控制大豆葉柄夾角大小的基因及其編碼蛋白與應用的制作方法
本發明涉及基因工程領域,特別是涉及控制大豆葉柄夾角大小的GmLPA1基因及其編碼的蛋白與應用。
背景技術:
葉柄夾角是大豆及眾多豆科植物株型性狀的構成因素之一,直接影響植株光截獲量、光和效率及最終產量,是作物育種中重要的育種目標性狀。葉柄夾角是由被稱為葉枕的馬達器官所決定,葉枕是葉柄或葉片基部與主莖相連的膨大組織,決定植物的感夜運動和輕觸性運動。現有研究中,僅蒺藜苜蓿中發現了控制小葉葉枕屬性的ELP1/PLP基因,該基因功能缺失的蒺藜苜蓿突變體葉枕機構和感夜運動缺失。然而,控制葉柄夾角的遺傳機制還未在任何植物中報道,因此,分離調控大豆葉柄夾角和感夜運動的主要因子,對通過優化株型提高大豆產量具有重要意義。
技術實現要素:
為進一步優化株型提高大豆產量,本發明的目的是提供一種從大豆中分離的控制大豆葉柄夾角大小的GmLPA1基因及其編碼蛋白與應用。
本發明提供一種控制大豆葉柄夾角大小的GmLPA1基因,其核苷酸序列為:
a如SEQ ID No.1所示;或b在SEQ ID No.1所示的核苷酸序列中經取代、缺失或添加一個或幾個核苷酸且具有同等控制大豆葉柄夾角大小功能的由a衍生的基因。
核苷酸序列如SEQ ID No.1所示的GmLPA1基因全長3708bp,共有4個外顯子和3個內含子,CDS區基因的核苷酸序列如SEQ ID No.3所示,長1734bp。
本發明提供由上述控制大豆葉柄夾角的GmLPA1基因編碼的蛋白,其為:
1)由SEQ ID No.2所示的氨基酸序列組成的蛋白;或2)在SEQ ID No.2所示的氨基酸序列中經取代、缺失或添加一個或幾個氨基酸且具有同等控制大豆葉柄夾角大小活性的由1)衍生的蛋白。
氨基酸序列如SEQ ID No.2所示的蛋白由577個氨基酸殘基組成,主要由6個功能域組成,從N端開始分別是TPR1、TPR2、TPR3、TPR4、TPR5、TPR6。
應當理解,本領域技術人員可根據本發明公開的氨基酸序列,在不影響其活性的前提下,取代、缺失和/或增加一個或幾個氨基酸,得到所述蛋白的突變序列。例如,將非活性區段的第550位精氨酸替換為絲氨酸,得到蛋白的突變體序列,且不影響其活性。
因此,本發明的控制大豆葉柄夾角的GmLPA1基因編碼的蛋白還包括SEQ ID No.2所示氨基酸序列經取代、替換和/或增加一個或幾個氨基酸,具有同等活性的控制大豆葉柄夾角的GmLPA1基因編碼的蛋白衍生得到的蛋白。本發明控制大豆葉柄夾角的GmLPA1基因包括編碼所述衍生得到的蛋白的核酸序列,此外,應理解,考慮到密碼子的簡并性以及不同物種密碼子的偏愛性,本領域技術人員可以根據需要使用適合特定物種表達的密碼子。
本發明還提供含有控制大豆葉柄夾角的GmLPA1基因核苷酸序列或其片段的克隆載體或各類表達載體。
本發明還提供含有所述載體的宿主細胞。
本發明還提供含有控制大豆葉柄夾角的GmLPA1基因核苷酸序列或其特異片段的轉化植物細胞和轉基因植物。
本發明還提供用于擴增GmLPA1基因的cDNA片段的特異性引物對,其為:
上游引物:5’-AGTGTAGCCGAAGGCAATGAG-3’,如SEQ ID No.4所示;
下游引物:5’-ACATGTGGATTAAGATCGAAGTGC-3’,如SEQ ID No.5所示。
本發明進一步提供控制大豆葉柄夾角的GmLPA1基因在調控植物株形中的應用,其為將GmLPA1基因轉入待改造植物獲得葉柄夾角變小的轉基因植物,具體步驟為i將GmLPA1基因轉入植物細胞;ii以i中的植物細胞培育轉基因植株。
所述植物優選為豆科植物,更優選為大豆。
本發明的有益效果在于:
(1)本發明提供了控制大豆葉柄夾角的GmLPA1基因及其編碼的蛋白,為進一步研究植物株型調控的分子機理提供依據。
(2)GMLPA1基因具有控制葉柄夾角大小的功能,有望以此對植物株形的形成進行調控進而對株形定向設計,以提高植物生產力。
附圖說明
圖1為大豆GMLPA1基因的基因組序列。
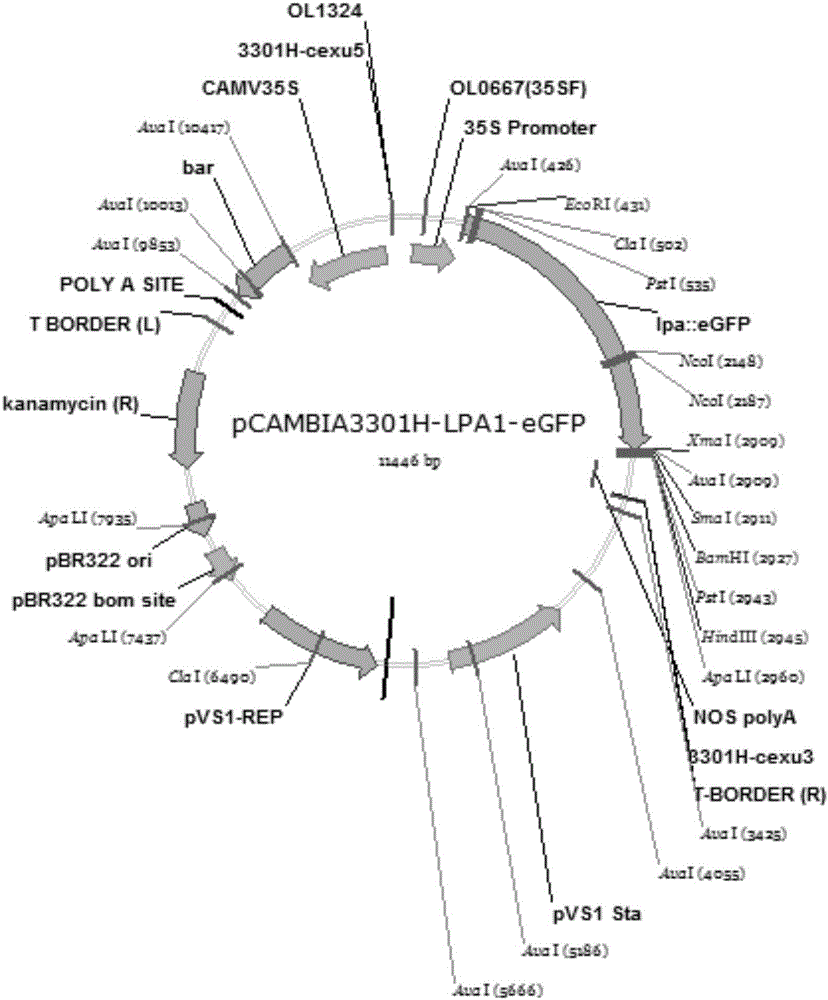
圖2為實施例2中大豆GmLPA1基因的正義表達載體。
圖3為實施例3中GmLPA1基因過量表達后的T2代大豆的葉柄夾角照片,其中,a為菏豆12號,b為Gmlpa1突變體,c為GmLPA1基因過量表達的Gmlpa1突變體。
圖4為實施例4中不同大豆栽培品種感夜運動折線圖。
圖5為實施例4中GmLPA1基因在不同大豆栽培品種中的表達水平柱狀圖。
具體實施方式
