一種語料處理方法和裝置及語料分析方法和裝置與流程
本發明涉及移動通訊領域,特別是涉及一種語料處理方法和裝置及語料分析方法和裝置。
背景技術:
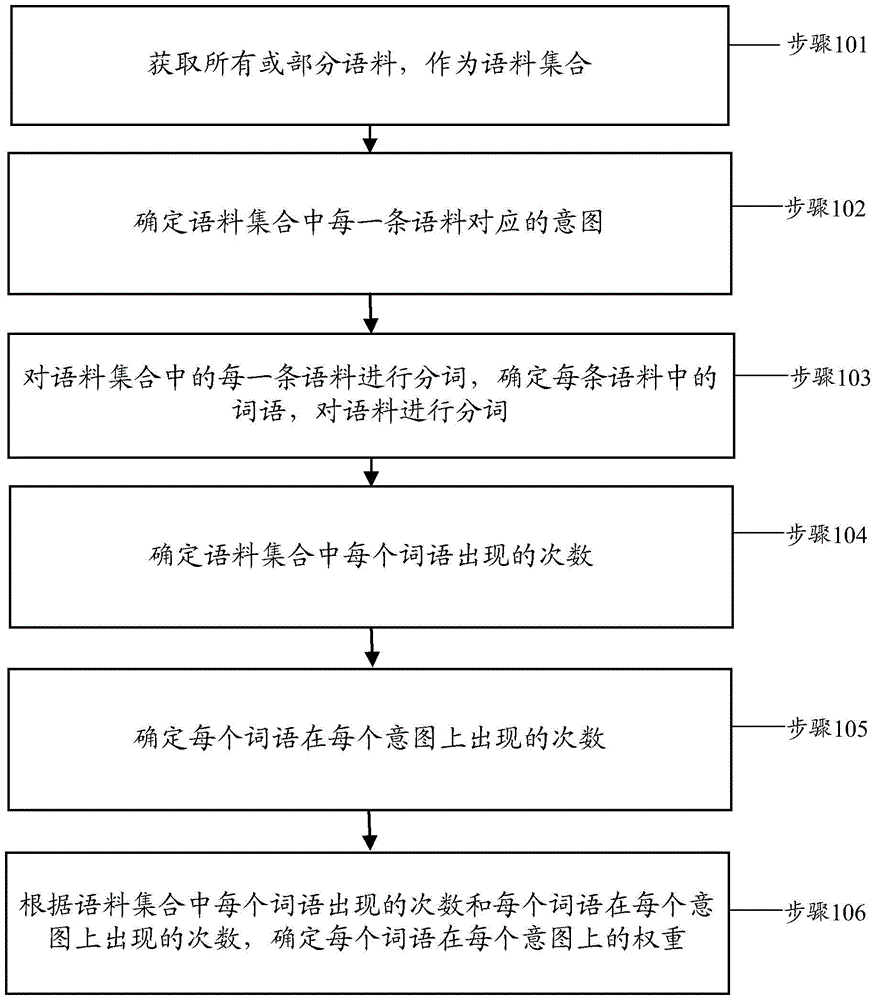
:隨著海量網絡信息的積累和規模的高速增長,準確快捷的找到自己所需要的信息已成為人們迫切的需求。自動問答系統通過理解人們自然語言形式的問句,返回答案或者包含答案的文本片段,在一定程度上提高了用戶檢索的效率和準確性。但是,在實際的應用環境中,由于自然語言自身的特性和用戶對系統的不熟悉,導致用戶錄入的交互信息很隨意;有時是寒暄信息,或業務質詢,或對系統的投訴;有時是價格咨詢,或業務流程咨詢,或產品基本信息咨詢;如果不做區別的應答,答案的準確性將會大打折扣,無法滿足用戶需求,極大地影響了用戶的滿意度,降低了用戶體驗。技術實現要素:鑒于現有技術中自動問答系統,無法滿足用戶需求,及大地影響了用戶的滿意度,降低了用戶體驗的問題,提出了本發明以便提供一種克服上述問題或者至少部分地解決上述問題的語料處理方法和裝置及語料分析方法和裝置。本發明提供一種語料處理方法,包括:獲取所有或部分語料,作為語料集合;確定語料集合中每一條語料對應的意圖;對語料集合中的每一條語料進行分詞,確定每條語料中的詞語;確定語料集合中每個詞語出現的次數;確定每個詞語在每個意圖上出現的次數;根據語料集合中每個詞語出現的次數和每個詞語在每個意圖上出現的次數,確定每個詞語在每個意圖上的權重。本發明還提供了一種語料處理裝置,包括:獲取模塊,用于獲取所有或部分語料,作為語料集合;意圖確定模塊,用于確定語料集合中每一條語料對應的意圖;分詞確定模塊,用于對語料集合中的每一條語料進行分詞,確定每條語料中的詞語;次數確定模塊,用于確定語料集合中每個詞語出現的次數,以及用于確定每個詞語在每個意圖上出現的次數;權重確定模塊,用于根據語料集合中每個詞語出現的次數和每個詞語在每個意圖上出現的次數,確定每個詞語在每個意圖上的權重。本發明還提供了一種語料分析方法,包括:獲取一條語料;對語料進行分詞處理,確定語料中的每個詞語;獲取每個詞語在每個意圖上的權重;根據每個詞語在每個意圖上的權重,確定每個意圖的權重值;將大于或等于預定閾值的權重值對應的意圖,確定為語料的意圖。其中,根據每個詞語在每個意圖上的權重,確定每個意圖的權重值的處理包括:對于每一種意圖,將每個詞語在該意圖上權重相加,作為該意圖的權重值。本發明還提供了一種語料分析裝置,其特征在于,包括:語料獲取模塊,用于獲取一條語料;分詞處理模塊,用于對語料進行分詞處理,確定語料中的每個詞語;權重獲取模塊,用于獲取每個詞語在每個意圖上的權重;權重值確定模塊,用于根據每個詞語在每個意圖上的權重,確定每個意圖的權重值;意圖處理模塊,用于將大于或等于預定閾值的權重值對應的意圖,確定為語料的意圖。本發明有益效果如下:借助于本發明實施例的語料處理方法和裝置及語料分析方法和裝置,解決了現有技術中自動問答系統,無法滿足用戶需求,極大地影響了用戶的滿意度,降低了用戶體驗的問題,能夠根據用戶的交互信息,來分析用戶的交流目的,即對用戶的意圖進行識別,以便對用戶的問題有針對性的答復,滿足了用戶需求,提高了用戶體驗。