一種新聞熱點標簽的生成方法及系統與流程
本發明涉及信息處理技術領域,具體而言,特別涉及一種新聞熱點標簽的生成方法及系統。
背景技術:
隨著互聯網的飛速發展,網絡媒體已被公認為是繼報紙、廣播、電視之后的“第四媒體”。由于網絡媒體與傳統媒體在傳播載體和傳播方式上的不同,將導致網絡輿論熱點、焦點層出不窮,而這些信息的產生將對社會產生巨大影響。因此,有必要對這些熱點信息的正確性及傳播范圍進行有效處理。目前,針對新聞信息的分析功能有:新聞分類和預警、新聞聚合、新聞智能關聯、新聞轉載追蹤等,而新聞事件熱點標簽的生成是上述分析功能的基礎工作之一,例如:利用新聞熱點標簽作為檢索關鍵字從而發現熱點新聞;或者利用新聞熱點標簽生成熱點新聞摘要等。目前,實用階段的新聞事件熱點標簽生成技術主要有以下兩類:1)基于統計特征的方法,該方法主要是對詞元的使用頻率進行統計,雖然操作簡單,但是會忽略出現頻率不高但對于文檔具有關鍵意義的詞語,導致新聞熱點標簽生成的準確性低;2)基于詞語網絡圖的方法,該方法根據一定規則將文檔映射為詞語網絡,利用詞語網絡圖計算詞語的關鍵度,在該方法中,目前主要是將高頻詞語以及它們在同一窗口(也即相互鄰接、在相同的句子或段落等)的共現關系映射成詞語網絡,但該方法需要設定的參數過多,如頂點數、邊數等,因而常造成邊界上的取舍問題,如果邊界取舍不當,則造成新聞熱點標簽生成的準確性低。針對現有技術中新聞熱點標簽生成準確性低的問題,目前尚未提出有效的解決方法。
技術實現要素:
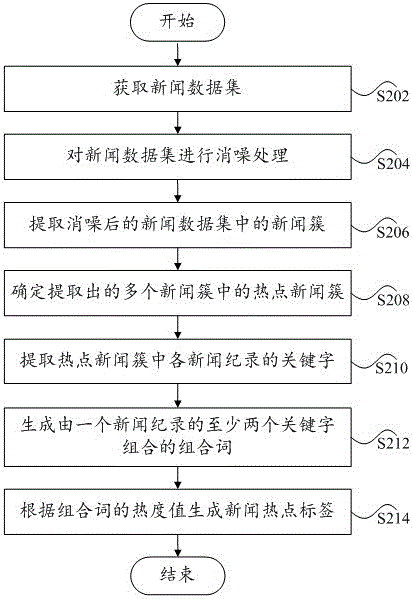
本發明的主要目的在于提供一種新聞熱點標簽的生成方法及系統,以解決現有技術中新聞熱點標簽生成準確性低的問題。為了實現上述目的,根據本發明的一個方面,提供了一種新聞熱點標簽的生成方法。本發明的新聞熱點標簽的生成方法包括:提取新聞數據集中的新聞簇,其中,新聞數據集由多個新聞記錄組成,一個新聞簇包括至少兩個新聞記錄;確定提取出的多個新聞簇中的熱點新聞簇;提取熱點新聞簇中各新聞記錄的關鍵字;生成由一個新聞記錄的至少兩個關鍵字組合的組合詞,其中,一個新聞記錄對應一個或多個組合詞;以及根據組合詞的熱度值生成新聞熱點標簽。進一步地,提取新聞數據集中的新聞簇包括:計算新聞數據集中兩個新聞記錄之間的相似度;判斷相似度是否大于第一預設閾值;以及若相似度大于第一預設閾值時,確定兩個新聞記錄屬于同一新聞簇。進一步地,計算兩個新聞記錄之間的相似度包括:將兩個新聞記錄分別進行特征化提取,得到一個新聞記錄對應的第一向量和另一個新聞記錄對應的第二向量;采用以下任意一個公式計算相似度:Sim(X,Y)=(X*Y)/(||X||*||Y||),或者其中,Sim(X,Y)為相似度,X為第一向量,Y為第二向量,X=(x1,x2,x3,...,xn),Y=(y1,y2,y3,...,yn),||X||和||Y||分別為X和Y的歐幾里得范數。進一步地,第一向量對應的新聞記錄為第一新聞記錄,將第一新聞記錄進行特征化提取,得到第一向量包括:對第一新聞記錄的標題和正文進行分詞,得到由多個詞元組成的第一詞元集;根據詞元在第一新聞記錄中出現的次數計算第一詞元集中詞元對應的特征值;刪除第一詞元集中特征值小于第二預設閾值的詞元;以及生成第一向量:X=(<w1,c1>,<w2,c2>,<w3,c3>,...,<wn,cn>),其 中,w1,w2,w3,...,wn第一詞元集中詞元,c1,c2,c3,...,cn分別為詞元對應的特征值,n為第一詞元集中詞元的個數。進一步地,計算第一詞元集中詞元對應的特征值包括采用以下公式進行計算:ci=a1+a2*T+a3*P+a4*K,其中,ci為第一詞元集中第i個詞元對應的特征值,a1為該詞元在第一新聞記錄中出現的次數,a2為該詞元在第一新聞記錄的標題中出現的次數,a3為該詞元在第一新聞記錄的段首或段尾中出現的次數,a4為該詞元在第一新聞記錄的關鍵句中出現的次數,T、P、K均為無量綱參數。進一步地,在得到第一詞元集之后、計算第一詞元集中詞元對應的特征值之前,將第一新聞記錄進行特征化提取還包括:去除第一詞元集中的無效詞。進一步地,在計算第一詞元集中詞元對應的特征值之后、生成第一向量之前,將第一新聞記錄進行特征化提取還包括:獲取第一詞元集中互為同義詞的詞元,得到同義詞元組;將同義詞元組對應的各特征值相加后作為最大詞元對應的特征值,其中,最大詞元為同義詞元組中特征值最大的詞元;在第一詞元集中刪除同義詞元組中除最大詞元之外的其他詞元。進一步地,提取熱點新聞簇中的關鍵字包括:提取熱點新聞簇中各新聞記錄對應的向量中的詞元作為關鍵字。進一步地,根據組合詞的熱度值生成新聞熱點標簽包括:針對熱點新聞簇的各新聞記錄,計算每個新聞記錄對應的組合詞的特征值,其中,一個組合詞的特征值為該組合詞中各詞元對應的特征值的和;采用以下公式計算組合詞的熱度值:其中,Term_hot_value為第一組合詞的熱度值,第一組合詞為任意一個組合詞,N為熱點新聞簇包括的新聞記錄的個數,M為熱點新聞簇中第j個新聞記錄對應的組合詞的個數,n為熱點新聞簇中具有第一組合詞的新聞記錄個數,Term_Countji為第j個新聞記錄對應的第i個組合詞的特征值;以及確定熱度值大于第三預設閾值的組合詞為新聞熱點標簽。