一種表達鮭魚降鈣素的方法及其專用表達盒與流程
本發明涉及生物技術領域,具體涉及一種表達鮭魚降鈣素的方法及其專用表達盒。
背景技術:
鮭魚降鈣素是由鮭魚后腮體分泌的由32個氨基酸組成的單鏈多肽。鮭魚降鈣素作為治療骨質疏松癥等代謝性骨病的防治藥已被載入多國藥典,并已在多國行銷近30年。鮭魚降鈣素具有調節體內鈣、磷代謝及骨骼代謝的重要生物學功能,可降低血鈣水平,還具有抗組胺、抗膽堿、抑制胃酸和胰腺分泌的作用。臨床上主要用于治療骨質疏松癥。鮭魚降鈣素的生產方法主要有提取法、化學合成法和基因工程法。提取法是以鮭魚、鰻魚的鰓為原料,提取獲得天然鮭魚降鈣素(生物學活性達到4500U/mg),但由于原料有限,因此獲得的天然鮭魚降鈣素極少。基因工程法是在大腸桿菌或酵母中表達鮭魚降鈣素,但由于鮭魚降鈣素C端第32位氨基酸不能酰胺化,因此表達出的鮭魚降鈣素的生物學活性,僅為100-200U/mg(天然鮭魚降鈣素為4500U/mg)。迄今為止,商業化銷售的鮭魚降鈣素都是采用化學合成法生產的,化學合成法步驟多、得率低且價格昂貴,注射針劑中的鮭魚降鈣素為12000元/mg,原藥價格也高達18000-20000元/g。
技術實現要素:
本發明所要解決的技術問題是如何表達鮭魚降鈣素。
為解決上述技術問題,本發明首先提供了表達盒。
本發明所提供的表達盒自上游至下游依次可包括如下元件:植物種子特異表達蛋白基因的啟動子、融合基因和終止序列;所述融合基因中可含有區段乙;所述區段乙編碼鮭魚降鈣素的前體;所述鮭魚降鈣素的前體可為氨基酸序列是序列表中序列5自N末端起第158至190位所示的蛋白質。
所述融合基因中,5’末端為起始密碼子,3’末端為終止密碼子,中間為連續的編碼區。
所述鮭魚降鈣素的前體在植物體內可自發形成鮭魚降鈣素。
所述區段乙可為如下b1)或b2)或b3)或b4)所示的DNA分子:
b1)具有序列表中序列4自5′末端起第34至132位核苷酸所示的DNA分子;
b2)核苷酸序列是序列表中序列4自5′末端起第34至132位所示的DNA分子;
b3)與b1)或b2)限定的核苷酸序列具有85%或85%以上同一性,且編碼所述鮭魚降鈣素的前體的DNA分子;
b4)在嚴格條件下與b1)或b2)限定的核苷酸序列雜交,且編碼所述鮭魚降鈣素的前體的DNA分子。
所述融合基因還可包括區段甲;所述區段甲編碼篩選標記蛋白。
所述融合基因還可包括一個以上區段丙;所述區段丙編碼蛋白標簽。所述蛋白標簽具體可為6×His標簽。
當融合基因中包括2個以上區段丙時,每個區段丙可以編碼不同的蛋白標簽。
所述融合基因還可包括區段丁;所述區段丁可為切割物質的識別序列。
所述融合基因自上游至下游依次可包括如下區段:所述區段丙、所述區段甲、所述區段丁和所述區段乙。
上述任一所述植物種子特異表達蛋白基因的啟動子可為菜豆儲存蛋白(GenBank號為X52626.1)基因的啟動子。所述菜豆儲存蛋白(GenBank號為X52626.1)基因的啟動子的核苷酸序列具體可如序列表中序列5自5′末端起第1至1619位所示。
上述任一所述篩選標記蛋白可為GUS蛋白。所述GUS蛋白的核苷酸序列如序列表中序列3自5′末端起第34至1839位所示。
上述任一所述終止序列可為植物種子特異表達蛋白基因的終止子。所述植物種子特異表達蛋白基因的終止子可為菜豆儲存蛋白(GenBank號為X52626.1)基因的終止子。所述菜豆儲存蛋白(GenBank號為X52626.1)基因的終止子的核苷酸序列具體可如序列表中序列5自5′末端起第3609至4213位所示。
上述任一所述切割物質可為滿足如下條件的切割物質:所述切割物質對于所述融合基因的表達產物的酶切位置為特定氨基酸殘基與其前一位氨基酸殘基之間;所述特定氨基酸殘基為所述鮭魚降鈣素的前體的第一個氨基酸殘基。
上述任一所述切割物質具體可為甲酸。
上述任一所述區段丁的核苷酸序列可為序列表中序列5自5′末端起第3465至3491位所示。
所述表達盒的核苷酸序列具體可如序列表中序列5所示。
含有上述任一所述表達盒的重組載體也屬于本發明的保護范圍。
所述重組載體Ⅰ具體可為重組質粒pPha(p/gc/t)2300。重組質粒pPha(p/gc/t)2300為將載體pCAMBIA2300的限制性內切酶SacⅠ和HindⅢ識別序列間的小片段替換為序列表中序列5所示的DNA分子,得到的重組質粒。重組質粒pPha(p/gc/t)2300表達序列表中序列6所示的蛋白質。
所述重組載體Ⅰ具體可為重組質粒pPha(p/gc/t)2300-DZ。重組質粒pPha(p/gc/t)2300和重組質粒pPha(p/gc/t)2300-DZ的唯一不同在于:重組質粒pPha(p/gc/t)2300的鮭魚降鈣素的前體的編碼基因(即sCT基因)為序列表中序列4自5′末端起第34至132位所示,重組質粒pPha(p/gc/t)2300-DZ的鮭魚降鈣素的前體的編碼基因(即sCT-DZ基因)為序列表中序列8自5′末端起第34至132位所示。重組質粒pPha(p/gc/t)2300-DZ表達序列表中序列6所示的蛋白質。
為解決上述技術問題,本發明還提供了表達鮭魚降鈣素的方法。
本發明所提供的表達鮭魚降鈣素的方法,依次可包括如下步驟:
(1)將上述任一所述重組載體導入受體植物,得到轉基因植物;
(2)通過培養所述轉基因植物得到鮭魚降鈣素。
上述方法中,所述鮭魚降鈣素存在或主要存在于轉基因植物的種子中。
上述方法中,所述受體植物可為油菜品種中雙4號。
上述方法中,所述“培養所述轉基因植物得到鮭魚降鈣素”還依次可包括如下步驟:
(4)取轉基因植物的種子,脫脂后提取粗蛋白;
(5)利用所述蛋白標簽從所述粗蛋白中純化所述融合蛋白;
(6)取步驟(5)得到的融合蛋白,用切割物質進行切割;
(7)從步驟(6)的產物中分離鮭魚降鈣素;
(8)醋酸化;
(9)脫鹽。
上述方法中,所述步驟(4)中,所述“脫脂”的步驟可為:先粉碎轉基因植物的種子,然后用正己烷脫脂。所述粉碎的程度可為200目。
上述方法中,所述步驟(4)中,所述“提取粗蛋白”可為用含8-12mg/mL蔗糖和1.5-2.5mg/mL SDS的pH6.5-7.0、0.1-0.3M Tris-Hcl緩沖液進行提取。
上述方法中,所述步驟(4)中,所述“提取粗蛋白”具體可為用含10mg/mL蔗糖和2.0mg/mL SDS的pH6.8、0.2M Tris-Hcl緩沖液進行提取。
上述方法中,所述步驟(5)中,所述蛋白標簽可為6×His標簽。
上述方法中,所述步驟(6)中,所述切割物質可為甲酸。
上述方法中,所述步驟(7)中,所述“分離鮭魚降鈣素”可采用陽離子交換層析進行分離。
上述方法中,所述步驟(8)中,所述醋酸化的步驟可為:調節步驟(7)分離的鮭魚降鈣素的pH值至1.0-3.0,然后加入醋酸鈉處理40-80min。
上述方法中,所述步驟(8)中,所述醋酸化的步驟具體可為:取步驟(7)分離的鮭魚降鈣素,用磷酸調節pH值至2.0,得到溶液1;取1體積份溶液1,加入3體積份濃度為333mM的醋酸鈉水溶液,得到溶液2;取所述溶液2,室溫放置60min。
上述方法中,所述步驟(9)中,所述脫鹽可為反相色譜脫鹽。
上述方法中,完成步驟(9)后,還可包括凍干的步驟。
實驗證明,將重組質粒pPha(p/gc/t)2300或重組質粒pPha(p/gc/t)2300-DZ導入油菜品種中雙4號,得到轉基因植物,然后培養該轉基因植物,進一步得到生物學活性較高的鮭魚降鈣素。可見,利用本發明所提供的方法可以表達鮭魚降鈣素,具有重要的應用價值。
附圖說明
圖1為實施例1步驟二8中(1)的實驗結果。
圖2為實施例1步驟二8中(2)的實驗結果。
圖3為實施例1中步驟三的實驗結果。
圖4為實施例1中步驟四的實驗結果。
具體實施方式
下面結合具體實施方式對本發明進行進一步的詳細描述,給出的實施例僅為了闡明本發明,而不是為了限制本發明的范圍。
下述實施例中的實驗方法,如無特殊說明,均為常規方法。
下述實施例中所用的材料、試劑等,如無特殊說明,均可從商業途徑得到。
油菜品種中雙4號記載于如下文獻中:羅曉輝,葉明海.“中雙4號”育苗移栽高產栽培[J].上海農業科技,1999年05期.在下文中,油菜品種中雙4號簡稱中雙4號。
下述實施例中的光暗交替培養(即光照培養和暗培養交替)的條件為:25℃。光照培養時的光照強度為15000Lx。光暗交替培養的周期具體為:14h光照培養/10h黑暗培養。
MS0培養基:將NH4NO3 1650mg、KNO3 1900mg、KH2PO4 170mg、MgSO4·7H2O 370mg、CaCl2·2H2O 440mg、FeSO4·7H2O 27.80mg、Na2EDTA 37.30mg、MnSO4·4H2O 22.30mg、ZnSO4·7H2O 8.60mg、H3BO3 6.20mg、KI 0.83mg、Na2MOO4·2H2O 0.25mg、CuSO4·5H2O 0.025mg、COCl2·6H2O 0.025mg、肌醇100.00mg、VB10.1mg、VB60.5mg、煙酸0.5mg、甘氨酸2.0mg和瓊脂7g溶于1L蒸餾水,調節pH值至5.8。
