基于多模態信息的視頻內容審查系統及方法與流程
本發明涉及視頻內容關系系統及其方法,更具體地說,涉及一種基于多模態信息的視頻內容審查系統及方法。
背景技術:
視頻內容審查是在當今互聯網形勢下的最要管理手段,尤其是在今后的三網融合之后,面對海量的互聯網內容,對于內容的審查是一個嚴峻的考驗。
視頻內容是相對比較困難的一類內容審查,其審查難度要高于單純的文字、圖像、聲音等,這是由于視頻是一系列圖像、聲音的組合,并且其具有播放時間長、內容多、動態性等特征。
目前,網絡視頻內容的審查仍然主要依靠人工,技術手段的自動審查主要停留在文字內容,對圖像、聲音等多媒體、多模態的內容沒有較好的解決方案。
技術實現要素:
針對現有技術中存在的視頻內容主要依靠人工,沒有較好的技術手段進行自動審查的問題,本發明的目的是提供一種基于多模態信息的視頻內容審查系統及方法。
為實現上述目的,本發明采用如下技術方案:
一種基于多模態信息的視頻內容審查方法,包括內容審查步驟和質量審查步驟,內容審查步驟包括:對視頻進行預處理,提取視頻中的關鍵幀和關鍵片段;搜索內容數據庫對關鍵幀進行匹配,而對于關鍵片段,并行進行臺標、人臉、文字、標語、旗幟的圖像識別和匹配;臺標識別和匹配 包括以下步驟:構建臺標樣本庫;提取待測臺標的顏色特征,確定其主顏色的參數范圍與面積比例;通過顏色匹配算法,在視頻幀中搜索與待測臺標顏色組成相同的區域,從而得到待測臺標可能出現的待測區域;提取待測區域中的梯度直方圖特征,判斷是否存在待測臺標;旗幟識別和匹配包括以下步驟:采集樣本集;對樣本圖片進行預處理,包括分割圖像,獲取圖像色彩值的范圍;對圖像進行腐蝕、膨脹、分割和形狀分析,將無關區域去除,留下旗幟的區域圖片。
根據本發明的一實施例,人臉識別包括以下步驟:構建邊緣人臉;提取互補特征;采用并行識別網絡進行人臉識別。
根據本發明的一實施例,內容審查步驟還包括以下步驟:將關鍵幀和關鍵片段的匹配結果合并,并且標示出帶有敏感內容的關鍵幀和關鍵片段在視頻中的位置以及敏感內容的類別;對敏感內容進行復查,并且將復查的結果反饋至內容數據庫,內容數據庫對敏感內容進行更新。
根據本發明的一實施例,質量審查步驟包括:檢測有方塊形狀邊沿的圖像區域,利用視頻幀前處理、模板匹配、空間投票方法,檢測視頻中的馬賽克區域;對視頻的幀進行區域分割和色彩識別,檢測視頻中的黑場、彩條和其他顏色彩屏;檢測視頻中超過一定時長的靜音內容,并標明靜音內容的位置和時長。
為實現上述目的,本發明還采用如下技術方案:
一種基于多模態信息的視頻內容審查系統,包括內容審查子系統和質量審查子系統,內容審查子系統包括:預處理模塊、多模態匹配模塊、內容數據庫;其中,多模態匹配模塊包括臺標識別匹配單元和旗幟識別匹配單元;預處理模塊對視頻進行預處理,提取視頻中的關鍵幀和關鍵片段;多模態匹配模塊搜索內容數據庫并對關鍵幀進行匹配,而對于關鍵片段,多模態匹配模塊內并行進行臺標、人臉、文字、標語、旗幟的圖像識別和匹配;臺標識別匹配單元首先構建臺標樣本庫;其次提取待測臺標的顏色特征,確定其主顏色的參數范圍與面積比例,再次通過顏色匹配算法,在 視頻幀中搜索與待測臺標顏色組成相同的區域,從而得到待測臺標可能出現的待測區域,最后提取待測區域中的梯度直方圖特征,判斷是否存在待測臺標;旗幟識別匹配單元首先采集樣本集,其次對樣本圖片進行預處理,包括分割圖像,獲取圖像色彩值的范圍,最后對圖像進行腐蝕、膨脹、分割和形狀分析,將無關區域去除,留下旗幟的區域圖片。