上述說明僅是本發明技術方案的概述,為了能夠更清楚了解本發明的技術手段,而可依照說明書的內容予以實施,并且為了讓本發明的上述和其它目的、特征和優點能夠更明顯易懂,以下特舉本發明的具體實施方式。附圖說明通過閱讀下文優選實施方式的詳細描述,各種其他的優點和益處對于本領域普通技術人員將變得清楚明了。附圖僅用于示出優選實施方式的目的,而并不認為是對本發明的限制。而且在整個附圖中,用相同的參考符號表示相同的部件。在附圖中:圖1是本發明實施例的語料處理方法的流程圖;圖2是本發明實施例的語料分析方法的流程圖;圖3是本發明實施例的語料處理裝置的結構示意圖;圖4是本發明實施例的語料分析裝置的結構示意圖。具體實施方式下面將參照附圖更詳細地描述本公開的示例性實施例。雖然附圖中顯示了本公開的示例性實施例,然而應當理解,可以以各種形式實現本公開而不應被這里闡述的實施例所限制。相反,提供這些實施例是為了能夠更透徹地理解本公開,并且能夠將本公開的范圍完整的傳達給本領域的技術人員。為了解決現有技術中自動問答系統,無法滿足用戶需求,極大地影響了用戶的滿意度,降低了用戶體驗的問題,本發明提供了語料處理方法和裝置及語料分析方法和裝置,能夠根據用戶的交互信息,來分析用戶的交流目的,即對用戶的意圖進行識別,以便對用戶的問題有針對性的答復,滿足了用戶需求,提高了用戶體驗。而且,對用戶的意圖進行識別后,我們可以在管理后臺數據時進行分類處理,把寒暄數據單獨創建一個庫,把業務咨詢數據單獨創建一個庫;這樣不但方便數據的管理和維護,而且還能分散數據訪問壓力、提高系統性能。目前業界有關意圖識別的專利和技術文檔也有不少,但這些方案要么識別率低、要么架構復雜、要么應用場景不適合問答;而本發明識別率高,簡單易用,能滿足問答業務需求。方法實施例一根據本發明的實施例,提供了一種語料處理方法,圖1是本發明實施例的語料處理方法的流程圖,如圖1所示,根據本發明實施例的語料處理方法包括如下處理:步驟101,獲取所有或部分語料,作為語料集合;步驟102,確定語料集合中每一條語料對應的意圖;步驟103,對語料集合中的每一條語料進行分詞,確定每條語料中的詞語,對語料進行分詞,可以采用下述方法之一:ansj分詞、stanford分詞、庖丁解牛,其中,ansj分詞是一個開源的Java中文分詞工具,基于中科院的ictclas中文分詞算法,stanford分詞是斯坦福大學(StanfordUniversity)自然語言處理實驗室針對中文開發的一款中文分詞工具;步驟104,確定語料集合中每個詞語出現的次數;步驟105,確定每個詞語在每個意圖上出現的次數;步驟106,根據語料集合中每個詞語出現的次數和每個詞語在每個意圖上出現的次數,確定每個詞語在每個意圖上的權重,可以利用下述公式確定每個詞語在每個意圖上的權重F(Xi):F(Xi)=(Mi/P)*(1/Ln(P))其中,F(Xi)表示Xi在意圖M上的權重,其中,Xi表示詞語,i表示詞語的序號,i的取值范圍是自然數,M表示意圖,Mi表示Xi在意圖M上出現的次數,P表示Xi在語料集合中出現的總次數,Ln是自然對數。