一種基于兩層模型的多聲道音頻質量評價方法與流程
本發明屬于多聲道音頻質量評價技術領域,涉及一種基于兩層模型的多聲道音頻質量評價方法。
背景技術:
近年來,隨著多媒體技術的日益發展,多聲道音頻逐漸走入人們的日常生活。和傳統的雙聲道立體聲相比,多聲道音頻能夠給聽眾提供更佳的音質體驗和更好的臨場感受,因此被廣泛的應用于多種場景,例如立體電影,3d游戲,實時視頻會議等等。這使得人們對多聲道音頻處理技術提出了更高的標準。為了對音頻技術的效果進行評價,通常采用的方法是評估經過處理后的音頻信號,通過對比處理前后音頻文件的質量差異,從而獲得相應技術的效果評價,這種方法即為多聲道音頻質量評價方法。
根據評價主體的不同,多聲道音頻質量評價方法主要分為兩大類:主觀評價方法和客觀評價方法。主觀評價方法是通過大量聽音人員對技術處理前后的三維音頻信號進行對比測聽后,按照實驗設計方案中規定的標尺對處理后的音頻信號進行質量等級劃分,從而得到待測音頻信號的主觀分數。目前通用的主觀評價方法主要是由國際電信聯盟無線電通信組(itu-r)頒布的一系列標準,包括適用于中等損傷程度的帶隱藏參考和基準的多激勵測試(mushra),即itu-rbs.1534標準,以及適用于小損傷的帶隱藏參考的三次聽音雙盲聽評法,即itu-rbs.1116標準等。在實驗設計及人員選擇合理的前提下,主觀評價可以提供更為可靠的結果。但主觀評價方法也有其局限性:其操作往往需要大量的聽音人員,并且需要嚴苛的環境條件,耗時耗力。
鑒于主觀評價的諸多困難,人們希望能夠有一種方便快捷的客觀手段對多聲道音頻質量進行評價。peaq(perceptualevaluationofaudioquality)方法是itu-r在bs.1387中提出的一種客觀音頻質量評估方法,也是目前唯一的音頻客觀評價國際標準。peaq通過模擬人耳聽覺特性,可以較準確地得到待測音頻質量的得分,但在用于計算多聲道音頻質量時,peaq方法的準確度卻不盡如人意,即peaq方法得出的客觀評價評分與主觀評價方法得出的評分相關性低。這是由于peaq在計算多聲道音頻質量時,往往將每一個聲道分開處理,再將得到的結果取平均值,從而導致聲道間信息的缺失。
針對于現存的多聲道音頻客觀評價標準評分與主觀得分相關系低的問題,很多研究都致力于改進客觀方法在應用于多聲道音頻場景下的準確度,但客觀方法中的模型只設計了一層結構,通過輸入待測音頻(需要評價的多聲道音頻信號)和參考音頻(原始無失真的多聲道音頻信號)直接得出客觀得分,忽略了中間可能影響整體音質得分的因素。我國授權公開號為cn102867518b的專利“3d音頻中水平方位參數的編解碼性能評價方法”,公開了一種3d音頻中水平方位參數的編碼性能評價方法,用于評估待測編碼后音頻的主觀感知失真,從而評價編解碼器的水平方位參數的主觀感知失真,但此方法主要用于評價3d音頻中水平方位參數的編碼性能,并不適用于經過其他音頻處理技術處理的多聲道音頻。
技術實現要素:
本發明的目的是為了解決現有的多聲道音頻質量客觀評價結果與主觀評價得分相關性過低的問題,提供一種基于兩層模型的多聲道音頻質量評價方法,提高了客觀評價方法的準確性。