進一步地,熱點新聞簇包括第二新聞記錄,提取第二新聞記錄的關鍵字包 括:對第二新聞記錄的標題和正文進行分詞,得到由多個詞元組成的第二詞元集;根據詞元在第二新聞記錄中出現的次數計算第二詞元集中詞元對應的特征值;刪除第二詞元集中特征值小于第四預設閾值的詞元;確定第二詞元集中的詞元為第二新聞記錄的關鍵字。進一步地,根據組合詞的熱度值生成新聞熱點標簽包括:針對熱點新聞簇的各新聞記錄,計算每個新聞記錄對應的組合詞的特征值,其中,一個組合詞的特征值為該組合詞中各關鍵字在該新聞記錄中出現次數的和;采用以下公式計算每個組合詞的熱度值:其中,Term_hot_value為第二組合詞的熱度值,第二組合詞為任意一個組合詞,N為熱點新聞簇包括的新聞記錄的個數,M為熱點新聞簇中第j個新聞記錄對應的組合詞的個數,n為熱點新聞簇中具有第二組合詞的新聞記錄個數,Term_Countji為第j個新聞記錄對應的第i個組合詞的特征值;以及確定熱度值大于第五預設閾值的組合詞為新聞熱點標簽。進一步地,確定提取出的多個新聞簇中的熱點新聞簇包括采用以下公式計算各個新聞簇的熱度值:Cluster_Hot_Value=Site_Count*Site_Rate+Publish_Count*Publish_Rate其中,Cluster_Hot_Value為一個新聞簇熱度值,Site_Count為該新聞簇中包含的網站個數,Site_Rate為曝光率權重,Publish_Count為新聞的發布量,Publish_Rate為發布率權重,且Site_Rate+Publish_Rate=1;以及根據各個新聞簇的熱度值確定熱點新聞簇。進一步地,在提取新聞數據集中的新聞簇之前,該方法還包括:對新聞數據集進行消噪處理。進一步地,對新聞數據集進行消噪處理包括:將新聞數據集中的新聞記錄的數據類型與預設的數據類型進行匹配;刪除新聞數據集中數據類型與預設的數據類型不匹配的新聞記錄,和/或判斷新聞數據集中的新聞記錄的標題與正文是否一致;刪除新聞數據集中標題與正文不一致的新聞記錄。進一步地,第三新聞記錄為新聞數據集中的任意一個新聞記錄,判斷第三 新聞記錄的標題與正文是否一致包括:對第三新聞記錄的標題進行分詞,得到由一個或多個詞元組成的第三詞元組;統計第三詞元組中各詞元在第三新聞記錄的正文中出現次數的和;判斷統計得到的和是否大于第六預設閾值;以及當統計得到的和大于第六預設閾值時,確定第三新聞記錄的標題與正文一致。為了實現上述目的,根據本發明的另一個方面,提供了一種新聞熱點標簽的生成系統。本發明的新聞熱點標簽的生成系統包括:第一提取單元,用于提取新聞數據集中的新聞簇,其中,新聞數據集由多個新聞記錄組成,一個新聞簇包括至少兩個新聞記錄;確定單元,用于確定提取出的多個新聞簇中的熱點新聞簇;第二提取單元,用于提取熱點新聞簇中各新聞記錄的關鍵字;第一生成單元,用于生成由一個新聞記錄的至少兩個關鍵字組合的組合詞,其中,一個新聞記錄對應一個或多個組合詞;以及第二生成單元,用于根據組合詞的熱度值生成新聞熱點標簽。進一步地,第一提取單元包括:第一計算模塊,用于計算新聞數據集中兩個新聞記錄之間的相似度;判斷模塊,用于判斷相似度是否大于第一預設閾值;以及第一確定模塊,用于當相似度大于第一預設閾值時,確定兩個新聞記錄屬于同一新聞簇。進一步地,第一計算模塊包括:特征化子模塊,用于將兩個新聞記錄分別進行特征化提取,得到一個新聞記錄對應的第一向量和另一個新聞記錄對應的第二向量;計算子模塊,用于采用以下任意一個公式計算相似度:Sim(X,Y)=(X*Y)/(||X||*||Y||),或者其中,Sim(X,Y)為相似度,X為第一向量,Y為第二向量,X=(x1,x2,x3,...,xn),Y=(y1,y2,y3,...,yn),||X||和||Y||分別為X和Y的歐幾里得范數。進一步地,第一向量對應的新聞記錄為第一新聞記錄,特征化子模塊采用 以下步驟得到第一向量:對第一新聞記錄的標題和正文進行分詞,得到由多個詞元組成的第一詞元集;根據詞元在第一新聞記錄中出現的次數計算第一詞元集中詞元對應的特征值;刪除第一詞元集中特征值小于第二預設閾值的詞元;以及生成第一向量:X=(<w1,c1>,<w2,c2>,<w3,c3>,...,<wn,cn>),其中,w1,w2,w3,...,wn第一詞元集中詞元,c1,c2,c3,...,cn分別為詞元對應的特征值,n為第一詞元集中詞元的個數。進一步地,特征化子模塊采用以下公式計算第一詞元集中詞元對應的特征值:ci=a1+a2*T+a3*P+a4*K,其中,ci為第一詞元集中第i個詞元對應的特征值,a1為該詞元在第一新聞記錄中出現的次數,a2為該詞元在第一新聞記錄的標題中出現的次數,a3為該詞元在第一新聞記錄的段首或段尾中出現的次數,a4為該詞元在第一新聞記錄的關鍵句中出現的次數,T、P、K均為無量綱參數。進一步地,第二提取單元提取熱點新聞簇中各新聞記錄對應的向量中的詞元作為關鍵字。