根據本發明的一實施例,多模態匹配模塊還包括人臉識別單元,人臉識別單元首先構建邊緣人臉,其次提取互補特征,最后采用并行識別網絡進行人臉識別。
根據本發明的一實施例,內容審查系統還包括:協同判定模塊,將關鍵幀和關鍵片段的匹配結果合并,并且標示出帶有敏感內容的關鍵幀和關鍵片段在視頻中的位置以及敏感內容的類別;外部審查接口,對敏感內容進行復查,并且將復查的結果反饋至內容數據庫,內容數據庫對敏感內容進行更新。
根據本發明的一實施例,質量審查系統包括馬賽克檢測模塊、色彩檢測模塊、聲音檢測模塊;馬賽克檢測模塊檢測有方塊形狀邊沿的圖像區域,利用視頻幀前處理、模板匹配、空間投票方法,檢測視頻中的馬賽克區域;色彩檢測模塊對視頻的幀進行區域分割和色彩識別,檢測視頻中的黑場、彩條和其他顏色彩屏;聲音檢測模塊檢測視頻中超過一定時長的靜音內容,并標明靜音內容的位置和時長。
在上述技術方案中,本發明的基于多模態信息的視頻內容審查系統及方法能夠實現利用計算機即互聯網進行自動的視頻內容審查,并且以人工檢查為復核與輔助,能夠縮短視頻審查周期,并且提高審查效果。
附圖說明
圖1是本發明的流程圖;
圖2是本發明的系統部分結構圖;
圖3是人臉識別流程圖;
圖4是文本識別流程圖;
圖5是標語識別流程圖;
圖6是馬賽克檢測流程圖;
圖7是黑場檢測流程圖;
圖8是靜音檢測流程圖。
具體實施方式
下面結合附圖和實施例進一步說明本發明的技術方案。
本發明公開一種基于多模態信息的視頻內容審查系統及其對應的審查方法。本發明的系統包括內容審查子系統和質量審查子系統,及其對應的方法。
視頻內容審查:面向視頻文件和圖像文件,支持包括黃色和政治敏感內容庫在內的敏感內容檢測。功能上包括敏感視頻數據庫的可更新、敏感視頻內容數據庫3可檢索、基于內容相似度的視頻分割、給定視頻內容高層語義概念自動標注、視頻字幕及語音信息的融合語義分析、基于多模態特征的內容敏感性評估、敏感內容與標注協同呈現、人工反饋記錄等。
視頻質量審查:面向視頻文件,支持黑屏、彩條、靜音、馬賽克等視頻節目質量損傷的檢測。功能上包括視頻質量損傷自動檢測、視頻幀信息與損傷標注協同呈現等。
如圖2所示,內容審查子系統包括:預處理模塊1、多模態匹配模塊2、內容數據庫3、協同判定模塊4和外部審查接口5。此外,多模態匹配模塊2又進一步包括臺標識別匹配單元22、人臉識別單元23、場景檢測單元24、文字檢測單元25、旗幟識別匹配單元21等。
如圖1和圖2所示,預處理模塊1對視頻進行預處理,提取視頻中的關鍵幀和關鍵片段。多模態匹配模塊2搜索內容數據庫3并對關鍵幀進行匹配,而對于關鍵片段,多模態匹配模塊2內并行進行臺標、人臉、文字、標語、旗幟的圖像識別和匹配。協同判定模塊4將關鍵幀和關鍵片段的匹 配結果合并,并且標示出帶有敏感內容的關鍵幀和關鍵片段在視頻中的位置以及敏感內容的類別。外部審查接口5對敏感內容進行復查,并且將復查的結果反饋至內容數據庫3,內容數據庫3對敏感內容進行更新。
