基于GPU的視頻SAR回波仿真并行實現方法與流程
本發明屬于雷達信號處理技術領域,尤其涉及一種基于gpu的視頻sar回波仿真并行實現方法,可用于視頻合成孔徑雷達(videosyntheticapertureradar,videosar)成像算法、運動補償算法的驗證以及視頻成像雷達系統性能的評估。
背景技術:
合成孔徑雷達具有全天時、全天候、遠距離和高分辨率成像等特點。而視頻合成孔徑雷達可以對分布式場景目標進行連續多幀的不間斷觀測成像,實現可靠的速度無關運動目標檢測,屬于雷達研究前沿技術。
在新型視頻sar系統付諸實踐之前,為對該系統進行驗證和評估,一般需要對回波信號進行精確仿真。面對視頻sar日益增長的高幀率高分辨寬測繪帶需求,需要對分布式場景目標進行高頻段回波仿真。但是對場景的每個點目標進行回波模擬的計算量巨大,回波信號生成非常耗時。這使得大場景、高幀率要求的視頻sar快速回波仿真成為了研究的熱點。
近年來,隨著圖形處理器(graphicsprocessingunit,gpu)軟硬件技術的日趨成熟,gpu強大的浮點運算和并行處理能力使得業界都在致力于挖掘其潛能,讓它能夠在非圖形領域得到廣泛應用。基于gpu的通用計算研究逐漸深入。
傳統視頻sar回波仿真采用基于中央處理器(centralprocessingunit,cpu)的串行處理方式實現。這種做法的缺點是回波模擬計算時間長、效率低,很難滿足大場景、高幀率的視頻sar回波仿真要求。
技術實現要素:
針對上述現有技術的問題,本發明的目的在于提供一種基于gpu的視頻sar回波仿真并行實現方法,用gpu并行實現視頻sar回波信號仿真的整個過程,具有高實時性和高效率的特點,特別在大場景、高幀率的視頻sar回波仿真方面有顯著優勢。
本發明的技術思路是:結合改進的同心圓算法與gpu并行處理技術實現高效的視頻sar回波仿真。采用統一計算設備架構(computeunifieddevicearchitecture,cuda)的異構編程模式,所述cuda異構編程包括cpu模塊和gpu模塊。用cpu做數據初始化和邏輯性事務管理,具體包括雷達系統參數設置、內存顯存分配、場景數據初始化、cpu-gpu數據傳輸和gpu線程分配與核函數調用。用gpu做回波仿真算法處理,具體包括點目標參數計算、點目標回波信號模擬生成和附加調頻項。
為達到上述目的,本發明采用如下技術方案予以實現。
一種基于gpu的視頻sar回波仿真并行實現方法,所述方法基于作為主控制器的cpu和作為設備端的gpu;所述方法包括如下步驟:
步驟1,設置cpu內存為頁鎖定內存,且采用連續地址訪問方式訪問gpu顯存;
步驟2,在所述cpu中設置雷達系統參數值,并將所述雷達系統參數值存儲在cpu的內存中;進而將所述雷達系統參數值從cpu內存復制到gpu的常量存儲器中;所述雷達系統參數值至少包含雷達的發射脈沖周期、雷達帶寬、雷達斜距采樣間隔、雷達方位向波束寬度以及雷達平臺的高度以及運行速度;
步驟3,獲取一幅sar圖像數據作為視頻sar回波仿真的原始場景圖像數據,所述sar圖像為二維灰度圖像,且所述二維灰度圖像中像素點的灰度值用于表征對應該像素點位置處的點目標的后向散射系數;并將所述原始場景圖像數據存儲于cpu內存中;進而將cpu內存中的原始場景圖像數據經pcie接口傳送到gpu顯存中;
步驟4,設置第一核函數,并行計算所述原始場景圖像數據中每個點目標的空間坐標及每個點目標的后向散射系數;
步驟5,設置第二核函數,并行計算每個方位采樣時刻雷達平臺的空間坐標以及每個方位采樣時刻雷達平臺與每個點目標的瞬時斜視角;