進一步地,第二生成單元包括:第二計算模塊,用于針對熱點新聞簇的各新聞記錄,計算每個新聞記錄對應的組合詞的特征值,其中,一個組合詞的特征值為該組合詞中各詞元對應的特征值的和;第三計算模塊,采用以下公式計算組合詞的熱度值:其中,Term_hot_value為第一組合詞的熱度值,第一組合詞為任意一個組合詞,N為熱點新聞簇包括的新聞記錄的個數,M為熱點新聞簇中第j個新聞記錄對應的組合詞的個數,n為熱點新聞簇中具有第一組合詞的新聞記錄個數,Term_Countji為第j個新聞記錄對應的第i個組合詞的特征值;以及第二確定模塊,用于確定熱度值大于第三預設閾值的組合詞為新聞熱點標簽。進一步地,確定單元包括第四計算模塊,用于采用以下公式計算各個新聞簇的熱度值:Cluster_Hot_Value=Site_Count*Site_Rate+Publish_Count*Publish_Rate其中,Cluster_Hot_Value為一個新聞簇熱度值,Site_Count為該新聞簇中包 含的網站個數,Site_Rate為曝光率權重,Publish_Count為新聞的發布量,Publish_Rate為發布率權重,且Site_Rate+Publish_Rate=1;以及第三確定模塊,用于根據各個新聞簇的熱度值確定熱點新聞簇。通過本發明,在生成新聞熱點標簽時,首先新聞數據集中提取新聞簇,每一個新聞簇都是由一群內容相似的新聞記錄組成,而不同的新聞簇之間的新聞高度相異,然后在提取出的多個新聞簇中確定熱點新聞簇,再提取熱點新聞簇中各新聞記錄的關鍵字,并生成由一個新聞記錄的至少兩個關鍵字組合的組合詞,最后根據組合詞的熱度值生成新聞熱點標簽,能夠依據海量的新聞數據集生成新聞熱點標簽,解決了新聞熱點標簽生成準確性低問題,達到了提高新聞熱點標簽生成準確性的效果。附圖說明圖1是根據本發明第一實施例的新聞熱點標簽的生成方法的流程圖;圖2是根據本發明第二實施例的新聞熱點標簽的生成方法的流程圖;圖3是根據本發明第三實施例的新聞熱點標簽的生成方法的流程圖;圖4是根據本發明第四實施例的新聞熱點標簽的生成系統的框圖;圖5是根據本發明第五實施例的新聞熱點標簽的生成系統的框圖;圖6是根據本發明第六實施例的新聞熱點標簽的生成系統的工作流程示意圖;圖7至圖10分別是根據本發明第六實施例的新聞熱點標簽的生成系統中各模塊的工作流程示意圖。具體實施方式下面結合附圖和具體實施方式對本發明做進一步說明。需要指出的是,在不沖突的情況下,本申請中的實施例及實施例中的特征可以相互組合。首先對本發明所提供的新聞熱點標簽的生成方法的實施例進行詳細描述。圖1是根據本發明第一實施例的新聞熱點標簽的生成方法的流程圖,如圖1所示,該方法包括如下的步驟S102至步驟S110。步驟S102:提取新聞數據集中的新聞簇。新聞數據集是由多個新聞記錄組成的集合,該集合可從網站上獲取,例如自動獲取各大門戶網站上新聞板塊 的新聞記錄。新聞簇是由至少兩個內容相似的新聞記錄組成,屬于不同新聞簇的新聞記錄之間內容高度相異。該步驟可通過聚類方法,將新聞數據集中各新聞記錄進行聚類,得到新聞簇。步驟S104:確定提取出的多個新聞簇中的熱點新聞簇。從提取出的多個新聞簇確定熱點新聞簇時,可根據新聞簇中各新聞記錄的曝光次數、轉載次數、評論量、發布量以及來源網站個數等因素計算新聞簇熱度值,然后根據新聞簇的熱度值進行排序,提取排名靠前的新聞簇作為熱點新聞事件,即熱點新聞簇。在該步驟中,根據實際需要,可能確定一個或多個熱點新聞簇,當確定的熱點新聞簇是多個時,分別對每個熱點新聞簇執行步驟S106至步驟S110,以確定每個熱點新聞簇的新聞熱點標簽。步驟S106:提取熱點新聞簇中各新聞記錄的關鍵字。在提取關鍵字時,對熱點新聞簇進行分析,通過多文檔關鍵字抽取技術提煉出熱點新聞簇中各新聞記錄的關鍵字。這些關鍵字是指能夠體現新聞記錄的核心詞,例如以位于新聞標題中的一些詞作為關鍵字。步驟S108:生成由一個新聞記錄的至少兩個關鍵字組合的組合詞。由于單一關鍵字所表示的信息量有限,因此在該步驟中將一個新聞記錄的至少兩個關鍵字組合為關鍵詞,優選地,以相鄰的關鍵字結合起來形成組合詞,從而起到了擴充信息量的作用。在進行關鍵字的組合時,可結合關鍵字的詞性進行合理組合,組合后,一個新聞記錄將對應一個或多個組合詞。步驟S110:根據組合詞的熱度值生成新聞熱點標簽。在生成新聞熱點標簽時,可根據組合詞在新聞記錄中出現的次數、位置、在整個熱點新聞簇中出現的概率等因素計算該組合詞的熱度值,然后根據組合詞熱度值進行排序,提取排名靠前的組合詞作為新聞熱點標簽。采用該實施例提供的新聞熱點標簽的生成方法,從海量的新聞數據集中獎相似的新聞進行聚類得到新聞簇,并確定新聞簇中的熱點新聞簇,然后在熱點新聞簇的多個新聞記錄中獲取到由多個關鍵字組成組合詞,最后根據組合詞的熱度值確定新聞熱點標簽,提高了獲取新聞熱點標簽的準確性。圖2是根據本發明第二實施例的新聞熱點標簽的生成方法的流程圖,如圖2所示,該方法包括如下的步驟S202至步驟S214。步驟S202:獲取新聞數據集。