以下實施例用于說明本發明,但不用來限制本發明的范圍。若未特別指明,所用的技術手段為本領域技術人員所熟知的常規手段;所用的實驗方法均為常規方法;所用的材料、試劑等,均可從商業途徑得到。
實施例中所涉植物材料如下:
以下實施例中使用的大豆品種為菏豆12號(審定編號:魯種審字2002012)。
實施例1 大豆中GmLPA1基因的分離和結構分析
(1)基因的分離
從大豆品種菏豆12號的幼嫩葉片中提取mRNA,以此mRNA為模板,以Oligo(T)17為引物合成cDNA第一條鏈。接著以該cDNA第一條鏈為模板,引物(5’-AGTGTAGCCGAAGGCAATGAG-3’,如SEQ ID No.4所示)和引物(5’-ACATGTGGATTAAGATCGAAGTGC-3’,如SEQ ID No.5所示)進行PCR擴增,獲得了1個GmLPA1基因的長為1734bp的cDNA片段,克隆到pGEM T Easy載體(TaKaRa公司)中并命名為pGEM T Easy-LPA1。
pGEM T Easy-LPA1中所包含GmLPA1基因的CDS序列如SEQ ID NO:3所示,共1734bp,它編碼一個577個氨基酸的蛋白(SEQ ID NO:2)。
(2)基因的結構分析
以菏豆12號幼嫩葉片為材料,提取其中的DNA,接著以該基因組DNA為模板,OL4234/OL4235為引物進行擴增獲得了GmLPA1基因組的片段,GmLPA1基因的DNA序列如SEQ ID NO:1所示,共3708bp,它含有3個內含子和4個外顯子(如圖1)。
實施例2 GmLPA1正義表達載體的構建
將GmLPA1的CDS和綠色熒光蛋白GFP的CDS融合正向連到植物表達載體pCAMBIA3301H(CAMBIA研究中心)中,得到帶有GFP標簽的GmLPA1正義的表達載體,該載體全長為11.4Kbp(如圖2),在大腸桿菌中的抗性為卡那霉素抗性,在植物體中的抗性為草銨膦抗性。
實施例3 農桿菌介導法轉化豆科植物
在本實施例中,通過農桿菌介導法轉化大豆胚尖的方法,得到含有GmLPA1調控基因的正義表達載體的Gmlpa1突變體的外植體。
(A)大豆外植體的獲得
從荷豆12號中發現葉柄夾角大的突變體植株(由γ射線誘變的菏豆12號突變體庫中篩選獲得),突變體命名為Gmlpa1,選取表面光滑、無破損、無病斑、無裂痕的Gmlpa1突變體成熟大豆種子,以氯氣方法滅菌14h。將滅菌后的種子在超凈臺上通風,使氯氣完全揮發,在萌發培養基萌發處理6h。去掉大豆1/2胚軸,將大豆沿胚軸縱向切開,將剩余下胚軸作為農桿菌介導轉化的受體材料。
(B)大豆轉化
農桿菌介導法采用二次農桿菌侵染,在共培養基上于22℃暗培養5d;SI-I培養基中,于強光下培養7d;切去外植體大芽,在SI-II培養基中,于強光下培養14d;切去外植體子葉和胚軸,于SE培養基中,每14d繼代一次;將約3cm叢生芽剪下,放入生根培養基中生根;將RM生根培養基中,根部生長發達的植株轉入土中栽植。最終篩選得到了8個抗性植株,Bar檢測這8株植物均為陽性。在溫室中培養5個月后果莢開始成熟,6個月后收種完畢。
(C)可以遺傳的轉基因植株
將收獲的T1代種子在溫室中每個株系種植4株,可以觀察到過量表達GmLPA1基因的Gmlpa1突變體植株葉枕恢復膝狀凸起結構、葉柄夾角明顯小于Gmlpa1突變體葉柄夾角,與野生型荷豆12號的葉柄夾角一致(如圖3)。
實施例4 大豆GmLPA1基因的育種學意義
通過分析和檢測16個不同大豆品種(青雜豆、青皮豆、小黃金、壓迫車、黑青豆8號、吉黃35號、滿倉金、吉林19號、鐵莢青、青皮豆16號、鞍掛豆、長農2號、吉林4號、吉林6號、吉林35號、吉林小粒)中感夜運動能力和GmLPA1基因的表達水平,發現不同品種的運動能力強弱可同通過12:00和18:00點的葉片夾角劃分,所有品種在12:00點的葉片夾角顯著大于18:00點的葉片夾角(如圖4),同時,GmLPA1基因的表達水平在12:00點顯著高于18:00點。GmLPA1基因的表達水平在運動能力強的品種中顯著高于運動能力弱的品種(如圖5)。因此,GmLPA1基因的表達水平與植物的運動能力直接存在顯著正相關性。
綜上所述,大豆GmLPA1基因可以參與調控植物的葉柄夾角大小的決定,通過轉基因的手段可以改變植物葉枕結構及葉柄夾角大小,從而優化植物的株型結構,提高產量。
雖然,上文中已經用一般性說明及具體實施方案對本發明作了詳盡的描述,但在本發明基礎上,可以對之作一些修改或改進,這對本領域技術人員而言是顯而易見的。因此,在不偏離本發明精神的基礎上所做的這些修改或改進,均屬于本發明要求保護的范圍。