步驟6,設置第三核函數,對所有采樣時刻的所有點目標進行分塊,計算得到多個分塊數據,對每個分塊數據進行塊內點目標的回波信號的疊加,得到每個分塊數據內的點目標在所有方位采樣時刻的一維距離像數據;
步驟7,設置第四核函數,對所有分塊數據的一維距離像數據進行塊間疊加,從而得到雷達所有方位時刻的初始回波信號;
步驟8,設置第五核函數,將所述雷達所有方位時刻的初始回波信號變換到頻域,并在頻域乘以調頻因子后,再變換到時域進行線性調頻處理,得到最終經過線性調頻處理后的回波信號,并將所述最終經過線性調頻處理后的回波信號作為視頻sar回波信號;
步驟9,將所述視頻sar回波信號從gpu顯存復制到cpu內存。
本發明技術方案的特點和進一步的改進為:
(1)步驟3中,將cpu內存中的原始場景圖像數據分成多個數據流,使一個數據流經pcie接口到gpu顯存的傳輸過程與另一個數據流在gpu中的數據處理同時進行。
(2)在cpu端為第一核函數分配二維線程網格,所述二維線程網格由多個線程塊組成,每個線程塊由多個線程組成,且每個線程計算一個點目標的空間坐標和后向散射系數;步驟4具體包括如下子步驟:
(4a)獲取原始場景圖像數據中像素點(m,n),將像素點(m,n)作為原始場景圖像中的一個對應點目標,按照所述雷達斜距采樣間隔將所述點目標均勻分布在二維坐標平面上,得到該點目標在所述二維坐標平面上的坐標(xm,n,ym,n),進而得到該點目標的空間坐標(xm,n,ym,n,zm,n),其中,xm,n表示像素點(m,n)在x軸方向上的坐標,ym,n表示像素點在y軸方向上的坐標,zm,n表示像素點在z軸方向上的坐標,且zm,n=0;m=1,2,..,m,n=1,2,..,n,m為原始場景圖像的長度,n為原始場景圖像的寬度;
(4b)以原始場景圖像數據中每個像素點(m,n)處的灰度值表征對應點目標的后向散射系數,并附加一個隨機相位因子,得到該點目標的后向散射系數
(3)在cpu端為第二核函數分配二維線程網格,采用所述二維線程網格中對應方位采樣時刻的線程計算每個方位采樣時刻雷達平臺的空間坐標,再采用所述二維線程網格中的每個線程計算一個瞬時斜視角;步驟5具體包括如下子步驟:
(5a)雷達平臺以速度v沿x軸正方向即方位向做勻速直線運動,對雷達平臺在方位向的運動時間以所述發射脈沖周期為間隔進行采樣得到各方位采樣時刻,并得到每個方位采樣時刻雷達平臺的空間坐標(xi,yi,zi),其中,下標i表示第i個方位采樣時刻,且i大于零;根據第i個方位采樣時刻雷達平臺的空間坐標(xi,yi,zi)以及原始場景圖像數據中第(m,n)個點目標的空間坐標(xm,n,ym,n,zm,n),計算得到第i個方位采樣時刻雷達平臺與第(m,n)個點目標的瞬時斜視角
(5b)遍歷所有方位采樣時刻,得到每個方位采樣時刻雷達平臺的空間坐標,從而計算得到每個方位采樣時刻雷達平臺與每個點目標的瞬時斜視角。
(4)在cpu端為所述第三核函數分配三維線程網格,步驟6具體包括如下子步驟:
(6a)對所有方位采樣時刻的所有點目標進行分塊,每個分塊數據的大小不超過可用的gpu顯存空間;
(6b)三維線程按照分塊順序串行計算每個分塊數據內點目標對應的回波信號。
(5)子步驟(6b)具體包括如下子步驟:
每個分塊數據內點目標對應的回波信號的計算過程如下,且各方位采樣時刻的回波數據的計算是并行進行的:
(6b1)根據第i個方位采樣時刻該分塊數據中雷達平臺與每個點目標的瞬時斜視角,判斷該分塊數據中每個點目標在第i個方位采樣時刻是否在雷達方位向波束寬度范圍內,若在第i個方位采樣時刻雷達平臺與某一點目標的瞬時斜視角小于或者等于所述雷達方位向波束寬度,則該點目標在雷達方位向波束寬度范圍內;
