一種機床溫度敏感點選取與熱誤差建模方法
本發明涉及數控機床,具體涉及一種機床溫度敏感點選取與熱誤差建模方法。
背景技術:
1、影響機床加工精度的主要因素是幾何誤差、熱誤差、力誤差、其他誤差等,其中,熱誤差占機床總誤差達到了40%-70%。熱誤差是機床內部溫度場分布不均勻引起的時變非線性變量。由于機床運動,工況的不斷變化,機床的溫度場也在實時變化,熱變形相對于溫度的變化存在時滯性,這導致熱誤差的變化具有非線性,這也是熱誤差難以預測的原因。
2、熱誤差模型反映了溫度變量與熱變形之間的非線性關系。準確可靠的熱誤差模型可以預測機床的熱誤差,通過補償提高機床的加工精度和穩定性,提高生產效率。熱誤差建模主要分為篩選溫度敏感點和建立熱誤差模型。溫度敏感點的選擇是熱誤差建模的先決條件。傳統方法是通過歐幾里得距離矩陣計算溫度點的相似度進行聚類分析,篩選溫度敏感點。相似度計算方法都是按照相同采樣時刻的溫度數據進行計算,存在時間上的嚴格對齊性。然而,由于數控機床熱源的熱量向外擴散需要時間,靠采樣獲得的溫度數據時間序列雖然具有相似的變化趨勢,但會存在相位上的差異,這影響聚類的準確性。人工神經網絡已經被應用于熱誤差建模中,但是傳統的bp神經網絡收斂速度慢,對初始值敏感,且容易產生震蕩影響穩定性,同時容易陷入局部最優解,影響bp神經網絡的性能。
技術實現思路
1、本發明的目的是為克服現有技術的不足之處,提供一種可減少溫度數據相位差異的影響、優化機床溫度敏感點選擇、加快模型的收斂速度和減少建模的精度損失的機床溫度敏感點選取與熱誤差建模方法。
2、本發明的上述目的通過以下技術方案來實現:
3、一種機床溫度敏感點選取與熱誤差建模方法,其特征在于,包括如下步驟:
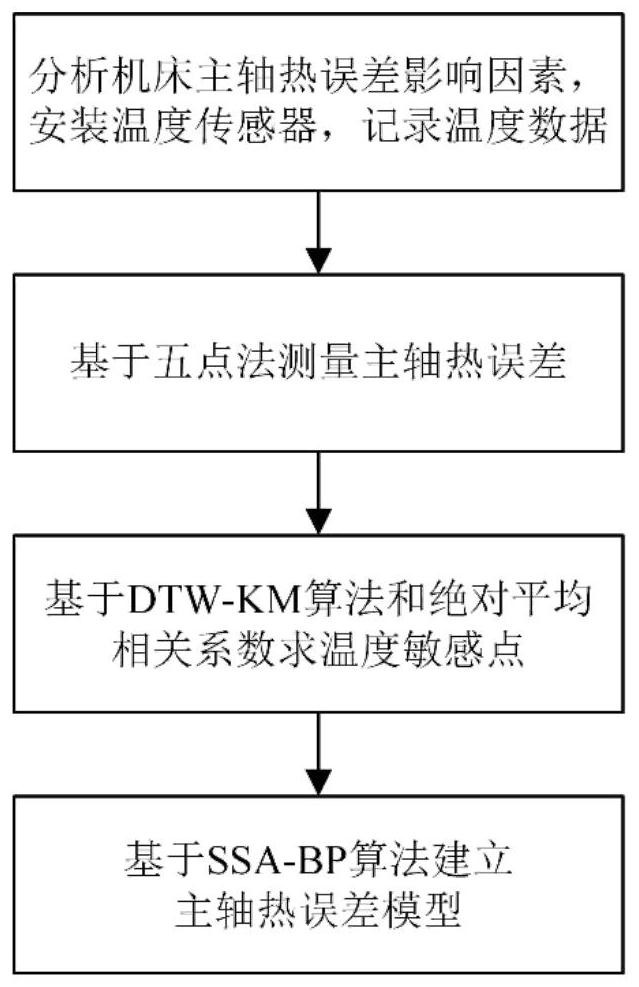
4、步驟1、分析機床的主要熱源分布,在主軸箱周圍放置多個溫度傳感器,記錄溫度數據,用于篩選溫度敏感點;
5、步驟2、基于五點法,利用電渦流位移傳感器測量主軸的熱誤差;
6、步驟3、基于dtw-km算法,對步驟1測得的溫度數據進行聚類分析,采用“肘部法”確定聚類數量,通過凝聚度和dunn指數選擇聚類結果,利用絕對平均相關系數,在每一個類別中選擇一個溫度點作為溫度敏感點;
7、步驟4、基于ssa-bp算法,利用步驟1測得的數據構建的溫度敏感點的溫度數據集作為輸入,利用步驟2測得的主軸熱誤差數據構建的熱誤差數據集作為輸出,訓練模型,建立溫度與熱誤差的映射關系。
8、而且,所述步驟3中的選擇溫度敏感點,具體包括:
9、步驟3.1、確定聚類數量k的取值范圍[k1,k2];
10、步驟3.2、基于高斯濾波算法優化溫度數據和熱誤差數據;
11、步驟3.3、在溫度數據集中,隨機選擇一個溫度監測點的數據,作為第一個聚類中心,對于每個溫度監測點,計算其與當前已選擇聚類中心的距離:
12、
13、其中,xi表示被選擇的溫度監測點x的第i個數據,ci表示聚類中心c的第i個數據;
14、步驟3.4、計算每個溫度點被選擇為下一個聚類中心的概率,其到當前已被選擇為聚類中心的溫度點之間的距離平方和成正比,基于概率選擇下一個聚類中心,概率計算如下:
15、
16、其中,pi表示第i個溫度點的概率,di表示第i個溫度點到聚類中心距離的平方和;
17、步驟3.5、重復步驟3.4,直到選擇出k個聚類中心為止;
18、步驟3.6、構建距離矩陣:利用歐氏距離計算任意兩個溫度變量x和y在每個時間點之間的距離,組成一個m×n的距離矩陣d,即
19、
20、其中,xi表示被選擇的溫度變量x的第i個數據,yi表示被選擇的溫度變量y的第j個數據;
21、步驟3.7、在距離矩陣d中尋找最佳匹配路徑,使得路徑上的累積距離最小,累計距離矩陣的右下角的元素γ(m,n)為最佳路徑的最小累計距離,以此作為相似度;
