一種同步語音及虛擬動作的方法、系統及機器人與流程
本發明涉及機器人交互技術領域,尤其涉及一種同步語音及虛擬動作的方法、系統及機器人。
背景技術:
機器人作為與人類的交互工具,使用的場合越來越多,例如一些老人、小孩較孤獨時,就可以與機器人交互,包括對話、娛樂等。而為了讓機器人與人類交互時更加擬人化,發明人研究出一種虛擬機器人的顯示設備和成像系統,能夠形成3D的動畫形象,虛擬機器人的主機接受人類的指令例如語音等與人類進行交互,然后虛擬的3D動畫形象會根據主機的指令進行聲音和動作的回復,這樣就可以讓機器人更加擬人化,不僅在聲音、表情上能夠與人類交互,而且還可以在動作等上與人類交互,大大提高了交互的體驗感。
然而,虛擬機器人如何將回復內容中的語音和虛擬動作進行同步是一個比較復雜的問題,如果語音和動作不能匹配,則會大大影響用戶的交互體驗。
因此,如何提供一種同步語音及虛擬動作的方法、系統及機器人,提升人機交互體驗成為亟需解決的技術問題。
技術實現要素:
本發明的目的是提供一種同步語音及虛擬動作的方法、系統及機器人,提升人機交互體驗。
本發明的目的是通過以下技術方案來實現的:
一種同步語音及虛擬動作的方法,包括:
獲取用戶的多模態信息;
根據用戶的多模態信息和生活時間軸生成交互內容,所述交互內容至少包括語音信息和動作信息;
將語音信息的時間長度和動作信息的時間長度調整到相同。
優選的,所述將語音信息的時間長度和動作信息的時間長度調整到相同的具體步驟包括:
若語音信息的時間長度與動作信息的時間長度的差值不大于閾值,當語音信息的時間長度小于動作信息的時間長度,則加快動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
優選的,當語音信息的時間長度大于動作信息的時間長度,則加快語音信息的播放速度或/和減緩動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
優選的,所述將語音信息的時間長度和動作信息的時間長度調整到相同的具體步驟包括:
若語音信息的時間長度與動作信息的時間長度的差值大于閾值,當語音信息的時間長度大于動作信息的時間長度時,則將至少兩組動作信息進行排序組合,使組合后的動作信息的時間長度等于所述語音信息的時間長度。
優選的,當語音信息的時間長度小于動作信息的時間長度時,則選取動作信息中的部分動作,使選取的部分動作的時間長度等于所述語音信息的時間長度。
優選的,所述機器人的生活時間軸的參數的生成方法包括:
將機器人的自我認知進行擴展;
獲取生活時間軸的參數;
對機器人的自我認知的參數與生活時間軸中的參數進行擬合,生成機器人的生活時間軸。
優選的,所述將機器人的自我認知進行擴展的步驟具體包括:將生活場景與機器人的自我認識相結合形成基于生活時間軸的自我認知曲線。
優選的,所述對機器人的自我認知的參數與生活時間軸中的參數進行擬合的步驟具體包括:使用概率算法,計算生活時間軸上的機器人在時間軸場景參數改變后的每個參數改變的概率,形成擬合曲線。
優選的,其中,所述生活時間軸指包含一天24小時的時間軸,所述生活時間軸中的參數至少包括用戶在所述生活時間軸上進行的日常生活行為以及代表該行為的參數值。
一種同步語音及虛擬動作的系統,包括:
獲取模塊,用于獲取用戶的多模態信息;
人工智能模塊,用于根據用戶的多模態信息和生活時間軸生成交互內容,所述交互內容至少包括語音信息和動作信息;
控制模塊,用于將語音信息的時間長度和動作信息的時間長度調整到相同。
優選的,所述控制模塊具體用于:
若語音信息的時間長度與動作信息的時間長度的差值不大于閾值,當語音信息的時間長度小于動作信息的時間長度,則加快動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
優選的,當語音信息的時間長度大于動作信息的時間長度,則加快語音信息的播放速度或/和減緩動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
優選的,所述控制模塊具體用于:
若語音信息的時間長度與動作信息的時間長度的差值大于閾值,當語音信息的時間長度大于動作信息的時間長度時,則將至少兩組動作信息進行組合,使組合后的動作信息的時間長度等于所述語音信息的時間長度。
優選的,當語音信息的時間長度小于動作信息的時間長度時,則選取動作信息中的部分動作,使選取的部分動作的時間長度等于所述語音信息的時間長度。
優選的,所述系統包括處理模塊,用于:
將機器人的自我認知進行擴展;
獲取生活時間軸的參數;
對機器人的自我認知的參數與生活時間軸中的參數進行擬合,生成機器人的生活時間軸。
優選的,所述處理模塊具體用于:將生活場景與機器人的自我認識相結合形成基于生活時間軸的自我認知曲線。
優選的,所述處理模塊具體用于:使用概率算法,計算生活時間軸上的機器人在時間軸場景參數改變后的每個參數改變的概率,形成擬合曲線。
優選的,其中,所述生活時間軸指包含一天24小時的時間軸,所述生活時間軸中的參數至少包括用戶在所述生活時間軸上進行的日常生活行為以及代表該行為的參數值。
本發明公開一種機器人,包括如上述任一所述的一種同步語音及虛擬動作的系統。
相比現有技術,本發明具有以下優點:本發明的同步語音及虛擬動作的方法包括:獲取用戶的多模態信息;根據用戶的多模態信息和生活時間軸生成交互內容,所述交互內容至少包括語音信息和動作信息;將語音信息的時間長度和動作信息的時間長度調整到相同。這樣就可以通過用戶的多模態信息例如用戶語音、用戶表情、用戶動作等的一種或幾種,來生成交互內容,交互內容中至少包括語音信息和動作信息,而為了讓語音信息和動作信息能夠同步,將語音信息的時間長度和動作信息的時間長度調整到相同,這樣就可以讓機器人在播放聲音和動作時可以同步匹配,使機器人在交互時不僅具有語音表現,還可以具有動作等多樣的表現形式,機器人的表現形式更加多樣化,使機器人更加擬人化,也提高了用戶于機器人交互時的體驗度。
附圖說明
圖1是本發明實施例一的一種同步語音及虛擬動作的方法的流程圖;
圖2是本發明實施例二的一種同步語音及虛擬動作的系統的示意圖。
具體實施方式
雖然流程圖將各項操作描述成順序的處理,但是其中的許多操作可以被并行地、并發地或者同時實施。各項操作的順序可以被重新安排。當其操作完成時處理可以被終止,但是還可以具有未包括在附圖中的附加步驟。處理可以對應于方法、函數、規程、子例程、子程序等等。
計算機設備包括用戶設備與網絡設備。其中,用戶設備或客戶端包括但不限于電腦、智能手機、PDA等;網絡設備包括但不限于單個網絡服務器、多個網絡服務器組成的服務器組或基于云計算的由大量計算機或網絡服務器構成的云。計算機設備可單獨運行來實現本發明,也可接入網絡并通過與網絡中的其他計算機設備的交互操作來實現本發明。計算機設備所處的網絡包括但不限于互聯網、廣域網、城域網、局域網、VPN網絡等。
在這里可能使用了術語“第一”、“第二”等等來描述各個單元,但是這些單元不應當受這些術語限制,使用這些術語僅僅是為了將一個單元與另一個單元進行區分。這里所使用的術語“和/或”包括其中一個或更多所列出的相關聯項目的任意和所有組合。當一個單元被稱為“連接”或“耦合”到另一單元時,其可以直接連接或耦合到所述另一單元,或者可以存在中間單元。