(6b2)計算該分塊數據中每個位于雷達方位向波束寬度范圍內的點目標到雷達平臺的斜距
(6b2)從而得到該分塊數據中位于雷達方位向波束寬度范圍內的每個點目標在第i個方位采樣時刻對應的回波信號
其中,k為sinc插值點數,u表示插值點標號,且u=1,...,k,σ(m,n)表示點目標后向散射系數,b表示發射信號帶寬,τ(u)表示快時間,c表示光速;
(6b3)將該分塊數據中位于雷達方位向波束寬度范圍內的所有點目標在第i個方位采樣時刻對應的回波信號采用cuda原子加操作進行時域疊加得到該分塊數據在第i個方位采樣時刻的回波信號
與現有技術相比,本發明的有益效果是:(1)本發明對gpu顯存進行合并訪存,并通過合理分配線程塊大小,增加每個線程擁有的寄存器和共享內存資源,充分發揮了gpu顯存和片內高速存儲器高傳輸帶寬的優勢,不僅實現了數據并行,還實現了指令級并行;(2)本發明利用流處理將數據傳輸和核函數執行分成多個流進行處理,利用流與流之間的并行執行來隱藏部分數據傳輸時間,解決了cpu-gpu的io傳輸瓶頸問題,有效節省了cpu-gpu數據傳輸時間;(3)本發明為回波模擬生成核函數分配三維線程網格,并行計算各方位時刻的回波信號,與傳統各方位時刻回波信號串行計算相比,極大地提高了計算的并行度,有效節省了回波模擬生成的時間;(4)本發明采用線程外推的方法,對所有點目標分塊進行回波模擬生成和疊加,分塊大小根據顯存空間自動調整,克服了因目標回波數據量過大而造成顯存溢出的問題,滿足了大場景高幀率視頻sar回波仿真要求;(5)本發明利用原子加操作進行點目標回波信號的時域疊加,與傳統回波信號的并行歸約求和相比,減少了對顯存空間和計算資源的開銷,有效提高了回波信號疊加的實時性。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
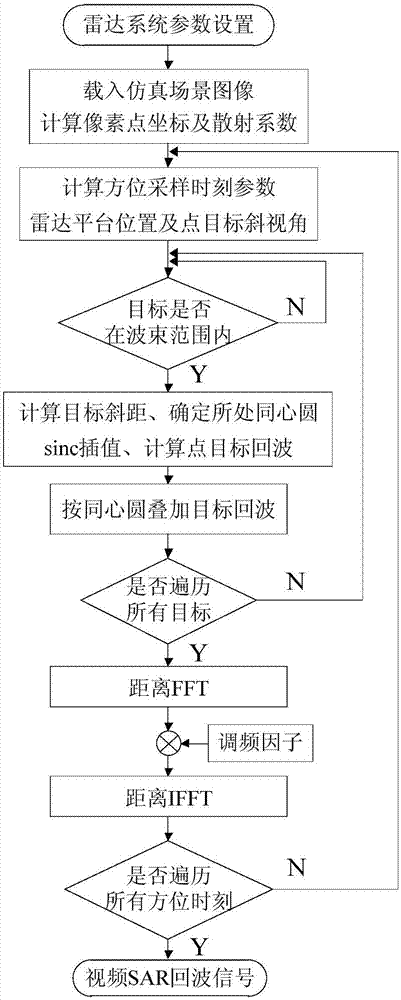
圖1為本發明實施例提供的改進同心圓算法的流程示意圖;
圖2為本發明實施例提供的cuda異構編程的流程示意圖;
圖3為本發明實施例提供的合并訪存與結構體數組替換示意圖;
圖4為本發明實施例提供的流處理的過程示意圖;
圖5為本發明實施例提供的雷達回波獲取的幾何示意圖;
圖6為本發明實施例提供的三維線程映射示意圖;
圖7為本發明實施例提供的點目標分塊與回波時域疊加示意圖;
圖8為本發明實施例提供的視頻sar回波仿真成像結果圖;
圖9為本發明實施例提供的視頻sar回波仿真運行時間圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。
本發明實施例提供一種基于gpu的視頻sar回波仿真并行實現方法,結合改進的同心圓算法與gpu并行技術實現高效的視頻sar回波仿真。采用cuda異構編程模式,所述cuda異構編程包括cpu模塊和gpu模塊。用cpu做數據初始化和邏輯性事務管理,具體包括雷達系統參數設置、內存顯存分配、場景數據初始化、cpu-gpu數據傳輸和gpu線程分配與核函數調用。用gpu做回波仿真算法處理,具體包括點目標參數計算、點目標回波信號模擬生成和附加調頻項。
具體的,所述改進同心圓算法的流程圖如圖1所示。
所述改進的同心圓算法是一種適用于分布式場景目標的快速時域回波仿真方法。在分布式場景目標中,斜距間隔小于斜距采樣間隔的相鄰點目標將落到同一距離單元上,形成許多以雷達相位中心為原點的同心圓,位于相同圓上的所有點目標的回波信號被累加到同一個距離單元上。當按每個同心圓累加點目標回波信號時,得到分布式場景目標的一維距離像。