載體pUC57為百奧邁科生物技術有限公司的產品,產品目錄號為BK0033。λDNA/EcoRI+HindⅢ Marker為北京康潤生物科技有限公司的產品,產品目錄號為M125-01。粉碎機為紹興市科宏儀器有限公司的產品,產品型號為EW-100。鮭魚降鈣素標準品為北京華大蛋白質研發中心有限公司合成。密鈣息為Novartis Pharma Stein AG公司的產品。載體pCAMBIA2301為華越洋生物(北京)科技有限公司的產品,產品目錄號為VECT0310。
菜豆儲存蛋白的GenBank號為X52626.1。
實施例1、利用轉基因油菜種子表達系統表達鮭魚降鈣素
一、重組質粒pPha(p/gc/t)2300的構建
1、人工合成序列表中序列1所示的雙鏈DNA分子。序列表中序列1中,自5′末端起第1至6位為限制性內切酶SacⅠ的識別序列,第7至1625位為菜豆儲存蛋白的啟動子的核苷酸序列,第1626至1631位為限制性內切酶KpnⅠ的識別序列。
2、用限制性內切酶SacⅠ和KpnⅠ雙酶切步驟1合成的雙鏈DNA分子,回收1631bp的DNA片段甲。
3、用限制性內切酶SacⅠ和KpnⅠ雙酶切載體pCAMBIA2301,回收約11.6bp的載體骨架甲。
4、將DNA片段甲和載體骨架甲進行連接,得到中間載體甲。
5、人工合成序列表中序列2所示的雙鏈DNA分子。序列表中序列2中,自5′末端起第1至6位為限制性內切酶PstI的識別序列,第7至611位為菜豆儲存蛋白的終止子的核苷酸序列,第612至617位為限制性內切酶HindⅢ的識別序列。
6、用限制性內切酶PstI和HindⅢ雙酶切步驟5合成的雙鏈DNA分子,回收617bp的DNA片段乙。
7、用限制性內切酶PstI和HindⅢ雙酶切中間載體甲,回收約13.2Kb的載體骨架乙。
8、將DNA片段乙和載體骨架乙進行連接,得到中間載體乙。
9、人工合成序列表中序列3所示的雙鏈DNA分子。序列表中序列3中,自5′末端起第1至6位為限制性內切酶KpnⅠ的識別序列,第7至9位為起始密碼子ATG(編碼甲硫氨酸),第10至33位為編碼8×His標簽的核苷酸序列,第34至1839位為編碼GUS蛋白的核苷酸序列(已按油菜偏愛密碼子對GUS蛋白的核苷酸序列進行優化),第1840至1845位為限制性內切酶BamHI的識別序列。
10、用限制性內切酶Kpn Ⅰ和BamHI雙酶切步驟9合成的雙鏈DNA分子,回收1845bp的DNA片段丙。
11、用限制性內切酶Kpn Ⅰ和BamHI雙酶切中間載體乙,回收約13.8kb的載體骨架丙。
12、將DNA片段丙和載體骨架丙進行連接,得到中間載體丙。
13、人工合成序列表中序列4所示的雙鏈DNA分子。序列表中序列4中,自5′末端起第1至6位為限制性內切酶BamHⅠ的識別序列,第7至33位為甲酸切割的識別序列,第34至132位為鮭魚降鈣素的前體的編碼基因(以下簡稱sCT基因),第133至144位為四個終止密碼子,第145至150位為限制性內切酶PstI的識別序列。
14、將步驟13合成的雙鏈DNA分子連接至載體pUC57,得到重組質粒psCT。
15、用限制性內切酶BamHⅠ和PstI雙酶切重組質粒psCT,回收150bp的DNA片段丁。
16、用限制性內切酶BamHⅠ和PstI雙酶切中間載體丙,回收約15.6kb的載體骨架丁。
17、將DNA片段丁和載體骨架丁進行連接,得到重組質粒pPha(p/gc/t)2300。
根據測序結果,對重組質粒pPha(p/gc/t)2300進行結構描述如下:將載體pCAMBIA2300的限制性內切酶SacⅠ和HindⅢ識別序列間的小片段替換為序列表中序列5所示的DNA分子。重組質粒pPha(p/gc/t)2300表達序列表中序列6所示的融合蛋白甲。
序列表中序列5中,自5′末端起第1至1619位菜豆儲存蛋白的啟動子的核苷酸序列,第1620至1625位為限制性內切酶KpnⅠ的識別序列,第1626至1628位為起始密碼子ATG(編碼甲硫氨酸),第1629至1652位為編碼8×His標簽的核苷酸序列,第1653至3458位為編碼GUS蛋白的核苷酸序列,第3459至3464位為限制性內切酶BamHI的識別序列,第3465至3491位為甲酸的識別序列,第3492至3590位為鮭魚降鈣素的前體的編碼基因(以下簡稱sCT基因),第3591至3602位為四個終止密碼子,第3603至3608位為限制性內切酶PstI的識別序列,第3609至4213位為菜豆儲存蛋白的終止子的核苷酸序列。
序列表中序列6中,自N末端起第1位為甲硫氨酸,第2至9位為8×His標簽,第10至611位為GUS蛋白,第614至622位為甲酸的識別位點,第623至655位為鮭魚降鈣素的前體。
二、油菜遺傳轉化
1、農桿菌侵染液的制備
(1)采用電擊法將重組質粒pPha(p/gc/t)2300導入根癌農桿菌LBA4404,得到重組農桿菌,命名為LBA4404/pPha(p/gc/t)2300。
(2)將LBA4404/pPha(p/gc/t)2300的單克隆接種至5mL含100mg/L卡那霉素(Kanamycin,Kan)和50mg/L利福平(Rifampicin,Rif)的YEB液體培養基,28℃、200rpm振蕩培養12h,得到培養菌液1。
(3)將1mL培養菌液1接種至50mL含100mg/L Kan和50mg/L Rif的YEB液體培養基,28℃、200rpm振蕩培養至OD600nm值為0.3~0.4,得到培養菌液2。
(4)取步驟(3)得到的培養菌液2,4℃、5000rpm離心5min,收集菌體1。
(5)取步驟(4)收集的菌體1,用含1.0mg/L 6-BA的MS0培養基重懸,然后4℃、5000rpm離心5min,收集菌體2。
(6)取步驟(5)收集的菌體2,用含100mg/L乙酰丁香酮(Acetosyringone,As)的MS0培養基重懸,得到農桿菌侵染液。以含100mg/L As的MS0培養基為參照,調整農桿菌侵染液的OD600nm值至0.15~0.25。
2、中雙4號的子葉的獲得
取中雙4號的種子,先用75%(v/v)的乙醇水溶液浸泡2min,然后用次氯酸鈉水溶液(由1體積份次氯酸鈉溶液(有效氯≥10.0)和4體積份水混合而成)浸泡10min,最后用無菌水反復沖洗,瀝干后接種于MS0培養基上,光暗交替培養5d,得到中雙4號的材料。
取中雙4號的材料,剪取子葉(盡量靠近生長點),得到中雙4號的子葉。
3、侵染
取步驟2獲得的中雙4號的子葉,置于離心管,然后加入農桿菌侵染液(OD600nm值為0.2)浸泡10min。
4、共培養
完成步驟3后,將所述中雙4號的子葉轉移至共培養培養基上(子葉需正面朝上)共培養4d。
共培養培養基:含1.25mg/L NAA、5.0mg/L 6-BA和5.0mg/L AgNO3的MS0培養基。
共培養條件:25℃,暗培養。
5、選擇培養
完成步驟4后,將所述中雙4號的子葉轉移至選擇培養基上(子葉需正面朝上),光暗交替培養4d。
選擇培養基:含1.0mg/L NAA、3.0mg/L 6-BA和100mg/L頭孢噻吩(cefalotin,Cf)的MS0培養基。
6、分化培養
完成步驟5后,將所述中雙4號的子葉轉移至分化培養基上(子葉需正面朝上),光暗交替培養4周,得到長約1cm的分化芽。
分化培養基:含0.2mg/L NAA、2.0mg/L 6-BA、40mg/L Kan、100mg/L Cf的MS0培養基。
7、生根培養
完成步驟6后,將所述分化芽轉移至生根培養基上,光暗交替培養2周,獲得擬轉sCT基因油菜。
生根培養基:含100mg/L Kan和100mg/L Cf的MS0培養基。
隨機選擇7株擬轉sCT基因油菜,依次命名為GCt1至GCt7。
8、分子檢測
(1)PCR檢測
分別提取步驟7獲得的7株擬轉sCT基因油菜葉片的基因組DNA并作為模板,以GC5:5'-ACCGATACCATCAGCGATC-3'和GC3:5'-GTTCCAGATCCGGTGTTAG-3'為引物進行PCR擴增,得到PCR擴增產物。用等體積超純水代替擬轉sCT基因油菜的葉片的基因組DNA,作為陰性對照。用等體積重組質粒pPha(p/gc/t)2300的DNA代替擬轉sCT基因油菜的葉片的基因組DNA,作為陽性對照。
PCR反應程序為:94℃預變性5min;94℃變性30s,55℃退火1min,72℃延伸1min,35個循環;72℃延伸10min,4℃保持。
