基于大曲各成分理化指標與產酒量和酒質聯系的測定方法與流程
本發明屬于自動控制技術領域,尤其涉及一種基于大曲各成分理化指標與產酒量和酒質聯系的測定方法。
背景技術:
隨著釀酒工藝的創新和發展,不同風格的白酒相繼問世。大曲是一種富含多酶多菌的微生物發酵劑,大曲是大曲酒釀造生產中的重要物質,是釀酒生產的糖化、發酵、酒化和生香劑,含有多種微生物及其產生的多種酶類,是傳統固態發酵蒸餾大曲酒的重要物質保障,其品質對曲酒的出酒率和優級品率有較大的影響。傳統的大曲質量判定標準體系即是在這種背景下建立起來的,其意義在于:初步認識了大曲的主要酶系狀況:淀粉酶、糖化酶、酒化酶、酯化酶、蛋白酶、脂肪酶等;初步認識了大曲在固態白酒發酵體系中的生化作用:產酒、產酯、產香等;初步認識了大曲的主要微生物類群:酵母菌、霉菌、細菌以及放線菌等。在制曲工藝條件確定的前提下,傳統大曲的質量品質,就主要取決于制曲環境所處的地理條件、氣候條件、水質條件等所滋生和孕育的微生物類群。傳統大曲生產主要采用自然網羅自然界的微生物和人工制作曲坯及人工管理,不僅大曲因氣候、環境等自然因素的影響而容易導致質量的不穩定性,而且人工制曲坯及人工管理的勞動量大、工作效率低,且大曲質量受工人工作經驗的影響。強化大曲發酵技術可以解決大曲中某種微生物數量和酶系種類的不足,為大曲坯提供良好的微生物及酶系體系。大曲的質量對白酒品質的影響很大,因此穩定大曲品質是保證酒質的前提。大曲質量評定方法有感官評定法、理化特征指標評定法、微生物種群數量評定法。這些方法及有關標準對大曲質量的進一步規范化、標準化起到一定推動作用。由于影響釀酒生產的因素極其復雜,每種評定方法的可靠性、穩定性都存在一定的缺陷,其評定指標和方法也有待進一步完善。
綜上所述,現有技術存在的問題是:目前測定大曲脂肪酸的檢測方法存在沒有合適的微生物傳感器來檢測大曲脂肪酸;大曲酒酒體中的呈香呈味物質含量僅占酒體總量的2%左右,所形成酒品的價值就遠遠超越食用酒精的價值;曲藥的各理化指標由于生產季節、生產環境、工藝參數、取樣方法和部位等因素差異,導致同一指標分析結果差異較大。具體如下:
(1)到目前為止,還沒有測定大曲脂肪酸更好的檢測方法。存在的主要問題是:原料中脂肪降解產物脂肪酸以及曲坯中的色素、固醇等均共同顯示為粗脂肪含量,我們擬用脂肪酸含量的高低表征脂肪轉化力。脂肪轉化力雖是體現大曲復合曲香物質的重要指標之一,但到目前為止,由于沒有合適的微生物傳感器來檢測大曲脂肪酸,大曲脂肪酸的測定方法將成為今后共同探討的方向。(2)大曲中紛繁復雜的微生物區系和酶系,進入大曲酒發酵體系中又進一步彼消此長地繁殖代謝和生化演化,形成種類繁多的酒體呈香呈味物質,目前還未完全確定其種類(3)大曲酒酒體中的呈香呈味物質含量僅占酒體總量的2%左右,但所形成酒品的價值就遠遠超越食用酒精的價值。(4)制曲工藝有一定差異(5)曲藥的各理化指標由于生產季節、生產環境、工藝參數、取樣方法和部位等因素差異,導致同一指標分析結果差異較大。
技術實現要素:
針對現有技術存在的問題,本發明提供了一種基于大曲各成分理化指標與產酒量和酒質聯系的測定方法。
本發明是這樣實現的,一種基于大曲各成分理化指標與產酒量和酒質聯系的測定方法,所述大曲各成分理化指標與產酒量和酒質聯系的測定方法曲料成份采集分析系統和微生物快速檢測系統;