所述cuda異構編程模型是將cpu作為主控制器(host),負責進行邏輯性強的事務管理和串行計算相關的工作;將gpu作為設備端(device),專注于執行高度線程化的并行處理任務,兩者協調一致完成工作。所述cuda異構編程的流程圖如圖2所示,包括:
(1)所述雷達系統參數設置即先在cpu端設置雷達系統參數值,如發射脈沖周期、帶寬、斜距采樣間隔、方位向波束寬度及雷達平臺速度與高度等。先將參數值存入內存,再將參數值傳送給gpu端的常量存儲器(constantmemory),以供gpu模擬回波信號時使用。
具體的,先在cpu端初始化雷達系統參數值,再利用cuda的常量復制函數將cpu內存的雷達系統參數值通過pci-e接口傳送給gpu的常量存儲器。由于雷達系統參數值在回波模擬計算中頻繁使用,將系統參數值存儲在常量存儲器中,不僅可以保護參數值不被非法修改,而且常量存儲器的訪問速度快于顯存,可以節省數據讀取時間。
(2)所述內存顯存分配即在cpu端使用頁鎖定內存,在gpu端對顯存采用合并訪存方式。
(2.1)頁鎖定內存分配:
在cuda中,cpu端的內存分為兩種:可分頁內存和頁鎖定內存。可分頁內存即通過操作系統api分配的存儲空間,內存中的數據可能被存入低速的虛擬內存中。頁鎖定內存始終不會分配低速的虛擬內存,能夠保證數據存放在快速的物理內存中,并且能夠通過dma加速與gpu的通信。
具體的,通過cuda的頁鎖定內存分配函數和釋放函數為cpu端的數據分配頁鎖定內存,并在使用完成后釋放頁鎖定內存。
(2.2)顯存合并訪問:
所述顯存合并訪問即連續地址的顯存訪問,且速度快于非連續地址的顯存訪問。合并訪存一般用于對顯存中數組的存取,對于簡單數組,cuda顯存分配函數已經確保數組在顯存中連續對齊存放,對于結構體數組經常發生非連續訪問,造成訪存事件增加,訪存時延增大。
具體的,合并訪存與結構體數組替換如圖3所示,通過將結構體數組替換為數組的結構體,或拆分為多個簡單數組,以實現顯存合并訪問,進而節省數據存取時間,有效利用顯存帶寬。
(3)所述場景數據初始化即以一幅原始sar圖像作為回波仿真的分布式場景目標,將場景圖像數據由cpu內存傳送到gpu顯存,以供gpu模擬回波信號時使用。
改進的同心圓法以一幅原始sar圖像作為分布式場景目標進行回波仿真,所述原始sar圖像為二維灰度圖像,以圖像像素點的灰度值表征對應位置點目標的后向散射系數幅度值。
具體的,先在cpu端將讀取的sar圖像灰度矩陣存入頁鎖定內存,再利用cuda的數組復制函數將cpu內存的場景圖像數據通過pci-e接口傳送給gpu顯存。
(4)所述cpu-gpu數據傳輸即通過cpu與gpu之間的pci-e接口將上述的雷達系統參數及場景圖像數據由cpu端傳送給gpu端進行運算,再將最終的視頻sar回波數據由gpu端傳回cpu端。為了減少cpu-gpu數據傳輸時延,采用流處理。
具體的,利用cuda的數組復制函數將cpu端頁鎖定內存的場景圖像數據通過pci-e接口傳送給gpu顯存,最終將生成的視頻sar回波數據以同樣方式由gpu端傳回到cpu端。
流處理將數據傳入gpu、核函數執行和數據傳出gpu的整個過程分成多個流進行處理,每個流順序執行一系列操作,流與流之間異步并行執行。這樣,一個流的cpu-gpu數據傳輸和另一個流的核函數執行可以同時進行,以隱藏部分cpu-gpu數據傳輸時間。從而解決了cpu-gpu的io傳輸瓶頸問題,有效地節省了數據傳輸時間。所述流處理的過程示意圖如圖4所示。