22、步驟3.8、根據相似度,把溫度點劃分入不同的簇,根據新劃分的簇,計算新的中心;
23、步驟3.9、重復步驟3.6-3.8,如果聚類中心保持不變,則進入步驟3.10;
24、步驟3.10、計算凝聚度和dunn指數,綜合判斷,得到最佳的聚類結果;凝聚計算公式如下
25、
26、其中,ci代表第i個簇的中心點;xj代表第j個溫度點;sse數值越小,類內聚集程度越好。dunn指數定義為:
27、
28、其中,dmin(ci,cj)表示簇ci與簇cj之間最近溫度點之間的距離;diam(c)表示簇c內溫度點間的最遠距離;
29、步驟3.11、繪制肘部圖,得到求出最佳k值;
30、步驟3.12、利用相關分析,選擇溫度敏感點。
31、而且,所述步驟4中的ssa-bp算法,具體如下:
32、步驟4.1、確定ssa-bp算法的基礎參數,如麻雀數量,發現者、更隨者和警覺者的占比,最大迭代次數等;
33、步驟4.2、導入溫度敏感點和熱誤差數據;
34、步驟4.3、對溫度數據和熱誤差數據進行歸一化;
35、步驟4.4、初始化麻雀種群位置和適應度,適應度表示為:
36、
37、其中,n表示麻雀的數量;d表示需要被優化的參數數量;f中的每一行代表一只麻雀的適應度值;
38、步驟4.5、適應度較高的麻雀將承擔發現者,根據以下公式更新其位置:
39、
40、式中,表示第i只麻雀在迭代t次時第j維度的值,j=1,2,…,d;α∈(0,1]是一個隨機數;itermax表示最大迭代次數;r2∈[0,1]是一個隨機數,表示報警值;st∈[0.5,1]是一個隨機數,表示安全閾值;q是服從正態分布的隨機數;l是一個所有元素都為1的1×d向量;
41、步驟4.6、跟隨者位置更新公式如下:
42、
43、式中,表示當前迭代時發現者所占據的最佳位置;a表示1×d的矩陣,它的每一個元素隨機賦值1或者-1,a+=at(aat)-1;表示上一次迭代中,適應度最差的麻雀位置;
44、步驟4.7、隨機從種群中挑選少數麻雀充當警覺者作為意識到危險的麻雀,警覺者的位置更新公式如下:
45、
46、式中,β是步長控制參數,它服從均值為0、方差為1的正態分布的隨機數;k∈[-1,1]是一個隨機數;fi表示當麻雀的適應度;fw和fg分別代表在當前迭代中所有麻雀中的最差和最佳適應度值,ε是一個較小的常數,避免除數為0;
47、步驟4.8、計算適應度,將麻雀的參數帶入bp神經網絡中的權值w和閾值b,bp網絡正向傳播,計算測量值和計算值的方差,即適應度值;
48、步驟4.9、更新麻雀種群參數,若同一只麻雀在當前迭代中的適應度值較上一次迭代下降,則記錄其當前位置參數信息;
49、步驟4.10、重復步驟4.5-4.9,并標記最佳適應度值的麻雀;
50、步驟4.11、經過最大迭代次數或者適應度值低于設定值,則停止迭代,最佳適應度值的麻雀位置參數即為bp神經網絡的代求的相關參數。
51、本發明具有的優點和積極效果為:
52、本發明提出基于dtw-km算法和絕對相關平均系數選擇溫度敏感點,采用動態時間規整衡量溫度變量之間的相似度,以替代傳統k均值聚類中的歐氏距離,該方法可減弱由溫度傳遞的滯后效應而導致的溫度數據序列相位差異對聚類結果的影響,提高對數據趨勢變化的識別準確性,并能更準確地比較不同數據之間的相似性。此外,針對傳統k均值聚類算法中k值無法確定、聚類結果對初值敏感以及聚類結果存在多樣性等問題,本發明采用“肘部法”確定聚類數量k,引入加權概率分布選擇初始中心,并通過凝聚度和dunn指數選擇聚類結果,優化機床溫度敏感點選擇,提高聚類結果的穩定性。針對熱誤差建模,bp神經網絡收斂速度慢,容易陷入局部最優,影響bp神經網絡的性能。本發明采用麻雀搜索算法優化bp神經網絡的權值和閾值,加快了模型的收斂速度,減少了建模的精度損失。
- 還沒有人留言評論。精彩留言會獲得點贊!