曲料成份采集分析系統通過傳感器模塊能夠實時檢測曲料成份的變化和微生物群落的生長,根據其理化指標與數據庫中的不同廠家的理化指標對比,尋求最佳制曲工藝,并可更新數據庫;根據其理化指標將其控制參數應用于曲料發酵自動控制系統,初步實現制曲工業化;
所述微生物快速檢測系統是通過低選擇性交互敏感的多傳感器陣列檢測曲料樣品的整體特征響應信號,檢測培養基隨著微生物生長的變化,通過檢測取得特征值,再通過pca和神經網絡等模式識別方法的數據處理來確定不同階段培養基的不同特征。
進一步,所述曲料成份采集分析系統包括:
傳感器陣列,由六個工作電極和一個輔助電極組成一個獨立的單元機構并和一個參比電極(鉑)共同組成一個完整的傳感器陣列,通過檢測大曲中的主要成分的理化指標來分析大曲的品質;
信號激勵采集單元,由信號激勵單元,信號采集單元和信號調理單元構成。測試平臺為樣品安置、檢測提供嚴格的工作環境;信號激勵單元和調理單元和數據分析模塊通過串口協議實現通信,傳感器上的信號經過調理電路由數據采集卡再次通過調理電路輸出最終的傳感器信號,并通過串口或usb傳送至電腦pc,采用labview實現上位機的通信和分析軟件;
應用軟件單元,是在電腦上運行的用于控制智舌檢測、分析數據、數據結果的應用程序;
數據分析模塊,運用主成分析法模式識別和神經網絡算法進行數據的分析處理。
進一步,所述理化指標智能分析方法是粗糙集理論結合神經網絡、主成分分析法包括:
(1)模式識別,以各種傳感器為信息源,以信息處理與模式識別的理論技術為核心,以數學方法與計算機為工具,對各種媒體信息進行處理、分類、理解;
(2)特征值提取,分別利用1hz、10hz、100hz三種脈沖脈沖頻率作為激勵信號掃描,以100μs作為采樣頻率,則在1hz、10hz、100hz的三個頻段內的采集點的個數分別為200000、20000、2000個,對數據進行特征選擇和特征提取;
(3)主成分分析,把原來多個變量劃分為少數幾個綜合指標;
(4)dfa判別函數分析,根據已知觀測對象的分類和若干表明觀測對象特征的變量值,建立判別函數和判別準則和判別函數,并使其錯判率最小;
(5)人工神經網絡,利用輸出后的誤差來估計輸出層的直接前導層的誤差,然后利用此誤差去估計更前一層的誤差,如此反復訓練一層層的反傳,得到其他各層的誤差估計。
所述主成分分析法進一步包括:
首先標準化處理,原始數據構成的矩陣為x,它是由行n行p列構成;
標準化處理:
則標準化后的相關系數的計算公式為:
經過主成分分析法的處理分解問特征值與載荷矩陣的相積,計算其相應的特征值和特征向量,得到即x=tl';根據t的得分矩陣做出圖形來判斷樣品的歸類效果圖。
所述dfa判別函數分析進一步包括:
采用的判別準則主要是線性判別分析,取線性判別函數:
u(x)=atx=a1x1+a2x2+…+apxp;
各總體內離差平方和:
其中
不同總體間離差平方和:
其中
為滿足式中各總體內離差平方和最小而式中各總體間離差平方和最大,則需要使
所述人工神經網絡進一步包括:
學習因子,根據輸出誤差大小利用變步長法自動調整學習因子,h=h+a·(ep(n)-ep(n-1))/ep(n),其中a為調整步長,取值在0~1;h為步長因子;
隱層節點數,當某節點出發指向下一層節點的所有權值和閾值均落在死區中時,死區的范圍取±0.1、±0.5區間,則把該節點刪除;
l=(m+n)1/2+c;
其中m為輸入節點數,n為輸出節點數,c為1~10之間的常數;
輸入輸出神經元的確定,利用多元回歸分析法對神經網絡的輸入參數進行處理,將相關性強的輸入參數刪除;