(5)所述gpu線程分配與核函數調用即根據gpu端核函數(kernel)所處理的數據模型,分配相適宜的gpu線程網格(grid),線程網格劃分為一定數量的線程塊(block),每個線程塊又由一定數量的線程(thread)組成。調用核函數將線程網格中的各線程映射到數據模型中的各數據元素,使每個線程計算對應的一個數據元素。
在線程塊中分配較少的線程。本實施例為每個線程塊分配128個線程,在低設備占有率的情況下,增加了每個線程擁有的寄存器和共享內存資源,利用盡可能多的高速存儲器來提高數據存取速度。
(5.1)kernel1函數實現:
該核函數用于并行計算分布式場景目標中各點目標的空間坐標及其后向散射系數。
將原始sar圖像即二維灰度圖像中各像素點(m,n)按所述雷達系統參數中的斜距采樣間隔均勻分布在二維坐標平面上,計算得到各像素點的坐標即為分布式場景目標中各點目標的空間坐標(xm,n,ym,n,zm,n)。所述點目標的空間坐標不考慮起伏高度,即zm,n=0。
以原始sar圖像即二維灰度圖像中(m,n)處的像素點灰度值表征對應點目標的后向散射系數幅度值,并附加一個隨機相位因子,得到該點目標的后向散射系數為
具體的,由于場景目標數據是二維結構體數組,可以在cpu端為kernel1函數分配二維線程網格,線程網格由一定數量的線程塊組成,每個線程塊又由一定數量的線程組成。調用kernel1函數將二維線程網格映射到場景二維結構體數組,使每個線程計算一個點目標的空間坐標和后向散射系數即場景二維結構體數組中的一個數據元素。
(5.2)kernel2函數實現:
該核函數用于并行計算各方位采樣時刻雷達平臺的空間坐標及雷達與各點目標的瞬時斜視角。
本發明實施例假設雷達工作在條帶模式,雷達回波獲取的幾何關系如圖5所示。雷達平臺飛行高度為h,并以速度v沿x軸正方向即方位向做勻速直線運動,對雷達平臺在方位向的運動時間以所述雷達系統參數中的發射脈沖周期為間隔進行采樣得到各方位采樣時刻i。計算雷達平臺在各方位采樣時刻的空間坐標(xi,yi,zi)。由各方位采樣時刻雷達平臺的空間坐標(xi,yi,zi)及分布式場景中各點目標的空間坐標(xm,n,ym,n,zm,n)可計算求得各方位采樣時刻雷達平臺與各點目標的瞬時斜視角
具體的,由于分布式場景中各點目標在各方位時刻的瞬時斜視角數據構成二維數組,其中一維表示方位時刻,另一維表示點目標數。可以在cpu端為kernel2函數分配二維線程網格,調用kernel2函數將二維線程網格映射到瞬時斜視角二維數組,先用其中一維對應方位采樣時刻的線程計算各方位采樣時刻雷達平臺的空間坐標(xi,yi,zi)。再使二維線程網格中每個線程計算一個瞬時斜視角。
(5.3)kernel3和kernel4函數實現:
該核函數用于點目標回波模擬生成計算,具體包括判斷點目標是否在方位向波束寬度范圍內、計算雷達到點目標的斜距、點目標回波幅度sinc插值和點目標回波信號分塊疊加。
改進的同心圓法在常規同心圓法基礎上還對點目標回波信號的幅度進行sinc插值處理即得到插值點數個子回波信號,用所有子回波信號的幅度模擬點目標回波信號的脈沖波形,即所有子回波信號構成了一個點目標回波信號。
下面詳細敘述視頻sar回波模擬生成并行實現的整個過程:
由于視頻sar回波數據是三維數據模型(sinc插值點數、點目標數和方位向點數),可以在cpu端為kernel3函數分配三維線程網格,調用kernel3函數將三維線程網格映射到回波三維數據模型,使每個線程計算三維數據中的一個元素即一個子回波數據。每個線程依次進行如下操作:根據點目標的瞬時斜視角是否滿足θi,m,n≤θbw,判斷點目標是否在方位向波束寬度范圍內,其中θbw為所述雷達系統參數的方位向波束寬度;對位于方位向波束寬度范圍內的點目標計算其到雷達的斜距