在該步驟中,可定時或者在滿足一定條件時,從預定的各大門戶網站新聞板塊自動獲取多條新聞記錄,該獲取到的新聞記錄采用統一格式存儲,將每條新聞記錄存儲為由<新聞標題,新聞內容,發布網站,發布時間,新聞鏈接>五部分內容組成的數據。步驟S204:對新聞數據集進行消噪處理。由于現實情況下數據是存在噪音的,因此該步驟的主要功能便是針對數據源中不合理數據進行數據清理,保留有效數據,過濾無效數據,以進一步提高獲取新聞熱點標簽的準確性,同時,降低數據處理的復雜度。優選地,在進行消噪處理時采用如下的一種和/或兩種方法。方法1:將新聞數據集中的新聞記錄的數據類型與預設的數據類型進行匹配,從而篩選出有問題的數據,其中,預設的數據類型包括<新聞標題,新聞內容,發布網站,發布時間,新聞鏈接>五部分內容,并且任意一部分內容的數據格式均是標準數據格式。在匹配時,如一條新聞記錄的某部分內容為空,或者該新聞記錄的某部分內容的數據格式和標準數據格式不一致,確定該新聞紀錄的數據類型與預設數據類型不匹配,將該新聞紀錄從新聞數據集中刪除。方法2:判斷新聞數據集中的新聞記錄的標題與正文是否一致,當標題與正文不一致時,確定該新聞記錄屬于無效的新聞記錄,從新聞數據集中刪除。為了準確的將無效的新聞記錄從新聞數據集中刪除,更優選地,在判斷新聞記錄的標題與正文是否一致時,首先對該新聞記錄的標題進行分詞,得到一個或多個詞元,將該一個或多個詞元組成一個詞元組;然后統計該詞元組中各詞元在該新聞記錄的正文中出現次數的和;再判斷統計得到的和是否大于預設的閾值,當統計得到的和大于該閾值時,確定該新聞記錄的標題與正文一致,否則確定為不一致。步驟S206:提取消噪后的新聞數據集中的新聞簇。優選地,在提取新聞簇時,首先計算新聞數據集中各新聞記錄之間的相似度,將相似度較高的新聞紀錄構成新聞簇。步驟S208:確定提取出的多個新聞簇中的熱點新聞簇。在確定熱點新聞簇時,首先計算各個新聞簇的熱度值,然后根據計算得到的熱度值確定熱點新聞簇。優選地,在計算新聞簇的熱度值時,采用以下的公進行計算:Cluster_Hot_Value=Site_Count*Site_Rate+Publish_Count*Publish_Rate其中,Cluster_Hot_Value為一個新聞簇熱度值,Site_Count為該新聞簇中包含的網站個數,也即曝光度,是指該新聞簇中各新聞記錄的不同源網站的個數,Site_Rate為曝光率權重,用來衡量曝光度Site_Count的重要程度,即在計算新聞簇熱度值時Site_Count所占的比重;Publish_Count為新聞的發布量,是指在新聞簇中包含的所有新聞數;Publish_Rate為發布率權重,用來衡量新聞發布量Publish_Count的重要程度,即在計算新聞簇熱度值時Publish_Count所占的比重,且Site_Rate+Publish_Rate=1。對每個新聞簇進行計算,得到各新聞簇的熱度值,然后將各個熱度值進行由大到小的排序,根據實際需要選擇熱度值排名前幾位的新聞簇作為熱點新聞簇,或者將計算得到的熱度值與預設值相比較,選擇熱度值大于預設值的新聞簇作為熱點新聞簇。步驟S210:提取熱點新聞簇中各新聞記錄的關鍵字。對于一個新聞紀錄,在提取關鍵字時,首先對該新聞記錄的標題和正文進行分詞,得到由多個詞元組成詞元集;然后根據詞元在該新聞記錄中出現的次數計算詞元集中每個詞元對應的特征值,其中,針對詞元在新聞記錄中出現的位置給予不同程度的線性加權;然后將每個詞元的特征值與預設閾值比較,找出特征值小于預設閾值的詞元,并將這些詞元從詞元集中刪除,該詞元集中剩下的詞元作為該新聞記錄的關鍵字。將熱點新聞簇中各新聞紀錄按照上述方法確定關鍵字后,便可得到一個熱點新聞簇對應的關鍵字。步驟S212:生成由一個新聞記錄的至少兩個關鍵字組合的組合詞。針對每個新聞紀錄,在得到關鍵字后,根據該新聞紀錄的關鍵字生成該新聞紀錄對應的組合詞。在生成組合詞時,可將相鄰的兩個或多個關鍵字進行組合,具體地,可采用如下的組合方法。對于兩個關鍵字生成的組合詞,若前面關鍵字的詞性為形容詞,則后面關鍵字只能是名詞,即“形容詞+名詞”,其他的形式還有“動詞+副詞”,“動詞+名詞”,“名詞+名詞”,“名詞+動詞”五種形式;對于三個關鍵字生成的組合詞,組合可以是下面的任意一種:“名詞+名詞+名詞”,“名詞+形容詞+名詞”,“動詞+名詞+名詞”,“名詞+名詞+動詞”,“名詞+動詞+名詞”,“形容詞+名詞+動詞”, “副詞+形容詞+名詞”,此外用戶還可以根據自己的業務需求擴充組合詞形式。將關鍵字組合為組合詞以后,擴充了新聞熱點標簽的信息量。步驟S214:根據組合詞的熱度值生成新聞熱點標簽。通過上述步驟S212,可以得到熱點新聞簇中各新聞記錄的組合詞,在該步驟中,針對一個新聞紀錄,首先計算各個組合詞的特征值,一個組合詞的特征值為該組合詞中各關鍵字在該新聞記錄中出現次數的和;然后分別根據每個組合詞的特征值計算其熱度值,具體地,可采用如下的公式計算:其中,Term_hot_value為組合詞的熱度值,該組合詞為某熱點新聞簇中第j個新聞記錄對應的組合詞,N為該熱點新聞簇包括的新聞記錄的個數,M為該第j個新聞記錄對應的組合詞的個數,n為該熱點新聞簇中具有該組合詞的新聞記錄個數,Term_Countji為該第j個新聞記錄對應的第i個組合詞的特征值。