為了實現上述目的,本發明方法的基本思路是:首先待測音頻和參考音頻經過第一層中的兩個模型,即客觀基本音質模型和客觀空間質量模型,分別計算出客觀的基本音質得分和空間質量得分;然后將其作為輸入自變量,通過第二層的整體客觀模型,最終得到待測音頻的整體客觀分數。其中,第一層的客觀基本音質模型和客觀空間質量模型,以及第二層的整體客觀模型都是通過主觀聽音測試結果訓練得到的。所用主觀聽音測試評分方法優選為mushra法或者帶隱藏參考的三次聽音雙盲聽評法。在所述的主觀聽音測試訓練中,對訓練音頻進行評分的指標包括:基本音質(代表多聲道音頻綜合每一路聲道信號基礎音質的感受)、空間質量(代表多聲道音頻信號的在空間范圍內的擴散和環繞感)以及整體質量(代表多聲道音頻信號在基本音質和空間質量上的綜合感受)。
本發明方法的實施步驟包括:
(a)、將待測音頻和參考音頻輸入到第一層中的客觀基本音質模型中,計算得到基本音質得分。
所述的客觀基本音質模型是通過主觀基本音質得分訓練得到的。作為優選的方案是:首先將訓練所用的多聲道音頻信號經過peaq算法計算出每一個聲道的音質得分,然后利用數據擬合工具將其擬合到對應的主觀音質得分,從而得到客觀基本音質模型。作為優選,這里的數據擬合工具采用多元線性回歸(mlr,multiplelinearregression)方法。
(b)、將待測音頻和參考音頻輸入到第一層中的客觀空間質量模型中,計算出空間質量得分。
所述的客觀空間質量模型是通過主觀空間質量得分訓練得到的。作為優選的方案為:首先通過計算每兩個聲道之間的空間參數,來獲得待測音頻的空間信息,在得到待測音頻的一系列聲道間空間參數后,利用數據擬合工具將空間參數擬合到相應的主觀空間質量得分,從而得到客觀空間質量模型。作為優選,這里的數據擬合工具采用神經網絡。客觀空間質量模型中用到的空間參數包括:
聲道間相位差
聲道間強度差
聲道間相干性
其中,ab是在子帶b中的頻譜系數的個數,a1(k)表示輸入音頻中一個聲道的頻譜系數,a2(k)表示輸入音頻另一個聲道的頻譜系數,*表示取共軛。
上述步驟(a)和(b)可以交換次序,二者不是時間上的先后順序,只是步驟的標記。
(c)、將步驟(a)和(b)中所得的基本音質得分和空間質量得分通過第二層的整體客觀模型,最終輸出待測音頻的整體客觀分數。
所述的整體客觀模型是通過主觀整體質量得分訓練得到的。作為優選的方案為:將第一層的客觀基本音質模型輸出的客觀基本音質得分和客觀空間質量模型輸出的客觀空間質量得分作為輸入,通過數據擬合工具之與主觀整體質量得分進行擬合,從而獲得整體客觀模型。作為優選,這里的數據擬合工具采用mlr方法。
至此,就完成了基于兩層模型的多聲道音頻質量評價。
本發明方法對比現有的技術,有如下的有益效果:
1.本發明所述方法提出了一種兩層模型結構,第一層模型可以計算得出中間參數,即客觀基本音質得分和空間質量得分,再經由第二層模型得出整體音質得分。中間參數的獲取可以幫助測試者更詳細地了解待測音頻的質量信息,進而更好地了解對應的音頻處理技術對音頻哪一部分造成了損傷;
2.本發明所述方法的兩層模型結構相比于單層模型,可以更好的模擬人耳的聽覺感知系統,實驗表明,該方法與主觀實驗結果之間相關性較高,反映出此雙層模型具有很好的準確性。
附圖說明
圖1為本發明方法的流程框圖;
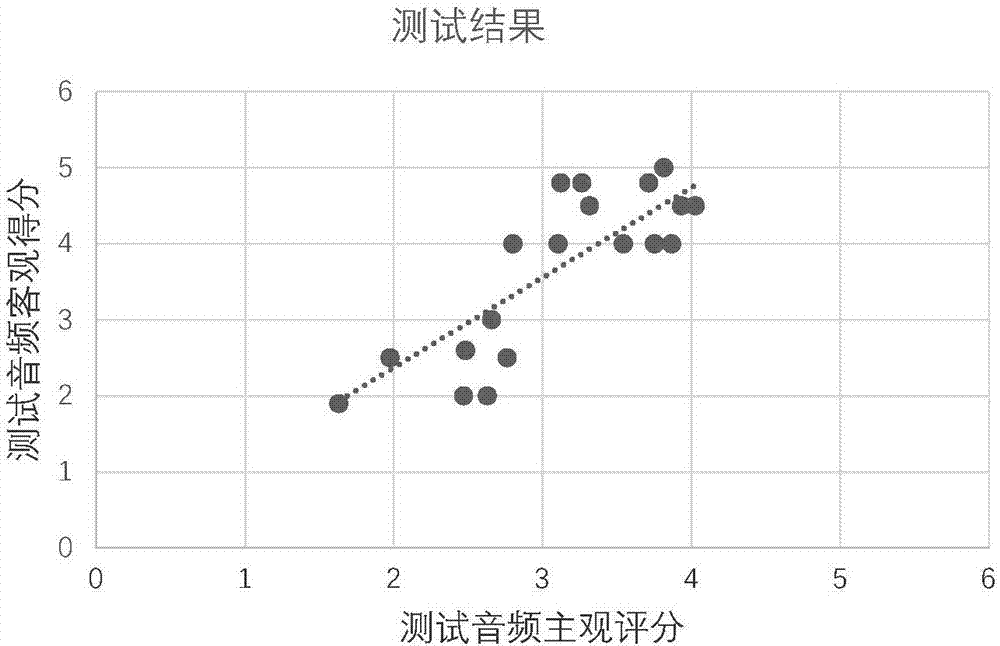