根據本發明實施例,首先根據應用需求,把用戶的交互信息分為相應的N類,例如,N={寒暄,問答}或N={價格咨詢,業務流程咨詢,產品基本信息咨詢};然后進行語料標注,例如收集用戶交互信息的語料,比如收集1000條,并對語料進行整理(比如,刪除重復語料等),然后對語料進行標注,每條語料標注一種意圖;再對語料進行分詞,統計每個詞語出現的總次數P,并統計詞語在各中意圖上出現的次數Mi,計算詞語Xi(Xi表示第i個詞語)在意圖M上的概率公式F(Xi)為:F(Xi)=(Mi/P)*(1/Ln(P)),其中,Xi表示詞語,i表示詞語的序號,i的取值范圍是自然數,M表示意圖,Mi表示Xi在意圖M上出現的次數,P表示Xi在語料集合中出現的總次數,Ln是自然對數。方法實施例二根據本發明的實施例,提供了一種語料分析方法,圖2是本發明實施例的語料分析方法的流程圖,如圖2所示,根據本發明實施例的語料分析方法包括如下處理:步驟201,獲取一條語料;步驟202,對語料進行分詞處理,確定所述語料中的每個詞語;步驟203,獲取每個詞語在每個意圖上的權重;步驟204,根據每個詞語在每個意圖上的權重,確定每個意圖的權重值,具體地,對于每一種意圖,將每個詞語在該意圖上權重相加,作為該意圖的權重值;步驟205,將大于或等于預定閾值的權重值對應的意圖,確定為所述語料的意圖。在本發明實施例中,當用戶錄入一個語句時,首先對問句進行分詞,分詞后,逐個計算詞語在各個意圖上的概率值,然后求和,優選地,可以選擇概率值最大的意圖即為語句的意圖。通過本發明實施例,能夠根據用戶的交互信息,來分析用戶的交流目的,即對用戶的意圖進行識別,以便對用戶的問題有針對性的答復,滿足了用戶需求,提高了用戶體驗。下面結合具體實施例,對方法實施例一和方法實施例二進行詳細說明:從“意圖識別總體架構圖”可以看出,本發明實施例分為兩部分:離線部分(即上文所述的方法實施例一)和在線部分(即上文所述的方法實施例二),其中,離線部分根據標注語料對“意圖模型”進行訓練,為后續意圖識別的處理做數據基礎;本操作是離線完成,不影響運行系統的性能。在線部分中,用戶錄入一個語句,首先做預處理、分詞等,然后根據“意圖模型”計算各個詞語的意圖概率,再匯總求和,最終得出語句的意圖。具體過程如下(在下邊敘述過程中以“寒暄、問答”兩個意圖為例進行說明):模型訓練1、語料標注首先收集語料,這些語料是在問答交互系統中真實使用的語句,一般收集的語料不少于1000條,越多越好。語料標注后,形式如下表1所示:語料標注是意圖識別的基本數據依據,語料標注的好壞,直接影響意圖識別的準確率。2、訓練模型該訓練過程是本發明的核心,首先,取一條標注語料,例如,寧夏軟件升級找誰?標注為問答,該訓練過程是對語料逐條進行處理,直到所有語料處理完為止;然后,進行數據預處理,該過程主要目的是過濾對意圖識別無幫助的噪音部分,例如:開頭或結尾的空格、~、#、&、制表符等;再進行分詞處理,利用中文分詞工具把語句分解成一組詞語,例如:寧夏/軟件/升級/找/誰/?