SEQUENCE LISTING
<110> 中國科學院東北地理與農業生態研究所
<120> 控制大豆葉柄夾角大小的基因及其編碼蛋白與應用
<130> KHP161117683.4Q
<160> 5
<170> PatentIn version 3.3
<210> 1
<211> 3708
<212> DNA
<213> 大豆GMLPA1
<400> 1
agaagcccag aagcgaatga aaaagagagg gggaaaggaa ttggagagaa caatttgaaa 60
acagcagtgg cagtgtttgc attacatgca gtgtagccga aggcaatgag ttccaaagag 120
agttgcagaa gtgaacttcg cattgcgatc cgccaactca gtgatcgatg tctctactct 180
gcttctaaat ggtacccctt acaaaaaccc taattcaaac aaattggggg tttccacttg 240
acctcaagtt ttgaattttg aagtcccctt ttacttttct gtgtgattcc gcaaatgggt 300
cgtttgtttc tgacgaaaat gtggtttcag ggctgcagaa cagttggtgg gtattgagca 360
agaccctgcc aagttcactc cctcgaacac gagatttcag cgtgggagtt cgagcattcg 420
caggaagtac aagactcacg agatcacggg aaccccaatc gcgggtgttt cgtatgttgc 480
cacgcctgcg atggaggaag atgagcttgt agatggtgat ttctaccttc tggcaaagtc 540
ctattttgat tgccgtgagt ataagagagc tgctcatgtt cttcgtgatc agaacggaag 600
gaaatcggtg ttcctgcgct gccatgctct ctatctggtc agttttgtgt cccctctttt 660
gctttggatt gaatttgcct tttcatcagt gggattttac gtgttaatgt gatagtgaag 720
cttggatttt ctgagttttg gtgcattctg gagttgaatg ttcttttccc catgattcgt 780
atgtatcatt gaagagaatt tgatttttaa ttcacgtgtg tgtatgtctt tggctaacga 840
atcttctttg atgattgtaa ttcgattagt ggatacaaag ggcttcggtg aagttagtgg 900
aagtatagaa agattacata aacatgtctt tcagttcaat ttcatggcta aatctatttt 960
ggtgtgatat gccggttatc ctctaaatag attgcaatta ataggtggga atacactctg 1020
tgctgctata ggccattgat tactttgttc taaggagaag gtccttagcc tgttatgttt 1080
tacatttttc ttcttcttct tcttcttttt ctaagcaaag aggattacta tgaagcctat 1140
acttgatgca acactggtat gatacgacat ctgaatgact tatacatatc taaaagtacc 1200
atacatgtat cagtatcaga tacatgtcat caattctttg ccatttatgg agtatttgag 1260
cttcattggc gggctacatc tatttttatt cttggtgtct agtgctgtca agtgatgttt 1320
accttcatta tgtgttctgt ttttcttaat ctggacctgt actccccaca tgaccattat 1380
ggtaaataat tgtgcaactt cctggtgtgc tgtttggctc aaaaacaagt cttcagatcc 1440
catgggaagt aaaaagtcta attatactca attgacttca ttttgactac tcattttctc 1500
