一種在分布式存儲系統中統計數據的方法、裝置及系統與流程
本發明涉及通信領域,特別涉及一種在分布式存儲系統中統計數據的方法、裝置及系統。
背景技術:
HBase數據存儲系統是一種分布式存儲系統,具有高可靠性、高性能、面向列、可伸縮等特性,利用HBase數據存儲系統可以在廉價的PC Server上搭建起大規模結構化存儲集群。目前HBase數據存儲系統常常用作網站的存儲系統,用于存儲網站與用戶交互中產生的各類網絡數據。
網站的技術人員為了把握市場需求需要常常對網站中產生的各類網絡數據進行統計,根據各類網絡數據的統計結果分析市場需求。目前技術人員可以在自己的終端上向網站的HBase數據存儲系統發送查詢請求消息;HBaes數據存儲系統中的各服務器將自身存儲的網絡數據發送給終端;然后終端接收每個服務器發送的網絡數據,從接收的網絡數據中找出所需要統計的數據,對找出的數據進行統計得到統計結果。
在實現本發明的過程中,發明人發現現有技術至少存在以下問題:
目前HBase數據存儲系統中的每服務器將自身存儲的網絡數據發送給終端,導致網絡IO(Input Output,輸入輸出)開銷大,另外,由終端對所有數據進行統計,統計效率低下。
技術實現要素:
為了減少網絡IO開銷以及提高統計效率,本發明提供了一種在分布式存儲系統中統計數據的方法、裝置及系統。所述技術方案如下:
一種在分布式存儲系統中統計數據的方法,所述方法包括:
接收查詢請求消息,所述查詢請求消息攜帶數據條件;
向分布式存儲系統中的數據服務器發送所述查詢請求消息,使所述數據服 務器分別從自身存儲的數據中找出滿足所述數據條件的數據,統計所述找出的數據得到統計結果;
接收所述分布式存儲系統中的數據服務器返回的統計結果,對接收的統計結果進行匯總得到最終統計結果。
一種在分布式存儲系統中統計數據的裝置,所述裝置包括:
接收模塊,用于接收查詢請求消息,所述查詢請求消息攜帶數據條件;
發送模塊,用于向分布式存儲系統中的數據服務器發送所述查詢請求消息,使所述數據服務器分別從自身存儲的數據中找出滿足所述數據條件的數據,統計所述找出的數據得到統計結果;
匯總模塊,用于接收所述分布式存儲系統中的數據服務器返回的統計結果,對接收的統計結果進行匯總得到最終統計結果。
一種分布式存儲系統,所述分布式存儲系統包括:交互服務器和多個數據服務器;
所述交互服務器,用于接收終端發送的查詢請求消息,所述查詢請求消息攜帶數據條件,向分布式存儲系統中的數據服務器發送該查詢請求消息;接收所述數據服務器返回的統計結果,對接收的各統計結果進行匯總得到最終統計結果;
所述數據服務器,用于接收所述交互服務器發送的查詢請求消息,從自身存儲的數據文件中找出滿足所述數據條件的數據,對找出的數據進行統計得到統計結果,向所述交互服務器發送所述統計結果。
在本發明實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短到秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。
附圖說明
圖1-1是本發明實施例1提供的一種分布式存儲系統的網絡架構圖;
圖1-2是本發明實施例1提供的分區結構示意圖;
圖1-3是本發明實施例1提供的合并數據文件示意圖;
圖2是本發明實施例2提供的一種在分布式存儲系統中統計數據的方法流 程圖;
圖3是本發明實施例3提供的一種在分布式存儲系統中統計數據的方法流程圖;
圖4是本發明實施例4提供的一種在分布式存儲系統中統計數據的裝置結構示意圖;
圖5是本發明實施例5提供的一種服務器結構示意圖。
具體實施方式
為使本發明的目的、技術方案和優點更加清楚,下面將結合附圖對本發明實施方式作進一步地詳細描述。
實施例1
參見圖1-1,本發明實施例提供了一種分布式存儲系統,包括:
交互服務器和多個數據服務器,交互服務器分別與每個數據服務器相連,并與每個數據服務器組成一個局域網,交互服務器接入外網并通過外網與用戶的終端進行交互。