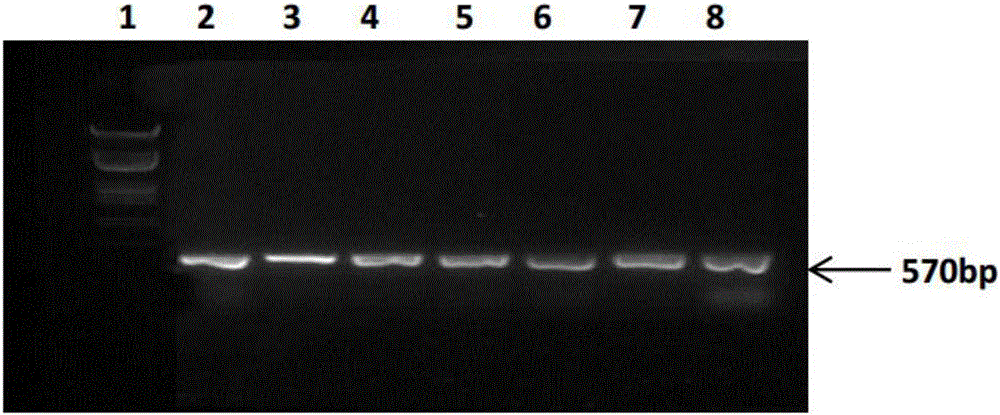
PCR擴增反應完成后,取10μL PCR擴增產物進行1%瓊脂糖凝膠電泳。實驗結果見圖1(泳道1為λDNA/EcoRI+HindⅢMarker,泳道2為GCt1,泳道3為GCt2,泳道4為GCt3,泳道5為GCt4,泳道6為GCt5,泳道7為GCt6,泳道8為GCt7)。結果表明,如果以擬轉sCT基因油菜的葉片的基因組DNA為模板,能夠擴增出約570bp的條帶,則該擬轉sCT基因油菜即為轉sCT基因油菜;陰性對照不能獲得570bp的條帶;陽性對照可以獲得570bp的條帶。
(2)RT-PCR檢測
菜豆儲存蛋白是種子中特異表達的蛋白,一般在開花后4-6周的種子中開始轉錄,9-11周的種子中mRNA的含量達到最高水平,種子的成熟后期的mRNA含量急劇降低。
(a)提取待測油菜(GCt1、GCt2、GCt3、GCt4、GCt5、GCt6或GCt7)開花后9-11周的種子的總RNA,然后該總RNA用M-MLV反轉錄出第一鏈cDNA,得到待測油菜的cDNA。待測油菜的cDNA中,DNA濃度為500ng/μL。
(b)以步驟(a)得到的待測油菜的cDNA為模板,以GC5:5'-ACCGATACCATCAGCGATC-3'和GC3:5'-GTTCCAGATCCGGTGTTAG-3'為引物進行RT-PCR擴增,得到PCR擴增產物。用等體積超純水代替待測油菜的cDNA,作為陰性對照。
PCR反應程序為:94℃預變性5min;94℃變性30s,55℃退火1min,72℃延伸1min,35個循環;72℃延伸10min,4℃保持。
PCR擴增反應完成后,取10μL PCR擴增產物進行1%瓊脂糖凝膠電泳。實驗結果見圖2(泳道1為λDNA/EcoRI+HindⅢMarker,泳道2為GCt1,泳道3為GCt2,泳道4為GCt3,泳道5為GCt4,泳道6為GCt5,泳道7為GCt6)。結果表明,如果以擬轉sCT基因油菜的cDNA為模板,能夠擴增出約570bp的條帶,則該擬轉sCT基因油菜即為轉sCT基因油菜,說明sCT基因已經整合到中雙4號的基因組,并轉錄表達;陰性對照不能獲得570bp的條帶。
PCR檢測和RT-PCR檢測的結果完全一致。因此,GCt1、GCt2、GCt3、GCt4、GCt5、GCt6和GCt7均為轉sCT基因油菜。
待GCt1成熟后收集種子,然后進行繁育和PCR檢測,直至獲得純合種子。將該純合種子命名為GCt1種子,進行后續實驗。
三、鮭魚降鈣素的提取和純化
1、脫脂
(1)取步驟二收集的GCt1種子,用粉碎機(粉碎程度200目)粉碎,得到油菜籽粉。
(2)將油菜籽粉和正己烷按照1:10(1g/10mL)的比例混勻,得到混合物甲;將混合物甲置于密封玻璃的容器中室溫攪拌8h,然后棄上清,收集殘渣甲。
(3)將殘渣甲和正己烷按照1:10(1g/10mL)的比例混勻,得到混合物乙;將混合物乙置于密封玻璃的容器中室溫攪拌8h,然后棄上清,收集殘渣乙。
(4)將殘渣乙和正己烷按照1:10(1g/10mL)的比例混勻,得到混合物丙;將混合物丙置于密封玻璃的容器中室溫攪拌8h,然后棄上清,收集殘渣丙。
(5)將殘渣丙冷凍風干,即為脫脂的油菜籽粉。
2、提取
(1)取離心管(規格為50mL),加入100mg脫脂的油菜籽粉和20mL含10%(10mg/mL)蔗糖和2%(2mg/mL)SDS的pH6.8、0.2M Tris-Hcl緩沖液,充分混勻,4℃攪拌9h。
(2)完成步驟(1)后,取所述離心管,4℃、20000rpm離心60min。收集上清液。上清液即為GCt1種子蛋白的粗提物。
3、His-tag初步純化
鎳離子螯合磁珠的商品名稱為BeaverBeadsTM IDA-Nickel,具體為蘇州海貍生物醫學工程有限公司的產品,產品編號為70501-5。
Buffer A為含500mM NaCl和10mM咪唑的pH7.4、20mM磷酸鈉緩沖液。
Buffer B為含500mM NaCl和50mM咪唑的pH7.4、20mM磷酸鈉緩沖液。
Buffer C為含500mM NaCl和500mM咪唑的pH7.4、20mM磷酸鈉緩沖液。
(1)取10mL步驟2收集的上清液和10mL Buffer A,充分混勻;然后加入2mL磁珠懸浮液,充分懸浮后置于旋轉混合儀上溫育30min;最后通過磁性分離,將鎳離子螯合磁珠轉移到新的離心管中。
磁珠懸浮液的制備方法為:取2mL鎳離子螯合磁珠,加入5mL Buffer A,用移液器輕輕吹打數次得到的懸浮液。
(2)完成步驟(1)后,取裝有鎳離子螯合磁珠的離心管,加入10mL Buffer B,用移液器輕輕吹打數次,然后通過磁性分離,將鎳離子螯合磁珠轉移到新的離心管中。
(3)重復步驟(2)兩次。
(4)完成步驟(3)后,取裝有鎳離子螯合磁珠的離心管,加入5mL Buffer C,用移液器輕輕吹打數次,然后通過磁性分離,收集上清液。
(5)將步驟(4)收集的上清液利用分子量為10kD MW的超濾管進行超濾濃縮,獲得融合蛋白乙的濃縮液。
鮭魚降鈣素主要用于治療骨質疏松癥。通過基因工程法生產鮭魚降鈣素,主要是在大腸桿菌或酵母中表達鮭魚降鈣素,但由于鮭魚降鈣素C端第32位氨基酸不能酰胺化,因此表達出的鮭魚降鈣素的生物學活性僅為100-200U/mg;而天然的鮭魚降鈣素的生物學活性為4500U/mg。已有研究結果表明,鮭魚降鈣素的前體(氨基酸序列如序列表中序列6自N末端起第623至655位所示)通過植物自身的酰胺化系統,可轉化為鮭魚降鈣素。
融合蛋白乙氨基酸序列如序列表中序列7所示,且其C末端酰胺化。融合蛋白乙在轉sCT基因油菜體內經過如下轉化得到:轉sCT基因油菜中首先表達融合蛋白甲,之后通過自身的酰胺化系統,將融合蛋白甲轉化為C末端酰胺化的融合蛋白乙。
4、甲酸切割
(1)取融合蛋白乙的濃縮液,加入無菌水和甲酸,得到反應體系;反應體系中,融合蛋白乙的濃度為1mg/mL,甲酸的濃度為37%(v/v)。
(2)完成步驟(1)后,取所述反應體系,45℃切割2.5h。
5、陽離子交換純化
將完成步驟4的體系在AKTA蛋白純化系統上經陽離子交換層析純化,得到鮭魚降鈣素溶液。具體步驟如下:
(1)將1體積份完成步驟4的體系和3體積份pH3.0、10mM檸檬酸鈉緩沖液混合,得到混合液(電導率為7mS/cm);然后將混合液用0.22μM的濾膜過濾,得到上樣液。
(2)取SP-Sepharose fast flow(5×1mL)(美國GE公司的產品),先用10個柱體積的pH3.0、10mM檸檬酸鈉緩沖液預平衡(流速為1mL/min)。
(3)完成步驟(2)后,取步驟(1)得到的上樣液,進行上樣(流速為0.5mL/min)。
(4)完成步驟(3)后,用10個柱體積的pH3.0、10mM檸檬酸鈉緩沖液洗脫(流速為1mL/min)至紫外檢測基線平穩(檢測波長為220nm)。
(5)完成步驟(4)后,用含400mM NaCl的pH3.0、10mM檸檬酸鈉緩沖液進行洗脫(流速為0.5mL/min),收集洗脫峰約5-10mL的洗脫溶液。
6、醋酸化
(1)取步驟5收集的洗脫溶液,先加入磷酸調節pH值至2.0,得到溶液1。
(2)取1體積份溶液1,加入3體積份濃度為333mM的醋酸鈉水溶液,混合均勻,得到溶液2。
(3)取所述溶液2,室溫放置60min,得到溶液3。
7、反相色譜脫鹽及凍干
Amberchrom CG300md resin為北京慧德易科技有限責任公司的產品。
(1)取Amberchrom CG300md resin,用10個柱體積的0.1%(v/v)醋酸水溶液洗脫(流速為5mL/min)至電導率基線平穩。
(2)完成步驟(1)后,用10個柱體積的濃度為250mM醋酸鈉水溶液洗脫(流速為5mL/min)至pH值基線平穩。
(3)完成步驟(2)后,取步驟6得到的溶液3,進行上樣(流速2mL/min)。
(4)完成步驟(3)后,用10個柱體積的濃度為250mM醋酸鈉水溶液洗脫(流速為5mL/min)至pH值基線平穩。
(5)完成步驟(4)后,用10個柱體積的0.1%(v/v)醋酸水溶液洗脫(流速為5mL/min)至電導率基線平穩。
(6)完成步驟(5)后,用40%(v/v)乙醇水溶液洗脫(流速為2mL/min),收集洗脫峰約5-10mL的洗脫溶液。
(7)用冷凍干燥機將步驟(6)收集的洗脫溶液凍干至粉末,即鮭魚降鈣素粉末。-20℃備用。
取1mg鮭魚降鈣素粉末,加入1mL超純水溶解,得到鮭魚降鈣素溶液。
將鮭魚降鈣素溶液和濃度為1mg/mL鮭魚降鈣素標準品水溶液進行SDS-PAGE。
實驗結果見圖3(1為蛋白Marker,2為鮭魚降鈣素溶液,3為鮭魚降鈣素標準品水溶液)。結果表明,鮭魚降鈣素溶液中含有鮭魚降鈣素,純度約90%。每10g步驟二收集的GCt1種子產生0.2mg鮭魚降鈣素(以100%純度計)。