cctaatgcat tcaatgaact atgttataat gacattttat gcatgatttc tttccaaaag 1560
ggtgtgtttc cttcaataac gataagcttg acaacattga atatatttgt ggaagctgca 1620
gcagatgtca ggccataaac agtacaaaac cattgggtga atggttaatg taatattgat 1680
cccatgttgt acatcatctg ggattcaact ttccatccaa tgatatgtgt agaattttct 1740
taaaatgaaa catttttttt tatatttttg ttccaaaaac attttttttt ttatattttt 1800
ctatcactgt gactccactc ctgtaacata cacttttcta agagaaattt tttgtcgact 1860
actttagtta atccaccccc ttatatctat ccatagatat agagagattg ttgatcatag 1920
tgtgtgcggc tgtatcactt gttacttttc tctttggtga aatcaaaata aaaacaatta 1980
agtgtacatt gtttgtgtta atatttttcc ataatttttt tctttttaca ggctggtgaa 2040
aagcggaaag aggaagagat gatagaactt gaggggcctc tgggtaagag tgacgctgtc 2100
aatcatgaat tggtttcttt ggagagagag ttgtcaactt ttcgcaagaa tggcaaagtt 2160
gatccttttt gtttgtactt atatggtctt gtgctcaaac agaaaggcag tgagaatctt 2220
gcacgtgcag ttcttgtaga atctgtgaat agctaccctt ggaactggaa tgcctggact 2280
gagttgcaat ccttatgcaa aacagtggat atattgaata gtcttaatct caatagccat 2340
tggatgaagg actttttcct tgccagtgtt taccaagaat taaggatgca caatgactct 2400
ctgtcaaaat atgaatacct actaggaacc tttagtaata gtaattatgt acaagcacaa 2460
attgcaaaag cccagtacag tttgagggaa tttgaccaag ttgaagcaat atttgaagaa 2520
ctgctgagta atgatcctta cagagtggaa gacatggaca tgtactccaa tgtgctttat 2580
gctaaggaat gcttttctgc tttgagttat cttgcccata gagtattcat gactgataaa 2640
tacagacctg aatcttgttg tattattggg aattactata gtttaaaggg acagcatgag 2700
aagtcagttg tgtattttag gagagccctt aaattgaaca aaaacttttt atcggcttgg 2760
acacttatgg ggcatgagtt tgtagagatg aaaaacactc ctgctgctgt ggatgcctat 2820
cgtcgggcag tagatataga cccacgtgat tatcgtgctt ggtatggact aggacaggct 2880
tatgagatga tgggcatgcc tttctatgcg cttcattact tcaaaaaatc tgtattcttg 2940
cagccaaatg attctcgttt gtggattgca atggctcagt gttatgaaac tgatcaactt 3000
cgcatgcttg atgaagcaat aaagtgttac agaagggcag caaactgtaa tgacagggaa 3060
gcaattgctc tgcacaactt ggcaaaactt cactcggagc tagggcgccc tgaagaggct 3120