中文分詞工具可以使用ansj分詞、stanford分詞、庖丁解牛等;接著進行詞語統計,一是統計詞語出現的次數,記作P,二是統計詞語在各個意圖上出現的次數,意圖按順序標記為i=0、1、2、…、n,詞語在意圖i上出現的次數,記作Ni,即N0、N1、N2、…、Nn;其中P=N0+N1+N2+…+Nn,即然后統計詞語出現次數,根據詞語統計結果,計算出詞語出現次數,即在語料中所有語句中出現的次數,詞語記作w,則詞語出現次數記作P;接著計算詞語權重,詞語出現次數越多,其作為意圖的權重越小,例如,詞語w0出現10詞,詞語w1出現100詞,則w0詞語權重比w1詞語權重大,計算權重系數的方式:f(P)=1/Ln(P),Ln()是自然對數,例如:f(10)=0.434/f(100)=0.217,其中,計算權重系數的要求:既要使權重有區分,使其能夠在意圖概率計算中起作用,又不能使權重區分太大,避免權重小的詞語變成無用詞語,也可以對其進行一些優化調整,例如:f(P)=1/Ln(e+P),其中常數e=2.718281828459;根絕上述,計算詞語意圖概率值,計算公式為f(Wi)=(Ni/P)*(1/Ln(P))或表示為即意圖概率值為詞語意圖比率*詞語權重,例如:“軟件”一詞,在“寒暄語句”中出現1次,在“問答語句”中出現9次,則“寒暄意圖”的比率為1/(1+9)=10%;“問答意圖”的比率為9/(1+9)=90%,假設“軟件”一詞的權重1/Ln(p)=0.434,那么,“軟件”的“寒暄意圖”概率為10%*0.434,“軟件”的“問答意圖”概率為90%*0.434,這說明,當新的語句中出現“軟件”一詞時,則語句是“問答”意圖的可能性比較大;最后,形成意圖模型,根據對詞語的統計以及詞語在各個意圖的比率,計算出詞語的意圖概率值,生成意圖模型,該數據模型可以存放在txt文件或者excel語句中,運行是可以存入內存中,最終結果形式如下表2所示:詞語意圖意圖概率值軟件問答0.2286軟件寒暄0.0254你好問答0.1062你好寒暄0.2478………意圖識別1、用戶錄入自然語言語句例如:下午好!你今天忙不忙?你們客戶電話是多少?2、數據預處理該過程主要目的是過濾掉對意圖識別無幫助的噪音部分,例如:開頭或結尾的空格、~、#、&、制表符等。3、意圖計算意圖計算是本發明的最終目的,首先進行數據預處理,即語句預處理,,該過程主要目的是過濾對意圖識別無幫助的噪音部分,例如:開頭或結尾的空格、~、#、&、制表符等;再進行分詞處理,利用中文分詞工具把語句分解成一組詞語,例如:寧夏/軟件/升級/找/誰/?中文分詞工具可以使用ansj分詞、stanford分詞、庖丁解牛等;獲取詞語意圖概率值,詞語的意圖概率值可以在上述“意圖模型”中直接查詢(例如上表2),記作Xi。;然后計算出各個意圖上的概率和,例如用戶錄入的語句有X、Y、Z三個詞語,在意圖0上的概率和為:G0=X0+Y0+Z0,在意圖1上的概率和為:G1=X1+Y1+Z1,在意圖2上的概率和為:G2=X2+Y2+Z2,這樣就計算出在各個意圖上的概率和,在此我們使用加法,在實際測試時發現,乘法效果更好,可以根據需要靈活選擇;最后,取最大意圖值,經過上述取值的累計和,我們得到了各個意圖的概率值,根據概率模型的設計,取概率值最大的意圖,是該語句的最終意圖,得到該意圖編號后,把意圖編號轉換成最終意圖,例如,0代表寒暄意圖,1代表問答意圖。經過驗證,系統對“寒暄、問答”的意圖識別,準確率達到99.7%。