具體來說,如圖1所示,首先對輸入視頻進行多層分割處理,生成關鍵幀和視頻片段。對視頻片段和關鍵幀,提取多模態語義特征,并評估其內容敏感性。對視頻關鍵幀,通過與敏感內容數據庫3內的圖像匹配決定其內容敏感性。最后將機器推薦的敏感內容及其相關信息融合并呈現給專業編輯,由專業編輯最終判定其敏感性。專業編輯的判斷結果將被反饋到敏感內容數據庫3和用于實時更新內容敏感性評估模型。
臺標識別
臺標識別匹配單元22首先構建臺標樣本庫,其次提取待測臺標的顏色特征,確定其主顏色的參數范圍與面積比例,再次通過顏色匹配算法,在視頻幀中搜索與待測臺標顏色組成相同的區域,從而得到待測臺標可能出現的待測區域,最后提取待測區域中的梯度直方圖特征,判斷是否存在待測臺標。
具體來說,臺標檢測部分用于檢測視頻中的敏感臺標,包括話筒、車身上等。主要步驟如下:構建臺標樣本庫,通過提取庫中樣本的HOG(Histograms of Oriented Gradients梯度直方圖)特征來訓練SVM(support vector machine支持向量機)分類器。提取待測臺標的顏色特征,確定其前三種主顏色(可以小于三種)的參數范圍與面積比例;通過顏色匹配算法,在視頻幀中搜索與待測臺標顏色組成相同的區域,從而得到臺標可能出現的待測區域;將待測區域進行基于仿射變換與最小外接矩形的圖像矯正;提取待測區域中的HOG(Histograms of Oriented Gradients梯度直方圖)特征,通過訓練好的分類器判斷是否存在待測臺標。經過嚴格的實驗證明,該臺標識別方法能夠準確的、近實時的識別視頻中臺標(包括話筒上,背景中等)。
(a)構建臺標樣本庫
在模板臺標中選擇湖南衛視臺臺標作為待測臺標,通過對其進行各種仿射變換獲得900個正樣本,將剩下的模板臺標每個做20次仿射變換得到980個負樣本。最終樣本庫包含這900個正樣本,和1980個負樣本。
將樣本庫中的樣本歸一化到96×96像素,并提取其HOG(HISTOGRAMS OF ORIENTED GRADIENTS梯度直方圖)特征來訓練SVM(support vector machine支持向量機)分類器
(b)提取待測臺標的顏色特征,確定其主顏色的參數范圍與面積比例
通過顏色聚類的方法,在HSV顏色空間下找到湖南衛視臺標的兩種主顏色橘紅色和黃色的參數邊界,記錄各個顏色的面積比例,在此基礎上給予ΔS(本發明中ΔS=0.2),面積最大的為第一主顏色。
對參數邊界進行放大,增強其在真實場景中一定光照變換下的魯棒性,具體冗余參數為ΔH(0~360)(本發明中ΔH=10)、ΔS(0~1)(本發明中ΔS=0.1)、ΔV(0~1)(本發明中ΔV=0.2),該參數為在實驗中獲得的最優化參數,允許使用者根據具體情況進行修改。
(c)通過顏色匹配算法,在視頻幀中搜索與待測臺標顏色組成相同的區域,從而得到待測臺標可能出現的待測區域。
根據上一節中的橘紅色與黃色的HSV顏色參數范圍,在視頻幀中分別提取出只含有一種顏色的子圖。在每一張子圖中,尋找其中每一個色塊的輪廓,并找到其輪廓的外接矩形。
湖南衛視臺臺標有兩種主顏色,將每一個橘紅色子圖中的色塊與每一個黃色子圖中的色塊進行對比,如果兩個色塊的外接矩形相交,并且顏色面積比例只比在b2所得范圍之內,則將包含這兩個色塊的外接矩形確定為待測區域,并從原圖中截取出來。