為防止gpu顯存因點目標回波模擬計算時數據量過大而溢出,采用線程外推的方法,使有限線程可以遍歷所有點目標,即對所有點目標按一定數量進行分塊處理,分塊確保數據大小不超過可用顯存空間。由三維線程按分塊順序串行計算各分塊的回波信號,并進行塊內點目標回波信號疊加及塊間回波信號疊加,最終得到所有方位時刻的回波信號。點目標分塊與回波時域疊加如圖7所示。
塊內點目標回波信號疊加具體采用cuda原子加操作實現。如圖7右下圖所示,首先為塊內各點目標分配插值點數大小的顯存空間用于存儲點目標的子回波信號,再用cuda原子加操作將點目標回波信號(子回波信號構成的數組)疊加到對應的距離采樣點(距離單元)處,其中距離采樣點數遠大于sinc插值點數。各方位采樣時刻都進行上述操作,從而實現各分塊點目標回波信號的并行疊加。采用cuda原子加操作實現點目標回波信號疊加減少了顯存空間占用和非必要計算開銷,節省了點目標回波信號疊加的時間。調用kernel4函數,對上述各分塊數據即點目標回波信號疊加后的二維矩陣(距離采樣點數,方位采樣點數)進行塊間數據疊加,得到各方位采樣時刻的回波信號(距離采樣點數,方位采樣點數)即初始回波信號。
(5.4)kernel5函數實現:
該核函數用于將(5.3)計算得到的初始回波信號由時域變換到頻域,乘以調頻因子再變換到時域,做線性調頻處理,得到最終的經線性調頻的回波信號即視頻sar回波信號。
具體的,調用cuda的cufft函數即可將模擬生成的初始回波信號由時域快速變換到頻域,乘以調頻因子后再快速變換到時域,以得到最終的線性調頻回波信號即視頻sar回波信號。
(6)為上述各kernel函數所分配的線程網格由一定數量的線程塊組織而成,每個線程塊又由一定數量的線程組成。本實施例對各kernel函數的線程網格進行優化分配,即在線程塊中分配較少的線程,本實施例為每個線程塊分配128個線程,實現在低設備占有率的情況下,增加每個線程擁有的寄存器和共享內存資源,利用盡可能多的高速存儲器來提高數據存取速度。高速存儲器中共享內存帶寬是顯存的7.6倍,寄存器帶寬是共享內存的6倍。
本發明的結果可由實測數據處理結果進一步說明:
圖8為本發明實施例提供的由上述模擬生成的視頻sar回波信號經成像算法處理后截取的視頻sar單幀圖像,所成圖像質量良好。圖9為本發明實施例提供的視頻sar回波仿真的運行時間圖,從回波仿真運行時間上看,基于gpu的視頻sar回波仿真比基于cpu的視頻sar回波仿真具有明顯的速度提升,極大地縮短了仿真運行時間,驗證了并行實現方案設計的可行性及有效性。
本領域普通技術人員可以理解:實現上述方法實施例的全部或部分步驟可以通過程序指令相關的硬件來完成,前述的程序可以存儲于計算機可讀取存儲介質中,該程序在執行時,執行包括上述方法實施例的步驟;而前述的存儲介質包括:rom、ram、磁碟或者光盤等各種可以存儲程序代碼的介質。
以上所述,僅為本發明的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本發明揭露的技術范圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應以所述權利要求的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!