用戶需要統計數據時可以在其對應的終端上設置數據條件,然后終端向交互服務器發送攜帶該數據條件的查詢請求消息,以請求交互服務器統計分布式存儲系統中滿足該數據條件的數據。
交互服務器用于接收終端發送的查詢請求消息,該查詢請求消息攜帶數據條件,向分布式存儲系統中的數據服務器發送該查詢請求消息;接收數據服務器返回的統計結果,對接收的各統計結果進行匯總得到最終統計結果,向終端發送該最終統計結果。
數據服務器用于存儲分布式存儲系統中的數據文件,接收交互服務器發送的查詢請求消息,從自身存儲的數據文件中找出滿足該數據條件的數據,對找出的數據進行統計得到統計結果,向交互服務器發送該統計結果。
進一步地,交互服務器還用于獲取服務器列表,該服務器列表中的數據服務器用于存儲分布存儲系統中的各數據文件且一個數據文件存儲在一個數據服務器中;在接收到該查詢請求消息時,向該服務器列表中的各數據服務器發送該查詢請求消息。
可選的,交互服務器將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件;配置一個服務器集合,該服務器集合中包括分布式存儲系統中的一個或多個數據服務器;將合并的數據文件分別存儲在該服務器集合中的各數據服務器中;從該服務集合中選擇一數據服務器,將選擇的數據服務器的標識添加到服務器列表中。
在本實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短為秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。
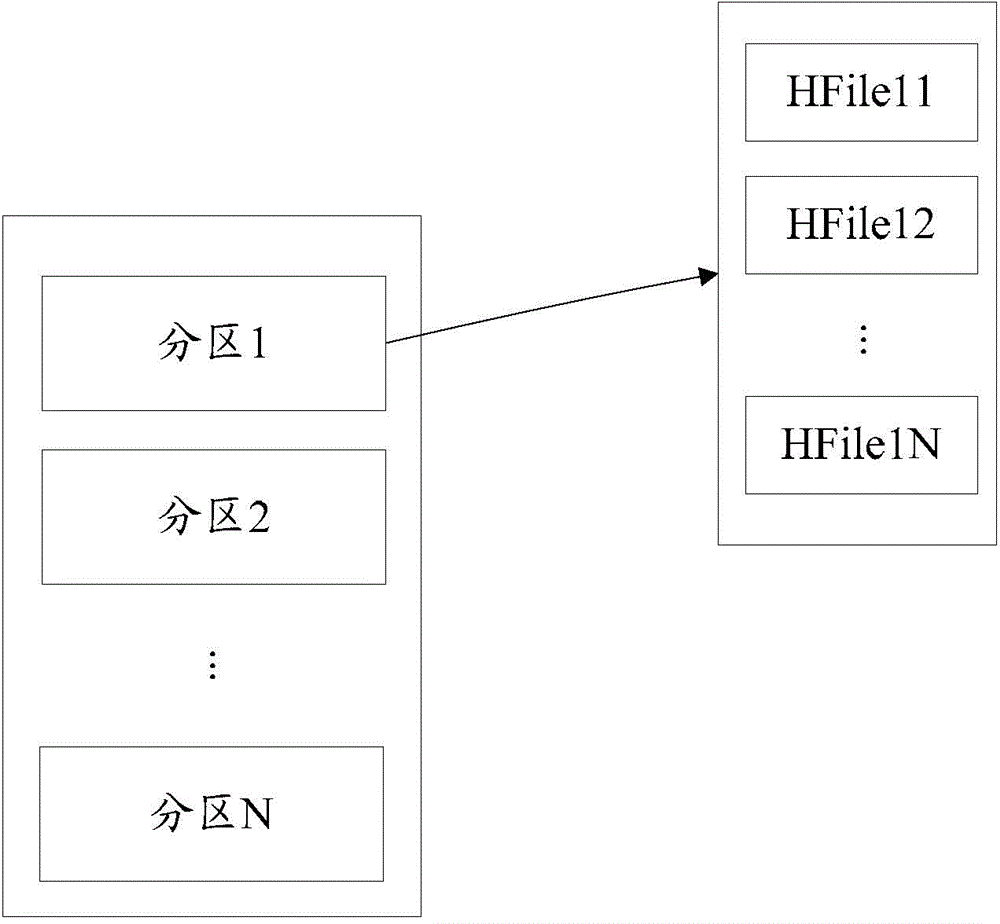
數據服務器中存儲的數據都是網站在與用戶交互時產生的數據,網站將產生的數據存儲在數據服務器的數據文件中。網站在分布式存儲系統中是按分區來存儲數據,一個分區中可以包括一個或多個數據文件,且一個分區可以位于同一數據服務器上或在不同的數據服務器上。例如,參見圖1-2,分區1中包括數據文件HFile11、HFile12……HFile1N,網站產生數據時,如果將該數據存儲在分區1,網站從分區1包括的數據文件HFile11、HFile12……HFile1N中選擇一個或多個數據文件,假設選擇數據文件HFile11和HFile12,將該數據存儲在數據文件HFile11和HFile12中。
當一個分區包括多個數據文件且該多個數據文件可能位于不同的數據服務器中,由于多個數據文件中可能存在部分數據相同,由各數據服務器直接對自身存儲的數據進行統計會影響統計結果的精度,所以在請求每個數據服務器對數據進行統計之前,交互服務器還用于將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件,并存儲在一臺數據服務器中。
交互服務器合并一個數據文件后,還配置一個服務器集合,該服務器集合中包括分布式存儲系統中的一個或多個數據服務器;將合并的數據文件分別存儲在服務器集合中的各數據服務器中,服務器集合中的各數據服務器相互備份各自的數據;從服務器集合中選擇一數據服務器,選擇的數據服務器用于進行數據統計,其他未選擇的數據服務器對選擇的數據服務器進行備份,將選擇的數據服務器的標識添加到服務器列表中。相應地,交互服務器在接收到終端發送的查詢請求消息時,向服務器列表中的各數據服務器發送該查詢請求消息。
參見圖1-3,交互服務器可以將屬于分區1的數據文件HFile11、HFile12…… HFile1N合并成一個數據文件HFile1,配置一個服務器集合,該服務器集合中包括數據服務器Server1、Server2和Server3,將合并的數據文件HFile1分別存儲在數據服務器Server1、Server2和Server3中,然后選擇數據服務器Server1并將數據服務器Server1的標識添加到服務器列表中。其中,數據服務器Server1用于進行數據統計,數據服務器Server2和Server3用于對數據服務器Server1進行備份。
