一種基于行為的多水下機器人路徑規劃方法與流程
本發明涉及一種基于行為的多水下機器人路徑規劃方法,是一種基于行為的多水下機器人協同信息采集的路徑規劃方法。
背景技術:
多水下機器人(multipleautonomousunderwatervehicles,簡稱mauv)是指由多個相對比較簡單的同構或異構的auv通過某種形式的協同合作,最終可以共同完成特定的比較復雜的作業任務的系統。多水下機器人的并行性可以顯著提高auv工作性能,縮短任務時間,并且通過系統中不同個體的協調來增加成功完成任務的可能性。此外,多水下機器人系統相比于單水下機器人具有效率更高、成本更低、靈活性高、魯棒性強等優點。
發揮多水下機器人協作優勢的關鍵是在系統中每個auv都被分配明確任務的前提下,通過既定的規劃和控制策略,組成一個使不同auv自身進行作業任務的同時還能夠兼顧與其他auv合作和協調的團隊,通過發揮團隊意識和協作精神最終完成復雜的任務。對于數據收集任務,auv需要安全地靠近分布在海洋中的節點進而通訊獲得數據。在水下海洋環境中,為了自主完成數據收集任務,對于多水下機器人系統來說,有效的路徑規劃策略是非常有必要的。傳統的多水下機器人路徑規劃方法大多只考慮auv執行任務時,不與其它auv發生碰撞,并未考慮auv與其他成員可能失去聯系,從而不能完成協同任務。
本發明提出了一種適用于動態未知環境下基于行為的多水下機器人路徑規劃策略,通過定義基本行為來對auv的航行路徑添加約束,之后建立行為目標函數和全局目標函數來解決協同信息采集過程中的安全和協作問題。本發明采用一種帶有慣性權重的粒子群優化算法來求解全局目標函數,通過輸出的最優解可以生成一條免于碰撞并且是最短的路徑。
技術實現要素:
本發明的目的是為了提供一種在保證多個水下機器人協同完成數據收集任務的同時,使用最少的能耗的安全的路徑規劃算法。
本發明的目的是這樣實現的:(1)定義3個基本行為用來約束auv的運動,保證在安全的前提下,auv的航行距離最短,并且實現與其它auv的協同;
(2)行為目標函數與基本行為對應,是基本行為的具體數學化,定義在auv的決策空間中,并要保證函數的收斂性;
(3)全局目標函數考慮到了3個基本行為的綜合影響,利用帶有慣性權重的粒子群優化算法來求解不同時刻全局目標函數的最優解,不同時刻全局目標函數的最優解組成auv的路徑軌跡。
本發明還包括這樣一些結構特征:
1.所述3個基本行為的目標函數具體為:
路徑規劃的環境設置為二維平面,u為t時刻auv的速度大小,θ為當前的艏向角,(xt,yt)為該時刻的位置坐標,δt為時間間隔,auv的決策輸出包括速度和艏向角,假設(fx,fy)為下一時刻auv的位置坐標,得到:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
a、節能目標函數f1(θ,u,t)為:
其中:(xs,ys)為目標點的位置坐標,d1為下一時刻auv與目標點間的歐氏距離,s1和s2是放縮系數;
b、協同目標函數f2(θ,u,t)為:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
其中:(fbx,fby)為與該auv距離最近的auv下一時刻的位置,d2為下一時刻的兩個auv的歐氏距離,[dmin,dmax]為d2的期望取值范圍,s1和s2是放縮系數,m2為設定的常值;
c、安全行為目標函數f3(θ,u,t)為:
其中:(xo,yo)為障礙物點的位置坐標,d3為auv與障礙物下一時刻的歐氏距離,ds為距離d3的安全閾值,m3為設定的常值。
2.所述建立并求解全局目標函數的過程如下:
全局目標函數具體的形式為:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中:ω1,ω2,ω3是可變化的權重系數,將3種行為按照相對重要程度排序為安全行為、協同行為和節能行為,并設置3個權重系數,全局目標函數中具有2個空間變量θ和u、1個時間變量t;
