使用聽覺數據的碰撞規避的制作方法
本發明涉及在自主車輛中的執行障礙物規避。
背景技術:
自主車輛裝備有檢測其環境的傳感器。算法評估傳感器的輸出以及識別障礙物。然后導航系統可以轉向車輛、制動和/或加速以既避開識別的障礙物又達到需要的目的地。傳感器可以既包括例如攝像機的成像系統,也包括radar(雷達)或lidar(激光雷達)傳感器。
公開在此處的系統和方法提供一種用于檢測障礙物的改善方法。
技術實現要素:
根據本發明,提供一種用于自主車輛的系統,包含:
安裝到自主車輛的兩個或多個麥克風;
控制器,控制器執行:
預處理器,預處理器編程為檢測在來自兩個或多個麥克風的兩個或多個音頻流中的音頻特征;
碰撞規避模塊,碰撞規避模塊編程為分類音頻特征和到音頻特征源頭的方向,以及如果聲源的類別是車輛,那么關于該方向啟動障礙物規避。
根據本發明的一個實施例,其中碰撞規避模塊還編程為,通過執行能有效規避與音頻特征的源頭碰撞的自主車輛的轉向執行器、加速器執行器以及制動器執行器中的至少一個,來啟動相對于到音頻特征源頭的方向的障礙物規避。
根據本發明的一個實施例,其中碰撞規避模塊還編程為:
接收來自安裝到自主車輛的兩個或多個攝像機的兩個或多個圖像流;
在多個車輛圖像中識別一組可能障礙物;
評估自主車輛和一組可能障礙物以及音頻特征的源頭之間的可能碰撞;以及
激活能有效規避與該組可能障礙物的碰撞的自主車輛的轉向執行器、加速器執行器以及制動器執行器中的至少一個。
根據本發明的一個實施例,其中兩個或多個麥克風配置為當音頻特征源頭不處于兩個或多個攝像機中的任何攝像機的視野里時檢測來自音頻特征源頭的聲音。
根據本發明的一個實施例,其中碰撞規避模塊還編程為通過濾波兩個或多個音頻流以獲得各自包括一個或多個音頻特征的兩個或多個濾波后信號來識別音頻特征。
根據本發明的一個實施例,其中碰撞規避模塊還編程為通過消除來自兩個或多個音頻流的環境噪音來濾波兩個或多個音頻流。
根據本發明的一個實施例,其中碰撞規避模塊還編程為:
通過將音頻特征輸入到機器學習模型來分類音頻特征。
根據本發明的一個實施例,其中機器學習模型輸出表明音頻特征對應于車輛的可能性的置信值。
根據本發明的一個實施例,其中機器學習模型是深度神經網絡。
根據本發明的一個實施例,其中碰撞規避模塊還編程為通過評估音頻特征之間的時間差來檢測到音頻特征源頭的方向。
根據本發明,提供一種用于在自主車輛中障礙物檢測的方法,方法包含:
由包括一個或多個處理裝置的控制器接收來自安裝到自主車輛的兩個或多個麥克風的兩個或多個音頻流;
由控制器檢測在兩個或多個音頻流中的音頻特征;
由控制器根據音頻特征檢測到聲源的方向;
由控制器根據音頻特征識別聲源的類別;以及
由控制器確定聲源的類別是車輛,
響應于確定聲源的類別是車輛,啟動相對于到聲源的方向的障礙物規避。
根據本發明的一個實施例,該方法還包含通過執行能有效規避與聲源的碰撞的自主車輛的轉向執行器、加速器執行器以及制動器執行器中的至少一個來啟動相對于到聲源的方向的障礙物規避。
根據本發明的一個實施例,該方法還包含:
由控制器接收來自安裝到自主車輛的兩個或多個攝像機的兩個或多個圖像流;
由控制器在多個車輛圖像中識別一組可能障礙物;
由控制器評估自主車輛和該組可能障礙物以及聲源之間的可能碰撞;以及
由控制器激活能有效規避與該組可能障礙物的碰撞的自主車輛的轉向執行器、加速器執行器以及制動器執行器中的至少一個。
根據本發明的一個實施例,其中聲源不在兩個或多個攝像機中的任何攝像機的視野內。
根據本發明的一個實施例,其中識別音頻特征包含由控制器濾波兩個或多個音頻流以獲得各自包括一個或多個音頻特征的兩個或多個濾波信號。
根據本發明的一個實施例,其中濾波兩個或多個音頻流還包含消除來自兩個或多個音頻流的環境噪聲。
