一種動畫口型與語音實時匹配的方法與流程
本發明涉及通過分析語音的音節為語音實時匹配動畫人物的口型,可為錄制好的語音或實時語音,匹配動畫人物的口型進行實時聊天、直播、錄播,使得使用者可以使用不同形象的動畫人物進行交互,具體為一種動畫口型與語音實時匹配的方法。
背景技術:
社交娛樂中的趣味性越來越成為吸引人們的一個要素,本發明可以為錄制好的語音或實時語音,匹配動畫人物的口型進行實時聊天、直播、錄播,使得使用者可以使用不同形象的動畫人物進行交互,大大提升社交娛樂中的趣味性。
技術實現要素:
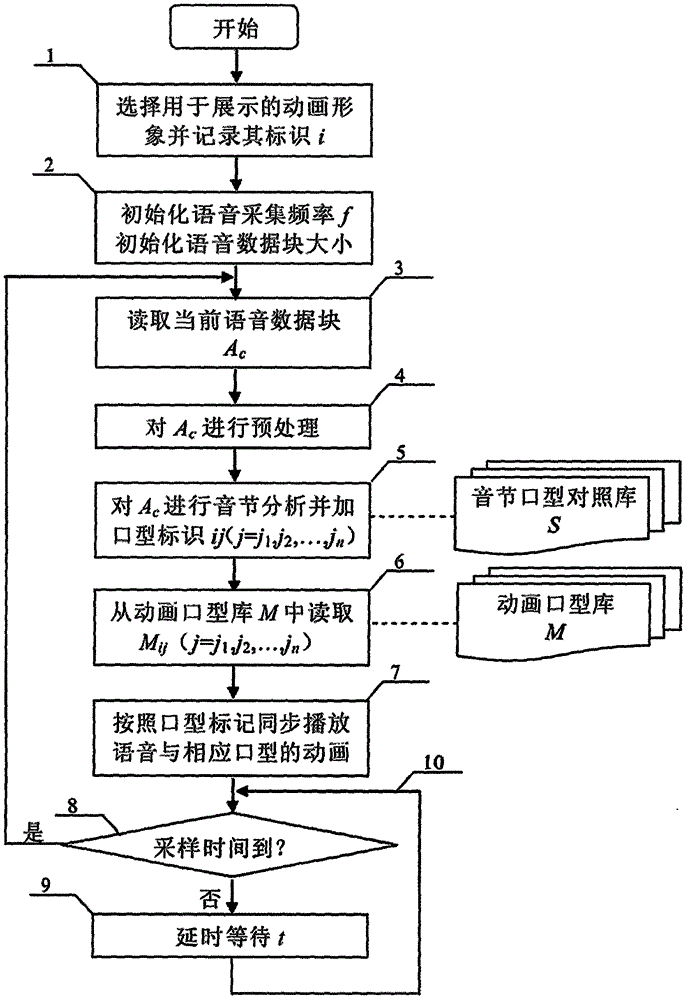
本發明采用的技術方案為:首先建立動畫口型庫M、音節口型對照庫S;然后按照一定的周期與大小讀取語音數據,為了音節分析的準確性,先對語音數據進行去噪及增強處理,然后進行音節分析并根據所述音節口型對照庫S對語音數據添加口型標記,最后依據口型標記從所述動畫口型庫M中獲取相應圖片并同步播放。本發明的技術方案總流程圖如圖1所示。
本發明包括動畫口型庫M、音節口型對照庫S及以下步驟:
(1)選擇用于展示的動畫形象并記錄其標識i;
(2)初始化語音采集頻率f,初始化語音數據塊大小;
(3)讀取當前語音數據塊Ac;
(4)對所述當前語音數據塊Ac進行預處理;
(5)對所述當前語音數據塊Ac進行音節分析,并根據所述音節口型對照庫S對所述當前語音數據塊Ac添加口型標識ij(j=j1,j2,...,jn),生成添加了口型標識的語音數據塊Ac’;
(6)從所述動畫口型庫M中讀取Mij(j=j1,j2,...,jn);
(7)按照口型標記同步播放語音與相應口型的動畫圖片;
(8)判斷采樣時間是否到,若是則轉步驟(3),否則轉步驟(9);
(9)延時等待t時長;
(10)轉步驟(8)。
所述動畫口型庫M是與不同音節口型對應的動畫圖片集合。
所述語音采集頻率f與語音數據塊大小是可變的;
對所述當前語音數據塊Ac的預處理操作包括去噪及信號增強。
對所述當前語音數據塊Ac進行音節分析并添加口型標識ij(j=j1,j2,...,jn),是對語音進行元音、輔音及停頓的分析,并對不同音節按照所述音節口型對照庫S添加該音節對應的口型標識。
本發明具有以下優點:
(1)可以用不同的動畫形象為語音匹配口型進行實時視頻聊天、直播、錄播,提升了聊天、直播、錄播的趣味性;
(2)可以通過語音驅動自動制作多人物形象與角色的簡單動畫作品。
附圖說明
圖1是一種動畫口型與語音實時匹配的方法的總流程圖。
具體實施方式
下面結合附圖,通過一個為實時語音流匹配動畫口型的具體實施例來進一步闡述本發明。具體實施例僅用于說明本發明而不用于限制本發明要求保護的范圍。
有n個動畫人物,每個動畫人物有m種口型,因此共有m×n個動畫口型。
其中,ij為Mij的標識,i=1,2,...,n,j=1,2,...,m。
音節與口型的對應關系是多對一的關系,音節口型對照庫用對應列表描述。
參照圖1,在步驟1中,使用者選擇第i個動畫人物作為播出的動畫形象,記錄i,其中i=1,2,...,n;
步驟2中,初始化語音采集頻率f和初始化語音數據塊大小,對于實時語音流,f=25次/秒,語音數據塊大小即為當前40ms的語音數據大小;
步驟3中,讀取當前40ms的語音數據塊Ac;
步驟4中,對Ac用小波變換進行預處理;
步驟5中,對Ac進行元音、輔音、停頓的音節分析,然后根據所述音節口型對照庫S通過查表法選擇對應的口型,并對所述語音數據塊Ac添加口型標識ij(j=j1,j2,...,jn),生成添加了口型標識的語音數據塊Ac’;
步驟6中,從所述動畫口型庫M中讀取Mij(j=j1,j2,...,jn);
步驟7中,按照口型標記同步播放語音與相應口型的動畫,f=25次/秒,在處理效率不足時可以降低圖片播放頻率,但是必須滿足25次/秒≥f≥15次/秒,因此動畫可以達到非常連貫的動畫效果,由于語音的處理與分析延時40ms,因此動畫播出比讀取到語音延時40ms,但是最終的動畫與語音是同步播放;
步驟8中,判斷采樣時間40ms是否到,若是則轉步驟3,若否則轉步驟9;
步驟9中,延時等待t=5ms,考慮到采樣延時,在實時語音的情況下,動畫與語音同步播出比語音產生延時最多45ms;
步驟10中,轉步驟8。
盡管已經參照本發明的特定示例性實施例詳細闡述了本發明,但是本領域技術人員應理解,在不脫離由權利要求及其等同物定義的本發明的精神和范圍的情況下,可在形式和細節上進行各種改變。
- 還沒有人留言評論。精彩留言會獲得點贊!