將待測區域進行基于仿射變換與最小外接矩形的圖像矯正。
于截取出來的待測區域中找到色塊的最小外接矩形。將色塊旋轉,使其最小外接矩的長邊與水平方向平行。將待測區域歸一化到96*96像素大小的圖像。
(d)提取待測區域中的HOG(HISTOGRAMS OF ORIENTED GRADIENTS梯度直方圖)特征,通過訓練好的分類器判斷是否存在待測臺標。
由于該算法通過模板臺標的顏色構成對視頻幀中的可能出現臺標的區域進行定位,模板臺標顏色越鮮明,種類越多(在1-3種內),定位越精確,可能出現的干擾項越少,準確率越高并且速度越快。
人臉識別
如圖3所示,人臉識別單元23首先構建邊緣人臉,其次提取互補特征,最后采用并行識別網絡進行人臉識別。
總體來說,本發明模擬人類的視覺認知模式,通過訓練目標人物的正負邊緣人臉來模擬指定人物的人臉模式邊界ΜF,這一模擬邊界構成了針對指定人物的人臉識別器,映射到邊界內部的人臉被識別為指定人物,而映射在邊界外部的人臉判定為非指定人物。因此,該識別器能夠有效的判定接受目標人物的人臉,同時拒絕非目標人物的人臉。同時,通過并聯基于互補特征的人臉識別器來提升識別性能。整個流程可歸納為三個階段,下面分別進行概述:
(1)第一階段:構建邊緣人臉
這一階段的工作是為目標人物生成大量的邊緣人臉。邊緣人臉集合Borderline_Face_Set由剛好屬于目標人物的正邊緣人臉BFpos和剛好不屬于目標人物的負邊緣人臉BFneg構成,是后續指定人物識別器的原始訓練數據。邊緣人臉通過由目標人臉向大量非目標人臉的變形來生成,變形程度淺dpos的結果為正邊緣人臉,變形程度深dneg的結果為負邊緣人臉(dpos<dneg)。其中,變形程度組合dpos&dneg是本方法的關鍵參數之一,不同的目標人物有著不同的正負變形程組合。本方法采用網格搜索策略來確定dpos&dneg。
(2)第二階段:互補特征提取
這一階段的工作是采用具有互補性質的不同特征描述子分別對上一階段生成的邊緣人臉進行特征提取,以生成邊緣模式特征向量。實際上,正 負邊緣人臉之間只有細微的形狀和紋理差別,所以需要采用能夠精確反映這些細微差別的算子進行特征描述和提取。Local Binary Pattern和Gabor Wavelets[4]具有明顯的互補特性,并且在紋理分析和人臉識別領域都能取得很好的效果,所以我們采用這兩種特征描述子對邊緣人臉進行特征提取。
(3)第三階段:并行識別網絡
這一階段的工作是對邊緣模式進行訓練,構建針對目標人物的人臉識別器。本方法模擬人類的認知模式,采用Support Vector Machine來訓練邊緣模式,以模擬指定人物的人臉模式邊界。這一模擬邊界構成了針對指定人物的人臉識別器,映射到邊界內部的人臉被識別為指定人物,而映射在邊界外部的人臉判定為非指定人物。如系統框架圖所示,分別對由LBP算子和Gabor算子表征的邊緣模式進行訓練,生成兩個獨立的二分人臉識別器。輸入人臉通過這兩個識別器均可得到“是”(輸出為“1”)或者“不是”(輸出為“0”)所指定人物的結果。理論和實踐都表明,基于上述兩種互補特性算子的識別器具有互補的人臉識別結果,這一現象在非目標人物的人臉判定結果中尤為突出。所以本方法利用這種特性,通過一個與運算并聯兩個識別器,形成一個并行識別網絡,有效的消除在非指定人物人臉的識別過程中,由某一子識別器判定錯誤而導致的虛警結果。