這里所使用的術語僅僅是為了描述具體實施例而不意圖限制示例性實施例。除非上下文明確地另有所指,否則這里所使用的單數形式“一個”、“一項”還意圖包括復數。還應當理解的是,這里所使用的術語“包括”和/或“包含”規定所陳述的特征、整數、步驟、操作、單元和/或組件的存在,而不排除存在或添加一個或更多其他特征、整數、步驟、操作、單元、組件和/或其組合。
下面結合附圖和較佳的實施例對本發明作進一步說明。
實施例一
如圖1所示,本實施例中公開一種同步語音及虛擬動作的方法,包括:
S101、獲取用戶的多模態信息;
S102、根據用戶的多模態信息和生活時間軸300生成交互內容,所述交互內容至少包括語音信息和動作信息;
S103、將語音信息的時間長度和動作信息的時間長度調整到相同。
本發明的同步語音及虛擬動作的方法包括:獲取用戶的多模態信息;根據用戶的多模態信息和生活時間軸生成交互內容,所述交互內容至少包括語音信息和動作信息;將語音信息的時間長度和動作信息的時間長度調整到相同。這樣就可以通過用戶的多模態信息例如用戶語音、用戶表情、用戶動作等的一種或幾種,來生成交互內容,交互內容中至少包括語音信息和動作信息,而為了讓語音信息和動作信息能夠同步,將語音信息的時間長度和動作信息的時間長度調整到相同,這樣就可以讓機器人在播放聲音和動作時可以同步匹配,使機器人在交互時不僅具有語音表現,還可以具有動作等多樣的表現形式,機器人的表現形式更加多樣化,使機器人更加擬人化,也提高了用戶于機器人交互時的體驗度。
對于人來講每天的生活都具有一定的規律性,為了讓機器人與人溝通時更加擬人化,在一天24小時中,讓機器人也會有睡覺,運動,吃飯,跳舞,看書,吃飯,化妝,睡覺等動作。因此本發明將機器人所在的生活時間軸加入到機器人的交互內容生成中去,使機器人與人交互時更加擬人化,使得機器人在生活時間軸內具有人類的生活方式,該方法能夠提升機器人交互內容生成的擬人性,提升人機交互體驗,提高智能性。交互內容可以是表情或文字或語音或動作等一種或幾種的組合。機器人的生活時間軸300是提前進行擬合和設置完成的,具體來講,機器人的生活時間軸300是一系列的參數合集,將這個參數傳輸給系統進行生成交互內容。
本實施例中的多模態信息可以是用戶表情、語音信息、手勢信息、場景信息、圖像信息、視頻信息、人臉信息、瞳孔虹膜信息、光感信息和指紋信息等其中的其中一種或幾種。
本實施例中,基于生活時間軸具體是:根據人類日常生活的時間軸,按照人類的方式,將機器人本身在日常生活時間軸中的自我認知的數值做擬合,機器人的行為按照這個擬合行動,也就是得到一天中機器人自己的行為,從而讓機器人基于生活時間軸去進行自己的行為,例如生成交互內容與人類溝通等。假如機器人一直喚醒的話,就會按照這個時間軸上的行為行動,機器人的自我認知也會根據這個時間軸進行相應的更改。生活時間軸與可變參數可以對自我認知中的屬性,例如心情值,疲勞值等等的更改,也可以自動加入新的自我認知信息,比如之前沒有憤怒值,基于生活時間軸和可變因素的場景就會自動根據之前模擬人類自我認知的場景,從而對機器人的自我認知進行添加。生活時間軸中不僅包括語音信息,也包括了動作等信息。