根據本發明的一個實施例,其中根據音頻特征識別聲源的類別包含由控制器將音頻特征輸入到機器學習模型。
根據本發明的一個實施例,該方法還包含由機器學習模型輸出表明音頻特征對應于車輛的可能性的置信值。
根據本發明的一個實施例,其中機器學習模型是深度神經網絡。
根據本發明的一個實施例,其中根據音頻特征檢測到聲源的方向包含由控制器評估音頻特征之間的時間差。
附圖說明
為了很容易理解本發明的優點,上面簡要描述的本發明的更具體的描述將通過參考在附圖中示出具體實施例來呈現。應理解這些附圖僅描述本發明的典型實施例,因此不被認為是對其范圍的限制,本發明將通過使用附圖另外具體和詳細地進行描述和解釋,其中:
圖1是用于實施本發明的實施例的系統的原理框圖;
圖2是適用于實施根據本發明實施例的方法的實例計算裝置的原理框圖;
圖3是說明使用聽覺數據的障礙物檢測的圖;
圖4是用于使用聽覺數據執行障礙物檢測的部件的系統方框圖;以及
圖5是根據本發明的實施例的基于聽覺數據執行碰撞規避的方法的流程圖。
具體實施方式
將容易理解,本發明的組件,如大體在本文的附圖中描述和示出的,可以布置并設計為各種不同的結構。因此,以下附圖中所示的本發明的實施例的更詳細說明并非意在限制要求保護的本發明的范圍,而僅僅表示根據本發明的目前預期實施例的某些實例。目前描述的實施例將通過參考附圖得到最好的理解,其中相同的部件始終由相同的附圖標記指示。
根據本發明的實施例可以實現為裝置、方法或計算機程序產品。因此,本發明可以采取完全硬件實施例、完全軟件實施例(包括固件、常駐軟件、微代碼(micro-code)等),或者結合軟件和硬件方面的實施例的形式,其可以全部在本文中統稱為“模塊”或“系統”。而且,本發明可以采取包含在任何有形表達媒介中的計算機程序產品的形式,該計算機程序產品具有包含在媒介中的計算機可用程序代碼。
可以使用一種或多種計算機可用或計算機可讀介質的任何組合。例如,計算機可讀介質可以包括一種或多種便攜式計算機磁盤、硬盤、隨機存取存儲器(randomaccessmemory,ram)裝置、只讀存儲器(read-onlymemory,rom)裝置、可擦除可編程只讀存儲器(eprom(erasableprogrammableread-onlymemory)或閃存)裝置、便攜式光盤只讀存儲器(compactdiscread-onlymemory,cdrom)、光學存儲裝置和磁性存儲裝置。在選定的實施例中,計算機可讀介質可以包含任何非暫時性介質,該非暫時性介質可以包含、存儲、通信、傳播或傳輸由指令執行系統、裝置或設備所使用的程序或與其有關的程序。
用于實施本發明操作的計算機程序代碼可以以一種或多種編程語言的任何組合來編寫,編程語言包括如java、smalltalk、c++等的面向對象的編程語言以及如“c”編程語言或類似編程語言的常規程序編程語言。程序代碼可以作為獨立的軟件包完全在計算機系統上執行,該軟件包處在獨立硬件單元上、部分處在與計算機隔開一定距離的遠程計算機上或全部處在遠程計算機或服務器上。在后者的情形中,遠程計算機可以通過任何類型的網絡連接到計算機,網絡包括局域網(lan)或廣域網(wan)或連接可以通向外部計算機(如通過使用互聯網服務商的互聯網)。
本發明在下文中參照根據本發明實施例的方法、裝置(系統)和計算機程序產品的流程圖和/或框圖進行了描述。應理解的是,流程圖和/或框圖中的每個框和流程圖和/或框圖中的框的組合可以由計算機程序指令或代碼實施。可以將這些計算機程序指令提供給通用計算機、專用計算機或用于產生機器的其它可編程數據處理裝置的處理器,以使通過計算機或其它可編程數據處理裝置的處理器執行的指令產生用于實施流程圖和/或框圖的一個或多個框中設定的功能/動作的手段。
