。
為了減少運算量,本申請所屬方法先對原始數據集進行簡單抽樣,再進行預檢索。同時為了得到均衡的樣本,正樣本、負樣本的數量應大致保持相同。預檢索的過程如下:
(1)向全庫圖像進行簡單隨機抽樣,獲得n個抽樣樣本;
(2)對每個抽樣樣本在每種特征上分別進行20近鄰檢索,合并每種 特征上得到的候選圖片,計算每一張候選圖片各個特征與樣本圖像相應特征之間的歐式距離;記第j個特征上候選圖像與樣本圖像的歐氏距離為xij,那么對于第i張圖像(1≤i≤n),則有向量xi=[1xi1···xiM]為訓練樣本;
(3)若當前候選圖片與樣本圖像是源于一個目標,那么記相應的yi值為0,否則為1。
(4)統計當前樣本圖像檢索結果中正樣本(yi=0的樣本)數量,從負樣本(yi=1的樣本)中隨機抽取相同數量的樣本,與正樣本一同納入訓練數據集X以及目標結果集Y;
(5)重復(2)(3)(4)直到所有抽樣樣本均被檢索;
至此,預檢索的過程完成。
為了學習得到每種特征的權重,在預檢索過程之后,將對訓練數據集X以及目標結果集Y進行最小均方差回歸。考慮到X、Y的表達式(1)以及相應的線性判別式(2),那么關于X、Y的關系表達式為:
Y=Xβ (3)
其中β={β0,β1,…,βN}T為回歸參數,由每個特征的權重{β1,…,βN}以及偏置β0組成。
令為β的估計,那么最小均方差回歸以下式進行:
在實際檢索的過程中,對于每張待檢索圖像通過與預檢索過程(2)相同的步驟,獲得其xi,然后代入計算其得分。最后將按從小到大排序,值越小認為其得分越高。得分最高的前n項,就是待檢索圖像的n近鄰檢索結果。
將本申請的基于可分解詞包模型的圖像檢索方法與基于PCA的特征融合方法(PCA)、中位數投票法(MidRank)、均權投票法(Borda)、基于詞頻統計的加權投票(TF-IDF)、LRFF融合法(LRFF)以及用詞包模型結合SVM的方法(BoW+SVM)這六種多特征圖像檢索方法進行對比。對比過程中,逐步增加多特征數量,并以多特征中檢索準確率最高的特征的檢索結果作為基線(BSF,Best Single Feature)。實驗在ZuBuD和CAVIAR4REID兩個分別表示建筑和行人的圖像數據庫上進行,實驗結果分別如圖5和圖6所示。其中實驗使用的特征及其編號為:1.CEDD,2.LBP,3.Color Layout,4.PHOG,5.Color Histogram,6.FCTH,7.Gabor Texture。
對比以上六種多特征圖像檢索方法,本申請所提方法能夠顯著提高在多特征背景下的檢索準確率。尤其在CAVIAR4REID數據集上,對于使用普通等權投票的模型檢索準確率提高了13.57%;對于其他六種方法,準確率提高了5.42%。實驗結果表明與當前其他算法相比,基于可分解詞包模型的圖像檢索方法可以有效提高識別準確率。
以上公開的僅為本申請的具體實施例。根據本申請提供的技術思想,本領域的技術人員能思及的變化,都應落入本申請的保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!