gcattttact acaaaaagga cttagagagg atggaatctg aagaaaggga aggacctaaa 3180
atggttgagg ctttactcta tcttgcaaaa tattacagag cacaaaaaaa atttgaagat 3240
gctgaagttt actgtacacg tcttctggat tatactggcc cggtaagtct aaatattcga 3300
ctcagctttc gatttgaaac aggttagtta gtcttgtcta atcatttaat ggtttaaatc 3360
attcttccag gagagagaaa cagcaaagag tatacttaga ggaatgcgat caacgcaatc 3420
taattttcct tccatggatg ttgagcattt tcctccctaa ttccttttga tgaagtactg 3480
gtgttttatg ctgcatttat gagtttttat atagatgcat caaaacggat ggaaaacaag 3540
gaaattgcac ttcgatctta atccacatgt tgtattttat tttgacttgt ttaatttttt 3600
ggtatacaca gcacttcact catatttgtc tttatatcag tgaattggtg gatatcgaca 3660
caaataacga gtatttgtag ttatttatcg gtatttaaga atttaaaa 3708
<210> 2
<211> 577
<212> PRT
<213> GMLPA1蛋白
<400> 2
Met Ser Ser Lys Glu Ser Cys Arg Ser Glu Leu Arg Ile Ala Ile Arg
1 5 10 15
Gln Leu Ser Asp Arg Cys Leu Tyr Ser Ala Ser Lys Trp Ala Ala Glu
20 25 30
Gln Leu Val Gly Ile Glu Gln Asp Pro Ala Lys Phe Thr Pro Ser Asn
35 40 45
Thr Arg Phe Gln Arg Gly Ser Ser Ser Ile Arg Arg Lys Tyr Lys Thr
50 55 60
His Glu Ile Thr Gly Thr Pro Ile Ala Gly Val Ser Tyr Val Ala Thr
65 70 75 80
Pro Ala Met Glu Glu Asp Glu Leu Val Asp Gly Asp Phe Tyr Leu Leu
85 90 95
Ala Lys Ser Tyr Phe Asp Cys Arg Glu Tyr Lys Arg Ala Ala His Val
100 105 110
Leu Arg Asp Gln Asn Gly Arg Lys Ser Val Phe Leu Arg Cys His Ala
115 120 125
Leu Tyr Leu Ala Gly Glu Lys Arg Lys Glu Glu Glu Met Ile Glu Leu
130 135 140
Glu Gly Pro Leu Gly Lys Ser Asp Ala Val Asn His Glu Leu Val Ser
145 150 155 160
Leu Glu Arg Glu Leu Ser Thr Phe Arg Lys Asn Gly Lys Val Asp Pro
165 170 175
Phe Cys Leu Tyr Leu Tyr Gly Leu Val Leu Lys Gln Lys Gly Ser Glu
180 185 190
Asn Leu Ala Arg Ala Val Leu Val Glu Ser Val Asn Ser Tyr Pro Trp
195 200 205
Asn Trp Asn Ala Trp Thr Glu Leu Gln Ser Leu Cys Lys Thr Val Asp
210 215 220
Ile Leu Asn Ser Leu Asn Leu Asn Ser His Trp Met Lys Asp Phe Phe
225 230 235 240