在本實施例中,分布式存儲系統可以為HBase存儲系統,數據文件為可以為HFile文件。在數據服務器中存儲的數據可以為(key,value)對,value為具體的數據內容,key為數據標識。例如,該(key,value)對可以為用戶標識與用戶信息,用戶信息可以包括用戶性別、姓名、所在城市和/或愛好等信息。
在本發明實施例中,分布式存儲系統為Hbase分布式存儲系統。
在本發明實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短到秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。交互服務器還用于將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件,并存儲在一臺數據服務器中,提高了統計結果的精度。
實施例2
參見圖2,本發明實施例提供了一種在分布式存儲系統中統計數據的方法,包括:
步驟201:接收查詢請求消息,該查詢請求消息攜帶數據條件。
步驟202:向分布式存儲系統中的數據服務器發送該查詢請求消息,使數據服務器分別從自身存儲的數據中找出滿足數據條件的數據,統計找出的數據得到統計結果。
步驟203:接收分布式存儲系統中的數據服務器返回的統計結果,對接收的統計結果進行匯總得到最終統計結果。
進一步地,在向分布式存儲系統中的各數據服務器發送該查詢請求消息之前,還包括:
獲取服務器列表,該服務器列表中的數據服務器用于存儲分布存儲系統中 的各數據文件且一個數據文件存儲在一個數據服務器中;
可選的,向分布式存儲系統中的各數據服務器發送該查詢請求消息,包括:
向服務器列表中的各數據服務器發送該查詢請求消息。
可選的,獲取服務器列表,包括:
將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件;
配置一個服務器集合,該服務器集合中包括分布式存儲系統中的一個或多個數據服務器;
將合并的數據文件分別存儲在該服務器集合中的各數據服務器中;
從該服務集合中選擇一數據服務器,將選擇的數據服務器的標識添加到服務器列表中。
其中,分布式存儲系統為Hbase分布式存儲系統。
在本發明實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短到秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。
實施例3
參見圖3,本發明實施例提供了一種在分布式存儲系統中統計數據的方法,包括:
步驟301:交互服務器將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件。
在分布式存儲系統中每個數據文件中包含其屬于的分區的分區標識。本步驟可以為:交互服務器對分布式存儲系統中的每個數據服務器中的數據文件進行掃描,掃描出包含同一分區標識的數據文件,將包含同一分區標識的數據文件合并為一個數據文件。
分布式存儲系統中的數據都是網站與用戶進行交互時產生的數據。網站按分區來存儲數據。一個分區中包括一個或多個數據文件,且一個分區可以位于同一數據服務器上或位于不同的數據服務器上。由于屬于同一分區的數據文件中可能存在部分數據相同,如果將這些相同的數據分布在不同數據服務器,由各數據服務器分別進行統計,得到統計結果中存在部分數據被重復統計,造成 最終統計結果不準確,因此需要執行本步驟將同一分區的數據文件合并為同一數據文件。
步驟302:交互服務器配置服務器集合,該服務器集合中包括分布式存儲系統中的一個或多個數據服務器。
分布式存儲系統中的各數據服務器可以被事先劃分成多個服務器集合,每個服務器集合中包括的數據服務器的數目相同。服務器集合中的各數據服務器用于進行相互間的備份,所以服務器集合中的各數據服務器存儲的數據都相同。