采用上述公式,可確定每一個組合詞的熱度值,然后將每個熱度值與預設閾值,也即預設的熱度值進行比較,找出熱度值大于該預設閾值的組合詞,將這一部分組合詞作為新聞熱點標簽。采用該實施例提供的新聞熱點標簽的生成方法,獲取到新聞數據集后,首先對其進行消噪處理,能夠避免噪聲數據對新聞熱點標簽準確性的影響,同時提高后續步驟中數據處理效率;在確定熱點新聞簇時,考慮新聞記錄來源網站個數、曝光率權重、新聞的發布量以及發布率權重因素,能夠準確的從新聞數據集中提取熱點新聞簇;在利用關鍵字生成組合詞時,考慮了關鍵字的詞性,使得新聞熱點標簽的提取結果更加準確。圖3是根據本發明第三實施例的新聞熱點標簽的生成方法的流程圖,如圖3所示,該方法包括如下的步驟S302至步驟S318。步驟S302:獲取新聞數據集。步驟S304:對新聞數據集進行消噪處理。上述的步驟S302與第二實施例中的步驟S202相同,上述的步驟S304與第二實施例中的步驟S204相同,此處不再贅述。步驟S306:將消噪后的新聞數據集中的新聞紀錄進行特征化提取,得到 每個新聞紀錄對應的向量。優選地,針對一個新聞紀錄A,計算該新聞紀錄A對應的向量的方法具體包括如下的步驟S3060至步驟S3063。步驟S3060:對該新聞記錄A的標題和正文進行分詞,得到由多個詞元組成的詞元集{w1,w2,w3,...,wn}。步驟S3061:根據詞元在該新聞記錄A中出現的次數計算詞元集中每個詞元對應的特征值。以詞元集{w1,w2,w3,...,wn}中任意一個詞元wi為例,可采用以下公式計算該詞元wi對應的特征值ci:ci=(a1+a2*T+a3*P+a4*K),其中,a1為該詞元wi在新聞記錄A中出現的次數,a2為該詞元wi在新聞記錄A的標題中出現的次數,a3為該詞元wi在新聞記錄A的段首或段尾中出現的次數,a4為該詞元wi在新聞記錄A的關鍵句中出現的次數,該處的關鍵句是指新聞紀錄中的核心的和綜述的句子,可采用預設詞進行標定,例如將包括有“關鍵是”、“旨在”、“總之”等的句子標定為關鍵句,T、P、K均為大于零的無量綱參數。步驟S3062:刪除詞元集{w1,w2,w3,...,wn}中特征值小于預設閾值的詞元。步驟S3063:根據刪除后的詞元及其對應的特征值生成新聞記錄A對應的向量:X=(<w1,c1>,<w2,c2>,<w3,c3>,...,<wn,cn>),n為詞元集中詞元的個數。更優選地,在步驟S3060與步驟S3061之間,設置步驟S3064:去除詞元集{w1,w2,w3,...,wn}中的無效詞。在該步驟S3064中,通過詞性分型,確定詞元集中的連詞、方位詞、區別詞、嘆詞、擬聲詞、介詞、量詞、代詞、助詞、語氣詞、狀態詞等無效詞,然后將詞元集{w1,w2,w3,...,wn}中的無效詞去除。通過該步驟S3064,在步驟S3061中,只需計算剩余詞元的詞元集,減少步驟S3061的計算量,提升數據處理效率。同時,步驟S3063中的n為原始詞元集經過S3064去除和步驟S3062刪除后剩余詞元的個數。為了進一步提升數據處理效率,并使新聞熱點標簽的準確度更高,進一步優選地,在步驟S3061與步驟S3062之間,設置步驟S3065至步驟S3067進行同義詞元的處理,其中,對于經過的向量計算方法,在步驟S3063中,n為原始詞元集經過S3064去除、步驟S3062刪除和步驟S3067去除后剩余詞元個數。步驟S3065:獲取去除無效詞后的詞元集中互為同義詞的詞元,得到同義詞元組。步驟S3066:將同義詞元組對應的各特征值相加后作為最大詞元對應的特征值,其中,最大詞元為同義詞元組中特征值最大的詞元。步驟S3067:在去除無效詞后的詞元集中刪除同義詞元組中除最大詞元之外的其他詞元。步驟S308:根據兩個新聞紀錄對應向量計算兩個新聞紀錄之間的相似度。優選地,可采用以下任意一種方法計算相似度。余弦值相似度計算法:Sim(X,Y)=(X*Y)/(||X||*||Y||),X和Y分別為兩個新聞紀錄對應的向量,X*Y表示向量X和向量Y之間的向量積,||X||和||Y||分別為X和Y的歐幾里得范數;曼哈頓距離相似度計算法:X=(x1,x2,x3,...,xn),Y=(y1,y2,y3,...,yn),|xi-yi|為xi減去yi的絕對值。歐幾里得距離相似度計算法:(xi-yi)*(xi-yi)表示xi減去yi后差的平方。步驟S310:根據兩個新聞紀錄之間的相似度確定其是否屬于同一新聞簇。在確定新聞簇時,判斷兩個新聞紀錄的相似度Sim(X,Y)是否大于預設閾值,如果大于,則認為兩個新聞紀錄的內容是相似的,屬于同一新聞簇,將其合并成簇;否則,繼續計算兩個新聞紀錄中一個新聞紀錄與下一個新聞紀錄之間的相似度,其中,預設閾值可由用戶根據實際需要定義。步驟S312:確定提取出的多個新聞簇中的熱點新聞簇。步驟S314:提取熱點新聞簇中各新聞記錄對應的向量中的詞元作關鍵字。