一種參數自適應設置及自動調整的雷達輻射源信號分選方法與流程
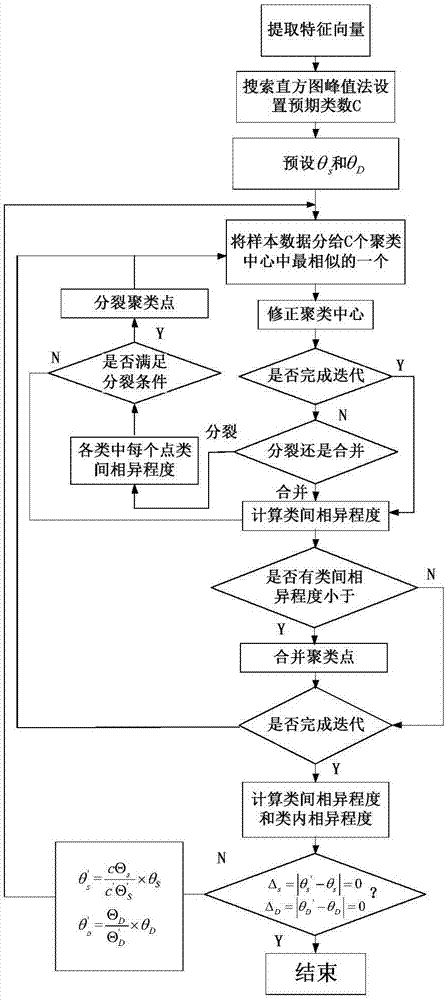
本發明涉及一種雷達輻射源信號分選方法。
背景技術:
隨著現代雷達技術的快速發展,尤其是各式新體制雷達的廣泛應用,戰場電磁環境日益復雜多變,其主要表現為同時同地的輻射源信號嚴重交錯,信號調制形式復雜多樣,這使得由基本參數所描述的特征空間邊界嚴重交疊,基于傳統五大基本參數的輻射源信號分選基本不能滿足實際的需要。
脈內特征分析方法為減小特征空間的交疊開辟了新的研究思路,它使得提取新的信號參數以進一步充分表征雷達輻射源信號特征的想法成為現實。
isodata算法的優點在于通過逐步分化的過程可以認識到大部分待分類對象在分類伊始中不太可能顯示的本質屬性,它是根據樣本的差異來自行決定最終的聚類數目,這使得分類更加科學。但是isodata算法也有其明顯的缺點:傳統isodata聚類算法參數的預設往往是根據經驗設置,而現代戰場電磁環境下,雷達輻射源信號種類數量繁多,變幻莫測,根本無法獲得先驗信息對算法的參數進行準確預設,從而導致聚類的結果差強人意。
因此,本發明把脈內特征參數——對稱holder系數補充到分選參數當中,通過自適應調整isodata算法的方式,合理地實現雷達輻射源信號的分選。
技術實現要素:
為了解決雷達輻射源信號的準確分選問題,本發明公開了一種參數自適應設置及自動調整的雷達輻射源信號分選方法。該方法采用的特征向量是脈沖到達角和對稱holder系數這兩個參數,基于迭代自組織數據分析算法,算法簡稱為isodata,首先根據特征向量自身的特征,利用搜索直方圖峰值統計的方法設置預期類數,同時對類內各數據分布的標準差的上限和各類中心間最小距離的下限進行初步設定,在算法運行時對類內各數據分布的標準差的上限和各類中心間最小距離的下限控制設定自適應準則,通過這種方式解決信號分選問題。
本發明的詳細技術措施步驟如下:
第一步:特征向量的選取
選用雷達輻射源信號脈沖到達角和對稱holder系數構成特征向量。
(一)雷達輻射源脈沖到達角的提取
提取雷達信號脈沖流的脈沖,獲取雷達信號脈沖流脈沖描述字中的脈沖到達角。
(二)對稱holder系數的提取
提取雷達信號脈沖流的脈沖,并對提取的信號進行預處理,主要包括對信號頻域的轉換,帶寬和能量的歸一化。
根據下式,計算脈沖的頻譜和矩形信號以及三角形信號的對稱holder系數hu和ht。
(1)與矩形信號u(k)的對稱holder系數
(2)與三角形信號t(k)的對稱holder系數
式中,f(i)為信號的頻譜,同時選定p=5,q=5。
構造特征向量b=(doa,ht)和d=(doa,ht,hu),其中b用于搜索直方圖峰值統計,d用于最終的輻射源信號分選。
第二步:搜索直方圖峰值統計的方法來預估聚類的大致數目
得到特征向量b后,通過搜索直方圖峰值統計的方法設置isodata算法的預期類數。
記特征向量b={bi}={b1,b2,...,bn}(i=1,2,...,n),特征向量的維數為2維。
劃分區間由樣本數量決定。設每一維劃分區間數為q,
式中,
記doamax,doamin,htmax,htmin分別為特征向量中doa和ht的最大值和最小值。
則向量doa維區間寬度doaδ和向量ht維區間寬度htδ分別為
至此將特征向量b所在的平面區域劃分為q=q2個小區間,每個小區間可以表示為
{bij=(doai,htj)|doai∈[doam,doam+1],htj∈[htn,htn+1],m,n∈[1,q]}(8)
式中,doam=doamin+(m-1)doaδ,htn=htmin+(m-1)htδ。
然后分別統計落于不同小區間中向量元素的個數,到區間統計值的直條高度。將每一個劃分好區間中統計值與相鄰區間進行比較,若該區間的統計值大于其所有相鄰區間的統計值,則記該區間為一個峰值區間。最后統計峰值區間的數目即為峰值數目s。
預設類數設置為直方圖峰值的數目即
式中,
第三步:類內各數據分布的標準差的上限和各類中心間最小距離的下限的預先設置