在t時刻,利用帶有慣性權重的粒子群優化算法,得到全局目標函數的最優解的具體步驟如下:
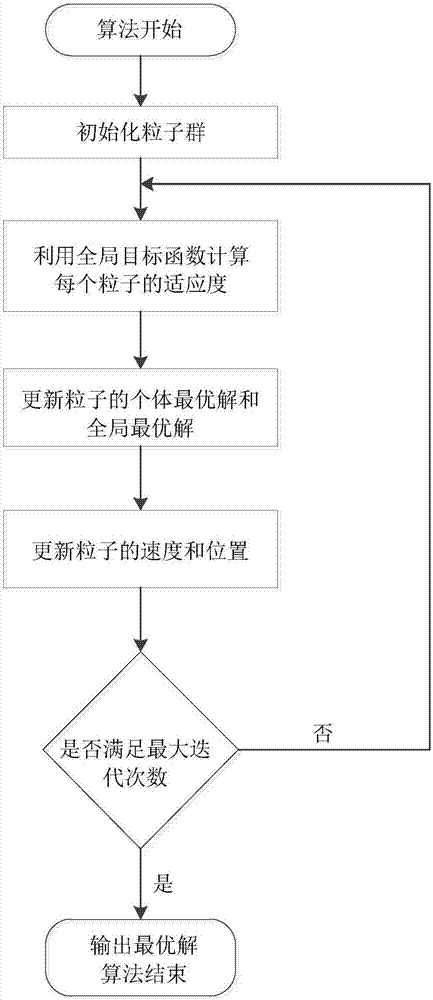
步驟1:利用帶有慣性權重的粒子群優化算法求解生成的全局目標函數,算法開始;
步驟2:初始化帶有慣性權重的粒子群優化算法參數,包括設置搜索空間為二維空間,其中姿態角空間取值范圍為[θ0-θmax,θ0+θmax],速度空間取值范圍為[0,umax],其中:θ0為auv當前時刻姿態角,θmax為auv最大轉角能力,umax為auv的最大航行速度;群體規模為n,設置各個粒子的初始位置和速度;
步驟3:利用全局目標函數作為適應度函數,計算每個粒子的適應度;
步驟4:更新粒子的個體最優解和全局最優解:
每個粒子所處的位置都表示二維解空間中的一個解,解的質量由適應值決定,某一粒子i在二維空間的位置表示為矢量xi=(θi,ui),粒子通過不斷調整自己的位置來搜索新解,每個粒子都能記住自己搜索到的最優解,記作pid;以及整個粒子群經歷過的最好的位置,即目前搜索到的最優解,記作pgd;
步驟5:更新粒子的位置和速度:
粒子具有飛行速度,飛行速度可以表示為矢量
其中,vik+1表示第i個粒子在k+1次迭代中的速度,c0為慣性權重,c1和c2為加速常數,rand()為0到1之間的隨機數;
對于慣性權重c0,利用先增后減慣性權重的慣性權重確定方法為:
式中,maxnumber為算法的最大迭代次數。
步驟6:判斷是否已經達到最大迭代次數,如果達到最大迭代次數,輸出最優解,算法結束;否則,算法的迭代次數加1,返回步驟3。
3.所述計算每個粒子的適應度是指得到每個粒子的適應值,每個粒子都有一個由目標函數決定的適應值,適應值直接設置為全局目標函數f(θ,u,t)。
與現有技術相比,本發明的有益效果是:本發明定義了auv的3種基本行為,包括節能行為、安全行為和協同行為,并建立了基本行為相對應的局部目標函數,從而來約束auv的航行,并可以實現與其它auv協同航行的目的。最后建立全局目標函數,并利用帶有慣性權重的粒子群優化算法進行求解,通過利用先增后減慣性權重的慣性權重確定方法,比一般的粒子群優化算法具有更快的收斂能力和更好的局部收斂速度。
附圖說明
圖1是本發明提出的多水下機器人路徑規劃方法示意圖;
圖2是本發明中的粒子群優化算法的流程示意圖;
圖3是本發明中auv在時間和空間運動示意圖;
圖4是本發明中粒子位置改變的示意圖。
具體實施方式
下面結合附圖與具體實施方式對本發明作進一步詳細描述。
一種基于行為的多水下機器人路徑規劃方法,包括:
1、定義3個基本行為用來約束auv的運動,保證在安全的前提下,auv的航行距離最短,并且實現與其它auv的協同。
2、行為目標函數與基本行為對應,是基本行為的具體數學化,定義在auv的決策空間中,并要保證函數的收斂性。
3、全局目標函數考慮到了3個基本行為的綜合影響,利用帶有慣性權重的粒子群優化算法來求解不同時刻全局目標函數的最優解,不同時刻全局目標函數的最優解組成auv的路徑軌跡,
所述3個行為目標函數具體為:
路徑規劃的環境設置為二維平面,u為t時刻auv的速度大小,θ為當前的艏向角,(xt,yt)為該時刻的位置坐標,δt為時間間隔,auv的決策輸出包括速度和艏向角。假設(fx,fy)為下一時刻auv的位置坐標,可以得到下式:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
1)節能目標函數可以表示為:
(xs,ys)為目標點的位置坐標為,d1為下一時刻auv與目標點間的歐氏距離。其中s1和s2是放縮系數。