例如,用戶向機器人說話:“好困啊”,機器人聽到后理解的為用戶很困,然后結合機器人的生活時間軸,例如當前的時間為上午9點,那么機器人就知道主人是剛剛起床,那么就應該向主人問早,例如回答語音“早上好”作為回復,還可以唱一首歌,并配上相應舞蹈動作等。而如果用戶向機器人說話:“好困啊”,機器人聽到后理解的為用戶很困,然后機器人的生活時間軸,例如當前的時間為晚上9點,那么機器人就知道主人需要睡覺了,那么就會回復語音“主人晚安,睡個好覺”等類似用語,并配上相應的晚安、睡眠動作等。這種方式要比單純的語音和表情回復更加貼近人的生活,具有動作更加擬人化。
本實施例中,所述將語音信息的時間長度和動作信息的時間長度調整到相同的具體步驟包括:
若語音信息的時間長度與動作信息的時間長度的差值不大于閾值,當語音信息的時間長度小于動作信息的時間長度,則加快動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
當語音信息的時間長度大于動作信息的時間長度,則加快語音信息的播放速度或/和減緩動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
因此,當語音信息的時間長度與動作信息的時間長度的差值不大于閾值,調整的具體含義可以為壓縮或拉伸語音信息的時間長度或/和動作信息的時間長度,也可以是加快播放速度或者減緩播放速度,例如將語音信息的播放速度乘以2,或者將動作信息的播放時間乘以0.8等等。
例如,語音信息的時間長度與動作信息的時間長度的閾值是一分鐘,機器人根據用戶的多模態信息生成的交互內容中,語音信息的時間長度是1分鐘,動作信息的時間長度是2分鐘,那么就可以將動作信息的播放速度加快,為原來播放速度的兩倍,那么動作信息調整后的播放時間就會為1分鐘,從而與語音信息進行同步。當然,也可以讓語音信息的播放速度減緩,調整為原來播放速度的0.5倍,這樣就會讓語音信息經過調整后減緩為2分鐘,從而與動作信息同步。另外,也可以將語音信息和動作信息都調整,例如語音信息減緩,同時將動作信息加快,都調整到1分30秒,也可以讓語音和動作進行同步。
此外,本實施例中,所述將語音信息的時間長度和動作信息的時間長度調整到相同的具體步驟包括:
若語音信息的時間長度與動作信息的時間長度的差值大于閾值,當語音信息的時間長度大于動作信息的時間長度時,則將至少兩組動作信息進行排序組合,使組合后的動作信息的時間長度等于所述語音信息的時間長度。
當語音信息的時間長度小于動作信息的時間長度時,則選取動作信息中的部分動作,使選取的部分動作的時間長度等于所述語音信息的時間長度。
因此,當語音信息的時間長度與動作信息的時間長度的差值大于閾值,調整的含義就是添加或者刪除部分動作信息,以使動作信息的時間長度與語音信息的時間長度相同。
例如,語音信息的時間長度與動作信息的時間長度的閾值是30秒,機器人根據用戶的多模態信息生成的交互內容中,語音信息的時間長度是3分鐘,動作信息的時間長度是1分鐘,那么就需要將其他的動作信息也加入到原本的動作信息中,例如找到一個時間長度為2分鐘的動作信息,將上述兩組動作信息進行排序組合后就與語音信息的時間長度匹配到相同了。當然,如果沒有找到時間長度為2分鐘的動作信息,而找到了一個時間長度為了2分半的,那么就可以選取這個2分半的動作信息中的部分動作(可以是部分幀),使選取后的動作信息的時間長度為2分鐘,這樣就可以語音信息的時間長度匹配相同了。
本實施例中,可以根據語音信息的時間長度,選擇與語音信息的時間長度最接近的動作信息,也可以根據動作信息的時間長度選擇最接近的語音信息。
這樣在選擇的時候根據語音信息的時間長度進行選擇,可以方便控制模塊對語音信息和動作信息的時間長度的調整,更加容易調整到一致,而且調整后的播放更加自然,平滑。
根據其中一個示例,在將語音信息的時間長度和動作信息的時間長度調整到相同的步驟之后還包括:將調整后的語音信息和動作信息輸出到虛擬影像進行展示。