步驟303:交互服務器將合并的數據文件分別存儲在該服務器集合中的各數據服務器中。
步驟304:交互服務器從該服務器集合中選擇一數據服務器,將選擇的數據服務器的標識添加到服務器列表中。
服務器集合中包括的各數據服務器存儲的數據都相同,所以一個服務器集合只需要一個數據服務器用于統計數據,其他的數據服務器對應該數據服務器進行備份。其中,交互服務器從服務器集合中選擇出來的一個數據服務器即用于統計數據,其他未選擇的各數據服務器對選擇的數據服務器進行備份。
交互服務器重復按上述步驟301至304將分布式存儲系統中的所有屬于同一分區的數據文件合并為一數據文件。然后用戶便可以在終端中請求交互服務器進行數據統計,具體流程如下。
步驟305:交互服務器接收終端發送的查詢請求消息,該查詢請求消息攜帶數據條件。
用戶需要交互服務器進行數據統計時,可以在其對應的終端上設置數據條件,例如,該數據條件可以為統計所在地為上海的用戶數目,統計愛好為打籃球的用戶數目或統計性別為女性的用戶數目等。然后終端向交互服務器發送攜帶該數據條件的查詢請求消息。
步驟306:交互服務器向該服務器列表中的每個數據服務器發送該查詢請求消息。
交互服務器根據該服務器列表中的每個數據服務器的標識,分別向每個數據服務器發送該查詢請求消息。
步驟307:數據服務器接收該查詢請求消息,根據該查詢請求消息攜帶的數據條件從自身存儲的數據中尋找出滿足該數據條件的數據。
步驟308:數據服務器對找出的數據進行統計得到統計結果,返回該統計結果給交互服務器。
步驟309:交互服務器接收各數據服務器的統計結果,對各數據服務器的統計結果進行匯總得到最終統計結果,向終端發送最終統計結果。
交互服務器對接收的各統計結果進行累加得到最終統計結果,向終端發送最終統計結果,終端接收并顯示最終統計結果給用戶,以使用戶對統計結果進行分析。
在本實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短至秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。交互服務器還用于將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件,并存儲在一臺數據服務器中,提高了統計結果的精度。
實施例4
參見圖4,本發明實施例提供了一種在分布式存儲系統中統計數據的裝置,包括:
接收模塊401,用于接收查詢請求消息,所述查詢請求消息攜帶數據條件;
發送模塊402,用于向分布式存儲系統中的數據服務器發送所述查詢請求消息,使所述數據服務器分別從自身存儲的數據中找出滿足所述數據條件的數據,統計所述找出的數據得到統計結果;
匯總模塊403,用于接收所述分布式存儲系統中的數據服務器返回的統計結果,對接收的統計結果進行匯總得到最終統計結果。
進一步地,所述裝置還包括:
獲取模塊,用于獲取服務器列表,所述服務器列表中的數據服務器用于存儲所述分布存儲系統中的各數據文件且一個數據文件存儲在一個數據服務器中;
可選的,所述發送模塊402,用于向所述服務器列表中的各數據服務器發送所述查詢請求消息。
可選的,所述獲取模塊包括:
合并單元,用于將所述分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件;
配置單元,用于配置一個服務器集合,所述服務器集合中包括所述分布式存儲系統中的一個或多個數據服務器;
存儲單元,用于將所述合并的數據文件分別存儲在所述服務器集合中的各數據服務器中;
添加單元,用于從所述服務集合中選擇一數據服務器,將所述選擇的數據服務器的標識添加到服務器列表中。
其中,所述分布式存儲系統為Hbase分布式存儲系統。