步驟S316:生成由一個新聞記錄的至少兩個關鍵字組合的組合詞。上述的步驟S312、步驟S314和步驟S316分別依次與上述第二實施例中的步驟S208、步驟S210和步驟S212相同,此處不再贅述。步驟S318:根據組合詞的熱度值生成新聞熱點標簽。在該步驟中,針對一個新聞紀錄,首先計算各個組合詞的特征值,一個組 合詞的特征值為該組合詞中各關鍵字(也即各詞元)對應的特征值的和,然后分別根據每個組合詞的特征值計算其熱度值,具體地,可采用如下的公式計算:其中,Term_hot_value為組合詞的熱度值,該組合詞為某熱點新聞簇中第j個新聞記錄對應的組合詞,N為該熱點新聞簇包括的新聞記錄的個數,M為該第j個新聞記錄對應的組合詞的個數,n為該熱點新聞簇中具有該組合詞的新聞記錄個數,Term_Countji為該第j個新聞記錄對應的第i個組合詞的特征值。采用上述公式,可確定每一個組合詞的熱度值,然后將每個熱度值與預設閾值,也即預設的熱度值進行比較,找出熱度值大于該預設閾值的組合詞,將這一部分組合詞作為新聞熱點標簽。優選地,可將每一個組合詞的熱度值進行歸一化處理,將歸一化處理后的值作為熱度值。采用該實施例提供的新聞熱點標簽的生成方法,在計算詞元對應的特征值時,將詞元所在的位置給予線性加權,從而避免漏掉出現次數少但重要的詞元,提高獲取新聞熱點標簽的準確性;在計算特征值之前,根據詞元的詞性將無效詞去掉,提高方法的執行效率;在計算特征值之后,從語義出發,將同義的詞元特征值進行合并處理,提升數據處理效率的同時進一步使得新聞熱點標簽的準確度更高;在計算熱度值時,根據每個組合詞的特征值進行計算,保證了新聞熱點標簽的準確性;在確定新聞簇時,計算新聞紀錄的相似度進行確定,計算方法簡單,準確性高。以上是對本發明所提供的新聞熱點標簽的生成方法進行的描述。下面將對本發明提供的新聞熱點標簽的生成系統進行描述,需要說明的是,該系統可用于執行上述任意一種新聞熱點標簽的生成方法。圖4是根據本發明第四實施例的新聞熱點標簽的生成系統的框圖,如圖4所示,該系統包括第一提取單元10、確定單元20、第二提取單元30、第一生成單元40和第二生成單元50。其中,第一提取單元10用于提取新聞數據集中的新聞簇。新聞數據集是由多個新聞記錄組成的集合,該提取單元10首先從網站上獲取各大門戶網站 上新聞板塊的新聞記錄,得到細紋數據集,然后通過聚類方法將新聞數據集中各新聞記錄進行聚類,得到新聞簇,因而新聞簇至少由兩個內容相似的新聞記錄組成,屬于不同新聞簇的新聞記錄之間內容高度相異。確定單元20用于確定提取出的多個新聞簇中的熱點新聞簇,該確定單元20可根據新聞簇中各新聞記錄的曝光次數、轉載次數、評論量、發布量以及來源網站個數等因素計算新聞簇熱度值,然后根據新聞簇的熱度值進行排序,提取排名靠前的新聞簇作為熱點新聞事件,也即熱點新聞簇。第二提取單元30用于提取熱點新聞簇中各新聞記錄的關鍵字,在提取關鍵字時,第二提取單元30對熱點新聞簇進行分析,通過多文檔關鍵字抽取技術提煉出熱點新聞簇中各新聞記錄的關鍵字。這些關鍵字是指能夠體現新聞記錄的核心詞,例如以位于新聞標題中的一些詞作為關鍵字。第一生成單元40用于生成由一個新聞記錄的至少兩個關鍵字組合的組合詞,由于單一關鍵字所表示的信息量有限,因此通過該單元將一個新聞記錄的至少兩個關鍵字組合為關鍵詞,優選地,以相鄰的關鍵字結合起來形成組合詞,從而起到了擴充信息量的作用。在進行關鍵字的組合時,可結合關鍵字的詞性進行合理組合,組合后,一個新聞記錄將對應一個或多個組合詞。第二生成單元50用于根據組合詞的熱度值生成新聞熱點標簽,在生成新聞熱點標簽時,可根據組合詞在新聞記錄中出現的次數、位置、在整個熱點新聞簇中出現的概率等因素計算該組合詞的熱度值,然后根據組合詞熱度值進行排序,提取排名靠前的組合詞作為新聞熱點標簽。采用該實施例提供的新聞熱點標簽的生成系統,從海量的新聞數據集中獎相似的新聞進行聚類得到新聞簇,并確定新聞簇中的熱點新聞簇,然后在熱點新聞簇的多個新聞記錄中獲取到由多個關鍵字組成組合詞,最后根據組合詞的熱度值確定新聞熱點標簽,提高了獲取新聞熱點標簽的準確性。圖5是根據本發明第五實施例的新聞熱點標簽的生成系統的框圖,如圖5所示,該系統包括獲取單元60、消噪單元70、第一提取單元10、確定單元20、第二提取單元30、第一生成單元40和第二生成單元50,其中,消噪單元60包括第一消噪模塊62和/或第二消噪模塊64;第一提取單元10包括第一計算模塊12、判斷模塊14、第一確定模塊16;確定單元20包括第四計算模塊22 和第三確定模塊24;第二生成單元50包括第二計算模塊52、第三計算模塊54和第二確定模塊56。獲取單元60用于獲取多個新聞紀錄構成新聞數據集。該獲取單元60可定時或者在滿足一定條件時,從預定的各大門戶網站新聞板塊自動獲取多條新聞記錄,該獲取到的新聞記錄采用統一格式存儲,將每條新聞記錄存儲為由<新聞標題,新聞內容,發布網站,發布時間,新聞鏈接>五部分內容組成的數據。消噪單元70用于對新聞數據集中的數據進行消噪處理,過濾無效數據,以進一步提高獲取新聞熱點標簽的準確性,同時,降低數據處理的復雜度。