四、鮭魚降鈣素的HPLC檢測
使用配有Agilent Zorbax SB C18柱(5.0μm,150mm×2.1mm)的Agilent 1200液相色譜儀分析步驟三中的鮭魚降鈣素溶液和濃度為1mg/mL的鮭魚降鈣素標準品水溶液。進樣量20μL。流動相由0.1%(v/v)三氟乙酸(trifluoroacetic acid,TFA)水溶液(A液)和0.1%(v/v)TFA乙腈溶液(B液)組成,流速為0.2mL/min,使用流動相中B液遞增、A液遞減的梯度洗脫條件進行梯度洗脫,具體如下(%均為體積百分比):0-8min,流動相中B液的體積百分含量由10%勻速升至30%;8-50min,流動相中B液的體積百分含量由30%勻速升至55%;50-55min,流動相中B液的體積百分含量由55%勻速升至100%。檢測波長為210nm。
實驗結果見圖4(A為鮭魚降鈣素標準品水溶液,B為步驟三中的鮭魚降鈣素溶液):步驟三中的鮭魚降鈣素溶液與鮭魚降鈣素標準品水溶液的目的峰出峰時間基本一致(見圖4中箭頭標注,出峰時間為5.8min)。結果表明,步驟三中的鮭魚降鈣素溶液中含有鮭魚降鈣素。
五、檢測鮭魚降鈣素的生物學活性
Vr:CD1(ICR)小鼠為北京維通利華實驗動物技術有限公司的產品。鈣測定試劑盒為北京中生北控生物科技股份有限公司的產品。
1、取30只體重為24-26g的健康Vr:CD1(ICR)小鼠,隨機分成鮭魚降鈣素組、密鈣息組和生理鹽水組(每組10只,雌雄各半),禁食10-12h(僅給蒸餾水)后,分別進行如下處理:
鮭魚降鈣素組:尾靜脈注射步驟三中的鮭魚降鈣素溶液(注射劑量為0.1mL/只);
密鈣息組:尾靜脈注射密鈣息(注射劑量為0.5IU/只);
生理鹽水組:尾靜脈注射0.9%(0.9mg/100mL)生理鹽水(注射劑量為0.1mL/只)。
2、完成步驟1 60min后,每只小鼠先腹腔注射10%(10mg/100mL)水合氯醛水溶液(注射劑量為0.15mL/只),再分別從眼眶取血,室溫靜置2h;最后3000g離心15min,上清液即為血清。
3、完成步驟2后,取血清,按照鈣測定試劑盒的操作步驟,用全自動生化分析測定每只小鼠的血鈣濃度。
實驗結果見表1。結果表明,密鈣息組小鼠的血鈣濃度比生理鹽水組降低26.09%,鮭魚降鈣素組小鼠的血鈣濃度比生理鹽水組降低25.45%,方差分析差異極顯著。因此,使用步驟一至步驟三的方法獲得的鮭魚降鈣素溶液具有降低血鈣的生物學活性。
表1
實施例2、利用轉基因油菜種子表達系統表達鮭魚降鈣素
按照實施例1步驟一至步驟三的方法,將步驟一中的重組質粒pPha(p/gc/t)2300替換為重組質粒pPha(p/gc/t)2300-DZ,其它步驟均不變,得到鮭魚降鈣素溶液;每10g油菜種子產生0.15mg鮭魚降鈣素(以100%純度計)。
重組質粒pPha(p/gc/t)2300-DZ的構建方法為:按照實施例1步驟一的方法,將步驟13中“人工合成序列表中序列4所示的雙鏈DNA分子”替換為“人工合成序列表中序列8所示的雙鏈DNA分子”,其它步驟均不變,得到重組質粒pPha(p/gc/t)2300-DZ。重組質粒pPha(p/gc/t)2300-DZ也表達序列表中序列6所示的融合蛋白甲。
序列表中序列8中,自5′末端起第1至6位為限制性內切酶BamHⅠ的識別序列,第7至33位為甲酸的識別序列,第34至132位為鮭魚降鈣素的前體的編碼基因(以下簡稱sCT-DZ基因),第133至144位為四個終止密碼子,第145至150位為限制性內切酶PstI的識別序列。重組質粒pPha(p/gc/t)2300-DZ和重組質粒pPha(p/gc/t)2300的唯一不同在于:重組質粒pPha(p/gc/t)2300的鮭魚降鈣素的前體的編碼基因(即sCT基因)為序列表中序列4自5′末端起第34至132位所示,重組質粒pPha(p/gc/t)2300-DZ的鮭魚降鈣素的前體的編碼基因(即sCT-DZ基因)為序列表中序列8自5′末端起第34至132位所示。
<110> 中國農業科學院生物技術研究所
<120> 一種表達鮭魚降鈣素的方法及其專用表達盒
<160>8
<170> PatentInversion3.5
<210>1
<211>1631
<212>DNA
<213>人工序列
<220>
<223>
<400>1
gagctcgaat tcattgtact cccagtatca ttatagtgaa agttttggct ctctcgccgg 60
tggtttttta cctctattta aaggggtttt ccacctaaaa attctggtat cattctcact 120
ttacttgtta ctttaatttc tcataatctt tggttgaaat tatcacgctt ccgcacacga 180
tatccctaca aatttattat ttgttaaaca ttttcaaacc gcataaaatt ttatgaagtc 240
ccgtctatct ttaatgtagt ctaacatttt catattgaaa tatataattt acttaatttt 300
agcgttggta gaaagcataa agatttattc ttattcttct tcatataaat gtttaatata 360
caatataaac aaattcttta ccttaagaag gatttcccat tttatatttt aaaaatatat 420
ttatcaaata tttttcaacc acgtaaatct cataataata agttgtttca aaagtaataa 480
aatttaactc cataattttt ttattcgact gatcttaaag caacacccag tgacacaact 540
agccattttt ttctttgaat aaaaaaatcc aattatcatt gtattttttt tatacaatga 600
aaatttcacc aaacaatcat ttgtggtatt tctgaagcaa gtcatgttat gcaaaattct 660
ataattccca tttgacacta cggaagtaac tgaagatctg cttttacatg cgagacacat 720
cttctaaagt aattttaata atagttacta tattcaagat ttcatatatc aaatactcaa 780
tattacttct aaaaaattaa ttagatataa ttaaaatatt acttttttaa ttttaagttt 840
aattgttgaa tttgtgacta ttgatttatt attctactat gtttaaattg ttttatagat 900
agtttaaagt aaatataagt aatgtagtag agtgttagag tgttacccta aaccataaac 960
tataacattt atggtggact aattttcata tatttcttat tgcttttacc ttttcttggt 1020
atgtaagtcc gtaactagaa ttacagtggg ttgccatggc actctgtggt cttttggttc 1080
atgcatgggt cttgcgcaag aaaaagacaa agaacaaaga aaaaagacaa aacagagaga 1140
caaaacgcaa tcacacaacc aactcaaatt agtcactggc tgatcaagat cgccgcgtcc 1200
atgtatgtct aaatgccatg caaagcaaca cgtgcttaac atgcacttta aatggctcac 1260
ccatctcaac ccacacacaa acacattgcc tttttcttca tcatcaccac aaccacctgt 1320
atatattcat tctcttccgc cacctcaatt tcttcacttc aacacacgtc aacctgcata 1380
tgcgtgtcat cccatgccca aatctccatg catgttccaa ccaccttctc tcttatataa 1440
tacctataaa tacctctaat atcactcact tctttcatca tccatccatc cagagtacta 1500
ctactctact actataatac cccaacccaa ctcatattca atactactct actatgatga 1560
gagcaagggt tccactcctg ttgctgggaa ttcttttcct ggcatcactt tctgcctcat 1620
