一種基于改進DBN的近紅外光譜分析紡織品棉含量的方法與流程
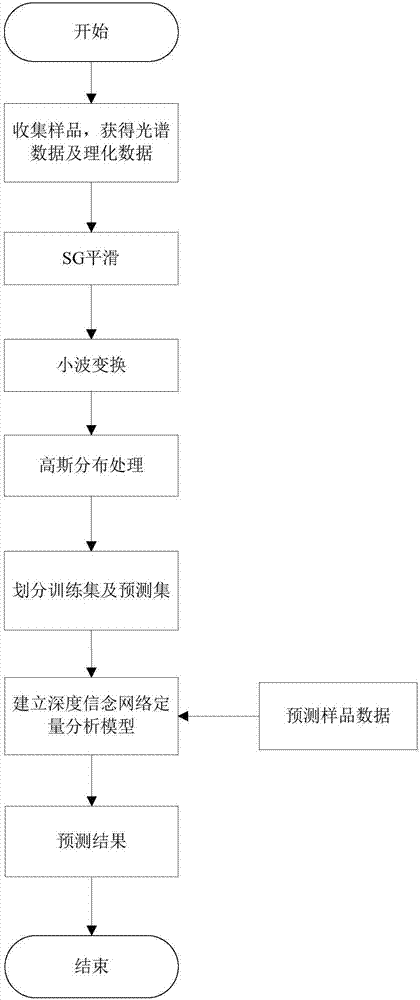
本發明涉及紅外無損檢測技術領域,尤其涉及一種基于改進dbn的近紅外光譜分析紡織品棉含量的方法。
背景技術:
紡織品與人們的生活息息相關,隨著生活水平的提高,紡織品的質量逐漸受到人們的重視。有關紡織品和服裝質量問題的日益突出,諸如成分及含量標識不清、以次充好等,欺騙消費者,不僅影響人們的日常生活,而且擾亂了市場秩序。因此,為了防止紡織品含量混淆不清的情況,應加強紡織品的質量監測,其在紡織品檢測項目中有著重要的地位。
常用的傳統檢測方法操作復雜、費時費力、成本高,無法滿足紡織品質量檢測的需要。近紅外光譜技術以其快速、無損等優點,在紡織品質量檢測方面有較好的應用前景,其原理為對有機物中的含氫集團x-h的倍頻合頻的吸收,通過化學計量方法測得有機物的理化指標,用有效的數學算法將理化值與光譜數據建立函數關系,實現對未知的定性或定量分析。近幾年來,近紅外光譜分析技術在紡織品領域也得到了廣泛的應用。目前存在的基于近紅外光譜法的紡織品棉含量的預測方法,主要為單隱層網絡和支持向量回歸等淺層學習方法,些網絡的共同特點是,它們都使用不超過三層的結構將原始輸入信號變換到一個特征空間。毋庸置疑,淺層學習對于解決簡單的問題非常有效,但是在解決復雜實際應用問題時,往往出現函數表達能力不足等問題,從而會導致結果會出現較大的誤差等問題,進而會導致預測結果不準確。而此時深度學習網絡則僅需要相對較少的計算單元,即在表達同樣的復雜函數時,與淺層網絡相比,深度學習網絡可能僅需要較少的節點和較少的參數。這意味著,在節點數相同的情況下,深度學習網絡通常較淺層網絡的函數表達能力更強。對此情況,本發明設計一種基于改進dbn的紡織品棉含量的預測方法,以提高預測的準確度和可靠性。
技術實現要素:
本發明的目的在于提出一種基于改進dbn的近紅外光譜分析紡織品棉含量的測定方法,旨在解決現有技術中棉滌紡織品棉含量預測準確度和可靠性較低的問題。
本發明所采用的技術方案是:一種基于改進dbn的近紅外光譜分析紡織品棉含量的方法,其特征在于,具體包括以下步驟:
(1)收集樣品,采集樣品的近紅外光譜以及樣品的理化數據;
(2)對獲取的光譜數據進行預處理,得到預處理后的數據;
(3)使用改進dbn方法,建立定量分析模型,通過全局學習算法對網絡進行調整,從而獲得最優紡織品棉含量定量分析模型;
(4)將預測數據導入所述最優紡織品棉含量定量分析模型進行紡織品棉含量的預測分析。
進一步的,所述步驟(1)具體實現如下:使用近紅外光譜儀以及相關漫反射部件對紡織品布料進行正反兩面采集光譜數據,得到正反兩面的平均樣品光譜,并且按定量化學分析方法——硫酸溶解法對紡織品中棉含量進行測定,得到樣品棉含量的理化分析值。
進一步的,所述步驟(2)具體實現如下:
(2.1)對步驟(1)獲得的光譜數據進行sg平滑處理;
(2.2)對步驟(2.1)sg平滑處理后的光譜數據進行小波變換方法對光譜數據進行壓縮,得到壓縮后的近紅外光譜數據矩陣;
(2.3)對步驟(2.2)經小波變換處理后的數據進行高斯分布處理,得到規范化后的數據;
(2.4)使用spxy樣品集劃分方法將步驟(2.3)處理后的樣品數據劃分訓練集及預測集。
進一步的,所述步驟(2.1)中的sg平滑處理具體如下:
(2.1.1)利用最小二乘擬合系數建立數字濾波函數,對移動窗口內的波長點數據進行多項式最小二乘擬合,其表達式如下:
式中,m是多項式的次數;q是平滑窗口點數的中心點;p為平滑窗口點數;
(2.1.2)采用最小二乘法求解待定二項方程式系數,最小二乘擬合的殘差ε如下所示:
令