2)協同目標函數可以表示為:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
(fbx,fby)為與該auv距離最近的auv下一時刻的位置,d2為下一時刻的兩個auv的歐氏距離,[dmin,dmax]為d2的期望取值范圍,s1和s2是放縮系數,m2為設定的常值。
3)安全行為目標函數可以表示如下:
(xo,yo)為障礙物點的位置坐標,d3為auv與障礙物下一時刻的歐氏距離,ds為距離d3的安全閾值,m3為設定的常值。
所述建立并求解全局目標函數的過程如下:
全局目標函數具體的形式如下式所示:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中,ω1,ω2,ω3是可變化的權重系數。將3種行為按照相對重要程度排序為安全行為、協同行為和節能行為,按照這個原則來設置3個權重系數。全局目標函數中具有2個空間變量θ和u,1個時間變量t。
在t時刻,下面利用帶有慣性權重的粒子群優化算法,來求全局目標函數的最優解,具體步驟如下:
步驟1:利用帶有慣性權重的粒子群優化算法求解生成的全局目標函數,算法開始;
步驟2:初始化帶有慣性權重的粒子群優化算法參數,包括設置搜索空間為二維空間,其中姿態角空間取值范圍為[θ0-θmax,θ0+θmax],速度空間取值范圍為[0,umax],這里θ0為auv當前時刻姿態角,θmax為auv最大轉角能力,umax為auv的最大航行速度;群體規模為n,設置各個粒子的初始位置和速度;
步驟3:利用全局目標函數作為適應度函數,計算每個粒子的適應度。每個粒子都有一個由目標函數決定的適應值(fitnessvalue),這里適應值可以直接設置為全局目標函數f(θ,u,t);
步驟4:更新粒子的個體最優解和全局最優解。每個粒子所處的位置都表示二維解空間中的一個解,解的質量由適應值決定,適應度越大,解的質量越好。某一粒子i在二維空間的位置表示為矢量xi=(θi,ui),粒子通過不斷調整自己的位置來搜索新解,每個粒子都能記住自己搜索到的最優解,記作pid;以及整個粒子群經歷過的最好的位置,即目前搜索到的最優解,記作pgd;
步驟5:更新粒子的位置和速度。粒子具有飛行速度,從而可以調整自己的位置。飛行速度可以表示為矢量
其中,vik+1表示第i個粒子在k+1次迭代中的速度,c0為慣性權重,c1和c2為加速常數,rand()為0到1之間的隨機數;
對于慣性權重c0,利用先增后減慣性權重的慣性權重確定方法,該方法在迭代的初期,具有較快的收斂速度;在迭代的后期,具有較好的局部搜索能力,具體方法如下式所示:
式中,maxnumber為算法的最大迭代次數。
步驟6:判斷是否已經達到最大迭代次數,如果達到最大迭代次數,輸出最優解,算法結束。否則,算法的迭代次數加1,返回步驟3。
下面結合附圖對本發明進行詳細描述:
如圖1所示,本發明提出的一種基于行為的多水下機器人路徑規劃方法,主要包含以下部分:3個基本行為,分別是節能行為、協同行為和安全行為;與3個基本行為對應的行為目標函數;通過3個行為目標函數生成的全局目標函數,并對全局目標函數進行求解。3個基本行為用來約束auv的運動,保證在安全的前提下,auv的航行距離最短,并且實現與其它auv的協同。行為目標函數分別是對應3個基本行為的具體數學化,行為目標函數需要定義在auv的決策空間中,并要保證函數的收斂性。全局目標函數考慮到了3個基本行為的綜合影響,不同時刻全局目標函數的最優解組成auv的路徑軌跡,本發明利用帶有慣性權重的粒子群優化算法來求解不同時刻全局目標函數的最優解。
(1)所述的基本行為通過以下方式定義:
路徑規劃的環境設置為二維平面,建立環境地圖的全局坐標系o-xy。如圖1所示,當auv獲取需要的周圍環境信息后,這些信息包括目標點的位置,其它auv的位置速度大小和艏向角,以及障礙物位置信息。在這里,u為t時刻auv的速度大小,θ為當前的艏向角,(xt,yt)為該時刻的位置坐標,δt為時間間隔,auv的決策輸出包括速度和艏向角,如圖3所示為auv在時間和空間上的運動示意圖。
假設(fx,fy)為下一時刻auv的位置坐標,可以表示為下式:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
1.1)節能行為
考慮到auv工作時的能源有限,為了簡化問題,本發明只考慮航行距離的影響,并且認為,航行距離越短,節能性越好。為了定義節能行為,可以對auv的航行條件添加一些約束,并把約束條件定為auv與目標點的距離。
d1為下一時刻auv與目標點間的歐氏距離,節能行為在整個任務過程中一直處于激活狀態。將auv與目標點的距離對應到具體的決策空間,利用auv的姿態角、速度以及時間變量可以將d1表示如下:
d1=d1(θ,u,t)
1.2)協同行為
考慮到實際水下傳感器以及通訊手段的限制,在保證安全的前提下,協同行為要求的數學形式可以表示如下:
dmin<d2<dmax
d2為下一時刻的兩個auv的歐氏距離,[dmin,dmax]為d2的期望取值范圍。以上述公式為協同行為處于激活狀態的條件,利用auv的姿態角、速度以及時間變量可以將d2表示如下:
d2=d2(θ,u,t)
1.3)安全行為
安全行為的數學形式可以表示如下式:
d3>dmin
d3為auv與障礙物下一時刻的歐氏距離,ds為距離d3的安全閾值。利用auv的姿態角、速度以及時間變量可以將d3表示如下式:
d3=d3(θ,u,t)
(2)建立局部目標函數:
2.1)節能目標函數
與節能行為相對應,節能目標函數的變量是auv與目標點的距離d1。對于節能目標函數來說,d1的值越小,說明auv越接近目標點。在時間間隔δt確定時,距離d1與auv速度和艏向角有關。對d1進行度量處理,得到節能性的目標函數具體形式如下式:
式中s1和s2是放縮系數。
2.2)協同目標函數
與協同行為對應,協同目標函數的變量值是auv與其他成員的距離,在執行任務的過程中,各個auv之間應該保持協同作業,這里表現為auv與系統中最近的成員距離要處于一個閾值[dmin,dmax]范圍內。最終的協同目標函數如下式所示:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
(fbx,fby)為與該auv距離最近的auv下一時刻的位置,d2為下一時刻的兩個auv的歐氏距離,[dmin,dmax]為d2的期望取值范圍,s1和s2是放縮系數,m2為設定的常值。
2.3)安全目標函數
安全行為的激活需要滿足一定的限制條件,具體體現為auv與障礙物的距離閾值ds。最終的安全行為目標函數如下式所示:
(xo,yo)為障礙物點的位置坐標,d3為auv與障礙物下一時刻的歐氏距離,ds為距離d3的安全閾值,m3為設定的常值。
(3)所述的全局目標函數建立方法和求解過程如下:
全局目標函數的作用是實現之前一系列基本行為的協調,全局目標函數具體的形式如下式所示:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中,ω1,ω2,ω3是可變化的權重系數。將3種行為按照相對重要程度排序為安全行為、協同行為和節能行為,按照這個原則來設置3個權重系數。全局目標函數中具有2個空間變量θ和u,1個時間變量t。
在t時刻,利用帶有慣性權重的粒子群優化算法,來求全局目標函數的最優解,函數輸出為空間變量θ和u。如圖2所示,具體步驟如下:
步驟1:利用帶有慣性權重的粒子群優化算法求解生成的全局目標函數,算法開始;