ttgccggtac c 1631
<210>2
<211>617
<212>DNA
<213>人工序列
<220>
<223>
<400>2
ctgcagataa gtatgaacta aaatgcatgt atggtgtaag agcacatgga gagcatggaa 60
atatgtatcc gaccatgtaa cactataata actgtgctcc atctcacttc ttctatgaat 120
aaacaaagga tgttatgata tattaacact atatgcacct tcacaagtaa tacattaata 180
tttaatactt tttattttaa ctttttagtt taaaatatta ttatattatt aactttttag 240
tttaaaatat ttatattatt ataaagagaa ataaacaaag gatgttatga tatattaaca 300
ctatatgtac cttacatagt aatatattaa tatttaatac tttttatttt aactttttaa 360
tttaaaatat tattataaat gacgcttgtg ttttatgtgt tggcatgctt gtattttatg 420
tgttgacttt ctgtgtgaag gtaatgtgat atggtgagct ggtggtaaca attgtgtttt 480
atgtgttggc tttctgtgaa gctaatttga tatggttagc tgatgtgaac aaaatattaa 540
aggaagctaa tttgatatgg ttagccgata gtaacaaaat atcaaaataa atttcttctt 600
actttaataa aaagctt 617
<210>3
<211>1845
<212>DNA
<213>人工序列
<220>
<223>
<400>3
ggtaccatgc atcatcacca ccatcaccat cacttacgtc ctgtagaaac cccaacccgt 60
gaaatcaaaa aactcgacgg cctgtgggca ttcagtctgg atcgcgaaaa ctgtggaatt 120
gatcagcgtt ggtgggaaag cgcgttacaa gaaagccggg caattgctgt gccaggcagt 180
tttaacgatc agttcgccga tgcagatatt cgtaattatg cgggcaacgt ctggtatcag 240
cgcgaagtct ttataccgaa aggttgggca ggccagcgta tcgtgctgcg tttcgatgcg 300
gtcactcatt acggcaaagt gtgggtcaat aatcaggaag tgatcgagca tcagggcggc 360
tatacgccat ttgaagccga tgtcacgccg tatgttattg ccgggaaaag tgtacgtatc 420
accgtttgtg tgaacaacga actgaactgg cagactatcc cgccgggagc tgtgattacc 480
gacgaaaacg gcaagaaaaa gcagtcttac ttccatgatt tctttaacta tgccggaatc 540
catcgcagcg taatcctcta caccacgccg aacacctggg tggacgatat caccgtggtg 600
acgcatgtcg cgcaagactg taaccacgcg tctgttgact ggcaggtggt ggccaatggt 660
gatgtcagcg ttgaactgcg tgatgcggat caacaggtgg ttgcaactgg acaaggcact 720
agcgggactt tgcaagtggt gaatccgcac ctctggcaac cgggtgaagg ttatctctat 780
gaactgtgcg tcacagccaa aagccagaca gagtgtgata tctacccgct tcgcgtcggc 840
atccggtcag tggcagtgaa gggcgaacag ttcctgatta accacaaacc gttctacttt 900
actggctttg gtcgtcatga agatgcggac ttgcgtggca aaggattcga taacgtgctg 960
attgtgcacg accacgcatt agctgactgg attggggcca actcctaccg tacctcgcat 1020
tacccttacg ctgaagagat cctcgactgg gcagatgaac atggcatcgt ggtgattgat 1080
gaaactgctg ctgtcggctt taacctctct ttaggcattg gtttcgaagc gggcaacaag 1140
ccgaaagaac tgtacagcga agaggcagtc aacggggaaa ctcagcaagc gcacttacag 1200
gcgattaaag agctgatagc gcgtgacaaa aaccacccaa gcgtggtgat ttggagtatt 1260
gccaacgaac cggatacccg tccgcaaggt gcacgggaat atttcgcgcc actggcggaa 1320
gcaacgcgta aactcgaccc gacgcgtccg atcacctgcg tcaatgtagc attctgcgac 1380
gctcacaccg ataccatcag cgatctcttt gatgtgctgt gcctgaaccg ttattacgga 1440
tggtatgtcc aaagcggcga tttggaaacg gcagagaagg tactggaaaa agaacttctg 1500
gcctggcagg agaaactgca tcagccgatt atcatcaccg aatacggcgt ggatacgtta 1560
gccgggctgc actcagcata caccgacatt tggagtgaag agtatcagtg tgcatggctg 1620
gatacctatc accgcgtctt tgatcgcgtc agcgccgtcg tcggtgaaca ggtatggaat 1680
ttcgccgatt ttgcgacctc gcaaggcata ttgcgcgttg gcggtaacaa gaaagggatc 1740
ttcactcgcg accgcaaacc gaagtcggcg gcttttctgc tgcaaaaacg ctggactggc 1800
ataaacttcg gtgaaaaacc gcagcaggga ggcaaacaag gatcc 1845
<210>4
<211>150
<212>DNA
<213>人工序列
<220>
<223>
<400>4
ggatccgacc cacctgatcc acctgatcca atgtgctcta acctttctac ttgcgttctt 60
ggaaagttgt ctcaagagct tcataaactt caaacttacc caagaactaa caccggatct 120
ggaactccag gataatgata atgactgcag 150
<210>5
<211>4213
<212>DNA
<213>人工序列
<220>
<223>
<400>5
gaattcattg tactcccagt atcattatag tgaaagtttt ggctctctcg ccggtggttt 60
tttacctcta tttaaagggg ttttccacct aaaaattctg gtatcattct cactttactt 120
gttactttaa tttctcataa tctttggttg aaattatcac gcttccgcac acgatatccc 180
tacaaattta ttatttgtta aacattttca aaccgcataa aattttatga agtcccgtct 240
atctttaatg tagtctaaca ttttcatatt gaaatatata atttacttaa ttttagcgtt 300
ggtagaaagc ataaagattt attcttattc ttcttcatat aaatgtttaa tatacaatat 360