這些計算機程序指令也可以存儲在非暫時性計算機可讀介質中,該指令可以指示計算機或其它可編程數據處理裝置以特定方式運行,以使存儲在計算機可讀介質中的指令產生制品,該指令包括實施流程圖和/或框圖的一個或多個框中設定的功能/動作的指令手段。
計算機程序指令也可以加載在計算機或其它可編程數據處理裝置中,以引起一系列的操作步驟在計算機或其它可編程裝置中實施,以產生計算機實施過程,從而使在計算機或其它可編程裝置中執行的指令提供用于實施流程圖和/或框圖的一個或多個框中設定的功能/動作的過程。
參考圖1,控制器102可以裝載在車輛中。車輛可以包括本領域已知的任何車輛。車輛可以具有本領域已知任何車輛全部結構和特征,包括車輪、連接到車輪的傳動系統、連接到傳動系統的發動機、轉向系統、制動系統以及本領域已知的包括在車輛中的其他系統。
如此處詳細的論述,控制器102可以執行自主導航和碰撞規避。特別地,圖像數據和聽覺數據可以被分析以識別可能障礙物。特別地,音頻數據可以用于識別不在一個或多個攝像機或其他成像傳感器的視野中的車輛,如下關于圖3和4所詳細描述的。
控制器102可以從一個或多個成像裝置104接收一個或多個圖像流。例如,一個或多個攝像機可以安裝到車輛且輸出由控制器102接收的圖像流。控制器102可以從一個或多個麥克風106接收一個或多個音頻流。例如,一個或多個麥克風或麥克風陣列可以安裝到車輛且輸出由控制器102接收的音頻流。麥克風106可以包括具有隨角度變化的靈敏度的定向麥克風。
控制器102可以執行碰撞規避模塊108,碰撞規避模塊108接收圖像流和音頻流且識別可能障礙物且采取措施來避開障礙物。在此處公開的實施例中,僅圖像和音頻數據用于執行碰撞規避。然而,同樣可以使用檢測障礙物的其他傳感器,例如radar、lidar、sonar(聲納)等。因此,由控制器102接收的“圖像流”可以包括由攝像機檢測的光學圖像以及使用一個或多個其他感測裝置檢測到的物體和拓撲結構中的一個或兩個。然后控制器102分析圖像和感測的對象和拓撲結構以確定可能的障礙物。
碰撞規避模塊108可以包括音頻檢測模塊110a。音頻檢測模塊110a可以包括音頻預處理模塊112a,音頻預處理模塊112a編程為處理一個或多個音頻流以識別可能對應于車輛的特征。音頻檢測模塊110a可以進一步包括機器學習模塊112b,機器學習模塊112b執行評價來自預處理模塊112a的處理音頻流中的特征以及試圖分類音頻特征的模型。音頻檢測模塊110a的模塊112a、112b的功能在下面圖5的方法500更詳細的描述。
碰撞規避模塊108可以還包括障礙物識別模塊110b、碰撞預測模塊110c和決策模塊110d。障礙物識別模塊110b分析一個或多個圖像流且識別包括人、動物、車輛、建筑物、路緣和其他物體和結構的可能障礙物。特別地,障礙物識別模塊110b可以在圖像流中識別車輛圖像。
碰撞預測模塊110c基于障礙物現在軌跡或現在計劃的道路預測哪一個障礙物圖像可能與車輛碰撞。碰撞預測模塊110c可以評估與由障礙物識別模塊110b鑒定的物體以及使用音頻檢測模塊110a檢測的障礙物碰撞的可能性。決策模塊110d可以為了規避障礙物而做出停止、加速、轉彎等的決定。碰撞預測模塊110c預測可能碰撞的方式和決策模塊110d采取行動以規避可能碰撞的方式可以是根據自主車輛本領域已知的任何方法或系統。
決策模塊110d可以由驅動一個或多個控制車輛方向和車速的執行器126來控制車輛軌跡。例如,執行器114可以包括轉向執行器116a、加速器執行器116b以及制動器執行器116c。執行器116a-116c的配置可以是根據自主車輛的本領域已知這樣執行器的任何實施例。
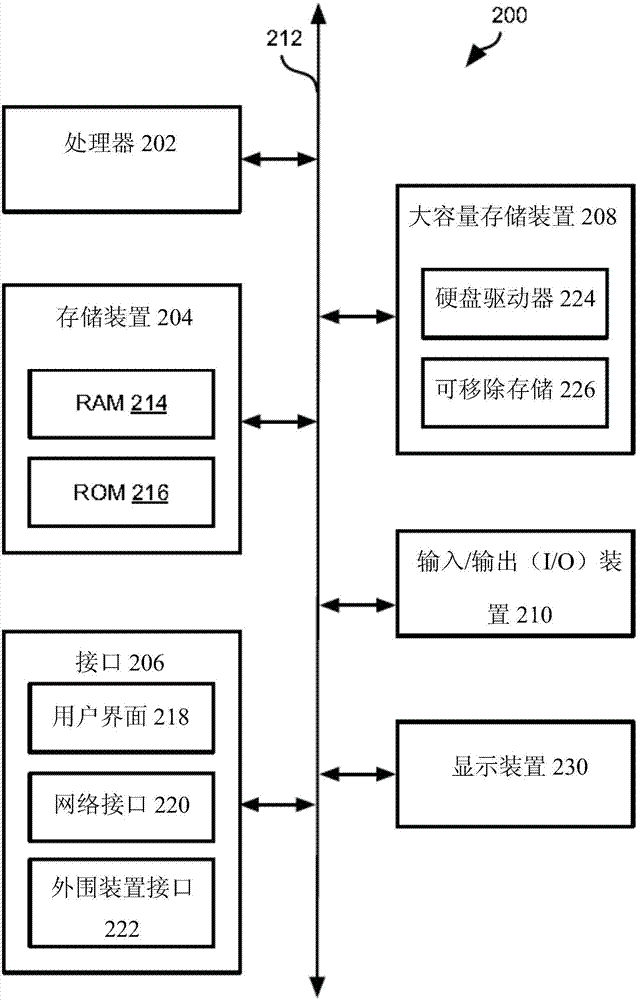
圖2是示出了實例計算裝置200的框圖。計算裝置200可以用于執行例如此處討論的各種程序。控制器102可以具有一些或全部計算裝置200的特性。