圖2為本發明實施例中的得分結果散點圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步詳細描述。
在下面的實施例中,為闡述方便,多聲道音頻選擇5.1聲道音頻。本發明的方法同樣適用于其他多聲道音頻的質量評價,并能獲得同樣有益的技術效果。具體地,由于5.1聲道的音頻在目前的實際中應用較為廣泛,并且通常被認為是一種需要揚聲器數目最少的環繞聲制式,因此在實例中采用5.1聲道音頻文件作為模型訓練和測試音源。經過主觀聽音測試得出的主觀質量評分,作為客觀模型的訓練集和測試集。
本發明方法步驟如圖1所示,具體如下:
(a)、將待測音頻和參考音頻輸入到第一層中的客觀基本音質模型中,計算得到基本音質得分,對應圖1中的1;
在這一步中,客觀基本音質模型的訓練首先利用了peaq方法計算出訓練音頻的第k個聲道得分xk,然后利用mlr將這些得分與主觀實驗中得到的基本音質得分y1映射,即:
(b)、將待測音頻和參考音頻輸入到第一層中的客觀空間質量模型中,算出空間質量得分,對應圖1中的2;
在這一步中,客觀空間質量模型中包含了三個能夠反映聲道間空間信息的參數:
聲道間相位差
聲道間強度差
聲道間相干性
其中,ab是在子帶b中的頻譜系數的個數,a1(k)表示輸入音頻中一個聲道的頻譜系數,a2(k)表示輸入音頻另一個聲道的頻譜系數,*表示取共軛。這三個參數通過提取兩兩聲道間的信息,來獲取待測音頻的空間信息。對于5.1聲道的音頻,由于低音聲道lef和其他聲道間無甚相關性,因此選取四組聲道對,即fl-fr,bl-br,fc-fl,fc-fr,來計算聲道間參數。每一組聲道對均需要計算三個空間參數,因此對于每一條5.1聲道音頻需要計算12個空間參數。在客觀空間質量模型的訓練中,通過將參考音頻和訓練音頻的12個空間參數對應相減,得到訓練音頻的空間損傷參數。然后,用得到的空間損傷參數與對應的主觀空間質量得分做神經網絡擬合。經過測試不同的隱藏節點數目對神經網絡模型性能的影響,優選4為本實例中的客觀空間質量模型的隱藏節點數目。實驗證明4個隱藏節點可以為模型提供足夠的擬合優度并且復雜度較低。在測試和實際計算時,將參考音頻和待測音頻輸入到客觀空間質量模型中,可輸出客觀空間質量得分。
(c)、將前兩步所得分數通過第二層中的整體客觀模型,最終輸出待測音頻的整體客觀分數,對應圖1中的3。
在這一步中,整體客觀模型的訓練用到的是訓練音頻的主觀基本音質得分、空間質量得分和整體得分。將主觀基本音質得分和空間質量得分通過mlr擬合到主觀整體得分,得到整體客觀模型。在測試和實際計算時,將前兩步得到的客觀基本音質得分和空間質量得分輸入到該模型中,即可得到待測音頻的整體客觀分數。
圖2為模型在本實例中的測試結果散點圖。圖中橫坐標表示對應測試音頻的主觀整體分數,縱坐標表示對應測試音頻的客觀整體得分。由圖中可以看出,圖中散點分布的趨勢線較接近于y=x線(主客觀分數完全相等),反映出該算法所得到的客觀分數與主觀評分的一致性較高。
以上所述的具體描述,對發明的目的、技術方案和有益效果進行了進一步詳細說明,所應理解的是,以上所述僅為本發明的具體實施例而已,并不用于限定本發明的保護范圍,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!