aaacaaattc tttaccttaa gaaggatttc ccattttata ttttaaaaat atatttatca 420
aatatttttc aaccacgtaa atctcataat aataagttgt ttcaaaagta ataaaattta 480
actccataat ttttttattc gactgatctt aaagcaacac ccagtgacac aactagccat 540
ttttttcttt gaataaaaaa atccaattat cattgtattt tttttataca atgaaaattt 600
caccaaacaa tcatttgtgg tatttctgaa gcaagtcatg ttatgcaaaa ttctataatt 660
cccatttgac actacggaag taactgaaga tctgctttta catgcgagac acatcttcta 720
aagtaatttt aataatagtt actatattca agatttcata tatcaaatac tcaatattac 780
ttctaaaaaa ttaattagat ataattaaaa tattactttt ttaattttaa gtttaattgt 840
tgaatttgtg actattgatt tattattcta ctatgtttaa attgttttat agatagttta 900
aagtaaatat aagtaatgta gtagagtgtt agagtgttac cctaaaccat aaactataac 960
atttatggtg gactaatttt catatatttc ttattgcttt taccttttct tggtatgtaa 1020
gtccgtaact agaattacag tgggttgcca tggcactctg tggtcttttg gttcatgcat 1080
gggtcttgcg caagaaaaag acaaagaaca aagaaaaaag acaaaacaga gagacaaaac 1140
gcaatcacac aaccaactca aattagtcac tggctgatca agatcgccgc gtccatgtat 1200
gtctaaatgc catgcaaagc aacacgtgct taacatgcac tttaaatggc tcacccatct 1260
caacccacac acaaacacat tgcctttttc ttcatcatca ccacaaccac ctgtatatat 1320
tcattctctt ccgccacctc aatttcttca cttcaacaca cgtcaacctg catatgcgtg 1380
tcatcccatg cccaaatctc catgcatgtt ccaaccacct tctctcttat ataataccta 1440
taaatacctc taatatcact cacttctttc atcatccatc catccagagt actactactc 1500
tactactata ataccccaac ccaactcata ttcaatacta ctctactatg atgagagcaa 1560
gggttccact cctgttgctg ggaattcttt tcctggcatc actttctgcc tcatttgccg 1620
gtaccatgca tcatcaccac catcaccatc acttacgtcc tgtagaaacc ccaacccgtg 1680
aaatcaaaaa actcgacggc ctgtgggcat tcagtctgga tcgcgaaaac tgtggaattg 1740
atcagcgttg gtgggaaagc gcgttacaag aaagccgggc aattgctgtg ccaggcagtt 1800
ttaacgatca gttcgccgat gcagatattc gtaattatgc gggcaacgtc tggtatcagc 1860
gcgaagtctt tataccgaaa ggttgggcag gccagcgtat cgtgctgcgt ttcgatgcgg 1920
tcactcatta cggcaaagtg tgggtcaata atcaggaagt gatcgagcat cagggcggct 1980
atacgccatt tgaagccgat gtcacgccgt atgttattgc cgggaaaagt gtacgtatca 2040
ccgtttgtgt gaacaacgaa ctgaactggc agactatccc gccgggagct gtgattaccg 2100
acgaaaacgg caagaaaaag cagtcttact tccatgattt ctttaactat gccggaatcc 2160
atcgcagcgt aatcctctac accacgccga acacctgggt ggacgatatc accgtggtga 2220
cgcatgtcgc gcaagactgt aaccacgcgt ctgttgactg gcaggtggtg gccaatggtg 2280
atgtcagcgt tgaactgcgt gatgcggatc aacaggtggt tgcaactgga caaggcacta 2340
gcgggacttt gcaagtggtg aatccgcacc tctggcaacc gggtgaaggt tatctctatg 2400
aactgtgcgt cacagccaaa agccagacag agtgtgatat ctacccgctt cgcgtcggca 2460
tccggtcagt ggcagtgaag ggcgaacagt tcctgattaa ccacaaaccg ttctacttta 2520
ctggctttgg tcgtcatgaa gatgcggact tgcgtggcaa aggattcgat aacgtgctga 2580
ttgtgcacga ccacgcatta gctgactgga ttggggccaa ctcctaccgt acctcgcatt 2640
acccttacgc tgaagagatc ctcgactggg cagatgaaca tggcatcgtg gtgattgatg 2700
aaactgctgc tgtcggcttt aacctctctt taggcattgg tttcgaagcg ggcaacaagc 2760
cgaaagaact gtacagcgaa gaggcagtca acggggaaac tcagcaagcg cacttacagg 2820
cgattaaaga gctgatagcg cgtgacaaaa accacccaag cgtggtgatt tggagtattg 2880
ccaacgaacc ggatacccgt ccgcaaggtg cacgggaata tttcgcgcca ctggcggaag 2940
caacgcgtaa actcgacccg acgcgtccga tcacctgcgt caatgtagca ttctgcgacg 3000
ctcacaccga taccatcagc gatctctttg atgtgctgtg cctgaaccgt tattacggat 3060
ggtatgtcca aagcggcgat ttggaaacgg cagagaaggt actggaaaaa gaacttctgg 3120
cctggcagga gaaactgcat cagccgatta tcatcaccga atacggcgtg gatacgttag 3180
ccgggctgca ctcagcatac accgacattt ggagtgaaga gtatcagtgt gcatggctgg 3240
atacctatca ccgcgtcttt gatcgcgtca gcgccgtcgt cggtgaacag gtatggaatt 3300
tcgccgattt tgcgacctcg caaggcatat tgcgcgttgg cggtaacaag aaagggatct 3360
tcactcgcga ccgcaaaccg aagtcggcgg cttttctgct gcaaaaacgc tggactggca 3420
taaacttcgg tgaaaaaccg cagcagggag gcaaacaagg atccgaccca cctgatccac 3480