計算裝置200包括全部連接到總線212的一個或多個處理器202,一個或多個存儲裝置204、一個或多個接口206、一個或多個大容量存儲裝置208、一個或多和輸入/輸出(input/output,i/o)裝置210和顯示裝置230。處理器202包括執行存儲在存儲裝置204和/或大容量存儲裝置208中的指令的一個或多個處理器或控制器。處理器202同樣可以包括各種類型的計算機可讀媒介,例如高速緩存。
存儲裝置204包括例如易失性存儲器(例如隨機存儲存儲器(ram)214)和/或非易失性存儲器(例如只讀存儲器(rom)216)的各種計算機可讀媒介。存儲裝置204可以同樣包括可再寫rom,例如閃存。
大容量存儲裝置208包括各種計算機可讀媒介,例如磁帶、磁盤、光盤、固態存儲器(例如閃存)等等。如圖2所示,具體的大容量存儲裝置是硬盤驅動器224。各種驅動器可以同樣被包括進大容量存儲裝置208以能夠從各種計算機可讀媒介讀取和/或寫入各種計算機可讀媒介。大容量存儲裝置208包括可移除媒介226和/或非移除性媒介。
i/o裝置210包括允許數據和/或其他信息被輸入到計算裝置200或從計算裝置200中被檢索的各種裝置。實例i/o裝置210包括光標控制裝置、鍵盤、小鍵盤、麥克風、監視器或其他顯示裝置、揚聲器、打印機、網絡接口卡、調制解調器、鏡頭、ccd(charge-coupleddevices,電荷耦合裝置)或其他圖像捕捉裝置等。
顯示裝置230包括能夠顯示信息給計算裝置200的一個或更多用戶的任何類型裝置。顯示裝置230的實例包括監視器、顯示終端、視頻投影裝置等。
接口206包括允許計算裝置200與其他系統、裝置或計算環境相互作用的各種接口。實例接口206包括任何數量的不同網絡接口220,例如連接到局域網(localareanetworks,lan)、廣域網(wideareanetworks,wan)、無線網和互聯網的接口。其他接口包括用戶界面218和外圍裝置接口222。接口206可以同樣包括一個或多個外部接口,例如用于打印機、定點裝置(鼠標、觸式控制板等)、鍵盤等的接口。
總線212允許處理器202、存儲裝置204、接口206、大容量存儲裝置208、i/o裝置210和顯示裝置230來相互通信,同時與連接到總線212其他裝置或部件通信。總線212代表幾個類型總線結構的其中一個或多個,例如系統總線、pci總線、ieee1394總線、usb總線等。
為了說明的目的,程序或其他可執行程序部件以分立的框顯示在此處,盡管可以理解的是這樣的程序和部件可以在不同的時間駐留于計算裝置200不同存儲組件中,以及由處理器202執行。另外,此處描述的系統和程序可以在硬件、或硬件、軟件和/或固件的結合中實施。例如,一個或多個專用集成電路(applicationspecificintegratedcircuits,asic)可以被編程為執行此處描述的一個或多個系統和程序。
現轉到圖3,在很多實例中裝載控制器102的車輛(在下文中車輛300)可能無法視覺檢測到可能障礙物302,例如另一個車輛、騎自行車的人、行人等。例如,障礙物302可以通過如停放的車輛、建筑物、樹木、標志等的擋住物體306從駕駛員或圖像傳感器104的視線304中被掩蓋。因此,成像裝置104在檢測這樣物體上不是有效的。然而,車輛300可以是足夠接近以使用麥克風106檢測由擋住的障礙物302所產生的聲音,特別地在擋住的障礙物302是車輛的情況下。盡管此處公開的方法在存在擋住物體306的情況下是特別有用的,此處描述的障礙物的識別可以在圖像數據是可獲得的情況中執行且可以例如確認同樣對于成像裝置104是可見的障礙物位置。