算法優化,采用lm-bp神經網絡算法:
其中能量方程為:
最后解得:δxk=[jt(xk)j(xk)+μi]-1jt(xk)e(xk);
當μ=0時,為牛頓法,而當μ接近于8時,則是steepestdecent法。
本發明的優點及積極效果為:利用多頻脈沖法對傳感器陣列信號的數值進行有效提取,大大減少了冗余信息,對后面分類定性和定量起指導作用。利用電子舌伏安法,運用采集方法是傳感器陣列的電化學信號的采集。采集的電位范圍-1v~+1v,以0.2v脈沖幅度遞減,頻率段是1,10,100hz這樣的幾個頻段,采集頻率位100微秒一個點,這樣的采樣頻率在這三個段就可以采集222000個點,傳感器陣列一般是由5,6個傳感器組成,就會有很大數量的采集數據,大量的采集數據,雖然是有豐富的信息量,但是同是有可能會對計算機造成負荷,也會造成冗余。
本發明多頻率脈沖法提取的特征點是頂點和拐點,頂點是與脈沖電流信號和溶液帶電離子性質的特征有關聯;而拐點則是脈沖電流信號和溶液中氧化還原組分性質相似,如圖4所示。這樣電位的變化范圍—1v~+1v,以0.2v的幅度遞減,圖4中的片段只需要取40個特征值,對比222000,數據量就少了很多,這樣就加快了數據的處理速度。
本發明利用改進的主成分分析法和粗神經網絡方法對大曲的重要屬性進行分析,從而能夠得出決定大曲質量的理化指標;利用特異性傳感器和人工智能的方法對微生物進行定性定量檢測;采用開放式數據庫,能夠快速的查詢、建立、分析不同廠家和企業的大曲質量。本發明能夠對生產曲料的過程中對大曲品質進行實時檢測,可以提高生產效率,也對品牌效益起到了保護作用;該技術的應用前景長遠,對社會起到了推動的作用。微生物快速檢測系統可應用于食品安全檢測領域,對食源性細菌的檢測可滿足快速,簡便,經濟,可靠等要求,同時也對食品品牌保護和社會安全起保障作用。
附圖說明
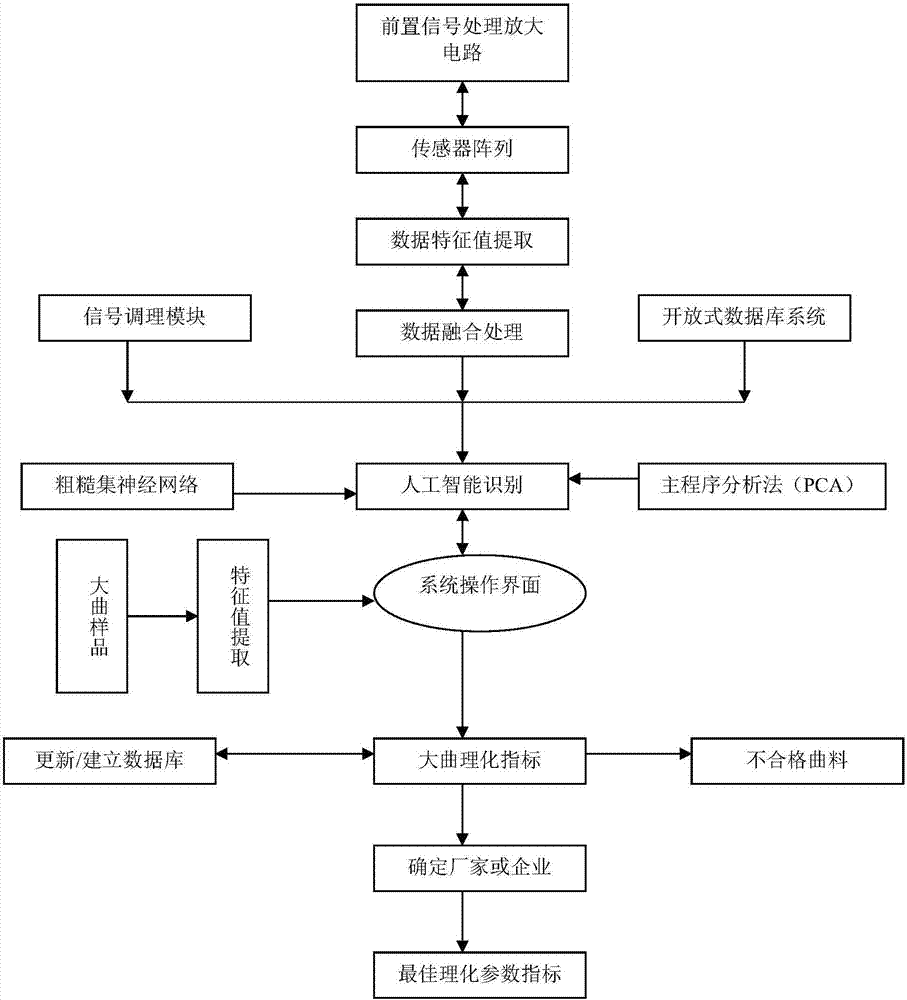
圖1是本發明實施例提供的曲料品質分析與評價系統框圖;
圖2是本發明實施例提供的bp和神經網絡相結合的培養基優化算法;
圖3是本發明實施例提供的微生物快速檢測系統。
圖4是本發明實施例提供的多頻率脈沖法提取的特征點是頂點和拐點示意圖。
具體實施方式
為能進一步了解本發明的發明內容、特點及功效,茲例舉以下實施例,并配合附圖詳細說明如下。
下面結合附圖1附圖2附圖3對本發明的原理作詳細的描述。
如圖1所示曲料成份采集分析系統分為硬件和軟件兩部分系統。
硬件系統由傳感器陣列模塊、信號調理系統、數據預處理模塊和數據分析模塊。各組成部分功能如下:
(1)傳感器陣列模塊:傳感器采用貴金屬裸電極陣列,并采用多頻脈沖作為激發信號。通過采集工作電機上的響應信號,利用多頻脈沖原理提取有效信號特征值,結合模式識別方法對數據最后分析。
(2)信號調理系統:為了能夠從中提取到傳感器輸出信號——激發電流,必須采用電流電壓放大電路,使其信號的強度和幅值的大小能夠在信號采集電路信號采集的范圍之內。其次,電化學裝置的電極系統本身的內阻非常大,所以系統的輸入級需滿足的基本條件是具有高的輸入阻抗和低的輸入電流。輸入級放大信號后為了保持原有信號的信息需要通過的一定的電路進行濾波,使其噪聲降到最小。每個工作極上設置單獨的模擬開關,從而控制每個工作極上信號電放大和濾波處理。
(3)數據預處理模塊和數據分析模塊:多通道高精度數據采集器,將調理好的模擬信號轉換為數字信號輸入到計算機,系統軟件會將龐大的數據通過進行分析、存儲,并且可以完成數據庫更新。
