語音合成方法、電子設備、存儲介質及程序產品與流程
本技術涉及語言處理,尤其涉及一種語音合成方法、電子設備、存儲介質及程序產品。
背景技術:
1、語音合成技術,是一種將文本信息轉換為可聽語音的技術,它涉及多個學科領域,包括聲學、語言學、數字信號處理和計算機科學等,語音合成的基本過程包括輸入文本分析、語言處理、韻律處理和聲學處理等階段,通過這些處理,機器能夠實時地產生語音,實現人機交互。
2、語音合成中的音素轉換是一個關鍵步驟,它涉及將文本信息轉換為音素序列,這是語音識別和合成的基本單位。音素是語言中具有獨立發音和意義的最小音質單位。在語音合成系統中,音素轉換過程包括從輸入文本中提取音素、聲調、語速等信息,并通過模型訓練和算法優化將這些信息轉化為相應的音頻信號,音素轉換通常通過查詢標準音素字典來實現,例如,單詞"though"、"through"、"cough"和"rough"雖然拼寫相似,但發音不同,因此需要音素來準確表達它們的發音。
3、音素轉換方式,即將一種語種的音素轉到通用音素上來,轉換過程中有的采用規則的方式進行轉換,該方法較為僵硬,導致后面合成語音的音質一般,不滿足日益豐富的語音環境。
技術實現思路
1、本技術實施例提供語音合成方法、電子設備、存儲介質及程序產品,用以解決音頻自然度和流暢度低的問題。
2、第一方面,本技術實施例提供一種語音合成方法,包括:
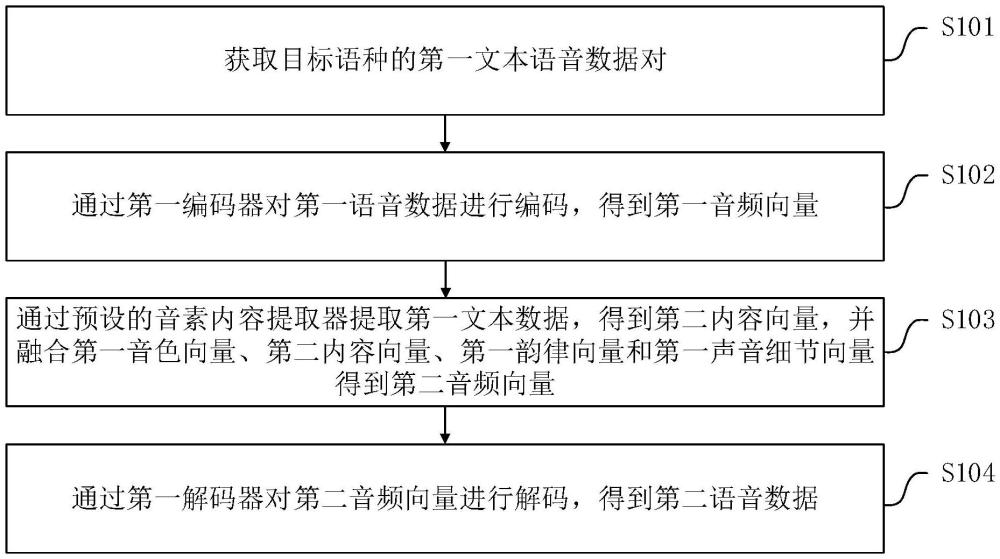
3、獲取目標語種的第一文本語音數據對,其中,第一文本語音數據對包括第一語音數據,以及與第一語音數據對齊的第一文本數據;
4、通過第一編碼器對第一語音數據進行編碼,得到第一音頻向量,并通過預設的音頻屬性分解器分解第一音頻向量,得到第一音色向量、第一內容向量、第一韻律向量和第一聲音細節向量;
5、通過預設的音素內容提取器提取第一文本數據,得到第二內容向量,并融合第一音色向量、第二內容向量、第一韻律向量和第一聲音細節向量,得到第二音頻向量;
6、通過第一解碼器對第二音頻向量進行解碼,得到第二語音數據。
7、可選的,如上所示的方法,通過第一編碼器對第一語音數據進行編碼,得到第一音頻向量,包括:
8、提取第一語音數據中的語音特征幀,得到語音特征幀序列;
9、通過第一編碼器對語音特征幀序列進行編碼,得到語音編碼序列;其中,語音編碼序列包括第一音頻向量;
10、提取語音編碼序列中的第一音頻向量。
11、可選的,如上所示的方法,通過預設的音素內容提取器提取第一文本數據之前,該方法還包括:
12、獲取目標語種的第二文本數據;
13、通過第二編碼器對第二文本數據進行編碼,得到第三內容向量;
14、根據第三內容向量訓練得到音素內容提取器。
15、可選的,如上所示的方法,通過第二編碼器對第二文本數據進行編碼,得到第三內容向量,包括:
16、將第二文本數據中的專用符號轉寫為通用文本,得到正則化文本數據;
17、基于目標語種的音標,將正則化文本數據轉化為目標語種的音素序列;
18、通過第二編碼器對音素序列進行編碼,得到文本編碼序列;其中,文本編碼序列包括第三內容向量;
19、提取文本編碼序列中的第三內容向量。
20、可選的,如上所示的方法,基于目標語種的音標,將正則化文本數據轉化為目標語種的音素序列,包括:
21、將正則化文本數據輸入預設的訓練模型中,得到訓練模型輸出的多個預測音素;
22、根據多個預測音素基于正則化文本數據的上下文,生成音素序列。
23、可選的,如上所示的方法,根據第三內容向量訓練得到音素內容提取器,包括:
24、獲取目標語種的第三語音數據;
25、根據第三內容向量通過迭代優化算法,得到目標語種的合成語音數據;
26、通過損失函數,計算第三語音數據與合成語音數據之間的損失值,其中,損失函數用于預測合成語音數據相對第三語音數據的實際語音差異;
27、在損失值大于預設閾值時,調整訓練模型的參數,以重新生成第三內容向量,直至損失值不大于預設閾值,訓練得到音素內容提取器。
28、第二方面,本技術實施例提供一種語音合成裝置,包括:
29、獲取模塊,用于獲取目標語種的第一文本語音數據對,其中,第一文本語音數據對包括第一語音數據,以及與第一語音數據對齊的第一文本數據;