步驟2:初始化帶有慣性權重的粒子群優化算法參數,包括設置搜索空間為二維空間,其中姿態角空間取值范圍為[θ0-θmax,θ0+θmax],速度空間取值范圍為[0,umax],這里θ0為auv當前時刻姿態角,θmax為auv最大轉角能力,umax為auv的最大航行速度;群體規模為n,設置各個粒子的初始位置和速度。
步驟3:利用全局目標函數作為適應度函數,計算每個粒子的適應度。每個粒子都有一個由目標函數決定的適應值(fitnessvalue),這里適應值設置為全局目標函數f(θ,u,t)。
步驟4:更新粒子的個體最優解和全局最優解。每個粒子所處的位置都表示二維解空間中的一個解,解的質量由適應值決定,適應度越大,解的質量越好。某一粒子i在二維空間的位置表示為矢量xi=(θi,ui),粒子通過不斷調整自己的位置來搜索新解,每個粒子都能記住自己搜索到的最優解,記作pid;以及整個粒子群經歷過的最好的位置,即目前搜索到的最優解,記作pgd。
步驟5:更新粒子的位置和速度。粒子具有飛行速度,從而可以調整自己的位置。飛行速度可以表示為矢量
式中,vik+1表示第i個粒子在k+1次迭代中的速度,c0為慣性權重,c1和c2為加速常數,rand()為0到1之間的隨機數。
對于慣性權重c0,利用先增后減慣性權重的慣性權重確定方法,該方法在迭代的初期,具有較快的收斂速度;在迭代的后期,具有較好的局部搜索能力,具體方法如下式所示:
式中,maxnumber為算法的最大迭代次數。
步驟6:判斷是否已經達到最大迭代次數,如果達到最大迭代次數,輸出最優解,算法結束。否則,算法的迭代次數加1,返回步驟3。
當算法達到最大迭代次數時便會終止;此時輸出最優解,即整個粒子群經歷過的最好的位置pgd,該位置對應的矢量xi=(θi,ui)代表auv在時刻t應該輸出的姿態角和速度。最后,利用不同時刻粒子群優化算法輸出的最優解對應的姿態角和速度,可以生成auv最后的路徑。
(1)定義基本行為:
路徑規劃的環境設置為二維平面,建立環境地圖的全局坐標系o-xy。當auv獲取需要的周圍環境信息后,這些信息包括目標點的位置,其它auv的位置速度大小和艏向角,以及障礙物位置信息。在這里,u為auv的速度大小,θ為艏向角,(xt,yt)為t時刻的位置坐標,δt為時間間隔,auv的決策輸出包括速度和艏向角。
假設(fx,fy)為下一時刻auv的位置坐標,可以表示為下式:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
1.1)節能行為
考慮到auv工作時的能源有限,為了簡化問題,本發明只考慮航行距離的影響,并且認為,航行距離越短,節能性越好。為了定義節能行為,可以對auv的航行條件添加一些約束,并把約束條件定為auv與目標點的距離。d1為下一時刻auv與目標點間的歐氏距離,節能行為在整個任務過程中一直處于激活狀態。將auv與目標點的距離對應到具體的決策空間,利用auv的姿態角、速度以及時間變量可以將d1表示如下:
d1=d1(θ,u,t)
1.2)考慮到實際水下傳感器以及通訊手段的限制,在保證安全的前提下,協同行為要求的數學形式可以表示如下:
dmin<d2<dmax
d2為下一時刻的兩個auv的歐氏距離,[dmin,dmax]為d2的期望取值范圍。以上述公式為協同行為處于激活狀態的條件,利用auv的姿態角、速度以及時間變量可以將d2表示如下:
d2=d2(θ,u,t)
1.3)安全行為數學形式可以表示如下:
d3>dmin
d3為auv與障礙物下一時刻的歐氏距離,ds為距離d3的安全閾值。利用auv的姿態角、速度以及時間變量可以將d3表示如下:
d3=d3(θ,u,t)
(2)建立局部目標函數:
2.1)節能目標函數
與節能行為相對應,節能目標函數的變量是auv與目標點的距離。假設目標點的位置坐標為(xs,ys),d1可以表示為式:
對于節能目標函數來說,d1的值越小,說明auv越接近目標點。在時間間隔δt確定時,這個距離與auv速度和艏向角有關。對d1進行度量處理,得到節能性的目標函數具體形式如下式:
其中s1和s2是放縮系數。
2.2)協同目標函數
與協同行為對應,協同目標函數的變量值是auv與其他成員的距離,在執行任務的過程中,各個auv之間應該保持協同作業,這里體現為auv與系統中最近的成員距離要處于一個閾值[dmin,dmax]范圍內。最終的協同目標函數如下式所示:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
(fbx,fby)為與該auv距離最近的auv下一時刻的位置,d2為下一時刻的兩個auv的歐氏距離,[dmin,dmax]為d2的期望取值范圍,s1和s2是放縮系數,m2為設定的常值。
2.3)安全目標函數
安全行為的激活需要滿足一定的限制條件,具體體現為auv與障礙物的距離閾值ds。最終的安全行為目標函數如下式所示:
(xo,yo)為障礙物點的位置坐標,d3為auv與障礙物下一時刻的歐氏距離,ds為距離d3的安全閾值,s1和s2是放縮系數,m3為設定的常值。
(3)建立并求解全局目標函數:
全局目標函數的作用是實現之前一系列基本行為的協調,具體的形式如下式所示:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中,ω1,ω2,ω3是可變化的權重系數。將3種行為按照相對重要程度排序為安全行為、協同行為和節能行為,按照這個原則來設置3個權重系數。全局目標函數中具有2個空間變量θ和u,1個時間變量t。
下面利用帶有慣性權重的粒子群優化算法,在t時刻,來求全局目標函數的最優解。
3.1)路徑規劃參數、帶有慣性權重的粒子群優化算法參數初始化
設置搜索空間為二維空間,其中姿態角空間取值范圍為[θ0-θmax,θ0+θmax],速度空間取值范圍為[0,umax],這里θ0為auv當前時刻姿態角,θmax為auv最大轉角能力,umax為auv的最大航行速度。群體規模為n,設置各個粒子的初始位置和速度;
3.2)利用粒子對路徑進行優化:
算法初始化之后,進入算法的主體迭代優化過程;粒子群算法是通過個體間的協作和競爭,實現復雜空間中最優解的搜索。某一粒子i在二維空間的位置表示為矢量xi=(θi,ui),每個粒子所處的位置都表示二維解空間中的一個解。粒子通過不斷調整自己的位置來搜索新解,每個粒子都能記住自己搜索到的最優解,記作pid;以及整個粒子群經歷過的最好的位置,即目前搜索到的最優解,記作pgd。
粒子具有飛行速度,從而可以調整自己的位置。飛行速度可以表示為矢量
式中,vik+1表示第i個粒子在k+1次迭代中的速度,c0為慣性權重,c1和c2為加速常數,rand()為0到1之間的隨機數。
之后判斷是否已經達到最大迭代次數,如果達到最大迭代次數則進入下一步;否則,算法的迭代次數加1,繼續進行下一步優化過程。
3.3)輸出最優解
當算法達到最大迭代次數時便會終止;此時輸出最優解,即整個粒子群經歷過的最好的位置pgd,該位置對應的矢量xi=(θi,ui)代表auv在時刻t應該輸出的姿態角和速度。
最后,利用不同時刻粒子群優化算法輸出的最優解對應的姿態角和速度,可以形成auv最后的路徑。
綜上,本發明提出一種基于行為的多水下機器人路徑規劃方法,屬于路徑規劃技術領域。
本發明提出了一種適用于動態未知環境下的多水下機器人路徑規劃策略,具體包括:首先,定義基本行為來對auv的航行路徑添加約束,基本行為分別為節能行為、協同行為和安全行為;然后,建立與基本行為對應的行為目標函數,將與auv有關的時間變量和空間變量結合起來;最后,建立全局目標函數來實現3種基本行為的行為融合,并采用一種帶有慣性權重的粒子群優化算法來求解全局目標函數,通過輸出的最優解可以生成一條免于碰撞并且是最短的路徑。
- 還沒有人留言評論。精彩留言會獲得點贊!