參考圖4,麥克風106可以包括多個麥克風106a-106d。每個麥克風106a-106d的輸出信號106a-106d可以輸入到相應的預處理模塊112a-1-112a-4。每個預處理模塊112a-1-112a-4的輸出可以通過噪聲消除濾波器400a-400d進一步處理。然后噪聲消除模塊400a-400d的輸出可以被輸入到機器學習模塊112b。特別地,噪聲消除模塊400a-400d的輸出可以被輸入到將輸出中的特征分類為對應于特定車輛的機器學習模型402。機器學習模塊112b還可以輸出分類的置信值。
預處理模塊112a-1-112a-4可以處理來自麥克風106a-106d的原始輸出和產生輸入到噪聲消除模塊400a-400d或直接到機器學習模塊112a的處理后輸出。處理后輸出可以是原始輸出的濾波版本,處理后輸出具有相對于原始輸出增強的音頻特征。增強的音頻特征可以是有可能對應于車輛的片段、頻段或原始輸出的其他組成。因此,預處理模塊112a-1-112a-4可以包括帶通濾波器,帶通濾波器通過在對應于由車輛及車輛發動機產生的聲音的頻段中的原始輸出的一部分同時阻斷該頻段外的原始輸出部分。預處理模塊112a-1-112a-4可以是數字濾波器,其具有選擇為通過具有相應車輛發動機或其他車輛噪聲的頻譜成分和/或時間分布的信號的系數,如具有將通過車輛產生的聲音而衰減其他聲音的實驗選擇系數的自適應濾波器。預處理模塊112a-1-112a-4的輸出可以是時域信號或頻域信號,或兩者都是。預處理模塊112a-1-112a-4的輸出可以包括多個信號,多個信號包括時域和頻域的其中一個或兩個內的信號。例如,使用不同的通帶濾波器濾波產生的信號可以在時域或頻域中輸出。
噪聲消除模塊400a-400d可以包括任何本領域已知的噪聲消除濾波器或實施本領域已知的任何噪聲消除方法。特別地,噪聲消除模塊400a-400d還可以將車輛300的速度、車輛300的發動機轉速或描述發動機狀態的其他信息作為輸入,車輛300通風風扇的速度,或其他信息。這些信息可以由噪聲消除模塊400a-400d使用以消除由發動機和風扇以及車輛風噪聲引起的聲音。
機器學習模型402可以是深度神經網絡,但是可以使用機器學習模型的其他類型,如決策樹、聚類、貝葉斯網絡、遺傳或機器學習模型的其他類型。機器學習模型402可以在不同類型的情況下訓練各種類型噪聲。特別地,使用麥克風陣列106a-106d(或相近規格的陣列)記錄的聲音可以從已知的源頭在不同的相對位置、相對速度和有無背景噪聲下記錄。
然后模型402可以被訓練以識別來自已知源頭的聲音。例如,該模型可以被訓練使用<音頻輸入,聲源類型>項目,該條目分別將在上述各種情況下用麥克風106a-106d得到的音頻記錄與聲源類型配對。然后,機器學習算法可以使用這些項目訓練模型402來輸出給定的音頻輸入的聲源類型。機器學習算法可以針對各種聲源類型訓練模型402。因此,一組訓練項目可以為每類聲源和訓練它的模型產生,或為每類聲源訓練單獨模型。機器學習模型402可以輸出決策和該決策的置信分數。因此,機器學習模型402可以產生表明輸入信號是否對應于特定類型的輸出和這個輸出是正確的置信分數。
機器學習模塊112b可進一步包括麥克風陣列處理模塊404。麥克風陣列處理模塊404可以評估來自不同的麥克風106a-106d的音頻特征到達時間,以評估到音頻特征源頭的方向。例如,音頻特征可能是車輛聲音,車輛聲音開始于在噪聲消除模塊400a-400d輸出中的時間t1、t2、t3和t4。因此,已知麥克風106a-106d的相對位置和聲音速度s,麥克風106a-106d到源頭的距離差被確定,例如d2=s/(t2-t1),d3=s/(t3-t1),d4=s/(t4-t1),其中d2、d3、d4是在由聲音特征相對于參考麥克風行進的估計距離差,這個例子中參考麥克風為麥克風106a。