30、編碼模塊,用于通過第一編碼器對第一語音數據進行編碼,得到第一音頻向量,并通過預設的音頻屬性分解器分解第一音頻向量,得到第一音色向量、第一內容向量、第一韻律向量和第一聲音細節向量;
31、提取模塊,用于通過預設的音素內容提取器提取第一文本數據,得到第二內容向量,并融合第一音色向量、第二內容向量、第一韻律向量和第一聲音細節向量,得到第二音頻向量;
32、解碼模塊,用于通過第一解碼器對第二音頻向量進行解碼,得到第二語音數據。
33、可選的,如上所示的裝置,編碼模塊,包括:
34、第一提取模塊,用于提取第一語音數據中的語音特征幀,得到語音特征幀序列;
35、第一編碼模塊,用于通過第一編碼器對語音特征幀序列進行編碼,得到語音編碼序列;其中,語音編碼序列包括第一音頻向量;
36、第二提取模塊,用于提取語音編碼序列中的第一音頻向量。
37、可選的,如上所示的裝置,通過預設的音素內容提取器提取第一文本數據之前,該方法還包括:
38、第一獲取模塊,用于獲取目標語種的第二文本數據;
39、第二編碼模塊,用于通過第二編碼器對第二文本數據進行編碼,得到第三內容向量;
40、第一訓練模塊,用于根據第三內容向量訓練得到音素內容提取器。
41、可選的,如上所示的裝置,第二編碼模塊,包括:
42、轉寫模塊,用于將第二文本數據中的專用符號轉寫為通用文本,得到正則化文本數據;
43、轉化模塊,用于基于目標語種的音標,將正則化文本數據轉化為目標語種的音素序列;
44、第三編碼模塊,用于通過第二編碼器對音素序列進行編碼,得到文本編碼序列;其中,文本編碼序列包括第三內容向量;
45、第三提取模塊,用于提取文本編碼序列中的第三內容向量。
46、可選的,如上所示的裝置,轉化模塊,包括:
47、第二訓練模塊,用于將正則化文本數據輸入預設的訓練模型中,得到訓練模型輸出的多個預測音素;
48、預測模塊,用于根據多個預測音素基于正則化文本數據的上下文,生成音素序列。
49、可選的,如上所示的裝置,第一訓練模塊,包括:
50、第二獲取模塊,用于獲取目標語種的第三語音數據;
51、迭代模塊,用于根據第三內容向量通過迭代優化算法,得到目標語種的合成語音數據;
52、計算模塊,用于通過損失函數,計算第三語音數據與合成語音數據之間的損失值,其中,損失函數用于預測合成語音數據相對第三語音數據的實際語音差異;
53、調整模塊,用于在損失值大于預設閾值時,調整訓練模型的參數,以重新生成第三內容向量,直至損失值不大于預設閾值,訓練得到音素內容提取器。
54、本發明實施例第三方面提供一種電子設備,包括:存儲器和處理器;
55、存儲器存儲計算機執行指令;
56、處理器執行存儲器存儲的計算機執行指令,用于實現第一方面任一項的語音合成方法。
57、本發明實施例第四方面提供一種計算機可讀存儲介質,計算機可讀存儲介質中存儲有計算機執行指令,計算機執行指令被處理器執行時,用于實現第一方面任一項的語音合成方法。
58、本發明實施例第五方面提供一種計算機程序產品,包括計算機程序,計算機程序被處理器執行時,用于實現第一方面任一項的語音合成方法。
59、本技術實施例提供的語音合成方法、電子設備、存儲介質及程序產品,通過獲取目標語種的第一文本語音數據對,其中,第一文本語音數據對包括第一語音數據,以及與第一語音數據對齊的第一文本數據,通過第一編碼器對第一語音數據進行編碼,得到第一音頻向量,并通過預設的音頻屬性分解器分解第一音頻向量,得到第一音色向量、第一內容向量、第一韻律向量和第一聲音細節向量,通過預設的音素內容提取器提取第一文本數據,得到第二內容向量,并融合第一音色向量、第二內容向量、第一韻律向量和第一聲音細節向量,得到第二音頻向量,通過第一解碼器對第二音頻向量進行解碼,得到第二語音數據。實現如下技術效果:;利用音頻屬性解耦,復用不同語種間的音色、韻律和聲音細節屬性減少對目標語種數據的要求;通過訓練音素內容提取器基于上下文動態生成詞向量構建準確內容向量;通過文本數據訓練的內容向量替換語音數據中的內容向量解決語音合成不流暢的問題。
- 還沒有人留言評論。精彩留言會獲得點贊!