確定文本串公共子序列的方法和設備與流程
本發明涉及計算機應用領域,具體而言,涉及用于確定文本串公共子序列的方法和設備。
背景技術:
當今,人們對網絡安全日益重視,包括防火墻在內的多種安全設備被廣泛應用。然而,僅部署安全設備還不足以保護網絡的安全,相關人員還需要持續不斷監控和分析安全設備產生的日志,這是因為日志中包含非常有價值的信息,比如利用這些日志可以檢測出諸如網絡入侵、病毒攻擊、反常行為、異常流量等安全威脅,從而有針對性地配置和調整網絡整體安全策略。
一種對日志進行分析的方式是將日志的事件歸為“信息”、“錯誤”和“警告”等幾個大類。這種分析方法具有局限性,由于日志數量巨大并且內容繁雜,重要的事件信息很可能被淹沒在“警告”類別中而未能被及時處理。因此,為了方便統計并及時發現問題、避免一類小事件被淹沒在同類的其他事件中,需要對日志進行細分,以便能夠及時從日志判斷出事件類型并做相應處理。
日志具有基于文本、因來源不同而可能格式各異的特點。例如,來自防火墻和網絡服務器的日志格式就存在差異。此外,即使來源相同,日志仍然可以按照其含義進行細分。
對日志進行細分的常規方法是計算最長公共子序列(LCS),即把兩個日志文本歸并在一起,抽出公共的序列部分,進而判斷兩者是否能夠歸為一類。然而,這種常規方法只支持兩個文本,在存在多個日志文本的情況下,需要對任何兩個文本進行計算,導致計算量非常大。
技術實現要素:
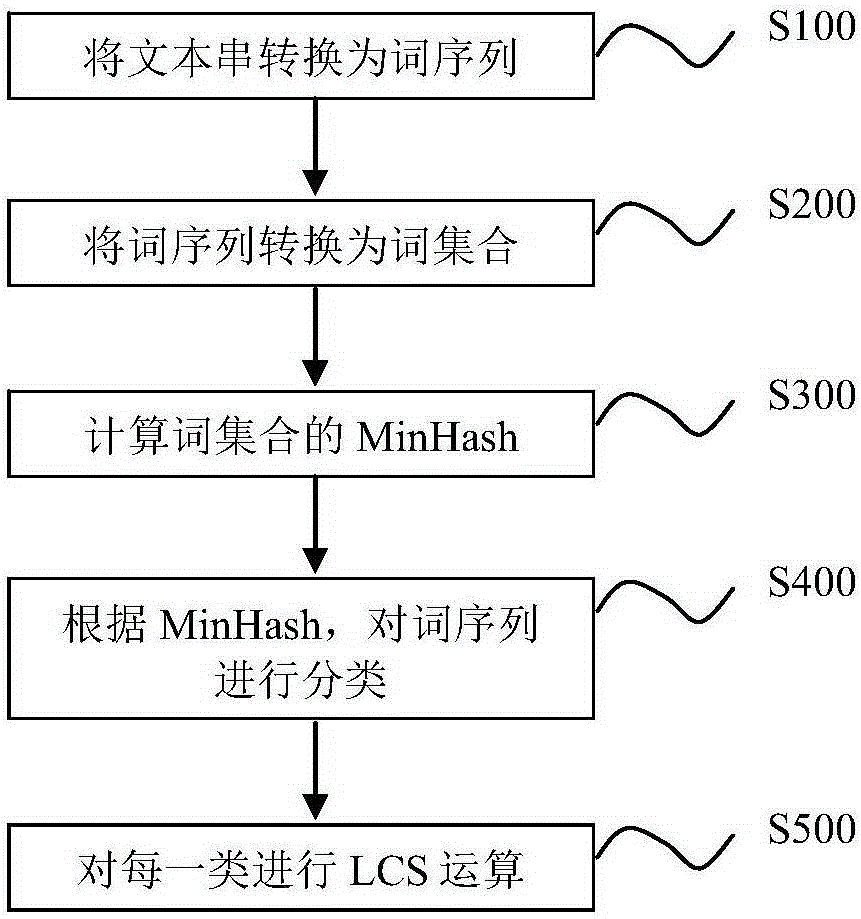
根據本發明的一方面,提供了一種用于在多個文本串中確定最長公共子序列的方法,包括:將多個文本串分別轉換為詞序列;將詞序列分別轉換為相應的詞集合;計算每個詞集合的最小哈希值;根據最小哈希值,對詞序列進行分類;以及在每一類中進行最長公共子序列運算。
在這里和下文中,“詞序列”是指詞的序列;相應的,“詞集合”是指詞的集合。換言之,序列和集合的構成元素都是詞。兩者的區別在于,序列中的元素可以重復且必須有順序,而在集合中不考慮元素順序且元素無重復。
根據本發明的另一方面,提供了一種用于在多個文本串中確定最長公共子序列的設備,包括:第一轉換裝置,用于將多個文本串分別轉換為詞序列;第二轉換裝置,用于將詞序列分別轉換為相應的詞集合;第一運算裝置,用于計算每個詞集合的最小哈希值;分類裝置,用于根據最小哈希值對詞序列進行分類;以及第二運算裝置,用于在每一類中進行最長公共子序列運算。
本發明的實施方式可以包括下列一個或多個特征。
將最小哈希距離小于第一閾值的兩個詞序列劃分為同一類。
最長公共子序列運算包括:在該類中選擇一個詞序列作為第一詞序列,分別計算該第一詞序列與該類中的其他詞序列的最長公共子序列,直至所得到的最長公共子序列長度大于第二閾值。
最長公共子序列運算包括:如果所得到的最長公共子序列長度均不大于第二閾值,則從該類中刪除該第一詞序列,繼續最長公共子序列運算。
將長度大于第二閾值的最長公共子序列確定為文本串模板。
文本串模板依次與該類中的其他詞序列計算最長公共序列,在該計算過程中,將長度大于第二閾值的最長公共子序列確定為新的文本串模板并繼續該計算過程。
輸出最終的文本串模板,刪除該類中能與所述最終的文本串模板匹配的詞序列。
繼續進行最長公共子序列運算,直至該類為空。
本發明的某些實施方式可能具有下列一個或多個有益效果:與常規LCS算法相比,支持多文本,并且通過最小哈希算法快速判斷文本之間是否差異過大,從而有效節省了LCS運算所需的時間。