文字識別
本發明采用基于圖像局部特征的文本識別方法,本質上屬于基于內容的數字圖像檢索范疇,其核心思想是采用圖像匹配的方法,來識別圖像中的文本信息。與基于OCR技術的識別框架相比,基于局部特征技術的識別框架和處理方法:
1、免除了基于OCR技術的識別框架中的區域增強,二值化,圖層分析,幾何歸一化等一系列預處理環節。
2、通過采用具有幾何和光度不變性的局部特征,并引入針對性的投票算法和幾何一致性驗證,克服了OCR對于字符旋轉,不規則排列,圖像解析度不均,視角變換和扭曲等條件下識別的局限性。
3、通過采用科學的模版字符圖像檢索庫構建方法,可以實現語種和字體上的識別透明性和魯棒性。
數字圖像局部特征(Local Feature),是數字圖像處理和計算機視覺領域發展中一個非常重要的概念和強有力的工具,特別是具有較強幾何不變形和描述獨特性的高性能局部特征的出現,標志著基于內容的圖像處理進入了一個全新的領域。
局部特征,可以理解為圖像中的一個關鍵點或者一塊關鍵區域,這些關鍵區域由坐標,方向,尺度等一系列幾何特性和一組抽象的高維視覺信息描述向量構成,這些信息能夠自適應于圖像的幾何變換和光學變換,包括拉伸,縮放,旋轉,視角變換,透視變換,曝光,霧化,噪聲等,具有很強的穩定性與獨特性,對圖像視覺信息具有很強的描述能力。
局部特征的核心組成包括:檢測算子(Detector)和描述算子(Descriptor)。局部特征檢測算子按照檢測形式可以分為角點檢測、塊檢測和區域檢測;按照不變性可以分為旋轉不變、尺度不變、仿射不變和透視不變;對檢測算子的評價則主要從可重復性(穩定性)、幾何特征精準性、變換魯棒性和算法效率進行考察。
SIFT(Scale-invariant feature transform)是一種檢測局部特征的算法,該算法通過求一幅圖中的特征點(interest points,or corner points)及其有關scale和orientation的描述子得到特征并進行圖像特征點匹配,是一種非常有名的局部特征描述子。多年來,SIFT在重復性、可區分性、準確性、數量以及效率、不變性等特性上久經考驗,具有非常優秀的性能表現,本發明的文字識別使用了SIFT作為局部特征算法。
基于特征裝袋(Bag-of-Features)的識別
本發明的文字識別技術采用基于特征裝袋(Bag-of-Features),特征裝袋則主要由特征檢測、特征描述、特征聚類、頻率向量表達等環節構成。
特征聚類與詞匯法
向量聚類與詞匯法是一種高級特征描述方法,通過對基本特征向量進 行聚類分析,形成一定數量的抽象主題詞匯(Abstract Topic Vocabulary),之后對樣本所包含的特征進行主題詞匯劃分和統計,形成對應的詞匯頻率統計向量,用以后續的相應處理,該方法通常被稱之為Bag-of-Words[5]或Bag-of-Features。