ctgatccaat gtgctctaac ctttctactt gcgttcttgg aaagttgtct caagagcttc 3540
ataaacttca aacttaccca agaactaaca ccggatctgg aactccagga taatgataat 3600
gactgcagat aagtatgaac taaaatgcat gtatggtgta agagcacatg gagagcatgg 3660
aaatatgtat ccgaccatgt aacactataa taactgtgct ccatctcact tcttctatga 3720
ataaacaaag gatgttatga tatattaaca ctatatgcac cttcacaagt aatacattaa 3780
tatttaatac tttttatttt aactttttag tttaaaatat tattatatta ttaacttttt 3840
agtttaaaat atttatatta ttataaagag aaataaacaa aggatgttat gatatattaa 3900
cactatatgt accttacata gtaatatatt aatatttaat actttttatt ttaacttttt 3960
aatttaaaat attattataa atgacgcttg tgttttatgt gttggcatgc ttgtatttta 4020
tgtgttgact ttctgtgtga aggtaatgtg atatggtgag ctggtggtaa caattgtgtt 4080
ttatgtgttg gctttctgtg aagctaattt gatatggtta gctgatgtga acaaaatatt 4140
aaaggaagct aatttgatat ggttagccga tagtaacaaa atatcaaaat aaatttcttc 4200
ttactttaat aaa 4213
<210>6
<211>655
<212>PRT
<213>人工序列
<220>
<223>
<400>6
Met His His His His His His His His Leu Arg Pro Val Glu Thr Pro
1 5 10 15
Thr Arg Glu Ile Lys Lys Leu Asp Gly Leu Trp Ala Phe Ser Leu Asp
20 25 30
Arg Glu Asn Cys Gly Ile Asp Gln Arg Trp Trp Glu Ser Ala Leu Gln
35 40 45
Glu Ser Arg Ala Ile Ala Val Pro Gly Ser Phe Asn Asp Gln Phe Ala
50 55 60
Asp Ala Asp Ile Arg Asn Tyr Ala Gly Asn Val Trp Tyr Gln Arg Glu
65 70 75 80
Val Phe Ile Pro Lys Gly Trp Ala Gly Gln Arg Ile Val Leu Arg Phe
85 90 95
Asp Ala Val Thr His Tyr Gly Lys Val Trp Val Asn Asn Gln Glu Val
100 105 110
Ile Glu His Gln Gly Gly Tyr Thr Pro Phe Glu Ala Asp Val Thr Pro
115 120 125
Tyr Val Ile Ala Gly Lys Ser Val Arg Ile Thr Val Cys Val Asn Asn
130 135 140
Glu Leu Asn Trp Gln Thr Ile Pro Pro Gly Ala Val Ile Thr Asp Glu
145 150 155 160
Asn Gly Lys Lys Lys Gln Ser Tyr Phe His Asp Phe Phe Asn Tyr Ala
165 170 175
Gly Ile His Arg Ser Val Ile Leu Tyr Thr Thr Pro Asn Thr Trp Val
180 185 190
Asp Asp Ile Thr Val Val Thr His Val Ala Gln Asp Cys Asn His Ala
195 200 205
Ser Val Asp Trp Gln Val Val Ala Asn Gly Asp Val Ser Val Glu Leu
210 215 220
Arg Asp Ala Asp Gln Gln Val Val Ala Thr Gly Gln Gly Thr Ser Gly
225 230 235 240
Thr Leu Gln Val Val Asn Pro His Leu Trp Gln Pro Gly Glu Gly Tyr
245 250 255
Leu Tyr Glu Leu Cys Val Thr Ala Lys Ser Gln Thr Glu Cys Asp Ile
260 265 270
Tyr Pro Leu Arg Val Gly Ile Arg Ser Val Ala Val Lys Gly Glu Gln
275 280 285
Phe Leu Ile Asn His Lys Pro Phe Tyr Phe Thr Gly Phe Gly Arg His
290 295 300
Glu Asp Ala Asp Leu Arg Gly Lys Gly Phe Asp Asn Val Leu Ile Val
305 310 315 320
His Asp His Ala Leu Ala Asp Trp Ile Gly Ala Asn Ser Tyr Arg Thr
325 330 335
Ser His Tyr Pro Tyr Ala Glu Glu Ile Leu Asp Trp Ala Asp Glu His
340 345 350
Gly Ile Val Val Ile Asp Glu Thr Ala Ala Val Gly Phe Asn Leu Ser
355 360 365
Leu Gly Ile Gly Phe Glu Ala Gly Asn Lys Pro Lys Glu Leu Tyr Ser
370 375 380
Glu Glu Ala Val Asn Gly Glu Thr Gln Gln Ala His Leu Gln Ala Ile
385 390 395 400
Lys Glu Leu Ile Ala Arg Asp Lys Asn His Pro Ser Val Val Ile Trp
405 410 415
Ser Ile Ala Asn Glu Pro Asp Thr Arg Pro Gln Gly Ala Arg Glu Tyr
420 425 430
Phe Ala Pro Leu Ala Glu Ala Thr Arg Lys Leu Asp Pro Thr Arg Pro
435 440 445
Ile Thr Cys Val Asn Val Ala Phe Cys Asp Ala His Thr Asp Thr Ile
450 455 460
Ser Asp Leu Phe Asp Val Leu Cys Leu Asn Arg Tyr Tyr Gly Trp Tyr
465 470 475 480
Val Gln Ser Gly Asp Leu Glu Thr Ala Glu Lys Val Leu Glu Lys Glu
485 490 495
Leu Leu Ala Trp Gln Glu Lys Leu His Gln Pro Ile Ile Ile Thr Glu
500 505 510
Tyr Gly Val Asp Thr Leu Ala Gly Leu His Ser Ala Tyr Thr Asp Ile
515 520 525
Trp Ser Glu Glu Tyr Gln Cys Ala Trp Leu Asp Thr Tyr His Arg Val
530 535 540
Phe Asp Arg Val Ser Ala Val Val Gly Glu Gln Val Trp Asn Phe Ala
545 550 555 560
Asp Phe Ala Thr Ser Gln Gly Ile Leu Arg Val Gly Gly Asn Lys Lys
565 570 575
Gly Ile Phe Thr Arg Asp Arg Lys Pro Lys Ser Ala Ala Phe Leu Leu
580 585 590