這樣就可以在調整一致后進行輸出,輸出可以是在虛擬影像上進行輸出,從而使虛擬機器人更加擬人化,提高用戶體驗度。
根據其中一個示例,所述機器人的生活時間軸的參數的生成方法包括:
將機器人的自我認知進行擴展;
獲取生活時間軸的參數;
對機器人的自我認知的參數與生活時間軸中的參數進行擬合,生成機器人的生活時間軸。
這樣將生活時間軸加入到機器人本身的自我認知中去,使機器人具有擬人化的生活。例如將中午吃飯的認知加入到機器人中去。
根據其中另一個示例,所述將機器人的自我認知進行擴展的步驟具體包括:將生活場景與機器人的自我認識相結合形成基于生活時間軸的自我認知曲線。
這樣就可以具體的將生活時間軸加入到機器人本身的參數中去。
根據其中另一個示例,所述對機器人的自我認知的參數與生活時間軸中的參數進行擬合的步驟具體包括:使用概率算法,計算生活時間軸上的機器人在時間軸場景參數改變后的每個參數改變的概率,形成擬合曲線。這樣就可以具體的將機器人的自我認知的參數與生活時間軸中的參數進行擬合。其中概率算法可以是貝葉斯概率算法。
例如,在一天24小時中,使機器人會有睡覺,運動,吃飯,跳舞,看書,吃飯,化妝,睡覺等動作。每個動作會影響機器人本身的自我認知,將生活時間軸上的參數與機器人本身的自我認知進行結合,擬合后,即讓機器人的自我認知包括了,心情,疲勞值,親密度,好感度,交互次數,機器人的三維的認知,年齡,身高,體重,親密度,游戲場景值,游戲對象值,地點場景值,地點對象值等。為機器人可以自己識別所在的地點場景,比如咖啡廳,臥室等。
機器一天的時間軸內會進行不同的動作,比如夜里睡覺,中午吃飯,白天運動等等,這些所有的生活時間軸中的場景,對于自我認知都會有影響。這些數值的變化采用的概率模型的動態擬合方式,將這些所有動作在時間軸上發生的幾率擬合出來。場景識別:這種地點場景識別會改變自我認知中的地理場景值。
實施例二
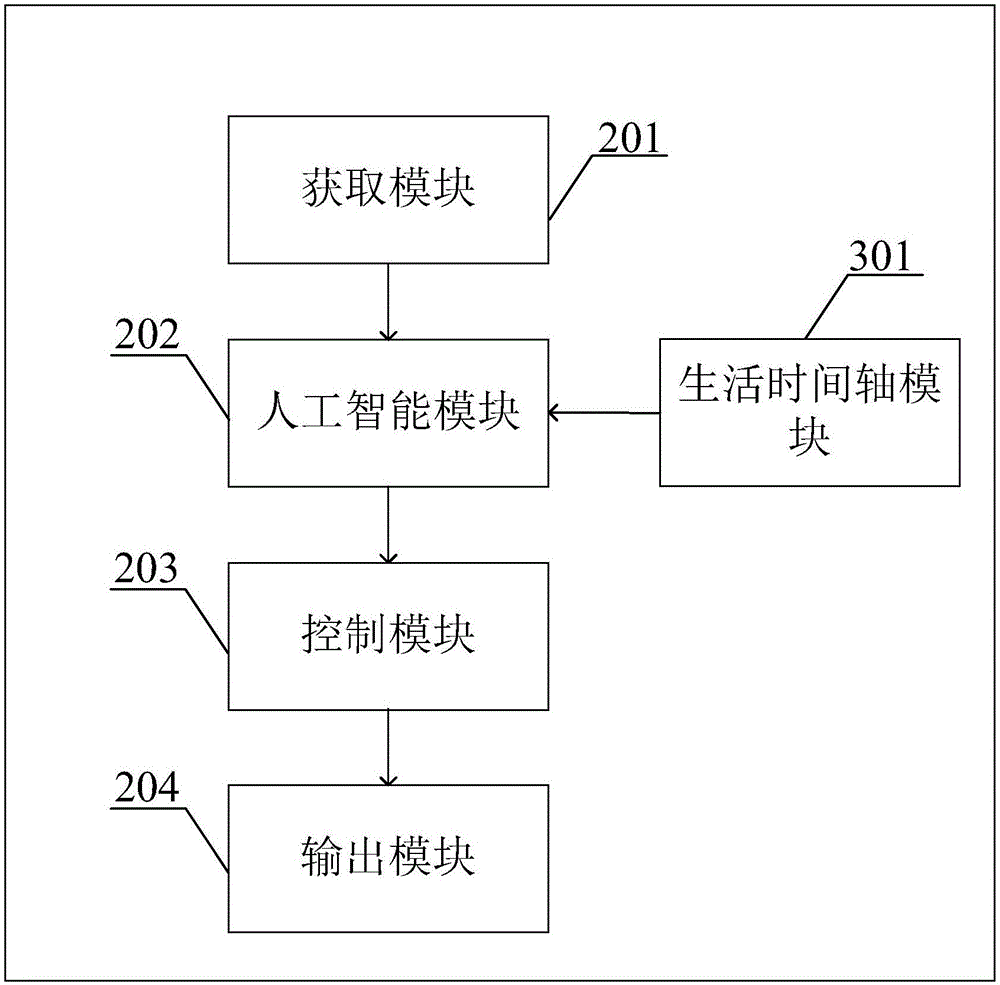
如圖2所示,本實施例中公開一種同步語音及虛擬動作的系統,包括:
獲取模塊201,用于獲取用戶的多模態信息;
人工智能模塊202,用于根據用戶的多模態信息和生活時間軸生成交互內容,所述交互內容至少包括語音信息和動作信息,其中生活時間軸由生活時間軸模塊301生成;
控制模塊203,用于將語音信息的時間長度和動作信息的時間長度調整到相同。
這樣就可以通過用戶的多模態信息例如用戶語音、用戶表情、用戶動作等的一種或幾種,來生成交互內容,交互內容中至少包括語音信息和動作信息,而為了讓語音信息和動作信息能夠同步,將語音信息的時間長度和動作信息的時間長度調整到相同,這樣就可以讓機器人在播放聲音和動作時可以同步匹配,使機器人在交互時不僅具有語音表現,還可以具有動作等多樣的表現形式,機器人的表現形式更加多樣化,使機器人更加擬人化,也提高了用戶于機器人交互時的體驗度。
對于人來講每天的生活都具有一定的規律性,為了讓機器人與人溝通時更加擬人化,在一天24小時中,讓機器人也會有睡覺,運動,吃飯,跳舞,看書,吃飯,化妝,睡覺等動作。因此本發明將機器人所在的生活時間軸加入到機器人的交互內容生成中去,使機器人與人交互時更加擬人化,使得機器人在生活時間軸內具有人類的生活方式,該方法能夠提升機器人交互內容生成的擬人性,提升人機交互體驗,提高智能性。交互內容可以是表情或文字或語音或動作等一種或幾種的組合。機器人的生活時間軸300是提前進行擬合和設置完成的,具體來講,機器人的生活時間軸300是一系列的參數合集,將這個參數傳輸給系統進行生成交互內容。