綜上所述所述,本發明的最終目的是對用戶交互信息的意圖進行識別,首先收集語料并標注,對語料進行分詞,并統計詞語的意圖概率值,得到概率模型,用戶錄入交互語句后,對用戶語句進行分詞,根據上述概率模型對詞語意圖概率值進行加權求和,得出整個語句的意圖概率值,概率值最大的意圖即為該語句的意圖。裝置實施例一圖3是本發明實施例的語料處理裝置的結構示意圖,如圖3所示,語料處理裝置包括獲取模塊30、意圖確定模塊32、分詞確定模塊34、次數確定模塊36和權重確定模塊38,其中,獲取模塊30,用于獲取所有或部分語料,作為語料集合;意圖確定模塊32,用于確定所述語料集合中每一條語料對應的意圖;分詞確定模塊34,用于對語料集合中的每一條語料進行分詞,確定每條語料中的詞語;次數確定模塊36,用于確定所述語料集合中每個詞語出現的次數,以及用于確定每個詞語在每個意圖上出現的次數;權重確定模塊38,用于根據所述語料集合中每個詞語出現的次數和所述每個詞語在每個意圖上出現的次數,確定每個詞語在每個意圖上的權重。其中,權重確定模塊可以利用下述公式確定每個詞語在每個意圖上的權重F(Xi):F(Xi)=(Mi/P)*(1/Ln(P)),其中,其中,Xi表示詞語,i表示詞語的序號,i的取值范圍是自然數,M表示意圖,Mi表示Xi在意圖M上出現的次數,P表示Xi在語料集合中出現的總次數,Ln是自然對數。裝置實施例二圖4是本發明實施例的語料分析裝置的結構示意圖,如圖4所示,語料分析裝置包括語料獲取模塊40、分詞處理模塊42、權重獲取模塊44、權重值確定模塊46和意圖處理模塊48,其中,語料獲取模塊40,用于獲取一條語料;分詞處理模塊42,用于對所述語料進行分詞處理,確定所述語料中的每個詞語;權重獲取模塊44,用于獲取每個詞語在每個意圖上的權重;權重值確定模塊46,用于根據所述每個詞語在每個意圖上的權重,確定每個意圖的權重值;意圖處理模塊48,用于將大于或等于預定閾值的權重值對應的意圖,確定為所述語料的意圖。其中,權重值確定模塊具體用于對于每一種意圖,將每個詞語在該意圖上權重相加,作為該意圖的權重值。綜上所述,本發明使用概率模型,不需要收集用戶點擊行為數據和session數據,簡單快捷,效率很高,且本發明主要針對問答系統中語句的意圖,根據語句意圖,更準確的回答用戶問題,提高用戶滿意度。本發明通過簡單的數據集訓練,就能達到很好的識別效果,不需要用戶點擊記錄、用戶操作記錄、session日志等信息,也不需要總結實體、特征詞、句法格式。故本發明是一種簡單實用、效率和識別率都很高的意圖識別方法。顯然,本領域的技術人員可以對本發明進行各種改動和變型而不脫離本發明的精神和范圍。這樣,倘若本發明的這些修改和變型屬于本發明權利要求及其等同技術的范圍之內,則本發明也意圖包含這些改動和變型在內。在此提供的算法和顯示不與任何特定計算機、虛擬系統或者其它設備固有相關。各種通用系統也可以與基于在此的示教一起使用。根據上面的描述,構造這類系統所要求的結構是顯而易見的。此外,本發明也不針對任何特定編程語言。應當明白,可以利用各種編程語言實現在此描述的本發明的內容,并且上面對特定語言所做的描述是為了披露本發明的最佳實施方式。