(4)系統為了增加可調式部分,預留多個接口(usb)。使電路模塊實現靈活拔插或擴展,增加系統的擴展性。
所述曲料成份采集分析系統包括:
傳感器陣列,由六個工作電極和一個輔助電極組成一個獨立的單元機構并和一個參比電極(鉑)共同組成一個完整的傳感器陣列,通過檢測大曲中的主要成分的理化指標來分析大曲的品質;
信號激勵采集單元,由信號激勵單元,信號采集單元和信號調理單元構成。測試平臺為樣品安置、檢測提供嚴格的工作環境;信號激勵單元和調理單元和數據分析模塊通過串口協議實現通信,傳感器上的信號經過調理電路由數據采集卡再次通過調理電路輸出最終的傳感器信號,并通過串口或usb傳送至電腦pc,采用labview實現上位機的通信和分析軟件;
應用軟件單元,是在電腦上運行的用于控制智舌檢測、分析數據、數據結果的應用程序;
數據分析模塊,運用主成分析法模式識別和神經網絡算法進行數據的分析處理。
軟件系統需具備大曲監測成分實時顯示、參數設置和調度的實時控制管理、綜合信息管理、人工智能識別等功能。按照其功能主要包括數據庫、模型方法庫、知識庫、在線數據采集子系統、實時控制管理、綜合分析與決策支持子系統、綜合信息管理子系統。
其中數據庫是整個系統運轉的基礎,準確高效地收集和及時處理大量復雜的監測數據資料是整個系統設計和開發的重點。數據庫及綜合信息管理子系統是面向數據信息存儲和信息查詢的計算機軟件系統。本系統的數據庫內容包括:監測儀器特征庫;原始監測數據庫;整編監測數據庫;在線數據實時分析庫;人工巡視檢查資料庫;數據自動采集參數庫;模型輸入輸出數據庫;實時控制日志數據庫等。
(1)模型庫及其管理子系統
提供相應分析處理使用的處理模型和計算方法的例程庫。包括各種時態和空間模型、在線數據可靠性分析算法等。包括大曲成分預報模型、大曲質量評價模型、大曲質量預測模型、酒質評價模型、酒質預測模型等。
(2)知識庫及其管理子系統
是用于知識信息的存儲及其使用管理的計算機軟件系統。本系統的知識庫內容包括:1.各監測工程的監測指標,2.各廠家企業的評判標準,3.監測數據誤差限值,4.專業規律指標,5.專家知識經驗,6白酒法律、法規,行業規程、規范的有關條款等。
如圖3所示是本發明實施例提供的微生物快速檢測系統。
通過低選擇性交互敏感的多傳感器陣列檢測曲料樣品的整體特征響應信號,檢測培養基隨著微生物生長的變化(把大的有機物分子轉化成小的有機分子和離子),過程中培養基其本身的特性(電導、電阻、粘度等等)也發生了改變,通過對這一變化的檢測取得特征值,再通過pca和神經網絡等模式識別方法的數據處理來確定不同階段培養基的不同特征。
(1)傳感器陣列的確定
采用電化學的方法對微生物及其代謝產物檢測,傳感器是檢測系統的核心部件。關鍵往往在于如何提高檢測的靈敏度,以及從電信號中提取出和待測微生物指標呈良好線性關系的特征,通過氧化還原酶反應和適當的媒介,能將微生物的代謝氧化還原反應轉換成可量化的電信號。
傳感器陣列采用重金屬鉑,金,鈀,鎢,鈦,銀的電極構成,并利用相同的處理方法(主成分分析法或最小二乘法)來選取對微生物培養基檢測的最佳電極和頻率段。
(2)微生物檢測池的設計
由于微生物的生長會產生很多氣泡,導致檢測的誤差加大,所以不能采取傳統將電極倒置插入培養基檢測的方法。微生物檢測池是一個密閉的空間,池體底部裝有電極的設置可以避免外界對被檢測培養基的污染,使檢測的數據更加準確,傳感器陣列位于檢測池的底座還可以消除微生物在生長的時候產生的氣泡對電極的影響,檢測池池體內側設有內螺紋,底座外周設有與該內螺紋相匹配的外螺紋,設置螺旋結構,可以使檢測池池體與底座脫離,便于清洗電極表面。