本實施例中的多模態信息可以是用戶表情、語音信息、手勢信息、場景信息、圖像信息、視頻信息、人臉信息、瞳孔虹膜信息、光感信息和指紋信息等其中的其中一種或幾種。
本實施例中,基于生活時間軸具體是:根據人類日常生活的時間軸,按照人類的方式,將機器人本身在日常生活時間軸中的自我認知的數值做擬合,機器人的行為按照這個擬合行動,也就是得到一天中機器人自己的行為,從而讓機器人基于生活時間軸去進行自己的行為,例如生成交互內容與人類溝通等。假如機器人一直喚醒的話,就會按照這個時間軸上的行為行動,機器人的自我認知也會根據這個時間軸進行相應的更改。生活時間軸與可變參數可以對自我認知中的屬性,例如心情值,疲勞值等等的更改,也可以自動加入新的自我認知信息,比如之前沒有憤怒值,基于生活時間軸和可變因素的場景就會自動根據之前模擬人類自我認知的場景,從而對機器人的自我認知進行添加。生活時間軸中不僅包括語音信息,也包括了動作等信息。
例如,用戶向機器人說話:“好困啊”,機器人聽到后理解的為用戶很困,然后結合機器人的生活時間軸,例如當前的時間為上午9點,那么機器人就知道主人是剛剛起床,那么就應該向主人問早,例如回答語音“早上好”作為回復,還可以唱一首歌,并配上相應舞蹈動作等。而如果用戶向機器人說話:“好困啊”,機器人聽到后理解的為用戶很困,然后機器人的生活時間軸,例如當前的時間為晚上9點,那么機器人就知道主人需要睡覺了,那么就會回復語音“主人晚安,睡個好覺”等類似用語,并配上相應的晚安、睡眠動作等。這種方式要比單純的語音和表情回復更加貼近人的生活,具有動作更加擬人化。
本實施例中,所述控制模塊具體用于:
若語音信息的時間長度與動作信息的時間長度的差值不大于閾值,當語音信息的時間長度小于動作信息的時間長度,則加快動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
當語音信息的時間長度大于動作信息的時間長度,則加快語音信息的播放速度或/和減緩動作信息的播放速度,使動作信息的時間長度等于所述語音信息的時間長度。
因此,當語音信息的時間長度與動作信息的時間長度的差值不大于閾值,調整的具體含義可以壓縮或拉伸語音信息的時間長度或/和動作信息的時間長度,也可以是加快播放速度或者減緩播放速度,例如將語音信息的播放速度乘以2,或者將動作信息的播放時間乘以0.8等等。
例如,語音信息的時間長度與動作信息的時間長度的閾值是一分鐘,機器人根據用戶的多模態信息生成的交互內容中,語音信息的時間長度是1分鐘,動作信息的時間長度是2分鐘,那么就可以將動作信息的播放速度加快,為原來播放速度的兩倍,那么動作信息調整后的播放時間就會為1分鐘,從而與語音信息進行同步。當然,也可以讓語音信息的播放速度減緩,調整為原來播放速度的0.5倍,這樣就會讓語音信息經過調整后減緩為2分鐘,從而與動作信息同步。另外,也可以將語音信息和動作信息都調整,例如語音信息減緩,同時將動作信息加快,都調整到1分30秒,也可以讓語音和動作進行同步。
此外,本實施例中,所述控制模塊具體用于:
若語音信息的時間長度與動作信息的時間長度的差值大于閾值,當語音信息的時間長度大于動作信息的時間長度時,則將至少兩組動作信息進行組合,使組合后的動作信息的時間長度等于所述語音信息的時間長度。
當語音信息的時間長度小于動作信息的時間長度時,則選取動作信息中的部分動作,使選取的部分動作的時間長度等于所述語音信息的時間長度。
因此,當語音信息的時間長度與動作信息的時間長度的差值大于閾值,調整的含義就是添加或者刪除部分動作信息,以使動作信息的時間長度與語音信息的時間長度相同。
