一種基于FOA優化的SOM?RBF的壓力傳感器溫度補償方法與流程
本發明涉及壓力傳感器溫度補償方法,尤其涉及一種基于FOA優化的SOM-RBF的壓力傳感器溫度補償方法。
背景技術:
壓力傳感器中,硅壓阻式壓力傳感器使用最為廣泛,發展最為成熟。它利用半導體材料的壓阻效應來進行壓力測量,體積小、靈敏度高。工程應用中由于硅材料和封裝介質受溫度的影響,導致傳感器的實際輸出發生漂移,傳感器溫度補償問題是提高傳感器性能的一個關鍵環節。壓力傳感器主要有兩種溫度補償方法:硬件補償和軟件補償。硬件補償方法存在調試困難、精度低、成本高、通用性差等缺點,不利于工程應用。利用數字信號處理技術的軟件補償能夠克服以上缺點。
影響壓力傳感器溫度特性的因素很多,表現為復雜的非線性,傳統的線性軟件補償無法滿足智能傳感器的高精度要求。神經網絡具有優秀的非線性系統建模和逼近能力,可實現自適應和自學習,廣泛用于非線性系統的回歸和擬合、并行處理和優化計算,非常適合應用于解決傳感器的溫度補償問題。
BP神經網絡可用于傳感器溫度補償,利用誤差反向傳播原理,可達到一定輸出精度,但網絡相對復雜,隨機參數較多。
技術實現要素:
本發明的目的在于克服上述現有技術的缺點和不足,提供一種基于FOA優化的SOM-RBF的壓力傳感器溫度補償方法。具有較好的補償精度,一定的魯棒性和泛化能力。
本發明通過下述技術方案實現:
一種基于FOA優化的SOM-RBF的壓力傳感器溫度補償方法,包括步驟:
步驟(1):將壓力標定實驗采集得到的樣本數據歸一化并隨機分為訓練數據和測試數據,以訓練數據建立基本RBF網絡模型,利用迭代誤差收斂速度和精度穩定性確定RBF網絡隱含層節點數;具體包括:
11)建立RBF網絡確定隱含層節點數:
若輸入向量Xm=[x1,x2,…,xm]T為m列向量,隱含層具有n個隱含節點,則第i個隱含節點的輸出為Φ(||Xm-Xi||),Xi=[xi1,xi2,…,xim]T為基函數的中心;
輸出層包含若干線性單元,每個線性單元與所有隱含節點相連,ωij為第i個隱含層到第j個輸出層的權值,網絡的最終輸出是隱含節點輸出的線性加權和;
設實際輸出為Yk=[yk1,yk2,…,ykm]T,則當訓練樣本為Xk時,網絡的第J個輸出神經元的輸出為:
基函數選用高斯函數,則:
其中σ為網絡擴展值;
隨機初始化網絡參數,取輸出最大相對誤差和均方差作為評價標準,并給出目標值;
隱含層節點數從最小值開始向最大值迭代,記錄誤差變化并根據目標值確定節點數。
步驟(2):利用測試數據和隱含層節點數建立自適應SOM網絡得到RBF網絡中心值;具體包括:
21)構造SOM網絡確定網絡中心值:SOM采用拓撲學習,不僅更新獲勝神經元的權值,每個神經元拓撲結構內臨近的神經元權值也會得到更新,使其不僅可學習輸入樣本的分布,還能識別輸入樣本的拓撲結構;
22)SOM網絡的訓練步驟為:
1)數據處理及參數初始化:選取訓練輸入數據每個數據為m維向量x=[x1,x2,…,xm],并做歸一化處理;隨機初始化網絡權值ωij,設置最大和最小學習率lrmax和lrmin,設置領域最大值和最小值dmax和dmin;其中i=1,2,…,m為輸入向量維數,j=1,2,…,n為RBF隱含層節點個數;