具體地,第一消噪模塊62用于將新聞數據集中的新聞記錄的數據類型與預設的數據類型進行匹配,并所述新聞數據集中數據類型與預設的數據類型不匹配的新聞記錄,該消噪模塊62可用于執行上述第二實施例中的方法1,此處不再贅述。第二消噪模塊64用于判斷新聞數據集中的新聞記錄的標題與正文是否一致,并刪除新聞數據集中標題與正文不一致的新聞記錄,該消噪模塊64在判斷新聞紀錄的標題與正文是否一致時,首先對新聞記錄的標題進行分詞,得到由一個或多個詞元組成的詞元組,然后統計該詞元組中各詞元在該新聞記錄的正文中出現次數的和;再判斷統計得到的和是否大于預設閾值,如果統計得到的和大于預設閾值時,確定該新聞記錄的標題與正文一致。第一提取單元10用于提取消噪后的新聞數據集中的新聞簇,該提取單元10在提取新聞簇時,首先計算新聞數據集中各新聞記錄之間的相似度,將相似度較高的新聞紀錄組成新聞簇。第一計算模塊12用于計算新聞數據集中兩個新聞記錄之間的相似度。具體地,第一計算模塊包括特征化子模塊和計算子模塊。特征化子模塊用于將兩個新聞記錄分別進行特征化提取,得到每個新聞記錄對應的向量。在對一個新聞紀錄A進行特征化提取時,首先對該新聞記錄A的標題和正文進行分詞,得到由多個詞元組成的詞元集{w1,w2,w3,...,wn};然后根據詞元在該新聞記錄A中出現的次數計算該詞元集中詞元對應的特征值;再刪除詞元集中特征值小于預設閾值的詞元;最后根據刪除后的詞元及其對應的特征值生成該新聞記錄的向量:X=(<w1,c1>,<w2,c2>,<w3,c3>,...,<wn,cn>), 其中,c1,c2,c3,...,cn分別為詞元對應的特征值,n為詞元集中詞元的個數。其中,特征化子模塊在計算詞元對應的特征值時,可采用如下的公式:ci=a1+a2*T+a3*P+a4*K其中,ci為詞元集{w1,w2,w3,...,wn}中第i個詞元wi對應的特征值,a1為該詞元wi在該新聞記錄A中出現的次數,a2為該詞元wi在新聞記錄A的標題中出現的次數,a3為該詞元wi在新聞記錄A的段首或段尾中出現的次數,a4為該詞元wi在新聞記錄A的關鍵句中出現的次數,T、P、K均為無量綱參數。計算子模塊用于采用上述的余弦值相似度計算法、曼哈頓距離相似度計算法或歐幾里得距離相似度計算法計算兩個新聞紀錄之間的相似度,此處不再贅述。判斷模塊14用于判斷相似度是否大于一個預設閾值,當相似度大于該預設閾值時,第一確定模塊16確定兩個新聞記錄屬于同一新聞簇。確定單元20用于確定熱點新聞簇,具體地,第四計算模塊22采用以下公式計算各個新聞簇的熱度值:Cluster_Hot_Value=Site_Count*Site_Rate+Publish_Count*Publish_Rate其中,Cluster_Hot_Value為一個新聞簇熱度值,Site_Count為該新聞簇中包含的網站個數,Site_Rate為曝光率權重,Publish_Count為新聞的發布量,Publish_Rate為發布率權重,且Site_Rate+Publish_Rate=1。第三確定模塊24用于根據各個新聞簇的熱度值確定熱點新聞簇。第二提取單元30用于提取熱點新聞簇中各新聞記錄對應的向量中的詞元作為關鍵字,第一生成單元40與上述第四實施例中的第一生成單元40相同,此處不再贅述。第二生成單元50中的第二計算模塊52用于針對熱點新聞簇的各新聞記錄,計算每個新聞記錄對應的組合詞的特征值,其中,一個組合詞的特征值為該組合詞中各詞元對應的特征值的和。第三計算模塊54用于采用以下公式計算某熱點新聞簇中第j個新聞中的一個組合詞的熱度值:其中,Term_hot_value為該組合詞的熱度值,N為該熱點新聞簇包括的 新聞記錄的個數,M為該第j個新聞記錄對應的組合詞的個數,n為該熱點新聞簇中具有該組合詞的新聞記錄個數,Term_Countji為第j個新聞記錄對應的第i個組合詞的特征值。第二確定模塊56用于確定熱度值大于預設熱度值的組合詞為新聞熱點標簽。圖6是根據本發明第六實施例的新聞熱點標簽的生成系統的工作流程示意圖,該系統最大的特點是對新聞紀錄進行了結構化分析,針對詞元在新聞紀錄中出現的位置給予不同程度的線性加權;并且考慮了詞元的基本語義信息,對詞元的詞性和同義詞進行分析,從而使得新聞熱點標簽的提取結果更加準確;基于多文檔的標簽提取,與基于單一文檔的標簽提取方法相比,充分考慮了多個新聞紀錄同時分析時對標簽提取的影響。具體地,如圖6所示,該系統主要包含數據清理模塊、特征化提取模塊、熱點新聞聚焦模塊和熱點標簽發現模塊四個模塊。其中,數據清理模塊相當于上述各實施例中的消噪單元。由于現實情況下數據是存在噪音的,因此該模塊的主要功能便是針對數據源中不合理數據進行數據清理,保留有效數據,過濾無效數據。特征化提取模塊是源數據的一般特性進行匯總,特征化后的數據既能清晰地代表源數據,又能在分析時對源數據進行有效降維,從而提高后續算法的執行效率,經過該特征化提取模塊,可獲得每個新聞紀錄對應的向量。該特征化提取模塊相當于上述各實施例中的特征化子模塊。