例如,語音信息的時間長度與動作信息的時間長度的閾值是30秒,機器人根據用戶的多模態信息生成的交互內容中,語音信息的時間長度是3分鐘,動作信息的時間長度是1分鐘,那么就需要將其他的動作信息也加入到原本的動作信息中,例如找到一個時間長度為2分鐘的動作信息,將上述兩組動作信息進行排序組合后就與語音信息的時間長度匹配到相同了。當然,如果沒有找到時間長度為2分鐘的動作信息,而找到了一個時間長度為了2分半的,那么就可以選取這個2分半的動作信息中的部分動作(可以是部分幀),使選取后的動作信息的時間長度為2分鐘,這樣就可以語音信息的時間長度匹配相同了。
本實施例中,可以為所述人工智能模塊具體用于:根據語音信息的時間長度,選擇與語音信息的時間長度最接近的動作信息,也可以根據動作信息的時間長度選擇最接近的語音信息。
這樣在選擇的時候根據語音信息的時間長度進行選擇,可以方便控制模塊對語音信息和動作信息的時間長度的調整,更加容易調整到一致,而且調整后的播放更加自然,平滑。
根據其中一個示例,所述系統還包括輸出模塊204,用于將調整后的語音信息和動作信息輸出到虛擬影像進行展示。
這樣就可以在調整一致后進行輸出,輸出可以是在虛擬影像上進行輸出,從而使虛擬機器人更加擬人化,提高用戶體驗度。
根據其中一個示例,所述系統包括基于時間軸與人工智能云處理模塊,用于:
將機器人的自我認知進行擴展;
獲取生活時間軸的參數;
對機器人的自我認知的參數與生活時間軸中的參數進行擬合,生成機器人生活時間軸。
這樣將生活時間軸加入到機器人本身的自我認知中去,使機器人具有擬人化的生活。例如將中午吃飯的認知加入到機器人中去。
根據其中另一個示例,所述基于時間軸與人工智能云處理模塊具體用于:將生活場景與機器人的自我認識相結合形成基于生活時間軸的自我認知曲線。這樣就可以具體的將生活時間軸加入到機器人本身的參數中去。
根據其中另一個示例,所述基于時間軸與人工智能云處理模塊具體用于:使用概率算法,計算生活時間軸上的機器人在時間軸場景參數改變后的每個參數改變的概率,形成擬合曲線。這樣就可以具體的將機器人的自我認知的參數與生活時間軸中的參數進行擬合。其中概率算法可以是貝葉斯概率算法。
例如,在一天24小時中,使機器人會有睡覺,運動,吃飯,跳舞,看書,吃飯,化妝,睡覺等動作。每個動作會影響機器人本身的自我認知,將生活時間軸上的參數與機器人本身的自我認知進行結合,擬合后,即讓機器人的自我認知包括了,心情,疲勞值,親密度,好感度,交互次數,機器人的三維的認知,年齡,身高,體重,親密度,游戲場景值,游戲對象值,地點場景值,地點對象值等。為機器人可以自己識別所在的地點場景,比如咖啡廳,臥室等。
機器一天的時間軸內會進行不同的動作,比如夜里睡覺,中午吃飯,白天運動等等,這些所有的生活時間軸中的場景,對于自我認知都會有影響。這些數值的變化采用的概率模型的動態擬合方式,將這些所有動作在時間軸上發生的幾率擬合出來。場景識別:這種地點場景識別會改變自我認知中的地理場景值。
本發明公開一種機器人,包括如上述任一所述的一種同步語音及虛擬動作的系統。
以上內容是結合具體的優選實施方式對本發明所作的進一步詳細說明,不能認定本發明的具體實施只局限于這些說明。對于本發明所屬技術領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干簡單推演或替換,都應當視為屬于本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!