一種油品性質不確定度的評定方法與流程
本發明涉及石油化工領域的油品性質檢測分析方面,基于近紅外光譜快速分析技術,建立一種油品性質不確定度的評定方法。
背景技術:
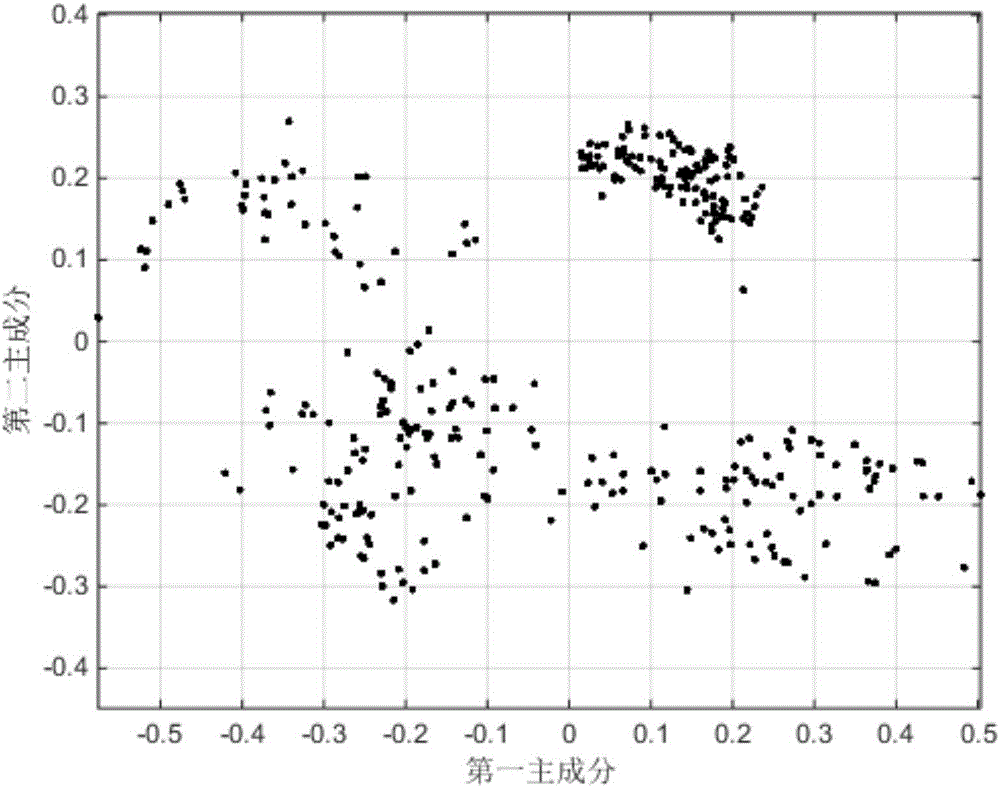
:在油品性質分析領域,基于近紅外光譜的快速分析技術相較傳統實驗室化驗方法具有快速、無損等諸多優點,近年來已越來越多地應用于油品性質的實時檢測中。然而,基于近紅外光譜的建模方法對校正集樣本要求嚴格,例如要求校正集樣本分布范圍寬、樣本分布均勻等,否則模型預測的結果極易出現偏差。在實際的工程應用中,校正集樣本往往來自企業的實際生產工藝過程,而為了保證生產的穩定性,企業往往難以提供覆蓋范圍大、性質分布均勻的樣本,從而影響油品性質建模分析的精度。因此,在企業生產發生波動,當前待測的油品落入性質分布稀疏的區域時,如果能給生產人員提供及時的報警或提示,對及時發現問題、提升產品質量均具有重要的應用價值。技術實現要素:本發明目的是針對油品性質快速分析過程中樣本光譜數據分布不均勻的情況,建立與每個油品性質相對應的不確定度指標,以量化的方式反映模型預測性質值與實驗室化驗值間的匹配程度。本發明采用以下的技術方案:本發明基于油品近紅外光譜數據及對應的油品性質數據,首先對預處理后的近紅外光譜數據進行主成分分析得到得分矩陣,以得分矩陣中前三個列向量為橫軸、縱軸和豎軸繪制所有樣本的主成分分布圖,再以待測樣本為中心,建立與樣本總數及樣本分布相適應的長方體框,最后統計長方體框內相似樣本的數量n,根據相似樣本數量n和不確定度u的對應規則確定油品性質的不確定度。本方法中油品性質不確定度分為5個等級,不確定度為1表示模型預測性質值與實驗室化驗值非常匹配,不確定度為2~4表示模型預測性質值與實驗室化驗值的匹配度逐漸下降,不確定度為5表示模型預測性質值與實驗室化驗值不匹配或者模型無法預測待測樣本的性質值,該量化指標反映了模型預測性質值與實驗室化驗值的匹配程度。本方法在主成分分布圖中建立與樣本總數及樣本分布相適應的長方體框,其長寬高的選取按照3:2:1的比例。本方法建立了框內相似樣本數量n與油品性質不確定度u間的對應規則,設長方體框內相似樣本數量的參考值為m,根據gb/t29858—2013規定校正集至少含有6(k+1)個樣品,則m至少為6(k+1),其中k為主成分數,相似樣本數量n與油品性質不確定度u間采用如下規則:有益效果:本發明針對油品性質近紅外建模過程中光譜數據分布不均勻的情況,建立與每個油品性質相對應的不確定度指標,直觀反映模型預測性質值與實驗室化驗值的匹配程度,為生產人員提供一種簡便有效的量化指標,用于及時報警或提示,對及時發現問題、提升企業產品質量具有重要的應用價值。附圖說明圖1是油品性質不確定度評定方法的實施流程圖圖2是實施例中95#汽油樣本數據的二維主成分分布圖圖3是實施例中長方體框及框內相似樣本分布圖(以樣本庫中第49號樣本為待測樣本)圖4是實施例中95#汽油研究法辛烷值不確定度與絕對偏差均值的柱狀圖具體實施過程下面結合附圖以及具體的算例,給出詳細的計算過程和具體操作流程,以對本發明作進一步說明。本實施案例在以本發明技術方案為前提下進行實施,但本發明的保護范圍不限于下述的實施案例。本案例以95#汽油的研究法辛烷值(ron)為例,選取的是某煉化企業在2015年5月至2017年5月期間生產的335個95#汽油樣本,用近紅外光譜儀掃描獲得335個樣本的光譜,并通過matlab中主成分分析和偏最小二乘回歸得到335個樣本的預測性質值,同時通過實驗室化驗方法獲取335樣本的化驗值。本案例實施流程如圖1所示,具體的實施步驟如下:(1)建立95#汽油樣本集測定95#汽油樣本的近紅外光譜,從而獲得所有95#汽油樣本的近紅外光譜數據,對光譜數據進行常規預處理,包括基線校正和矢量歸一化,選擇4000-4800cm-1波數段的吸光度數據。