在本實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短至秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。交互服務器還用于將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件,并存儲在一臺數據服務器中,提高了統計結果的精度。
實施例5
參見圖5,本發明實施例提供的服務器的結構示意圖,該服務器可以為上述交互服務器。服務器1900可因配置或性能不同而產生比較大的差異,可以包括一個或一個以上中央處理器(central processing units,CPU)1922(例如,一個或一個以上處理器)和存儲器1932,一個或一個以上存儲應用程序1942或數據1944的存儲介質1930(例如一個或一個以上海量存儲設備)。其中,存儲器1932和存儲介質1930可以是短暫存儲或持久存儲。存儲在存儲介質1930的程序可以包括一個或一個以上模塊(圖示沒標出),每個模塊可以包括對服務器中的一系列指令操作。更進一步地,中央處理器1922可以設置為與存儲介質1930通信,在服務器1900上執行存儲介質1930中的一系列指令操作。
服務器1900還可以包括一個或一個以上電源1926,一個或一個以上有線或無線網絡接口1950,一個或一個以上輸入輸出接口1958,一個或一個以上鍵盤1956,和/或,一個或一個以上操作系統1941,例如Windows ServerTM,Mac OS XTM,UnixTM,LinuxTM,FreeBSDTM等等。
服務器1900可以包括有存儲器,以及一個或者一個以上的程序,其中一個或者一個以上程序存儲于存儲器中,且經配置以由一個或者一個以上處理器執行所述一個或者一個以上程序包含用于進行以下操作的指令:
接收查詢請求消息,所述查詢請求消息攜帶數據條件;
向分布式存儲系統中的數據服務器發送所述查詢請求消息,使所述數據服務器分別從自身存儲的數據中找出滿足所述數據條件的數據,統計所述找出的數據得到統計結果;
接收所述分布式存儲系統中的數據服務器返回的統計結果,對接收的統計結果進行匯總得到最終統計結果。
進一步地,所述向分布式存儲系統中的各數據服務器發送所述查詢請求消息之前,還包括:
獲取服務器列表,所述服務器列表中的數據服務器用于存儲所述分布存儲系統中的各數據文件且一個數據文件存儲在一個數據服務器中;
所述向分布式存儲系統中的各數據服務器發送所述查詢請求消息,包括:
向所述服務器列表中的各數據服務器發送所述查詢請求消息。
可選的,所述獲取服務器列表,包括:
將所述分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件;
配置一個服務器集合,所述服務器集合中包括所述分布式存儲系統中的一個或多個數據服務器;
將所述合并的數據文件分別存儲在所述服務器集合中的各數據服務器中;
從所述服務集合中選擇一數據服務器,將所述選擇的數據服務器的標識添加到服務器列表中。
所述分布式存儲系統為Hbase分布式存儲系統。
在本實施例中,各數據服務器具有統計數據的功能,各數據服務器可以并行的進行數據統計,統計時間由之前的分級縮短至秒級,大大提高了數據統計的效率;另外,各數據服務器只將統計結果返回給交互服務器,再由交互服務器返回給客戶端,相比直接返回數據,大大減少網絡IO的開銷。交互服務器還用于將分布式存儲系統中屬于同一分區的各數據文件合并為一個數據文件,并存儲在一臺數據服務器中,提高了統計結果的精度。
本領域普通技術人員可以理解實現上述實施例的全部或部分步驟可以通過硬件來完成,也可以通過程序來指令相關的硬件完成,所述的程序可以存儲于一種計算機可讀存儲介質中,上述提到的存儲介質可以是只讀存儲器,磁盤或光盤等。
以上所述僅為本發明的較佳實施例,并不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!