熱點新聞聚焦模塊的主要功能是從海量的新聞數據集中提煉新聞簇,每一個新聞簇都是由一群內容相似的新聞組成,而不同的新聞簇之間的新聞高度相異。然后根據新聞簇的熱度值進行排序,提取排名靠前的新聞簇作為熱點新聞簇。熱點標簽發現模塊的主要功能即在上述各模塊的基礎上,對熱點新聞簇進行分析,通過多文檔關鍵字抽取技術提煉出這些熱點新聞簇的各新聞紀錄中的的關鍵字,然后根據關鍵字生成組合詞,最后根據組合詞熱度值進行排序,提取排名靠前的組合詞作為熱點新聞標簽。具體地,如圖7所示,數據清理模塊的工作流程如下:1)從數據源中獲得新聞數據集,每條新聞記錄由<新聞標題,新聞內容,發布網站,發布時間,新聞鏈接>五部分內容組成;2)讀取系統和用戶定義的問題數據類型,將每條新聞記錄進行匹配,從而篩選出有問題的數據。該系統默認提供缺失值和格式不一致兩種問題數據類型。缺失值類型是指該條新聞記錄某部分內容為空的情況;格式不一致類型是指新聞記錄某部分內容的數據格式和標準數據格式不一致情況。3)發現問題數據后,選擇問題數據處理方式,本系統提供兩種默認忽略元組處理法和默認缺失值處理法兩種處理方式。在忽略元組處理法中,如果新聞記錄的某部分內容為問題數據,則將整條新聞記錄忽略不考慮;在默認缺失值處理法,如果新聞記錄的某部分內容為問題數據,則將該部分內容用一個默認的常量代替。4)將上述步驟處理后所得到的新聞紀錄進行標題與正文一致性判斷,其目的是清理掉那些標題與正文不符的無效新聞,具體的一致性判斷方法上文已做詳細描述,此處不再贅述。5)將標題內容不一致的新聞記錄采用上述的忽略元組法進行處理,最終完成數據清理流程。如圖8所示,征化提取模塊為整個系統的數據預處理環節,特征化后的結果將為后續處理做數據準備,特征化提取模塊的工作流程如下:1)對新聞紀錄的標題和正文進行分詞,將新聞紀錄轉化為形如{w1,w2,w3,...,wn}的詞元集;2)分析詞性,將詞元集中的連詞、方位詞、區別詞、嘆詞、擬聲詞、介詞、量詞、代詞、助詞、語氣詞、狀態詞等無效詞性過濾;3)掃描過濾后的詞元集,并按下列方式進行詞元統計,為每個詞元設置一個相應的計數器,并初始化賦值為1,此后該詞元每出現一次就在其相應的計數器中加1,以<w,c>形式保存,其中w表示詞元,c表示計數器(計數器中的值為詞元對應的特征值);如果詞元在標題位置中出現,那么在相應的計數器中額外加整數T;如果詞元在段首或段尾出現,那么在相應的計數器中額外加整數P;判斷詞元是否在“關鍵句”中出現,所謂“關鍵句”是指例如那些包含諸如“關鍵是…”、“旨在…”、“總之…”等的句子。對在“關鍵句”中 出現的詞元,再在相應的計數器中額外加整數K。4)同義詞處理,如果多個詞元之間互為同義詞,那么選擇計數器的計分最高者,保留該詞元和相應計數器,然后把其它同義詞的計數器計分全部加入該計數器中;5)歸一化處理是將同義詞處理后所有詞元的計數器計分相加得到和S,然后每個計數器的計分除以S再放入計數器,此時每個計數器計分將是一個大于0小于1的值;6)閾值判斷先設定閾值λ,過濾計數器計分小于λ的詞元,保留計數器積分大于或等于λ的詞元,此時每條新聞記錄可表示成向量:X=(<w1,c1>,<w2,c2>,<w3,c3>,...,<wn,cn>),其中λ≤ci。熱點新聞聚焦模塊是在上述特征化提取模塊的基礎上,將內容相似的新聞聚集成簇,并計算新聞簇熱度值,最后提取出熱點新聞事件。如圖9所示,熱點新聞聚焦模塊的工作流程如下:1)新聞簇初始化:首先掃描所有的特征化后的新聞記錄,并將每個新聞對象作為一個初始簇;2)計算兩個新聞紀錄之間的相似度,可采用上述三種方法中的任一種。3)判斷相似度是否大于閾值,如果大于,則認為兩篇新聞紀錄的內容是相似的,將其合并成簇,否則繼續計算與下一篇新聞之間的相似度;4)計算新聞簇熱度值,具體計算方法上文已做詳細描述,此處不再贅述。5)最后將所有的新聞簇按照熱度值從高到低進行排序,抽取前幾位的新聞簇作為熱點新聞簇。如圖10所示,熱點標簽發現模塊的工作流程如下:1)讀取熱點新聞簇中的新聞記錄,針對每篇新聞記錄,進行分詞、過濾無效詞性、詞元統計和同義詞處理,其處理流程和特征化提取模塊中對應的流程一致,在此不再重復;2)組合詞生成:由于單一詞元所表示的信息量有限,因此需要將相鄰的詞元結合起來形成組合詞,從而擴充其信息量。3)計算所有組合詞的熱度值,具體計算方法上文已做詳細描述,此處不再贅述。4)最后將熱點新聞簇中的所有組合詞按照熱度值從高到低進行排序,抽取前幾位的即為新聞熱點標簽。從以上的描述中,可以看出,本發明實施例實現了如下技術效果:提高了獲取新聞熱點標簽的準確性。以上,僅為本發明較佳的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉該技術的人在本發明所揭露的技術范圍內,可輕易想到的變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應該以權利要求的保護范圍為準。
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1