Leu Ala Ser Val Tyr Gln Glu Leu Arg Met His Asn Asp Ser Leu Ser
245 250 255
Lys Tyr Glu Tyr Leu Leu Gly Thr Phe Ser Asn Ser Asn Tyr Val Gln
260 265 270
Ala Gln Ile Ala Lys Ala Gln Tyr Ser Leu Arg Glu Phe Asp Gln Val
275 280 285
Glu Ala Ile Phe Glu Glu Leu Leu Ser Asn Asp Pro Tyr Arg Val Glu
290 295 300
Asp Met Asp Met Tyr Ser Asn Val Leu Tyr Ala Lys Glu Cys Phe Ser
305 310 315 320
Ala Leu Ser Tyr Leu Ala His Arg Val Phe Met Thr Asp Lys Tyr Arg
325 330 335
Pro Glu Ser Cys Cys Ile Ile Gly Asn Tyr Tyr Ser Leu Lys Gly Gln
340 345 350
His Glu Lys Ser Val Val Tyr Phe Arg Arg Ala Leu Lys Leu Asn Lys
355 360 365
Asn Phe Leu Ser Ala Trp Thr Leu Met Gly His Glu Phe Val Glu Met
370 375 380
Lys Asn Thr Pro Ala Ala Val Asp Ala Tyr Arg Arg Ala Val Asp Ile
385 390 395 400
Asp Pro Arg Asp Tyr Arg Ala Trp Tyr Gly Leu Gly Gln Ala Tyr Glu
405 410 415
Met Met Gly Met Pro Phe Tyr Ala Leu His Tyr Phe Lys Lys Ser Val
420 425 430
Phe Leu Gln Pro Asn Asp Ser Arg Leu Trp Ile Ala Met Ala Gln Cys
435 440 445
Tyr Glu Thr Asp Gln Leu Arg Met Leu Asp Glu Ala Ile Lys Cys Tyr
450 455 460
Arg Arg Ala Ala Asn Cys Asn Asp Arg Glu Ala Ile Ala Leu His Asn
465 470 475 480
Leu Ala Lys Leu His Ser Glu Leu Gly Arg Pro Glu Glu Ala Ala Phe
485 490 495
Tyr Tyr Lys Lys Asp Leu Glu Arg Met Glu Ser Glu Glu Arg Glu Gly
500 505 510
Pro Lys Met Val Glu Ala Leu Leu Tyr Leu Ala Lys Tyr Tyr Arg Ala
515 520 525
Gln Lys Lys Phe Glu Asp Ala Glu Val Tyr Cys Thr Arg Leu Leu Asp
530 535 540
Tyr Thr Gly Pro Glu Arg Glu Thr Ala Lys Ser Ile Leu Arg Gly Met
545 550 555 560
Arg Ser Thr Gln Ser Asn Phe Pro Ser Met Asp Val Glu His Phe Pro
565 570 575
Pro
<210> 3
<211> 1734
<212> DNA
<213> GMLPA1 CDS
<400> 3
atgagttcca aagagagttg cagaagtgaa cttcgcattg cgatccgcca actcagtgat 60
cgatgtctct actctgcttc taaatgggct gcagaacagt tggtgggtat tgagcaagac 120
cctgccaagt tcactccctc gaacacgaga tttcagcgtg ggagttcgag cattcgcagg 180
aagtacaaga ctcacgagat cacgggaacc ccaatcgcgg gtgtttcgta tgttgccacg 240