2)構造網絡并輸入數據:確定網絡拓撲結構(鄰域范圍)并構造SOM網絡,將樣本數據輸入,并計算歐式距離d=||x-ω||,d值最小的神經元即為獲勝神經元;
3)更新網絡權值:對獲勝的神經元拓撲領域內的神經元,采用Kohonen規則進行權值更新:
ω(k+1)=ω(k)+lr(x-ω(k)
4)迭代,更新學習率和拓撲鄰域:對網絡進行迭代計算,并根據迭代次數更新網絡學習率和鄰域值:
其中N為最大迭代次數,i為本次迭代次數;
5)判斷是否達到最大迭代次數或ω值變化很小,則學習過程結束。
步驟(3):采用FOA對RBF網絡擴展參數進行尋優得到完整的優化RBF網絡,最后將測試數據輸入網絡得到補償輸出;具體包括:
31)利用獲得的中心值代入RBF網絡基函數,將訓練數據最終輸出的誤差最大值作為FOA味道濃度的適應度函數,并進行迭代,獲取網絡擴展值;
基于果蠅覓食行為的FOA優化算法基本步驟如下:
1)給定群體規模Popsize,最大迭代數maxgen,隨機初始化種群位置(X_axia,Y_axia);
2)設定果蠅個體利用嗅覺搜尋食物的隨機方向與距離:
Xi=X_axia+RandomValue-x
Yi=Y_axia+RandomValue-y
3)因為食物位置不能確定,利用果蠅個體與原點之間距離的倒數作為味道濃度判定值
4)將味道濃度判定值代入味道濃度判定函數(適應值函數),計算果蠅個體位置的味道;
5)找出該果蠅群體中味道濃度最佳的果蠅,記錄并保留最佳味道濃度值BestSmell與其X,Y坐標,這時候果蠅群體利用視覺向該位置飛去;
6)進入迭代尋優,重復執行步驟(2)~(5)并判斷最佳味道濃度是否優于前一迭代最佳味道濃度,直至迭代次數達到最大迭代數。
本發明相對于現有技術,具有如下的優點及效果:
本發明以結構簡單、實時性好、收斂速度快的RBF神經網絡作為基礎模型,利用自組織聚類網絡,選取RBF網絡中心值,克服了以往算法隨機選取中心導致網絡不穩定和計算量大的問題,提高了模型的泛化能力,然后采用果蠅算法對RBF網絡的基函數擴展值進行尋優,避免了傳統RBF算法依據經驗選取擴展值導致的數據不匹配問題。結合傳感器變溫實驗與提出的溫度補償算法,補償結果表明模型具有較好的補償精度,一定的魯棒性和泛化能力。
附圖說明
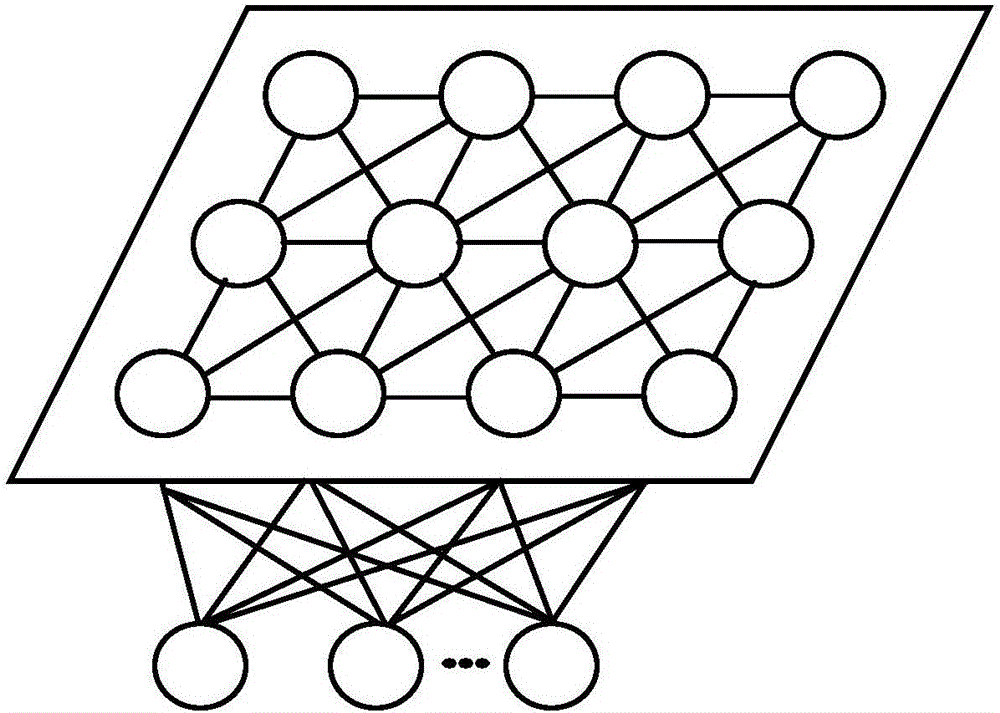
圖1是RBF神經網絡模型。
圖2是自組織映射網絡結構。
圖3是基于FOA優化SOM-RBF算法流程圖。
具體實施方式
下面結合具體實施例對本發明作進一步具體詳細描述。
實施例
如圖1至3所示。本發明公開了基于FOA優化的SOM-RBF的壓力傳感器溫度補償方法,可通過如下步驟實現。
(1)建立RBF網絡確定隱含層節點數:
RBF網絡的結構如附圖1所示:
若輸入向量Xm=[x1,x2,…,xm]T為m列向量,隱含層具有n個隱含節點,則第i個隱含節點的輸出為為基函數的中心。輸出層包含若干線性單元,每個線性單元與所有隱含節點相連,ωij為第i個隱含層到第j個輸出層的權值,網絡的最終輸出是隱含節點輸出的線性加權和。設實際輸出為Yk=[yk1,yk2,…,ykm]T,則當訓練樣本為Xk時,網絡的第J個輸出神經元的輸出為:
基函數一般選用高斯函數,則:
其中σ為網絡擴展值。
隨機初始化網絡參數,取輸出最大相對誤差和均方差作為評價標準,并給出目標值。隱含層節點數從最小值開始向最大值迭代,記錄誤差變化并根據目標值確定節點數。
(2)構造SOM網絡確定網絡中心值:SOM采用拓撲學習,不僅更新獲勝神經元的權值,每個神經元拓撲結構內臨近的神經元權值也會得到更新,使其不僅可學習輸入樣本的分布,還能識別輸入樣本的拓撲結構,SOM網絡模型如附圖2所示。
SOM網絡的訓練步驟為:
1)數據處理及參數初始化:選取訓練輸入數據每個數據為m維向量x=[x1,x2,…,xm],并做歸一化處理;隨機初始化網絡權值ωij,設置最大和最小學習率lrmax和lrmin,設置領域最大值和最小值dmax和dmin。其中i=1,2,…,m為輸入向量維數,j=1,2,…,n為RBF隱含層節點個數。
2)構造網絡并輸入數據:確定網絡拓撲結構(鄰域范圍)并構造SOM網絡,將樣本數據輸入,并計算歐式距離d=||x-ω||,d值最小的神經元即為獲勝神經元。
3)更新網絡權值:對獲勝的神經元拓撲領域內的神經元,采用Kohonen規則進行權值更新:
ω(k+1)=ω(k)+lr(x-ω(k)
4)迭代,更新學習率和拓撲鄰域:對網絡進行迭代計算,并根據迭代次數更新網絡學習率和鄰域值:
其中N為最大迭代次數,i為本次迭代次數。
5)判斷是否達到最大迭代次數或ω值變化很小,則學習過程結束。
(3)利用獲得的中心值代入RBF網絡基函數,將訓練數據最終輸出的誤差最大值作為FOA味道濃度的適應度函數,并進行迭代,獲取網絡擴展值。
基于果蠅覓食行為的FOA優化算法基本步驟如下:
1)給定群體規模Popsize,最大迭代數maxgen,隨機初始化種群位置(X_axia,Y_axia)。
2)設定果蠅個體利用嗅覺搜尋食物的隨機方向與距離:
Xi=X_axia+RandomValue-x
Yi=Y_axia+RandomValue-y
3)因為食物位置不能確定,利用果蠅個體與原點之間距離的倒數作為味道濃度判定值
4)將味道濃度判定值代入味道濃度判定函數(適應值函數),計算果蠅個體位置的味道。
5)找出該果蠅群體中味道濃度最佳的果蠅,記錄并保留最佳味道濃度值BestSmell與其X,Y坐標,這時候果蠅群體利用視覺向該位置飛去。
6)進入迭代尋優,重復執行步驟2~5并判斷最佳味道濃度是否優于前一迭代最佳味道濃度,直至迭代次數達到最大迭代數。
如上所述,便可較好地實現本發明。
本發明的實施方式并不受上述實施例的限制,其他任何未背離本發明的精神實質與原理下所作的改變、修飾、替代、組合、簡化,均應為等效的置換方式,都包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!