本發明的其他方面、特征和有益效果將在具體實施方式、附圖及權利要求中得到進一步明確。
附圖說明
下面結合附圖對本發明做進一步說明。
圖1是根據本發明的用于在多個文本串中確定最長公共子序列的方法的流程圖;
圖2和圖3是根據一種實施方式的進行最長公共子序列運算并確定文本串模板的流程圖;以及
圖4根據本發明的用于在多個文本串中確定最長公共子序列的設備的框圖。
具體實施方式
參看圖1步驟S100,將文本串分別轉換為相應的詞序列。下面示例性地借助文本串A和B對步驟S100做進一步說明。假設,文本串A為:“The quick brown fox jumps over the lazy dog”;文本串B為:“The lazy brown dog jumps over the quick fox”。
文本串A經過分詞操作得到詞序列A:{the,quick,brown,fox,jumps,over,the,lazy,dog}。文本串B經過分詞操作得到詞序列B:{the,lazy,brown,dog,jumps,over,the,quick,fox}。
除上述示例中基于拉丁字母的文本串外,分詞操作的對象同樣可以包括中文文本串,支持中文分詞操作的方案例如包括CRF和MMSEG等。分詞的簡單方法可以是查一個中文詞庫。例如,用一個包含“中華”、“人民”、“共和國”的詞庫可以把中英文混合的一句話“how to translate中華人民共和國”分詞成'how'、'to'、'translate'、“中華”、“人民”、“共和國”六個詞。
分詞操作影響詞序列的元素構成和長度。詞序列越長,后續執行LCS算法所需的時間也相應越長。然而需要指出,除了LCS運算速度外,分詞操作基本上對整個算法的結果沒有影響。
根據步驟S200,將詞序列分別轉換為相應的詞集合。繼續以詞序列A和B為例,在轉換過程中,重復出現的詞只保留一個,例如“the”。轉換后得到詞集合A為[the,quick,brown,fox,jumps,over,lazy,dog];詞集合B為[the,lazy,brown,dog,jumps,over,quick,fox]。
在存在多個文本串的情況下,可以按照上述步驟將所有文本串分別轉換為相應的詞集合。
根據步驟S300,計算每個詞集合的最小哈希(MinHash)值,最小哈希值用于判斷兩個集合的相似性。已知多種計算MinHash的方法,下文示出的是其中一種基于Python實現的偽碼。
在步驟S400中,計算任意兩個詞集合的MinHash距離。MinHash是固定長度的數值,假設其長度為64位,那么在這64位中,位置相同而值不同的位的個數即為兩個MinHash值的MinHash距離。這里,兩個集合的MinHash距離短是該兩個集合相似的必要非充分條件,這是因為MinHash本身是一種概率方法,存在誤報;此外MinHash只考慮元素集合,而忽略元素出現的先后次序。以文本串A和B為例,雖然兩個文本串不同,但其對應的詞集合有同樣的MinHash值。
將MinHash距離與第一閾值相比較,并且將MinHash距離小于第一閾值的兩個詞集合所對應的詞序列歸為同一類。其中第一閾值是可調的,其默認值可以設置為80% 乘以MinHash的位數。通過步驟S400,將所有文本串對應的詞序列劃分為一個或多個類。
根據步驟500,在每一類中進行最長公共子序列運算。已知多種LCS運算的方法,下文示出的是其中一種基于Java實現的偽碼。