(2)主成分分析對預處理后的樣本光譜數據進行主成分分析,為便于觀察,首先以二維坐標圖為例,選取主成分分析結果中得分矩陣的前兩個列向量分別作為二維坐標的橫軸和縱軸,繪制所有樣本點的二維主成分分布圖,如圖2所示,可見95#汽油校正集樣本分布顯然不夠均勻,這也是實際工程應用中常常發生的情況。在本發明中,為提升精度,選取主成分分析結果中得分矩陣的前三個列向量分別作為三維坐標的橫軸、縱軸和豎軸,繪制三維主成分分布圖。(3)建立長方體框及相似樣本數量統計樣本庫中共有335個樣本,依次從335個樣本中選擇一個樣本作為待測樣本。在主成分分布圖中,以待測樣本為中心,依據第一主成分、第二主成分、第三主成分重要度由高到低的規律,建立長寬高比例為3:2:1的長方體框。實際應用中,具體長寬高的數值可根據樣本總數及樣本分布作調整。本案例中長方體框的長為0.3,寬為0.2,高為0.1。框內樣本即為待測樣本的相似樣本,統計長方體框內相似樣本數量n,以335個樣本中的每個樣本作為待測樣本分別測定,共測得335組長方體框內相似樣本數量n。隨機選取某一樣本作為待測樣本,以樣本庫中第49號樣本為例,以待測樣本為中心建立的長方體框及框內相似樣本分布如圖3所示(圖中三角形表示待測樣本)。(4)建立95#汽油ron的不確定度指標基于上一步驟中統計的335組長方體框內相似樣本數量n,本案例中框內相似樣本數量的參考值為m=50,根據框內相似樣本數量n與不確定度u的對應規則,計算出每個不確定度相對應的框內相似樣本數的區間范圍,計算結果如表1所示。表195#汽油框內相似樣本數量與不確定度的具體關系序號框內樣本數n不確定度u145及以上12[35,45)23[20,35)34[5,20)45[0,5)5(5)相似樣本建模基于主成分分析和偏最小二乘回歸的原理,建立油品性質的局部預測模型,此模型基于matlab平臺建立,模型的輸入為長方體框內相似樣本的光譜數據和ron化驗值,此步驟完成樣本庫中335個95#汽油樣本的ron預測。(6)根據模型預測值與實驗室化驗值的絕對偏差評估不確定度指標如圖3所示,335個樣本在空間中分布不均勻,因此以不同待測樣本為中心建立的長方體框,框內相似樣本的數量不同。在主成分分布圖中的密集區,長方體框內樣本數量較多,基于較多的相似樣本預測95#汽油的ron,不確定度偏小。而在主成分分布圖中的稀疏區,框內樣本數量較少,基于較少的相似樣本進行預測95#汽油的ron,不確定度偏大。95#汽油樣本ron絕對偏差均值的變化趨勢驗證了樣本ron不確定度指標的合理性,本案例中335個95#汽油樣本的不確定度指標評定結果如表2所示。表295#汽油樣本框內相似樣本數統計與不確定度的評定將表2數據按95#汽油框內相似樣本數量n與不確定度u的對應規則進行分段匯總,在每個相似樣本數n的區間范圍內分別統計絕對偏差均值和絕對偏差超過ron重復性誤差的比例(國家標準中ron的重復性誤差為0.3),計算結果如表3所示。表3按照相似樣本數量與不確定度的對應規則分段匯總由表3得出,95#汽油樣本庫中的335個樣本,有121個樣本在各自長方體框內找到45及以上的相似樣本進行性質預測,模型預測性質值與實驗室化驗值的絕對偏差均值較小,其中超過ron重復性誤差的比例僅為13.2%,在此相似樣本數范圍內ron不確定度設定為1。隨著框內樣本數的減少,絕對偏差也在加大。當相似樣本數量小于5時,模型無法預測待測樣本的性質值,在此相似樣本數范圍內ron不確定度度設定為5。由圖4的柱狀圖可知,隨著不確定度增大,樣本預測的絕對偏差均值明顯增大。可見,本方法給出的不確定度,能夠較好反映模型預測性質值與實驗室化驗值的匹配程度。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1