得到特征向量d,預先設置類內各數據分布的標準差的上限θs和各類中心間最小距離的下限θd。
首先對d中每一維進行屬性歸一化:
式中:xij′為歸一化后的樣本數據,xij為歸一化前的樣本數據,
式中:uj為屬性歸一化樣本數據x′ij第j維的中心。
繼續求取樣本數據第j維的分布稀疏性:
λj是樣本數據中第j維規范后的標準化偏差。
由此設置初始值:
式中,s為預期類數;
然后直接求樣本數據自身第j維的方差
由此設置初始值
第四步:根據自適應準則運行isodata算法進行分選
對于整個算法的運行,采用自適應原則,即通過設置類內各數據分布的標準差的上限θs和各類中心間最小距離的下限θd的變換準則,達到自動逼近最佳聚類效果的目的。
首先計算假設所有樣本數據為同一類時的類內距離
設置參數后運行isodata算法。
每次聚類的算法結束后,分別計算提取結果的類內距離θs′和類間距離θd′。
式中:c′為算法運行產生的分類數,cp為歸類數據的集合,vi為第i類的中心,xn為屬于cp類的數據,vj為與vi不同的類的中心。
第一次聚類后僅改變θs,設定自適應原則如下
再次運行isodata算法
并設定自適應的準則如下:
而退出自適應迭代的條件為:
δs=|θs′-θs|=0(21)
δd=|θd′-θd|=0(22)
式中:δs、δd為算法前后連續兩次運行結果的類內距離以及類間距離的差值。
退出自適應迭代后即完成分選,進而統計分選結果。
至此,一種參數自適應設置及自動調整的雷達輻射源信號分選方法的整個過程結束。
本發明具有如下有益效果:
①分選準確率高。本發明中,預期類數設定的相對準確以及自適應準則的設定能夠提高準確率,另外,引入對稱holder系數這一脈內特征,大大增加了特征向量的可分性,所以分選效果相對理想。
附圖說明
圖1是基于自適應調整的雷達輻射源信號分選方法的流程圖;
圖2是搜索直方圖峰值統計數據平面分布圖;
圖3是搜索直方圖峰值統計效果圖;
圖4為理想分類圖;
圖5為算法分選效果圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步詳細描述。
采用圖1所示的方法,選取5種不同調制類型的且參數較為接近的雷達輻射源信號進行仿真實驗,工作參數變化類型及取值范圍如表1所示。
表1雷達輻射源信號特征參數表
(1)特征向量的選取
對雷達輻射源信號進行特征向量提取,每種類型的雷達產生500個樣本數據。
(2)搜索直方圖峰值統計的方法來預估聚類的大致數目
根據樣本數據數量確定劃分數
樣本數據分布于平面如圖2所示,然后經由搜索直方圖峰值統計,得到直方圖峰值圖如圖3所示,分析后峰值數目為
s=5
則預設分類數目
(3)類內各數據分布的標準差的上限和各類中心間最小距離的下限的預先設置
繼續求取樣本數據第j維的分布稀疏性:
得到
λ1=0.2330,λ2=0.2248,λ3=0.2596
由此設置初始值:
然后直接求樣本數據自身第j維的方差
得到
σ1=1.7908,σ2=1.9398,σ3=2.6530
(4)根據自適應原則運行isodata算法進行分類
1)計算所有樣本數據為同一類時的類內距離
2)設置基本參數
每個分類中允許的最少數據個數:θn=4;
迭代時最多可合并的類的對數:l=2
最多允許的迭代運算的次數:i=70;
預期類數:c=8;
類內各數據分布的標準差的上限:θs=0.35816;
不同類中心間最小距離的下限:θd=1.124。
2)運行isodata算法
得到第一次結果后計算類內距離和類間距離
θs=1067.1
θd=2.4872
改變類內各數據分布的標準差的上限后再次運行算法
θs=1067.1
θd=2.4872
改變參數后再次運行算法
θs=1067.1
θd=2.4872
此時
δs=|θs′-θs|=0
δd=|θd′-θd|=0
退出算法,得到分選結果如表2所示。樣本數據實際分布如圖4所示,方法分類如圖5所示,圖中不同的標簽代表不同的類。
表2仿真結果
- 還沒有人留言評論。精彩留言會獲得點贊!