publicclassLCSProblem
{
publicstaticvoidmain(String[]args)
{
String[]x={"","A","B","C","B","D","A","B"};
String[]y={"","B","D","C","A","B","A"};
int[][]b=getLength(x,y);
Display(b,x,x.length-1,y.length-1);
}
publicstaticint[][]getLength(String[]x,String[]y)
{
int[][]b=newint[x.length][y.length];
int[][]c=newint[x.length][y.length];
for(inti=1;i<x.length;i++)
{
for(intj=1;j<y.length;j++)
{
if(x[i]==y[j])
{
c[i][j]=c[i-1][j-1]+1;
b[i][j]=1;
}
elseif(c[i-1][j]>=c[i][j-1])
{
c[i][j]=c[i-1][j];
b[i][j]=0;
}
else
{
c[i][j]=c[i][j-1];
b[i][j]=-1;
}
}
}
returnb;
}
publicstaticvoidDisplay(int[][]b,String[]x,inti,intj)
{
if(i==0||j==0)
return;
if(b[i][j]==1)
{
Display(b,x,i-1,j-1);
System.out.print(x[i]+"");
}
elseif(b[i][j]==0)
{
Display(b,x,i-1,j);
}
elseif(b[i][j]==-1)
{
Display(b,x,i,j-1);
}
}
}
下面借助圖2對步驟S500進行詳細說明。
參看圖2,根據步驟S502到S506,從同一類中選擇兩個詞序列作為第一詞序列和第二詞序列,并計算第一詞序列和第二詞序列的最長公共子序列。需要指出,在這里和下文中,詞序列的選擇可以在符合條件的集合中任意進行。
根據步驟S508,將計算得到的LCS與第二閾值進行比較,如果LCS長度大于第二閾值,則將該LCS轉換為文本串模板。這里,第二閾值是可調的,其默認值可以設置為80%乘以第一詞序列和第二詞序列長度中的較大值。換言之,LCS長度與第一詞序列和第二詞序列長度中的較大值的比例應大于80%。
如果計算得到LCS長度不大于第二閾值,則返回步驟S504,將當前第二詞序列替換為同一類中的另一詞序列,并重復步驟S506和S508。這里,該另一詞序列是從該類中在當前第一詞序列的運算周期內尚未參與LCS運算的詞序列中選擇的。
重復步驟S504至S508,直到生成文本串模板。如果窮盡該類中的所有詞序列都無法生成模板(步驟S504),則刪除當前第一詞序列,并從該類中選擇一個詞序列作為第一詞序列開始重復上述步驟S504。
下面結合第一詞序列和第二詞序列的具體實例進一步說明生成文本串模板的過程。為簡便起見,假設第一和第二詞序列中的詞都是一個字母。