cctgcgatgg aggaagatga gcttgtagat ggtgatttct accttctggc aaagtcctat 300
tttgattgcc gtgagtataa gagagctgct catgttcttc gtgatcagaa cggaaggaaa 360
tcggtgttcc tgcgctgcca tgctctctat ctggctggtg aaaagcggaa agaggaagag 420
atgatagaac ttgaggggcc tctgggtaag agtgacgctg tcaatcatga attggtttct 480
ttggagagag agttgtcaac ttttcgcaag aatggcaaag ttgatccttt ttgtttgtac 540
ttatatggtc ttgtgctcaa acagaaaggc agtgagaatc ttgcacgtgc agttcttgta 600
gaatctgtga atagctaccc ttggaactgg aatgcctgga ctgagttgca atccttatgc 660
aaaacagtgg atatattgaa tagtcttaat ctcaatagcc attggatgaa ggactttttc 720
cttgccagtg tttaccaaga attaaggatg cacaatgact ctctgtcaaa atatgaatac 780
ctactaggaa cctttagtaa tagtaattat gtacaagcac aaattgcaaa agcccagtac 840
agtttgaggg aatttgacca agttgaagca atatttgaag aactgctgag taatgatcct 900
tacagagtgg aagacatgga catgtactcc aatgtgcttt atgctaagga atgcttttct 960
gctttgagtt atcttgccca tagagtattc atgactgata aatacagacc tgaatcttgt 1020
tgtattattg ggaattacta tagtttaaag ggacagcatg agaagtcagt tgtgtatttt 1080
aggagagccc ttaaattgaa caaaaacttt ttatcggctt ggacacttat ggggcatgag 1140
tttgtagaga tgaaaaacac tcctgctgct gtggatgcct atcgtcgggc agtagatata 1200
gacccacgtg attatcgtgc ttggtatgga ctaggacagg cttatgagat gatgggcatg 1260
cctttctatg cgcttcatta cttcaaaaaa tctgtattct tgcagccaaa tgattctcgt 1320
ttgtggattg caatggctca gtgttatgaa actgatcaac ttcgcatgct tgatgaagca 1380
ataaagtgtt acagaagggc agcaaactgt aatgacaggg aagcaattgc tctgcacaac 1440
ttggcaaaac ttcactcgga gctagggcgc cctgaagagg ctgcatttta ctacaaaaag 1500
gacttagaga ggatggaatc tgaagaaagg gaaggaccta aaatggttga ggctttactc 1560
tatcttgcaa aatattacag agcacaaaaa aaatttgaag atgctgaagt ttactgtaca 1620
cgtcttctgg attatactgg cccggagaga gaaacagcaa agagtatact tagaggaatg 1680
cgatcaacgc aatctaattt tccttccatg gatgttgagc attttcctcc ctaa 1734
<210> 4
<211> 21
<212> DNA
<213> 人工序列
<400> 4
agtgtagccg aaggcaatga g 21
<210> 5
<211> 24
<212> DNA
<213> 人工序列
<400> 5
acatgtggat taagatcgaa gtgc 24
- 還沒有人留言評論。精彩留言會獲得點贊!