(3)培養基優化設計
神經網絡有很強的輸入輸出非線性映射能力,特別適用于微生物發酵這種高度非線性、非結構化的復雜模型中。而遺傳算法又是一種有導向的全局隨機搜索方法,它對于目標函數和搜索空間沒有任何限制,因此非常適合神經網絡模型等無明確分析函數形式的優化問題。實驗培養基配比的組合被分成訓練組和預測組,訓練組用來訓練bp神經網絡,然后預測組用來對訓練好的網絡進行測試,由此構建神經網絡模型。并以該模型的輸出為ga的目標函數,通過遺傳算法的全局尋優,找到最優培養基組合。
(4)定量檢測微生物方法的建立
利用檢測平臺檢測微生物不同種類,所具有的不同酶系,在特定液體培養基中培養一定時間后,所產生的不同代謝產物,導致培養基具有整體的特殊性,本發明根據這種特殊性為依據,對微生物建立生長預測模型。
根據微生物呈指數生長的特點,微生物數量的對數隨時間的變化得到一條s形曲線,所繪制的生長曲線分別為延滯期、對數期、穩定器和衰老期。
用curveexpert軟件分析智舌檢測菌種的生長數據,擬合s曲線,建立生長模型,通過logistic、mmf、gompertz3種模型的標準差s和相關系數r的比較,確定最佳模型。從而確定檢測該菌種的最合適培養基。
本發明的理化指標智能分析方法是粗糙集理論結合神經網絡、主成分分析法,具體包括以下步驟:
1.1模式識別
模式識別是以各種傳感器為信息源,以信息處理與模式識別的理論技術為核心,以數學方法與計算機為主要工具,探索對各種媒體信息進行處理、分類、理解并在此基礎上構造具有某些智能特性的系統或裝置的方法、途徑與實現,以提高系統性能。本發明的電子舌系統的數據分析模塊主要用到pca、dfa等模式識別算法。
1.2特征值提取
多頻脈沖電子舌采用的是多頻脈沖伏安法采集傳感器陣列的電化學信號。在系統的操作中,對于傳感器電壓中的起始電壓、結束電壓以及步降電壓一般分別設置為正向最大電位1.0v、負向最大電位-1v、0.2v。按照多脈沖測試方法中,分別利用1hz、10hz、100hz三種脈沖脈沖頻率作為激勵信號掃描,以100μs(最大極限值是10-6s)作為采樣頻率,則在1hz、10hz、100hz的三個頻段內的采集點的個數分別為200000、20000、2000個。則所在的傳感器陣列的一次采樣中就可以獲取點的個數達到m級,同時還存在了大量的冗余信息,這對常規的數據分析(采取直接分析的方法)帶了不便,同時也給計算機帶來了超負荷的運算。所以在進行數據分析之前需要采取一定的算法對大量豐富的數據進行特征選擇和特征提取。
1.3主成分分析法
在解決實際問題時候,會遇到研究很多個變量的問題,而且在多數情況下,多個問題之間的具有相關性,這就增加了解決問題的難度。將多個變量用少數幾個變量替代,且能夠代表多個變量的信息,在少數幾個變量組成的新的樣本進行統計分析,這就是主成分分析法的目的。主成分分析是把原來多個變量劃分為少數幾個綜合指標的一種統計分析方法。從數學角度看,這是一種降維處理技術。
1.3.1主成分分析法數學模型
簡而言之,主成分分析法就是通過數學降維的處理,從多個變量中找出幾個具有代表性且不相關的綜合變量進行替代的方法。
假設具有n個樣本,每個樣本具有p個變量,構成一個n×p階的矩陣:
當p較大的時,在p維空間中考察問題比較麻煩。為了克服這種困難,就需要降維處理,需要幾個較少的綜合指標代替原來的綜合指標。使其盡量多的反映樣本信息且彼此獨立。現需要建立另一數學模型,fj=αj1x1+αj2x2+…+αjpxp(j=1,2,…,p)。xj=(x1j,x2j,x3j,...)t,(j=1,2,...p)為其組成元素。則構造的模型必須具有:變量之間不具有相關性,即fi,fj(i≠j,i,j=1,2,…,p)互不相關;新變量按照方差依次遞減的順序進行排列且保持變量的整體方差不變,即ak12+ak22+…+akp2=1k=1,2,…p.。第一變量具有最大方差,稱為第一主成分,第二變量的方差次大,并且與前一變量不具有相關性,稱為第二主成分,依次類推。
fj是p維的正交化變量,且fj之間互不相關且按其方差大小順序排列。可以看出fj共有p個主成分。設其主成分系數aij構成系數矩陣a。矩陣x=(x1,x2,...,xp),則協方差矩陣為:
σ=(σij)p×p=e[(x-e(x))(x-e(x))t];
新建模型滿足f=ax:
則σ必為半正定矩陣,用雅克比方法|λi-a|=0求特征值λi(按從大到小排序)及其特征向量:
由于需要滿足||ai||=1,即
其中貢獻率為:
累計貢獻率:
在這里可以理解主成分是原來變量的一種線性組合,結合其系數的定性分析可知,系數的大小因有正負大小相當之分。所以不能理所當然的認為主成分是某個變量的屬性作用。根據線性組合中系數絕對值的大小可以給主成分賦予實際意義,比如變量系數大小相當的情況下,則構成的主成分就是幾個變量的總和。根據標準化的原始數據可以得到各主成分的得分矩陣為式為:
1.3.2pca在本發明中的應用
在特征值的提取中,三個頻段(1hz、10hz、100hz)內經過預處理后的數據有40×3=120個,雖然脈沖法提取后大大減少了特征值的個數,但是直接對120個數據進行樣本處理還是有相當大的難度,而且數據里面仍有大量的冗余信息。采用pca主成分分析法,用少數幾個主成分值來代替這些特征值。按照主成分分析的計算步驟,首先標準化處理,假設原始數據構成的矩陣為x,它是由行n行p列構成。
標準化處理:
則標準化后的相關系數的計算公式為:
經過主成分分析法的處理可以將其分解問特征值與載荷矩陣的相積。計算其相應的特征值和特征向量,最后得到即x=tl'。根據t的得分矩陣做出圖形來判斷樣品的歸類效果圖。
1.4dfa判別函數分析
判別分析適用于判斷個體所屬類別的一種統計方法。根據已知觀測對象的分類和若干表明觀測對象特征的變量值,建立判別函數和判別準則和判別函數,并使其錯判率最小,對于一個未知分類的樣本,將所測指標代入判別方程,從而判斷它來自哪個總體。這種判別準則在某種意義上是最優的,但是局限于判概率最小或是損失最小的情況下。如果樣本的總體均值差異很大,則不是最優選擇。
判別分析與聚類分析的區別是,聚類分析預先不知道分類,需要對樣品進行分類,是一種純統計技術。而判別分析是在研究對象分類已知的情況下,根據樣本數據推導出一個或一組判別函數,同時制定一種判別準則,用于確定待判樣品的所屬類別,使判錯率最小。
1.4.1判別函數分析分類
從數學模型的角度來看,可以將判別問題描述為:對于n個樣品,每個樣品有p個指標,已知每個樣品屬于某一k類別(總體)g1,g2,...,gk,對于每一個類別其分布函數分別為f1(y),f2(y),...,fk(y)。給定一個樣品y,需要判斷來自于哪個總體。尋求一種最佳的判別方法或函數和建立一種最佳的判別準則的過程就是判別分析解決的主要問題。