例如,到聲源的角度a可以計算為asin(d2/r2)、asin(d3/r3)和asin(d4/r4)的平均值,其中r2是麥克風106a和麥克風106b之間的距離,r3是麥克風106c和麥克風106a之間的距離,和r4是麥克風106d和麥克風106a之間的距離。這種方法假定了聲源是在距麥克風106a-106d的較大距離以便使入射聲波可近似為平面波。本領域已知的基于不同到達時間來識別到聲音的方向的其他方法也可以被使用。同樣,不是簡單地確定方向,區域或角度范圍可以被估計,即關于任何評估方向的不確定性范圍,其中不確定性范圍指使用的方向評估技術的準確性上的限制。
由麥克風陣列處理模塊404評估的方向、由機器學習模型402產生的分類和置信分數然后可以作為機器學習模塊112b的輸出406。例如,障礙物識別模塊110b可以向一組可能障礙物增加位于評估的方向的具有確定類型的車輛,該組可能障礙物包括任何通過其他方式確定的障礙物,如使用成像裝置104。然后碰撞預測模塊110c就可以執行與該組可能障礙物的可能碰撞的識別和然后決策模塊110d可以確定要執行的操作來規避可能碰撞,例如車輛轉向、實施制動、加速等。
圖5示出了可以由控制器102通過處理來自麥克風106a-106d的音頻信號執行的方法500。方法500可以包括產生502表示用麥克風106a-106d檢測到的聲音的音頻信號和預處理504音頻信號以增強音頻特征。這可能包括關于預處理模塊112a-1-112a-4進行上述任何濾波功能。特別地,預處理504可以包括在時間域或頻率域內產生一個或多個預處理后信號,每個輸出可以是來自其中一個麥克風106a-106d的帶通濾波版本的音頻信號或每個輸出可以被濾波或用其他方法另行處理,如使用自適應濾波器或其他音頻處理技術。預處理504可以進一步包括在如上述預處理模塊112a-1-112a-4的輸入或輸出上關于噪聲消除模塊400a-400d執行噪聲消除。
方法500可以進一步包括輸入506預處理信號到機器學習模型402中。然后機器學習模型402會分類508聲音的來源,即在預處理后信號中的音頻特征屬性將根據機器學習模型402進行處理,然后機器學習模型402將輸出一個或多個分類和用于一個或多個分類的置信分數。
方法500可以進一步包括評估510到聲源的方向。如上所述,這可能包括啟動麥克風陣列處理模塊404功能以評估在預處理后輸出中的音頻特征到達時間的差異,從而確定到音頻特征起源的方向或到音頻特征起源的可能角度范圍。
方法500可以包括評估512在步驟508中分類的置信分數是否超過閾值。例如,在步驟508中沒有分類具有閾值以上的置信分數,方法500可以包括確定音頻特征是可能不對應于車輛的分類基礎。否則,如果置信分數超過閾值,那么方法500可以包括增加514可能障礙物到由例如使用成像裝置104的其它手段識別的一組障礙物。可能障礙物可能被定義為定位在步驟510確定的方向或角度范圍內的可能障礙物。
在步驟512的任一結果中,障礙物使用其他感測系統(例如成像裝置104)檢測,以及使用這些感測系統檢測到的障礙物被添加516到障礙物組。相對于障礙物組518執行碰撞規避。如上所述,這可能包括檢測可能碰撞和為了規避障礙物組中的障礙物以及將車輛引導到預定目的地而激活轉向執行器116a、加速器執行器116b以及制動器執行器116c中的一個或多個。
本發明可以在不脫離其精神或實質特征的情況下以其他具體形式實施。描述的實施例關于其所有方面都應認為是示例性的而非限制性的。因此本發明的保護范圍是由所附權利要求確定的,而不是前述說明書。在與權利要求的等同物的含義和范圍內的所有變化都應被包含在本發明的保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!