Bag-of-Words模型在算法實現和計算復雜度上是相對容易與簡單的,其處理思想和原理可以在多種應用中進行遷移與擴展。在實際應用中,首先通過樣本特征建立詞匯表;然后對樣本進行詞匯分布統計,表達成對應的詞頻向量;依賴于應用的具體類型,針對獲得的詞頻向量可以結合:支持向量機(SVM,Support VectorMachine),貝葉斯分類(Bayes Classification),逆文本指數(TF/IDF,Term Frequency/Inverse Document Frequency)等技術來進行進一步分析預處理,如圖4所示。
本發明所采用的基于Bag-of-Words模型的識別系統,主要通過以下核心流程實現復雜背景圖像文字識別。
1)模版字符圖像庫構建:模版字符圖像庫是Bag-of-Words模型核心詞匯的基礎來源,模版字符圖像庫的覆蓋范圍和樣本分布特性,決定著模型的識別性能和處理能力。
2)局部特征提取:本系統采用SIFT作為系統的局部特征提取方法,針對模版字符圖像庫和檢索輸入圖像進行特征分析和提取。SIFT算法所采用的DoG檢測算子和基于梯度方向直方圖統計的描述算子,在針對圖像的幾何變換與光度變換中就有較強的不變性,在空間定位與尺度估計上取得了良好平衡,同時SIFT算法的執行效率相對于基于Laplace歸一化的局部特征算法是較高的。
3)特征聚類與詞匯構建:將模版字符圖像庫中所提取的局部特征進行聚類,以聚類中心作為核心詞匯構建詞匯表,每一個局部特征都會被指派入一類詞匯,形成相應的映射關系。本系統采用K-means作為核心聚類算法。
4)TF/IDF索引:本系統采用TF/IDF作為詞頻向量的表達方法, TF/IDF被認為是信息檢索中的重要發明,基于關鍵字概率分布交叉熵原理,是一種標準的權重度量方法,為眾多搜索引擎和檢索系統所采用。
5)檢索與識別:通過對輸入圖像進行特征提取與詞匯映射得到輸入圖像的詞頻向量,比較輸入TF/IDF向量與模版字符圖像TF/IDF向量的相似程度,排序得到最佳匹配模版字符圖像,該圖像所對應的文字將作為識別結果。
標語識別
如圖5所示,圖像特征提取需要考慮的問題有:
1)如何對圖片進行預處理,使得特征提取能夠順利進行,這個問題比較容易解決,可以通過對圖片的格式作格式轉換和縮放以適應系統需求。
2)如何提取具有抗尺度、抗仿射變換的特征描述子,本系統使用SIFT特征。
3)如何對圖片或者圖片特征進行預分類,這是圖像檢索系統的高級功能,本系統提出了層級SVM分類與Bag Of Words結合樸素貝葉斯分類的方法,對圖像檢索系統的功能進行進一步擴展,本系統在系統中預留了此圖像分類接口,圖像分類模塊今后可以以插件的形式裝載到索引子系統的圖像特征分類模塊和檢索子系統的檢索圖像預處理模塊1中。
4)如何對圖片的特征進行權重分析,由于特征點所表示的對象在圖片中的位置與重要程度不一樣,因此,可以用一些方法對圖像的特征點權重進行估值分析,在索引建立階段,可以只載入那些權重較大的圖像特征,從而減小索引所占據的內存空間,從而達到優化索引的目的。
旗幟識別
旗幟識別是一項比較復雜的任務。雖然旗幟在總體形狀上基本上都是長方形,少量呈三角形等異形,但各種旗幟圖案和顏色千差萬別,目前很難有比較通用的方法來識別。旗幟識別的另外一個難點是:旗幟通常都有飄揚、下垂等嚴重非剛性變化。