Gln Lys Arg Trp Thr Gly Ile Asn Phe Gly Glu Lys Pro Gln Gln Gly
595 600 605
Gly Lys Gln Gly Ser Asp Pro Pro Asp Pro Pro Asp Pro Met Cys Ser
610 615 620
Asn Leu Ser Thr Cys Val Leu Gly Lys Leu Ser Gln Glu Leu His Lys
625 630 635 640
Leu Gln Thr Tyr Pro Arg Thr Asn Thr Gly Ser Gly Thr Pro Gly
645 650 655
<210>7
<211>654
<212>PRT
<213>人工序列
<220>
<223>
<400>7
Met His His His His His His His His Leu Arg Pro Val Glu Thr Pro
1 5 10 15
Thr Arg Glu Ile Lys Lys Leu Asp Gly Leu Trp Ala Phe Ser Leu Asp
20 25 30
Arg Glu Asn Cys Gly Ile Asp Gln Arg Trp Trp Glu Ser Ala Leu Gln
35 40 45
Glu Ser Arg Ala Ile Ala Val Pro Gly Ser Phe Asn Asp Gln Phe Ala
50 55 60
Asp Ala Asp Ile Arg Asn Tyr Ala Gly Asn Val Trp Tyr Gln Arg Glu
65 70 75 80
Val Phe Ile Pro Lys Gly Trp Ala Gly Gln Arg Ile Val Leu Arg Phe
85 90 95
Asp Ala Val Thr His Tyr Gly Lys Val Trp Val Asn Asn Gln Glu Val
100 105 110
Ile Glu His Gln Gly Gly Tyr Thr Pro Phe Glu Ala Asp Val Thr Pro
115 120 125
Tyr Val Ile Ala Gly Lys Ser Val Arg Ile Thr Val Cys Val Asn Asn
130 135 140
Glu Leu Asn Trp Gln Thr Ile Pro Pro Gly Ala Val Ile Thr Asp Glu
145 150 155 160
Asn Gly Lys Lys Lys Gln Ser Tyr Phe His Asp Phe Phe Asn Tyr Ala
165 170 175
Gly Ile His Arg Ser Val Ile Leu Tyr Thr Thr Pro Asn Thr Trp Val
180 185 190
Asp Asp Ile Thr Val Val Thr His Val Ala Gln Asp Cys Asn His Ala
195 200 205
Ser Val Asp Trp Gln Val Val Ala Asn Gly Asp Val Ser Val Glu Leu
210 215 220
Arg Asp Ala Asp Gln Gln Val Val Ala Thr Gly Gln Gly Thr Ser Gly
225 230 235 240
Thr Leu Gln Val Val Asn Pro His Leu Trp Gln Pro Gly Glu Gly Tyr
245 250 255
Leu Tyr Glu Leu Cys Val Thr Ala Lys Ser Gln Thr Glu Cys Asp Ile
260 265 270
Tyr Pro Leu Arg Val Gly Ile Arg Ser Val Ala Val Lys Gly Glu Gln
275 280 285
Phe Leu Ile Asn His Lys Pro Phe Tyr Phe Thr Gly Phe Gly Arg His
290 295 300
Glu Asp Ala Asp Leu Arg Gly Lys Gly Phe Asp Asn Val Leu Ile Val
305 310 315 320
His Asp His Ala Leu Ala Asp Trp Ile Gly Ala Asn Ser Tyr Arg Thr
325 330 335
Ser His Tyr Pro Tyr Ala Glu Glu Ile Leu Asp Trp Ala Asp Glu His
340 345 350
Gly Ile Val Val Ile Asp Glu Thr Ala Ala Val Gly Phe Asn Leu Ser
355 360 365
Leu Gly Ile Gly Phe Glu Ala Gly Asn Lys Pro Lys Glu Leu Tyr Ser
370 375 380
Glu Glu Ala Val Asn Gly Glu Thr Gln Gln Ala His Leu Gln Ala Ile
385 390 395 400
Lys Glu Leu Ile Ala Arg Asp Lys Asn His Pro Ser Val Val Ile Trp
405 410 415
Ser Ile Ala Asn Glu Pro Asp Thr Arg Pro Gln Gly Ala Arg Glu Tyr
420 425 430
Phe Ala Pro Leu Ala Glu Ala Thr Arg Lys Leu Asp Pro Thr Arg Pro
435 440 445
Ile Thr Cys Val Asn Val Ala Phe Cys Asp Ala His Thr Asp Thr Ile
450 455 460
Ser Asp Leu Phe Asp Val Leu Cys Leu Asn Arg Tyr Tyr Gly Trp Tyr
465 470 475 480
Val Gln Ser Gly Asp Leu Glu Thr Ala Glu Lys Val Leu Glu Lys Glu
485 490 495
Leu Leu Ala Trp Gln Glu Lys Leu His Gln Pro Ile Ile Ile Thr Glu
500 505 510
Tyr Gly Val Asp Thr Leu Ala Gly Leu His Ser Ala Tyr Thr Asp Ile
515 520 525
Trp Ser Glu Glu Tyr Gln Cys Ala Trp Leu Asp Thr Tyr His Arg Val
530 535 540
Phe Asp Arg Val Ser Ala Val Val Gly Glu Gln Val Trp Asn Phe Ala
545 550 555 560
Asp Phe Ala Thr Ser Gln Gly Ile Leu Arg Val Gly Gly Asn Lys Lys
565 570 575
Gly Ile Phe Thr Arg Asp Arg Lys Pro Lys Ser Ala Ala Phe Leu Leu
580 585 590
Gln Lys Arg Trp Thr Gly Ile Asn Phe Gly Glu Lys Pro Gln Gln Gly
595 600 605
Gly Lys Gln Gly Ser Asp Pro Pro Asp Pro Pro Asp Pro Met Cys Ser
610 615 620
Asn Leu Ser Thr Cys Val Leu Gly Lys Leu Ser Gln Glu Leu His Lys
625 630 635 640
Leu Gln Thr Tyr Pro Arg Thr Asn Thr Gly Ser Gly Thr Pro
645 650
<210>8
<211>150
<212>DNA
<213>人工序列
<220>
<223>
<400>8
ggatccgacc cacctgatcc acctgatcca atgtgctcaa acttgtctac ctgtgttctt 60
ggtaagttgt ctcaggaact tcacaagttg caaacctacc caaggactaa cactggttct 120
ggaaccccag gataatgata atgactgcag 150
- 還沒有人留言評論。精彩留言會獲得點贊!