一種情況下,假設第一詞序列為{A,B,A,D,E,F,G},第二詞序列為{A,B,B,D,E,F,G}。經過LCS運算,第一詞序列和第二詞序列的LCS為{A,B,D,E,F,G},長度為6。由于第一和第二詞序列的長度都是7,可知LCS長度大于默認的第二閾值80%。因此,可以將該LCS轉換為模板{A,B,*,D,E,F,G},其中,“*”為占位詞,表示在詞“B”和“D”之間的詞最多為一個。占位詞也可以選用其他符號,為避免歧義,通常使用在輸入文本中不出現的特殊詞。
另一種情況,假設第一詞序列為{A,B,D,E,F,G},第二詞序列為{A,B,B,D,E,F,G}。經過LCS運算,第一詞序列和第二詞序列的LCS為{A,B,D,E,F,G},長度為6。由于第一和第二詞序列長度的較大值是7,可知LCS長度大于默認的第二閾值 80%。因此,同樣可以將該LCS轉換為模板{A,B,*,D,E,F,G},其中,“*”為占位詞,表示在詞“B”和“D”之間的詞最多為一個。
再一種情況,第一詞序列為{A,B,A,D,E,F,G},第二詞序列為{A,B,B,C,E,F,G}。經過LCS運算,第一詞序列和第二詞序列的LCS為{A,B,E,F,G},長度為5。由于第一和第二詞序列的長度都是7,可知LCS長度小于默認的第二閾值80%。因此,該LCS不能被轉換為模板。
應當理解,根據詞序列的實際長度,生成的模板可以包括多個占位詞“*”,每個占位詞表示其所在位置最多可以插入一個詞。
在生成文本串模板之后,根據圖3中步驟S510到S512,選擇另一個詞序列與該文本串模板進行LCS計算。與步驟S502類似,該另一詞序列是從該類中在當前第一詞序列的運算周期內尚未參與LCS運算的詞序列中選擇的。例如,第一和第二詞序列計算得到的LCS已經轉換為文本串模板,則在該類中選擇除當前的第一、第二詞序列之外的一個詞序列與該文本串模板進行LCS計算。
根據步驟S512,將計算得到的LCS與第二閾值進行比較,如果LCS長度大于第二閾值,則將該LCS轉換為新的文本串模板。
如果計算得到LCS長度不大于第二閾值,則返回步驟S510。
重復步驟S510到S514,直到窮盡這個類中所有的詞序列。
根據步驟S516,輸出文本串模板,并將該文本串模板所能匹配的所有詞序列從該類中刪除。作為替代,刪除文本串模板所能匹配的詞序列也可以在每次得到該文本串模板后進行。
返回步驟S502,直至該類為空,即該類中所有的詞序列均被刪除。
同樣的,對其他類進行LCS及文本串模板運算,直至所有類為空。
圖4所示的根據本發明的用于在多個文本串中確定最長公共子序列的設備400包括第一轉換裝置402、第二轉換裝置404、第一運算裝置406、分類裝置408和第二運算裝置410。其中,第一轉換裝置402用于將多個文本串分別轉換為詞序列,第二轉換裝置404用于將詞序列分別轉換為相應的詞集合,第一運算裝置406用于計算每個詞集合的最小哈希值,分類裝置408用于根據最小哈希值對詞序列進行分類,第二運算裝置410用于在每一類中進行最長公共子序列運算。
設備400的功能模塊可以通過硬件、軟件或硬件與軟件的結合實現,從而執行上述根據本發明的方法步驟。此外,第一轉換裝置402、第二轉換裝置404、第一運算裝置406、分類裝置408和第二運算裝置410可以組合或者進一步分解成子模塊,從而執行上述根據本發明的方法步驟。因此,上述功能模塊的任何可能的組合、分解或進一步的定義都落入權利要求所保護的范圍之內。
本發明不限于上述具體描述,本領域技術人員在上述描述基礎上容易想到的任何改變,都在本發明的范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!