本系統的旗幟識別技術綜合顏色識別、形狀識別、圖像分割技術面積 統計等技術,針對幾種特定的旗幟有比較有效的識別。下面以藏獨的雪山獅子旗為例說明本系統的旗幟識別技術的研究。旗幟識別匹配單元21首先采集樣本集,其次對樣本圖片進行預處理,包括分割圖像,獲取圖像色彩值的范圍,最后對圖像進行腐蝕、膨脹、分割和形狀分析,將無關區域去除,留下旗幟的區域圖片。
識別一種旗幟首要任務是獲取旗幟的樣本,主要包括兩種:
1)該旗幟的高清完整樣本。
2)大量一般圖片中旗幟中的樣本。
旗幟的高清樣本的作用是為旗幟識別立一個標準圖,而一般圖片中的旗幟標本需要更多,是為了訓練系統掌握真實場景與標準旗幟圖之間的統計差異,提高在視頻或真實場景圖片中的檢出率。
對樣本圖片做RGB分量分解,為后續分割處理做準備。
圖像分割是圖像處理中最為基礎和重要的領域之一,它是對圖像進行視覺分析和模式識別的基本前提。圖像分割的目的在于根據某些特征將圖像分成若干有意義的區域,使得這些特征在某一區域內表現一致或相似,而在不同區域間表現出明顯的不同。
本系統的旗幟識別技術基于顏色綜合識別以及形狀和面積統計,所以需對各個顏色分量進行二值化分割,以利于判斷位置及形態。
在對大量的標準高清旗幟樣本及一般圖片中該旗幟的樣本進行統計后,需要確定該旗幟的各顏色分量的色彩值范圍,彩色空間有很多種,有RGB,HSI,YIQ,CMY,YUV等。
本系統的旗幟識別技術選用HIS色彩空間來對旗幟的彩色進行辨識和分割。單純依據顏色所占的比例做出判斷成功率低,并且誤判率高。實驗結果表明,僅使用前面的方法,成功率大致為35%。需要更有效的方法對圖像的黃、紅、藍顏色區域形狀進行識別,并考慮他們之間的相對位置,以去除干擾。經過腐蝕、膨脹以及分割和形狀分析,最終將無關區域去除掉,留下旗幟的區域圖片。
另一方面,質量審查系統包括馬賽克檢測模塊、色彩檢測模塊、聲音檢測模塊。
如圖6所示,馬賽克檢測模塊檢測有方塊形狀邊沿的圖像區域,利用視頻幀前處理、模板匹配、空間投票方法,檢測視頻中的馬賽克區域。
具體來說,馬賽克常發生于視頻轉碼和傳輸出現錯誤時。相比于人工添加的馬賽克,視頻損傷造成的馬賽克出現位置更加隨機化,馬賽克方格內的灰度不一定完全相等,馬賽克邊沿模糊。這些特性使得馬賽克的檢測有很大難度,并且需要一定的參數先驗假設。在實際操作中,由于損傷視頻序列難以采集,故本子系統對視頻損傷產生的馬賽克和人工添加的馬賽克不作區分,測試序列主要以人工產生的馬賽克為主。對實際情況,本算法具有一定的魯棒性,能檢測在一定大小范圍內的馬賽克(約20*20大小,10個馬賽克以上)。不失一般性,若馬賽克大小和個數與標準數字相差太大,如100*100的馬賽克塊,或視頻幀中只出現2個馬賽克,則可根據實例靈活調節參數來達到更好的檢測效果。本研究報告中假定馬賽克的大小和個數為標準參數。
馬賽克檢測主要利用其形狀特征,檢測有方塊形狀邊沿的圖像區域。算法包含視頻幀前處理、模板匹配、空間投票等環節。
前處理模塊首先從視頻中得到圖像幀序列,從而分別對每一幀圖像檢測馬賽克。前處理的主要工作是將彩色的圖像幀轉換為二值化的邊沿圖片。邊緣檢測采用Sobel算子。Sobel算子得出的緣圖像可能存在不清晰、不連續等現象,為此,我們進行了圖像增強與形態學腐蝕、膨脹的算法,加強圖像的連續性。基于馬賽克的形狀特征,我們分別得到橫向和縱向的邊沿圖片,并把它們合成成最后的邊沿圖片。因視頻拍攝時的圖片長寬比與制作時要求可能存在不同,或為添加字幕的需要,視頻中往往會出現上下或左右的“黑邊”。這種黑邊在邊沿圖片中產生了一個橫向或縱向的長線,往往會造成馬賽克的虛警情況。為此,我們進行了去黑邊的操作。