進一步的,所述步驟(2.2)具體實現如下:將sg平滑處理后的光譜數據進行小波變換處理,小波變換選擇小波母函數為dbn,n為消失矩,得到壓縮后的近紅外光譜數據矩陣。
進一步的,所述步驟(2.3)具體實現如下:將小波變換處理后的光譜進行高斯分布處理;其公式為:
進一步的,所述步驟(3)具體實現如下:將預處理后的近紅外光譜數據以及其對應的理化分析數據作為改進dbn定量分析模型的輸入,建立定量分析模型,改進dbn由多層稀疏高斯受限玻爾茲曼機(spare-grbm)的堆疊和bp神經網絡構成,建立定量分析模型的過程如下:
(3.1)將處理后的近紅外光譜數據矩陣作為網絡的輸入;
(3.2)從上而下,采用對比散度算法訓練得到高斯受限玻爾茲曼機參數,繼續向上逐層對高斯受限玻爾茲曼機進行訓練,并結合隨機隱匿算法來隱藏部分隱含層節點數,即高斯受限玻爾茲曼機的部分輸出置0,對網絡模型進行稀疏化處理,直到最頂層結束,得到稀疏后的dbn模型;直到最頂層結束;該模型對應的能量函數為:
其中,e(v,h)為能量模型函數,v為可見層,h為隱含層,vi為輸入層第i個節點的值,ci為輸入層第i個節點的偏置,σi為第i維輸入的標準差向量,wi,j為第i個輸入層節點與第j個隱含層節點的連接權重,hj為隱含層的第j個節點的值,bj為隱含層第j個節點的偏置;
相對應的條件概率分布為:
其中,sigmoid=1/(1+e-x),n代表高斯分布;
(3.3)以步驟(3.2)得到的參數{ci,bj,wi,j}作為初始值,使用bp算法對整個網絡進行全局訓練,得到最終的網絡參數,從而獲得最優的棉滌紡織品棉含量定量分析模型。
本發明的有益效果是:該改進dbn模型中由高斯分布輸入層來代替傳統深度信念網絡中二進制可視節點,減少了原始光譜數據輸入的遺漏。該網絡由多層稀疏高斯受限玻爾茲曼機組成,采用逐層無監督貪心算法訓練參數,并結合隨機隱匿算法來隱藏部分隱含層節點數,對網絡模型進行稀疏化處理,從而優化網絡的權值,得到稀疏后的dbn架構,從而提高網絡的訓練速率,然后利用bp算法對整個網絡進行全局訓練,得到最終的網絡參數,完成整個模型的訓練。與傳統神經網絡預測模型對比,該模型克服了傳統神經網絡容易陷入局部最優、訓練時間長及預測準確度低等問題,提高了預測的準確度和可靠性。本方法在紡織品質量監測等方面具有良好的應用前景。
附圖說明
圖1為本發明預測方法流程圖;
圖2為本發明樣品原始光譜圖;
圖3為本發明棉滌紡織品棉含量預測值與真實值的擬合曲線圖。
具體實施方法
本發明的具體實施方式提出了一種基于改進dbn的近紅外光譜分析紡織品棉含量的方法,下面結合附及實施例對本發明進一步詳細說明。所描述的實施例為解釋本發明,并非用于限定本發明。
實施例:
(1)收集樣品,采集樣品的近紅外光譜以及樣品的理化數據;具體為:從市場上收集混紡樣品308個,樣品狀態繁多,顏色有深有淺,有染色也有印花,面料有厚也有薄,有平紋也有斜紋,具有一定的代表性。使用supnir-1100近紅外光譜儀對滌棉紡織品的光譜數據進行采集,具體步驟如下:確定布樣后對布樣進行折疊,依據布料厚度進行z字型折疊,可保證布料內外表面不在同一個面上,便于檢測布料的正反兩面;將折疊后的布樣壓平;采集參比光譜后,開始采集樣品漫反射光譜,對布料正反兩面光譜進行采集,從而得到308個樣品正反兩面的平均樣品光譜,并將其用于后續分析,譜區采集范圍:1000-1800nm,實驗均在室溫下進行。并且按定量化學分析方法——硫酸溶解法對滌棉紡織品中棉含量進行測定,得到樣品棉含量的理化分析值。
(2)對獲取的光譜數據進行預處理,得到預處理后的數據;具體為:
(2.1)對步驟(1)獲得的光譜數據進行sg平滑處理;具體為:選用sg平滑窗口點數13對光譜數據進行降噪處理,得到降噪后的光譜數據矩陣。為了壓縮光譜數據,并去除光譜噪聲,保留了光譜的主要信息且大大減小了數據量。
(2.2)對步驟(2.1)sg平滑處理后的光譜數據進行小波變換方法對光譜數據進行壓縮,得到壓縮后的近紅外光譜數據矩陣;具體為:選擇小波母函數為dbn,n為消失矩,消失矩選取2,分解層數為3層,得到壓縮后的近紅外光譜數據矩陣,壓縮后的矩陣數據量縮減為原始數據量的23%,能量保留率達到99%,壓縮后的數據將提高建模速率。
(2.3)對步驟(2.2)經小波變換處理后的數據進行高斯分布處理,得到規范化后的數據;具體為:將上一步處理后的光譜進行高斯分布處理,其公式為:
(2.4)使用spxy(samplesetpartitioningbasedonjointx-ydistance)樣品集劃分方法將步驟(2.3)處理后的樣品數據劃分訓練集及預測集。具體為:將308個樣品按3:1數量比劃分為訓練集及預測集,訓練集樣品數為231個,預測集樣品數為77個,訓練集樣品用于模型的建立,預測集樣品用于驗證模型。
(3)使用改進的深度信念網絡方法,建立定量分析模型,通過全局學習算法對網絡進行調整,從而獲得最優紡織品棉含量定量分析模型;具體為:
將預處理后的近紅外光譜數據以及其對應的理化分析數據作為改進dbn定量分析模型的輸入,建立定量分析模型,改進dbn由多層稀疏高斯受限玻爾茲曼機(spare-grbm)的堆疊和bp神經網絡構成,建立定量分析模型的過程如下:
(3.1)將處理后的近紅外光譜數據矩陣作為網絡的輸入;
(3.2)從上而下,采用對比散度算法訓練得到高斯受限玻爾茲曼機參數,繼續向上逐層對高斯受限玻爾茲曼機進行訓練,并結合隨機隱匿算法來隱藏部分隱含層節點數,對網絡進行稀疏化處理,設置隨機隱匿算法中的參數為0.6,隨機隱藏60%隱含層節點數,即60%輸出置零,從而優化網絡的權值,直到最頂層結束,得到稀疏后的網絡模型;該模型對應的能量函數為:
其中,σi為第i維輸入的標準差,vi為輸入層第i個節點的值,hj為隱含層的第j個節點的值,wi,j為第i個輸入層節點與第j個隱含層節點的連接權重,ci為輸入層第i個節點的偏置,bj為隱含層第j個節點的偏置;相對應的條件概率分布為:
其中,sigmoid=1/(1+e-x),n代表高斯分布。
(3.3)以上一步得到的參數作為初始值,使用bp算法對整個網絡進行全局訓練,得到最終的網絡參數。從而獲得最優的棉滌紡織品棉含量定量分析模型。經過對比多次實驗結果,當網絡結構取[102,50,25,1]時,模型的穩定性較好,從而獲得最優的棉滌紡織品棉含量定量分析模型。
(4)將預測數據導入所述最優紡織品棉含量定量分析模型進行紡織品棉含量的預測分析。具體為:將預測集樣品的77條光譜導入最優棉滌紡織品棉含量定量分析模型,對滌棉紡織品棉含量進行預測,經驗證,預測結果和真實值有很好的線性關系,其擬合曲線如附圖3所示。圖中橫坐標表示預測值,縱坐標代表真實值,并引入相關系數r指標,r表示預測值與真實值之間的擬合程度,當r越大說明預測值與真實值之間的擬合程度越高。網絡預測分析評價標準預測標準差rmsep,其值越小代表模型的預測能力越高。實驗結果r=0.9957,rmsep=0.0253,結果表明所構建改進dbn模型具有較高的預測精度及可靠性。
(5)實驗結果對比。具體為:使用bp神經網絡對上述紡織品樣品數據進行建模預測,其網絡預測結果為相關系數r=0.9321,預測標準差rmsep=0.2362,對比本發明結果可以得出:所構建的改進dbn模型較bp神經網絡模型具有較好的預測精度及可靠性,其對紡織品的質量檢測等方面具有一定的實際意義。
- 還沒有人留言評論。精彩留言會獲得點贊!