判別分析的研究方法很多,根據研究對象的不同把判別分析方法分成不同的種類。目前主要有:
根據判別的組數不同劃分,主要有兩組判別分析和多組判別分析。
根據用不同的數學模型區分不同的總體劃分,主要有線性判別分析和非線性判別分析。
根據判別對變量處理方法的不同有序判別分析和逐步判別分析。
根據判別準則的不同,目前主要成熟的有費歇爾判別(fisher)判別準則、貝葉斯判別準則、馬氏距離最小準則、最小平方準則和最大似然準則。
1.4.2線性判別分析(lda)
在本發明采用的判別準則主要是線性判別分析,lineardiscriminantanalysis,lda是由ronaldfisher于1936年首次提出并由belhumeur于1996年引入了人工智能和模式識別領域,線性判別分析是模式識別中的經典算法,是一種快速學習算法(supervisedlearning)。
lda的工作原理從數學建模的角度看,就是利用投影的方法把帶有標簽的數據點從高維的空間投影到低維空間。要求投影后的點具有最佳矢量空間,即按簇類進行類別區分,使得相同類別的點在投影后具有最小距離,而類別不同型的點在投影后具有最大類間距離。使其投影后具有最佳分離性。即投影后的數據點類間散布矩陣最大而類內散布矩陣最小,是一種非常好的特征抽取方法。
線性判別分析的基本思想是將高維的模式樣本投影到最佳鑒別矢量空間,以達到抽取分類信息和壓縮特征空間維數的效果。投影后保證模式樣本在新的子空間有最大的類間距離和最小的類內距離,即模式在空間中有最佳的可分離性。與距離判別法不同的是,lda判別法對變量的類型及其概率分布形式不需要明確的限定,對數據點構成的空間不進行直接劃分,而是尋求一種最佳的投影方式將其從高維空間影射到低維空間進行分類,因此如何選擇恰當的投影方式是fisher判別方法的關鍵所在。
取線性判別函數:
u(x)=atx=a1x1+a2x2+…+apxp;
各總體內離差平方和:
其中
不同總體間離差平方和:
其中
為滿足式中各總體內離差平方和(ssr)最小而式中各總體間離差平方和(sse)最大,則需要使
1.4.3pca和dfa應用區別
本發明中采取了主成分分析法(pca)和判別函數分析(dfa)兩種模式識別算法。dfa中常用的方法就是lda,lda在給定訓練數據后,將會得到一系列的判別函數。lda的輸入數據就像是帶了標簽一樣,具有可預知性,對于以后數據的輸入,lda通過前面建立的判別方法就可以進行判斷了。而pca具有不可預見性,降低數據的維數并使各自的數據的不具有相關性或減小相關性,即增大他們的方差。
兩者都是通過降低維數進行特征提取,但是兩者的處理過程不同。當類中的樣本數據分布具有某一共同特征(如都服從高斯分布),則此時的lda優于pca。當都不服從時,則此時運用pca就是比較好的選擇。兩者各自有不同的長處和缺點,在處理具體問題時,需要選擇相應的方法或是兩者結合的方法是很好的。在設計中,增加了這樣的算法組合供操作員選擇。
1.5人工神經網絡
人工神經網絡(artificicalneuralnetworks,ann)是一種模仿生物神經網絡的結構和功能的數學模型或計算模型。它主要是由大量的神經元節點相互連接構成,并且能根據外部環境的變化改變內部自身的結構,它經常被用來對輸入輸出間的關系建模來探索數據的模式,是一種自適應系統。因具有分布式信息存儲、良好的自組織學習能力和大規模并行處理等特點而被廣泛應用在模式識別和智能控制等多個領域。