在此處所提供的說明書中,說明了大量具體細節。然而,能夠理解,本發明的實施例可以在沒有這些具體細節的情況下實踐。在一些實例中,并未詳細示出公知的方法、結構和技術,以便不模糊對本說明書的理解。類似地,應當理解,為了精簡本公開并幫助理解各個發明方面中的一個或多個,在上面對本發明的示例性實施例的描述中,本發明的各個特征有時被一起分組到單個實施例、圖、或者對其的描述中。然而,并不應將該公開的方法解釋成反映如下意圖:即所要求保護的本發明要求比在每個權利要求中所明確記載的特征更多的特征。更確切地說,如下面的權利要求書所反映的那樣,發明方面在于少于前面公開的單個實施例的所有特征。因此,遵循具體實施方式的權利要求書由此明確地并入該具體實施方式,其中每個權利要求本身都作為本發明的單獨實施例。本領域那些技術人員可以理解,可以對實施例中的客戶端中的模塊進行自適應性地改變并且把它們設置在與該實施例不同的一個或多個客戶端中。可以把實施例中的模塊組合成一個模塊,以及此外可以把它們分成多個子模塊或子單元或子組件。除了這樣的特征和/或過程或者單元中的至少一些是相互排斥之外,可以采用任何組合對本說明書(包括伴隨的權利要求、摘要和附圖)中公開的所有特征以及如此公開的任何方法或者客戶端的所有過程或單元進行組合。除非另外明確陳述,本說明書(包括伴隨的權利要求、摘要和附圖)中公開的每個特征可以由提供相同、等同或相似目的的替代特征來代替。此外,本領域的技術人員能夠理解,盡管在此所述的一些實施例包括其它實施例中所包括的某些特征而不是其它特征,但是不同實施例的特征的組合意味著處于本發明的范圍之內并且形成不同的實施例。例如,在下面的權利要求書中,所要求保護的實施例的任意之一都可以以任意的組合方式來使用。本發明的各個部件實施例可以以硬件實現,或者以在一個或者多個處理器上運行的軟件模塊實現,或者以它們的組合實現。本領域的技術人員應當理解,可以在實踐中使用微處理器或者數字信號處理器(DSP)來實現根據本發明實施例的加載有排序網址的客戶端中的一些或者全部部件的一些或者全部功能。本發明還可以實現為用于執行這里所描述的方法的一部分或者全部的設備或者裝置程序(例如,計算機程序和計算機程序產品)。這樣的實現本發明的程序可以存儲在計算機可讀介質上,或者可以具有一個或者多個信號的形式。這樣的信號可以從因特網網站上下載得到,或者在載體信號上提供,或者以任何其他形式提供。應該注意的是上述實施例對本發明進行說明而不是對本發明進行限制,并且本領域技術人員在不脫離所附權利要求的范圍的情況下可設計出替換實施例。在權利要求中,不應將位于括號之間的任何參考符號構造成對權利要求的限制。單詞“包含”不排除存在未列在權利要求中的元件或步驟。位于元件之前的單詞“一”或“一個”不排除存在多個這樣的元件。本發明可以借助于包括有若干不同元件的硬件以及借助于適當編程的計算機來實現。在列舉了若干裝置的單元權利要求中,這些裝置中的若干個可以是通過同一個硬件項來具體體現。單詞第一、第二、以及第三等的使用不表示任何順序。可將這些單詞解釋為名稱。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1