得到邊沿圖像后,模板匹配用于檢測邊沿圖片中的正方形形狀。在實 際情況中,馬賽克對應位置由Sobel算子得到的邊沿并不一定是標準的正方形。因復雜背景、馬賽克與周圍顏色相近、馬賽克內顏色不均等,馬賽克的實際邊沿會有一定的扭曲。因此,直接采用檢測垂直邊沿的方法并不能有效地檢測馬賽克。模板匹配即使用模板圖片和測試圖片中的區域做卷積,取匹配值高于閾值的區域作為模板匹配的匹配點。我們使用了4個模板圖片,分別對應馬賽克正方形的4個角。模板匹配的閾值默認為0.65。
因背景中存在干擾噪音,若一個區域僅僅與一個模板匹配,則有很大可能屬于虛警。為此,我們要求某區域至少與3個模板匹配才認定其為馬賽克點。前一步一共使用4個模板進行模板匹配,分別代表方形的4個角。模板匹配的匹配點均為模板圖片的左上角點。這樣,將4個模板的匹配結果投影到一個投票空間中,若某區域與多個模板匹配值都很高,那么在這個區域的左上角點會存在多于1個的匹配點。若在一定范圍內,存在著3個以上這樣的匹配點,則說明在此位置存在馬賽克。
在當前測試集中,馬賽克檢測的召回率為92%,查準率為85%。其中虛警主要發生于背景中存在方框形狀的干擾項的情況,如窗框、百葉窗等。
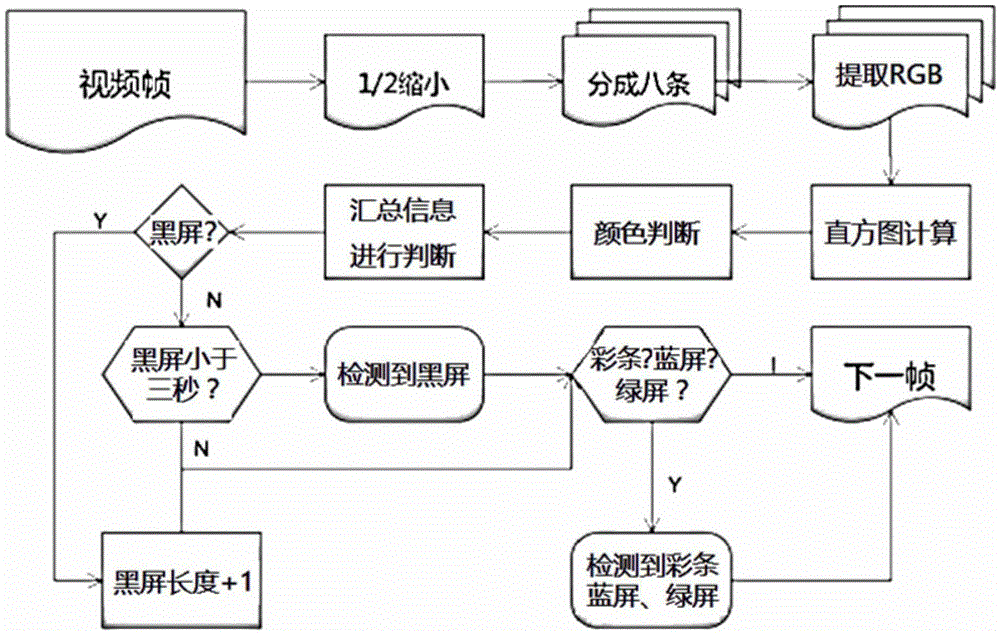
如圖7所示,色彩檢測模塊對視頻的幀進行區域分割和色彩識別,檢測視頻中的黑場、彩條和其他顏色彩屏。
本部分的算法主要分為兩個部分:黑場檢測,彩條和其他顏色彩屏(紅場、藍場等)檢測,其中兩者共用視頻幀的區域分割和色彩識別運算過程。最后根據運算結果對該幀情況進行判斷,最后按照一定的檢測順序進行判斷并輸出結果。
流程中先將視頻幀進行1/2的下采樣,采用線性下采樣法,得到分辨率縮小的幀,減少了后期處理的計算量。將視頻幀等間距分成八個圖像條,對每一個圖像條的RGB分量分別進行提取,將提取得到的RGB值進行直方圖統計,圖像條的顏色統計信息。根據得到的顏色統計信息判斷圖像條的顏色,匯總每一個圖像條的顏色信息,檢測是否有黑場、彩條等狀況出現。
因實際產生的黑場和彩條可能與理想的圖片稍有不同,為保證100%的召回率,我們適當地下調了黑場和彩條的要求。具體上,我們把灰度低于56的圖像點均看做“黑點”,視頻幀中超過98%的點均為“黑點”,則認定為黑場。
在當前測試集中,黑場、彩條檢測均達到100%召回率,查準率分別為88%和98%。黑場查準率較低因視頻中本身存在一定的黑色場景與質量損傷造成的黑場很難區分。
如圖8所示,聲音檢測模塊檢測視頻中超過一定時長的靜音內容,并標明靜音內容的位置和時長。
本技術領域中的普通技術人員應當認識到,以上的實施例僅是用來說明本發明,而并非用作為對本發明的限定,只要在本發明的實質精神范圍內,對以上所述實施例的變化、變型都將落在本發明的權利要求書范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!