bp(backpropagation)神經網絡最早是由rumelhart和mccelland課題研究小組于1985年提出來的,誤差反向后傳bp學習算法是一種有監督的神經網絡算法。bp網絡是一種按誤差逆向傳播算法,它無需知道描述大量數據輸入/輸出信息的映射關系的數學方程,就可以自我學習和存儲這些數據。
bp算法的基本原理是利用輸出后的誤差來估計輸出層的直接前導層的誤差,然后利用此誤差去估計更前一層的誤差,如此反復訓練一層層的反傳,就可以得到其他各層的誤差估計。
傳統bp算法的步驟總結為:
選定學習的數據,p=1,…,p,隨機確定初始權矩陣w(0)
用學習數據計算網絡輸出
反下式向修正,直到用完所有學習數據。
誤差反傳算法是一個無約束的非線性最優化計算過程,在bp網絡結構較大的情況下,容易出現計算時間長,甚至會陷入局部極小點而得不到最優結果。所以必須對bp網絡進行優化,本發明從以下幾個方面對其進行了優化:
學習因子優化
根據輸出誤差大小利用變步長法自動調整學習因子,減少迭代次數和加快收斂速度。h=h+a·(ep(n)-ep(n-1))/ep(n),其中a為調整步長,取值在0~1之間。h為步長因子。
隱層節點數優化
隱層節點數的多少決定了網絡性能的好壞,當隱層節點數太少時,網絡的容錯能力較差;而當隱層節點數太大時,則網絡學習時間太長導致不能收斂。利用逐步回歸分析對參數的顯著性進行檢驗,并刪除一些線形相關的隱節點。其中最佳隱節點計算,當某節點出發指向下一層節點的所有權值和閾值均落在死區中時(死區的范圍一般取±0.1、±0.5等區間),則把該節點刪除。
l=(m+n)1/2+c;
其中m為輸入節點數,n為輸出節點數,c為1~10之間的常數。
輸入輸出神經元的確定
可以利用多元回歸分析法對神經網絡的輸入參數進行處理,將相關性強的輸入參數刪除,減少輸入節點數。
算法優化
采用lm-bp(levenbergmarquardtbackpropagation)神經網絡算法,該算法在求解函數的最小應用方面能夠加快收斂速度,其采用的方法與牛頓法類似。
其中能量方程為:▽e2(x)=jt(x)j(x)+s(x);
最后解得:δxk=[jt(xk)j(xk)+μi]-1jt(xk)e(xk);
當μ=0時,即為牛頓法,而當μ接近于8時,則是steepestdecent法。steepestdecent法可以使函數收斂較為穩定,但是時間較長,而牛頓法效率高,但是不穩定,所以選擇適當的μ值,可以在較短的時間內達到收斂。
綜合以上所述,相比現有技術,本發明具有以下優勢:
(1)利用多頻脈沖法對傳感器陣列信號的數值進行有效提取,大大減少了冗余信息,對后面分類定性和定量起指導作用。
(2)有效的數學分析法方法,利用改進的主成分分析法和粗神經網絡方法對大曲的重要屬性進行分析。從而能夠得出決定大曲質量的理化指標。
(3)利用特異性傳感器和人工智能的方法對微生物進行定性定量檢測。
(4)采用開放式數據庫,能夠快速的查詢、建立、分析不同廠家和企業的大曲質量。
以上所述僅是對本發明的較佳實施例而已,并非對本發明作任何形式上的限制,凡是依據本發明的技術實質對以上實施例所做的任何簡單修改,等同變化與修飾,均屬于本發明技術方案的范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!